
Learning Multi-Types of Neighbor Node Attributes and Semantics by Heterogeneous Graph Transformer and Multi-View Attention for Drug-Related Side-Effect Prediction
Abstract
:1. Introduction
- (1)
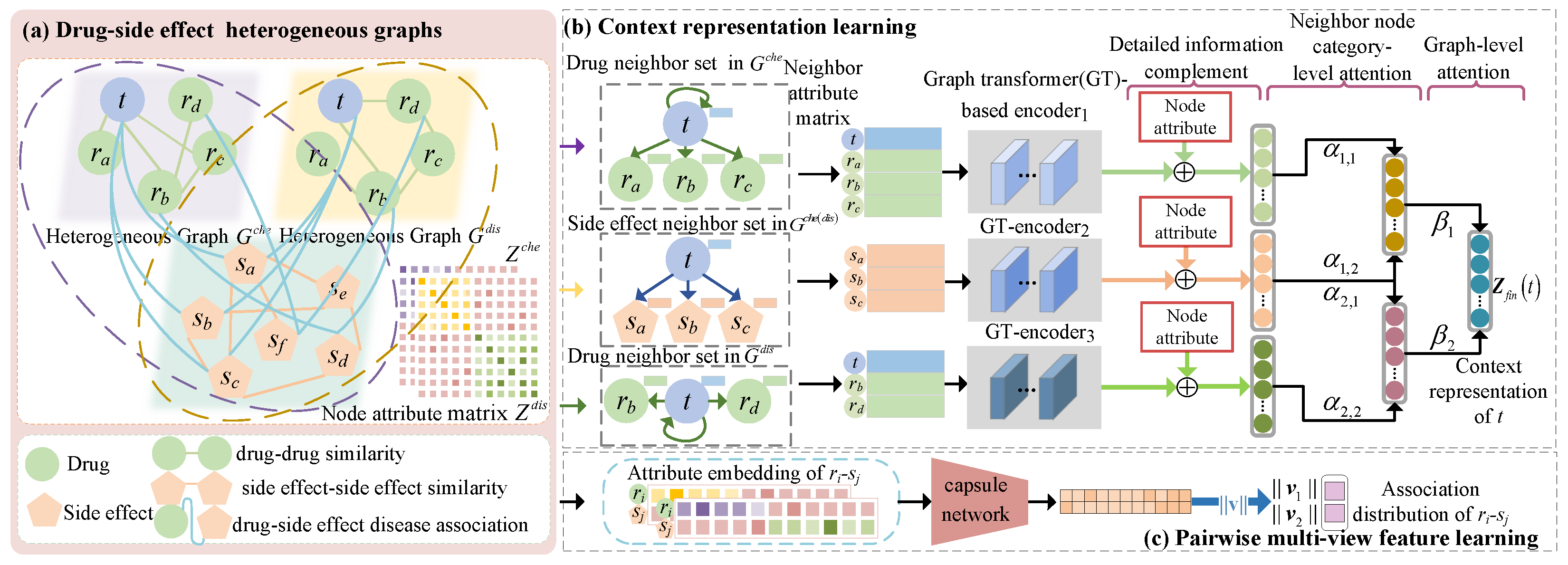
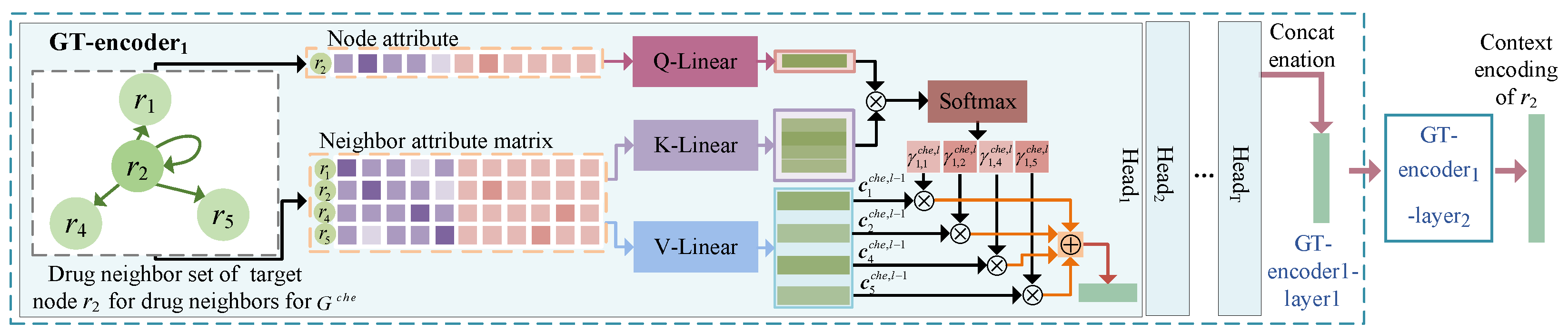
- First, two heterogeneous graphs composed of drug and side-effect nodes are constructed by utilizing two types of drug similarities to complement the encoding of the specific topology structure and node attributes of each heterogeneous graph. A target node in each graph has drug neighbor nodes and side-effect nodes, and there are contextual relationship among the attributes of the target node and the attributes of its diverse neighbor nodes. Most previous approaches have focused only on aggregating the information of a single type of neighbor node. A module based on a graph transformer is established to learn category-sensitive attributes for each category of neighbor nodes.
