Dual Quaternions as Constraints in 4D-DPM Models for Pose Estimation


Abstract
:1. Introduction
Related Work
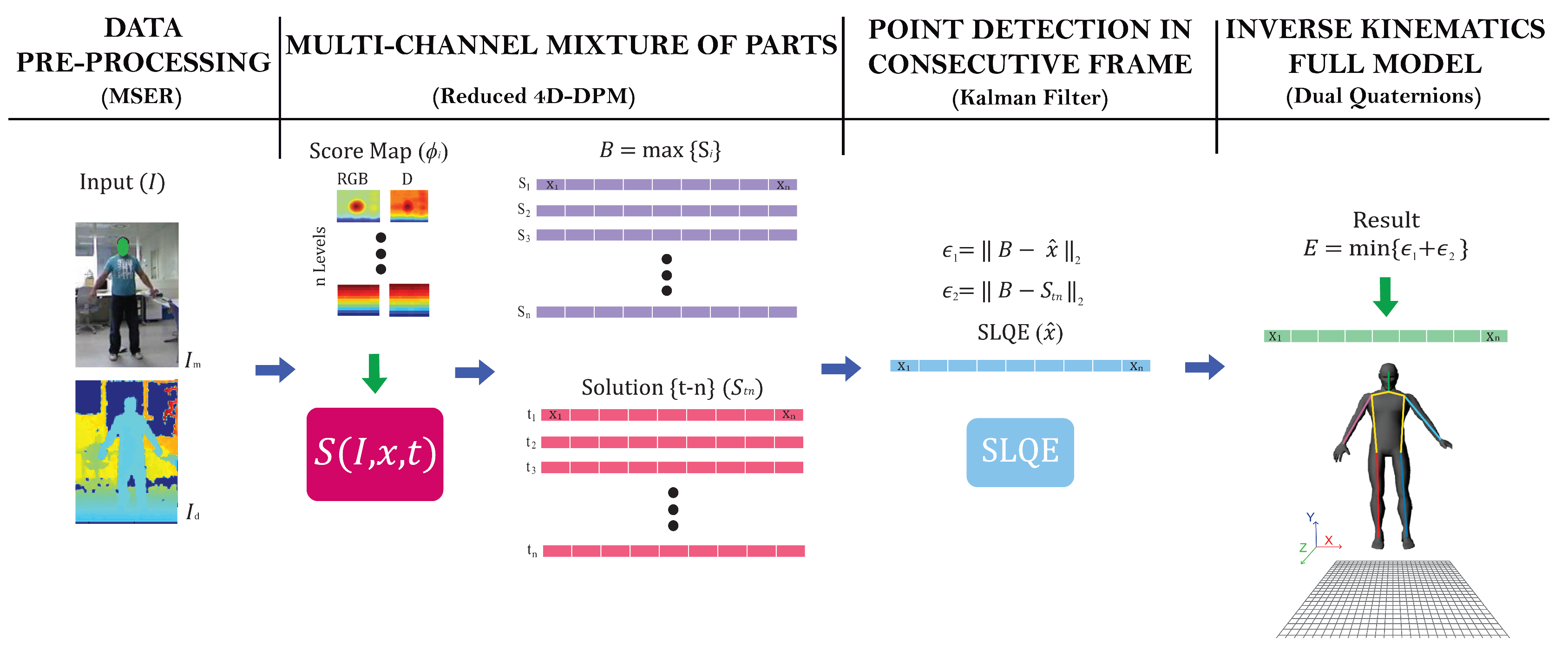
2. Proposed Method
2.1. Data Pre-Processing
2.2. Multi-Channel Mixture of Parts
2.3. Point Detection in Consecutive Frames
2.4. Geometric Model
2.5. Model Simplification
- Human body model: In order to track the human skeleton, we model it as a group of kinematic chains, where each part and joint in the human body corresponds to a link and joint in a kinematic chain. Given the joint positions predicted by the KF, inverse kinematics are used to obtain all of the joints using Dual Quaternions (DQ).
