

Deep Semantic Segmentation of Angiogenesis Images

 , , , , , , , , , , , , , , and
, , , , , , , , , , , , , , and 
Abstract
:1. Introduction
2. Results
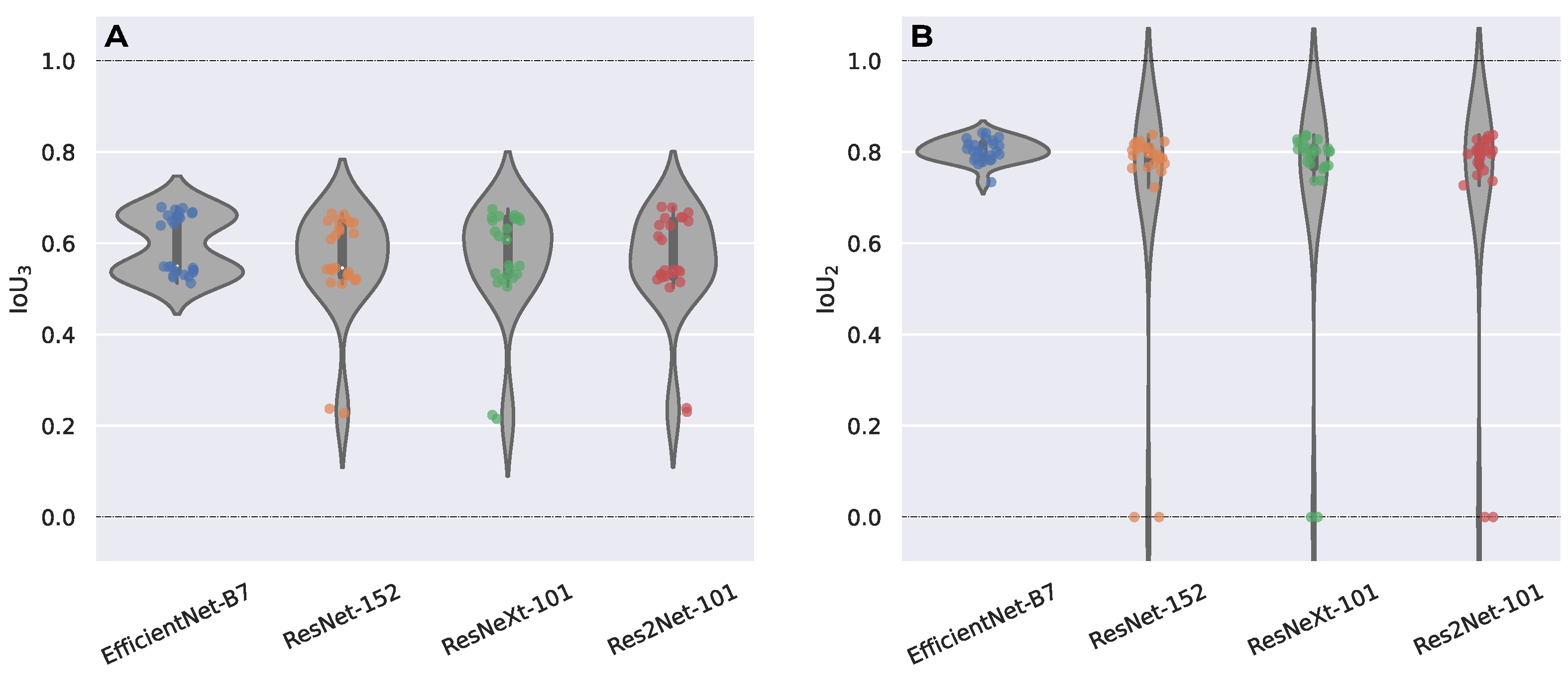
2.1. Encoder Selection
2.2. Optimization Loss Function
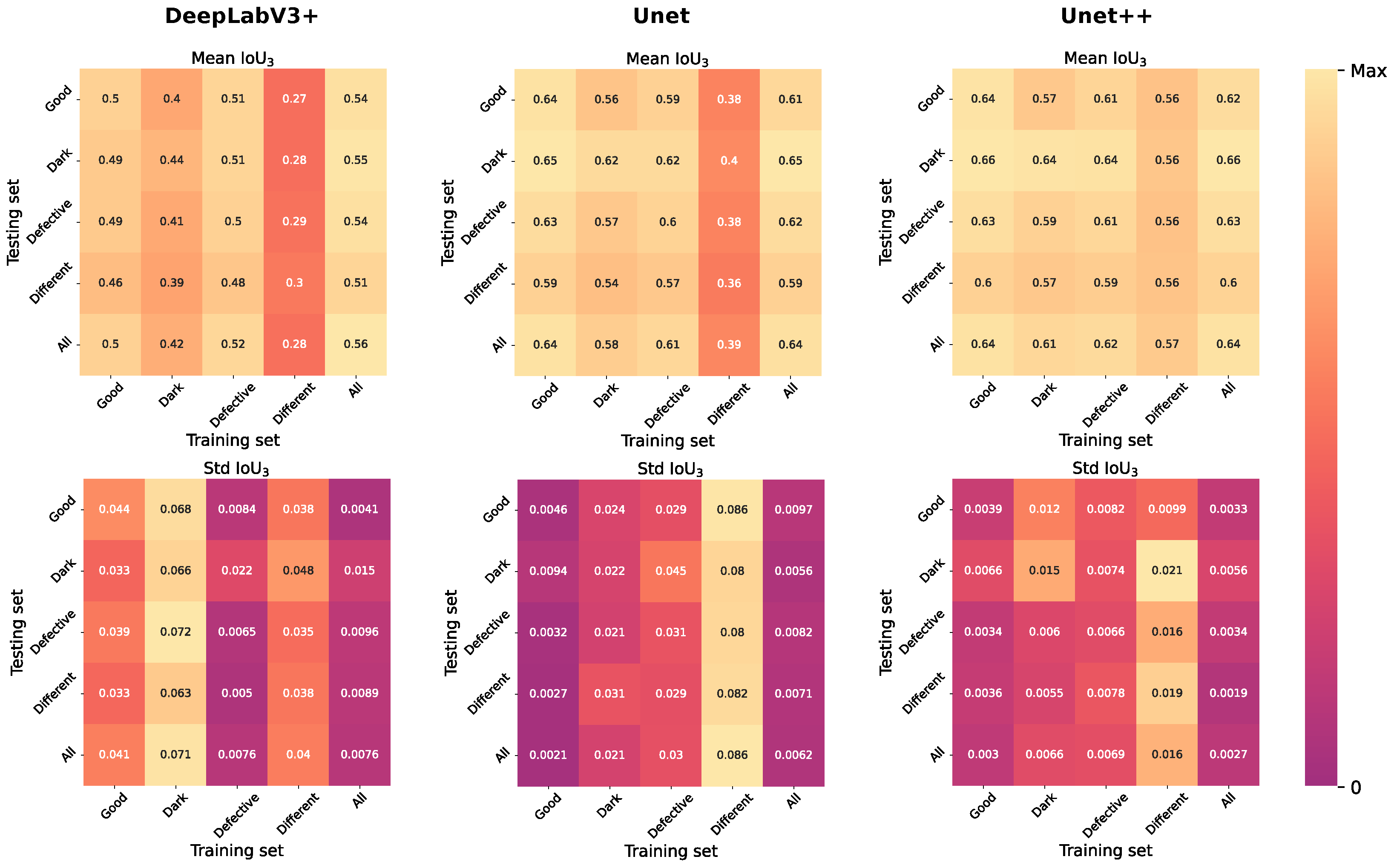
