1. Introduction
Elderly individuals (over 65 years old) represent the fastest growing segment of the population worldwide [
1]. In China, the percentage of elderly individuals was 8.87% in 2010 and is expected to quadruple between 2015 to 2050 [
2]. In the United States, this was 13% in 2010 and is expected to reach 20.2% by 2050. In Europe, this was 22.5% in 2005 and is expected to reach 30% by 2050 [
2]. In Japan, this was already 27.7% in 2017 and will reach 35.3% by 2040 [
3]. Worldwide, the population of elderly individuals over 80 years old was 126.5 million in 2015 and is expected to be more than triple that by 2050, increasing to 446.6 million [
1]. According to the World Health Organization, 28%–35% of elderly individuals have an accident involving a fall each year [
4]. According to the National Safety Council, 21,600 Americans lost their lives from falling in 2007 and over 80% were elderly [
5]. Globally, accidents involving falls, which are the second leading cause of unintentional death, are considered one of the most hazardous incidents for the elderly, with over 424,000 deaths occurring in 2008 [
4]. Although many falls do not cause physical injuries, 47% of the elderly who have fallen cannot stand up without assistance [
6]. If a solitary elderly individual falls, he or she may be lying on the floor for a long time without any help. Therefore, a fall-detection method that can automatically detect a fall in real time and send alerts to certain caregivers (such as family members, hospitals or health centers [
7]) is important for solitary elderly individuals as well as playing an important part in the health care system for the elderly [
8].
Fall-detection methods are roughly categorized into four groups, that is, radio-wave based, wearable/mobile-device based, pressure-sensor based and vision based. Vision-based methods are considered promising [
9]. Although such methods have been studied, many have limitations in terms of practicality [
10]. Some methods [
11,
12,
13,
14] establish a background model and use an image-subtraction method to segment the individual then extract features of that individual to detect a fall. However, such image-difference-based methods fail if the layout or lighting of the room changes, for example, switching lights on or changing the lighting level. The study in Reference [
15] also used a dual subtraction method (background subtraction and frame subtraction) to determine the effect of moved furniture on fall-detection accuracy but the effect of light has remained a problem. Three-dimensional (3D) molding [
9,
16] and deep-learning [
17,
18] methods provide a good solution to this problem since they are robust against light conditions. However, they cannot be used in dark rooms. Few studies used infrared cameras instead of RGB cameras [
19].
A depth camera/sensor [
20,
21] is independent of illumination and many fall-detection methods have benefited from depth-based algorithms [
22]. Previous studies [
23,
24,
25,
26] used the 3D coordinates of the skeleton as features to successfully detect falls. However, these methods heavily depend on the skeleton-detection results from Kinect SDK or OpenNI, which are not reliable [
8,
22]. Previous studies [
27,
28,
29] analyzed the 2D or 3D shape of humans to detect falls. However, there are problems with such shape-based methods. If an individual falls on the floor, the depth information of the floor and that of the individual are very similar, according to previous studies [