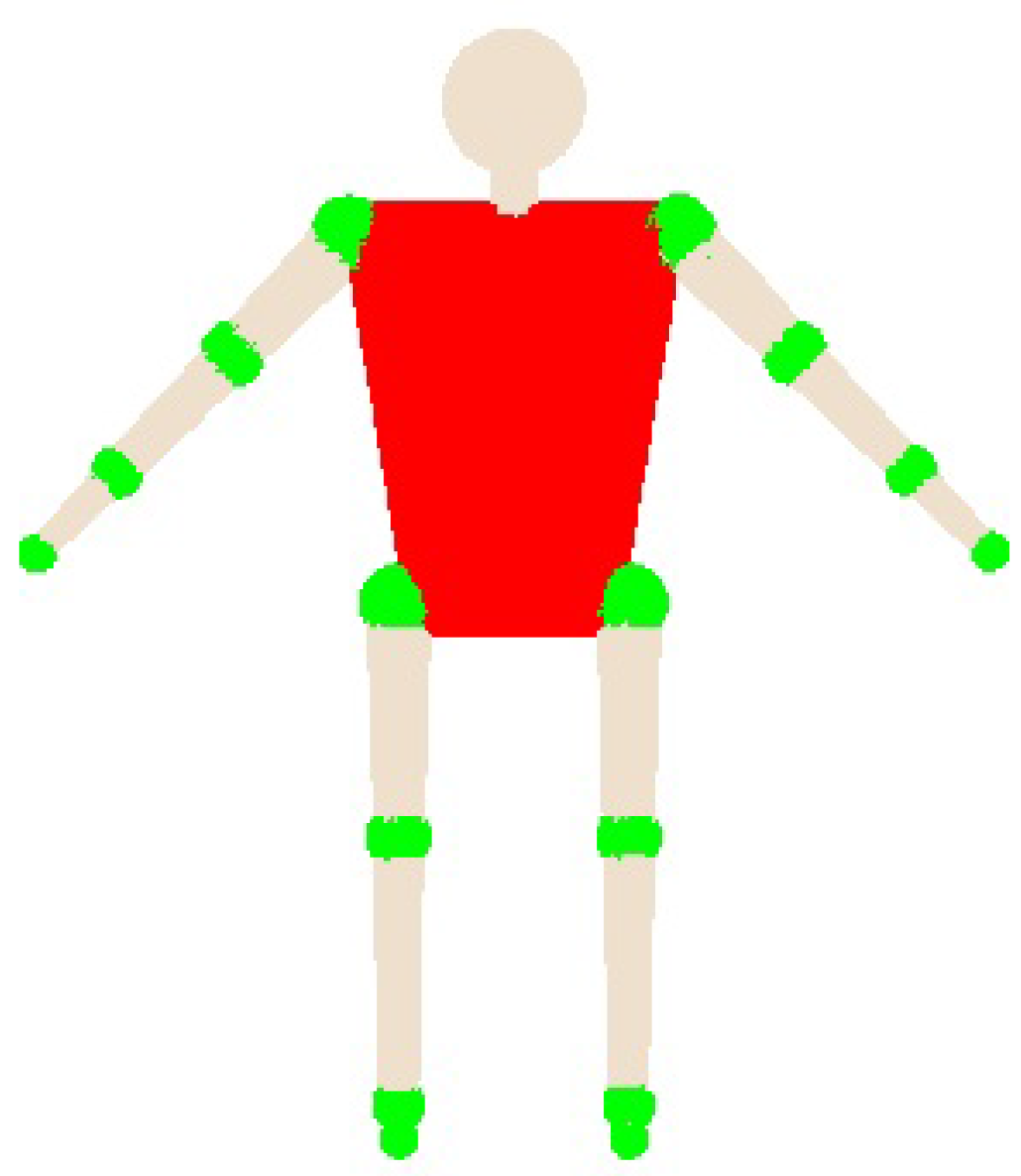
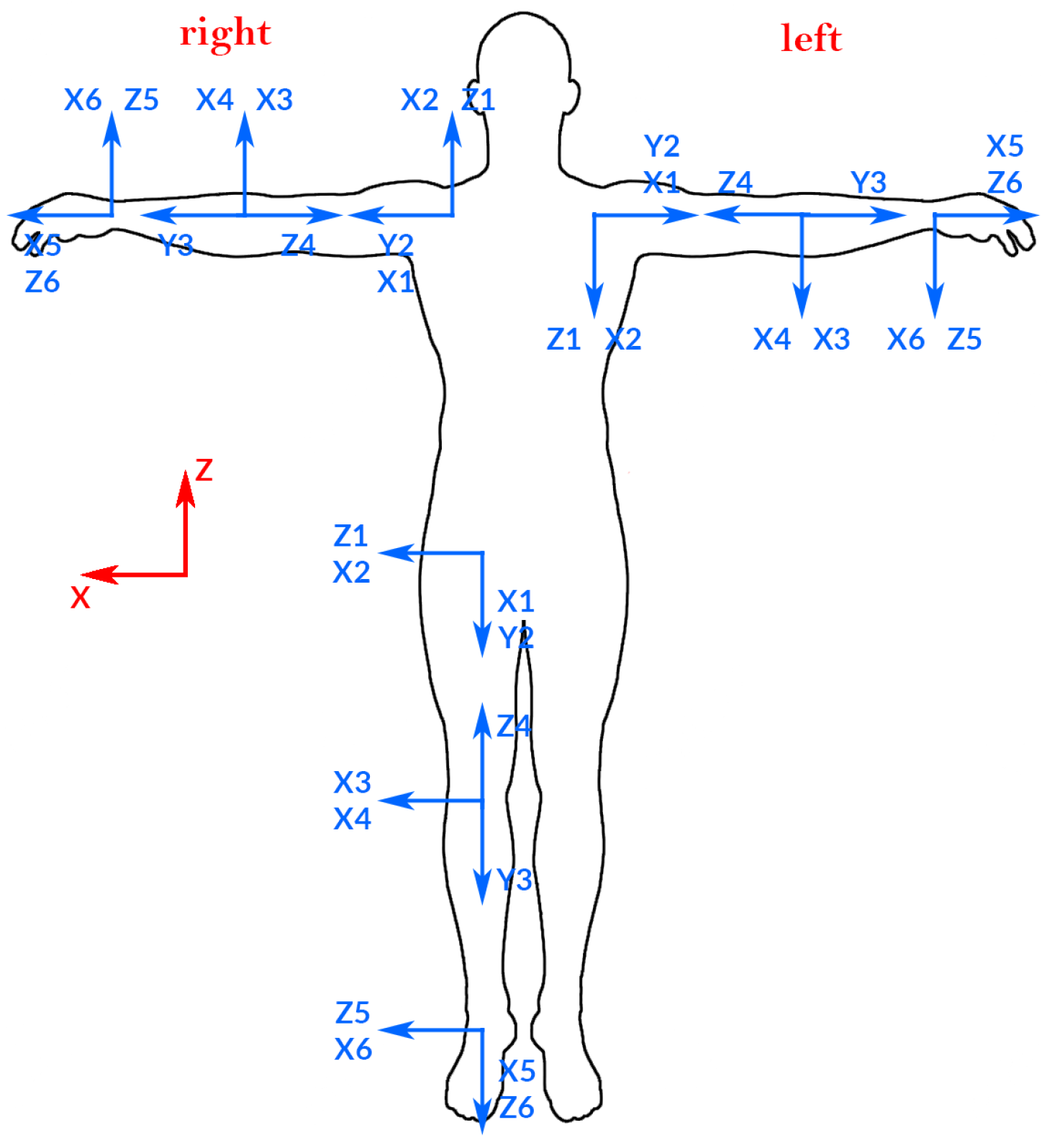
- State variables: The human body model is divided into four main kinematic chains (KC) that perform collision detection with their correspondent state variables, in essence: one KC for each arm and one for each leg. Figure 4 shows the state variable for each KC.