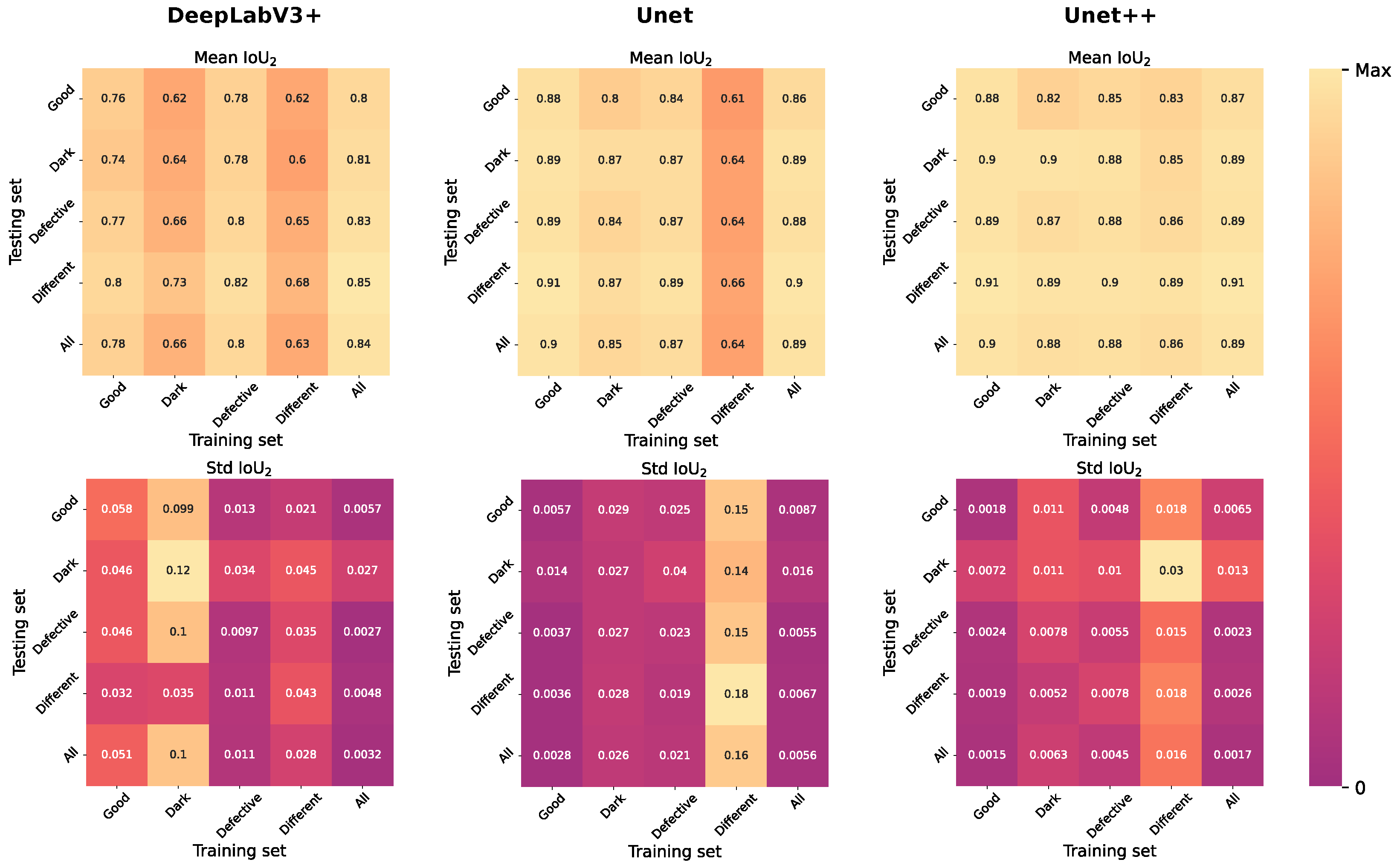
2.3. Architecture Selection
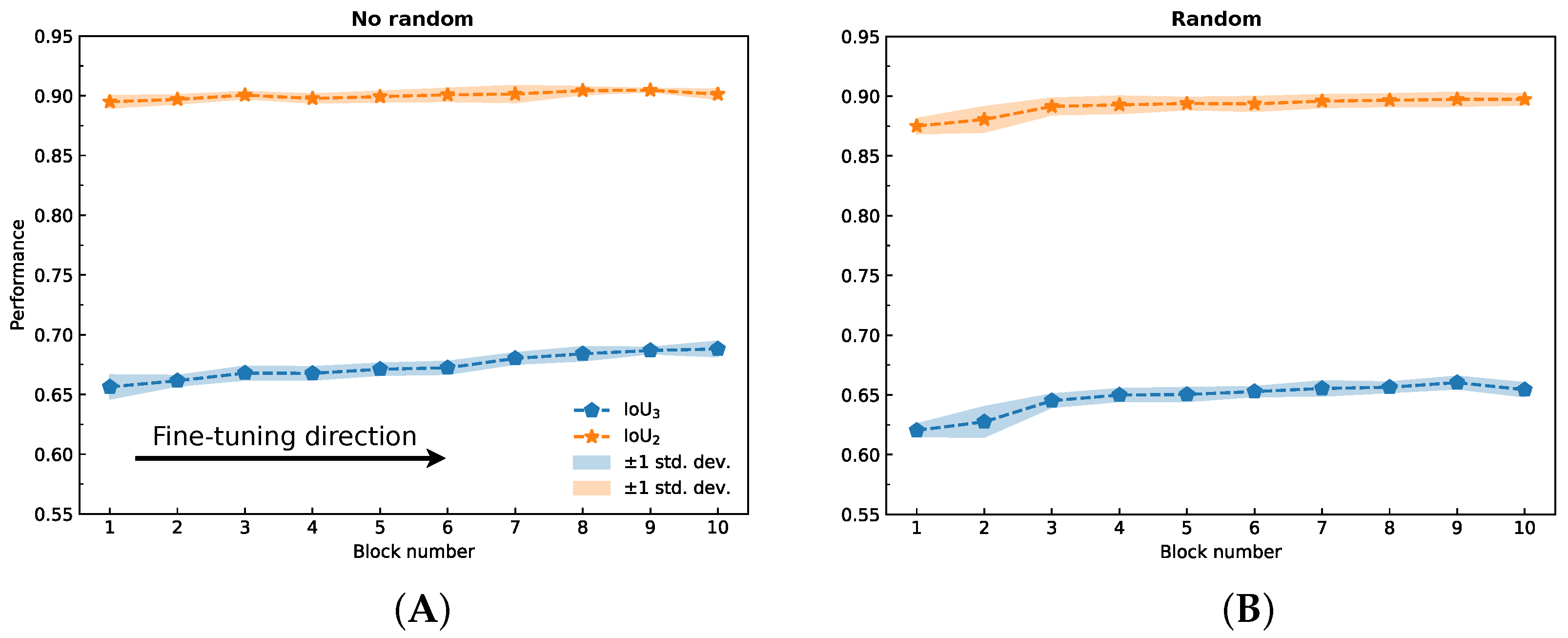
2.4. Fine-Tuning
- The model obtained in Section 2.3 was taken, all layers were frozen, the first block was unfrozen, and the network was trained using a fivefold cross-validation;
- The best performing network (IoU) from the previous experiment was taken, all layers were frozen, the next block was unfrozen, and the network was trained using a fivefold cross-validation;
- Step 2 was repeated until the network with a fully fine-tuned encoder was obtained.
