1. Introduction
Currently, brain tumor diagnosis mainly relies on the histopathological analysis of tissue biopsies, where the expert decision, based on visual inspection of the tissue slides, is the gold standard for diagnosis. In some cases, this expert decision system can be biased depending on the experience of the pathologist in the diagnosis of brain samples. In 2016, the World Health Organization (WHO) published the last Classification of Tumors of the CNS (Central Nervous System), where the diagnosis of the tissue is performed through employing molecular analysis, in addition to traditional histopathological analysis [
1]. In this sense, the use of new techniques that could help in the automatic identification of brain tissue will improve the reliability of the diagnosis.
Optical techniques have been extensively investigated on various tissues as an aid tool for classifying tumor type and grade [
2,
3]. Infrared (IR) spectroscopy measures the absorption or transmission intensity against wavenumber (different wavenumbers excite different covalent bonds) [
4]. Therefore, altered molecular make-up is demonstrated through differences in intensity between various types of tissues. Based on epithelial thickening, altered nuclear/cytoplasmic ratio, dysplasia, and neovascularization, IR spectroscopic differences offer non-invasive, cost-effective and rapid methods for screening [
2,
5]. In prepared tissue sections on slides, IR absorption spectroscopy has demonstrated great potential to differentiate between tumor grades and tissue types [
6,
7] without exogenous fluorophores. This is achieved based on differences in lipid, protein, and nucleic acid contents, which are altered when the tissue becomes malignant [
6]. The best correlation to malignancy is thought to be the lipid content [
6,
8]. Differences are demonstrated in cell cultures and tissue, and have been tenuously associated with increased cell motility, in line with chromatography and H&E (hematoxylin and eosin) staining [
6,
7,
8,
9].
The work exposed in this paper employs an IR spectroscopic dataset of brain tissue specimens for the development of a decision support system for tissue diagnosis based on a supervised machine learning algorithm. The support vector machines (SVMs) are supervised learning algorithms that are aimed at finding the maximum margin hyperplane that separates two classes [
10]. In this first stage, where the hyperplane is identified (also called the training stage), previously labeled data are used to generate the SVM model. It is possible to classify new data by determining on which side of the hyperplane they are located, and hence establish their class membership. In case the samples are not linearly separable, the use of kernel functions is required to map the input space into a higher-dimensional feature space where the data can be separated. These kernel functions have specific parameters that can be tuned in order to obtain the best discrimination among the different classes. The characteristics of the data to be classified and the type of the classification problem will determine the optimal kernel and parameters to be used. SVMs combined with medical spectroscopy samples have been widely used to analyze different types of diseases, such us the tissue characterization or the diagnostics of lymph nodes in breast cancer [
11,
12], the diagnosis of skin cancer in mice [
13], or the analysis of blood samples to detect dengue infection [
14], among others. SVMs have been also used to classify the identify samples of primary tumors of brain metastases obtained using Raman spectroscopy [
15]. In this work, the authors achieved an accuracy of 96.7% in the discrimination of tumor, necrosis, and normal brain. On the other hand, IR spectroscopic samples of brain tissue have been analyzed by Dreissig et al. [
16] using partial least squares (PLS) regression to identify different types of lipids that could improve the diagnosis of brain tumors. Decision tree-based algorithms, such as Random Forest, combined with a two-dimensional (2D) correlation analysis have been also employed to diagnose brain cancer from serum samples using IR spectroscopy [
17]. In this study, 433 patients were involved, collecting nine spectra from each in the range between 600–4000 cm
−1. The results obtained were quite promising, achieving sensitivities and specificities in the discrimination of cancer and non-cancer serum samples up to 92.8% and 91.5%, respectively.
Although several algorithms have been employed in the literature to analyze spectroscopic samples, in general, SVMs are preferred over other classification algorithms in different fields due to their strong theoretical foundations, good generalization capabilities, and ability to find optimal solutions when a limited number of training samples are available [
10,
18,
19]. In addition, SVMs provide good performance when the training datasets are highly unbalanced [
20,
21]. For these reasons, SVMs have been employed in this work, due to the available IR spectroscopic dataset being highly unbalanced and having only a limited number of samples.
Four different SVM kernels have been analyzed, optimizing their hyperparameters (kernel parameters whose values are set prior to the learning process) for the specific application of distinguishing the IR spectroscopic samples of brain tissue using only their spectral information as input features for the classifier. The type of tissue (tumor or normal), the grade of primary tumors (grade II, grade III, and grade IV), and the type of normal tissue (mixed normal, grey matter, and white matter) have been classified, finding the optimal SVM configuration (kernel and hyperparameters) to classify this type of sample. Finally, the most relevant regions in the IR spectra have been determined and analyzed employing the optimal classifier configuration.
2. Materials and Methods
The experiments accomplished in this research work were performed employing IR spectroscopic data from human brain samples processed using a supervised machine learning algorithm in order to find the most suitable configuration to accurately classify the data. The following sections will describe the methodology and the materials employed to reach the goal of distinguishing different brain tissue samples using spectroscopy.
2.1. Brain Samples
Patients undergoing craniotomy at the Wessex Neurological Centre of the University Hospital of Southampton, United Kingdom (UK), were consented prior to surgery. Patients either had a preliminary diagnosis of glioma or were undergoing a lobectomy for epilepsy treatment. The IR spectroscopic data were collected in two different acquisition campaigns. Ethical approvals were granted under REC08/H0505/165 and REC14/SC/0108 for the first data acquisition campaign (DC1) and for the second data acquisition campaign (DC2), respectively. The normal brain tissue and tumor tissue that were employed in this experiment were resected and not used for diagnostic purposes. Brain tissue was not removed in excess to that required for patients’ treatment. In DC1, a total of 23 patients were recruited over eight months. After refining the method to create pellets that are appropriate for spectroscopy, the samples were obtained. In three cases, some overlying cortex for analysis was obtained; two of these samples had clear grey and white matter. In DC2, a total of eight patients were recruited over six months, and samples were collected during surgery. In two cases, patients were epileptic and were scheduled for a lobectomy. The remaining cases consisted of a mixture of high-grade and low-grade gliomas, where mainly samples of overlying normal cortex were obtained for analysis, due to the lack of normal samples in DC1.