- DQ model: We use DQ to model each KC. In this sense, we use six joints for each KC for shoulders, hips, hands, and feet (see Figure 4).
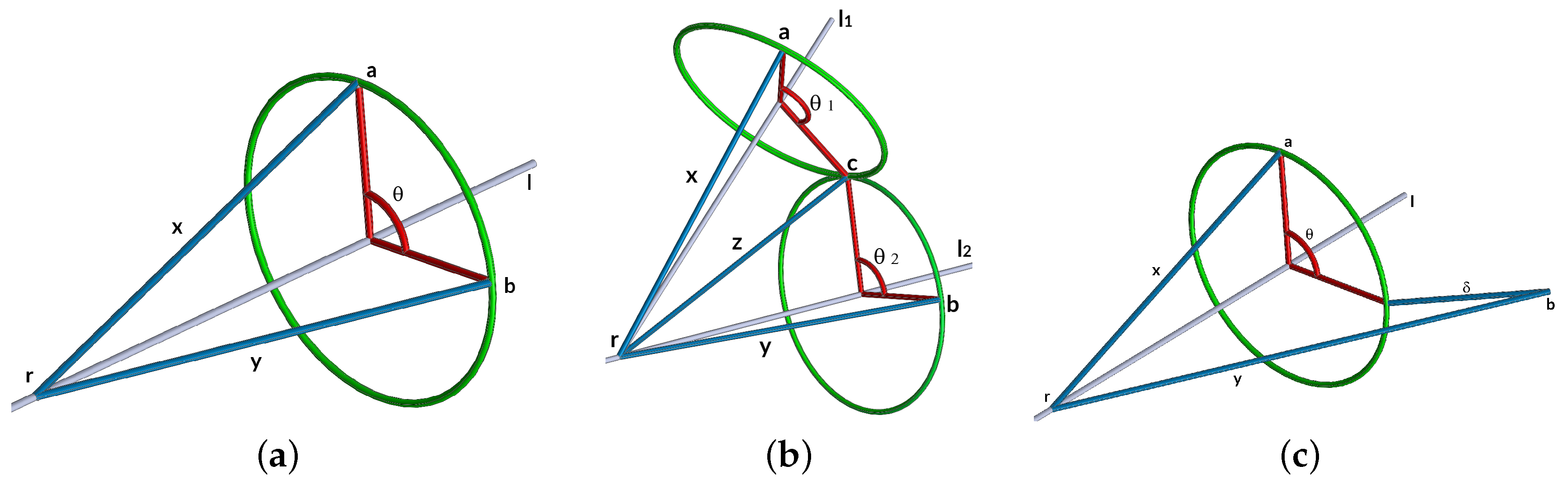
- DH model: We use the Denavit-Hartenberg (DH) method to obtain the base coordinate system for each joint. After that, we will apply the dual quaternion method. First, we establish the base coordinate system at the supporting base with the axis lying along the axis of motion of joint 1. We have four base coordinate systems , each one located at from each KC. Then, we establish a joint axis and align the with the axis of motion of joint .
3. Results
- Data sets: To train and test our method, we use a combination of videos from our own data set and a subset of the publicly available CAD60 data set [46].
- CAD60 data set: The original CAD60 data set [46] contains 60 RGB-D videos, four subjects (two male, two female), four different environments (office, bedroom, bathroom and living room) and 12 different activities. This data set was originally created for the activity recognition task [47,48,49]. The size of images is 320 × 240 pixels.
- Our data set: It consists of seven videos with only one person on the scene moving his arms and legs. We had almost 1000 frames of people to obtain specific movements, e.g., crossing arms over one’s body, to complement the CAD60 data set. Images were taken indoors in different scenarios. The subject inside the images is a male who wears different clothes. The size of the images is 320 × 240 pixels.
