Underwater Acoustic Target Recognition Based on Supervised Feature-Separation Algorithm


Abstract
:1. Introduction
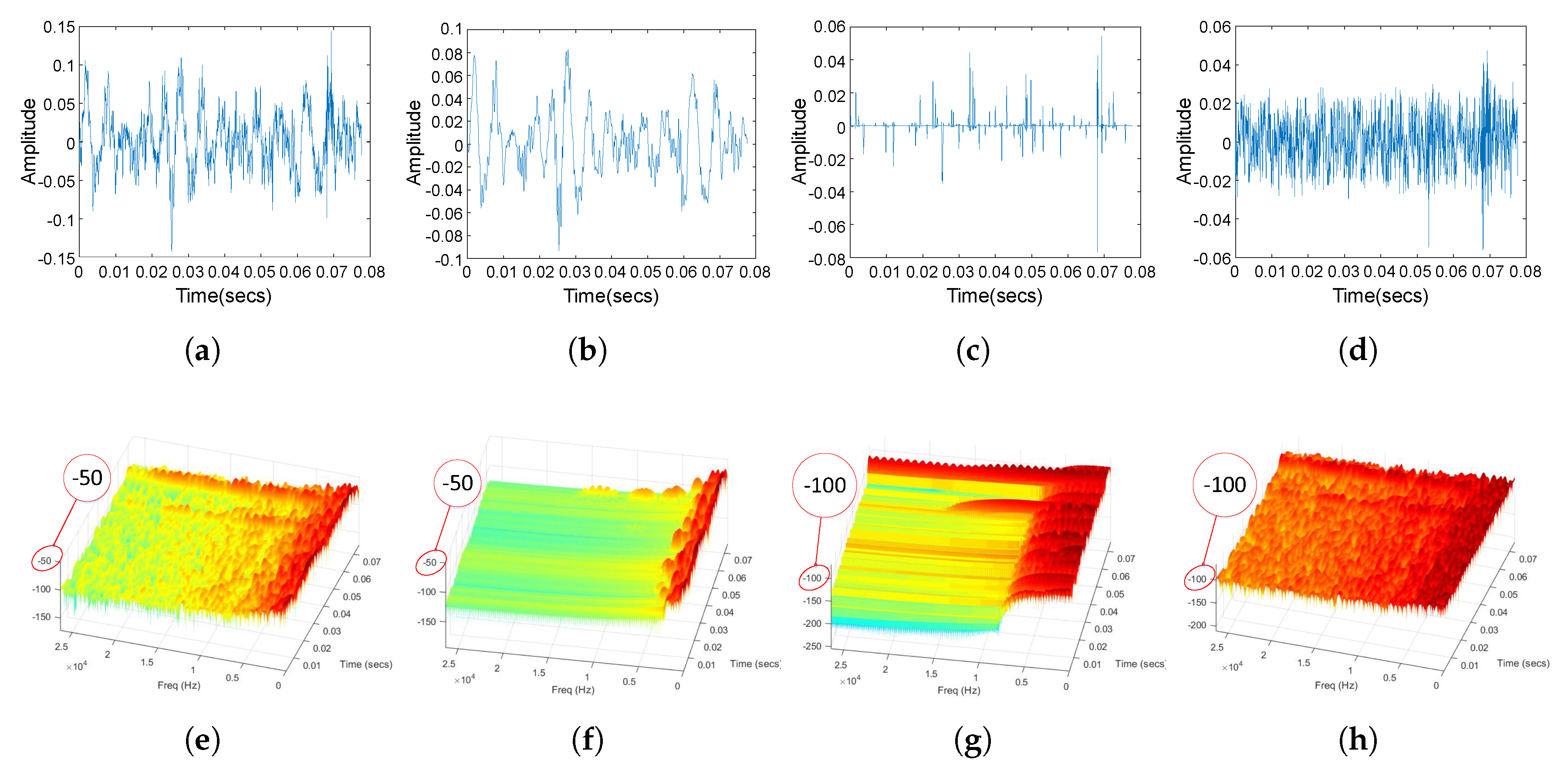
2. Resonance-Based Sparsity Signal Decomposition for Pre-Processing
3. One-Dimensional Convolution Autoencoder-Decoder Model for Unsupervised Pre-Training
3.1. Building Units
3.2. The First Layer of the Model
- (1)
- Sparse and shift-invariant: Traditionally, sparsity is introduced by adding L1 regularization on feature maps, but in the model, max-pooling layers are introduced to achieve sparsity as well as shift-invariance. The sparsity can be viewed as limiting “capacity” of the networks, and it often results in more easily interpretable feature representations. The shift-invariance will make the model tolerate slight difference of the inputs. The reason for introducing the shift-invariance is to make the same class of input result in a same output. For the same class of ship-radiated noise, their spectrum usually only has slight difference, and shift-invariance will make outputs of the same class cluster together.