Tissue samples were identified as tumor by the operating surgeon, who was assisted by image guidance. En bloc resection specimens were collected, along with the tissue derived from the ultrasonic aspirator system, which is used extensively in developing a plane around the tumor, and debulking the tumor mass. Samples were washed in sterile 0.9% saline to remove visible blood traces where appropriate. Then, they were weighed and air-dried at approximately 40 °C until they reached a consistency compatible with grinding. Once samples were dried, they were ground into a homogenous powder with KBr powder, using a pestle and mortar. Then, the resulting mixture was fractionated into 0.5-g portions and pressed at ~10 tons in a pellet press with a vacuum facility, to create a solid pellet that is suitable for mounting in the spectrometer. Samples were stored individually at −20 °C with a sachet of silica gel in order to reduce water absorption by KBr.
2.2. Spectrographic Acquisition Systems
The two data acquisition campaigns were recorded using two different spectrometers. In DC1, data were collected through an FT-IR (Fourier transform infrared) spectrometer, Varian 600-IR (Varian Inc., Palo Alto, CA, USA), set in transmission mode and assembled in Agilent Resolutions Pro V.5 (Agilent Technologies, Santa Clara, CA, USA) software, where data were transformed into absorption spectra. This spectrometer covers the wavenumber range from 400 cm−1 to 6000 cm−1 with a spectral resolution of 1.93 cm−1, obtaining 2906 spectral bands. Background was recorded at 20 scans/minute, and each of the sample pellets were recorded at 15 scans/min, which were all obtained at a resolution of 4 cm−1. The spectrometer was continuously purged with nitrogen during its use, and a new background spectrum was recorded at regular intervals. DC2 was captured using a different FT-IR spectrometer, Spectrum BX FT-IR Spectrometer (PerkinElmer, Waltham, MA, USA), set in absorption mode and collected by Spectrum v5.3.1 software (PerkinElmer, Waltham, MA, USA). This spectrometer obtains the samples in the wavenumber rage from 1000 cm−1 to 4000 cm−1 with a spectral resolution of 2 cm−1, having 1501 spectral bands. The previously described acquisition procedure was also followed in this data campaign.
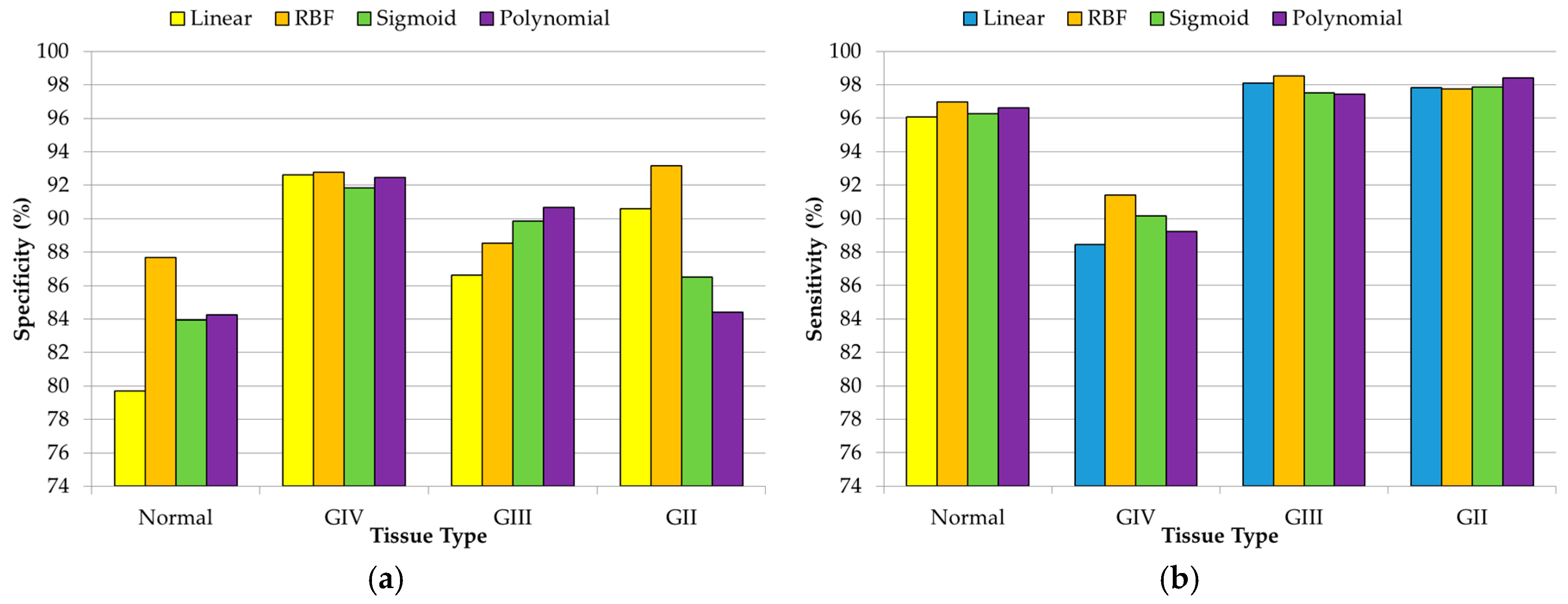
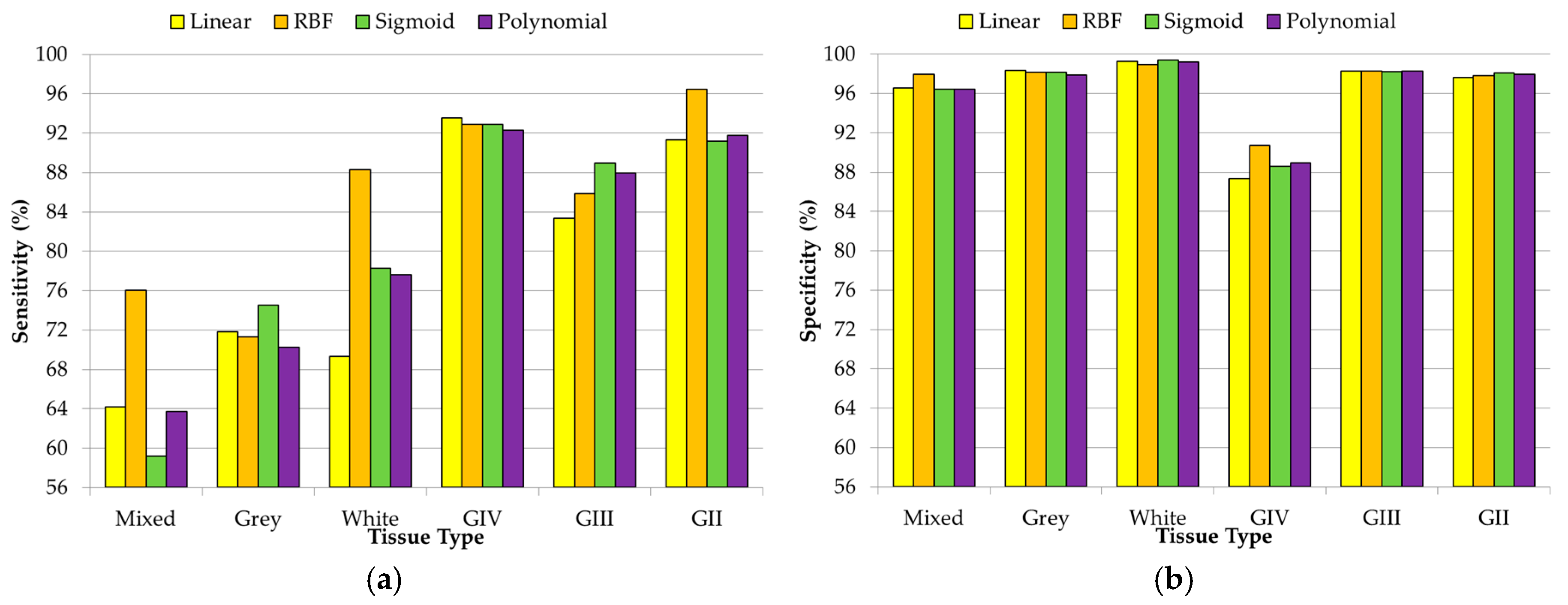