3.1. Quantitative Results
3.2. Time Complexity Analysis
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| PS | Pictorial Structures |
| MRFs | Markov Random Fields |
| DPM | Deformable Parts Model |
| MSER | Maximally Stable Extremal Regions |
| PCK | Probability of a Correct Kypoint |
| APK | Average Precision Keypoint |
| KF | Kalman Filter |
| DQ | Dual Quaternions |
| KC | Kinematic Chains |
References
- Yang, Y.; Ramanan, D. Articulated human detection with flexible mixtures of parts. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2878–2890. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Li, Y. Beyond physical connections: Tree models in human pose estimation. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 596–603. [Google Scholar]
- Pishchulin, L.; Andriluka, M.; Gehler, P.; Schiele, B. Poselet conditioned pictorial structures. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 588–595. [Google Scholar]
- Toshev, A.; Szegedy, C. Deeppose: Human pose estimation via deep neural networks. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1653–1660. [Google Scholar]
- Ramakrishna, V.; Munoz, D.; Hebert, M.; Bagnell, J.A.; Sheikh, Y. Pose Machines: Articulated Pose Estimation via Inference Machines. In Computer Vision–ECCV 2014; Springer: Berlin, Germany, 2014; pp. 33–47. [Google Scholar]
- Shotton, J.; Girshick, R.; Fitzgibbon, A.; Sharp, T.; Cook, M.; Finocchio, M.; Moore, R.; Kohli, P.; Criminisi, A.; Kipman, A.; et al. Efficient human pose estimation from single depth images. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2821–2840. [Google Scholar] [CrossRef] [PubMed]
- Martinez, E.; Nina, O.; Sanchez, A.; Ricolfe, C. Optimized 4D-DPM for Pose Estimation on RGBD Channels using polisphere models. In Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Porto, Portugal, 27 February–1 March 2017; Volume 5, pp. 281–288. [Google Scholar]
- Martinez, E.; Sanchez-Salmeron, A.J.; Ricolfe-Viala, C. 4D-DPM model for pose estimation using Kalman filter constraints. Int. J. Adv. Robot. Syst. 2017, 14, 1–13. [Google Scholar]
- Fischler, M.A.; Elschlager, R.A. The representation and matching of pictorial structures. IEEE Trans. Comput. 1973, 22, 67–92. [Google Scholar] [CrossRef]
- Eichner, M.; Ferrari, V. Better appearance models for pictorial structures. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 8–10 September 2009; Volume 2, p. 5. [Google Scholar]
- Andriluka, M.; Roth, S.; Schiele, B. Pictorial structures revisited: People detection and articulated pose estimation. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1014–1021. [Google Scholar]
- Huang, C.M.; Chen, Y.R.; Fu, L.C. Visual tracking of human head and arms using adaptive multiple importance sampling on a single camera in cluttered environments. IEEE Sens. J. 2014, 14, 2267–2275. [Google Scholar] [CrossRef]
- Ning, X.; Guo, G. Assessing spinal loading using the kinect depth. IEEE Sens. J. 2013, 13, 1139–1140. [Google Scholar] [CrossRef]
- Sapp, B.; Taskar, B. Modec: Multimodal decomposable models for human pose estimation. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3674–3681. [Google Scholar]
- Wang, Y.; Tran, D.; Liao, Z.; Forsyth, D. Discriminative hierarchical part-based models for human parsing and action recognition. J. Mach. Learn. Res. 2012, 13, 3075–3102. [Google Scholar]
- Bourdev, L.; Malik, J. Poselets: Body part detectors trained using 3d human pose annotations. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 1365–1372. [Google Scholar]
- Ionescu, C.; Li, F.; Sminchisescu, C. Latent structured models for human pose estimation. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 Nocember 2011; pp. 2220–2227. [Google Scholar]