- (2)
- Previous approaches did not fully utilize the diverse information of multiple types of connections among the drug and side-effect nodes. In order to improve the node feature-learning capacity in each heterogeneous graph, we design a strategy to integrate the similarity semantic connections between drugs (side-effects) and the association semantic connections between drugs and side-effects.
- (3)
- Third, we design two attention mechanisms for the effective fusion of learned information. To adaptively fuse the encoded contextual features from the drug neighbor nodes and the side-effect nodes for each target node, we design the attention at the neighbor category level. Since two heterogeneous graphs make different contributions to drug-related side-effect prediction, we design an attention from the graph perspective to discriminate their contributions.
- (4)
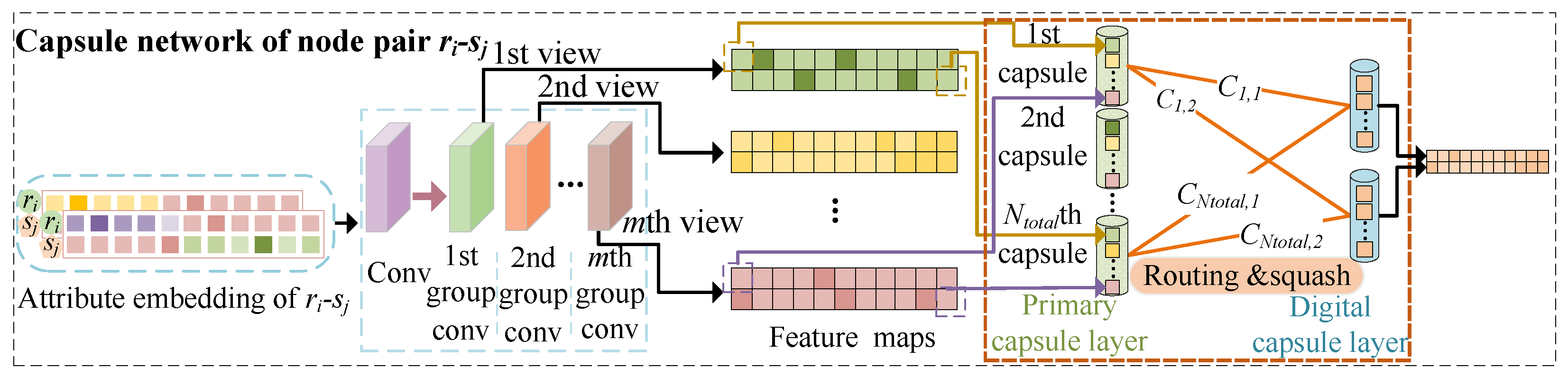
- Finally, we propose a capsule network-based strategy to learn the attributes of a pair of drug and side-effect nodes. The created multiple capsules and the dynamic routing mechanism enhance position information learning in the pairwise attribute embedding. Previous approaches did not integrate the information of the positions in the pairwise embedding. A comprehensive comparison with six state-of-the-art methods and case studies on five drugs showed TCSD’s superior performance and its ability in discovering potential association candidates.
