
An Uncharacterised lncRNA Coded by the ASAP1 Locus Is Downregulated in Serum of Type 2 Diabetes Mellitus Patients

 , , , , , ,
, , , , , ,  , ,
, ,  , and
, and
Abstract
:1. Introduction
2. Results
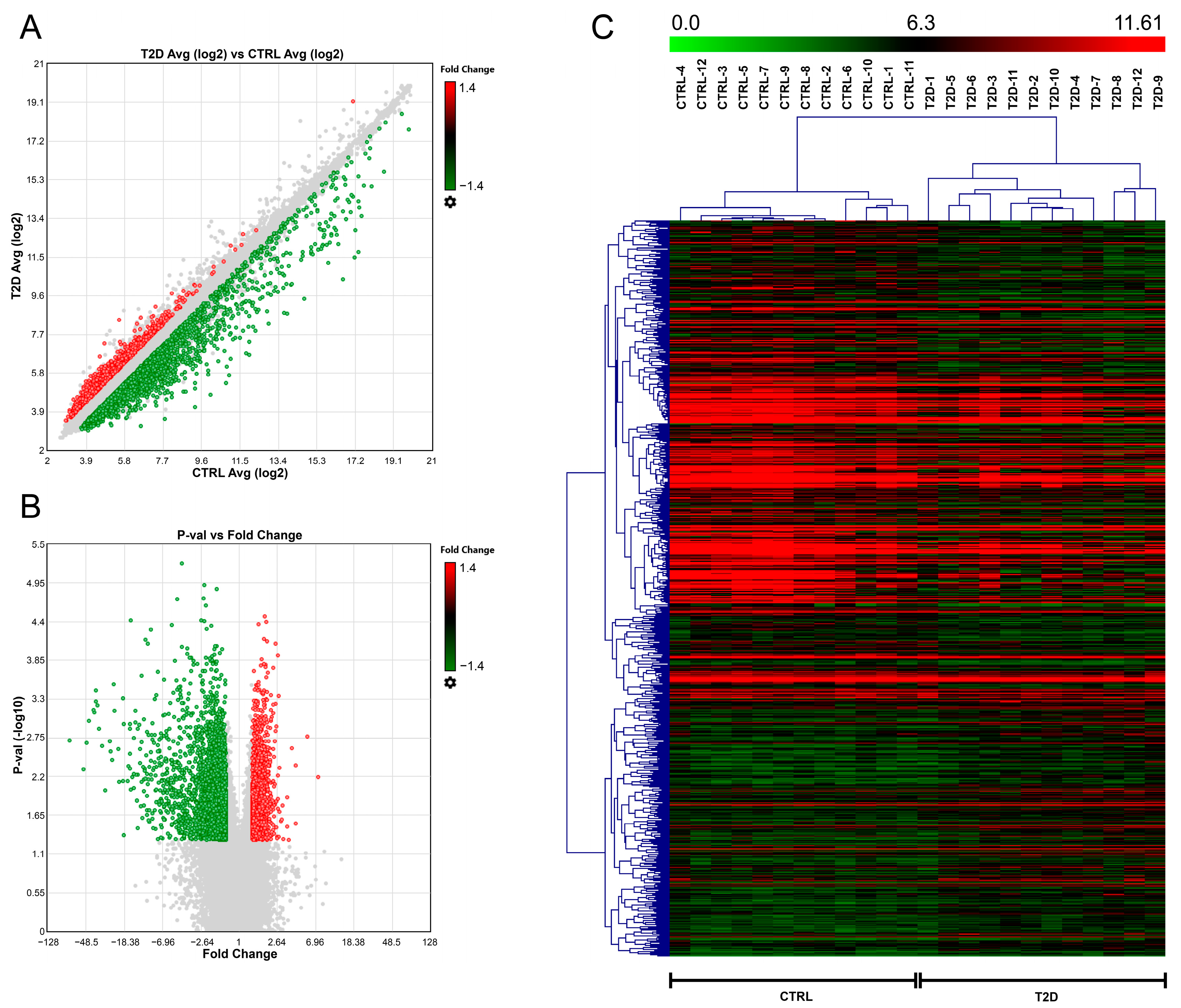
2.1. Profiling of Serum Samples from T2D Patients and CTRL Individuals
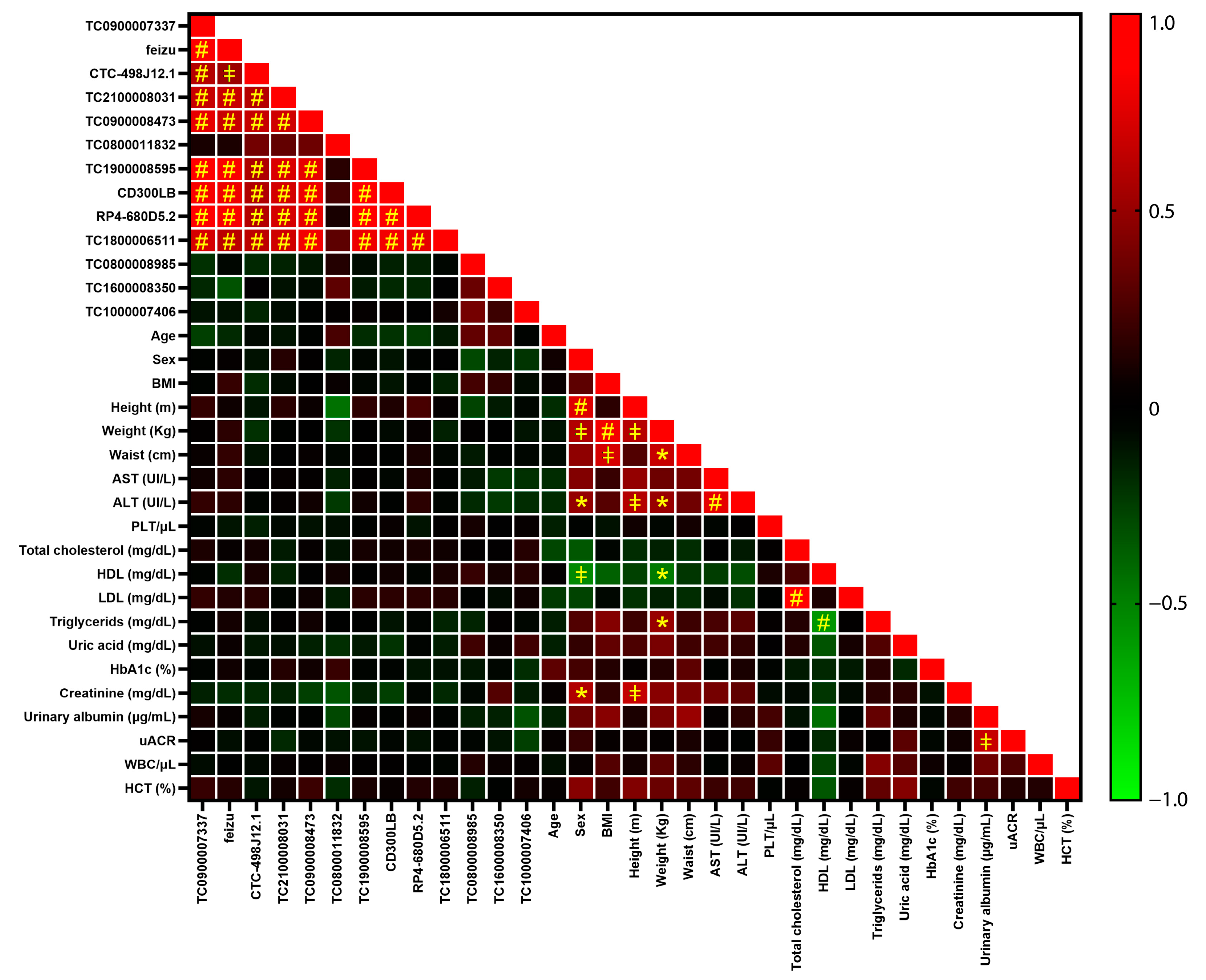
2.2. Validation of Profiling Results by Real-Time PCR Single Assays
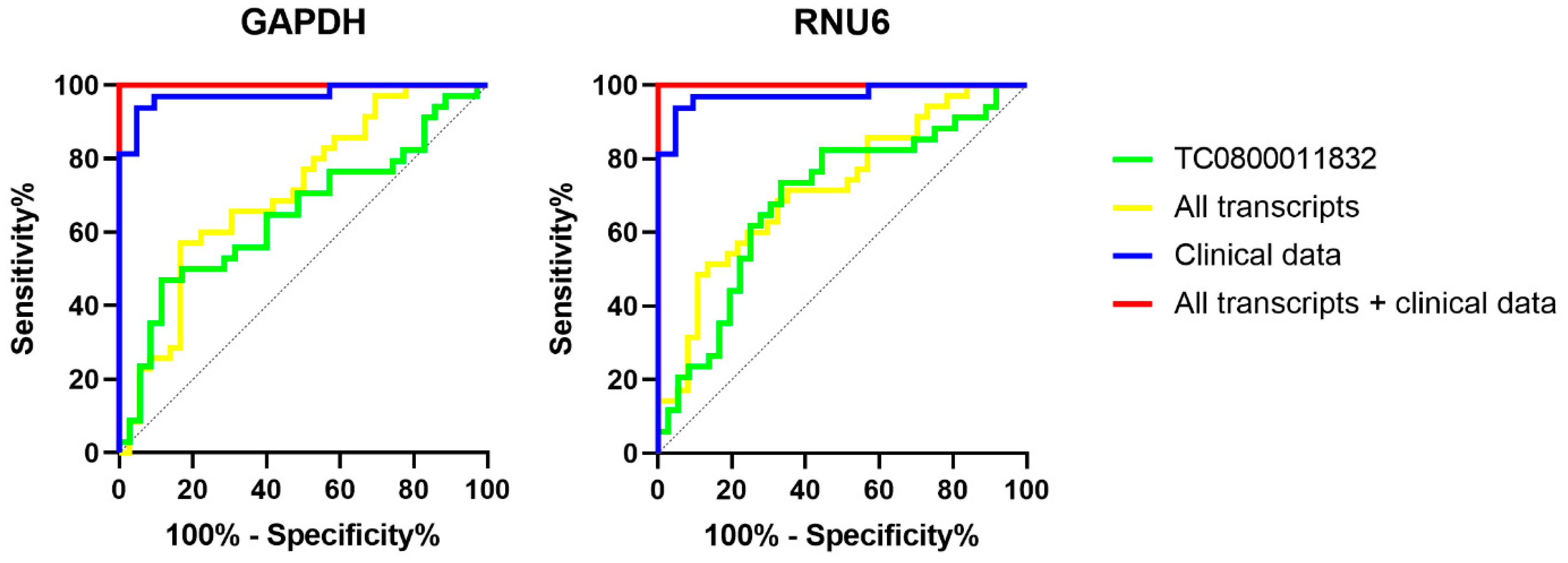
2.3. ROC Curves
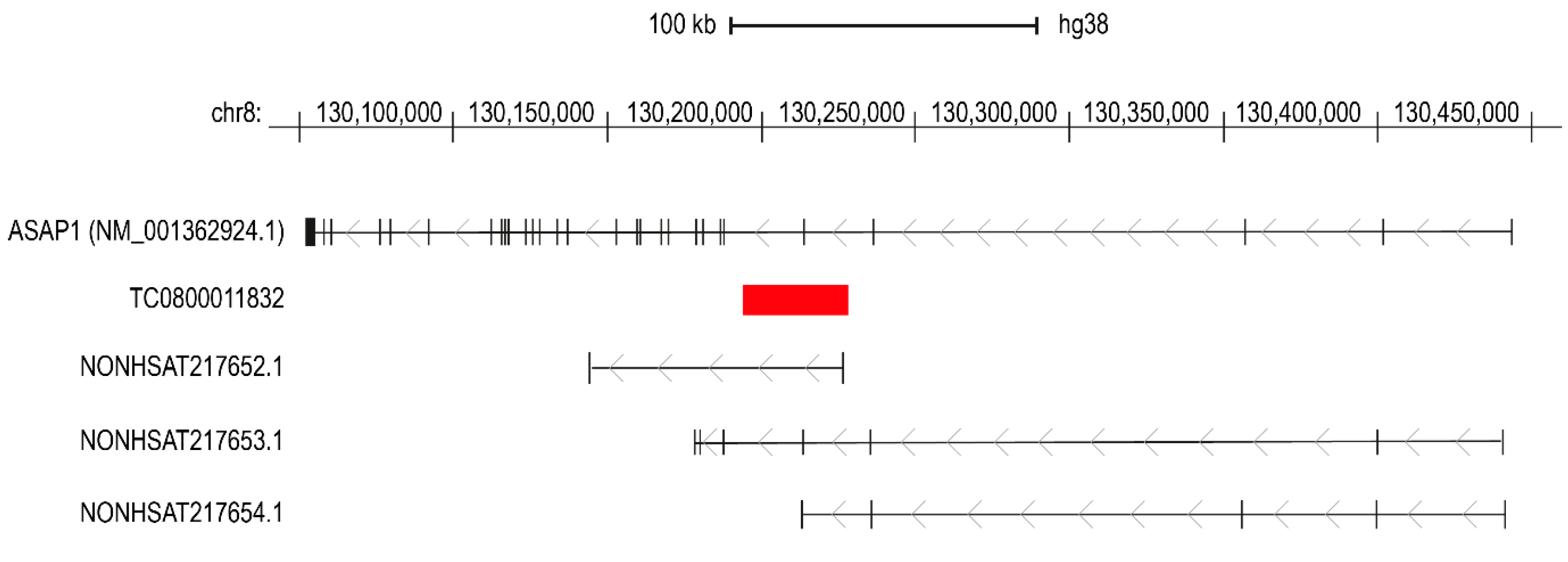
3. Discussion
4. Materials and Methods
4.1. Patient Recruitment
4.2. Serum Sample Processing
4.3. Total RNA Isolation
4.4. Microarray Analysis
4.5. Validation in Real-Time PCR
4.6. Evaluation of Diagnostic Accuracy
4.7. Statistical Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ortiz-Martinez, M.; Gonzalez-Gonzalez, M.; Martagon, A.J.; Hlavinka, V.; Willson, R.C.; Rito-Palomares, M. Recent Developments in Biomarkers for Diagnosis and Screening of Type 2 Diabetes Mellitus. Curr. Diab. Rep. 2022, 22, 95–115. [Google Scholar] [CrossRef] [PubMed]
- DeFronzo, R.A.; Ferrannini, E.; Groop, L.; Henry, R.R.; Herman, W.H.; Holst, J.J.; Hu, F.B.; Kahn, C.R.; Raz, I.; Shulman, G.I.; et al. Type 2 diabetes mellitus. Nat. Rev. Dis. Primers 2015, 1, 15019. [Google Scholar] [CrossRef] [PubMed]
- Chi, T.; Lin, J.; Wang, M.; Zhao, Y.; Liao, Z.; Wei, P. Non-Coding RNA as Biomarkers for Type 2 Diabetes Development and Clinical Management. Front. Endocrinol. 2021, 12, 630032. [Google Scholar] [CrossRef] [PubMed]
- Tomic, D.; Shaw, J.E.; Magliano, D.J. The burden and risks of emerging complications of diabetes mellitus. Nat. Rev. Endocrinol. 2022, 18, 525–539. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Yan, Y.; Guo, Z.; Hou, H.; Garcia, M.; Tan, X.; Anto, E.O.; Mahara, G.; Zheng, Y.; Li, B.; et al. All around suboptimal health—A joint position paper of the Suboptimal Health Study Consortium and European Association for Predictive, Preventive and Personalised Medicine. EPMA J. 2021, 12, 403–433. [Google Scholar] [CrossRef]
- Xu, T.; Yu, D.; Zhou, W.; Yu, L. A nomogram model for the risk prediction of type 2 diabetes in healthy eastern China residents: A 14-year retrospective cohort study from 15,166 participants. EPMA J. 2022, 13, 397–405. [Google Scholar] [CrossRef]
- Brunmair, J.; Bileck, A.; Schmidl, D.; Hagn, G.; Meier-Menches, S.M.; Hommer, N.; Schlatter, A.; Gerner, C.; Garhofer, G. Metabolic phenotyping of tear fluid as a prognostic tool for personalised medicine exemplified by T2DM patients. EPMA J. 2022, 13, 107–123. [Google Scholar] [CrossRef]
