
Detection of Large Herbivores in UAV Images: A New Method for Small Target Recognition in Large-Scale Images



Abstract
:1. Introduction
2. Data and Relevant Technical Principles
2.1. Data Sources
2.2. Data Preprocessing
2.3. Faster-RCNN Algorithm
2.4. MMdetection
3. Improvement of Faster-RCNN Algorithm
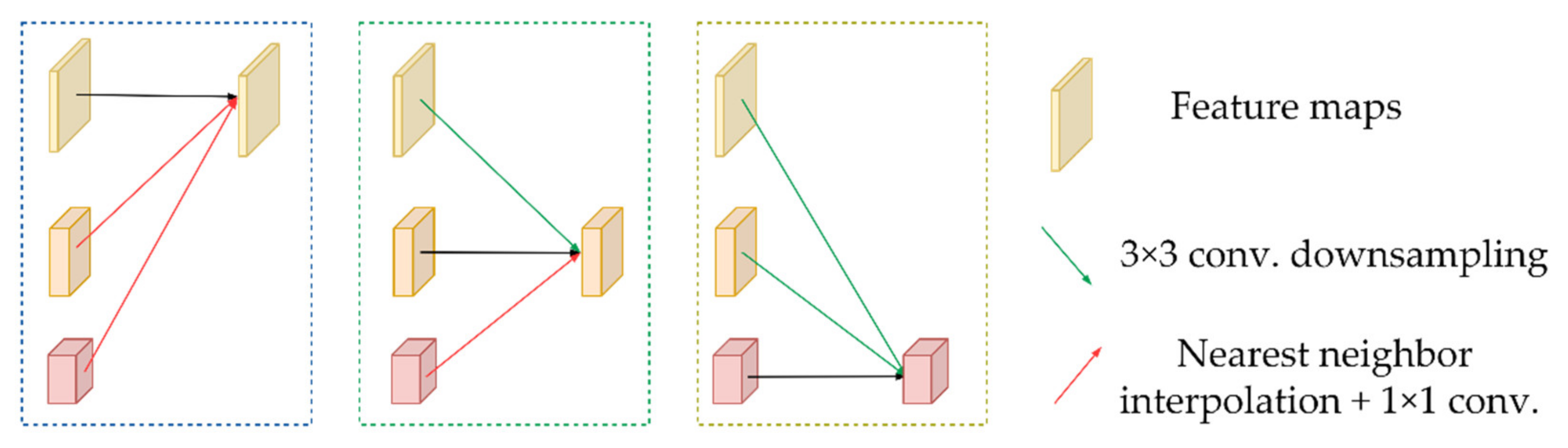
3.1. Replacing the Feature Extraction Network
3.2. Optimizing the Region Proposal Network
3.3. Post-Processing Optimization
3.4. New Detection Method of Overlap Segmentation
4. Experimental Verification and Analysis
4.1. Experimental Configuration
4.2. Experimental Design and Evaluation Index
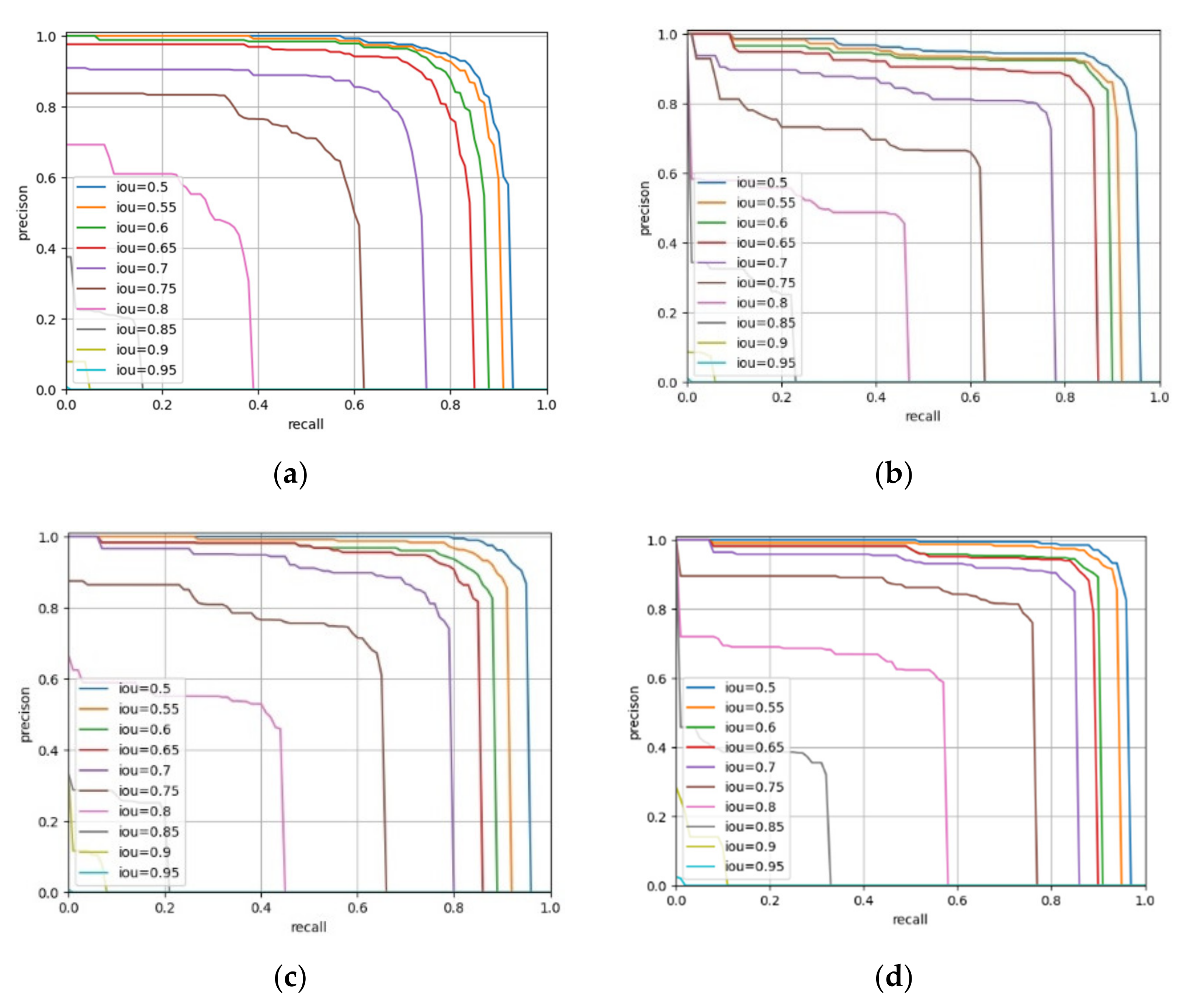
4.3. Comparative Experimental Results and Analysis of Improved Faster-RCNN Algorithm
4.3.1. Experimental Results and Analysis of the Original Faster-RCNN Algorithm Using Different Feature Extraction Networks
4.3.2. Experimental Results and Analysis of Optimizing Region Proposal Network
4.3.3. Test Results and Analysis of Post-Processing Optimization
4.3.4. Experimental Results and Analysis of Different Segmentation Methods
5. Conclusions
- (1)
- Compared with the VGG16 network, ResNet50 network, and ResNet101 network, it was proven that the HRNet feature extraction network is more suitable for the detection of large herbivores in UAV images.
- (2)
- According to the results of K-means clustering, the size and proportions of the anchor frame were adjusted. AR was increased by 0.038 and mAP was increased by 0.037. This shows that setting sizes and proportions of anchor frames that are suitable for the target according to the results of K-means clustering can improve the accuracy.
- (3)
- Using the results of K-means clustering to adjust the size and proportions of anchor frames and using NMS to eliminate the detection frames that did not fall within the range at the same time, the AP of yaks, Tibetan wild donkeys, and Tibetan sheep reached 0.971, 0.978, and 0.967, respectively, values which were 0.019, 0.005, and 0.099 higher than those obtained before the two improvements, whereas the mAP reached a value that was 0.972, and 0.041 higher than that obtained before the two improvements.