Table 1 shows the total number of IR spectroscopic samples collected in both data campaigns, specifying the type of tissue of each sample. Twenty-three patients from DC1 and eight patients from DC2 were included in this study, collecting a total of 246 spectral signatures. These two data campaigns were merged in order to generate a unique dataset where the samples of the two different spectrometers were included. Three different discrimination levels (DLs) were established to distinguish the different types of tissue available in the database. The use of these DLs implies the definition of different scenarios where the classification of IR spectroscopic data is accomplished by using different abstraction levels for tissue description, and hence, defining a hierarchical labeling where the classification is performed. Discrimination level 1 (DL1) distinguishes between tumor and normal samples. Discrimination level 2 (DL2) allows the discrimination between the grades of the tumor samples (grade II, grade III, and grade IV) and normal samples. Finally, discrimination level 3 (DL3) distinguishes between the different grades of the tumor samples and the different types of normal samples (grey matter, white matter, and mixed normal).
2.3. Data Pre-Processing
The spectroscopic signatures obtained during both acquisition data campaigns were denoised and normalized employing a smooth filter (five-point moving average), and a normalization process was independently applied to each spectroscopic signature using MATLAB
® (The MathWorks Inc., Natick, MA, USA). The normalization was applied in order to fit the spectral signatures between zero and one, thus isolating the samples from different illumination conditions. Since the two data campaigns were captured using different spectrometers, the spectroscopic samples were spectrally adapted in order to merge both datasets. The spectral signatures from DC1 were split to obtain spectroscopic samples covering the range from 1000 cm
−1 to 4000 cm
−1, which is the range of the spectrometer employed in the DC2. Since the spectral resolution of both datasets were different (1.93 cm
−1 for DC1 and 2 cm
−1 for DC2), a cubic spline interpolation was performed to the DC1 samples in order to fit the DC1 data along the spectral range of DC2 [
22]. Finally, the extreme bands of the spectroscopic samples (from 1000 cm
−1 to 1200 cm
−1 and from 3500 cm
−1 to 4000 cm
−1) were removed in order to avoid the noise introduced by the sensor of the DC2 dataset in such bands. After the pre-processing steps, both datasets were merged in a single dataset composed by spectroscopic signatures that cover the wavenumber rage from 1200 cm
−1 to 3500 cm
−1 with a spectral resolution of two cm
−1, which has 1151 spectral bands.
