
Energy Level Prediction of Organic Semiconductors for Photodetectors and Mining of a Photovoltaic Database to Search for New Building Units
 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Results and Discussions
2.1. Molecular Descriptors
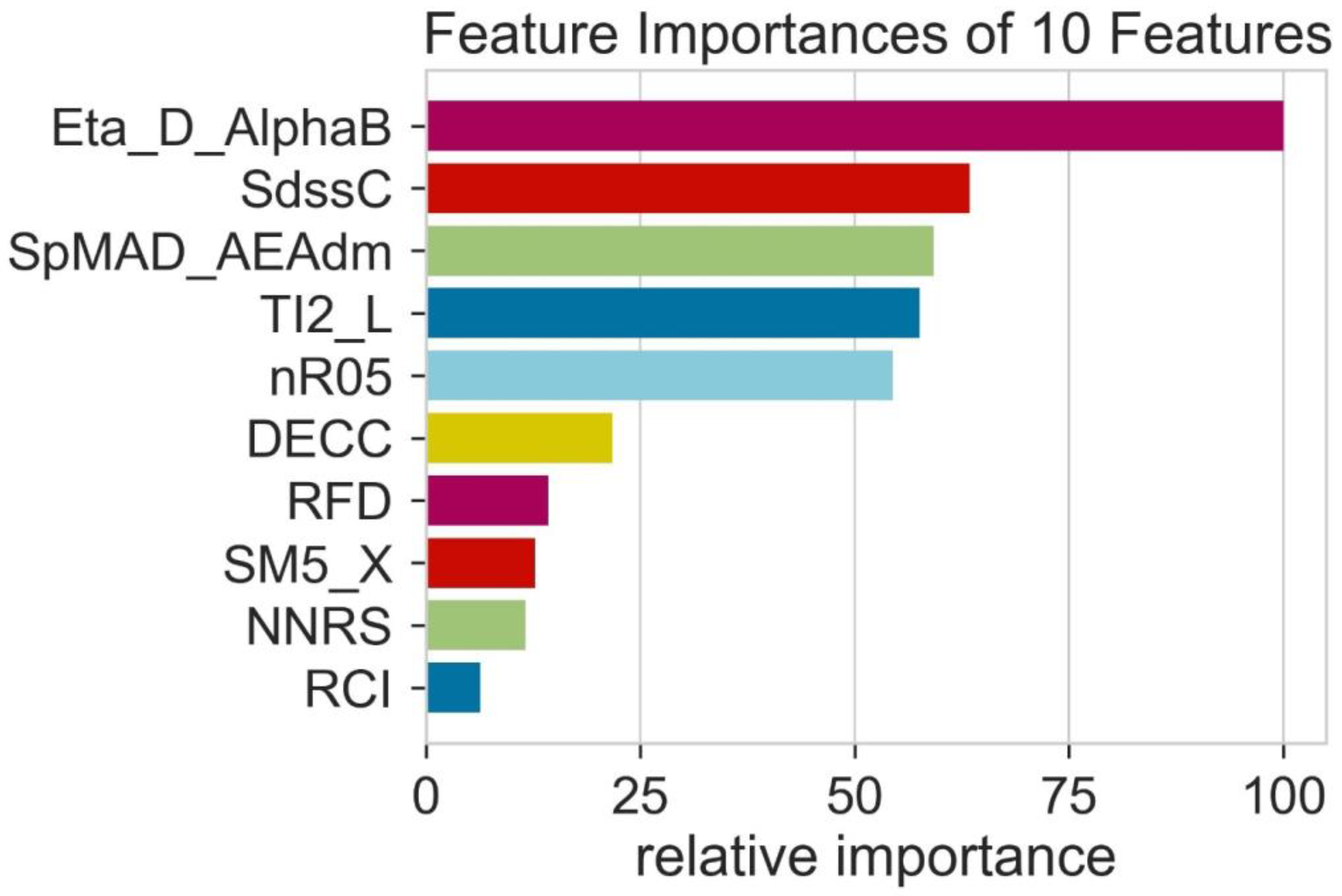
2.2. Regression Analysis
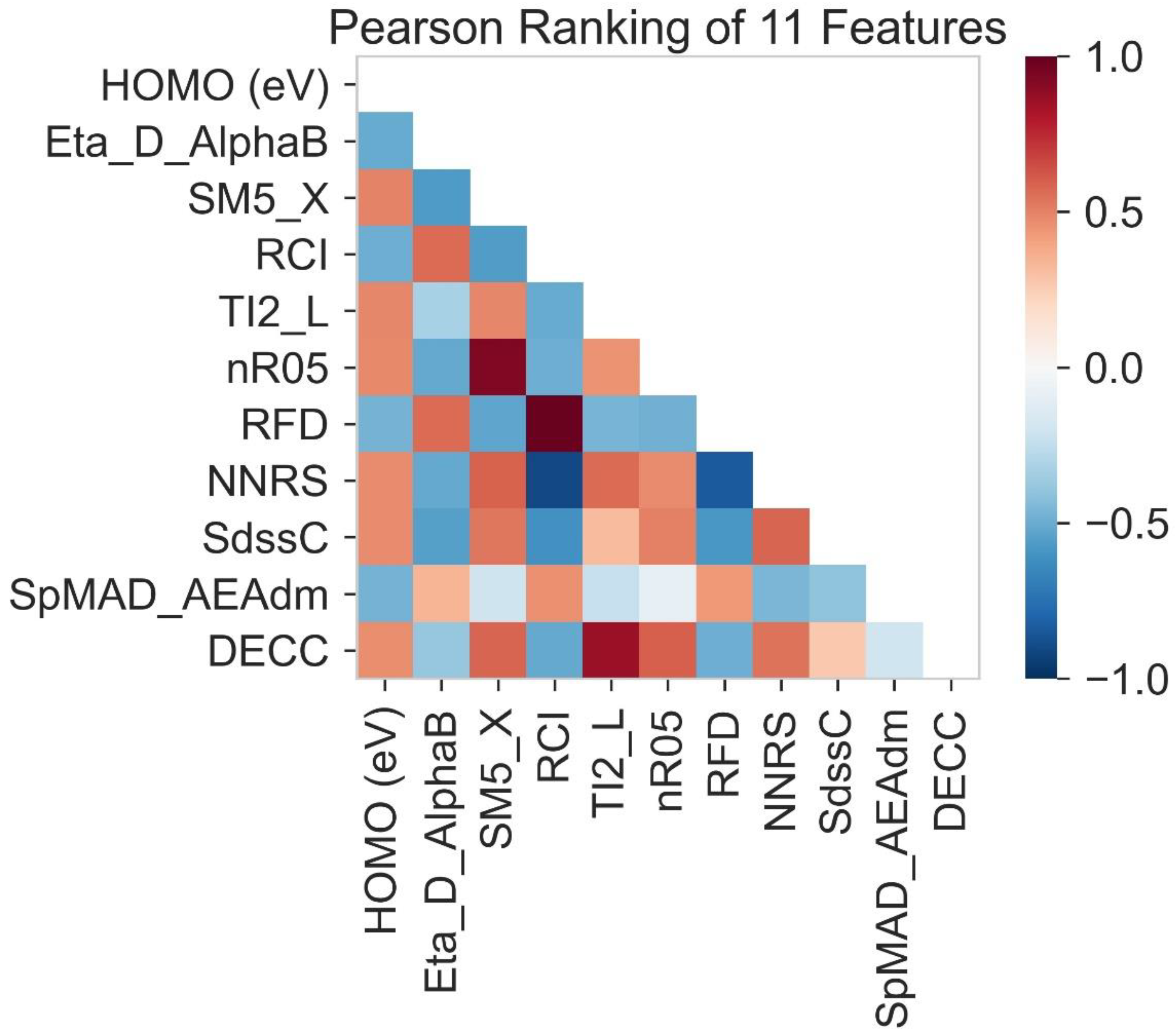
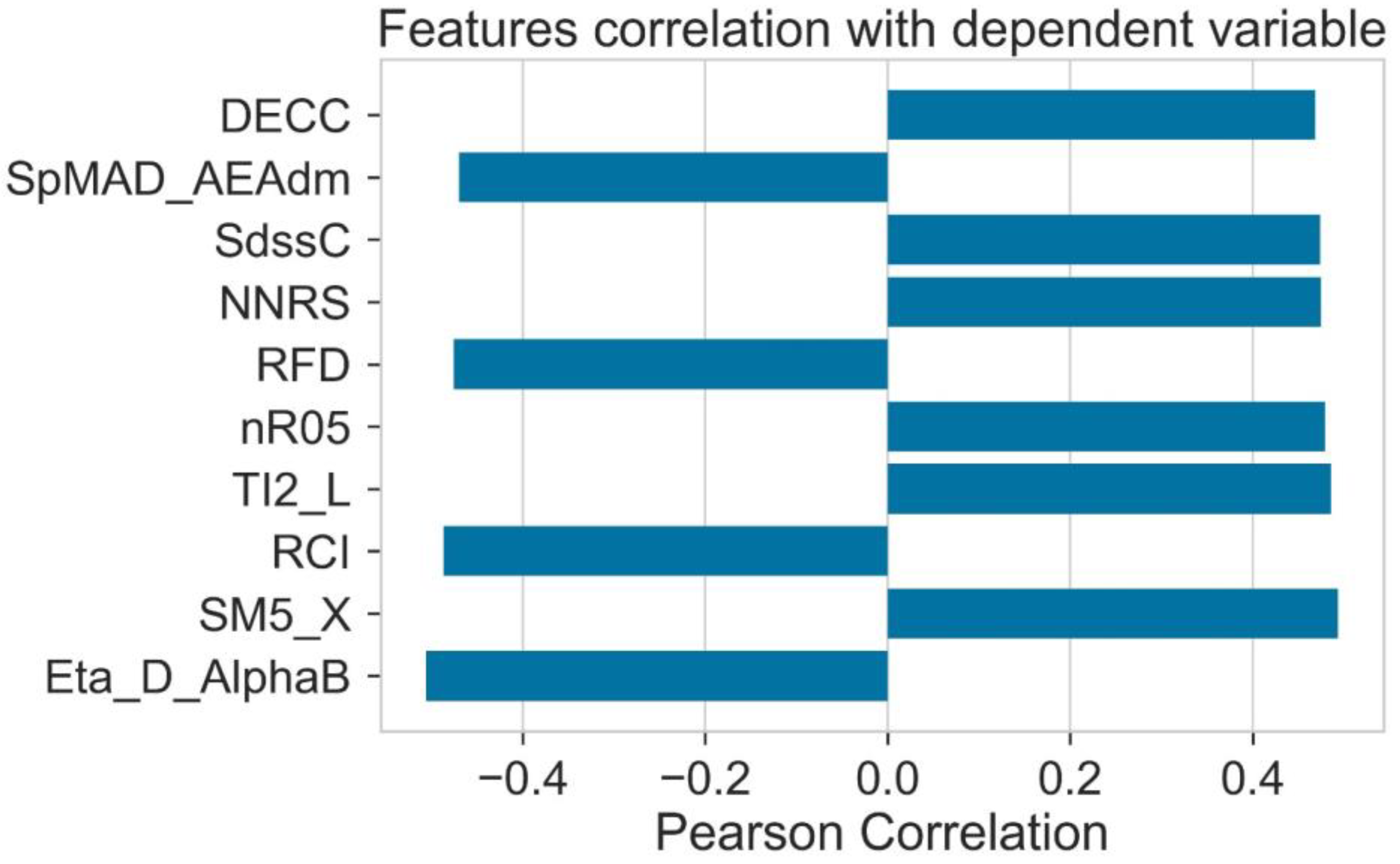
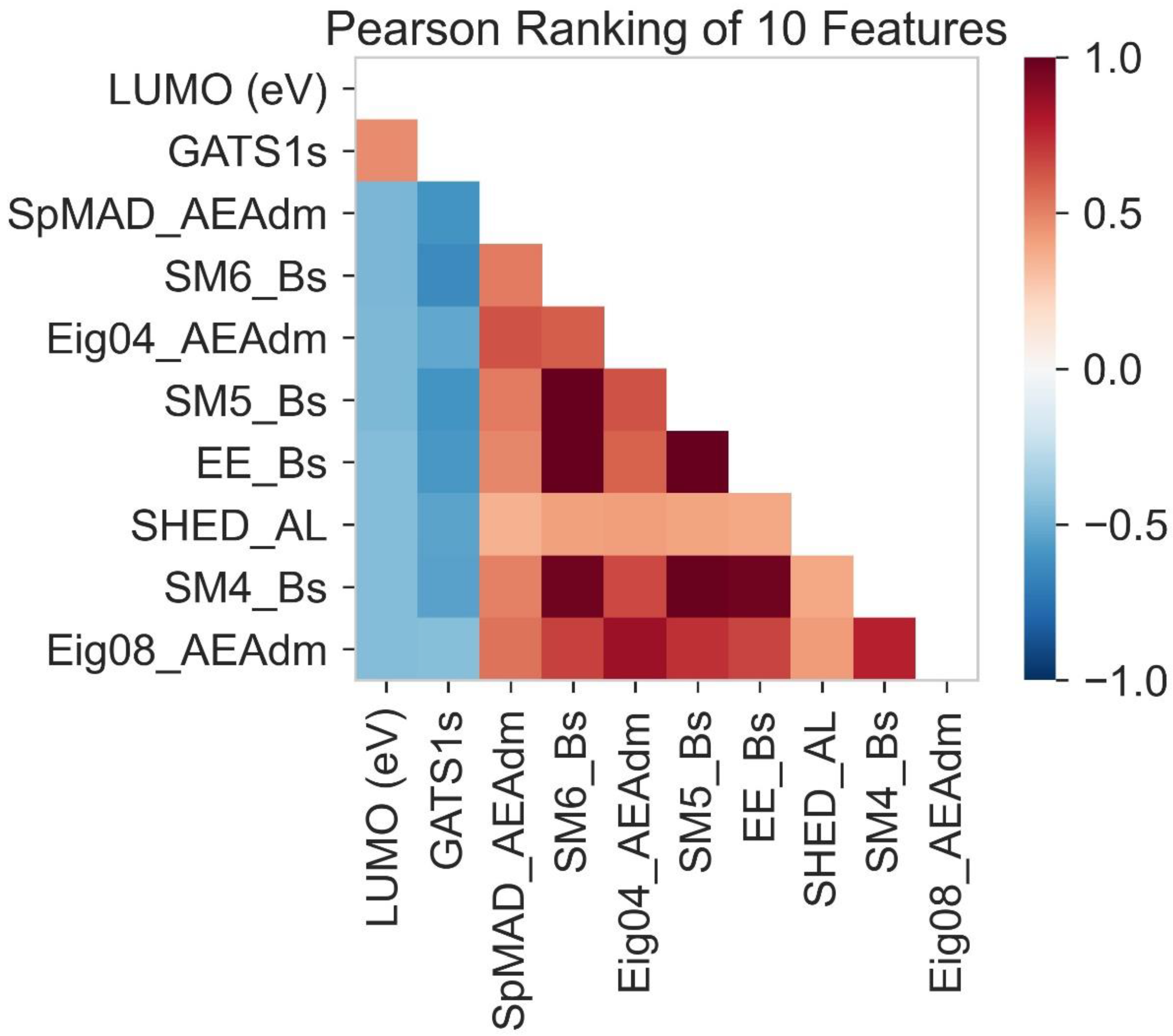
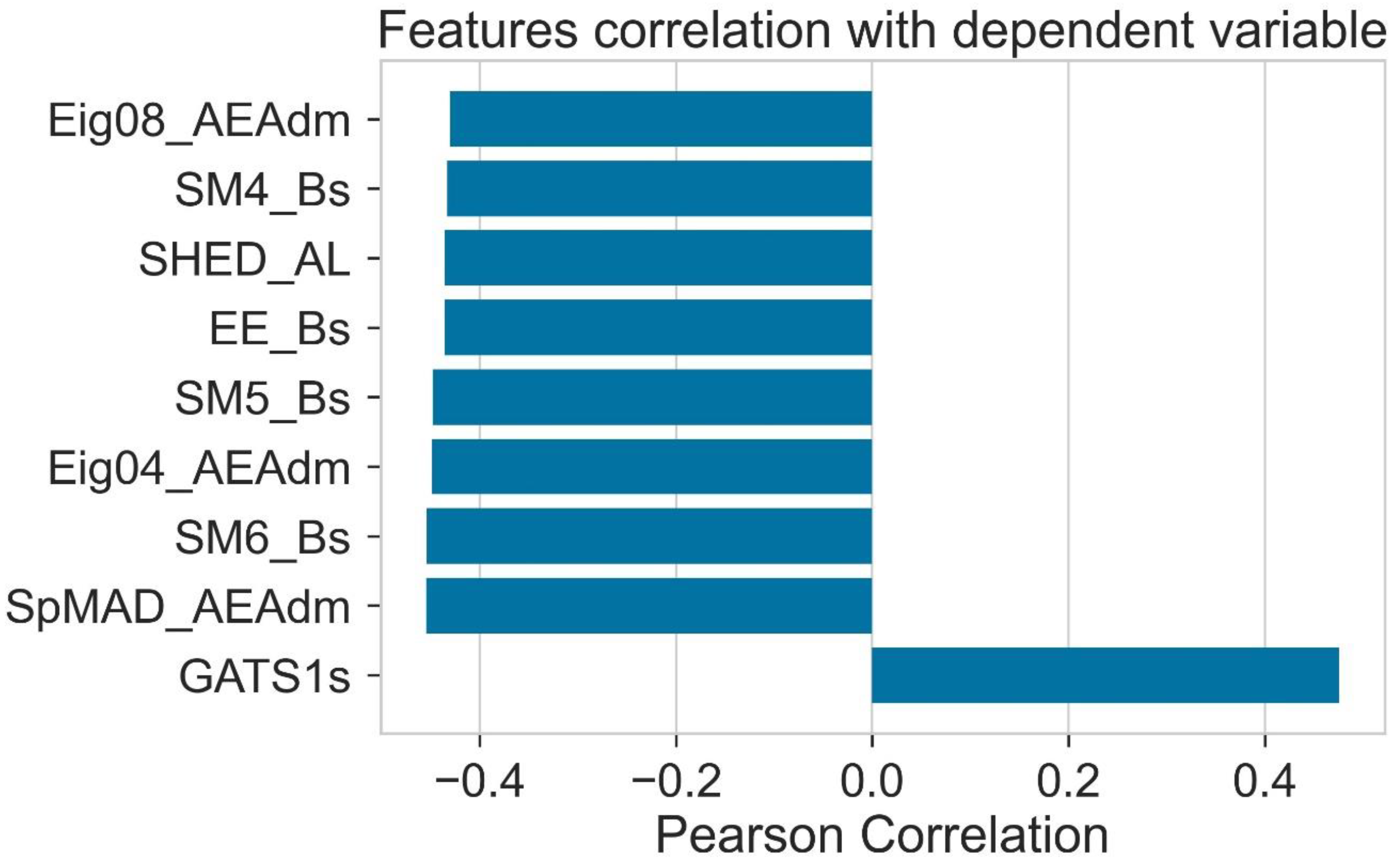
2.3. Pearson Ranking Correlation
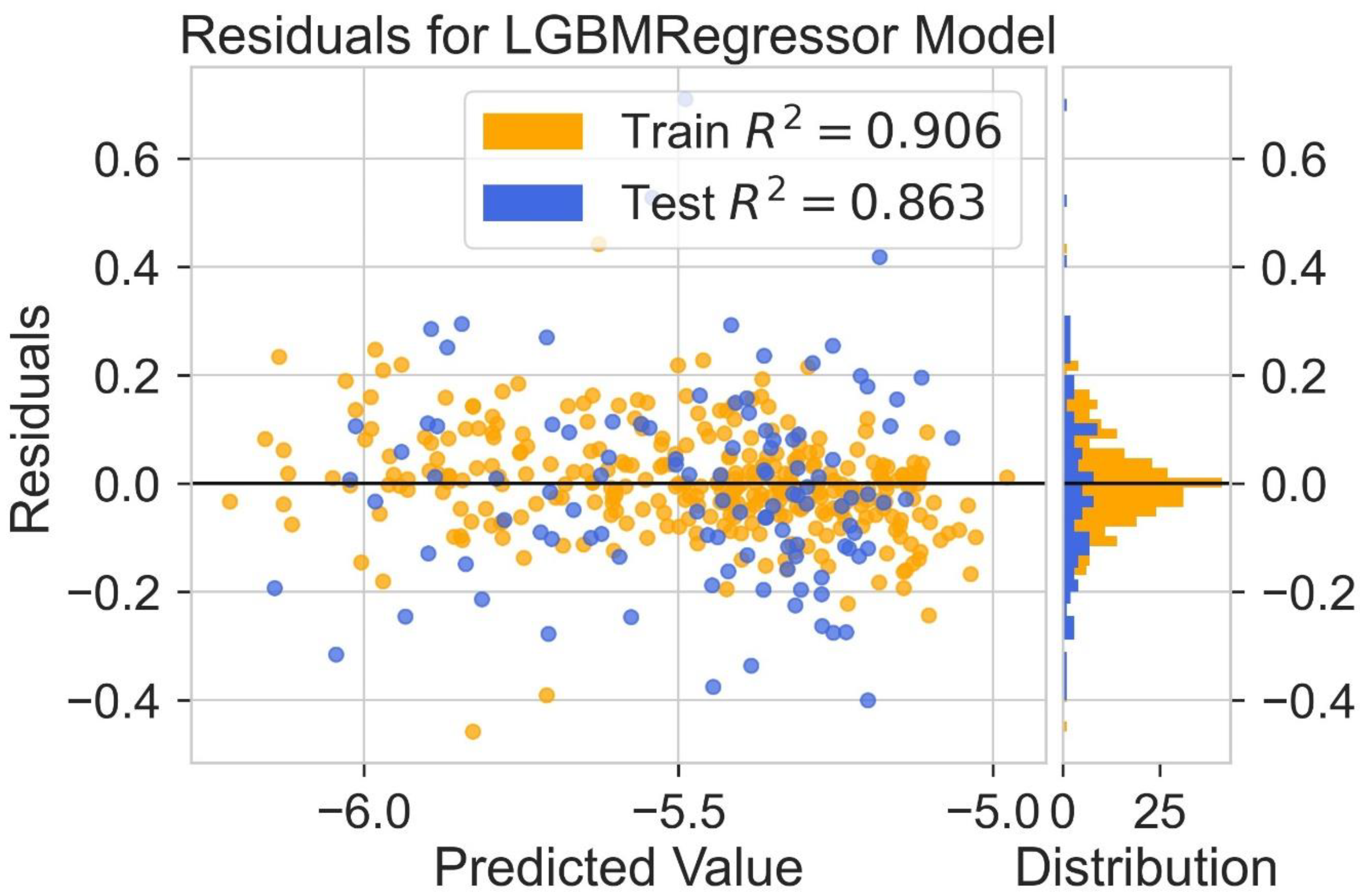
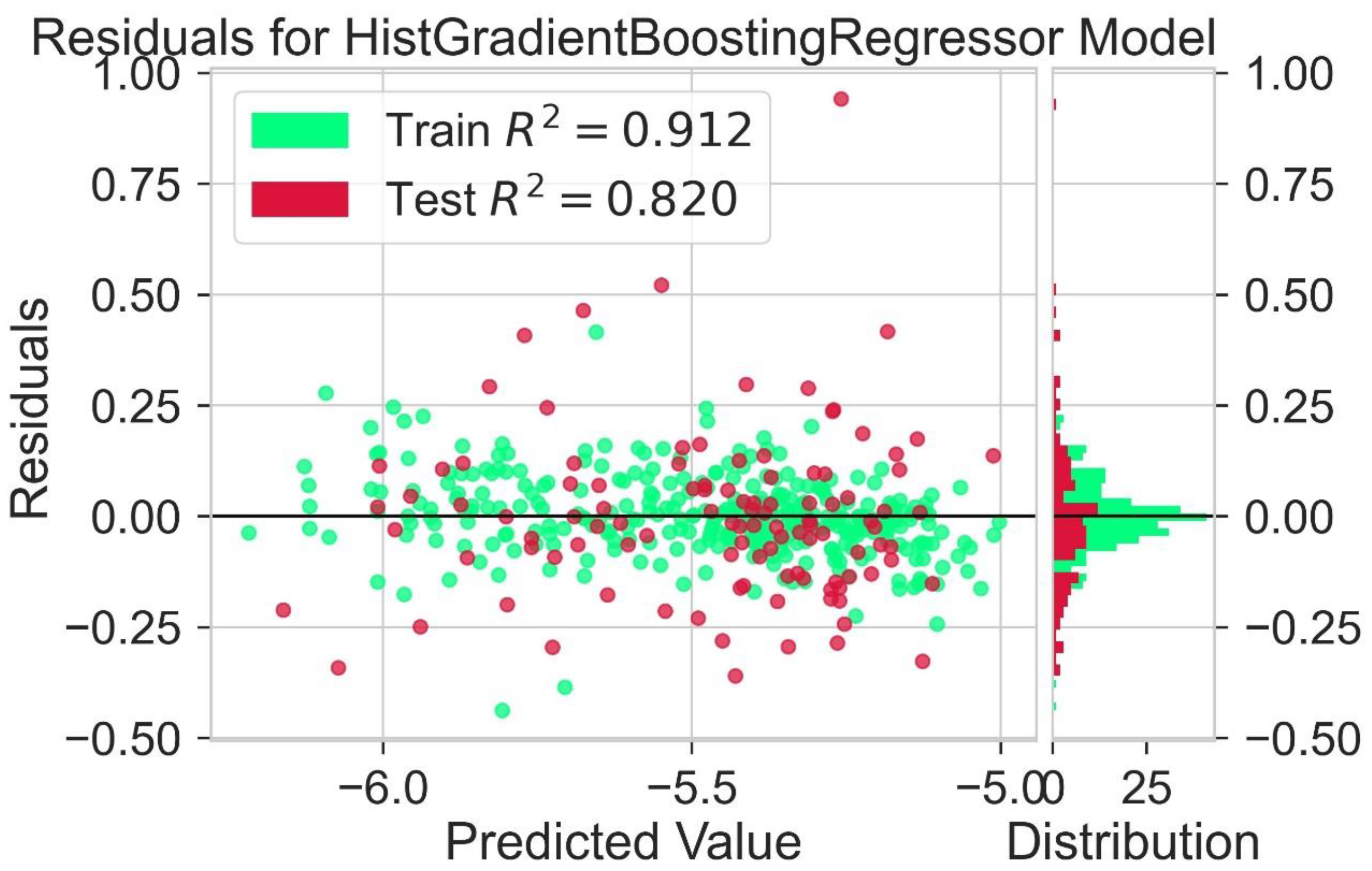
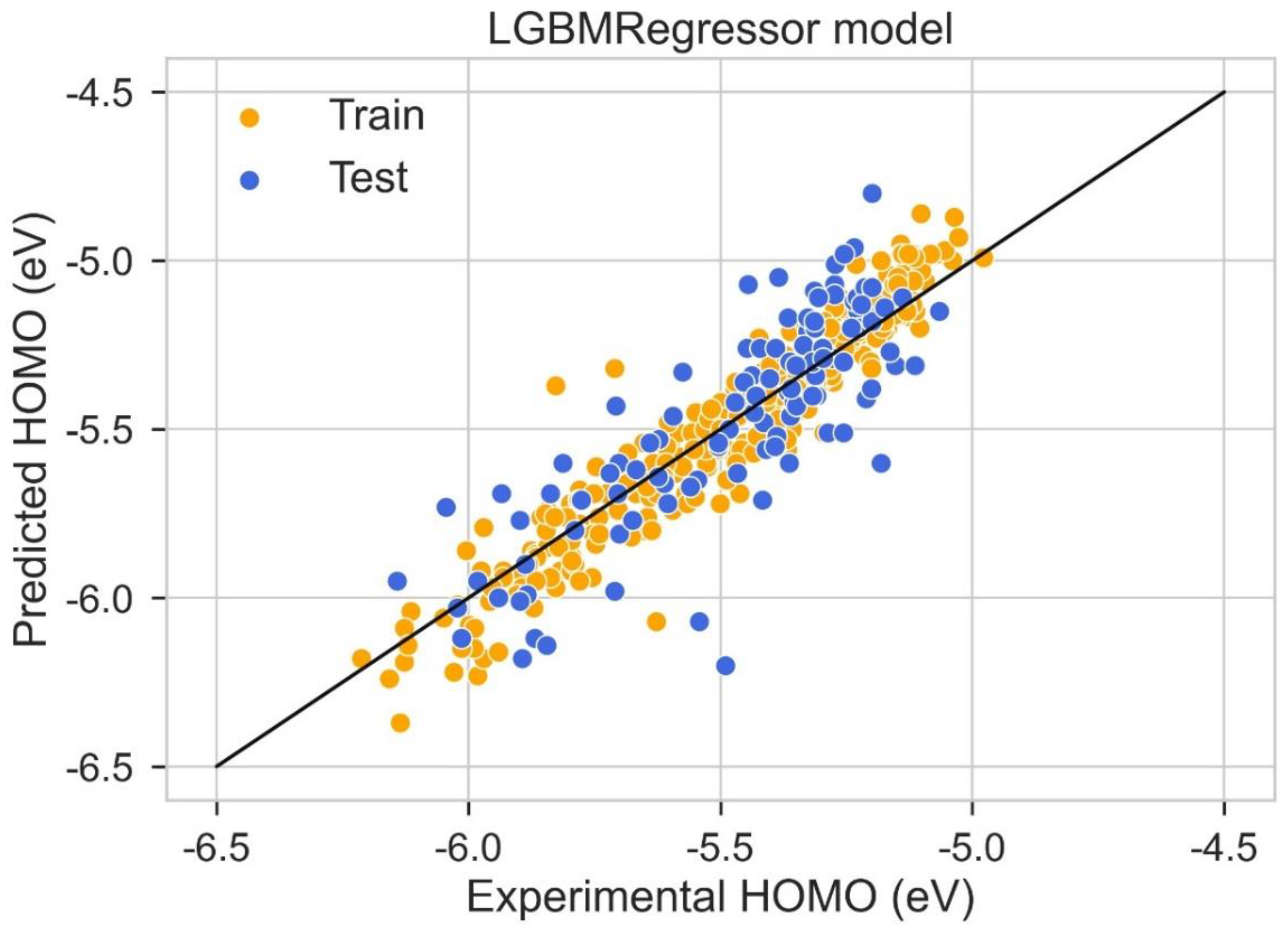
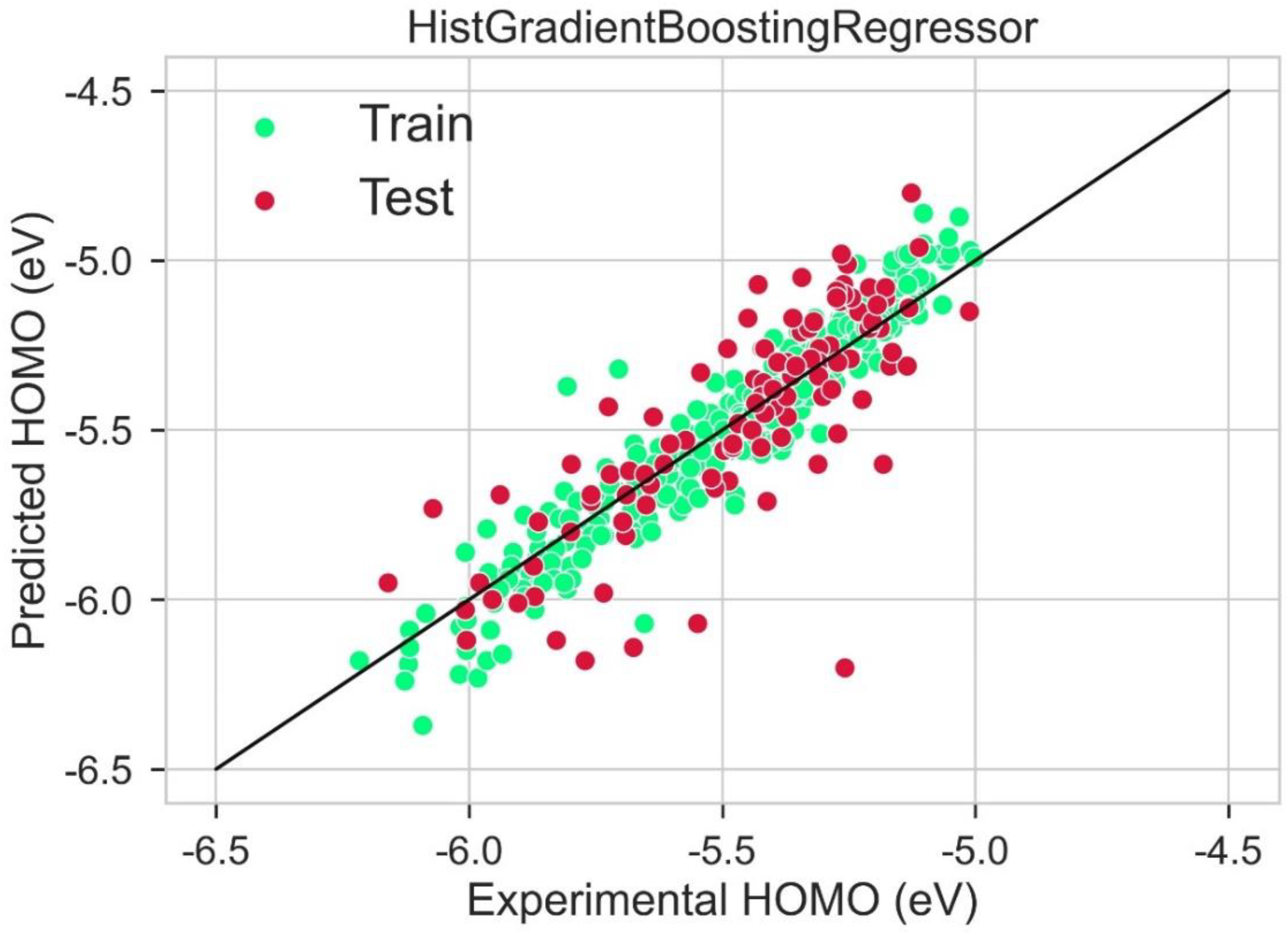
2.4. HOMO Prediction
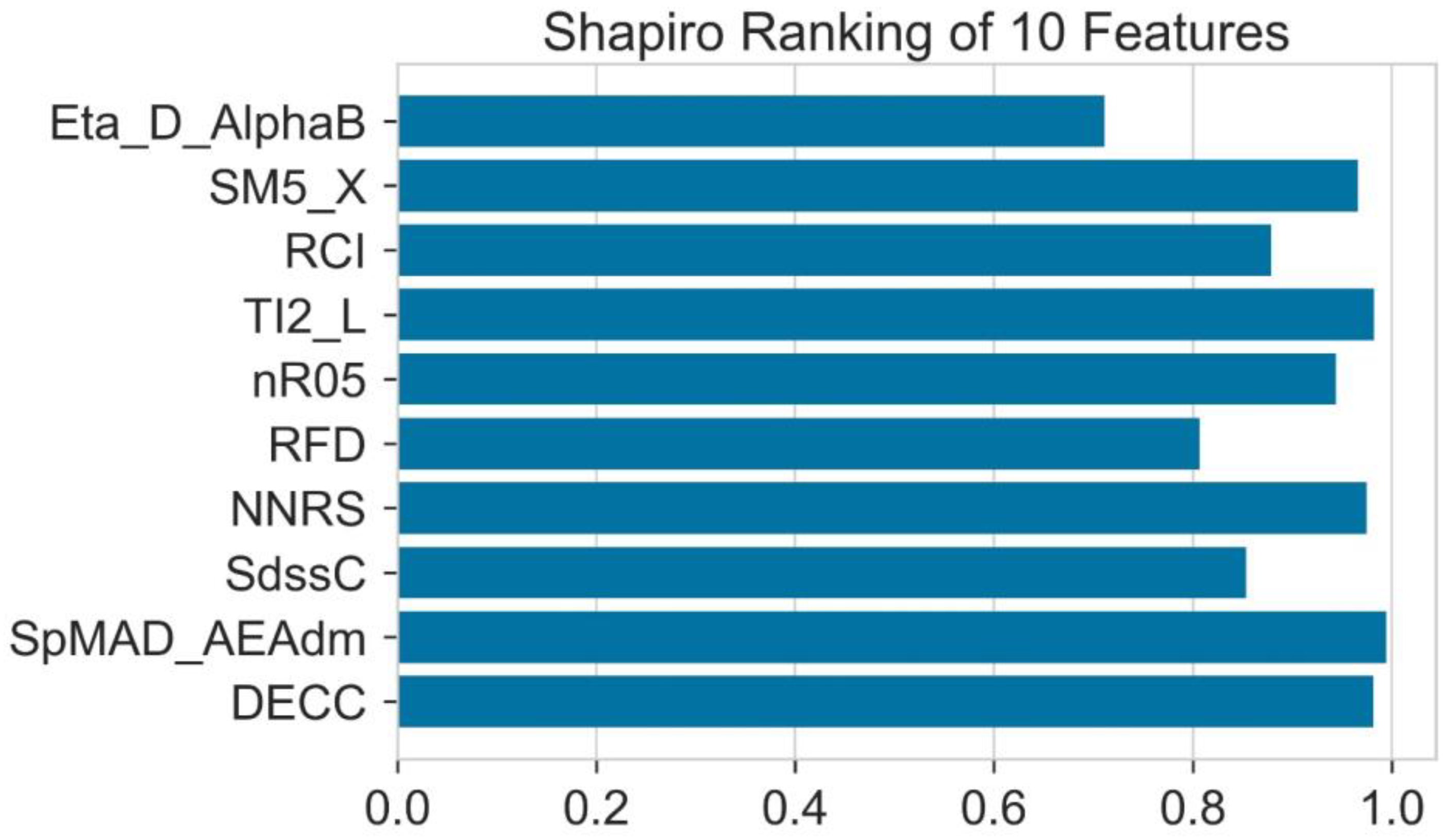
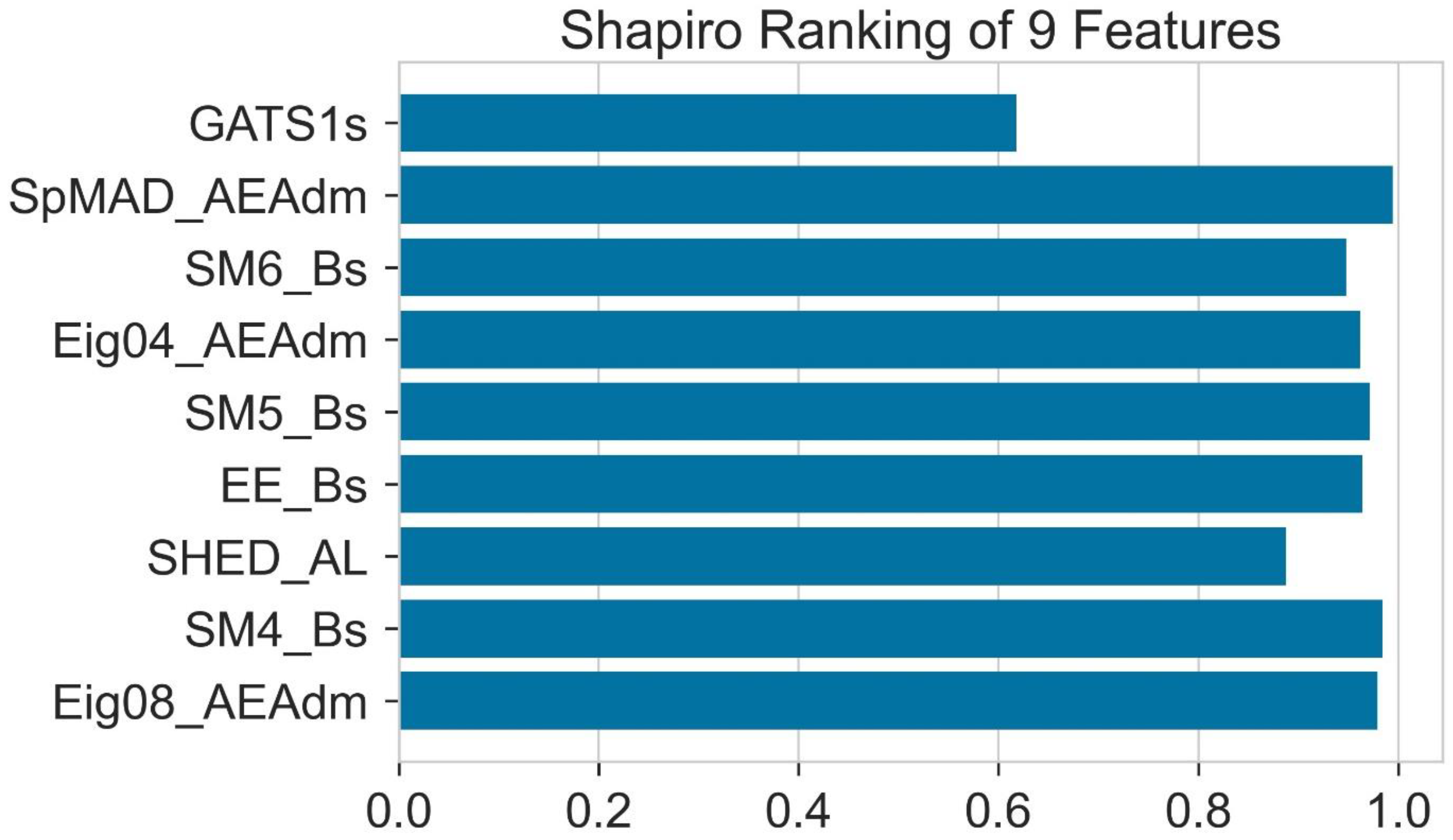
2.5. Shapiro Ranking
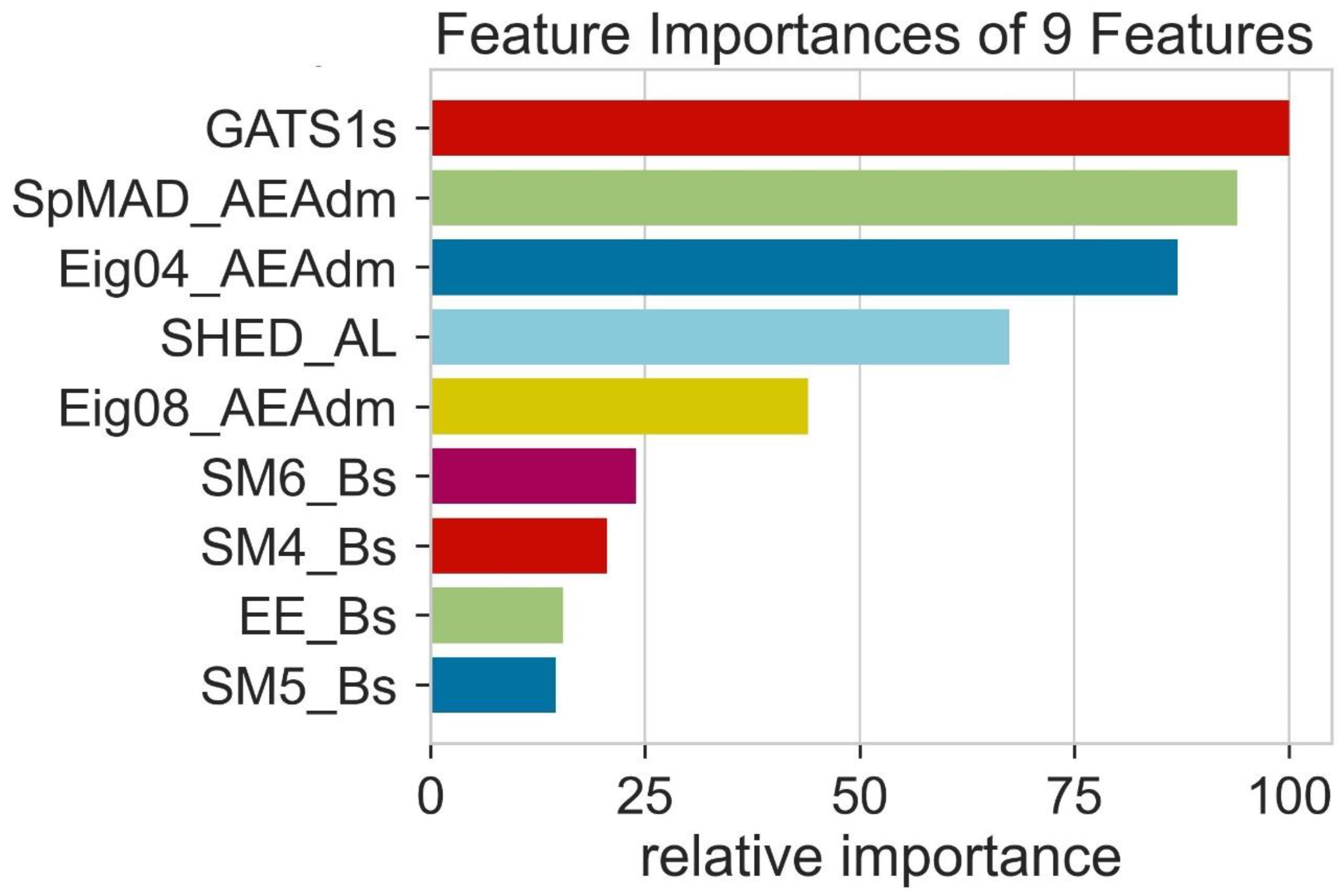
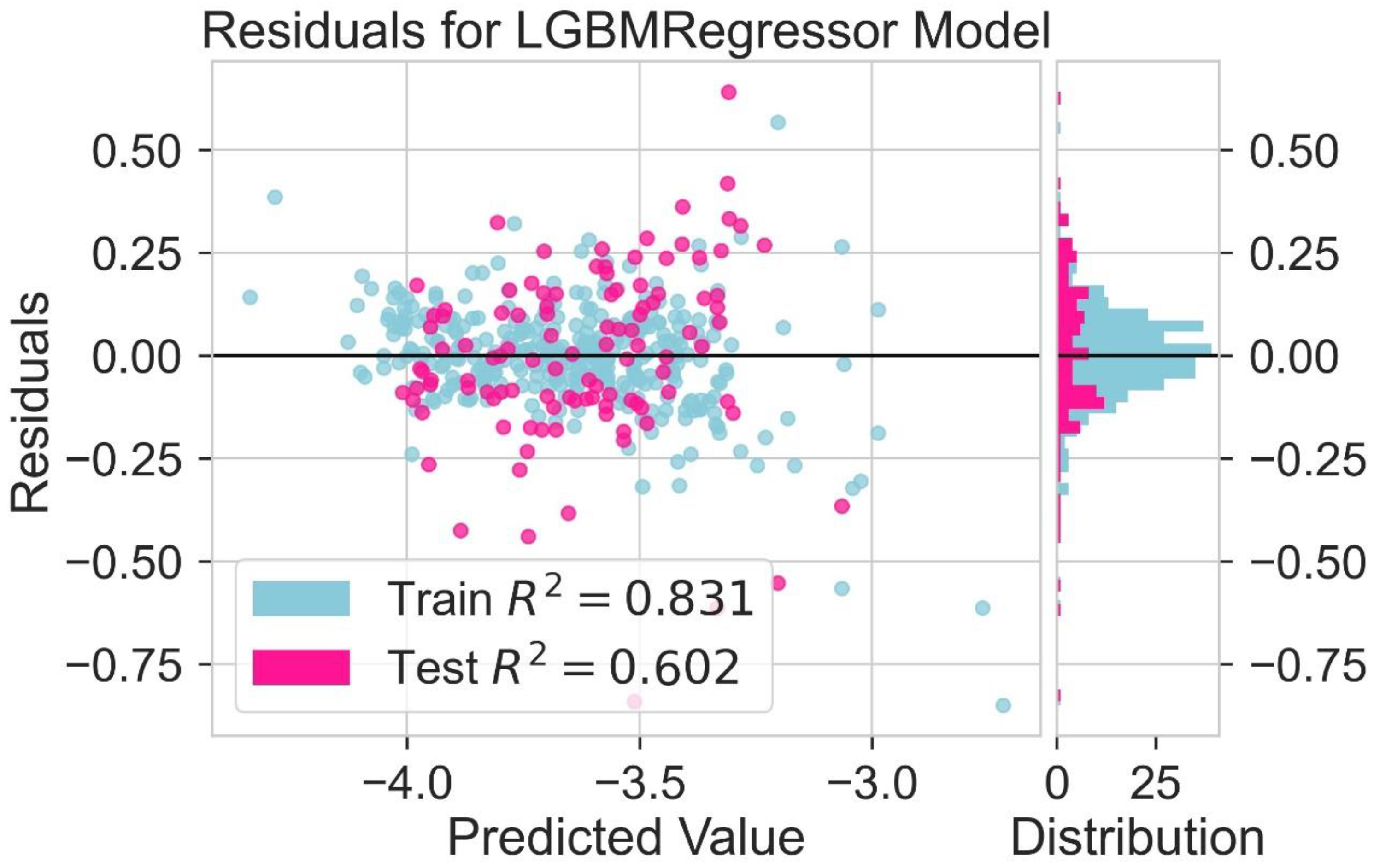
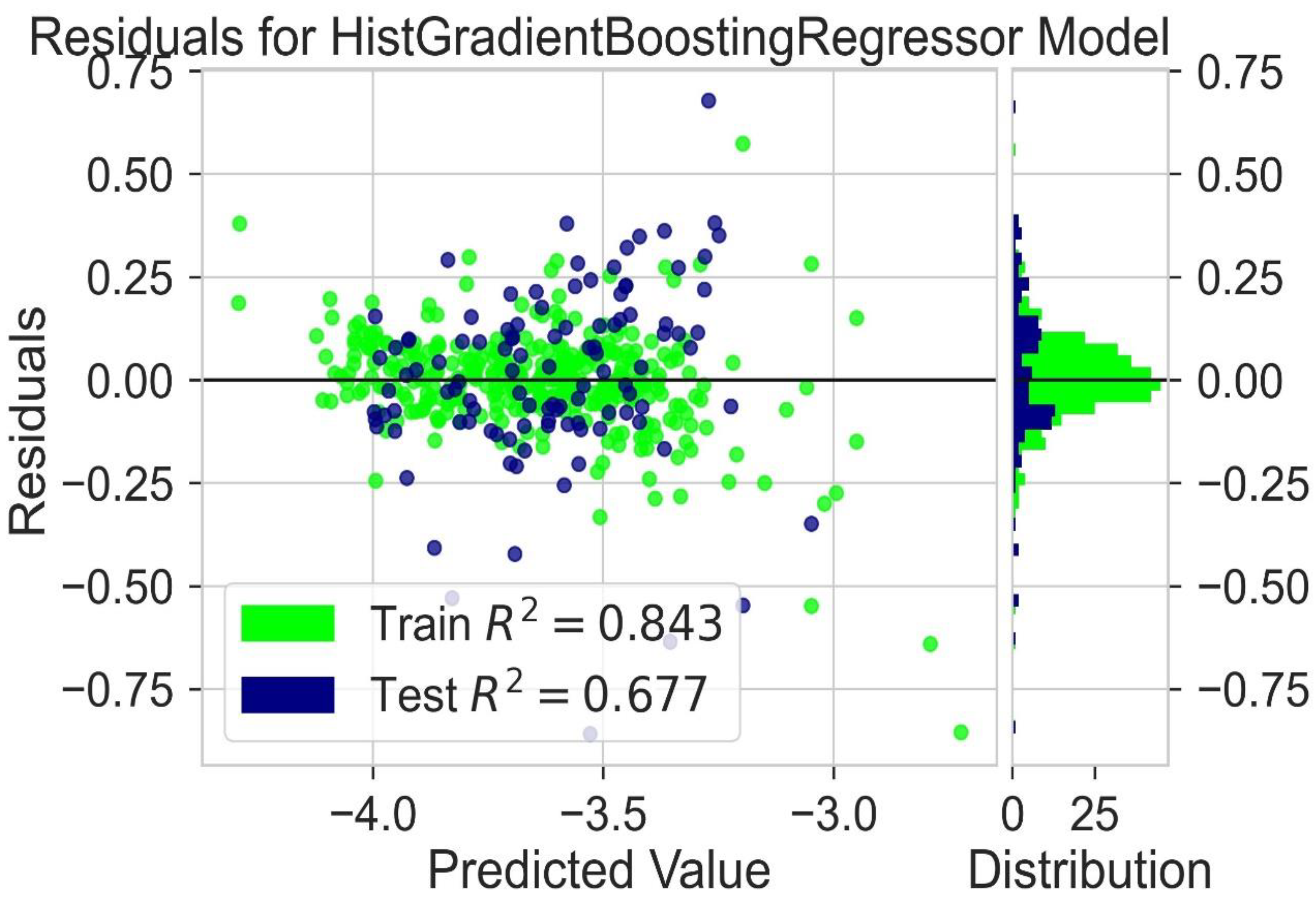
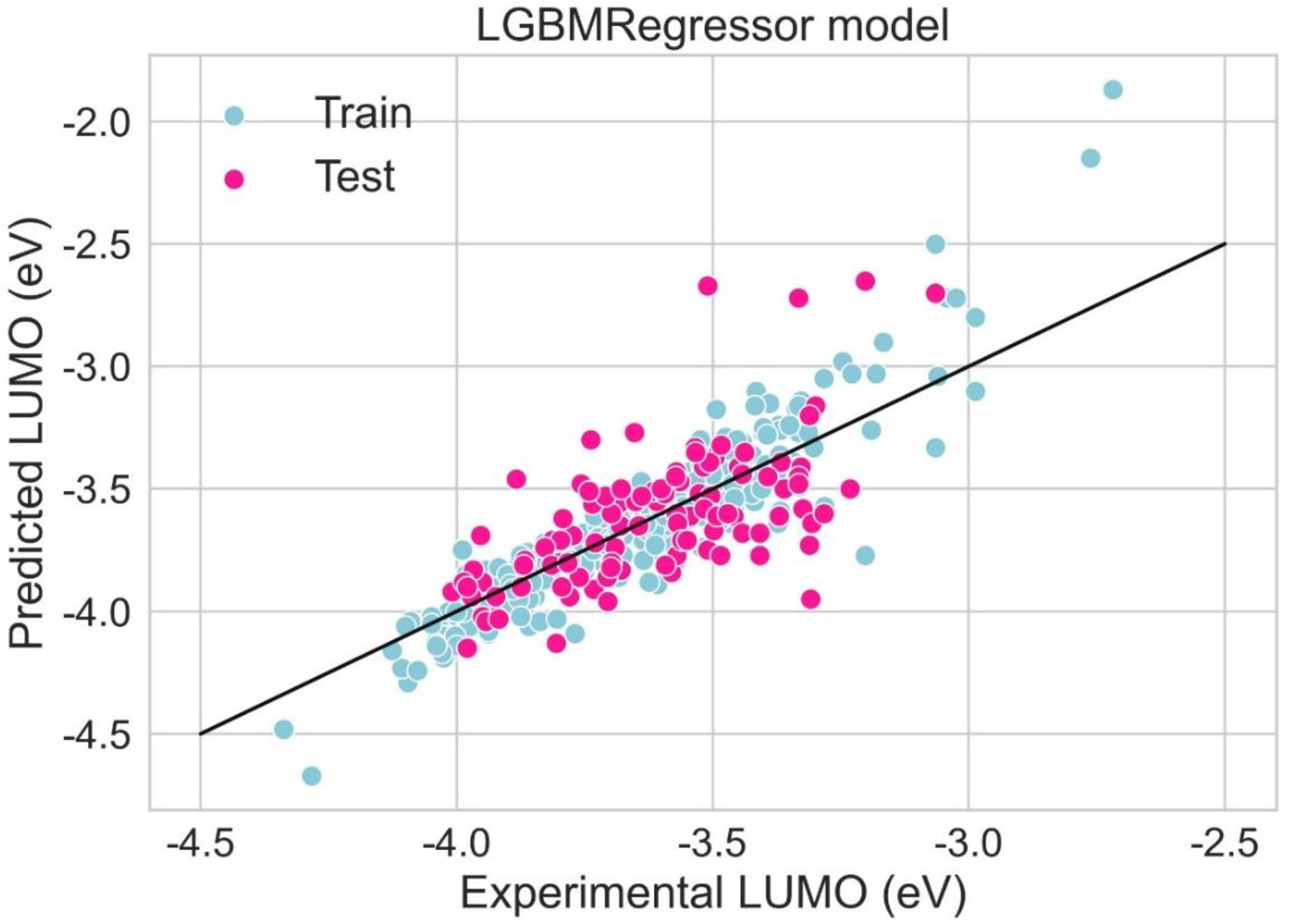
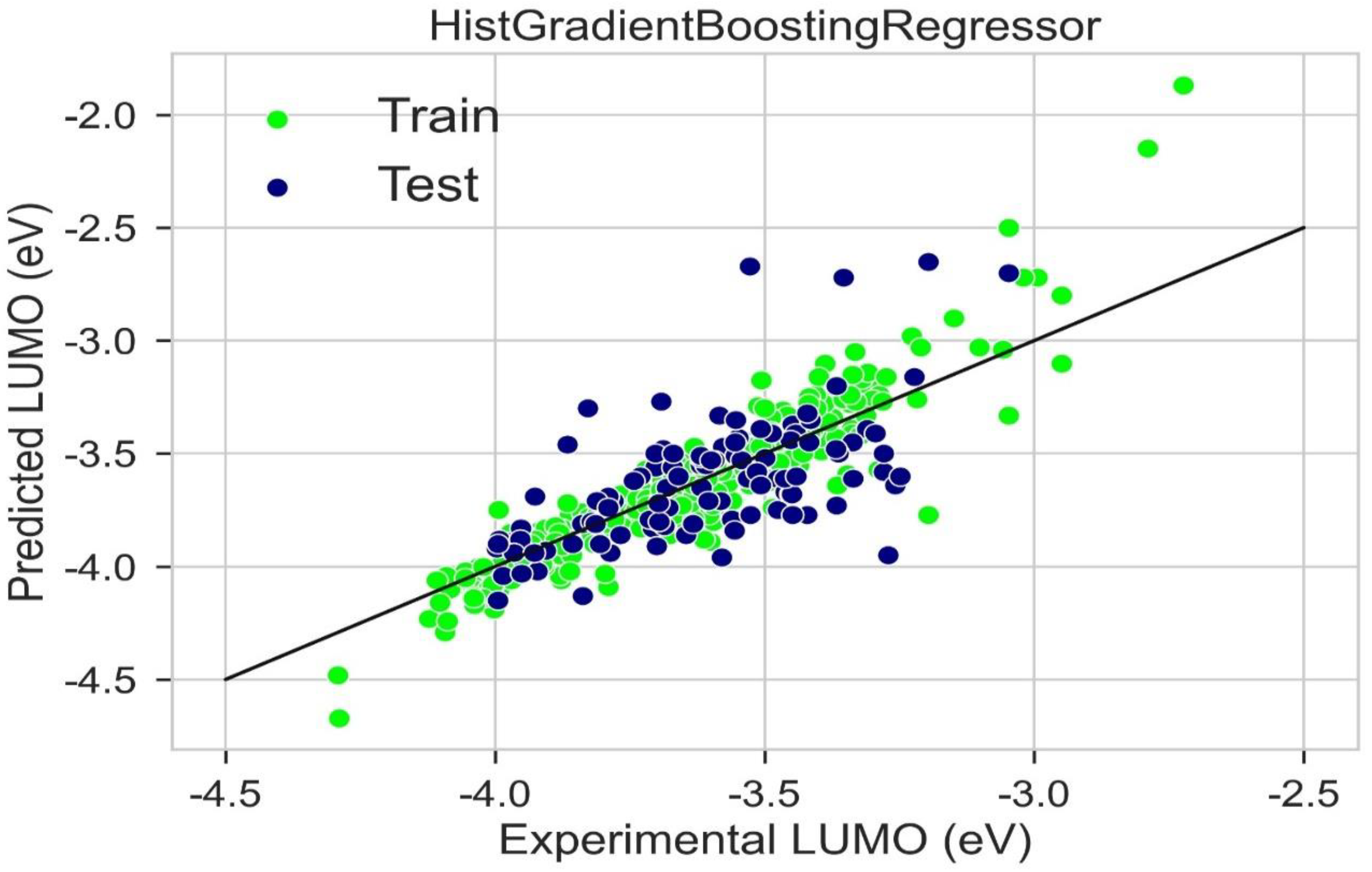
2.6. LUMO Prediction
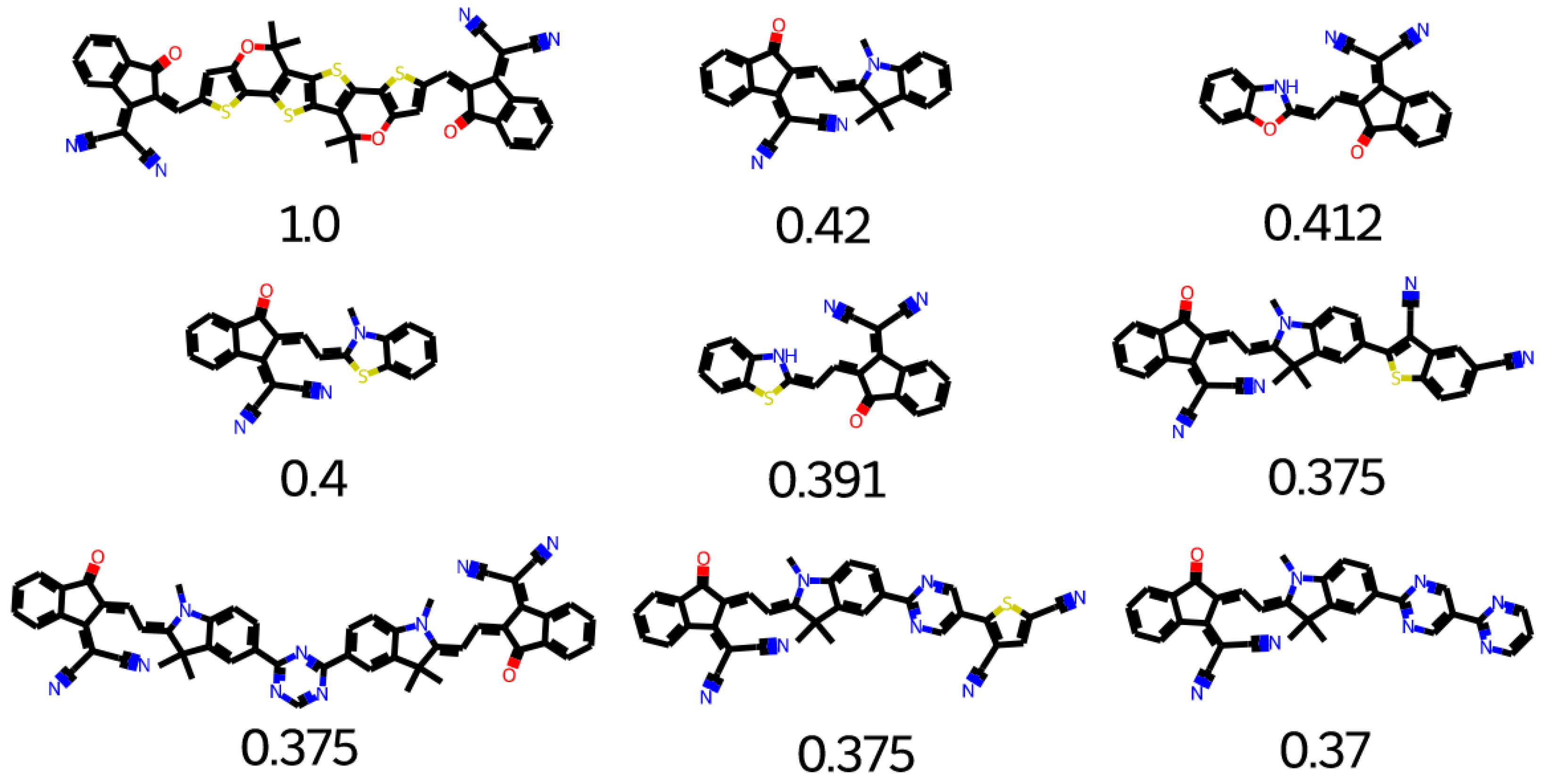
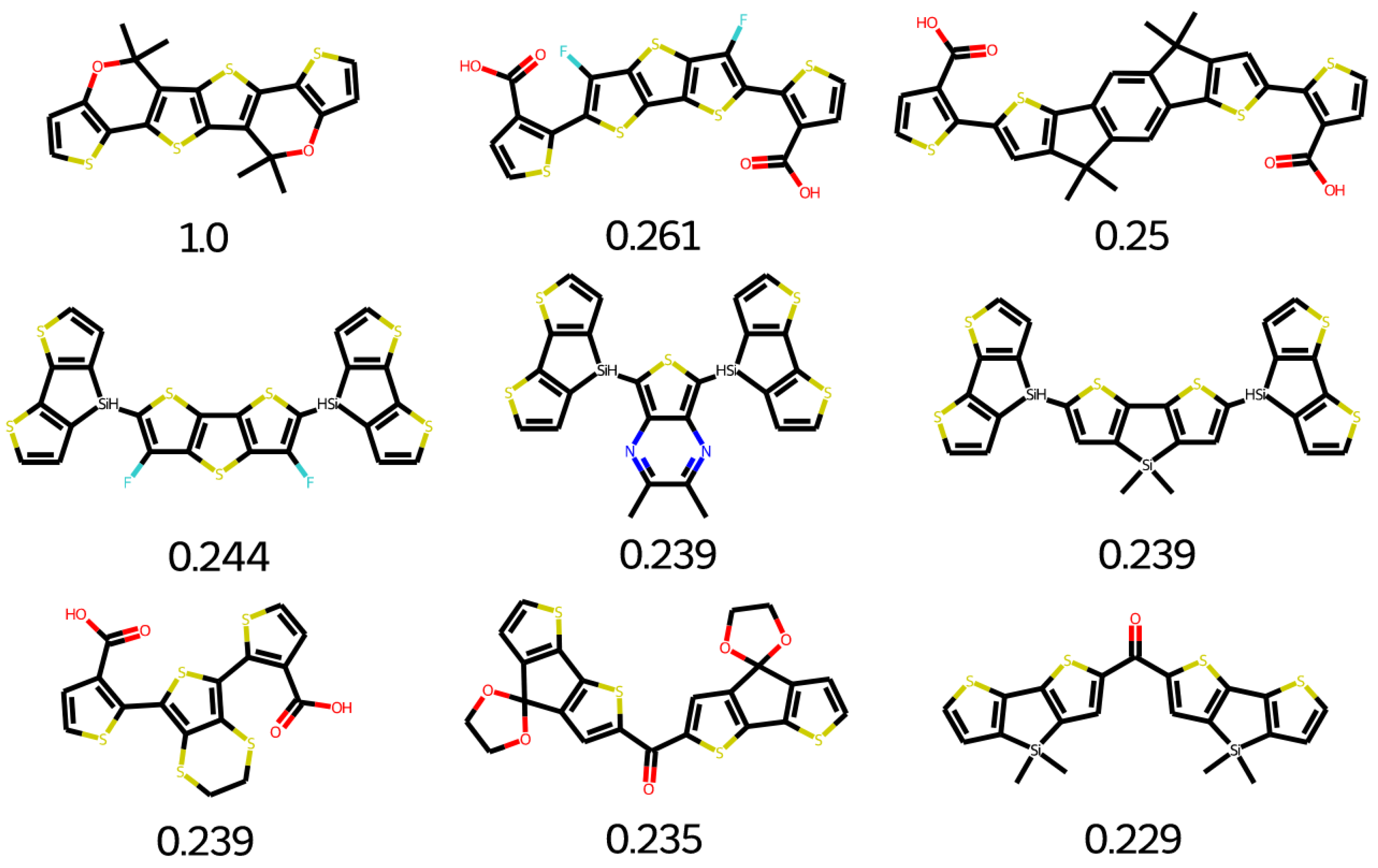
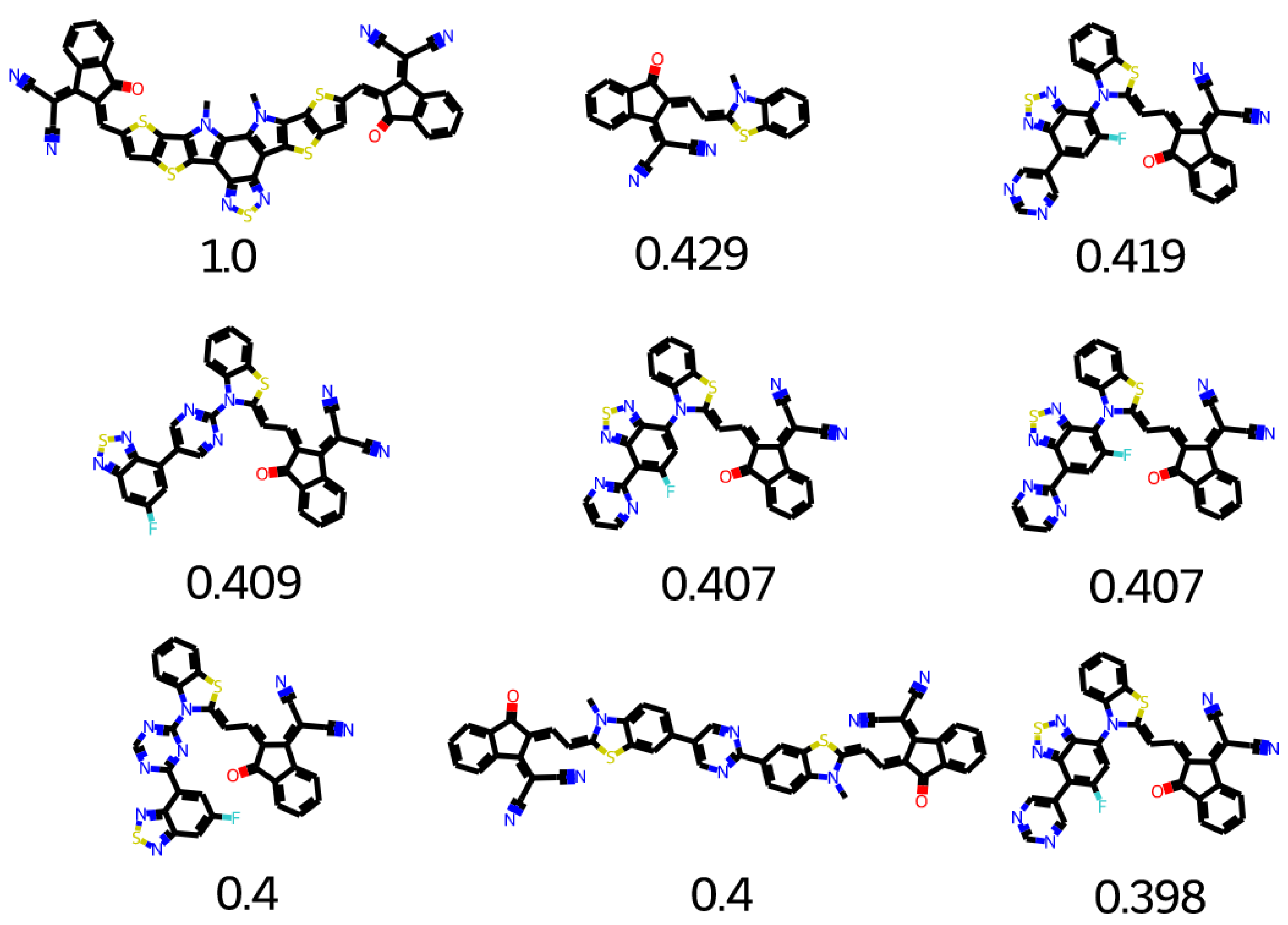
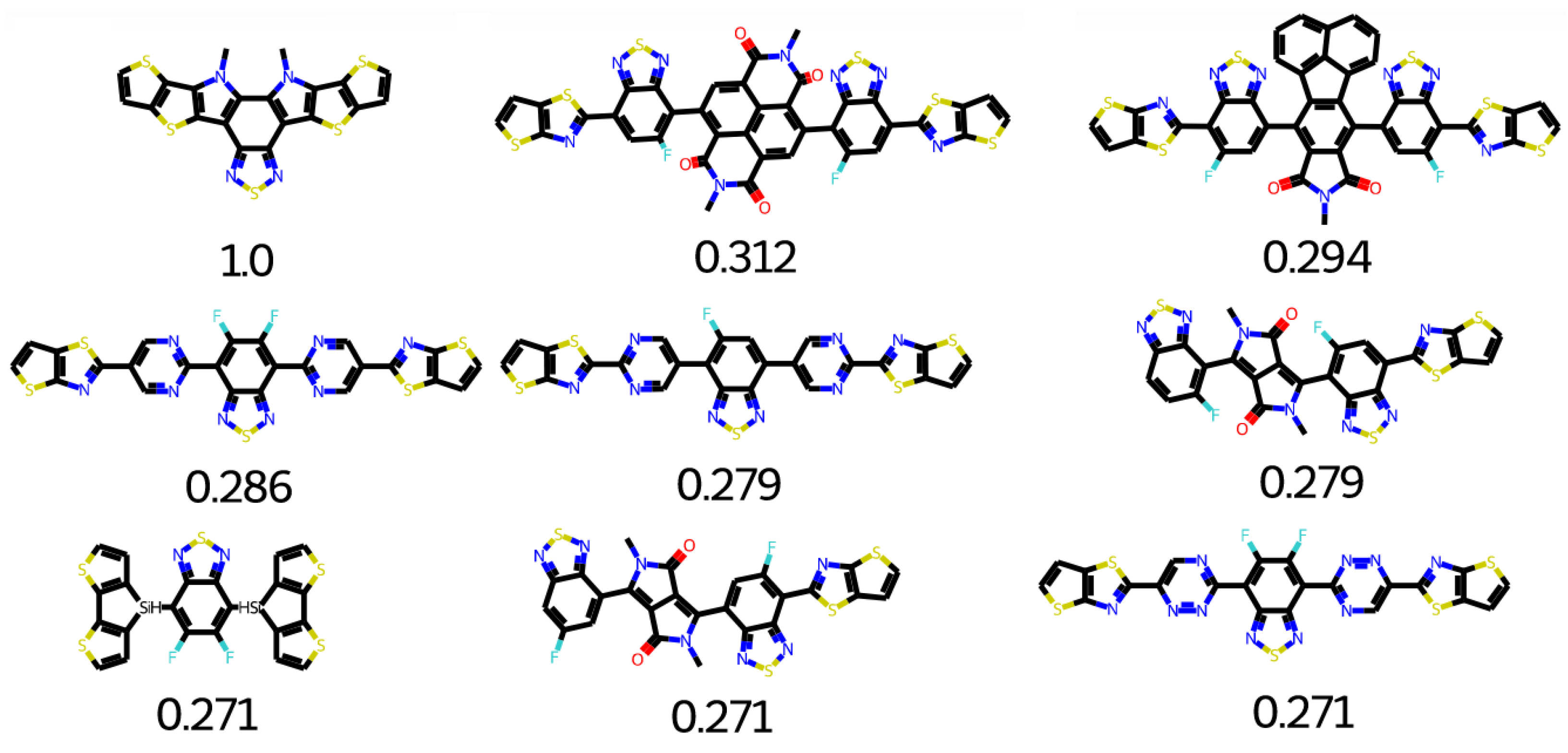
2.7. Database Mining
3. Methodology
3.1. Dataset
3.2. Molecular Descriptor Calculation
3.3. Training the Model
3.4. Similarity Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sulaman, M.; Yang, S.; Song, T.; Wang, H.; Wang, Y.; He, B.; Dong, M.; Tang, Y.; Song, Y.; Zou, B. High performance solution-processed infrared photodiode based on ternary PbSxSe1−x colloidal quantum dots. RSC Adv. 2016, 6, 87730–87737. [Google Scholar] [CrossRef]
- Sulaman, M.; Song, Y.; Yang, S.; Li, M.; Saleem, M.I.; Chandraseakar, P.V.; Jiang, Y.; Tang, Y.; Zou, B. Ultra-sensitive solution-processed broadband photodetectors based on vertical field-effect transistor. Nanotechnology 2019, 31, 105203. [Google Scholar] [CrossRef] [PubMed]
- Sulaman, M.; Song, Y.; Yang, S.; Saleem, M.I.; Li, M.; Perumal Veeramalai, C.; Zhi, R.; Jiang, Y.; Cui, Y.; Hao, Q.; et al. Interlayer of PMMA Doped with Au Nanoparticles for High-Performance Tandem Photodetectors: A Solution to Suppress Dark Current and Maintain High Photocurrent. ACS Appl. Mater. Interfaces 2020, 12, 26153–26160. [Google Scholar] [CrossRef] [PubMed]
- Sulaman, M.; Yang, S.; Bukhtiar, A.; Fu, C.; Song, T.; Wang, H.; Wang, Y.; Bo, H.; Tang, Y.; Zou, B. High performance solution-processed infrared photodetector based on PbSe quantum dots doped with low carrier mobility polymer poly(N-vinylcarbazole). RSC Adv. 2016, 6, 44514–44521. [Google Scholar] [CrossRef]