- Kropp, M.; Golubnitschaja, O.; Mazurakova, A.; Koklesova, L.; Sargheini, N.; Vo, T.K.S.; de Clerck, E.; Polivka, J., Jr.; Potuznik, P.; Polivka, J.; et al. Diabetic retinopathy as the leading cause of blindness and early predictor of cascading complications-risks and mitigation. EPMA J. 2023, 14, 21–42. [Google Scholar] [CrossRef]
- Kropp, M.; De Clerck, E.; Vo, T.K.S.; Thumann, G.; Costigliola, V.; Golubnitschaja, O. Short communication: Unique metabolic signature of proliferative retinopathy in the tear fluid of diabetic patients with comorbidities—preliminary data for PPPM validation. EPMA J. 2023, 14, 43–51. [Google Scholar] [CrossRef]
- American Diabetes, A. 2. Classification and Diagnosis of Diabetes: Standards of Medical Care in Diabetes-2020. Diabetes Care 2020, 43, S14–S31. [Google Scholar] [CrossRef]
- Stępień, E.; Costa, M.C.; Kurc, S.; Drozdz, A.; Cortez-Dias, N.; Enguita, F.J. The circulating non-coding RNA landscape for biomarker research: Lessons and prospects from cardiovascular diseases. Acta Pharmacol. Sin. 2018, 39, 1085–1099. [Google Scholar] [CrossRef]
- Shobeiri, P.; Alilou, S.; Jaberinezhad, M.; Zare, F.; Karimi, N.; Maleki, S.; Teixeira, A.L.; Perry, G.; Rezaei, N. Circulating long non-coding RNAs as novel diagnostic biomarkers for Alzheimer’s disease (AD): A systematic review and meta-analysis. PLoS ONE 2023, 18, e0281784. [Google Scholar] [CrossRef]
- Badowski, C.; He, B.; Garmire, L.X. Blood-derived lncRNAs as biomarkers for cancer diagnosis: The Good, the Bad and the Beauty. NPJ Precis. Oncol. 2022, 6, 40. [Google Scholar] [CrossRef] [PubMed]
- Filipow, S.; Laczmanski, L. Blood Circulating miRNAs as Cancer Biomarkers for Diagnosis and Surgical Treatment Response. Front. Genet. 2019, 10, 169. [Google Scholar] [CrossRef] [PubMed]
- Ren, H.; Wang, Q. Non-Coding RNA and Diabetic Kidney Disease. DNA Cell Biol. 2021, 40, 553–567. [Google Scholar] [CrossRef]
- Mori, M.A.; Ludwig, R.G.; Garcia-Martin, R.; Brandao, B.B.; Kahn, C.R. Extracellular miRNAs: From Biomarkers to Mediators of Physiology and Disease. Cell Metab. 2019, 30, 656–673. [Google Scholar] [CrossRef] [PubMed]
- Parrizas, M.; Novials, A. Circulating microRNAs as biomarkers for metabolic disease. Best Pract. Res. Clin. Endocrinol. Metab. 2016, 30, 591–601. [Google Scholar] [CrossRef] [PubMed]