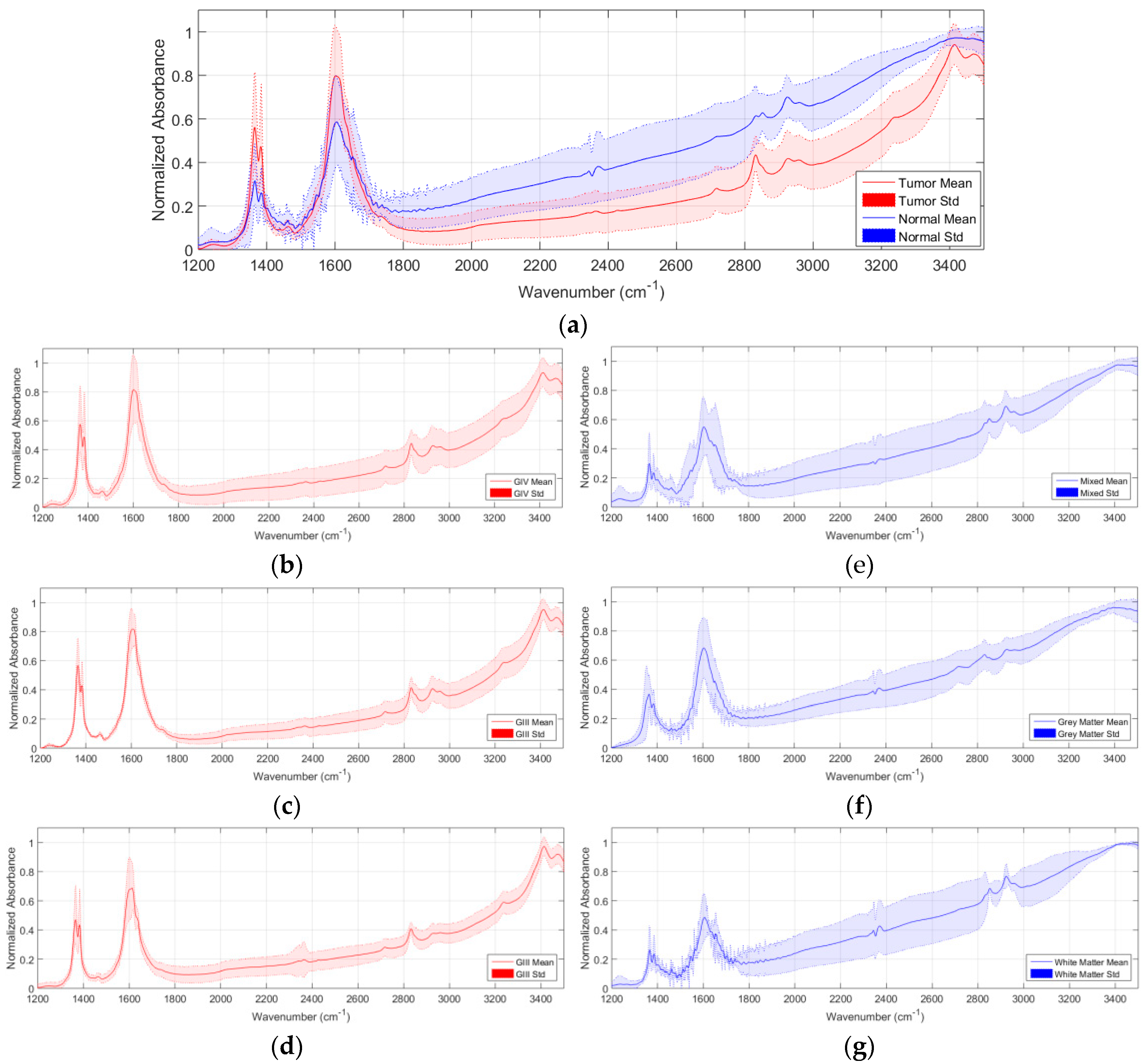
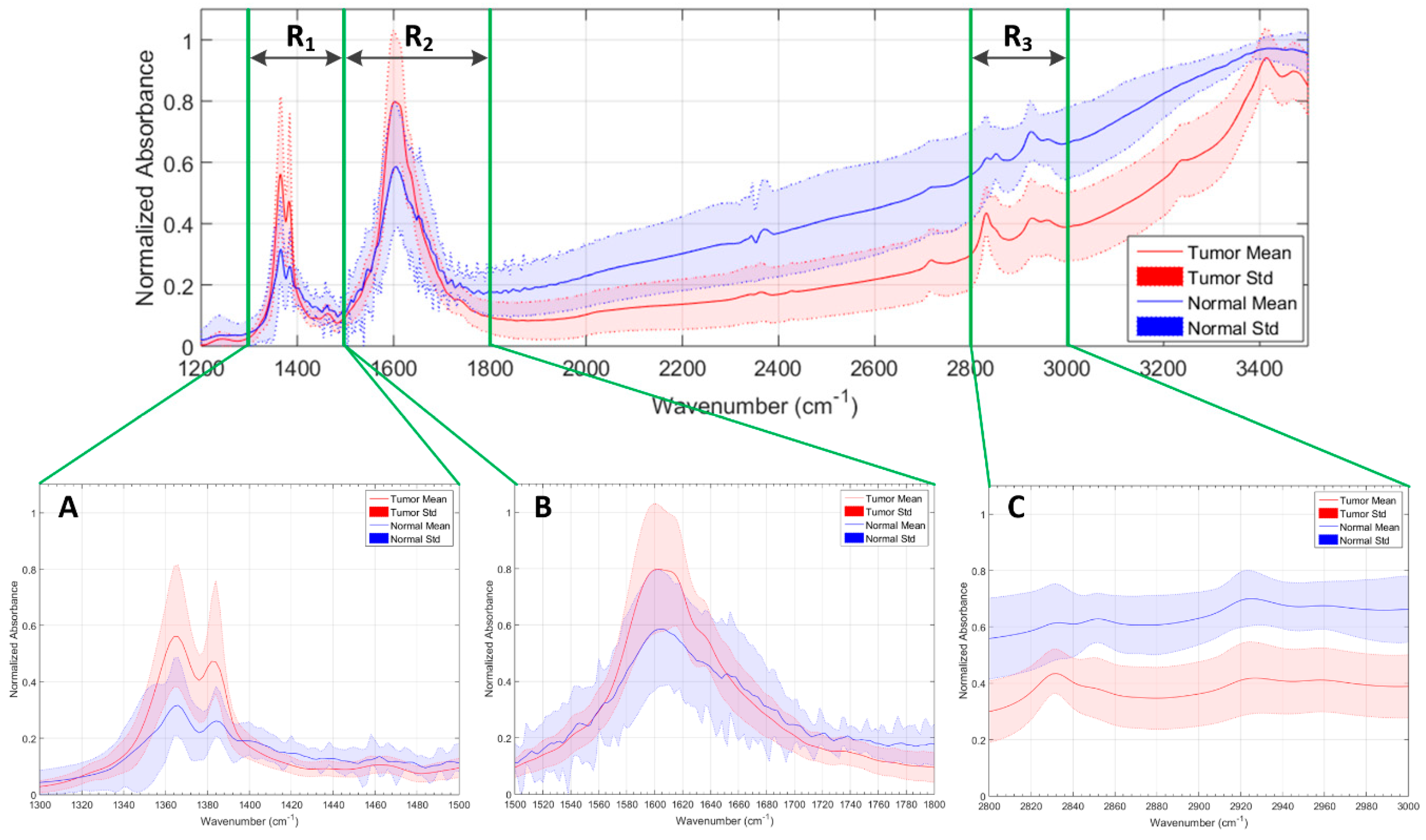
Figure 1a shows the average and standard deviation (STD) of the pre-processed spectral signatures of tumor and normal samples that compose the IR spectroscopic database. As it can be seen in this figure, there are several wavenumber ranges where the differences between the normal samples and the tumor samples are evident. As stated in [
6], the region comprised between 1300–1500 cm
−1 is mainly affected by the deformation vibration of alkyl groups CH
2 and CH
3, while the range 1500–1800 cm
−1 is associated to the
C = 0 stretching and N–H bending vibrations of the amide groups (amide I and II respectively), comprising the peptide linkages of proteins. Furthermore, in the wavenumber region between 2800–3000 cm
−1, the spectra are dominated by acyl chain stretching vibrations with fatty acids of lipids as the main contributors. These regions will be taken into account in
Section 3 for an optimization of the classification system, where only these regions of interest will be employed to train the system and classify the spectroscopic samples. In
Figure 1b–d, the average and standard deviation of the pre-processed spectroscopic signatures of grade IV (GIV), grade III (GIII), and grade II (GII) tumor samples are shown respectively. Finally,
Figure 1e–g show the average and standard deviation of the pre-processed spectroscopic signatures of mixed, grey matter, and white matter normal samples.