- Sulaman, M.; Yang, S.; Bukhtiar, A.; Tang, P.; Zhang, Z.; Song, Y.; Imran, A.; Jiang, Y.; Cui, Y.; Tang, L.; et al. Hybrid Bulk-Heterojunction of Colloidal Quantum Dots and Mixed-Halide Perovskite Nanocrystals for High-Performance Self-Powered Broadband Photodetectors. Adv. Funct. Mater. 2022, 32, 2201527. [Google Scholar] [CrossRef]
- Hussain, R.; Hassan, F.; Khan, M.U.; Mehboob, M.Y.; Fatima, R.; Khalid, M.; Mahmood, K.; Tariq, C.J.; Akhtar, M.N. Molecular engineering of A–D–C–D–A configured small molecular acceptors (SMAs) with promising photovoltaic properties for high-efficiency fullerene-free organic solar cells. Opt. Quantum Electron. 2020, 52, 364. [Google Scholar] [CrossRef]
- Saleem, M.I.; Yang, S.; Zhi, R.; Sulaman, M.; Chandrasekar, P.V.; Jiang, Y.; Tang, Y.; Batool, A.; Zou, B. Surface Engineering of All-Inorganic Perovskite Quantum Dots with Quasi Core−Shell Technique for High-Performance Photodetectors. Adv. Mater. Interfaces 2020, 7, 2000360. [Google Scholar] [CrossRef]
- Sulaman, M.; Song, Y.; Yang, S.; Hao, Q.; Zhao, Y.; Li, M.; Saleem, M.I.; Chandraseakar, P.V.; Jiang, Y.; Tang, Y.; et al. High-performance solution-processed colloidal quantum dots-based tandem broadband photodetectors with dielectric interlayer. Nanotechnology 2019, 30, 465203. [Google Scholar] [CrossRef]
- Hussain, R.; Mehboob, M.Y.; Khan, M.U.; Khalid, M.; Irshad, Z.; Fatima, R.; Anwar, A.; Nawab, S.; Adnan, M. Efficient designing of triphenylamine-based hole transport materials with outstanding photovoltaic characteristics for organic solar cells. J. Mater. Sci. 2021, 56, 5113–5131. [Google Scholar] [CrossRef]
- Khalid, M.; Khan, M.U.; Ahmed, S.; Shafiq, Z.; Alam, M.M.; Imran, M.; Braga, A.A.C.; Akram, M.S. Exploration of promising optical and electronic properties of (non-polymer) small donor molecules for organic solar cells. Sci. Rep. 2021, 11, 21540. [Google Scholar] [CrossRef]
- Babics, M.; Bristow, H.; Zhang, W.; Wadsworth, A.; Neophytou, M.; Gasparini, N.; McCulloch, I. Non-fullerene-based organic photodetectors for infrared communication. J. Mater. Chem. C 2021, 9, 2375–2380. [Google Scholar] [CrossRef]
- Liao, X.; Xie, W.; Han, Z.; Cui, Y.; Xia, X.; Shi, X.; Yao, Z.; Xu, X.; Lu, X.; Chen, Y. NIR Photodetectors with Highly Efficient Detectivity Enabled by 2D Fluorinated Dithienopicenocarbazole-Based Ultra-Narrow Bandgap Acceptors. Adv. Funct. Mater. 2022, 32, 2204255. [Google Scholar] [CrossRef]
- Mahmood, A. Photovoltaic and Charge Transport Behavior of Diketopyrrolopyrrole Based Compounds with A–D–A–D–A Skeleton. J. Cluster Sci. 2019, 30, 1123–1130. [Google Scholar] [CrossRef]