2. Materials and Methods
2.1. Dataset
2.2. Multi-Source Data Matrix Representation and Construction of Heterogeneous Graphs
2.2.1. Matrix Representation of Drug-Side-Effect Associations
2.2.2. Matrix Representation of Multi-Modality Similarities of Drugs
2.2.3. Matrix Representation of Side-Effect Similarity
2.2.4. Construction of Drug-Side-Effect Heterogeneous Graphs and Attribute Extraction
2.3. Context Representation Learning Based on Transformer with Attention
2.3.1. Neighborhood Node Set Extraction
2.3.2. Node Attribute Conversion
2.3.3. Contextual Encoding of Nodes of the Same Type
2.3.4. Neighborhood Node Category-Level and Graph-Level Attention Mechanisms
2.4. Local Information Enrichment Strategy for Drug-Side-Effect Node Pair Feature Representation Learning Based on Capsule Networks
2.4.1. Establishment of Primary Capsule Embedding Based on Convolution Operation
2.4.2. Creation of the Primary Capsule Layer
2.4.3. Design of Capsule Layer Routing Mechanism
2.5. Final Integration and Optimization
3. Experimental Evaluations and Discussion
3.1. Parameter Settings and Evaluation Metrics
3.2. Ablation Experiment
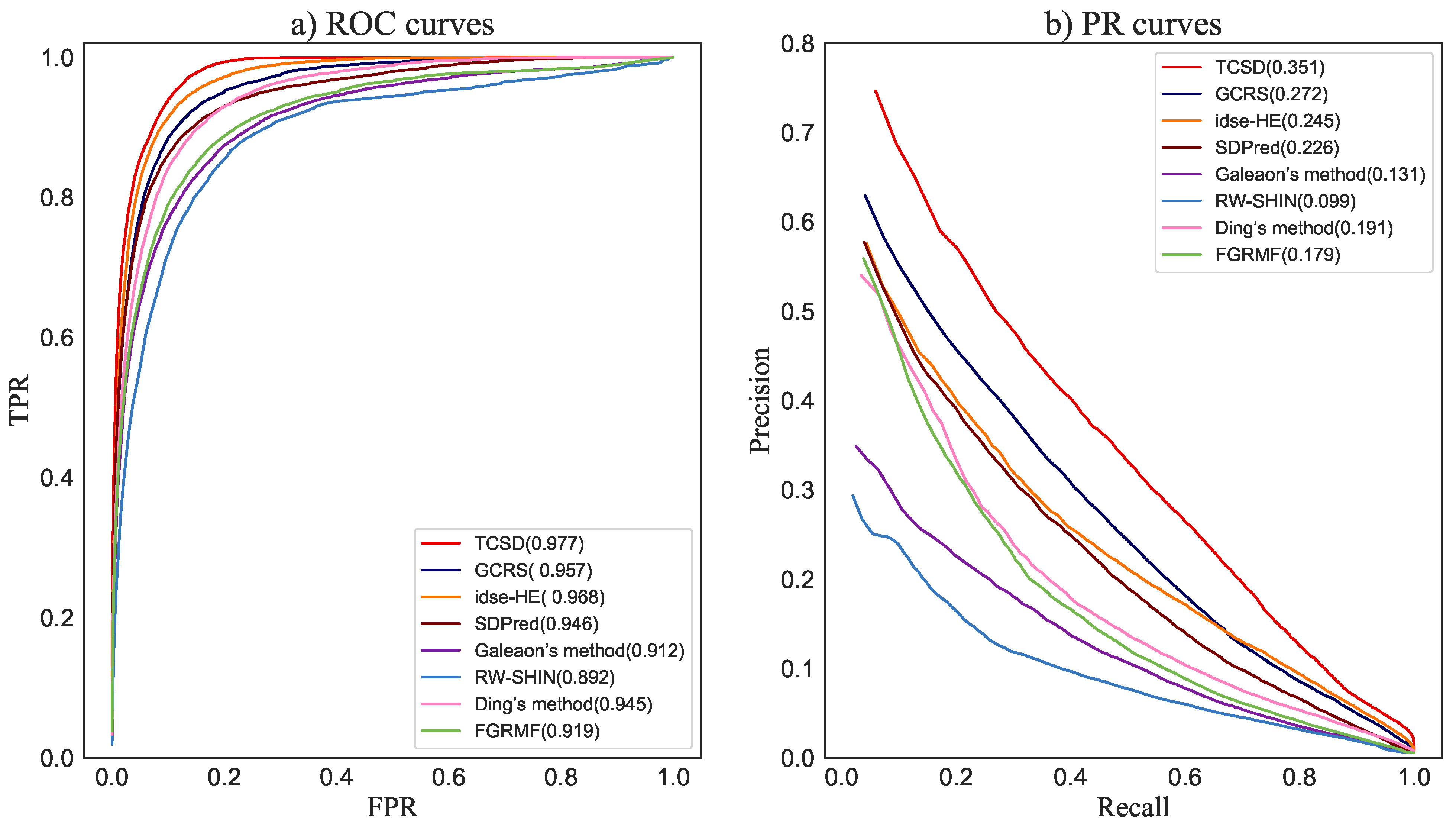
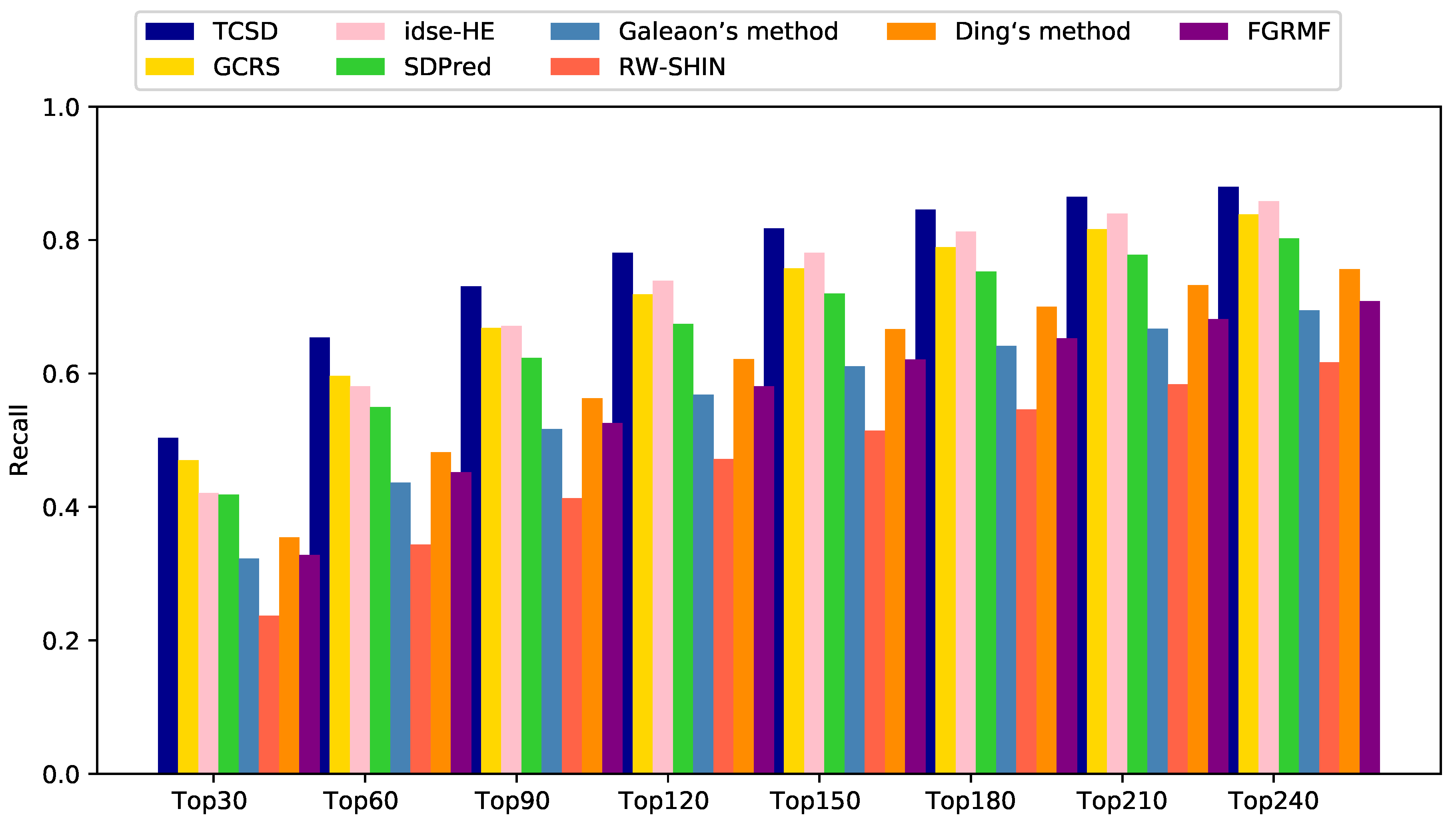
3.3. Comparison with Other Methods
3.4. Case Studies on Five Drugs
3.5. Predicting Novel Drug-Related Side-Effects
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cakir, A.; Tuncer, M.; Taymaz-Nikerel, H.; Ulucan, O. Side-effect prediction based on drug-induced gene expression profiles and random forest with iterative feature selection. Pharmacogenom. J. 2021, 21, 673–681. [Google Scholar] [CrossRef]
- Zhang, F.; Sun, B.; Diao, X.; Zhao, W.; Shu, T. Prediction of adverse drug reactions based on knowledge graph embedding. BMC Med. Lnformatics Decis. Mak. 2021, 21, 38. [Google Scholar] [CrossRef]
- Sachdev, K.; Gupta, M.K. A comprehensive review of feature based methods for drug target interaction prediction. J. Biomed. Inform. 2019, 93, 103159. [Google Scholar] [CrossRef]
- Jiang, H.; Qiu, Y.; Hou, W.; Cheng, X.; Yim, M.; Ching, W. Drug Side-Effect Profiles Prediction: From Empirical to Structural Risk Minimization. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 17, 402–410. [Google Scholar] [PubMed]
- Li, J.; Zheng, S.; Chen, B.; Butte, A.J.; Swamidass, S.J.; Lu, Z. A survey of current trends in computational drug repositioning. Briefings Bioinform. 2016, 17, 2–12. [Google Scholar] [CrossRef] [PubMed]
- dos Santos Nascimento, I.J.; da Silva Rodrigues, É.E.; da Silva, M.F.; de Araújo-Júnior, J.X.; de Moura, R.O. Advances in Computational Methods to Discover New NS2B-NS3 Inhibitors Useful Against Dengue and Zika Viruses. Curr. Top. Med. Chem. 2022, 22, 2435–2462. [Google Scholar] [CrossRef] [PubMed]
