

A Novel Variable Selection Method Based on Binning-Normalized Mutual Information for Multivariate Calibration
 ,
,
Abstract
:1. Introduction
2. Results and Discussion
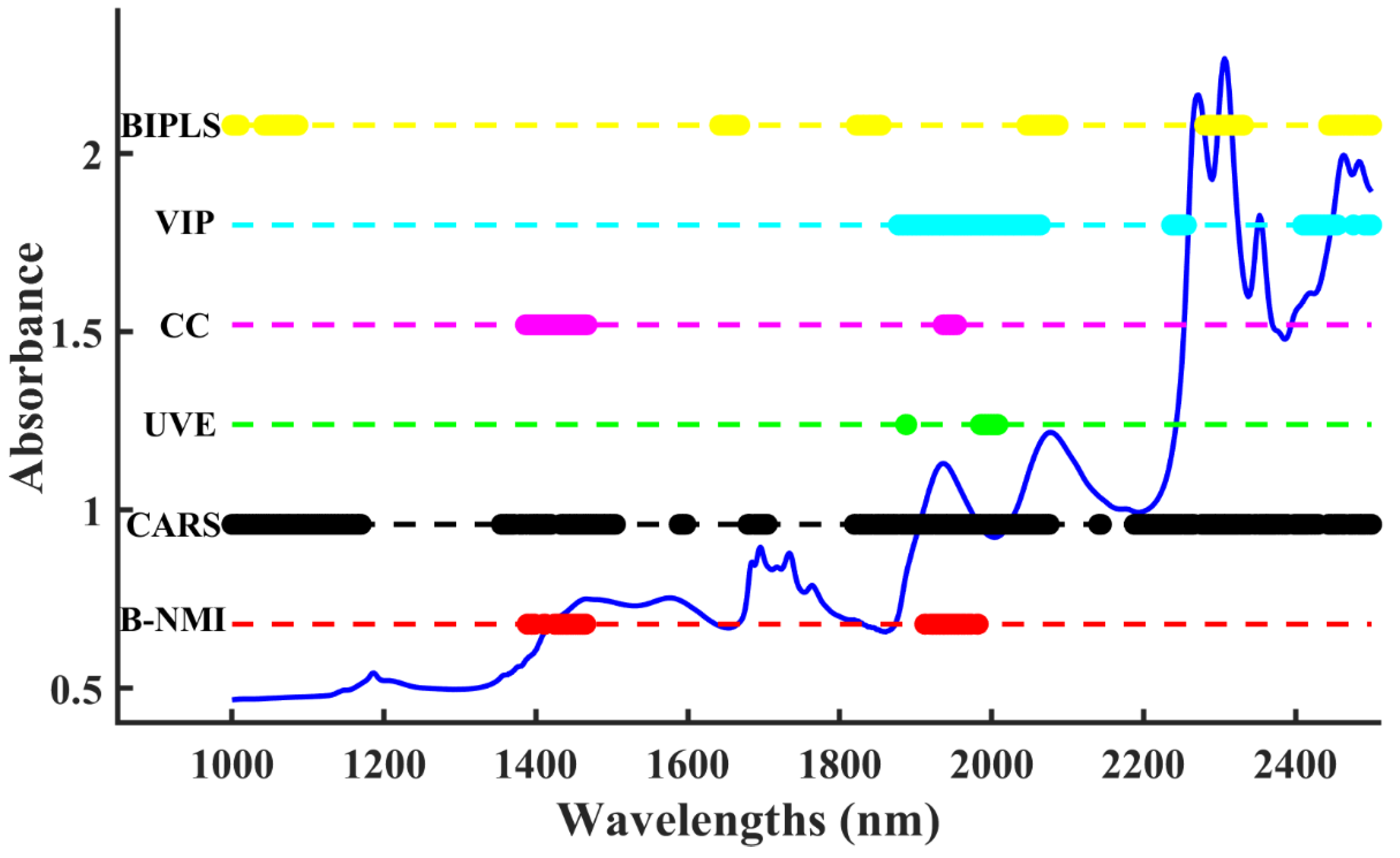
2.1. Model Analysis of Ideal Ternary Solvent Mixture Dataset
2.2. Model Analysis of Fluidized Bed Granulation Dataset
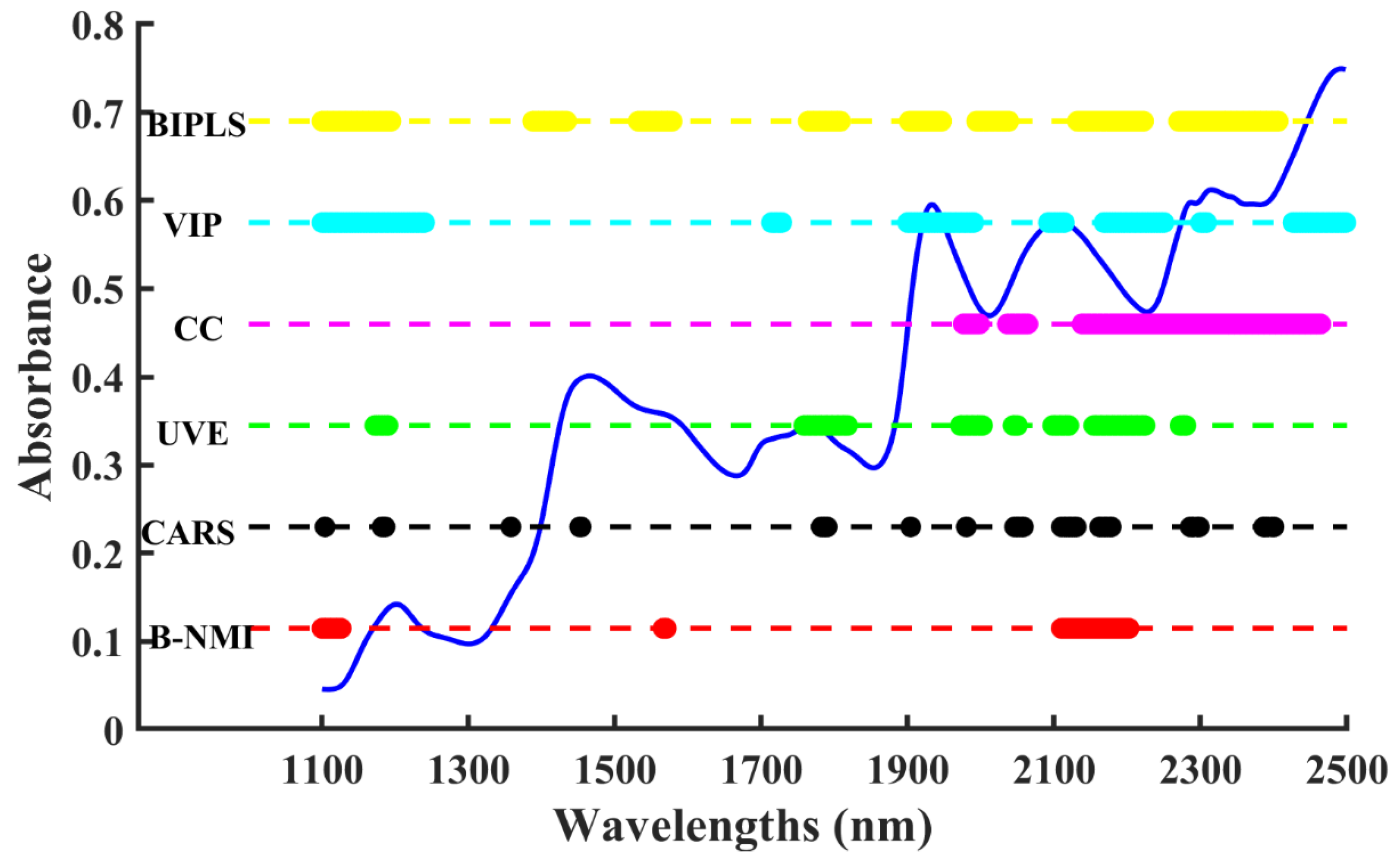
2.3. Model Analysis of Gasoline Octane Dataset
2.4. Model Analysis of Corn Protein Dataset
3. Theory and Algorithms
3.1. Data Binning
3.2. Mutual Information (MI)
3.3. Normalized Mutual Information (NMI)
3.4. Evaluation Criteria
4. Datasets
4.1. Ideal Ternary Solvent Mixture Dataset
4.2. Fluidized Bed Granulation Dataset
4.3. Gasoline Octane Dataset
4.4. Corn Protein Dataset
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Shepherd, K.D.; Walsh, M.G. Infrared spectroscopy—Enabling an evidence-based diagnostic surveillance approach to agricultural and environmental management in developing countries. J. Near Infrared Spectrosc. 2007, 15, 1–19. [Google Scholar] [CrossRef]
- Stenberg, B.; Rossel, R.A.V.; Mouazen, A.M.; Wetterlind, J. Visible and near infrared spectroscopy in soil science. In Advances in Agronomy; Sparks, D.L., Ed.; Elsevier: Amsterdam, The Netherlands, 2010; Volume 107, pp. 163–215. [Google Scholar]
- Meher, L.C.; Sagar, D.V.; Naik, S.N. Technical aspects of biodiesel production by transesterification—A review. Renew. Sustain. Energy Rev. 2006, 10, 248–268. [Google Scholar] [CrossRef]
- Murugesan, A.; Umarani, C.; Chinnusamy, T.R.; Krishnan, M.; Subramanian, R.; Neduzchezhain, N. Production and analysis of bio-diesel from non-edible oils—A review. Renew. Sustain. Energy Rev. 2009, 13, 825–834. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, H.; Zhong, L.; Liu, L.; Huang, R.; Zhang, H.; Xu, D.; Yin, W.; Li, L.; Zang, H. Evaluation and Monitoring of the API Content of a Portable Near Infrared Instrument Combined with Chemometrics Based on Fluidized Bed Mixing Process. J. Pharm. Innov. 2021, 17, 1136–1147. [Google Scholar] [CrossRef]
- Zhong, L.; Gao, L.; Li, L.; Nei, L.; Wei, Y.; Zhang, K.; Zhang, H.; Yin, W.; Xu, D.; Zang, H. Method development and validation of a near-infrared spectroscopic method for in-line API quantification during fluidized bed granulation. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 274, 121078. [Google Scholar] [CrossRef] [PubMed]