8,
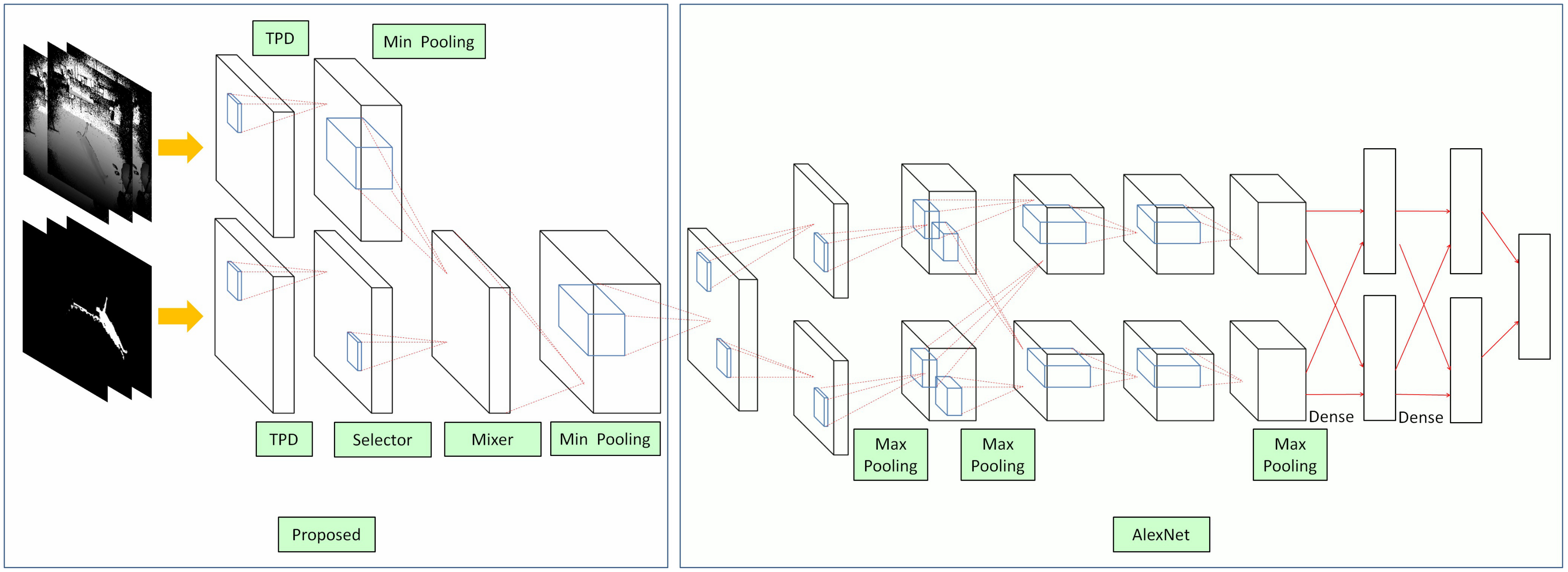
22] and our experimental results. This results in many tracking loss or wide-ranging noise. This study proposes Enhanced Tracking and Denoising Alex-Net (ETDA-Net) to solve this problem. The experimental results indicate that ETDA-Net outperforms traditional deep-learning-based methods (LeNet, AlexNet and GoogLeNet).
Due to differences in rooms, users may set a camera or sensors at the same height. Does camera height affect fall-detection accuracy? Few studies take this into consideration [
26,
30]. Moreover, few open data sets for fall detection are available to analyze the effect of camera height. The data set created in Reference [
12] represents various falls in different directions. That created in Reference [
13] recorded numbers of daily activities and falls in different directions. The data set created Reference [
31] is a well-constructed data set and images taken in different rooms, for example offices and coffee rooms, are provided. However, only a single camera was used for this data set and the camera height is not mentioned for their experiments. The data set created in Reference [
32] includes depth images but there are only 21,499 images. That created in Reference [
33] is a well-constructed data set and 12 people participated in their experiment. However, the camera was set at only one height, which was too low to avoid occlusion problems. The data set created in References [
14,
34] is also well-constructed and includes 30 fall videos and 40 videos of daily activities. Synchronization and accelerometer data were also recorded. However, the camera was set at a very low position, which may be occluded by furniture (although another camera was placed on the ceiling, it only recorded fall videos). Thus, this study creates a data set and analyzed how the camera affects fall-detection accuracy. In this data set, 16 types of daily activities (walking with a stick, sitting on a chair, sitting on the floor, using a smartphone, drinking water, etc.) and 16 types of falls (facing left, right, floor, ceiling, with/without leg bending, etc.) are carried out in eight directions and taken with the depth camera at five different heights. Eight people participated in the experiment and about 350,000 images (frames) are included in our data set. Not only depth images but also human segmentation results are provided, which will be convenient for comparative analysis.
From the experimental results, the proposed ETDA-Net provides better tacking and denoising performance than Kinect SDK and is robust against camera height. It automatically detects camera height and selects the most suitable model (trained using the images taken at the same height ) to detect a fall. The results also indicate that even if the camera height is not calculated correctly, ETDA-Net still provides a good detection rate.
The contributions of our study are as follows:
This study analyzes how camera height affects fall-detection accuracy, which has rarely been studied before.
This study proposes a self-adaptation fall-detection method that automatically calculates camera height and selects the most suitable detection model.
Depth-image-based person segmentation by using Kinect SDK has been widely used in previous studies but the tracking and noise problem were rarely addressed. The proposed ETDA-Net solves this problem.