- Nascimento., I.J.d.S.; de Aquino, T.M.; da Silva-Júnior, E.F. The New Era of Drug Discovery: The Power of Computer-aided Drug Design (CADD). Lett. Drug Des. Discov. 2022, 19, 951–955. [Google Scholar] [CrossRef]
- Seo, S.; Lee, T.; Kim, M.h.; Yoon, Y. Prediction of side-effects Using Comprehensive Similarity Measures. BioMed Res. Int. 2020, 2020, 1357630. [Google Scholar] [CrossRef]
- Zheng, Y.; Peng, H.; Ghosh, S.; Lan, C.; Li, J. Inverse similarity and reliable negative samples for drug side-effect prediction. BMC Bioinform. 2019, 17, 554. [Google Scholar] [CrossRef]
- Lee, W.P.; Huang, J.Y.; Chang, H.H.; Lee, K.T.; Lai, C.T. Predicting Drug side-effects Using Data Analytics and the Integration of Multiple Data Sources. IEEE Access 2017, 5, 20449–20462. [Google Scholar] [CrossRef]
- Yang, L.; Chen, J.; He, L. Harvesting Candidate Genes Responsible for Serious Adverse Drug Reactions from a Chemical-Protein Interactome. PLoS Comput. Biol. 2009, 5, e1000441. [Google Scholar] [CrossRef]
- Luo, H.; Chen, J.; Shi, L.; Mikailov, M.; Zhu, H.; Wang, K.; He, L.; Yang, L. DRAR-CPI: A server for identifying drug repositioning potential and adverse drug reactions via the chemical-protein interactome. Nucleic Acids Res. 2011, 39, W492–W498. [Google Scholar] [CrossRef] [PubMed]
- Bongini, P.; Scarselli, F.; Bianchini, M.; Dimitri, G.M.; Pancino, N.; Lio, P. Modular Multi-Source Prediction of Drug Side-Effects With DruGNN. IEEE-ACM Trans. Comput. Biol. Bioinform. 2023, 20, 1211–1220. [Google Scholar] [CrossRef] [PubMed]
- Mizutani, S.; Pauwels, E.; Stoven, V.; Goto, S.; Yamanishi, Y. Relating drug-protein interaction network with drug side-effects. Bioinformatics 2012, 28, I522–I528. [Google Scholar] [CrossRef]
- Liu, M.; Wu, Y.; Chen, Y.; Sun, J.; Zhao, Z.; Chen, X.w.; Matheny, M.E.; Xu, H. Large-scale prediction of adverse drug reactions using chemical, biological, and phenotypic properties of drugs. J. Am. Med. Inform. Assoc. 2012, 19, E28–E35. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, F.; Luo, L.; Zhang, J. Predicting drug side-effects by multi-label learning and ensemble learning. BMC Bioinform. 2015, 16, 365. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Tang, J.; Guo, F. Identification of drug-side-effect association via multiple information integration with centered kernel alignment. Neurocomputing 2019, 325, 211–224. [Google Scholar] [CrossRef]
- Xian, Z.; Lei, C.; Jing, L. A similarity-based method for prediction of drug side-effects with heterogeneous information. Math. Biosci. 2018, 306, 136–144. [Google Scholar]