- Filardi, T.; Catanzaro, G.; Mardente, S.; Zicari, A.; Santangelo, C.; Lenzi, A.; Morano, S.; Ferretti, E. Non-Coding RNA: Role in Gestational Diabetes Pathophysiology and Complications. Int. J. Mol. Sci. 2020, 21, 4020. [Google Scholar] [CrossRef]
- He, X.; Kuang, G.; Wu, Y.; Ou, C. Emerging roles of exosomal miRNAs in diabetes mellitus. Clin. Transl. Med. 2021, 11, e468. [Google Scholar] [CrossRef]
- Ji, C.; Guo, X. The clinical potential of circulating microRNAs in obesity. Nat. Rev. Endocrinol. 2019, 15, 731–743. [Google Scholar] [CrossRef]
- Pant, T.; Uche, N.; Juric, M.; Bosnjak, Z.J. Clinical Relevance of lncRNA and Mitochondrial Targeted Antioxidants as Therapeutic Options in Regulating Oxidative Stress and Mitochondrial Function in Vascular Complications of Diabetes. Antioxidants 2023, 12, 898. [Google Scholar] [CrossRef] [PubMed]
- Dinesen, S.; El-Faitarouni, A.; Dalgaard, L.T. Circulating microRNAs associated with gestational diabetes mellitus: Useful biomarkers? J. Endocrinol. 2023, 256, e220170. [Google Scholar] [CrossRef] [PubMed]
- Ruan, Y.; Lin, N.; Ma, Q.; Chen, R.; Zhang, Z.; Wen, W.; Chen, H.; Sun, J. Circulating LncRNAs Analysis in Patients with Type 2 Diabetes Reveals Novel Genes Influencing Glucose Metabolism and Islet beta-Cell Function. Cell Physiol. Biochem. 2018, 46, 335–350. [Google Scholar] [CrossRef] [PubMed]
- Crigna, A.T.; Samec, M.; Koklesova, L.; Liskova, A.; Giordano, F.A.; Kubatka, P.; Golubnitschaja, O. Cell-free nucleic acid patterns in disease prediction and monitoring-hype or hope? EPMA J. 2020, 11, 603–627. [Google Scholar] [CrossRef]
- Zhan, X.; Li, J.; Guo, Y.; Golubnitschaja, O. Mass spectrometry analysis of human tear fluid biomarkers specific for ocular and systemic diseases in the context of 3P medicine. EPMA J. 2021, 12, 449–475. [Google Scholar] [CrossRef]
- St Laurent, G.; Wahlestedt, C.; Kapranov, P. The Landscape of long noncoding RNA classification. Trends Genet. 2015, 31, 239–251. [Google Scholar] [CrossRef]
- Diaz-Arrastia, R.; Wang, K.K.; Papa, L.; Sorani, M.D.; Yue, J.K.; Puccio, A.M.; McMahon, P.J.; Inoue, T.; Yuh, E.L.; Lingsma, H.F.; et al. Acute biomarkers of traumatic brain injury: Relationship between plasma levels of ubiquitin C-terminal hydrolase-L1 and glial fibrillary acidic protein. J. Neurotrauma 2014, 31, 19–25. [Google Scholar] [CrossRef]