2.4. Support Vector Machines for IR Spectroscopic Samples Classification
The experiments that were performed in this study to classify the IR spectroscopic samples of brain tumor were carried out using an SVM classifier. LIBSVM was employed as the classifier implementation [
23] using Matlab
® environment. Since SVMs have different hyperparameters that can be fine-tuned to improve the outcomes of the classification, an extensive optimization analysis was performed. In this study, the classification results obtained with four different SVM kernels were compared. Linear, polynomial, radial basis function (RBF) and sigmoid kernels were tested. Polynomial, RBF, and sigmoid kernels were analyzed in order to find the optimal parameters that provide the best classification results for this particular case. All of the kernels have one common parameter called cost (
C). This parameter is the constant of constraint violation that observes whether a data sample is classified on the wrong side of the decision limit. The specific parameters to tune up each kernel are detailed herewith. In the RBF kernel, the width of the Gaussian radial basis function can be adjusted by the parameter
γ. In the sigmoid kernel, the parameters that can be adjusted are the slope (
γ) and the intercept constant (
cf). Finally, polynomial kernel employs the parameters
γ,
cf, and
d, which are the coefficient of the polynomial function, the coadditive constant and the degree of the polynomial, respectively.
Table 2 presents the mathematical expressions of each kernel.
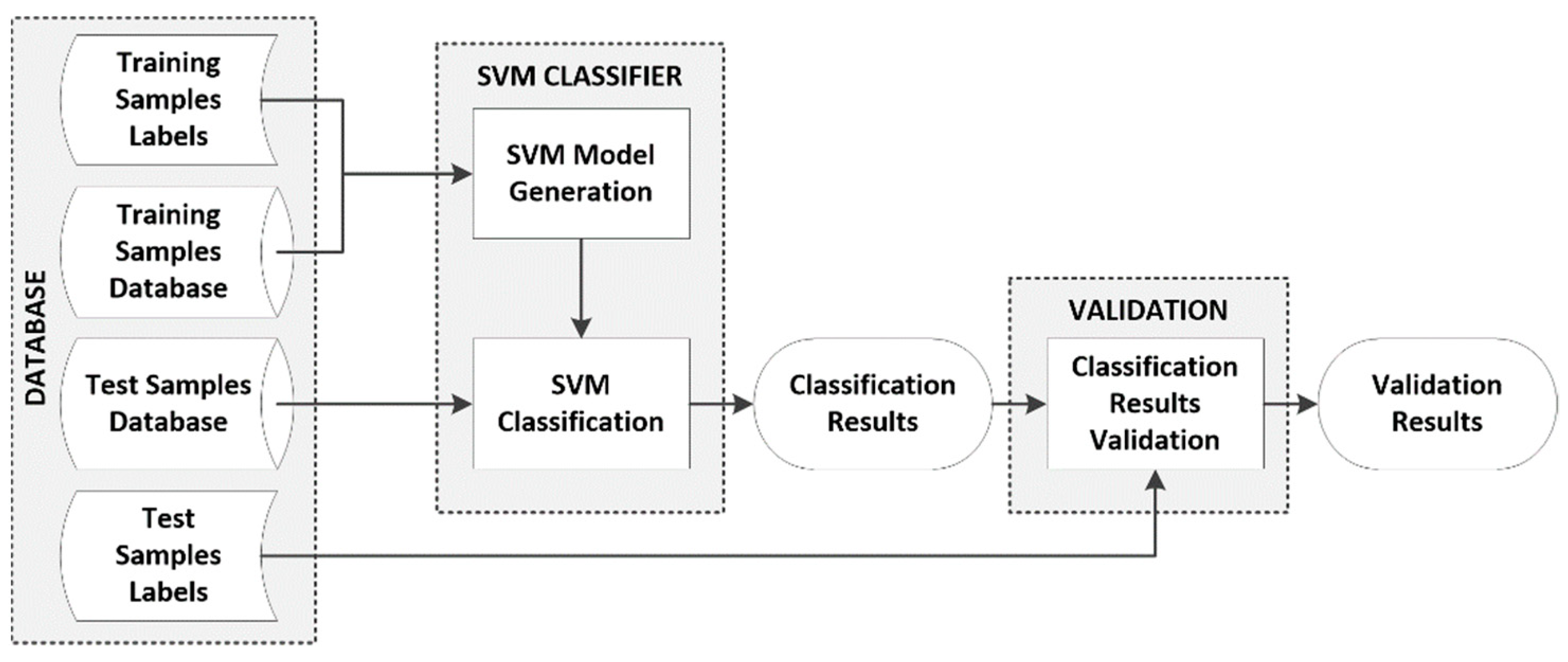
Figure 2 shows the SVM classification framework that was employed in this work to optimize the parameters of the SVM kernels and obtain the classification accuracy results. The database is composed by the spectroscopic samples that have been captured and labeled, identifying the type of tissue (tumor or normal), the grade of the tumor tissue (grade II, grade III, and grade IV) and the type of normal tissue (mixed normal, grey matter, and white matter). This database was split into test and training datasets, following a repeated fivefold cross-validation method, to generate the SVM model and obtain the classification results. The results presented in this paper are the average values obtained in 10 repetitions of the fivefold cross-validation.