- Hu, B.; Wang, H.; Yu, Z. Drug Side-Effect Prediction Via Random Walk on the Signed Heterogeneous Drug Network. Molecules 2019, 24, 3668. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, X.; Chen, Y.; Wu, W.; Wang, W.; Li, X. Feature-derived graph regularized matrix factorization for predicting drug side-effects. Neurocomputing 2018, 287, 154–162. [Google Scholar] [CrossRef]
- Galeano, D.; Li, S.; Gerstein, M.; Paccanaro, A. Predicting the frequencies of drug side-effects. Nat. Commun. 2020, 11, 4575. [Google Scholar] [CrossRef] [PubMed]
- Guo, X.; Zhou, W.; Yu, Y.; Ding, Y.; Tang, J.; Guo, F. A Novel Triple Matrix Factorization Method for Detecting Drug-Side Effect Association Based on Kernel Target Alignment. Biomed Res. Int. 2020, 2020, 4675395. [Google Scholar] [CrossRef] [PubMed]
- Mohsen, A.; Tripathi, L.P.; Mizuguchi, K. Deep Learning Prediction of Adverse Drug Reactions in Drug Discovery Using Open TG–GATEs and FAERS Databases. Front. Drug Discov. 2021, 1, 768792. [Google Scholar] [CrossRef]
- Zhao, H.; Zheng, K.; Li, Y.; Wang, J. A novel graph attention model for predicting frequencies of drug-side effects from multi-view data. Briefings Bioinform. 2021, 22, bbab239. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, S.; Zheng, K.; Zhao, Q.; Zhu, F.; Wang, J. A similarity-based deep learning approach for determining the frequencies of drug side-effects. Briefings Bioinform. 2022, 23, bbab449. [Google Scholar] [CrossRef]
- Xuan, P.; Wang, M.; Liu, Y.; Wang, D.; Zhang, T.; Nakaguchi, T. Integrating specific and common topologies of heterogeneous graphs and pairwise attributes for drug-related side-effect prediction. Briefings Bioinform. 2022, 23, bbac126. [Google Scholar] [CrossRef]
- Yu, L.; Cheng, M.; Qiu, W.; Xiao, X.; Lin, W. idse-HE: Hybrid embedding graph neural network for drug side-effects prediction. J. Biomed. Inform. 2022, 131, 104098. [Google Scholar] [CrossRef]
- Kuhn, M.; Letunic, I.; Jensen, L.J.; Bork, P. The SIDER database of drugs and side-effects. Nucleic Acids Res. 2016, 44, D1075–D1079. [Google Scholar] [CrossRef]
- Davis, A.P.; Grondin, C.J.; Johnson, R.J.; Sciaky, D.; Wiegers, J.; Wiegers, T.C.; Mattingly, C.J. Comparative Toxicogenomics Database (CTD): Update 2021. Nucleic Acids Res. 2021, 49, D1138–D1143. [Google Scholar] [CrossRef]
- Luo, Y.; Zhao, X.; Zhou, J.; Yang, J.; Zhang, Y.; Kuang, W.; Peng, J.; Chen, L.; Zeng, J. A network integration approach for drug-target interaction prediction and computational drug repositioning from heterogeneous information. Nat. Commun. 2017, 8, 573. [Google Scholar] [CrossRef]