- Barbagallo, C.; Di Martino, M.T.; Grasso, M.; Salluzzo, M.G.; Scionti, F.; Cosentino, F.I.I.; Caruso, G.; Barbagallo, D.; Di Pietro, C.; Ferri, R.; et al. Uncharacterized RNAs in Plasma of Alzheimer’s Patients Are Associated with Cognitive Impairment and Show a Potential Diagnostic Power. Int. J. Mol. Sci. 2020, 21, 7644. [Google Scholar] [CrossRef]
- Di Mauro, S.; Scamporrino, A.; Fruciano, M.; Filippello, A.; Fagone, E.; Gili, E.; Scionti, F.; Purrazzo, G.; Di Pino, A.; Scicali, R.; et al. Circulating Coding and Long Non-Coding RNAs as Potential Biomarkers of Idiopathic Pulmonary Fibrosis. Int. J. Mol. Sci. 2020, 21, 8812. [Google Scholar] [CrossRef]
- Alexeyenko, A.; Brustugun, O.T.; Eide, I.J.Z.; Gencheva, R.; Kosibaty, Z.; Lai, Y.; de Petris, L.; Tsakonas, G.; Grundberg, O.; Franzen, B.; et al. Plasma RNA profiling unveils transcriptional signatures associated with resistance to osimertinib in EGFR T790M positive non-small cell lung cancer patients. Transl. Lung Cancer Res. 2022, 11, 2064–2078. [Google Scholar] [CrossRef]
- Wang, X.; Guo, S.; Zhou, X.; Wang, Y.; Zhang, T.; Chen, R. Exploring the Molecular Mechanism of lncRNA-miRNA-mRNA Networks in Non-Syndromic Cleft Lip with or without Cleft Palate. Int. J. Gen. Med. 2021, 14, 9931–9943. [Google Scholar] [CrossRef]
- Lv, P.; Yang, S.; Liu, W.; Qin, H.; Tang, X.; Wu, F.; Liu, Z.; Gao, H.; Liu, X. Circulating plasma lncRNAs as novel markers of EGFR mutation status and monitors of epidermal growth factor receptor-tyrosine kinase inhibitor therapy. Thorac. Cancer 2020, 11, 29–40. [Google Scholar] [CrossRef] [PubMed]
- Wen, Y.; Wang, Y.; Xing, Z.; Liu, Z.; Hou, Z. Microarray expression profile and analysis of circular RNA regulatory network in malignant pleural effusion. Cell Cycle 2018, 17, 2819–2832. [Google Scholar] [CrossRef] [PubMed]
- Chen, P.W.; Billington, N.; Maron, B.Y.; Sload, J.A.; Chinthalapudi, K.; Heissler, S.M. The BAR domain of the Arf GTPase-activating protein ASAP1 directly binds actin filaments. J. Biol. Chem. 2020, 295, 11303–11315. [Google Scholar] [CrossRef] [PubMed]
- Muller, T.; Stein, U.; Poletti, A.; Garzia, L.; Rothley, M.; Plaumann, D.; Thiele, W.; Bauer, M.; Galasso, A.; Schlag, P.; et al. ASAP1 promotes tumor cell motility and invasiveness, stimulates metastasis formation in vivo, and correlates with poor survival in colorectal cancer patients. Oncogene 2010, 29, 2393–2403. [Google Scholar] [CrossRef]
- King, F.J.; Hu, E.; Harris, D.F.; Sarraf, P.; Spiegelman, B.M.; Roberts, T.M. DEF-1, a novel Src SH3 binding protein that promotes adipogenesis in fibroblastic cell lines. Mol. Cell Biol. 1999, 19, 2330–2337. [Google Scholar] [CrossRef]