- Zhong, L.; Gao, L.; Li, L.; Zang, H. Trends-process analytical technology in solid oral dosage manufacturing. Eur. J. Pharm. Biopharm. 2020, 153, 187–199. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Liu, L.; Yang, C.; Sun, Z.; Xu, X.; Li, L.; Zang, H. Research on the Structure of Peanut Allergen Protein Ara h1 Based on Aquaphotomics. Front. Nutr. 2021, 8, 696355. [Google Scholar] [CrossRef]
- Wu, S.; Wang, L.; Zhou, G.; Liu, C.; Ji, Z.; Li, Z.; Li, W. Strategies for the content determination of capsaicin and the identification of adulterated pepper powder using a hand-held near-infrared spectrometer. Food Res. Int. 2023, 163, 112192. [Google Scholar] [CrossRef]
- Schwanninger, M.; Rodrigues, J.C.; Fackler, K. A review of band assignments in near infrared spectra of wood and wood components. J. Near Infrared Spectrosc. 2011, 19, 287–308. [Google Scholar] [CrossRef]
- Gao, L.; Zhong, L.; Zhang, J.; Zhang, M.; Zeng, Y.; Li, L.; Zang, H. Water as a probe to understand the traditional Chinese medicine extraction process with near infrared spectroscopy: A case of Danshen (Salvia miltiorrhiza Bge) extraction process. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 244, 118854. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, X.; Li, L.; Li, H.; Gao, L.; Yuan, X.; Du, H.; Guan, Y.; Zang, H. Multi critical quality attributes monitoring of Chinese oral liquid extraction process with a spectral sensor fusion strategy. Spectrochim. Acta. Part A Mol. Biomol. Spectrosc. 2022, 278, 121317. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Liu, D.; Du, C.; Lin, L.; Zhu, J.; Huang, X.; Liao, Y.; Wu, Z. Novel NIR modeling design and assignment in process quality control of Honeysuckle flower by QbD. Spectrochim. Acta Part A-Mol. Biomol. Spectrosc. 2020, 242, 118740. [Google Scholar] [CrossRef] [PubMed]
- Nystrom, J.; Dahlquist, E. Methods for determination of moisture content in woodchips for power plants—A review. Fuel 2004, 83, 773–779. [Google Scholar] [CrossRef]
- Dong, Q.; Yu, C.; Li, L.; Nie, L.; Zhang, H.; Zang, H. Analysis of hydration water around human serum albumin using near-infrared spectroscopy. Int. J. Biol. Macromol. 2019, 138, 927–932. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.; Yu, C.; Zhang, M.; Yang, X.; Dong, H.; Dong, Q.; Zhang, H.; Li, L.; Guo, X.; Zang, H. Investigation of protective effect of ethanol on the natural structure of protein with infrared spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 271, 120935. [Google Scholar] [CrossRef]
- Fan, M.; Cai, W.; Shao, X. Investigating the Structural Change in Protein Aqueous Solution Using Temperature-Dependent Near-Infrared Spectroscopy and Continuous Wavelet Transform. Appl. Spectrosc. 2017, 71, 472–479. [Google Scholar] [CrossRef]