- Wang, D.; Wang, J.; Lu, M.; Song, F.; Cui, Q. Inferring the human microRNA functional similarity and functional network based on microRNA-associated diseases. Bioinformatics 2010, 26, 1644–1650. [Google Scholar] [CrossRef] [PubMed]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the Conference on Machine Learning 2010, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Hajian-Tilaki, K. Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation. Casp. J. Intern. Med. 2013, 4, 627–635. [Google Scholar]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A better measure than accuracy in comparing learning algorithms. In Proceedings of the Conference of the Canadian Society for Computational Studies of Inteligence 2003, Halifax, NS, Canada, 11–13 June 2003; pp. 329–341. [Google Scholar]
- Saito, T.; Rehmsmeier, M. The Precision-Recall Plot Is More Informative than the ROC Plot When Evaluating Binary Classifiers on Imbalanced Datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [PubMed]
- Kanagali, S.N.; Patil, B.M.; Khanal, P.; Unger, B.S. Cyperus rotundus L. reverses the olanzapine-induced weight gain and metabolic changes-outcomes from network and experimental pharmacology. Comput. Biol. Med. 2022, 141, 105035. [Google Scholar] [CrossRef] [PubMed]
- Iqbal, E.; Govind, R.; Romero, A.; Dzahini, O.; Broadbent, M.; Stewart, R.; Smith, T.; Kim, C.H.; Werbeloff, N.; MacCabe, J.H.; et al. The side-effect profile of Clozapine in real world data of three large mental health hospitals. PLoS ONE 2020, 15, e0243437. [Google Scholar] [CrossRef]
- Yu, Z.; Wu, Z.; Li, W.; Liu, G.; Tang, Y. MetaADEDB 2.0: A comprehensive database on adverse drug events. Bioinformatics 2021, 37, 2221–2222. [Google Scholar] [CrossRef]
- Steigerwalt, K. Online Drug Information Resources. Choice 2015, 52, 1601–1611. [Google Scholar] [CrossRef]
- Avram, S.; Bologa, C.G.; Holmes, J.; Bocci, G.; Wilson, T.B.; Nguyen, D.T.; Curpan, R.; Halip, L.; Bora, A.; Yang, J.J.; et al. DrugCentral 2021 supports drug discovery and repositioning. Nucleic Acids Res. 2021, 49, D1160–D1169. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CET | MVF | NCA | Average AUC | Average AUPR |
|---|---|---|---|---|
| ✕ | ✓ | ✕ | 0.963 | 0.209 |
| ✓ | ✕ | ✓ | 0.971 | 0.254 |
| ✓ | ✓ | ✕ | 0.976 | 0.298 |
| ✓ | ✓ | ✓ | 0.977 | 0.351 |
| GCRS | idse-HE | SDPred | Ding’s Method | FGRMF | Galeaon’s Method | RW-SHIN | |
|---|---|---|---|---|---|---|---|
| p-value of AUC | 8.4303 × 10 | 2.6327 × 10 | 4.7184 × 10 | 3.4493 × 10 | 1.8906 × 10 | 4.9532 × 10 | 2.5631 × 10 |
| p-value of AUPR | 2.6205 × 10 | 1.3362 × 10 | 5.3927 × 10 | 4.6451 × 10 | 2.2247 × 10 | 3.7876 × 10 | 4.8253 × 10 |
| Drug | Rank | Side-Effect | Evidence | Rank | Side-Effect | Evidence |
|---|---|---|---|---|---|---|