- Schreiber, C.; Saraswati, S.; Harkins, S.; Gruber, A.; Cremers, N.; Thiele, W.; Rothley, M.; Plaumann, D.; Korn, C.; Armant, O.; et al. Loss of ASAP1 in mice impairs adipogenic and osteogenic differentiation of mesenchymal progenitor cells through dysregulation of FAK/Src and AKT signaling. PLoS Genet. 2019, 15, e1008216. [Google Scholar] [CrossRef]
- Fan, Q.; Shike, T.; Shigihara, T.; Tanimoto, M.; Gohda, T.; Makita, Y.; Wang, L.N.; Horikoshi, S.; Tomino, Y. Gene expression profile in diabetic KK/Ta mice. Kidney Int. 2003, 64, 1978–1985. [Google Scholar] [CrossRef]
- Curtis, J.; Luo, Y.; Zenner, H.L.; Cuchet-Lourenco, D.; Wu, C.; Lo, K.; Maes, M.; Alisaac, A.; Stebbings, E.; Liu, J.Z.; et al. Susceptibility to tuberculosis is associated with variants in the ASAP1 gene encoding a regulator of dendritic cell migration. Nat. Genet. 2015, 47, 523–527. [Google Scholar] [CrossRef]
- Zhong, H.; Magee, M.J.; Huang, Y.; Hui, Q.; Gwinn, M.; Gandhi, N.R.; Sun, Y.V. Evaluation of the Host Genetic Effects of Tuberculosis-Associated Variants Among Patients With Type 1 and Type 2 Diabetes Mellitus. Open Forum Infect. Dis. 2020, 7, ofaa106. [Google Scholar] [CrossRef]
- Kalwat, M.A.; Thurmond, D.C. Signaling mechanisms of glucose-induced F-actin remodeling in pancreatic islet beta cells. Exp. Mol. Med. 2013, 45, e37. [Google Scholar] [CrossRef]
- Rachubik, P.; Szrejder, M.; Rogacka, D.; Typiak, M.; Audzeyenka, I.; Kasztan, M.; Pollock, D.M.; Angielski, S.; Piwkowska, A. Insulin controls cytoskeleton reorganization and filtration barrier permeability via the PKGIalpha-Rac1-RhoA crosstalk in cultured rat podocytes. Biochim. Biophys. Acta Mol. Cell Res. 2022, 1869, 119301. [Google Scholar] [CrossRef] [PubMed]
- Varela, R.; Rauschert, I.; Romanelli, G.; Alberro, A.; Benech, J.C. Hyperglycemia and hyperlipidemia can induce morphophysiological changes in rat cardiac cell line. Biochem. Biophys. Rep. 2021, 26, 100983. [Google Scholar] [CrossRef] [PubMed]
- Hien, T.T.; Turczynska, K.M.; Dahan, D.; Ekman, M.; Grossi, M.; Sjogren, J.; Nilsson, J.; Braun, T.; Boettger, T.; Garcia-Vaz, E.; et al. Elevated Glucose Levels Promote Contractile and Cytoskeletal Gene Expression in Vascular Smooth Muscle via Rho/Protein Kinase C and Actin Polymerization. J. Biol. Chem. 2016, 291, 3552–3568. [Google Scholar] [CrossRef]