This study creates a data set consisting of 350,000 images, more than those used in related studies. This data set includes various daily actives and falls. Each action is done in eight different directions and recorded using a depth camera at five different heights. The human-segmentation results are also included in this data set, not only for this research but also for comparative analysis.
The rest of this paper is organized as follows—
Section 2 reviews related works.
Section 3 introduces our fall-detection data set.
Section 4 presents the proposed fall detection system and the experimental results are shown in
Section 5. Finally,
Section 6 concludes this paper.
2. Related Work
Fall-detection methods are roughly categorized into four groups—radio-wave based, wearable/mobile-device based, pressure-sensor based and vision based.
2.1. Radio-Wave-Based Methods
Radio-wave-based methods are roughly categorized into two types: traditional and wireless. The major advantages of these methods are non-intrusive sensing and privacy preservation.
Radar-based fall-detection methods have a strong penetrating ability and are robust against environmental factors such as illumination and humidity. Reference [
35] proposed a dual-band radar-based fall-detection method. By optimizing the full ground plane and small element spacing, high mutual coupling is reduced by at least 10 dB. The effective distance with this method is 4 m at 0 degrees. However, only limited postures can be detected with the radar and some non-fall events are still detected as fall events [
36]. To address this issue, Reference [
37] recorded several types of daily activities (standing, walking, sitting and bending) and segmented them from several types of fall events (slipping, fainting and tripping). A hidden Markov model is used to analyze the frequency corresponding to the fall rate and is highly accurate. As vision-based and sound-based methods are obviously not preferred in the bathroom, Reference [
38] proposed an interesting radar-based fall-detection method that consists of two stages: Prescreen and classification. The first stage identifies when a fall may occur and the second stage extracts the frequency signals from wavelet coefficients at many scales as features to classify. Their experiment showed that this method performs robustly in bathrooms. Due to the limitations of traditional machine-learning methods, Reference [
39] proposed a radar-based method using deep learning and achieved high fall-detection accuracy. However, many radar-based methods are used in areas where the radar signal is not limited and the objects between the radar (such as pets and furniture) are not taken into consideration [
40], resulting in these methods not being practical. Solving these problems may be interesting future work. The wireless-based fall detection method WiFall was proposed [
41,
42], which uses commercial Wi-Fi devices. The main idea with this method is to use the sharp power-profile-decline pattern to detect falls and its major advantage is that it detects falls with a commercial Wi-Fi device without the need for any other sensors or wearable devices. Although wireless-based methods are an exciting solution to fall detection, there are still problems with them. They are not robust against environmental changes and different types of or many people.
2.2. Wearable/Mobile-Device-Based Methods
Wearable-device-based fall-detection methods are roughly categorized into two types: Wearable-sensor based and wearable-camera based. The main advantage of these methods is that they work both indoors and outdoors. Wearable-sensor-based methods have been widely studied as they are low cost and non-invasive in terms of privacy. Traditional machine-learning-based fall-detection methods involving wearable sensors usually use a non-lapping [
43] or overlapping [
44,
45] sliding window to segment the data then extract features to classify fall and non-fall events. However, these methods may lose useful information. Reference [
46] proposed a machine-learning-based method that is triggered by a fall event. This method uses a buffer to restore samples as a pre-process then detects multiple peaks as the trigger time. By comparing the samples in the buffer, fall/non-fall events are classified. The computational cost of this method is just 80% that of a non-overlapping sliding-window-based method and 78% that of an overlapping sliding-window-based method. However, the accuracy is still not high enough for practical use. To address this issue, Reference [
47] applied a Kalman filter to a non-liner filter to reduce the error rate of fall-event detection and Reference [
48] collected actual data of elderly individuals and compared several methods to improve the fall-detection rate. Reference [
49] developed a fog-computing-based deep-learning method and improved its performance by using a data-augmentation technique. Reference [
50] developed an application for smart watches to collect the actual data of volunteers to train a fall-detection model and considered problems for practical use, for example, habits of elderly individuals and the last time of battery. As there are few publicly available data sets for sensor-based fall detection, the approach of Reference [
51] creates an accelerometer and one gyroscope-based fall-detection data set, which is a well-constructed data set. Nineteen types of daily activities and 15 types of fall activities are included in this data set. Unlike other fall-detection data sets, the data of 14 actual elderly individuals over 60 years old are provided. The wearable-camera-based fall-detection methods proposed by References [
52,
53,
54] involve fixing a camera to a waistband and detecting falls by analyzing the changes in the images taken with the camera. This is an interesting solution that combines the advantages of vision-based and wearable-sensor-based methods. However, it is weak in terms of privacy. As wearable-sensor-based methods can be used almost ubiquitously and the sensor is low cost, commercial wearable devices have been developed, such as Apple Watch 4 [
55], Medical Guardian Fall Alert [
56] and Philips Lifeline Auto Alert [
57].