2.5. Qualitative Results
3. Discussion
4. Materials and Methods
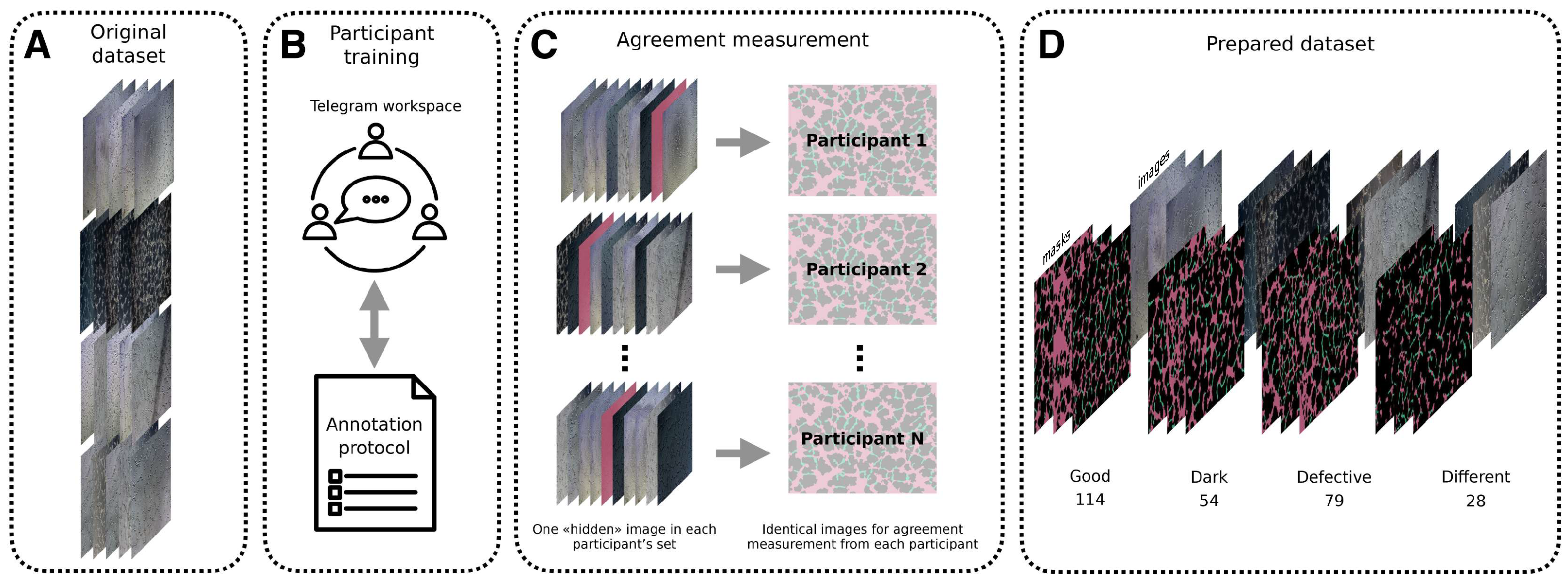
4.1. Dataset Description
4.2. Participant Training and Data Collection
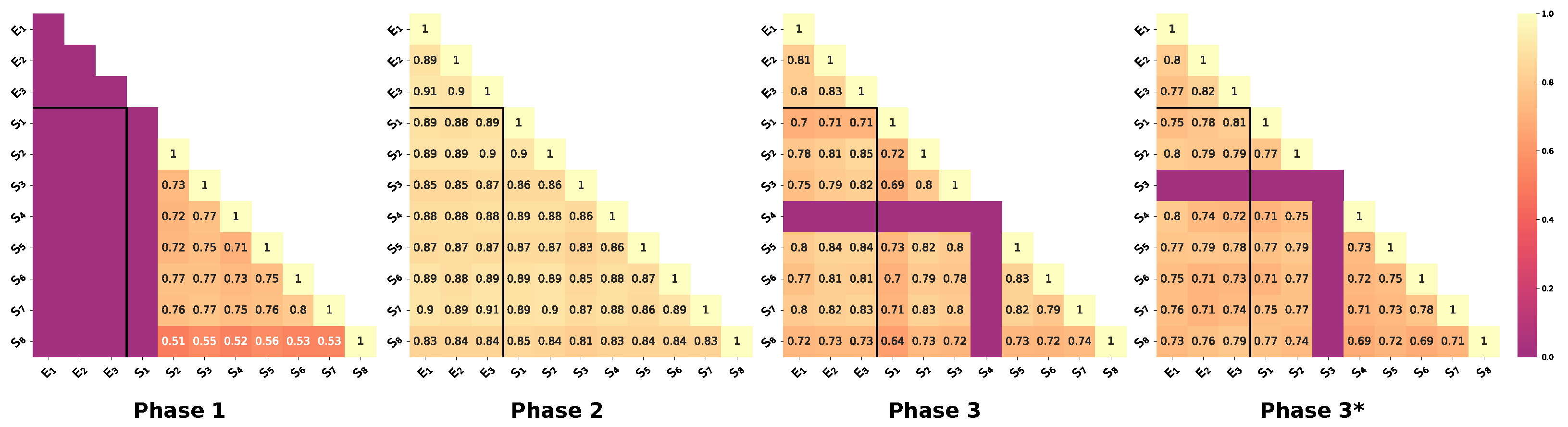
4.3. Measuring Annotation Interparticipant Agreement
4.4. Evaluation Model Performance
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Papetti, M.; Herman, I.M. Mechanisms of normal and tumor-derived angiogenesis. Am. J. Physiol.-Cell Physiol. 2002, 282, C947–C970. [Google Scholar] [CrossRef] [Green Version]
- Risau, W. Mechanisms of angiogenesis. Nature 1997, 386, 671–674. [Google Scholar] [CrossRef] [PubMed]
- Folkman, J.; Shing, Y. Angiogenesis. J. Biol. Chem. 1992, 267, 10931–10934. [Google Scholar] [CrossRef] [PubMed]
- Carmeliet, P.; Jain, R.K. Molecular mechanisms and clinical applications of angiogenesis. Nature 2011, 473, 298–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Udan, R.S.; Culver, J.C.; Dickinson, M.E. Understanding vascular development. Wiley Interdiscip. Rev. Dev. Biol. 2013, 2, 327–346. [Google Scholar] [CrossRef]
- Secomb, T.W.; Pries, A.R. Microvascular plasticity: Angiogenesis in health and disease–preface. Microcirculation 2016, 23, 93–94. [Google Scholar] [CrossRef] [Green Version]
- Carmeliet, P. Angiogenesis in life, disease and medicine. Nature 2005, 438, 932–936. [Google Scholar] [CrossRef]
- Folkman, J. Angiogenesis: An organizing principle for drug discovery? Nat. Rev. Drug Discov. 2007, 6, 273–286. [Google Scholar] [CrossRef]
- Herbert, S.P.; Stainier, D.Y. Molecular control of endothelial cell behaviour during blood vessel morphogenesis. Nat. Rev. Mol. Cell Biol. 2011, 12, 551–564. [Google Scholar] [CrossRef] [Green Version]
- Charnock-Jones, D.; Kaufmann, P.; Mayhew, T. Aspects of human fetoplacental vasculogenesis and angiogenesis. I. Molecular regulation. Placenta 2004, 25, 103–113. [Google Scholar] [CrossRef]
- Norrby, K. In vivo models of angiogenesis. J. Cell. Mol. Med. 2006, 10, 588–612. [Google Scholar] [CrossRef] [PubMed]
- Ponce, M.L. Tube formation: An in vitro matrigel angiogenesis assay. In Angiogenesis Protocols; Springer: Berlin/Heidelberg, Germany, 2009; pp. 183–188. [Google Scholar]
- Khoo, C.P.; Micklem, K.; Watt, S.M. A comparison of methods for quantifying angiogenesis in the Matrigel assay in vitro. Tissue Eng. Part C Methods 2011, 17, 895–906. [Google Scholar] [CrossRef] [Green Version]
- Russ, J.C. The Image Processing Handbook; CRC Press: Boca Raton, FL, USA, 2006. [Google Scholar]
- Wan, X.; Bovornchutichai, P.; Cui, Z.; O’Neill, E.; Ye, H. Morphological analysis of human umbilical vein endothelial cells co-cultured with ovarian cancer cells in 3D: An oncogenic angiogenesis assay. PLoS ONE 2017, 12, e0180296. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [Green Version]