- Han, L.; Cui, X.; Cai, W.; Shao, X. Three-level simultaneous component analysis for analyzing the near-infrared spectra of aqueous solutions under multiple perturbations. Talanta 2020, 217, 121036. [Google Scholar] [CrossRef]
- Serebryanskaya, T.V.; Novikov, A.S.; Gushchin, P.V.; Haukka, M.; Asfin, R.E.; Tolstoy, P.M.; Kukushkin, V.Y. Identification and H (D)-bond energies of C–H (D)⋯ Cl interactions in chloride–haloalkane clusters: A combined X-ray crystallographic, spectroscopic, and theoretical study. Phys. Chem. Chem. Phys. 2016, 18, 14104–14112. [Google Scholar] [CrossRef] [Green Version]
- Ostras’, A.S.; Ivanov, D.M.; Novikov, A.S.; Tolstoy, P.M. Phosphine oxides as spectroscopic halogen bond descriptors: IR and NMR correlations with interatomic distances and complexation energy. Molecules 2020, 25, 1406. [Google Scholar] [CrossRef] [Green Version]
- Novikov, A.S. 1, 3-Dipolar cycloaddition of nitrones to transition metal-bound isocyanides: DFT and HSAB principle theoretical model together with analysis of vibrational spectra. J. Organomet. Chem. 2015, 797, 8–12. [Google Scholar] [CrossRef]
- Il’in, M.V.; Novikov, A.S.; Bolotin, D.S. Aminonitrone–iminohydroxamic acid tautomerism: Theoretical and spectroscopic study. J. Mol. Struct. 2019, 1176, 759–765. [Google Scholar] [CrossRef]
- Usoltsev, A.N.; Novikov, A.S.; Kolesov, B.A.; Chernova, K.V.; Plyusnin, P.E.; Fedin, V.P.; Sokolov, M.N.; Adonin, S.A. Halogen··· halogen contacts in triiodide salts of pyridinium-derived cations: Theoretical and spectroscopic studies. J. Mol. Struct. 2020, 1209, 127949. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H. Estimating optimal transformations for multiple regression. J. Am. Stat. Assoc. 1985, 80, 121–134. [Google Scholar] [CrossRef]
- De Maesschalck, R.; Estienne, F.; Verdu-Andres, J.; Candolfi, A.; Centner, V.; Despagne, F.; Jouan-Rimbaud, D.; Walczak, B.; Massart, D.L.; de Jong, S.; et al. The development of calibration models for spectroscopic data using principal component regression. Internet J. Chem. 1999, 2, 1. [Google Scholar]
- Sanchez, F.C.; Vandeginste, B.G.M.; Hancewicz, T.M.; Massart, D.L. Resolution of complex liquid chromatography Fourier transform infrared spectroscopy data. Anal. Chem. 1997, 69, 1477–1484. [Google Scholar] [CrossRef]
- Geladi, P.; Kowalski, B.R. Partial least-squares regression—A tutorial. Anal. Chim. Acta 1986, 185, 1–17. [Google Scholar] [CrossRef]
- Gemperline, P.J.; Webber, L.D.; Cox, F.O. Raw-materials testing using soft independent modeling of class analogy analysis of near-infrared reflectance spectra. Anal. Chem. 1989, 61, 138–144. [Google Scholar] [CrossRef]