2.3. Pressure-Sensor-Based Methods
Although wearable/mobile-device based methods perform well, they may be weak at night. When an elderly individual goes to the toilet at night, she/he may forget to wear the smart sensor/watch or take his/her smart phone. In such a case, the elderly individual cannot be monitored [
58] under weak light conditions at night [
8]. Pressure-sensor-based methods provide a good solution to this problem since an elderly individual does not need to wear any device. The method proposed by Reference [
59] tracks an individual by using NFI floor [
60], then the features associated with that individual are extracted. We extracted the number of observations, longest dimension and sum of magnitudes as features and estimated the pose of the individual by using these features to detect falls. The method in Reference [
58] involves using pressure mate sensors (PMSs) and passive infrared sensors (PISs) to detect falls. The actions of ten elderly individuals generated using a simulator were used to create a data set. When an individual has fallen, the PMS and PIS are turned OFF and the fall is detected. The method proposed in Reference [
61] involves using fiber-optic sensors to detect falls. Pressure is detected with these sensors and a histogram is created to analyze human activity. If an individual is lying down longer than a threshold, a fall is detected. As pressure sensor-based methods cannot differentiate between falls and lying down for long periods, the method in Reference [
62] uses the fusion between pressure sensors and accelerometers hidden under smart tiles to detect falls and improve fall-detection accuracy. Pressure-sensor-based methods are low cost, reliable and accurate but not easy to install and maintain. Solving these problems is for future work.
2.4. Vision-Based Methods
Vision-based fall-detection methods have recently been studied since users do not need to wear devices or charge batteries. When an elderly individual goes to the toilet at night, she/he may forget to put on the wearable device or charge the battery. Therefore, although camera-based methods are limited to a very restricted area, they are still useful for elderly individuals. Some studies categorized vision-based methods into two types—RGB-camera based and depth-camera based [
8,
29]. Depth-camera-based methods usually perform better since the depth camera is not affected by the changes in illumination; thus, works well in dark rooms, and does not invade privacy. Hence, depth-camera-based methods are gaining attention. However, many RGB-camera-based methods can be used to effectively process depth-based images. Therefore, we surveyed vision-based methods by categorizing them into two types based on the analysis method: skeleton and shape. Skeleton-tracking-based methods usually involve depth cameras to capture images, as it is easy to track the 3D joints of people. The methods proposed in References [
23,
24] obtain the 3D coordinates of joints and the ground-plane equation. Falls can be detected by analyzing their relationship. The method proposed in Reference [
29] uses a support vector machine (SVM) to classify the 3D coordinates of joints during fall and non-fall events but only walking, sitting and falling are taken into consideration. The method proposed in Reference [
25] extracts the changing rate of the torso angle as a feature by using 3D skeleton coordinates to classify falls from other fall-like activities. The method proposed in Reference [
63] extracts similar features to predict fall risk. The accuracy of these methods is very high but the main drawback is that they heavily depend on the skeleton-detection results from Microsoft Kinet SDK or OpenNI and are not reliable enough [
8]. Reference [
28] proposed a head-tracking method but the camera is set at a very low position, which may be occluded by furniture. The methods proposed in References [
25,
29,
63] face the same problem. Shape analyzing is also a good method for detecting falls. Bounding boxes and bounding-ellipse-based fall-detection methods were proposed more than a decade ago [
11] and are still effective in detecting falls and have been improved [
7,
64]. The main drawback of these methods is that bounding boxes are heavily affected by the camera direction and shape analyses based on histogram analysis [
15] have the same problem. Thus, multiple cameras are necessary to achieve high accuracy. To address this issue, fusion of data obtained from different cameras is an alternative and has been recently studied. The method in Reference [
16] involves setting up four cameras and using voting algorithms to detect falls in different directions. To cover a larger range, multiple cameras have been used [
12]. Three-dimensional shape analysis is a good solution to this issue [
27] but incurs a high computational cost [
65].