- (2)
- Non-linear: Between the encoder and the decoder, there is a layer of sigmoid activation. This activation builds nonlinearity between two layers, which potentially makes the model build hierarchical representations of the inputs with the increasing of layers.
- (3)
- Depth-wise separable: The model treats each depth independently. First, in unsupervised pre-training, features of each kernel are extracted separately and correlations between them are ignored. Then in supervised fine-tuning, the correlations between features of each kernel will be actually considered. The purpose of this operation is to make each feature more interpretable. This will be discussed in experiments section.
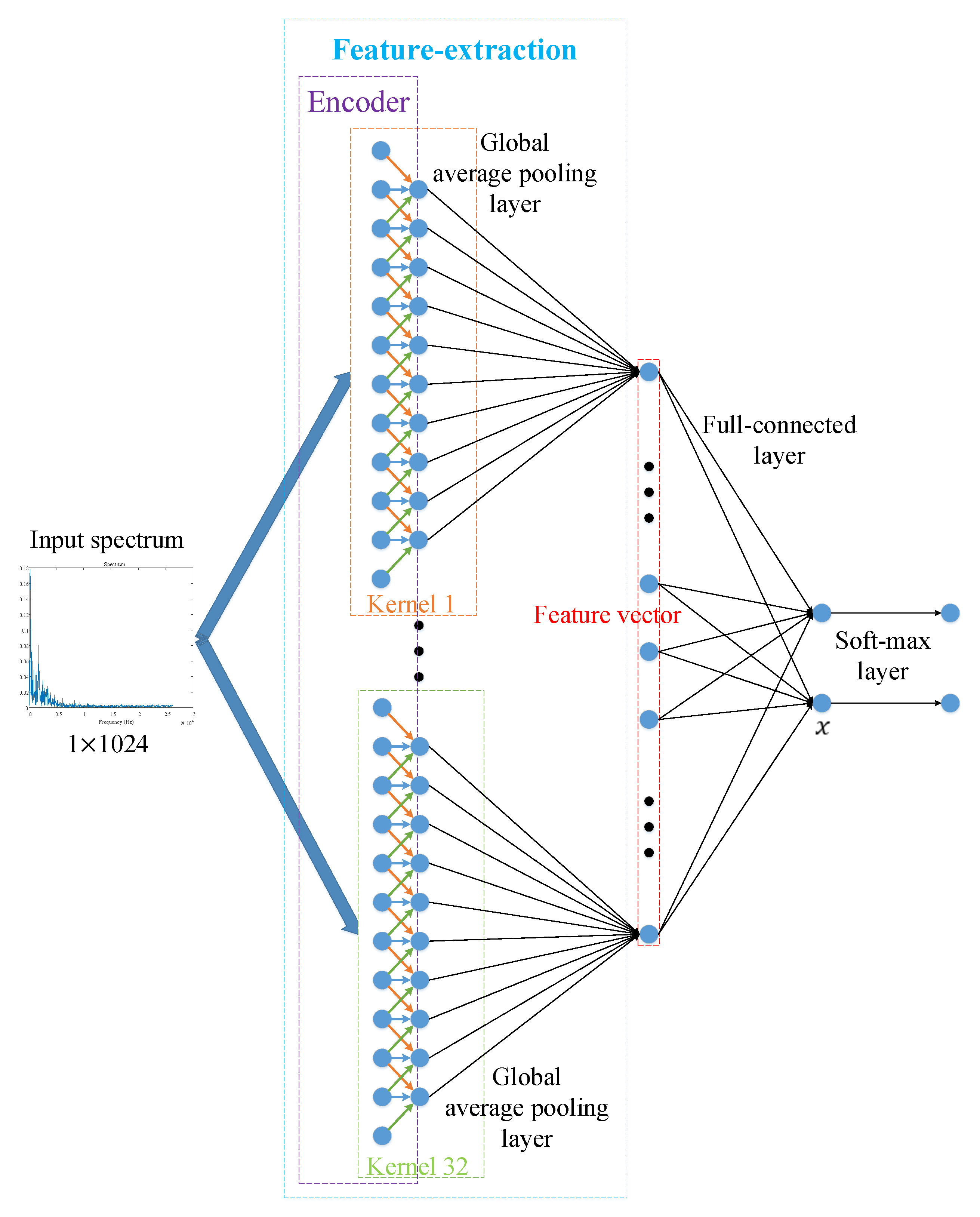
3.3. Stack Layers to Hierarchically Extract Features
3.3.1. Hyper-Parameter Optimization
3.3.2. The Structure of the Hierarchical Model
3.4. Learning Algorithm for Unsupervised Pre-Training
4. Supervised Fine-Tuning and Feature-Separation
4.1. The Traditional Supervised Training Algorithm for Fine-Tuning
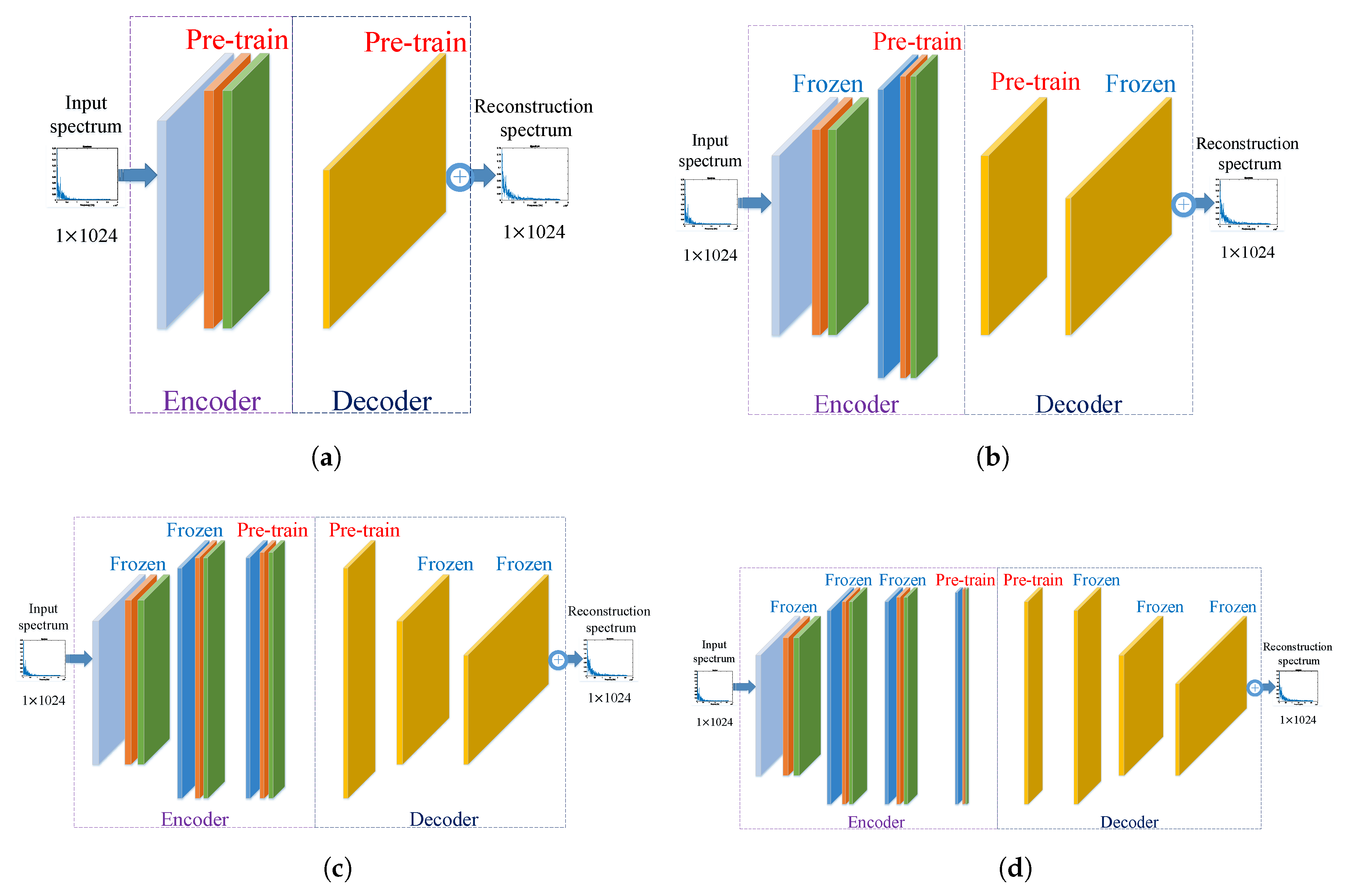
4.2. The Supervised Feature-Separation Algorithm for Fine-Tuning
4.2.1. Procedure of the Supervised Feature-Separation Algorithm