- (4)
- We used the detection method of overlapping segmentation first, removing the detection frame within 50 pixels of the edge, and then NMS could realize the high-precision detection of the whole UAV image, and there were no cases where the detection frame did not fit the target or where false alarms or missed detection were caused by the animals being divided into two halves.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Song, Q.J. Unmanned Aircraft System for Surveying Large Herbivores—A Case Study in Longbao Wetland National Nature Reserve, Qinghai Province, China. Master’s Thesis, Lanzhou University, Lanzhou, China, 26 May 2018. [Google Scholar]
- Lu, W.J. Mechanisms of Carbon Transformation in Grassland Ecosystems Affected by Grazing. Master’s Thesis, China Agricultural University, Beijing, China, 4 December 2017. [Google Scholar]
- Zhang, S.; Shao, Q.Q.; Liu, J.Y.; Xu, X.L. Grassland Cover Change near the Source of the Yellow River: Case Study of Madoi County, Qinghai Province. Resour. Sci. 2008, 30, 1547–1554. [Google Scholar]
- Liu, J.Y.; Xu, X.L.; Shao, Q.Q. Grassland degradation in the “Three-River Headwaters” region, Qinghai Province. J. Geogr. Sci. 2008, 18, 259–273. [Google Scholar] [CrossRef]
- Yang, F.; Shao, Q.Q.; Guo, X.J.; Li, Y.Z.; Wang, D.L.; Zhang, Y.X.; Wang, Y.C.; Liu, J.Y.; Fan, J.W. Effects of wild large herbivore populations on the grassland-livestock balance in Maduo County. Acta Prataculturae Sin. 2018, 27, 1–13. [Google Scholar]
- Luo, W.; Shao, Q.Q.; Wang, D.L.; Wang, Y.C. An Object-Oriented Classification Method for Detection of Large Wild Herbivores: A Case Study in the Source Region of Three Rivers in Qinghai. Chin. J. Wildl. 2017, 38, 561–564. [Google Scholar]
- Wang, N.; Li, Z.; Liang, X.L.; Wu, X.N.; Lü, Z.H. Research on Application of UAV Autonomous Target Recognition and Positioning. Comput. Meas. Control 2021, 29, 215–219. [Google Scholar]
- Shi, L.; Jing, M.E.; Fan, Y.B.; Zeng, X.Y. Segmentation Detection Algorithm Based on R-CNN Algorithm. J. Fudan Univ. Nat. Sci. 2020, 59, 412–418. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.F.; Yi, L.; He, K.M.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. In Proceedings of the Thirtieth Conference on Neural Information Processing Systems, Centre Convencions Internacional Barcelona, Barcelona, Spain, 5 December 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2015, 9905, 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 12 December 2016. [Google Scholar]
- Peng, H.; Li, X.M. Small target detection model based on improved Faster R-CNN. Electron. Meas. Technol. 2021, 44, 122–127. [Google Scholar]
- Lecun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Comput. Sci. Name 2014, arXiv:1409.1556. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 10 April 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Sermanet, P.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Xie, S.N.; Girshick, R.; Dollar, P.; Tu, Z.W.; He, K.M. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 25 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 21 June 2018. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J.D. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 19 June 2019. [Google Scholar]
- Zhang, S. Analysis of Land Use/Cover Change and Driving Forces in Maduo County, the Source Region of the Yellow River. Master’s Thesis, Institute of Geographic Sciences and Natural Resources Research, CAS, Beijing, China, 6 July 2007. [Google Scholar]
- Shao, Q.Q.; Guo, X.J.; Li, Y.Z.; Wang, Y.C.; Wang, D.L.; Liu, J.Y.; Fan, J.W.; Yang, J.W. Using UAV remote sensing to analyze the population and distribution of large wild herbivores. J. Remote Sens. 2018, 22, 497–507. [Google Scholar]