2.5. Discussion
Based on the results of our survey, we found the following problems to address and we design our algorithm and experiment.
Q1: Many studies fixed the camera at only one height. This limits the fall-detection method in terms of practicality since users may not set the camera at the same height. Does the camera height affect the fall-detection results? Is it possible to design a fall-detection method that is robust against camera height?
Since no data set is available to analyze how camera height affects fall-detection accuracy, this study creates a large data set consisting of 16 daily activities and 16 types of falls. Each activity is carried out by eight people in eight directions and taken with a depth camera at five different heights. About 350,000 images (frames) are included in this data set. This data set also includes human-segmentation results, which will be convenient for comparative analysis. Furthermore, these images are analyzed using a machine-learning method and deep-learning methods to study the effect of camera height on fall-detection accuracy.
Q2: Many studies were heavily based on the human/skeleton tracking results from Kinect SDK but they are not reliable enough. Is it possible to improve upon human tracking?
This study captures a large number of depth images and recorded the human tracking results of Kinect SDK (human segmentation). We then developed ETDA-Net to solve the problems found in these images and classify theme into fall and non-fall images.
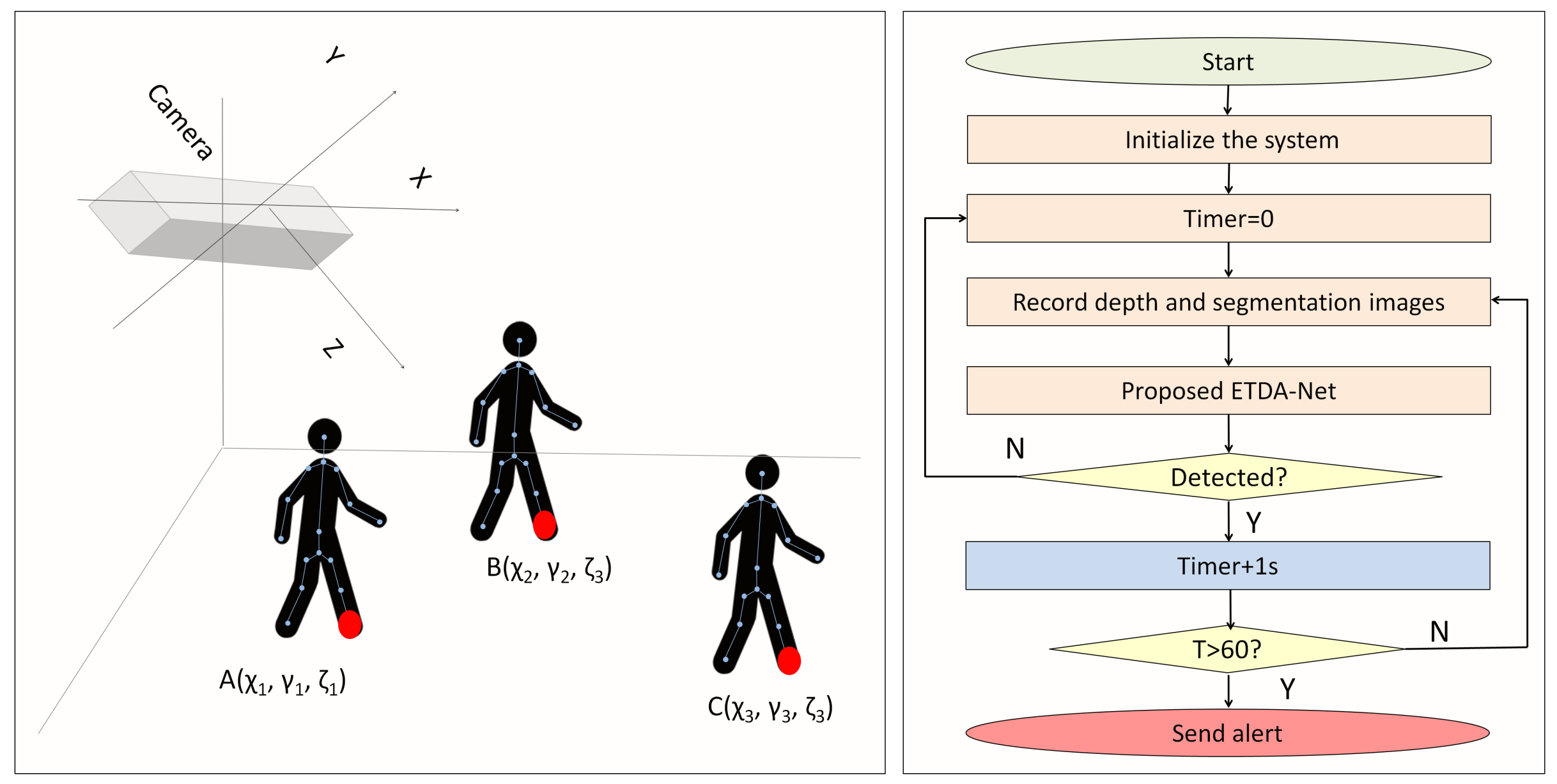
Q3: Since users may set the camera at different heights, is it possible to have the system automatically detect camera height and select the most suitable model to initialize the fall-detection method?