- Zou, X.; Zhao, J.; Povey, M.J.W.; Holmes, M.; Mao, H. Variables selection methods in near-infrared spectroscopy. Anal. Chim. Acta 2010, 667, 14–32. [Google Scholar] [CrossRef]
- Wold, J.P.; Jakobsen, T.; Krane, L. Atlantic salmon average fat content estimated by near-infrared transmittance spectroscopy. J. Food Sci. 1996, 61, 74–77. [Google Scholar] [CrossRef]
- Yun, Y.-H.; Li, H.-D.; Deng, B.-C.; Cao, D.-S. An overview of variable selection methods in multivariate analysis of near-infrared spectra. Trac Trends Anal. Chem. 2019, 113, 102–115. [Google Scholar] [CrossRef]
- Chong, I.G.; Jun, C.H. Performance of some variable selection methods when multicollinearity is present. Chemom. Intell. Lab. Syst. 2005, 78, 103–112. [Google Scholar] [CrossRef]
- Norgaard, L.; Saudland, A.; Wagner, J.; Nielsen, J.P.; Munck, L.; Engelsen, S.B. Interval partial least-squares regression (iPLS): A comparative chemometric study with an example from near-infrared spectroscopy. Appl. Spectrosc. 2000, 54, 413–419. [Google Scholar] [CrossRef]
- Yang, Z.; Xiao, H.; Zhang, L.; Feng, D.; Zhang, F.; Jiang, M.; Sui, Q.; Jia, L. Fast determination of oxides content in cement raw meal using NIR-spectroscopy and backward interval PLS with genetic algorithm. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 223, 117327. [Google Scholar] [CrossRef] [PubMed]
- Jiang, W.; Lu, C.; Zhang, Y.; Ju, W.; Wang, J.; Xiao, M. Molecular spectroscopic wavelength selection using combined interval partial least squares and correlation coefficient optimization. Anal. Methods 2019, 11, 3108–3116. [Google Scholar] [CrossRef]
- Xu, W.; Sun, T.; Wu, W.; Hu, T.; Hu, T.; Liu, M. Determination of Soluble Solids Content in Cuiguan Pear by Vis/NIR Diffuse Transmission Spectroscopy and Variable Selection Methods. In Proceedings of the 8th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Shenzhen, China, 20–23 November 2014; pp. 269–276. [Google Scholar]
- Zhang, F.; Tang, X.-J.; Tong, A.-X.; Wang, B.; Wang, J.-W. A near infrared wavelength selection method based on the variable stability and population analysis. J. Infrared Millim. Waves 2020, 39, 318–323. [Google Scholar] [CrossRef]
- Zhao, Z.-Y.; Lin, J.; Zhang, F.-D.; Li, J. Research on Wavelength Variates Selection Methods for Determination of Oil Yield in Oil Shales using Near-Infrared Spectroscopy. Spectrosc. Spectr. Anal. 2014, 34, 2948–2952. [Google Scholar] [CrossRef]