4.2.2. Explanation of the Supervised Feature-Separation Algorithm
5. Experiments and Discussion
5.1. Experiment Dataset
5.2. Experiment of Pre-Processing
5.3. Experiment of Unsupervised Pre-Training
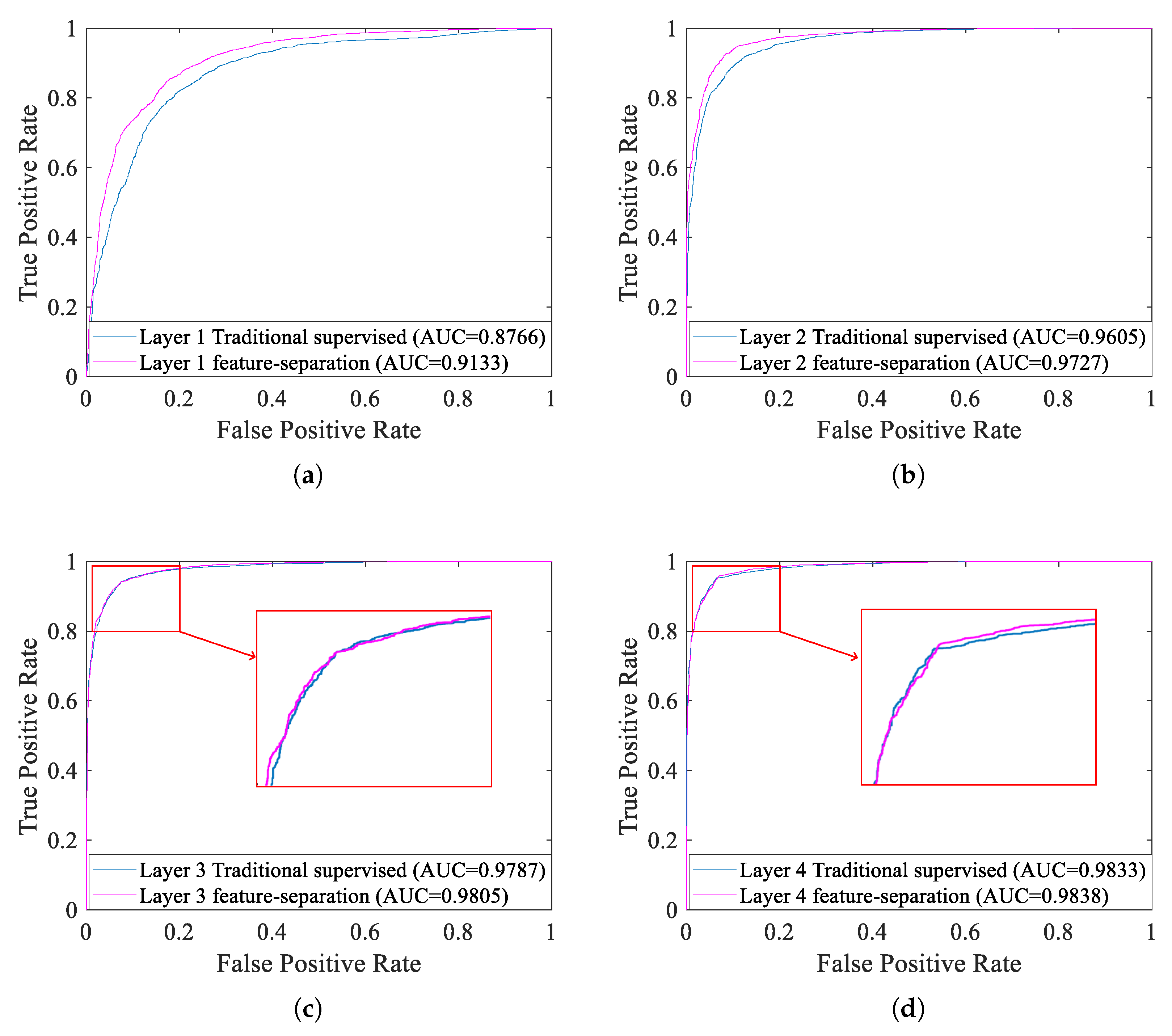
5.4. Experiment of Supervised Fine-Tuning
5.5. Experiment of Underwater Acoustic Target Recognition
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, L.; Chen, K. A perceptual space for underwater man-made sounds towards target classification. Appl. Acoust. 2016, 110, 119–127. [Google Scholar] [CrossRef]
- Harris, P.; Philip, R.; Robinson, S.; Wang, L. Monitoring anthropogenic ocean sound from shipping using an acoustic sensor network and a compressive sensing approach. Sensors 2016, 16, 415. [Google Scholar] [CrossRef] [PubMed]
- Averbuch, A.; Zheludev, V.; Neittaanmäki, P.; Wartiainen, P.; Huoman, K.; Janson, K. Acoustic detection and classification of river boats. Appl. Acoust. 2011, 72, 22–34. [Google Scholar] [CrossRef]
- Yan, J.; Sun, H.; Chen, H.; Junejo, N.U.R.; Cheng, E. Resonance-Based Time-Frequency Manifold for Feature Extraction of Ship-Radiated Noise. Sensors 2018, 18, 936. [Google Scholar] [CrossRef] [PubMed]