This study designs an algorithm to automatically detect the height of the camera and select the most suitable model to detect falls.
3. Fall-Detection Data Set
A data set is important for vision-based fall-detection methods. However many have limitations as mentioned above:
The data set created in Reference [
31] includes seven groups of images. The main contribution of this data set is that images taken in different rooms, for example, offices and coffee rooms, are provided. However, only a single camera was used with this data set and the camera height were not mentioned in this study. The data set created in Reference [
32] includes depth images but there are only 21,499 images. That created in Reference [
33] is a well-constructed data set and 12 people participated in their experiment. However, the camera was set at only one height, which was too low to avoid occlusion problems. The data set created in Reference [
34] is also well-constructed and includes 30 fall videos and 40 videos of daily activities. Synchronization and accelerometer data are also recorded. However, the camera was set at a very low position, which may be occluded by furniture (although another camera was set on the ceiling, it only recorded fall videos) in their experiment.
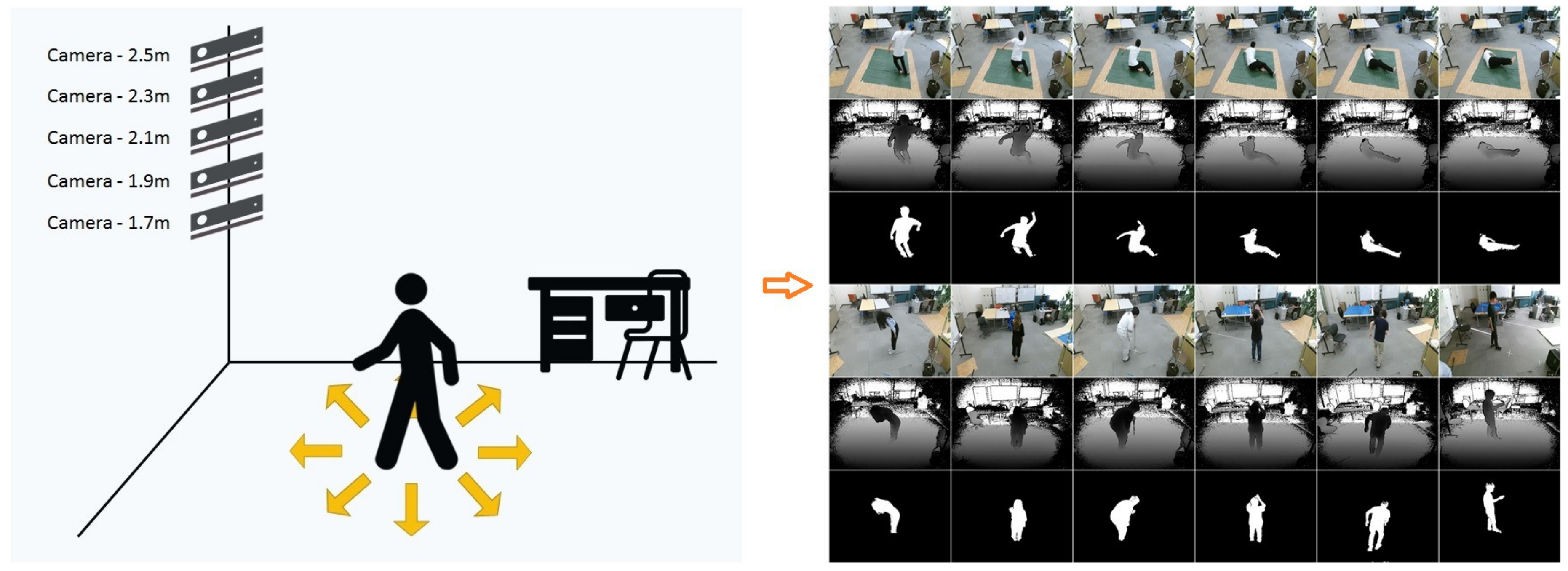
The images in our data set to study the effect of camera height on fall-detection accuracy are captured using a Kinect V2 depth sensor linked to a notebook PC. The CPU of this notebook PC is Intel core i5 5200 u and the memory is 4 GB. The frame rate is 20 fps. As mentioned above, this data set provides depth images and consists of 16 daily activities (walking, running, kicking, bowing, bending, walking with a stoop, clipping, rising hands, waving hands, looking at a watch, using a smartphone, throwing, drinking water, collecting, walking with a stick, sitting on the chair/floor) and 16 types of falls (facing ceiling, floor, left, right, with/without curled up legs, with left/right hand moving), as shown in
Table 1. Facing floor means the final state of the fall is the person ending up facing the floor (facing ceiling, left, right have the similar respective meanings). Each activity is carried out by eight people in eight directions and taken using a camera at five different heights (1.7, 1.9, 2.1, 2.3 and 2.5 m). Each activity is repeated 2–3 times at each direction. A total of 800 streams (640 non-fall streams and 160 fall streams) with about 350,000 depth images (frames) are included in this data set. This data set also includes human segmentation results, which will be convenient for comparative analysis, as shown in
Figure 1. This data set is publicly available [
