
Biofilm-i: A Platform for Predicting Biofilm Inhibitors Using Quantitative Structure—Relationship (QSAR) Based Regression Models to Curb Antibiotic Resistance


Abstract
:1. Introduction
2. Material and Methods
2.1. Data Collection
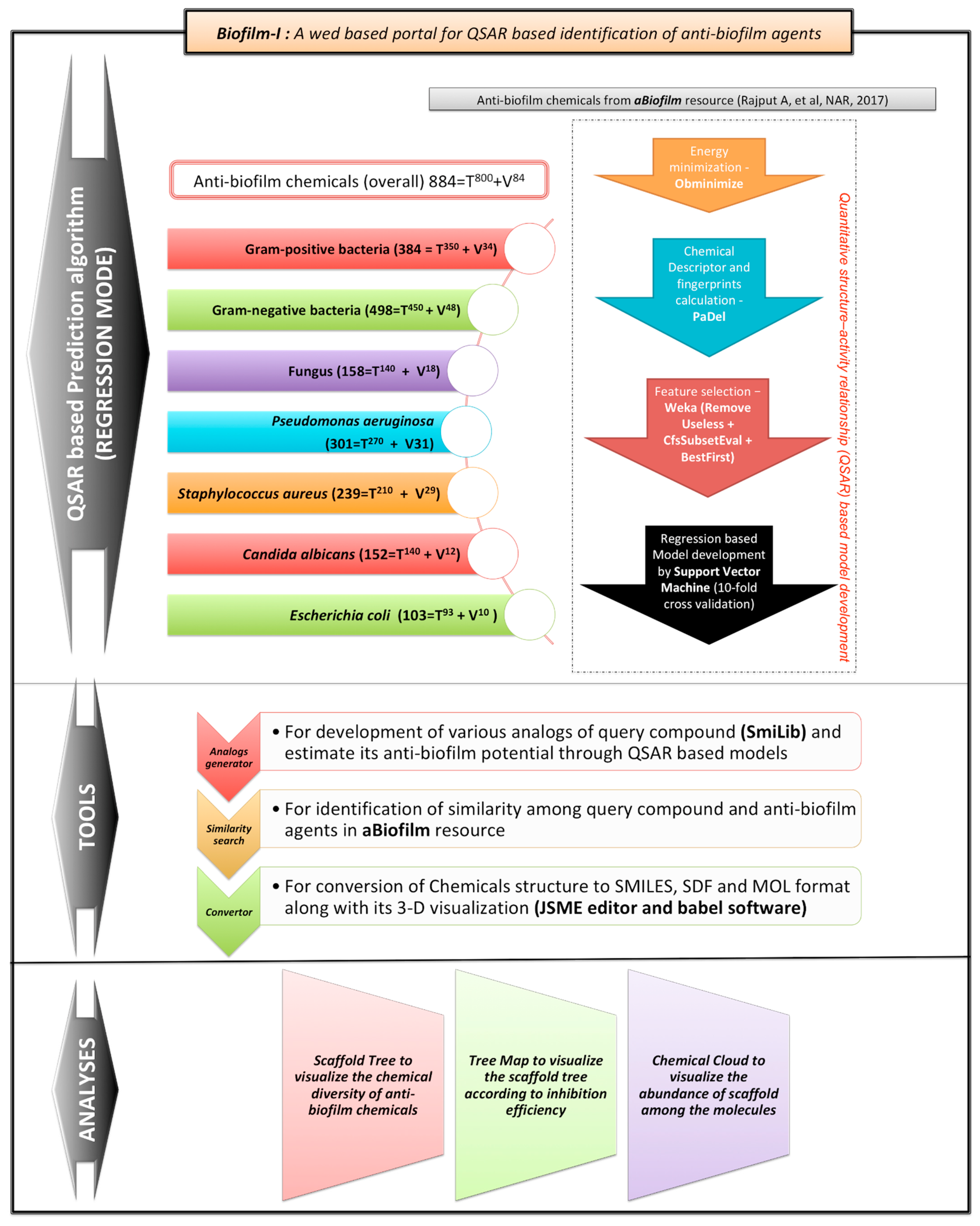
- Initially, for making the generalized predictor, we extracted 884 unique chemicals with biofilm inhibition potential that varies from 0–100%.
- For the group-specific predictors, 384, 498, and 158 chemicals were retrieved for Gram-positive, Gram-negative bacteria, and fungus, respectively.
- For the species-specific algorithms, we selected organisms with a number of non-redundant biofilm inhibitors >100. Thus, we identified four organisms: Staphylococcus aureus (Gram-positive bacteria), Pseudomonas aeruginosa (Gram-negative bacteria), Candida albicans (fungus or yeast), and Escherichia coli (Gram-negative bacteria). S. aureus, P. aeruginosa, C. albicans, and E. coli possess 239, 301, 152 and 103 biofilm inhibiting chemicals, respectively.