- Centner, V.; Massart, D.L.; de Noord, O.E.; de Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of uninformative variables for multivariate calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef]
- Huang, J.; Cai, Y.; Xu, X. A hybrid genetic algorithm for feature selection wrapper based on mutual information. Pattern Recognit. Lett. 2007, 28, 1825–1844. [Google Scholar] [CrossRef]
- Battiti, R. Using Mutual Information for Selecting Features in Supervised Neural-Net Learning. IEEE Trans. Neural Netw. 1994, 5, 537–550. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Xu, Q. Attribute selection based on information gain ratio in fuzzy rough set theory with application to tumor classification. Appl. Soft Comput. 2013, 13, 211–221. [Google Scholar] [CrossRef]
- Huang, D.; Chow, T.W.S. Effective feature selection scheme using mutual information. Neurocomputing 2005, 63, 325–343. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, H.; Chen, Y.; Tan, K.; Wang, L.; Xie, W. Neighborhood mutual information and its application on hyperspectral band selection for classification. Chemom. Intell. Lab. Syst. 2016, 157, 140–151. [Google Scholar] [CrossRef]
- Benoudjit, N.; Francois, D.; Meurens, M.; Verleysen, M. Spectrophotometric variable selection by mutual information. Chemom. Intell. Lab. Syst. 2004, 74, 243–251. [Google Scholar] [CrossRef]
- Thomas, M.; Joy, A.T. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Muncan, J.; Tsenkova, R. Aquaphotomics-From Innovative Knowledge to Integrative Platform in Science and Technology. Molecules 2019, 24, 2742. [Google Scholar] [CrossRef] [Green Version]
- Buschmueller, C.; Wiedey, W.; Doescher, C.; Dressler, J.; Breitkreutz, J. In-line monitoring of granule moisture in fluidized-bed dryers using microwave resonance technology. Eur. J. Pharm. Biopharm. 2008, 69, 380–387. [Google Scholar] [CrossRef]
- Chablani, L.; Taylor, M.K.; Mehrotra, A.; Rameas, P.; Stagner, W.C. Inline Real-Time Near-Infrared Granule Moisture Measurements of a Continuous Granulation-Drying-Milling Process. AAPS PharmSciTech 2011, 12, 1050–1055. [Google Scholar] [CrossRef] [Green Version]
- Dawoodbhai, S.; Rhodes, C.T. The effect of moisture on powder flow and on compaction and physical stability of tablets. Drug Dev. Ind. Pharm. 1989, 15, 1577–1600. [Google Scholar] [CrossRef]
- Anderson, J.E.; DiCicco, D.M.; Ginder, J.M.; Kramer, U.; Leone, T.G.; Raney-Pablo, H.E.; Wallington, T.J. High octane number ethanol-gasoline blends: Quantifying the potential benefits in the United States. Fuel 2012, 97, 585–594. [Google Scholar] [CrossRef]