- Janjua, M.R.S.A. How Does Bridging Core Modification Alter the Photovoltaic Characteristics of Triphenylamine-Based Hole Transport Materials? Theoretical Understanding and Prediction. Chem. Eur. J. 2021, 27, 4197–4210. [Google Scholar] [CrossRef] [PubMed]
- Janjua, M.R.S.A. Photovoltaic properties and enhancement in near-infrared light absorption capabilities of acceptor materials for organic solar cell applications: A quantum chemical perspective via DFT. J. Phys. Chem. Solids 2022, 171, 110996. [Google Scholar] [CrossRef]
- Mahmood, A.; Khan, S.U.-D.; Rehman, F.U. Assessing the quantum mechanical level of theory for prediction of UV/Visible absorption spectra of some aminoazobenzene dyes. J. Saudi Chem. Soc. 2015, 19, 436–441. [Google Scholar] [CrossRef] [Green Version]
- Mahmood, A.; Khan, S.U.-D.; Rana, U.A.; Tahir, M.H. Red shifting of absorption maxima of phenothiazine based dyes by incorporating electron-deficient thiadiazole derivatives as π-spacer. Arab. J. Chem. 2019, 12, 1447–1453. [Google Scholar] [CrossRef] [Green Version]
- Khalid, M.; Ali, A.; Khan, M.U.; Tahir, M.N.; Ahmad, A.; Ashfaq, M.; Hussain, R.; Morais, S.F.d.A.; Braga, A.A.C. Non-covalent interactions abetted supramolecular arrangements of N-Substituted benzylidene acetohydrazide to direct its solid-state network. J. Mol. Struct. 2021, 1230, 129827. [Google Scholar] [CrossRef]
- Mahmood, A.; Saqib, M.; Ali, M.; Abdullah, M.I.; Khalid, B. Theoretical investigation for the designing of novel antioxidants. Can. J. Chem. 2013, 91, 126–130. [Google Scholar] [CrossRef]
- Mahmood, A.; Abdullah Muhammad, I.; Nazar Muhammad, F. Quantum Chemical Designing of Novel Organic Non-Linear Optical Compounds. Bull. Korean Chem. Soc. 2014, 35, 1391–1396. [Google Scholar] [CrossRef]
- Khalid, M.; Ali, A.; Abid, S.; Tahir, M.N.; Khan, M.U.; Ashfaq, M.; Imran, M.; Ahmad, A. Facile Ultrasound-Based Synthesis, SC-XRD, DFT Exploration of the Substituted Acyl-Hydrazones: An Experimental and Theoretical Slant towards Supramolecular Chemistry. ChemistrySelect 2020, 5, 14844–14856. [Google Scholar] [CrossRef]
- Siddiqui, W.A.; Khalid, M.; Ashraf, A.; Shafiq, I.; Parvez, M.; Imran, M.; Irfan, A.; Hanif, M.; Khan, M.U.; Sher, F.; et al. Antibacterial metal complexes of o-sulfamoylbenzoic acid: Synthesis, characterization, and DFT study. Appl. Organomet. Chem. 2022, 36, e6464. [Google Scholar] [CrossRef]
- Khalid, M.; Ali, A.; Asim, S.; Tahir, M.N.; Khan, M.U.; Curcino Vieira, L.C.; de la Torre, A.F.; Usman, M. Persistent prevalence of supramolecular architectures of novel ultrasonically synthesized hydrazones due to hydrogen bonding [X–H⋯O.; X=N]: Experimental and density functional theory analyses. J. Phys. Chem. Solids 2021, 148, 109679. [Google Scholar] [CrossRef]