66] and the information of 8 participants is shown in
Table 2.
5. Experimental Results
5.1. Experimental Results of System Initialization
The main process of system initialization is automatically calculating camera height. The experimental results are listed in
Table 3. The proposed method accurately detected camera height. The height is a little lower than the actual height because this method uses the coordinates of ankle joints instead of those of the actual floor. This work measure the ankle height of different subjects and finds out the average height is 9.2 cm. Therefore, this work gives a correction parameter to measure the height more rigorously.
5.2. Experimental Results from Human Segmentation
The results of human segmentation are shown in
Figure 5. The first row shows the depth images, the second row shows the human segmentation results of Kinect SDK and the third row shows the human segmentation results using ETDA-Net. ETDA-Net produced better results in both human tracking and denoising.
5.3. Parameters and Performance-Evaluation Metrics
The eight participants in the experiment are divided into four groups. Participants A and B are in group 1, C and D in group 2, E and F in group 3 and G and H in group 4. During each test, three groups are for training and the remaining group is for testing to make the test data different with the training data. Then The data are trained using a desktop PC. The operation system is Ubuntu 16.04, the CUP is Intel(R) Xeon(R) CPU E5-1650 v4 3.60GHz and the GPUs are triple NVIDIA GTX 1080Ti with 33-GB memory. The framework is Torch and the hyper-parameters of the CNN are optimized automatically by NVIDIA DIGITS 6 [
70]. The window size of 64 × 128, block size of 16 × 16, block stride of 8 × 8 and a cell size of 8 × 8 (only these sizes are supported at OpenCV) [
72] are set as the parameters of histogram of oriented gradient (HOG) features. A totally of 800 video streams with 240,000 images (frames) are used in the experiment (not all the frames are used since the fall streams contained non-fall frames), while 180,000 images (frames) are used for training and 60,000 are used for testing. At each height, 6000 fall states (frames) and 6000 non-fall states (frames) are included. The shape of a participant does not change with distance but the size does. Therefore, the images of the participants are normalized to 256 × 256 (for AlexNet, GoogLeNet and ETD-AlexNet) or 28 × 28 (for LeNet) before input to the neural network.
We used the following performance-evaluation metrics proposed in Reference [
73] to analyze the experimental results.
True positive () is the number of fall events accurately detected.