| 1 | Edema | Drugcentral, MetaADEDB, SIDER | 9 | Diarrhea | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 2 | Nausea | MetaADEDB, Rxlist, SIDER | 10 | Hypotension | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 3 | Vomiting | Drugcentral, MetaADEDB, Rxlist, SIDER | 11 | Confusion | Drugcentral, Rxlist, SIDER | |
| Amitriptyline | 4 | Rash | Drugcentral, MetaADEDB, Rxlist, SIDER | 12 | Leukopenia | Drugcentral, MetaADEDB, Rxlist, SIDER |
| 5 | Dizziness | Drugcentral, MetaADEDB, Rxlist, SIDER | 13 | Constipation | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 6 | Blurred vision | Drugcentral, MetaADEDB, Rxlist | 14 | Paresthesia | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 7 | Anorexia | MetaADEDB, Rxlist, SIDER | 15 | Syncope | MetaADEDB, Rxlist, SIDER | |
| 8 | Headache | Drugcentral, MetaADEDB, Rxlist, SIDER |
| Drug | Rank | Side-Effect | Evidence | Rank | Side-Effect | Evidence |
|---|---|---|---|---|---|---|
| 1 | Edema | Drugcentral, MetaADEDB, Rxlist, SIDER | 9 | Paresthesia | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 2 | Vomiting | Rxlist, MetaADEDB, Rxlist, SIDER, Literature [36] | 10 | Dizziness | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 3 | Headache | Drugcentral, MetaADEDB, Rxlist, SIDER | 11 | Back pain | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| Olanzapine | 4 | Nausea | Drugcentral, MetaADEDB, Rxlist, SIDER | 12 | Pruritus | Drugcentral, MetaADEDB, Rxlist, SIDER |
| 5 | Rash | Drugcentral, MetaADEDB, Rxlist, SIDER | 13 | Dry mouth | Rxlist, SIDER | |
| 6 | Confusion | Drugcentral, Rxlist, SIDER | 14 | Cough | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 7 | Diarrhea | Drugcentral, Rxlist, SIDER | 15 | Arthralgia | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 8 | Constipation | MetaADEDB, Rxlist, SIDER, Literature [36] |
| Drug | Rank | Side-Effect | Evidence | Rank | Side-Effect | Evidence |
|---|---|---|---|---|---|---|
| 1 | Edema | Drugcentral, MetaADEDB, Rxlist, SIDER | 9 | Vomiting | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 2 | Nausea | Drugcentral, MetaADEDB, Rxlist, SIDER | 10 | Rash | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 3 | Pruritus | Drugcentral, MetaADEDB, SIDER | 11 | Blurred vision | Rxlist, Literature [37] | |
| Clozapine | 4 | Diarrhea | Drugcentral, MetaADEDB, Rxlist, SIDER | 12 | Headache | Drugcentral, MetaADEDB, Rxlist, SIDER |
| 5 | Anemia | Drugcentral, SIDER | 13 | Thrombocytopenia | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 6 | Paresthesia | Drugcentral, Rxlist, SIDER | 14 | Nervousness | Drugcentral, MetaADEDB | |
| 7 | Pain | Drugcentral, MetaADEDB, Rxlist, SIDER | 15 | Dizziness | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 8 | Anorexia | MetaADEDB, Rxlist, SIDER |