- Mebed, A.M.; Jafri, H.M.; Hakamy, A.; Abd-Elnaiem, A.M.; Sulaman, M.; Elshahat, S. Multidimensional modeling assisted mining of GDB17 chemical database: A search for polymer donors for organic solar cells and machine learning assisted performance prediction. Int. J. Quantum Chem 2022, 122, e26991. [Google Scholar] [CrossRef]
- Janjua, M.R.S.A.; Irfan, A.; Hussien, M.; Ali, M.; Saqib, M.; Sulaman, M. Machine-Learning Analysis of Small-Molecule Donors for Fullerene Based Organic Solar Cells. Energy Technol. 2022, 10, 2200019. [Google Scholar] [CrossRef]
- Mahmood, A.; Wang, J.-L. A time and resource efficient machine learning assisted design of non-fullerene small molecule acceptors for P3HT-based organic solar cells and green solvent selection. J. Mater. Chem. A 2021, 9, 15684–15695. [Google Scholar] [CrossRef]
- Mahmood, A.; Irfan, A.; Wang, J.-L. Machine learning and molecular dynamics simulation-assisted evolutionary design and discovery pipeline to screen efficient small molecule acceptors for PTB7-Th-based organic solar cells with over 15% efficiency. J. Mater. Chem. A 2022, 10, 4170–4180. [Google Scholar] [CrossRef]
- Khan, S.U.-D.; Mahmood, A.; Rana, U.A.; Haider, S. Utilization of electron-deficient thiadiazole derivatives as π-spacer for the red shifting of absorption maxima of diarylamine-fluorene based dyes. Theor. Chem. Acc. 2014, 134, 1596. [Google Scholar] [CrossRef]
- Sharif, H.M.A.; Cheng, H.-Y.; Haider, M.R.; Khan, K.; Yang, L.; Wang, A.-J. NO Removal with Efficient Recovery of N2O by Using Recyclable Fe3O4@EDTA@Fe(II) Complex: A Novel Approach toward Resource Recovery from Flue Gas. Environ. Sci. Technol. 2019, 53, 1004–1013. [Google Scholar] [CrossRef]
- Sharif, H.M.A.; Farooq, M.; Hussain, I.; Ali, M.; Mujtaba, M.A.; Sultan, M.; Yang, B. Recent innovations for scaling up microbial fuel cell systems: Significance of physicochemical factors for electrodes and membranes materials. J. Taiwan Inst. Chem. Eng. 2021, 129, 207–226. [Google Scholar] [CrossRef]
- Tahir, M.H.; Mubashir, T.; Shah, T.-U.-H.; Mahmood, A. Impact of electron-withdrawing and electron-donating substituents on the electrochemical and charge transport properties of indacenodithiophene-based small molecule acceptors for organic solar cells. J. Phys. Org. Chem. 2019, 32, e3909. [Google Scholar] [CrossRef]