- Arganda-Carreras, I.; Fernández-González, R.; Muñoz-Barrutia, A.; Ortiz-De-Solorzano, C. 3D reconstruction of histological sections: Application to mammary gland tissue. Microsc. Res. Tech. 2010, 73, 1019–1029. [Google Scholar] [CrossRef] [PubMed]
- Varberg, K.M.; Winfree, S.; Chu, C.; Tu, W.; Blue, E.K.; Gohn, C.R.; Dunn, K.W.; Haneline, L.S. Kinetic analyses of vasculogenesis inform mechanistic studies. Am. J. Physiol.-Cell Physiol. 2017, 312, C446–C458. [Google Scholar] [CrossRef] [PubMed]
- Chan, L.; Hosseini, M.; Rowsell, C.; Plataniotis, K.; Damaskinos, S. HistoSegNet: Semantic Segmentation of Histological Tissue Type in Whole Slide Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Seoul, Republic of Korea, 2019; pp. 10661–10670. [Google Scholar] [CrossRef]
- Punn, N.S.; Agarwal, S. Inception U-Net Architecture for Semantic Segmentation to Identify Nuclei in Microscopy Cell Images. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Saha, M.; Chakraborty, C. Her2Net: A Deep Framework for Semantic Segmentation and Classification of Cell Membranes and Nuclei in Breast Cancer Evaluation. IEEE Trans. Image Process. 2018, 27, 2189–2200. [Google Scholar] [CrossRef]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 3–11. [Google Scholar]
- Attribution 4.0 International [Internet]. Creative Commons Corporation. 2021. Available online: https://creativecommons.org/licenses/by/4.0/ (accessed on 21 October 2021).
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, A.; Le, T.B.; Laub, M.T. Bacterial chromosome organization and segregation. Annu. Rev. Cell Dev. Biol. 2015, 31, 171. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar]
- Honari, S.; Yosinski, J.; Vincent, P.; Pal, C. Recombinator networks: Learning coarse-to-fine feature aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5743–5752. [Google Scholar]
- Iglovikov, V.; Mushinskiy, S.; Osin, V. Satellite imagery feature detection using deep convolutional neural network: A kaggle competition. arXiv 2017, arXiv:1706.06169. [Google Scholar]
- Iglovikov, V.I.; Rakhlin, A.; Kalinin, A.A.; Shvets, A.A. Paediatric bone age assessment using deep convolutional neural networks. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2018; pp. 300–308. [Google Scholar]
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kaggle Teams. Carvana Image Masking Challenge–1st Place Winner’s Interview, (nd). Available online: https://medium.com/kaggle-blog/carvana-image-masking-challenge-1st-place-winners-interview-78fcc5c887a8 (accessed on 25 May 2020).
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Xie, Q.; Luong, M.T.; Hovy, E.; Le, Q.V. Self-training with noisy student improves imagenet classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10687–10698. [Google Scholar]