- Tuck, M.K.; Chan, D.W.; Chia, D.; Godwin, A.K.; Grizzle, W.E.; Krueger, K.E.; Rom, W.; Sanda, M.; Sorbara, L.; Stass, S.; et al. Standard operating procedures for serum and plasma collection: Early detection research network consensus statement standard operating procedure integration working group. J. Proteome Res. 2009, 8, 113–117. [Google Scholar] [CrossRef]
- Kirschner, M.B.; Kao, S.C.; Edelman, J.J.; Armstrong, N.J.; Vallely, M.P.; van Zandwijk, N.; Reid, G. Haemolysis during sample preparation alters microRNA content of plasma. PLoS ONE 2011, 6, e24145. [Google Scholar] [CrossRef]
- Di Mauro, S.; Salomone, F.; Scamporrino, A.; Filippello, A.; Morisco, F.; Guido, M.; Lembo, V.; Cossiga, V.; Pipitone, R.M.; Grimaudo, S.; et al. Coffee Restores Expression of lncRNAs Involved in Steatosis and Fibrosis in a Mouse Model of NAFLD. Nutrients 2021, 13, 2952. [Google Scholar] [CrossRef] [PubMed]
- Barbagallo, C.; Mostile, G.; Baglieri, G.; Giunta, F.; Luca, A.; Raciti, L.; Zappia, M.; Purrello, M.; Ragusa, M.; Nicoletti, A. Specific Signatures of Serum miRNAs as Potential Biomarkers to Discriminate Clinically Similar Neurodegenerative and Vascular-Related Diseases. Cell Mol. Neurobiol. 2020, 40, 531–546. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TAC ID | Gene Symbol | Chromosome | FC | p-Value |
|---|---|---|---|---|
| TC0100009744 | neelybu | chr1 | −2.42 | 1.19 × 10−5 |
| TC0800008985 | chr8 | −2.62 | 3.82 × 10−5 | |
| TC0100013004 | RP4-680D5.2 | chr1 | 1.62 | 4.25 × 10−5 |
| TC1700010637 | KRT26 | chr17 | 1.87 | 6.92 × 10−5 |
| TC1600006522 | feyzu | chr16 | −1.82 | 8.84 × 10−5 |
| TC1800006511 | chr18 | −1.54 | 9.72 × 10−5 | |
| TC0900008473 | chr9 | −2 | 0.0001 | |
| TC1600008350 | chr16 | −1.76 | 0.0001 | |
| TC0800011832 | chr8 | −1.59 | 0.0002 | |
| TC0900007337 | chr9 | −1.92 | 0.0002 | |
| TC0X00007972 | chrX | −1.95 | 0.0002 | |
| TC0500010990 | CTC-498J12.1 | chr5 | −4.46 | 0.0003 |
| TC1000007406 | chr10 | −4.06 | 0.0003 | |
| TC1700011697 | CD300LB | chr17 | −1.42 | 0.0003 |
| TC2100008031 | chr21 | −1.43 | 0.0003 | |
| TC1900008595 | chr19 | −1.25 | 0.0017 |
| TAC ID | Gene Symbol | FC Profiling | GAPDH | RNU6 |
|---|---|---|---|---|
| TC0100013004 | RP4-680D5.2 | 1.62 | 1.02 (0.28) | −1.11 (0.94) |
| TC0500010990 | CTC-498J12.1 | −4.46 | 1.1 (0.65) | −1.04 (0.78) |
| TC0800008985 | −2.62 | 1.02 (0.78) | −1.10 (0.46) | |
| TC0800011832 | −1.59 | −1.49 (0.034) | −1.54 (0.006) | |