- Sharif, H.M.A.; Mahmood, N.; Wang, S.; Hussain, I.; Hou, Y.-N.; Yang, L.-H.; Zhao, X.; Yang, B. Recent advances in hybrid wet scrubbing techniques for NOx and SO2 removal: State of the art and future research. Chemosphere 2021, 273, 129695. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, A.; Irfan, A.; Wang, J.-L. Developing Efficient Small Molecule Acceptors with sp2-Hybridized Nitrogen at Different Positions by Density Functional Theory Calculations, Molecular Dynamics Simulations and Machine Learning. Chem. Eur. J. 2022, 28, e202103712. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, A.; Irfan, A. Computational analysis to understand the performance difference between two small-molecule acceptors differing in their terminal electron-deficient group. J. Comput. Electron. 2020, 19, 931–939. [Google Scholar] [CrossRef]
- Mahmood, A.; Irfan, A.; Ahmad, F.; Ramzan Saeed Ashraf Janjua, M. Quantum chemical analysis and molecular dynamics simulations to study the impact of electron-deficient substituents on electronic behavior of small molecule acceptors. Comput. Theor. Chem. 2021, 1204, 113387. [Google Scholar] [CrossRef]
- Khalid, M.; Khan, M.U.; Razia, E.-t.; Shafiq, Z.; Alam, M.M.; Imran, M.; Akram, M.S. Exploration of efficient electron acceptors for organic solar cells: Rational design of indacenodithiophene based non-fullerene compounds. Sci. Rep. 2021, 11, 19931. [Google Scholar] [CrossRef]
- Khalid, M.; Momina; Imran, M.; Rehman, M.F.U.; Braga, A.A.C.; Akram, M.S. Molecular engineering of indenoindene-3-ethylrodanine acceptors with A2-A1-D-A1-A2 architecture for promising fullerene-free organic solar cells. Sci. Rep. 2021, 11, 20320. [Google Scholar] [CrossRef]
- Khan, M.U.; Hussain, R.; Mehboob, M.Y.; Khalid, M.; Ehsan, M.A.; Rehman, A.; Janjua, M.R.S.A. First theoretical framework of Z-shaped acceptor materials with fused-chrysene core for high performance organic solar cells. Spectrochim. Act A Mol. Biomol. Spectrosc. 2021, 245, 118938. [Google Scholar] [CrossRef]
- Mahmood, A.; Irfan, A.; Wang, J.-L. Machine Learning for Organic Photovoltaic Polymers: A Minireview. Chin. J. Polym. Sci. 2022, 40, 870–876. [Google Scholar] [CrossRef]
- Mahmood, A.; Abdullah, M.I.; Khan, S.U.-D. Enhancement of nonlinear optical (NLO) properties of indigo through modification of auxiliary donor, donor and acceptor. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2015, 139, 425–430. [Google Scholar] [CrossRef]
- Mahmood, A.; HussainTahir, M.; Irfan, A.; Khalid, B.; Al-Sehemi, A.G. Computational Designing of Triphenylamine Dyes with Broad and Red-shifted Absorption Spectra for Dye-sensitized Solar Cells using Multi-Thiophene Rings in π-Spacer. Bull. Korean Chem. Soc. 2015, 36, 2615–2620. [Google Scholar] [CrossRef]
- Mahmood, A.; Wang, J.-L. Machine learning for high performance organic solar cells: Current scenario and future prospects. Energy Environ. Sci. 2021, 14, 90–105. [Google Scholar] [CrossRef]