2.5. Evaluation Metrics
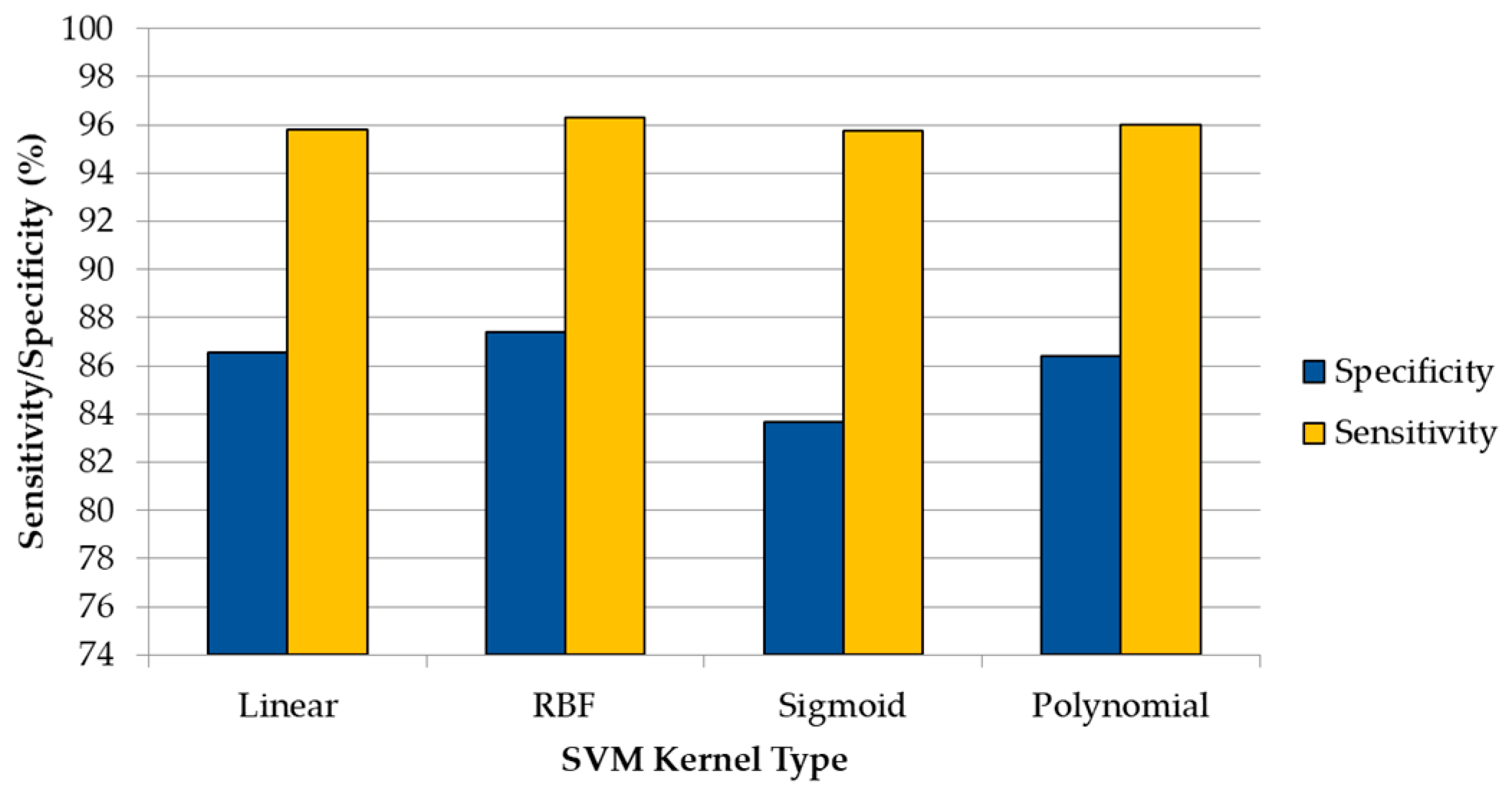
The results provided by the classification systems were evaluated using standard metrics to this end: sensitivity, specificity, and overall accuracy (ACC). These metrics are commonly used as statistical measures of the performance of binary classification methods [
24,
25,
26,
27]. Sensitivity is related to the test’s ability to identify a condition correctly. It is obtained as the number of true positives (TP) divided by the total number of true positives and false negatives (FN) in a population (Equation (1)). Specificity is related to the test’s ability to exclude a condition correctly. It is obtained as the number of true negatives (TN) divided by the total number of true negatives and false positives (FP) in a population (Equation (2)). Finally, ACC is calculated by dividing the total number of successful results by the total population (Equation (3)). The other metrics that were also computed for this study are detailed in
Section S1 of the Supplementary Material.