- Zanier, N. Prediction of the refractive index of hydrotreated gas oils with near infrared spectroscopy. In Near Infrared Spectroscopy: The Future Waves; NIR Publications: Chichester, UK, 1996; pp. 662–667. [Google Scholar]
- Sun, Z.; Nie, L.; Li, L.; Wang, J.; Li, W.; Cao, D.; Wang, H.; Du, R.; Liu, R.; Quan, S.; et al. Data mean and ratio of absorbance to concentration methods: A novel optimization strategy for near infrared spectroscopy modeling. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 215, 69–80. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Wang, Z.-B. Cross components calibration transfer of NIR spectroscopy Model through PCA and weighted ELM-based TrAdaBoost algorithm. Chemom. Intell. Lab. Syst. 2019, 192, 103824. [Google Scholar] [CrossRef]
- Gamal Al-Kaf, H.A.; Mohammed Alduais, N.A.; Saad, A.-M.H.Y.; Chia, K.S.; Mohsen, A.M.; Alhussian, H.; Haidar Mahdi, A.A.M.; Wan Salam, W.S.-I. A Bootstrapping Soft Shrinkage Approach and Interval Random Variables Selection Hybrid Model for Variable Selection in Near-Infrared Spectroscopy. IEEE Access 2020, 8, 168036–168052. [Google Scholar] [CrossRef]
- Bai, S.J.; Nayar, R.; Carpenter, J.F.; Manning, M.C. Noninvasive determination of protein conformation in the solid state using near infrared (NIR) spectroscopy. J. Pharm. Sci. 2005, 94, 2030–2038. [Google Scholar] [CrossRef] [PubMed]
- Laporte, M.F.; Paquin, P. Near-infrared analysis of fat, protein, and casein in cow’s milk. J. Agric. Food Chem. 1999, 47, 2600–2605. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Sowa, M.G.; Ahmed, M.K.; Mantsch, H.H. Photoacoustic near-infrared investigation of homo-polypeptides. J. Phys. Chem. 1994, 98, 4748–4755. [Google Scholar] [CrossRef]
- Fatemi, A.; Singh, V.; Kamruzzaman, M. Identification of informative spectral ranges for predicting major chemical constituents in corn using NIR spectroscopy. Food Chem. 2022, 383, 132442. [Google Scholar] [CrossRef]
- Haaland, D.M.; Thomas, E.V. Partial least-squares methods for spectral analyses. 1. Relation to other quantitative calibration methods and the extraction of qualitative information. Anal. Chem. 1988, 60, 1193–1202. [Google Scholar] [CrossRef]
- Clarke, E.J.; Barton, B.A. Entropy and MDL discretization of continuous variables for Bayesian belief networks. Int. J. Intell. Syst. 2000, 15, 61–92. [Google Scholar] [CrossRef]
- Rahmanian, M.; Mansoori, E.G. An unsupervised gene selection method based on multivariate normalized mutual information of genes. Chemom. Intell. Lab. Syst. 2022, 222, 104512. [Google Scholar] [CrossRef]