- Gkioxari, G.; Arbeláez, P.; Bourdev, L.; Malik, J. Articulated pose estimation using discriminative armlet classifiers. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 3342–3349. [Google Scholar]
- Grest, D.; Woetzel, J.; Koch, R. Nonlinear body pose estimation from depth images. In Pattern Recognition; Springer: Berlin, Germany, 2005; pp. 285–292. [Google Scholar]
- Plagemann, C.; Ganapathi, V.; Koller, D.; Thrun, S. Real-time identification and localization of body parts from depth images. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010; pp. 3108–3113. [Google Scholar]
- Helten, T.; Baak, A.; Bharaj, G.; Muller, M.; Seidel, H.P.; Theobalt, C. Personalization and Evaluation of a Real-Time Depth-Based Full Body Tracker. In Proceedings of the 2013 International Conference on 3D Vision, Seattle, WA, USA, 23 June–1 July 2013; pp. 279–286. [Google Scholar]
- Baak, A.; Müller, M.; Bharaj, G.; Seidel, H.P.; Theobalt, C. A data-driven approach for real-time full body pose reconstruction from a depth camera. In Consumer Depth Cameras for Computer Vision; Springer: Berlin, Germany, 2013; pp. 71–98. [Google Scholar]
- Spinello, L.; Arras, K.O. People detection in RGB-D data. In Proceedings of the 2011 IEEE Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Ganapathi, V.; Plagemann, C.; Koller, D.; Thrun, S. Real time motion capture using a single time-of-flight camera. In Proceedings of the 2010 IEEE Conference Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 755–762. [Google Scholar]
- Ye, M.; Yang, R. Real-time simultaneous pose and shape estimation for articulated objects using a single depth camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ding, M.; Fan, G. Articulated and Generalized Gaussian Kernel Correlation for Human Pose Estimation. IEEE Trans. Image Process. 2016, 25. [Google Scholar] [CrossRef] [PubMed]
- Ganapathi, V.; Plagemann, C.; Koller, D.; Thrun, S. Real-time human pose tracking from range data. In Proceedings of the 12th European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012. [Google Scholar]
- Ganapathi, V.; Plagemann, C.; Koller, D.; Thrun, S. Real time motion capture using a single time-of-flight camera. In Proceedings of the 2010 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Baak, A.; Muller, M.; Bharaj, G.; Seidel, H.; Theobalt, C. A datadriven approach for real-time full body pose reconstruction from a depth camera. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Ye, M.; Wang, X.; Yang, R.; Ren, L.; Pollefeys, M. Accurate 3D pose estimation from a single depth image. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Wei, X.; Zhang, P.; Chai, J. Accurate realtime full-body motion capture using a single depth camera. ACM Trans. Graph. 2012, 31, 188. [Google Scholar] [CrossRef]
- Stoll, C.; Hasler, N.; Gall, J.; Seidel, H.; Theobalt, C. Fast articulated motion tracking using a sums of Gaussians body model. In Proceedings of the 2011 IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Ding, M. Fast human pose tracking with a single depth sensor using sum of Gaussians models. Adv. Visual Comput. 2014, 8887, 599–608. [Google Scholar]
- Ding, M.; Fan, G. Generalized sum of Gaussians for real-time human pose tracking from a single depth sensor. In Proceedings of the 2015 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2015. [Google Scholar]
- Taylor, J.; Shotton, J.; Sharp, T.; Fitzgibbon, A. The Vitruvian manifold: Inferring dense correspondences for one-shot human pose estimation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Kurmankhojayev, D.; Hasler, N.; Theobalt, C. Monocular pose capture with a depth camera using a Sums-of-Gaussians body model. Pattern Recognit. 2013, 8142, 415–424. [Google Scholar]