- Li, Y.; Yu, Q.; Tan, M.; Mei, J.; Tang, P.; Shen, W.; Yuille, A.; Xie, C. Shape-texture debiased neural network training. arXiv 2020, arXiv:2010.05981. [Google Scholar]
- Lee, J.; Won, T.; Lee, T.K.; Lee, H.; Gu, G.; Hong, K. Compounding the performance improvements of assembled techniques in a convolutional neural network. arXiv 2020, arXiv:2001.06268. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Conover, W. Practical Nonparametric Statistics; Wiley & Sons.: New York, NY, USA, 1971. [Google Scholar]
- Jadon, S. A survey of loss functions for semantic segmentation. In Proceedings of the 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Via del Mar, Chile, 27–29 October 2020; pp. 1–7. [Google Scholar]
- Asgari Taghanaki, S.; Abhishek, K.; Cohen, J.P.; Cohen-Adad, J.; Hamarneh, G. Deep semantic segmentation of natural and medical images: A review. Artif. Intell. Rev. 2021, 54, 137–178. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar] [CrossRef]
- Bengio, Y.; LeCun, Y. Scaling learning algorithms towards AI. Large-Scale Kernel Mach. 2007, 34, 1–41. [Google Scholar]
- Amiri, M.; Brooks, R.; Rivaz, H. Fine tuning u-net for ultrasound image segmentation: Which layers. In Domain Adaptation and Representation Transfer and Medical Image Learning with Less Labels and Imperfect Data; Springer: Berlin/Heidelberg, Germany, 2019; pp. 235–242. [Google Scholar]
- Leung, D.W.; Cachianes, G.; Kuang, W.J.; Goeddel, D.V.; Ferrara, N. Vascular endothelial growth factor is a secreted angiogenic mitogen. Science 1989, 246, 1306–1309. [Google Scholar] [CrossRef]
- Nowak-Sliwinska, P.; Alitalo, K.; Allen, E.; Anisimov, A.; Aplin, A.C.; Auerbach, R.; Augustin, H.G.; Bates, D.O.; van Beijnum, J.R.; Bender, R.H.F.; et al. Consensus guidelines for the use and interpretation of angiogenesis assays. Angiogenesis 2018, 21, 425–532. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Patel, S.P.; Bourne, W.M. Corneal endothelial cell proliferation: A function of cell density. Investig. Ophthalmol. Vis. Sci. 2009, 50, 2742–2746. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Z.; Chen, H.; Cai, J.; Huang, Y.; Yue, J. IL-10 regulates the malignancy of hemangioma-derived endothelial cells via regulation of PCNA. Arch. Biochem. Biophys. 2020, 688, 108404. [Google Scholar] [CrossRef] [PubMed]
- Park, J.Y.; Kwon, B.M.; Chung, S.K.; Kim, J.H.; Joo, C.K. Inhibitory effect of 2’-O-benzoylcinnamaldehyde on vascular endothelial cell proliferation and migration. Ophthalmic Res. 2001, 33, 111–116. [Google Scholar] [CrossRef] [PubMed]
- Markova, K.; Mikhailova, V.; Milyutina, Y.; Korenevsky, A.; Sirotskaya, A.; Rodygina, V.; Tyshchuk, E.; Grebenkina, P.; Simbirtsev, A.; Selkov, S.; et al. Effects of Microvesicles Derived from NK Cells Stimulated with IL-1β on the Phenotype and Functional Activity of Endothelial Cells. Int. J. Mol. Sci. 2021, 22, 13663. [Google Scholar] [CrossRef]