- Sosa-Cabrera, G.; Garcia-Torres, M.; Gomez-Guerrero, S.; Schaerer, C.E.; Divina, F. A multivariate approach to the symmetrical uncertainty measure: Application to feature selection problem. Inf. Sci. 2019, 494, 1–20. [Google Scholar] [CrossRef]
- Kalivas, J.H. Two data sets of near infrared spectra. Chemom. Intell. Lab. Syst. 1997, 37, 255–259. [Google Scholar] [CrossRef]
- Galvao, R.K.H.; Araujo, M.C.U.; Jose, G.E.; Pontes, M.J.C.; Silva, E.C.; Saldanha, T.C.B. A method for calibration and validation subset partitioning. Talanta 2005, 67, 736–740. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | R2C | R2P | RMSEC | RMSECV | RMSEP | RPD | Bias | Number of Variables | LVs |
|---|---|---|---|---|---|---|---|---|---|
| FULL-PLSR | 0.986 | 0.965 | 0.00401 | 0.00470 | 0.00430 | 5.499 | −0.003 | 1557 | 3 |
| VIP-PLSR | 0.985 | 0.970 | 0.00414 | 0.00454 | 0.00399 | 5.927 | −0.003 | 164 | 3 |
| CC-PLSR | 0.985 | 0.971 | 0.00412 | 0.00456 | 0.00387 | 6.107 | −0.003 | 116 | 3 |
| UVE-PLSR | 0.985 | 0.978 | 0.00424 | 0.00457 | 0.00340 | 6.950 | −0.002 | 18 | 2 |
| CARS-PLSR | 0.986 | 0.966 | 0.00403 | 0.00459 | 0.00419 | 5.642 | −0.003 | 866 | 3 |
| BIPLS | 0.985 | 0.966 | 0.00420 | 0.00435 | 0.00420 | 5.572 | −0.004 | 259 | 2 |
| B-NMI-PLSR | 0.985 | 0.976 | 0.00412 | 0.00476 | 0.00354 | 6.679 | −0.002 | 95 | 3 |
| Models | R2C | R2P | RMSEC | RMSECV | RMSEP | RPD | Bias | Number of Variables | LVs |
|---|---|---|---|---|---|---|---|---|---|
| FULL-PLSR | 0.976 | 0.966 | 0.312 | 0.322 | 0.380 | 5.438 | −0.040 | 125 | 5 |
| VIP-PLSR | 0.974 | 0.965 | 0.325 | 0.333 | 0.387 | 5.345 | −0.061 | 40 | 4 |
| CC- PLSR | 0.977 | 0.968 | 0.308 | 0.321 | 0.367 | 5.626 | −0.025 | 41 | 5 |
| UVE-PLSR | 0.975 | 0.970 | 0.318 | 0.326 | 0.356 | 5.813 | −0.017 | 18 | 5 |
| CARS-PLSR | 0.978 | 0.968 | 0.303 | 0.312 | 0.370 | 5.581 | −0.036 | 26 | 5 |
| BIPLS | 0.978 | 0.969 | 0.303 | 0.296 | 0.362 | 5.709 | −0.097 | 19 | 5 |
| B-NMI-PLSR | 0.977 | 0.972 | 0.308 | 0.316 | 0.343 | 6.027 | 0.021 | 9 | 5 |
| Models | R2C | R2P | RMSEC | RMSECV | RMSEP | RPD | Bias | Number of Variables | LVs |
|---|---|---|---|---|---|---|---|---|---|
| FULL-PLSR | 0.990 | 0.987 | 0.150 | 0.252 | 0.180 | 9.013 | 0.000 | 401 | 6 |
| VIP-PLSR | 0.988 | 0.986 | 0.165 | 0.260 | 0.184 | 8.808 | −0.001 | 82 | 6 |
| CC-PLSR | 0.987 | 0.989 | 0.171 | 0.288 | 0.165 | 9.873 | 0.005 | 20 | 7 |
| UVE-PLSR | 0.987 | 0.987 | 0.171 | 0.216 | 0.180 | 9.015 | 0.001 | 217 | 4 |
| CARS-PLSR | 0.989 | 0.978 | 0.159 | 0.187 | 0.240 | 6.950 | 0.041 | 7 | 4 |
| BIPLS | 0.978 | 0.992 | 0.218 | 0.221 | 0.144 | 11.313 | 0.053 | 162 | 3 |