- Sridhar, S.; Rhodin, H.; Seidel, H.; Oulasvirta, A.; Theobalt, C. Real-time hand tracking using a sum of anisotropic Gaussians model. In Proceedings of the International Conference on 3D Vision (3DV), Tokyo, Japan, 8–11 December 2014. [Google Scholar]
- Tsin, Y.; Kanade, T. A correlation-based approach to robust point set registration. In European Conference on Computer Vision; Springer: Berlin, Germany, 2004. [Google Scholar]
- Lai, K.; Bo, L.; Ren, X.; Fox, D. Detection-based object labeling in 3D scenes. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), St Paul, MN, USA, 14–18 May 2012; pp. 1330–1337. [Google Scholar]
- Sridhar, S.; Oulasvirta, A.; Theobalt, C. Interactive markerless articulated hand motion tracking using RGB and depth data. In Proceedings of the International Conference on Computer Vision (ICCV) 2013, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Martinez, E.; Sanchez, A.; Ricolfe, C.; Nina, O. Human Pose Estimation for RGBD Imagery with Multi-Channel Mixture of Parts and Kinematic Constraints. WSEAS Trans. Comput. 2016, 15, 279–286. [Google Scholar]
- Berti, E.M.; Salmerón, A.J.S.; Benimeli, F. Human-Robot Interaction and Tracking Using low cost 3D Vision Systems. Romanian J. Tech. Sci. Appl. Mech. 2012, 7, 1–15. [Google Scholar]
- Ricolfe, C.; Sanchez, A.; Martinez, E. Calibration of a wide angle stereoscopic system. Opt. Lett. 2011, 36, 3064–3066. [Google Scholar] [CrossRef] [PubMed]
- Ricolfe, C.; Sanchez, A.; Martinez, E. Accurate calibration with highly distorted images. Appl. Opt. 2012, 51, 89–101. [Google Scholar] [CrossRef] [PubMed]
- Sung, J.; Ponce, C.; Selman, B.; Saxena, A. Human activity detection from RGBD images. Plan Act. Intent Recognit. 2011, 64, 47–55. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y. Learning actionlet ensemble for 3D human action recognition. In Human Action Recognition with Depth Cameras; Springer: Berlin, Germany, 2014; pp. 11–40. [Google Scholar]
- Shan, J.; Akella, S. 3D Human Action Segmentation and Recognition using Pose Kinetic Energy. In Proceedings of the 2014 IEEE Workshop on Advanced Robotics and its Social Impacts (ARSO), Evanston, IL, USA, 11–13 September 2014. [Google Scholar]
- Faria, R.D.; Premebida, C.; Nunes, U. A Probalistic Approach for Human Everyday Activities Recognition using Body Motion from RGB-D Images. In Proceedings of the 2014 RO-MAN: 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Metric | Head | Shoulders | Wrist | Hip | Ankle | Avg |
|---|---|---|---|---|---|---|---|
| Yang* [1] | APK | 82.70 | |||||
| PCK | 85.80 | ||||||
| Error | 10.87 | ||||||
| P. Method* with KF with DH | APK | 97.50 | 98.30 | 92.20 | 94.70 | 94.00 | 95.34 |
| PCK | 96.40 | 95.20 | 93.70 | 96.50 | 94.20 | 95.20 | |
| Error | 5.82 | 5.71 | 7.43 | 6.37 | 6.61 | 6.38 |
| Method | Memory | Products | Sum/Subtract | Total |
|---|---|---|---|---|
| Homogeneous Matrix | 16 | 64 | 48 | 112 |
| Dual Quaternions | 8 | 48 | 40 | 88 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martinez-Berti, E.; Sánchez-Salmerón, A.-J.; Ricolfe-Viala, C. Dual Quaternions as Constraints in 4D-DPM Models for Pose Estimation. Sensors 2017, 17, 1913. https://doi.org/10.3390/s17081913
Martinez-Berti E, Sánchez-Salmerón A-J, Ricolfe-Viala C. Dual Quaternions as Constraints in 4D-DPM Models for Pose Estimation. Sensors. 2017; 17(8):1913. https://doi.org/10.3390/s17081913
Chicago/Turabian StyleMartinez-Berti, Enrique, Antonio-José Sánchez-Salmerón, and Carlos Ricolfe-Viala. 2017. "Dual Quaternions as Constraints in 4D-DPM Models for Pose Estimation" Sensors 17, no. 8: 1913. https://doi.org/10.3390/s17081913