- Zhang, Y.; Ji, Y.; Zhang, Y.; Zhang, W.; Bai, H.; Du, M.; Wu, H.; Guo, Q.; Zhou, E. Recent Progress of Y6-Derived Asymmetric Fused Ring Electron Acceptors. Adv. Funct. Mater. 2022, 32, 2205115. [Google Scholar] [CrossRef]
- Yang, J.; Xiao, B.; Tang, A.; Li, J.; Wang, X.; Zhou, E. Aromatic-Diimide-Based n-Type Conjugated Polymers for All-Polymer Solar Cell Applications. Adv. Mater. 2019, 31, 1804699. [Google Scholar] [CrossRef] [PubMed]
- Mahmood, A.; Irfan, A.; Wang, J.-L. Molecular level understanding of the chalcogen atom effect on chalcogen-based polymers through electrostatic potential, non-covalent interactions, excited state behaviour, and radial distribution function. Polym. Chem. 2022, 13, 5993–6001. [Google Scholar] [CrossRef]
- Guo, Q.; Guo, Q.; Geng, Y.; Tang, A.; Zhang, M.; Du, M.; Sun, X.; Zhou, E. Recent advances in PM6:Y6-based organic solar cells. Mater. Chem. Front. 2021, 5, 3257–3280. [Google Scholar] [CrossRef]
- Nie, Q.; Tang, A.; Guo, Q.; Zhou, E. Benzothiadiazole-based non-fullerene acceptors. Nano Energy 2021, 87, 106174. [Google Scholar] [CrossRef]
- Mahmood, A.; Irfan, A. Effect of fluorination on exciton binding energy and electronic coupling in small molecule acceptors for organic solar cells. Comput. Theor. Chem. 2020, 1179, 112797. [Google Scholar] [CrossRef]
- Khan, M.U.; Hussain, R.; Yasir Mehboob, M.; Khalid, M.; Shafiq, Z.; Aslam, M.; Al-Saadi, A.A.; Jamil, S.; Janjua, M.R.S.A. In Silico Modeling of New “Y-Series”-Based Near-Infrared Sensitive Non-Fullerene Acceptors for Efficient Organic Solar Cells. ACS Omega 2020, 5, 24125–24137. [Google Scholar] [CrossRef]
- Khan, M.U.; Khalid, M.; Arshad, M.N.; Khan, M.N.; Usman, M.; Ali, A.; Saifullah, B. Designing Star-Shaped Subphthalocyanine-Based Acceptor Materials with Promising Photovoltaic Parameters for Non-fullerene Solar Cells. ACS Omega 2020, 5, 23039–23052. [Google Scholar] [CrossRef]
- Mahmood, A.; Hu, J.-Y.; Xiao, B.; Tang, A.; Wang, X.; Zhou, E. Recent progress in porphyrin-based materials for organic solar cells. J. Mater. Chem. A 2018, 6, 16769–16797. [Google Scholar] [CrossRef]
- Khan, M.U.; Khalid, M.; Hussain, R.; Umar, A.; Mehboob, M.Y.; Shafiq, Z.; Imran, M.; Irfan, A. Novel W-Shaped Oxygen Heterocycle-Fused Fluorene-Based Non-Fullerene Acceptors: First Theoretical Framework for Designing Environment-Friendly Organic Solar Cells. Energy Fuels 2021, 35, 12436–12450. [Google Scholar] [CrossRef]
- Mehboob, M.Y.; Hussain, R.; Khan, M.U.; Adnan, M.; Umar, A.; Alvi, M.U.; Ahmed, M.; Khalid, M.; Iqbal, J.; Akhtar, M.N.; et al. Designing N-phenylaniline-triazol configured donor materials with promising optoelectronic properties for high-efficiency solar cells. Comput. Theor. Chem. 2020, 1186, 112908. [Google Scholar] [CrossRef]