- Venter, C.; Niesler, C. Rapid quantification of cellular proliferation and migration using ImageJ. Biotechniques 2019, 66, 99–102. [Google Scholar] [CrossRef] [Green Version]
- Collins, T.J. ImageJ for microscopy. Biotechniques 2007, 43, S25–S30. [Google Scholar] [CrossRef]
- Markov, A.S.; Markova, K.L.; Sokolov, D.I.; Selkov, S.A. MARKMIGRATION, Russia; 2019. Registration Certificate No. 2019612366 for Computer Program “MarkMigratio”. 2019. Available online: https://www.fips.ru/registers-doc-view/fips_servlet?DB=EVM&DocNumber=2019612366&TypeFile=html (accessed on 18 February 2019).
- Lee, H.; Kang, K.T. Advanced tube formation assay using human endothelial colony forming cells for in vitro evaluation of angiogenesis. Korean J. Physiol. Pharmacol. 2018, 22, 705–712. [Google Scholar] [CrossRef]
- Sokolov, D.; Lvova, T.Y.; Okorokova, L.; Belyakova, K.L.; Sheveleva, A.; Stepanova, O.; Mikhailova, V.; Sel’kov, S. Effect of cytokines on the formation tube-like structures by endothelial cells in the presence of trophoblast cells. Bull. Exp. Biol. Med. 2017, 163, 148–158. [Google Scholar] [CrossRef]
- Carpentier, G.; Martinelli, M.; Courty, J.; Cascone, I. Angiogenesis analyzer for ImageJ. In Proceedings of the 4th ImageJ User and Developer Conference Proceedings, Luxembourg, 20 October 2012; pp. 198–201. [Google Scholar]
- Thornhill, M.H.; Li, J.; Haskard, D.O. Leucocyte endothelial cell adhesion: A study comparing human umbilical vein endothelial cells and the endothelial cell line EA-hy-926. Scand. J. Immunol. 1993, 38, 279–286. [Google Scholar] [CrossRef]
- Edgell, C.J.; McDonald, C.C.; Graham, J.B. Permanent cell line expressing human factor VIII-related antigen established by hybridization. Proc. Natl. Acad. Sci. USA 1983, 80, 3734–3737. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Riesbeck, K.; Billström, A.; Tordsson, J.; Brodin, T.; Kristensson, K.; Dohlsten, M. Endothelial cells expressing an inflammatory phenotype are lysed by superantigen-targeted cytotoxic T cells. Clin. Diagn. Lab. Immunol. 1998, 5, 675–682. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Benelli, R.; Albini, A. In vitro models of angiogenesis: The use of Matrigel. Int. J. Biol. Markers 1999, 14, 243–246. [Google Scholar] [CrossRef] [PubMed]
- Belyakova, K.L.; Stepanova, O.I.; Sheveleva, A.R.; Mikhailova, V.A.; Sokolov, D.I.; Sel’kov, S.A. Interaction of NK cells, trophoblast, and endothelial cells during angiogenesis. Bull. Exp. Biol. Med. 2019, 167, 169–176. [Google Scholar] [CrossRef] [PubMed]
- Markova, K.L.; Stepanova, O.I.; Sheveleva, A.R.; Kostin, N.A.; Mikhailova, V.A.; Selkov, S.A.; Sokolov, D.I. Natural killer cell effects upon angiogenesis under conditions of contact-dependent and distant co-culturing with endothelial and trophoblast cells. Med. Immunol. 2019, 21, 427–440. [Google Scholar] [CrossRef]