| B-NMI-PLSR | 0.981 | 0.994 | 0.205 | 0.255 | 0.126 | 12.905 | 0.016 | 71 | 5 |
| Models | R2C | R2P | RMSEC | RMSECV | RMSEP | RPD | Bias | Number of Variables | LVs |
|---|---|---|---|---|---|---|---|---|---|
| FULL-PLSR | 0.958 | 0.879 | 0.106 | 0.151 | 0.146 | 2.951 | 0.028 | 700 | 8 |
| VIP-PLSR | 0.925 | 0.903 | 0.142 | 0.179 | 0.131 | 3.293 | 0.025 | 221 | 7 |
| CC- PLSR | 0.952 | 0.967 | 0.113 | 0.144 | 0.076 | 5.635 | −0.014 | 191 | 8 |
| UVE-PLSR | 0.971 | 0.985 | 0.088 | 0.117 | 0.051 | 8.411 | −0.005 | 114 | 7 |
| CARS-PLSR | 0.979 | 0.951 | 0.074 | 0.097 | 0.092 | 4.651 | 0.003 | 51 | 8 |
| BIPLS | 0.986 | 0.992 | 0.062 | 0.147 | 0.038 | 11.284 | 0.028 | 280 | 6 |
| B-NMI-PLSR | 0.987 | 0.993 | 0.059 | 0.077 | 0.035 | 12.446 | −0.003 | 64 | 7 |
| Methods | Datasets | |||
|---|---|---|---|---|
| Solvent Mixture | Granulation | Gasoline Octane | Corn Protein | |
| B-NMI vs. VIP p-values | 0.494 | 0.000 | 0.038 | 0.000 |
| B-NMI vs. CC p-values | 0.732 | 0.000 | 0.915 | 0.000 |
| B-NMI vs. UVE p-values | 0.947 | 0.028 | 0.042 | 0.000 |
| B-NMI vs. CARS p-values | 0.324 | 0.000 | 0.002 | 0.000 |
| B-NMI vs. BIPLS p-values | 0.026 | 0.000 | 0.002 | 0.000 |
| Data | N | Calibration Set | N | Validation Set | ||
|---|---|---|---|---|---|---|
| Mean ± SD | Range | Mean ± SD | Range | |||
| Solvent mixture | 36 | 0.07 ± 0.04 | 0.02–0.12 | 16 | 0.07 ± 0.02 | 0.03–0.10 |
| Granulation | 75 | 5.62 ± 2.03 | 3.27–11.83 | 60 | 5.88 ± 2.07 | 3.02–10.94 |
| Gasoline octane | 45 | 87.28 ± 1.50 | 83.40–89.60 | 15 | 86.87 ± 1.63 | 84.50–88.90 |
| Corn protein | 60 | 8.67 ± 0.52 | 7.65–9.71 | 20 | 8.68 ± 0.43 | 7.79–9.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhong, L.; Huang, R.; Gao, L.; Yue, J.; Zhao, B.; Nie, L.; Li, L.; Wu, A.; Zhang, K.; Meng, Z.; et al. A Novel Variable Selection Method Based on Binning-Normalized Mutual Information for Multivariate Calibration. Molecules 2023, 28, 5672. https://doi.org/10.3390/molecules28155672
Zhong L, Huang R, Gao L, Yue J, Zhao B, Nie L, Li L, Wu A, Zhang K, Meng Z, et al. A Novel Variable Selection Method Based on Binning-Normalized Mutual Information for Multivariate Calibration. Molecules. 2023; 28(15):5672. https://doi.org/10.3390/molecules28155672
Chicago/Turabian StyleZhong, Liang, Ruiqi Huang, Lele Gao, Jianan Yue, Bing Zhao, Lei Nie, Lian Li, Aoli Wu, Kefan Zhang, Zhaoqing Meng, and et al. 2023. "A Novel Variable Selection Method Based on Binning-Normalized Mutual Information for Multivariate Calibration" Molecules 28, no. 15: 5672. https://doi.org/10.3390/molecules28155672