- Khan, M.U.; Mehboob, M.Y.; Hussain, R.; Fatima, R.; Tahir, M.S.; Khalid, M.; Braga, A.A.C. Molecular designing of high-performance 3D star-shaped electron acceptors containing a truxene core for nonfullerene organic solar cells. J. Phys. Org. Chem. 2021, 34, e4119. [Google Scholar] [CrossRef]
- Mahmood, A.; Hu, J.; Tang, A.; Chen, F.; Wang, X.; Zhou, E. A novel thiazole based acceptor for fullerene-free organic solar cells. Dyes Pigm. 2018, 149, 470–474. [Google Scholar] [CrossRef]
- Irfan, A.; Hussien, M.; Mehboob, M.Y.; Ahmad, A.; Janjua, M.R.S.A. Learning from Fullerenes and Predicting for Y6: Machine Learning and High-Throughput Screening of Small Molecule Donors for Organic Solar Cells. Energy Technol. 2022, 10, 2101096. [Google Scholar] [CrossRef]
- Mauri, A.; Consonni, V.; Pavan, M.; Todeschini, R. DRAGON software: An easy approach to molecular descriptor calculations. MATCH Commun. Math. Comput. Chem. 2006, 56, 237–248. [Google Scholar]
- Landrum, G. RDKit: Open-Source Cheminformatics. Available online: http://www.rdkit.org.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Molecular Descriptor | Category | Description |
|---|---|---|---|
| 1 | SM5_X | 2D matrix-based descriptors | Spectral moment of order 5 from chi matrix |
| 2 | RCI | Ring descriptors | Ring complexity index |
| 3 | nR05 | Ring descriptors | Number of 5-membered rings |
| 4 | RFD | Ring descriptors | Ring fusion density |
| 5 | NNRS | Ring descriptors | Normalized number of ring systems |
| 6 | DECC | Topological indice | Eccentric |
| 7 | ETA-D-AlphaB | Eta delta alpha b index | |
| 8 | SdssC | Atom-type E-state indices | Sum of dssC E-states |
| 9 | SpAD_AEA(dm) | Edge adjacency indices | Spectral absolute deviation from augmented edge adjacency mat. weighted by the dipole moment |
| 10 | TI2-LN | 2D matrix-based descriptors | Second Mohar index from Laplace matrix |
| Model | Train R2 | Test R2 | Train MAE (eV) | Test MAE (eV) | Train RMSE (eV) | Test RMSE (eV) |
|---|---|---|---|---|---|---|
| Hist Gradient Boosting Regressor | 0.912 | 0.820 | 0.136 | 0.146 | 0.163 | 0.176 |
| LGBM Regressor | 0.906 | 0.863 | 0.137 | 0.142 | 0.165 | 0.172 |
| Random Forest Regressor | 0.853 | 0.801 | 0.144 | 0.148 | 0.174 | 0.180 |
| Decision Tree Regressor | 0.752 | 0.683 | 0.150 | 0.155 | 0.183 | 0.193 |
| Extra Trees Regressor | 0.723 | 0.652 | 0.152 | 0.159 | 0.189 | 0.194 |
| AdaBoost Regressor | 0.623 | 0.560 | 0.161 | 0.172 | 0.1950 | 0.239 |
| K-Neighbors Regressor | 0.620 | 0.564 | 0.161 | 0.171 | 0.1950 | 0.237 |
| Linear Regression | 0.610 | 0.550 | 0.162 | 0.173 | 0.1960 | 0.243 |
| No | Molecular Descriptor | Category | Description |