| TC0900007337 | −1.92 | 1.08 (0.46) | −1.05 (0.72) | |
| TC0900008473 | −2 | −1.33 (0.32) | −1.21 (0.13) | |
| TC1000007406 | −4.06 | −1.07 (0.35) | −1.21 (0.62) | |
| TC1600006522 | feyzu | −1.82 | 1.12 (0.21) | −1.01 (0.65) |
| TC1600008350 | −1.72 | −1.08 (0.58) | −1.22 (0.14) | |
| TC1700011697 | CD300LB | −1.42 | 1 (0.65) | −1.14 (0.61) |
| TC1800006511 | −1.54 | −1.07 (0.76) | −1.21 (0.55) | |
| TC1900008595 | −1.25 | 1.00 (0.25) | −1.18 (0.66) | |
| TC2100008031 | −1.43 | −1.07 (0.39) | −1.26 (0.13) |
| Variables | TC0800011832 | Clinical Data | TC0800011832 + Clinical Data | All Transcripts | All Transcripts + Clinical Data | ||||
|---|---|---|---|---|---|---|---|---|---|
| Endogenous control | GAPDH | RNU6 | / | GAPDH | RNU6 | GAPDH | RNU6 | GAPDH | RNU6 |
| AUC | 0.649 | 0.692 | 0.973 | 0.972 | 0.975 | 0.71 | 0.723 | 1 | 1 |
| Std error | 0.067 | 0.065 | 0.02 | 0.021 | 0.02 | 0.062 | 0.06 | 0 | 0 |
| p-value | 0.034 | 0.006 | 7.34 × 10−9 | 1.34 × 10−8 | 6.59 × 10−9 | 0.002 | 0.001 | 1.75 × 10−9 | 9.95 × 10−10 |
| 95% CI min | 0.517 | 0.565 | 0.933 | 0.93 | 0.936 | 0.59 | 0.605 | 1 | 1 |
| 95% CI max | 0.781 | 0.819 | 1 | 1 | 1 | 0.831 | 0.84 | 1 | 1 |
| Cut-off | 4.588 | 2.116 | / | / | / | / | / | / | / |
| Accuracy | 0.68 | 0.7 | 0.94 | 0.94 | 0.94 | 0.66 | 0.65 | 1 | 1 |
| Sensitivity | 47.06 | 73.53 | 0.94 | 0.94 | 0.94 | 0.60 | 0.6 | 1 | 1 |
| Specificity | 88.57 | 66.67 | 0.95 | 0.95 | 0.95 | 0.72 | 0.7 | 1 | 1 |
| PPV | 0.8 | 0.68 | 0.97 | 0.97 | 0.97 | 0.68 | 0.66 | 1 | 1 |
| NPV | 0.63 | 0.73 | 0.91 | 0.9 | 0.91 | 0.65 | 0.65 | 1 | 1 |
| Parameter | T2D | CTRL |
|---|---|---|
| Age | 59.3 ± 8.3 | 55.8 ± 9.4 |
| Sex (M:F) | 31:16 | 27:22 |
| BMI | 28.1 ± 5.5 | 27.6 ± 5.1 |
| Height (m) | 1.66 ± 0.09 | 1.68 ± 0.09 |
| Weight (kg) | 77.5 ± 16.8 | 77.7 ± 17.9 |
| Waist (cm) | 99.3 ± 14.3 | 89 ± 21.7 |
| AST (IU/L) | 27.2 ± 11.5 | 28.4 ± 10.4 |
| ALT (IU/L) | 34 ± 25.2 | 30.4 ± 17.9 |
| PLT/μL | 227,131.9 ± 73,568 | 234,042.6 ± 52,032.4 |
| Total cholesterol (mg/dL) | 179.2 ± 34.5 | 197.5 ± 29.3 |
| HDL (mg/dL) | 52.8 ± 11.1 | 55.3 ± 14.1 |
| LDL (mg/dL) | 100.7 ± 29.9 | 116.3 ± 34.2 |
| Triglycerides (mg/dL) | 128.3 ± 68.8 | 123 ± 88 |
| Uric acid (mg/dL) | 5 ± 1.2 | 5.1 ± 1.8 |
| HbA1c (%) | 7.2 ± 1.1 | 5.6 ± 0.3 |
| Creatinine (mg/dL) | 0.7 ± 0.1 | 0.8 ± 0.1 |
| Urinary albumin (mg/mL) | 16.1 ± 18 | 15 ± 13.1 |
| uACR | 15.4 ± 18.3 | 17.1 ± 14.9 |
| WBC/μL | 7330 ± 2323.4 | 6522.9 ± 1931.5 |
| HCT (%) | 43.2 ± 6 | 43.5 ± 3.5 |