- Selesnick, I.W. Resonance-based signal decomposition: A new sparsity-enabled signal analysis method. Signal Process. 2011, 91, 2793–2809. [Google Scholar] [CrossRef] [Green Version]
- Jian, L.; Yang, H.; Zhong, L.; Ying, X. Underwater target recognition based on line spectrum and support vector machine. In Proceedings of the International Conference on Mechatronics, Control and Electronic Engineering (MCE2014), Shenyang, China, 29–31 August 2014; Atlantis Press: Paris, France, 2014; pp. 79–84. [Google Scholar]
- Wei, X. On feature extraction of ship radiated noise using 11/2 d spectrum and principal components analysis. In Proceedings of the 2016 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Hong Kong, China, 5–8 August 2016; pp. 1–4. [Google Scholar]
- Zhang, L.; Wu, D.; Han, X.; Zhu, Z. Feature extraction of underwater target signal using Mel frequency cepstrum coefficients based on acoustic vector sensor. J. Sens. 2016, 2016, 7864213. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S. A wave structure based method for recognition of marine acoustic target signals. J. Acoust. Soc. Am. 2015, 137, 2242. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, X.; Yu, Y.; Niu, L. Deep learning-based recognition of underwater target. In Proceedings of the 2016 IEEE International Conference on Digital Signal Processing (DSP), Beijing, China, 16–18 October 2016; pp. 89–93. [Google Scholar]
- Yang, H.; Shen, S.; Yao, X.; Sheng, M.; Wang, C. Competitive Deep-Belief Networks for Underwater Acoustic Target Recognition. Sensors 2018, 18, 952. [Google Scholar] [CrossRef] [PubMed]
- Ranzato, M.; Huang, F.J.; Boureau, Y.L.; LeCun, Y. Unsupervised learning of invariant feature hierarchies with applications to object recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR’07), Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Selesnick, I.W. Wavelet transform with tunable Q-factor. IEEE Trans. Signal Process. 2011, 59, 3560–3575. [Google Scholar] [CrossRef]
- Starck, J.L.; Elad, M.; Donoho, D.L. Image decomposition via the combination of sparse representations and a variational approach. IEEE Trans. Signal Process. 2005, 14, 1570–1582. [Google Scholar] [CrossRef] [Green Version]
- Selesnick, I. TQWT Toolbox Guide; Electrical and Computer Engineering, Polytechnic Institute of New York University: Brooklyn, NY, USA, 2011; Available online: http://eeweb.poly.edu/iselesni/TQWT/index.html (accessed on 6 October 2011).