True negative () is the number of non-fall events accurately detected.
False positive () is the number of non-fall events detected as fall events.
False negative () is the number of fall events detected as non-fall events.
In the study in Reference [
73], sensitivity (
), specificity (
), accuracy (
) and error (
) are given by the following formulas to obtain the performance-evaluation metrics:
5.4. Effect of Camera Height and Comparison
Table 4,
Table 5 and
Table 6 compare the experimental results of sensitivity, specificity and accuracy, respectively. The
column means the camera height at which training images are taken and the
column means the camera height at which test images are taken. The performance of ETDA-Net is compared with the machine-learning method HOG+SVM [
74] and deep-learning methods LeNet [
75], AlexNet [
71] and GoogLeNet [
76]. The effect of camera height on fall-detection accuracy is clearly illustrated in these tables. The fall-detection accuracy is high if the training images and test images are taken with the camera at the same height. However, the more this differs, the lower the accuracy. Therefore, camera height is an important parameter for fall-detection methods, which has been ignored in many studies.
Several studies set the camera at a low position. If the user sets the camera at a higher position, according to the experimental results, fall detection accuracy will drastically reduce, especially when the camera is set at a height of over 2.3 m.
According to these tables, the accuracy of HOG+SVM decreased by 38.4%, 17.5%, 20.2%, 25.9% and 31.9% at 1.7, 1.9, 2.1, 2.3 and 2.5 m, respectively, that of LeNet decreased by 50.5%, 12.1%, 35.7%, 31.1% and 50.4%, that of AlexNet decreased by 19.3%, 5.4%, 28.9%, 3.2% and 24.9%, that of GoogLeNet decreased by 10.7%, 4.2%, 21.5%, 2.3% and 29.2% and that of ETDA-Net decreased by 15.7%, 2.9%, 13.7%, 0.3% and 17.3% (the farthest distance is treated as a reference). ETDA-Net exhibited the most robust performance at 1.9, 2.1, 2.3 and 2.5 m. It only takes about 1.3 h to train ETDA-Net, while the training time of GoogLeNet is more than 8 h (trained by all the available data for each group). This lowered the computational cost of ETDA-Net compared to GoogLeNet, whose performance is similar to that of ETDA-Net. When the model is trained by all the available data, the robust performance is the best but is still less than 100%. Therefore, if the camera height is accurately calculated, ETDA-Net trained by the same height provides good fall-detection results.
5.5. Discussion and Future Work
Training on all or some images: As shown in
Table 4,
Table 5 and
Table 6, when the model is trained on all the available data, ETDA-Net exhibits the best robust performance. When the model is trained on only one height, the accuracy is higher (only when the camera height is accurately calculated) but performance becomes less robust. Considering the effect of furniture/pets, the camera height may not be accurately calculated; therefore, training the model with images at different heights may be a robust and credible solution at the current state. Developing an algorithm to calculate the camera height more efficiently and reliably will be for future work. This study confirms that training the model on images taken at different heights or calculating the camera height and selecting the model is necessary.
Sensitivity or specificity: Although ETDA-Net provides good results, it is still not unquestionably better than GoogLeNet: ETDA-Net has higher specificity, so it raises less false alarms; However, sometimes it has lower sensitivity (e.g., for the training data acquired at 1.7 m), so it ignores more actual falls. In other words, the sensitivity of a fall-detection method is more important because each non-detected fall may lead to death, while a false alarm may only lead to an unnecessary visit of a health-care personnel. Therefore, improving the sensitivity of ETDA-Net will be interesting future work.
Camera orientation: Since the monitoring angle (depth) of Kinect is only 70 degrees (horizontal) and 60 degrees (vertical), a large room cannot be monitored [
30], so the camera orientation is difficult to analysis; Therefore, it is set manually in our study. If the sensor is set at a high place (no less than 2.0 m) and the angle between the wall and main optical axis is more than 23.75 degrees, a larger range can be monitored [
30]. On the other hand, when the camera is placed parallel to the subject or up to 35 degrees higher, the accuracy is higher with the method in Reference [
26]. However, as the monitoring angle of Kinect is not wide enough, the analysis of camera orientation makes little sense in our study. Therefore, the development of a wide-angle depth camera and analysis of the orientation of this camera will be for future work.

 and
and 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}