|---|---|---|---|
| 1 | SpAD_AEA(dm) | Edge adjacency indices | Spectral absolute deviation from augmented edge mat. weighted by dipole moment |
| 2 | GATS1s | 2D autocorrelations | Geary autocorrelation of lag 1 weighted by I-state |
| 3 | Eig04_EA(dm) | Edge adjacency indices | Eigenvalue n. 4 from edge adjacency mat. weighted by dipole Moment |
| 4 | EE_B(s) | 2D matrix-based descriptor | Estrada-like index (log function) from Burden matrix weighted by I-State |
| 5 | SM4_B(s) | 2D matrix-based descriptors | Spectral moment of order 4 from Burden matrix by I-State |
| 6 | SM5_B(s) | 2D matrix-based descriptors | Spectral moment of order 5 from Burden matrix by I-State |
| 7 | SM6_B(s) | 2D matrix-based descriptors | Spectral moment of order 6 from Burden matrix by I-State |
| 8 | Eig08_EA(dm) | Edge adjacency indices | Eigenvalue n. 8 from edge adjacency mat. weighted by dipole Moment |
| 9 | SHED-AL | SHED Acceptor Lipophilic |
| Model | Train R2 | Test R2 | Train MAE (eV) | Test MAE (eV) | Train RMSE (eV) | Test RMSE (eV) |
|---|---|---|---|---|---|---|
| Hist Gradient Boosting Regressor | 0.843 | 0.667 | 0.070 | 0.074 | 0.084 | 0.089 |
| LGBM Regressor | 0.831 | 0.602 | 0.071 | 0.075 | 0.085 | 0.090 |
| Random Forest Regressor | 0.820 | 0.601 | 0.072 | 0.076 | 0.087 | 0.092 |
| Decision Tree Regressor | 0.732 | 0.583 | 0.075 | 0.078 | 0.093 | 0.097 |
| Extra Trees Regressor | 0.723 | 0.570 | 0.076 | 0.080 | 0.095 | 0.097 |
| AdaBoost Regressor | 0.652 | 0.540 | 0.081 | 0.086 | 0.098 | 0.120 |
| Linear Regression | 0.612 | 0.504 | 0.082 | 0.087 | 0.099 | 0.121 |
| K-Neighbors Regressor | 0.610 | 0.520 | 0.081 | 0.087 | 0.098 | 0.122 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Saleh, J.; Haider, S.; Akhtar, M.S.; Saqib, M.; Javed, M.; Elshahat, S.; Kamal, G.M. Energy Level Prediction of Organic Semiconductors for Photodetectors and Mining of a Photovoltaic Database to Search for New Building Units. Molecules 2023, 28, 1240. https://doi.org/10.3390/molecules28031240
Saleh J, Haider S, Akhtar MS, Saqib M, Javed M, Elshahat S, Kamal GM. Energy Level Prediction of Organic Semiconductors for Photodetectors and Mining of a Photovoltaic Database to Search for New Building Units. Molecules. 2023; 28(3):1240. https://doi.org/10.3390/molecules28031240
Chicago/Turabian StyleSaleh, Jehad, Sajjad Haider, Muhammad Saeed Akhtar, Muhammad Saqib, Muqadas Javed, Sayed Elshahat, and Ghulam Mustafa Kamal. 2023. "Energy Level Prediction of Organic Semiconductors for Photodetectors and Mining of a Photovoltaic Database to Search for New Building Units" Molecules 28, no. 3: 1240. https://doi.org/10.3390/molecules28031240