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. arXiv, 2017; arXiv:1610.02357. [Google Scholar]
- Tuma, M.; Rørbech, V.; Prior, M.K.; Igel, C. Integrated optimization of long-range underwater signal detection, feature extraction, and classification for nuclear treaty monitoring. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3649–3659. [Google Scholar] [CrossRef]
- Huang, F.; LeCun, Y. Large-scale learning with svm and convolutional netw for generic object recognition. In Proceedings of the IEEE 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.E. Training products of experts by minimizing contrastive divergence. Neural Comput. 2002, 14, 1771–1800. [Google Scholar] [CrossRef] [PubMed]
- Kinga, D.; Adam, J.B. A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; Volume 5. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A.; Pena-Gimenez, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Hou, W.L. SPECTRUM AUTOCORRELATION. Acta Acust. 1988, 2, 006. [Google Scholar]
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameters | Considered Values | Used Values | |
|---|---|---|---|
| Layer 1 | Kernel size | 1 × 256, 1 × 125, 1 × 64, 1 × 32, 1 × 16, 1 × 8, 1 × 4, 1 × 2 | 1 × 125 |
| Kernel number | 128, 64, 32, 16, 4 | 32 | |
| Kernel stride | [1,1], [1,2], [1,4] | [1,1] | |
| Layer 2 | Kernel size | 1 × 64, 1 × 32, 1 × 16, 1 × 8, 1 × 4, 1 × 2 | 1 × 64 |
| Kernel number | 128, 64, 32, 16, 4 | 32 | |
| Kernel stride | [1,1], [1,2], [1,4] | [1,1] | |
| Layer 3 | Kernel size | 1 × 32, 1 × 16, 1 × 8, 1 × 4, 1 × 2 | 1 × 16 |
| Kernel number | 128, 64, 32, 16, 4 | 32 | |
| Kernel stride | [1,1], [1,2], [1,4] | [1,1] | |
| Layer 4 | Kernel size | 1 × 16, 1 × 8, 1 × 4, 1 × 2 | 1 × 4 |
| Kernel number | 128, 64, 32, 16, 4 | 32 | |
| Kernel stride | [1,1], [1,2], [1,4] | [1,1] | |
| The number of layers | 1, 2, 3, 4, 5 | 4 | |
| Type of activation function | Sigmoid, Tanh, ReLU, Leakey ReLU | Sigmoid | |
| Max-pooling stride | [1,4], [1,8] | [1,4] | |
| Depthwise separable | Yes, not | Yes | |
| The Original Signals | The High-Resonance Components | ||||
|---|---|---|---|---|---|
| 0.5830 | 0.5389 | 0.6191 | 0.5496 | ||
| 0.5389 | 0.5409 | 0.5496 | 0.5622 | ||
| Methods | Features | Dimensions | Accuracy/% |
|---|---|---|---|
| Traditional | MFCC | 23 | 79.62 |
| Unsupervised pre-training | Layer 1 | 32 | 72.98 |
| Layer 2 | 32 | 88.33 | |
| Layer 3 | 32 | 92.29 | |
| Layer 4 | 32 | 92.75 | |
| Fine-tuning with the traditional supervised training algorithm | Layer 1 | 32 | 80.75 |
| Layer 2 | 32 | 89.29 | |
| Layer 3 | 32 | 92.49 | |
| Layer 4 | 32 | 93.24 | |
| Fine-tuning with the supervised feature-separation algorithm | Layer 1 | 32 | 83.37 |
| Layer 2 | 32 | 91.51 | |
| Layer 3 | 32 | 92.83 | |
| Layer 4 | 32 | 93.28 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ke, X.; Yuan, F.; Cheng, E. Underwater Acoustic Target Recognition Based on Supervised Feature-Separation Algorithm. Sensors 2018, 18, 4318. https://doi.org/10.3390/s18124318
Ke X, Yuan F, Cheng E. Underwater Acoustic Target Recognition Based on Supervised Feature-Separation Algorithm. Sensors. 2018; 18(12):4318. https://doi.org/10.3390/s18124318
Chicago/Turabian StyleKe, Xiaoquan, Fei Yuan, and En Cheng. 2018. "Underwater Acoustic Target Recognition Based on Supervised Feature-Separation Algorithm" Sensors 18, no. 12: 4318. https://doi.org/10.3390/s18124318