4. Conclusions
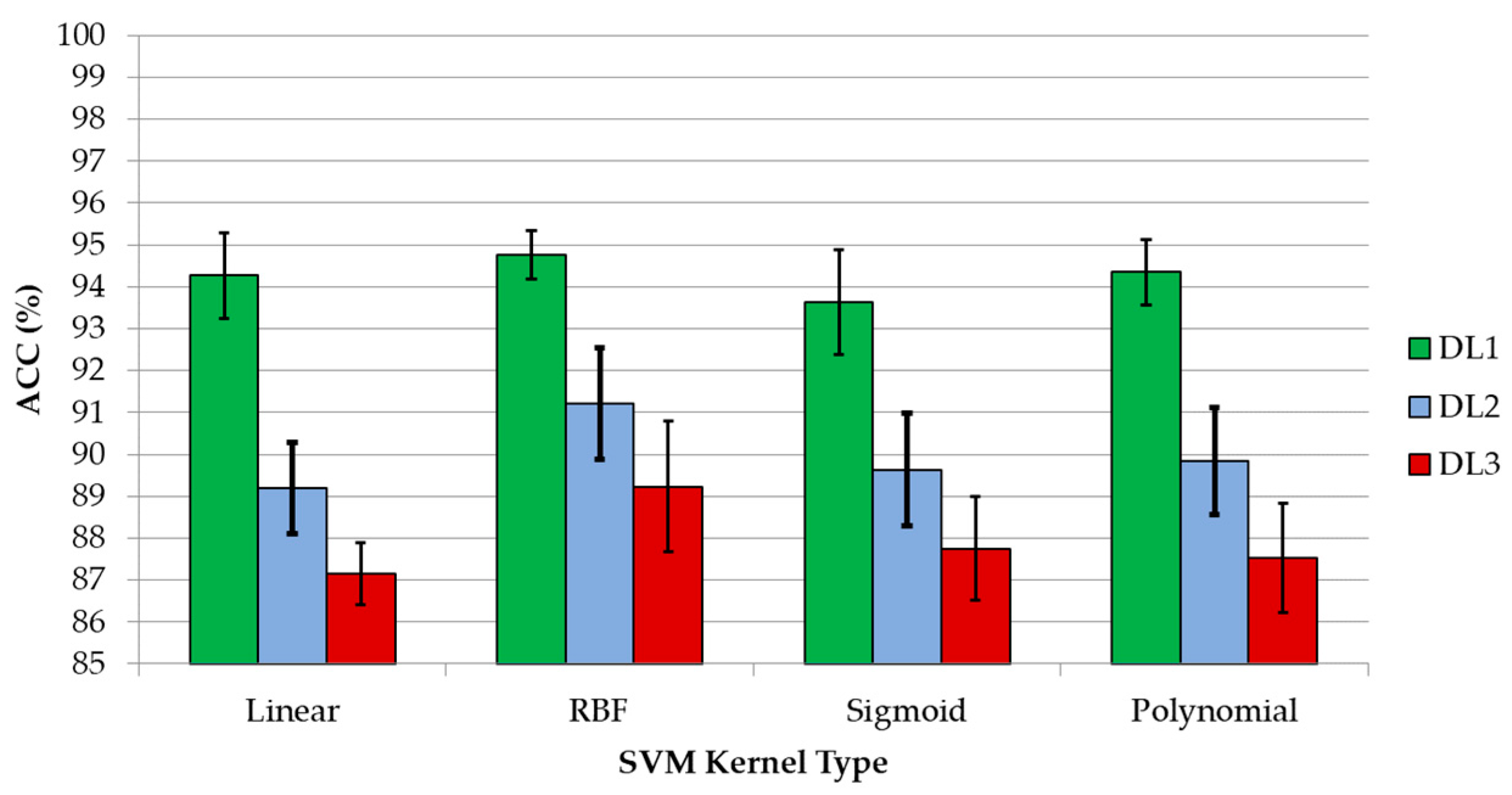
The use of IR spectroscopy for the identification of brain tissue samples is an emerging technique that may offer, in the near future, a reliable diagnostic tool to complement the traditional histopathological diagnosis. The work that is presented in this paper uses two different FT-IR spectrometers to obtain spectroscopic signatures of brain tissue samples in the wavenumber range from 1200 cm−1 to 3500 cm−1. Samples were obtained from 31 different patients during two different data acquisition campaigns, collecting 246 spectral signatures that were labeled according to their corresponding histopathological diagnosis. These spectroscopic signatures were employed to develop and optimize a machine-learning model based on an SVM classifier. Four different SVM kernels were evaluated to find the optimal configuration parameters for classifying three discrimination levels of brain tissue types (DL1: tumor versus normal; DL2: grade IV versus grade III versus grade II versus normal; DL3: grade IV versus grade III versus grade II versus mixed normal versus grey matter versus white matter). The results were obtained by averaging the overall accuracy results of an iterative cross-validation.
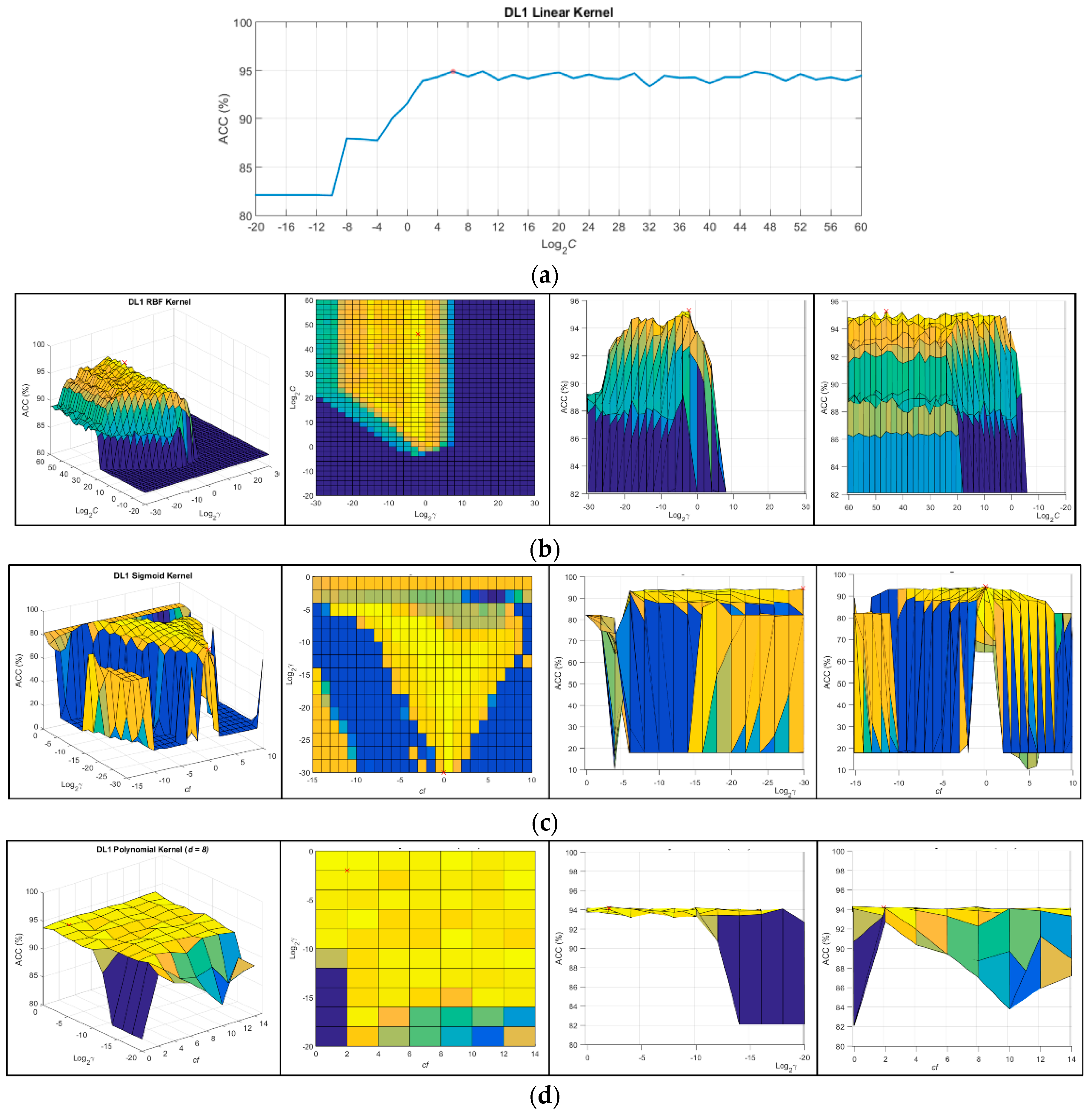
One of the main conclusions of this study is that, having available an extensive training dataset for the generation of the supervised machine learning algorithm, it is possible to accurately predict the type of brain tissue through exclusively using its IR spectral features. Results with an accuracy above 87% were achieved with all of the SVM kernels for the three DLs. The optimal SVM configuration for each DL employs the RBF kernel, but using different hyperparameters in each DL. The optimal hyperparameters for DL1 were and , achieving an ACC value of 94.76%, while the optimal configuration for DL2 was and , achieving 91.22% of