- Xie, X.H.; Lu, J.B.; Li, W.T.; Liu, C.X.; Huang, H.M. Classification Model of Clothing Image Based on Migration Learning. Comput. Appl. Softw. 2020, 37, 88–93. [Google Scholar]
- Huang, Y.X.; Fang, L.M.; Huang, S.Q.; Gao, H.L.; Yang, L.B.; Lou, S.X. Research on Crown Extraction Based on lmproved Faster R-CNN Model. For. Resour. Manag. 2021, 1, 173–179. [Google Scholar]
- Cheng, Z.A. Automatic Recognition of Terrestrial Wildlife in Inner Mongolia based on Deep Convolution Neural Network. Master’s Thesis, Beijing Forestry University, Beijing, China, 12 June 2019. [Google Scholar]
- Chen, X.E.; Li, H.M.; Chen, D.T. Research and Implementation of Dish Recognition Based on Convolutional Neural Network. Mod. Comput. 2021, 27, 95–98. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.H.; Xiao, B.; Liu, D.; Mu, Y.D.; Wang, X.G.; Liu, W.Y.; Wang, J.D. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.M.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 9 November 2017. [Google Scholar]
- Van Etten, A. You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Tan, T. The Optimization Algorithm Research of Stochastic Gradient Descent Based on Convolutional Neural Network. Master’s Thesis, Southwest University, Chongqing, China, 18 April 2020. [Google Scholar]
- Wang, J.; Zhang, D.Y.; Kang, X.Y. Improved Detection Method of Low Altitude Small UAV by Faster-RCNN. J. Shenyang Ligong Univ. 2021, 40, 23–28. [Google Scholar]
- Long, J.H.; Guo, W.Z.; Lin, S.; Wen, C.W.; Zhang, Y.; Zhao, C.J. Strawberry Growth Period Recognition Method Under Greenhouse Environment Based on Improved YOLOv4. Smart Agric. 2021, 3, 99–110. [Google Scholar]
- Chen, Y.Z. Research on Object Detection algorithm Based on Feature fusion and Adaptive Anchor Framework. Master’s Thesis, Henan University, Kaifeng, China, 24 June 2020. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extraction Network | AP | AR | mAP | ||
|---|---|---|---|---|---|
| Yak | Tibetan Wild Ass | Tibetan Sheep | |||
| VGG16 | 0.893 | 0.903 | 0.756 | 0.887 | 0.851 |
| ResNet50 | 0.908 | 0.951 | 0.832 | 0.921 | 0.897 |
| ResNet101 | 0.944 | 0.96 | 0.811 | 0.925 | 0.905 |
| HRNet | 0.952 | 0.973 | 0.868 | 0.942 | 0.931 |
| Anchor Frame Size | Anchor Frame Scale | AP | AR | mAP | ||
|---|---|---|---|---|---|---|
| Yak | Tibetan Wild Ass | Tibetan Sheep | ||||
| 8 | 0.5, 1.0, 2.0 | 0.952 | 0.973 | 0.868 | 0.942 | 0.931 |
| 8 | 0.75, 1.0, 1.35 | 0.962 | 0.966 | 0.902 | 0.947 | 0.943 |
| 4 | 0.5, 1.0, 2.0 | 0.972 | 0.977 | 0.948 | 0.974 | 0.966 |
| 4 | 0.75, 1.0, 1.35 | 0.985 | 0.963 | 0.955 | 0.980 | 0.968 |
| NMS | Anchor Frame Size | Anchor Frame Scale | AP | AR | mAP | ||
|---|---|---|---|---|---|---|---|
| Yak | Tibetan Wild Ass | Tibetan Sheep | |||||
| No | 8 | 0.5, 1.0, 2.0 | 0.952 | 0.973 | 0.868 | 0.942 | 0.931 |
| Yes | 8 | 0.5, 1.0, 2.0 | 0.964 | 0.962 | 0.902 | 0.958 | 0.942 |
| No | 4 | 0.7, 1.0, 1.35 | 0.985 | 0.963 | 0.955 | 0.980 | 0.968 |
| Yes | 4 | 0.7, 1.0, 1.35 | 0.971 | 0.978 | 0.967 | 0.982 | 0.972 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, J.; Hu, Z.; Shao, Q.; Wang, Y.; Zhou, Y.; Liu, J.; Liu, S. Detection of Large Herbivores in UAV Images: A New Method for Small Target Recognition in Large-Scale Images. Diversity 2022, 14, 624. https://doi.org/10.3390/d14080624
Ma J, Hu Z, Shao Q, Wang Y, Zhou Y, Liu J, Liu S. Detection of Large Herbivores in UAV Images: A New Method for Small Target Recognition in Large-Scale Images. Diversity. 2022; 14(8):624. https://doi.org/10.3390/d14080624
Chicago/Turabian StyleMa, Jiarong, Zhuowei Hu, Quanqin Shao, Yongcai Wang, Yanqiong Zhou, Jiayan Liu, and Shuchao Liu. 2022. "Detection of Large Herbivores in UAV Images: A New Method for Small Target Recognition in Large-Scale Images" Diversity 14, no. 8: 624. https://doi.org/10.3390/d14080624