- Lvova, T.Y.; Belyakova, K.L.; Sel’kov, S.A.; Sokolov, D.I. Effect of THP-1 cells on the formation of vascular tubes by endothelial EA.Hy926 cells in the presence of placenta secretory products. Bull. Exp. Biol. Med. 2017, 162, 545–551. [Google Scholar] [CrossRef] [PubMed]
- Sekachev, B.; Manovich, N.; Zhiltsov, M.; Zhavoronkov, A.; Kalinin, D.; Hoff, B.; Tosmanov; Kruchinin, D.; Zankevich, A.; DmitriySidnev; et al. Opencv/cvat: v1.1.0. OpenAIRE 2020. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Hallgren, K.A. Computing inter-rater reliability for observational data: An overview and tutorial. Tutor. Quant. Methods Psychol. 2012, 8, 23. [Google Scholar] [CrossRef] [Green Version]
- Landis, J.R.; Koch, G.G. The measurement of observer agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Light, R.J. Measures of response agreement for qualitative data: Some generalizations and alternatives. Psychol. Bull. 1971, 76, 365. [Google Scholar] [CrossRef]
- Naumov, A.; Ushakov, E.; Ivanov, A.; Midiber, K.; Khovanskaya, T.; Konyukova, A.; Vishnyakova, P.; Nora, S.; Mikhaleva, L.; Fatkhudinov, T.; et al. EndoNuke: Nuclei Detection Dataset for Estrogen and Progesterone Stained IHC Endometrium Scans. Data 2022, 7, 75. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Image–Mask Pairs | ||
|---|---|---|
| Data Type | Training Set (68%) | Testing Set (32%) |
| Good | 77 | 37 |
| Dark | 36 | 18 |
| Defective | 53 | 26 |
| Different | 19 | 9 |
| All | 185 | 90 |
| Performance | DeepLabV3+ | Unet | Unet++ |
|---|---|---|---|
| IoU | |||
| IoU |
| Performance | Focal Loss | Architecture Selection | Fine-Tuning |
|---|---|---|---|
| IoU | % | % | % |
| IoU | % | % | % |
| Agreement Study | Phase 1 | Phase 2 | Phase 3 | Phase 3* |
|---|---|---|---|---|
| − | ||||
| − | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibragimov, A.; Senotrusova, S.; Markova, K.; Karpulevich, E.; Ivanov, A.; Tyshchuk, E.; Grebenkina, P.; Stepanova, O.; Sirotskaya, A.; Kovaleva, A.; et al. Deep Semantic Segmentation of Angiogenesis Images. Int. J. Mol. Sci. 2023, 24, 1102. https://doi.org/10.3390/ijms24021102
Ibragimov A, Senotrusova S, Markova K, Karpulevich E, Ivanov A, Tyshchuk E, Grebenkina P, Stepanova O, Sirotskaya A, Kovaleva A, et al. Deep Semantic Segmentation of Angiogenesis Images. International Journal of Molecular Sciences. 2023; 24(2):1102. https://doi.org/10.3390/ijms24021102
Chicago/Turabian StyleIbragimov, Alisher, Sofya Senotrusova, Kseniia Markova, Evgeny Karpulevich, Andrei Ivanov, Elizaveta Tyshchuk, Polina Grebenkina, Olga Stepanova, Anastasia Sirotskaya, Anastasiia Kovaleva, and et al. 2023. "Deep Semantic Segmentation of Angiogenesis Images" International Journal of Molecular Sciences 24, no. 2: 1102. https://doi.org/10.3390/ijms24021102