ACC. Finally, in DL3, the best ACC result (89.22%) was obtained with the parameters and . The inclusion of other evaluation metrics that take into account the performance per class has reinforced the validity of the results, demonstrating that the RBF kernel is the most suitable SVM kernel for this application.
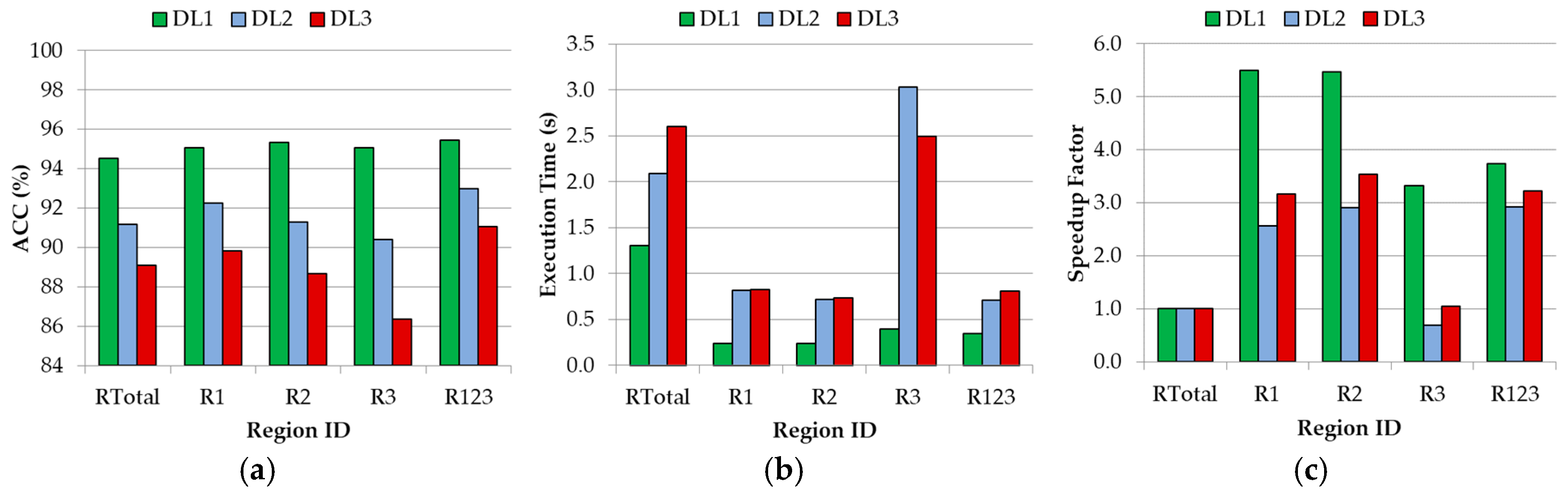
After the determination of the optimal configuration of the SVM classifier, three different wavenumber regions were studied, concluding that searching for the optimal spectral features within the spectral range can improve both the accuracy and the execution time of the classification. The combination of the regions covering from 1300 cm−1 to 1800 cm−1 and 2800 cm−1 to 3000 cm−1 (formed by 352 spectral bands) obtained the best accuracy results for each DL (DL1: 95.44%; DL2: 92.97%; DL3: 91.06%). Furthermore, an average speed up of 3× was achieved in the execution of the algorithm compared with the use of the complete spectroscopic signatures dataset.
Another remarkable result that was obtained from this study shows that it is possible to successfully exploit the IR spectroscopic data that was captured using different spectrometers by applying the appropriate data processing. Unfortunately, due the unbalanced amount of the sample types from each spectrometer, it was not possible to evaluate each one independently. Although promising results were achieved in this work, a larger IR spectroscopic database, involving more quantity of each type of sample, could lead to a more generic SVM model. Having enough samples of different types of primary tumors (glioblastoma, oligodendroglioma, astrocytoma, etc.) and different types of secondary tumors (lung, renal, breast, etc.) could allow the generation of a model that identifies the grade and type (primary) or origin (secondary) of the tumor tissue in all of the cases.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}