| Transcript | Forward Primer | Reverse Primer |
|---|---|---|
| CD300LB | CAACAGCAAGCTCACCTACCA | GTAGGGGCAGGAGAAAGAACC |
| CTC-498J12.1 | GCACTATTGATTCCTGCCCCA | CCTGGCCCCAACAAACTACA |
| feyzu | CCCGAGCTGGCTGAGACATA | TCATCAACACGCACCTCTGC |
| GAPDH | TGCACCACCAACTGCTTAGC | GGCATGGACTGTGGTCATGAG |
| KRT26 | GCCAGAAATGAGCTGACCGAAT | TCAGTCTCAGCCAAGGAGCATT |
| neelybu | CAACCTAGTCCCGTTGAACACA | ACACCAGAGGCTGGGTATTGA |
| RNU6 | CTCGCTTCGGCAGCACA | AACGCTTCACGAATTTGCGT |
| RP4-680D5.2 | GCAAGAAAGTGGGGGCTGAG | CTGCCCGGTAATGCTTCCTG |
| TC0800008985 | CTGCATGGGGGCAGTAAGTG | CTGTTCCACCCCTCCAGACT |
| TC0800011832 | TCCACACTGCTGAAAAATCTGGT | CCAAGGATTGAGGGGGAAGGA |
| TC0900007337 | TGTAGCATCACCTGGGAGGG | GGTGTGGTGTTTTGTGCAGC |
| TC0900008473 | AAGCCTCCTACCCTGCCAAT | TCCAGGTGAGGTGACTTGCT |
| TC0X00007972 | TGTCCCCACATCACTCACTGG | GGCAGGTCACAATGGGGTATTC |
| TC1000007406 | ACGAATAGCCCCATCAGGGA | AGAGCACATTGCACGCAGG |
| TC1100010184 | AAAGGTGCCAAAGAAAAGGCAG | TGAAAGCCAGAAAATAGCCACCT |
| TC1600008350 | GTAAGGGCTTCAGGCTGCTTC | GCAAACCCCAACTCCGCTT |
| TC1800006511 | CACCCACATTCCATACAGCCTT | GCAGGGCACCATGAGAAGTAA |
| TC1900008595 | GCAGAAAGGCTTGTGGCTTCA | TCTTCACACTGCTCTCCCTTACG |
| TC2100008031 | TCCCTAACGCACCTCTTGCT | TGAGGAAACTGAGGGCACCA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barbagallo, C.; Stella, M.; Di Mauro, S.; Scamporrino, A.; Filippello, A.; Scionti, F.; Di Martino, M.T.; Purrello, M.; Ragusa, M.; Purrello, F.; et al. An Uncharacterised lncRNA Coded by the ASAP1 Locus Is Downregulated in Serum of Type 2 Diabetes Mellitus Patients. Int. J. Mol. Sci. 2023, 24, 13485. https://doi.org/10.3390/ijms241713485
Barbagallo C, Stella M, Di Mauro S, Scamporrino A, Filippello A, Scionti F, Di Martino MT, Purrello M, Ragusa M, Purrello F, et al. An Uncharacterised lncRNA Coded by the ASAP1 Locus Is Downregulated in Serum of Type 2 Diabetes Mellitus Patients. International Journal of Molecular Sciences. 2023; 24(17):13485. https://doi.org/10.3390/ijms241713485
Chicago/Turabian StyleBarbagallo, Cristina, Michele Stella, Stefania Di Mauro, Alessandra Scamporrino, Agnese Filippello, Francesca Scionti, Maria Teresa Di Martino, Michele Purrello, Marco Ragusa, Francesco Purrello, and et al. 2023. "An Uncharacterised lncRNA Coded by the ASAP1 Locus Is Downregulated in Serum of Type 2 Diabetes Mellitus Patients" International Journal of Molecular Sciences 24, no. 17: 13485. https://doi.org/10.3390/ijms241713485