| Drug | Rank | Side-Effect | Evidence | Rank | Side-Effect | Evidence |
|---|---|---|---|---|---|---|
| 1 | Edema | Drugcentral, MetaADEDB, Rxlist, SIDER | 9 | Tachycardia | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 2 | Headache | Drugcentral, MetaADEDB, Rxlist, SIDER | 10 | Blurred vision | Drugcentral, MetaADEDB, Rxlist | |
| 3 | Rash | Drugcentral, MetaADEDB, Rxlist, SIDER | 11 | Dyspepsia | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| Aripiprazole | 4 | Dizziness | MetaADEDB, MetaADEDB, Rxlist, SIDER | 12 | Chest pain | Drugcentral, MetaADEDB, Rxlist, SIDER |
| 5 | Nervousness | Drugcentral, MetaADEDB, SIDER | 13 | Hemorrhage | MetaADEDB | |
| 6 | Infection | Drugcentral, MetaADEDB, Rxlist, SIDER | 14 | Hypersensitivity | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 7 | Constipation | Drugcentral, MetaADEDB, Rxlist, SIDER | 15 | Fatigue | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 8 | Back pain | Drugcentral, MetaADEDB, SIDER |
| Drug | Rank | Side-Effect | Evidence | Rank | Side-Effect | Evidence |
|---|---|---|---|---|---|---|
| 1 | Edema | MetaADEDB, Rxlist, SIDER | 9 | Dyspnea | Rxlist, SIDER | |
| 2 | Vomiting | Rxlist, SIDER | 10 | Constipation | MetaADEDB, Rxlist, SIDER | |
| 3 | Headache | MetaADEDB, Rxlist, SIDER | 11 | Confusion | Rxlist | |
| Asenapine | 4 | Pain | MetaADEDB, Rxlist, SIDER | 12 | Blurred vision | unconfirmed |
| 5 | Nausea | MetaADEDB, Rxlist, SIDER | 13 | Fatigue | Drugcentral, MetaADEDB, Rxlist, SIDER | |
| 6 | Dizziness | MetaADEDB, Rxlist, SIDER | 14 | Anorexia | unconfirmed | |
| 7 | Rash | Rxlist, SIDER | 15 | Pruritus | unconfirmed | |
| 8 | Diarrhea | Drugcentral, Rxlist |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xuan, P.; Li, P.; Cui, H.; Wang, M.; Nakaguchi, T.; Zhang, T. Learning Multi-Types of Neighbor Node Attributes and Semantics by Heterogeneous Graph Transformer and Multi-View Attention for Drug-Related Side-Effect Prediction. Molecules 2023, 28, 6544. https://doi.org/10.3390/molecules28186544
Xuan P, Li P, Cui H, Wang M, Nakaguchi T, Zhang T. Learning Multi-Types of Neighbor Node Attributes and Semantics by Heterogeneous Graph Transformer and Multi-View Attention for Drug-Related Side-Effect Prediction. Molecules. 2023; 28(18):6544. https://doi.org/10.3390/molecules28186544
Chicago/Turabian StyleXuan, Ping, Peiru Li, Hui Cui, Meng Wang, Toshiya Nakaguchi, and Tiangang Zhang. 2023. "Learning Multi-Types of Neighbor Node Attributes and Semantics by Heterogeneous Graph Transformer and Multi-View Attention for Drug-Related Side-Effect Prediction" Molecules 28, no. 18: 6544. https://doi.org/10.3390/molecules28186544