2.2. Quantitative Structure–Activity Relationship (QSAR) Based Model Development
2.3. Tenfold Cross-Validation
2.4. Support Vector Machine
2.5. Random Forest
2.6. Data Preprocessing
2.7. Descriptors Calculation
2.8. Features Selection
2.9. Chemical Analysis
2.10. Performance Measures
2.11. Webserver
3. Results
3.1. Performance of Quantitative Structure—Activity Relationship (QSAR) Based Models Using Support Vector Machine
3.2. Performance of Quantitative Structure–Activity Relationship (QSAR) Based Models Using Random Forest
3.3. Analyses
3.4. Web Server
4. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Donlan, R.M. Biofilms: Microbial Life on Surfaces. Emerg. Infect. Dis. 2002, 8, 881–890. [Google Scholar] [CrossRef] [PubMed]
- Kostakioti, M.; Hadjifrangiskou, M.; Hultgren, S.J. Bacterial Biofilms: Development, Dispersal, and Therapeutic Strategies in the Dawn of the Postantibiotic Era. Cold Spring Harb. Perspect. Med. 2013, 3, a010306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- O’Toole, G.; Kaplan, H.B.; Kolter, R. Biofilm Formation as Microbial Development. Annu. Rev. Microbiol. 2000, 54, 49–79. [Google Scholar] [CrossRef] [PubMed]
- Kolter, R.; Peter Greenberg, E. The Superficial Life of Microbes. Nature 2006, 441, 300–302. [Google Scholar] [CrossRef] [PubMed]
- Tolker-Nielsen, T. Biofilm Development. Microbiol. Spectr. 2015, 3, 3-2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wynendaele, E.; Bronselaer, A.; Nielandt, J.; D’Hondt, M.; Stalmans, S.; Bracke, N.; Verbeke, F.; Van De Wiele, C.; De Tré, G.; De Spiegeleer, B. Quorumpeps Database: Chemical Space, Microbial Origin and Functionality of Quorum Sensing Peptides. Nucleic Acids Res. 2013, 41, D655–D659. [Google Scholar] [CrossRef] [PubMed]
- Yarwood, J.M.; Bartels, D.J.; Volper, E.M.; Greenberg, E.P. Quorum Sensing in Staphylococcus Aureus Biofilms. J. Bacteriol. 2004, 186, 1838–1850. [Google Scholar] [CrossRef] [Green Version]
- Solano, C.; Echeverz, M.; Lasa, I. Biofilm Dispersion and Quorum Sensing. Curr. Opin. Microbiol. 2014, 18, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Parsek, M.R.; Greenberg, E.P. Sociomicrobiology: The Connections between Quorum Sensing and Biofilms. Trends Microbiol. 2005, 13, 27–33. [Google Scholar] [CrossRef]
- Estrela, A.B.; Heck, M.G.; Abraham, W.-R. Novel Approaches to Control Biofilm Infections. Curr. Med. Chem. 2009, 16, 1512–1530. [Google Scholar] [CrossRef]
- Brooun, A.; Liu, S.; Lewis, K. A Dose-Response Study of Antibiotic Resistance in Pseudomonas Aeruginosa Biofilms. Antimicrob. Agents Chemother. 2000, 44, 640–646. [Google Scholar] [CrossRef] [Green Version]
- Stewart, P.S. Mechanisms of Antibiotic Resistance in Bacterial Biofilms. Int. J. Med. Microbiol. 2002, 292, 107–113. [Google Scholar] [CrossRef]
- Van Acker, H.; Van Dijck, P.; Coenye, T. Molecular Mechanisms of Antimicrobial Tolerance and Resistance in Bacterial and Fungal Biofilms. Trends Microbiol. 2014, 22, 326–333. [Google Scholar] [CrossRef]
- Rogers, S.A.; Huigens, R.W., 3rd; Cavanagh, J.; Melander, C. Synergistic Effects between Conventional Antibiotics and 2-Aminoimidazole-Derived Antibiofilm Agents. Antimicrob. Agents Chemother. 2010, 54, 2112–2118. [Google Scholar] [CrossRef] [Green Version]
- Rajput, A.; Thakur, A.; Sharma, S.; Kumar, M. aBiofilm: A Resource of Anti-Biofilm Agents and Their Potential Implications in Targeting Antibiotic Drug Resistance. Nucleic Acids Res. 2018, 46, D894–D900. [Google Scholar] [CrossRef] [Green Version]
- Rajput, A.; Bhamare, K.T.; Mukhopadhyay, A.; Rastogi, A.; Sakshi; Kumar, M. Efficacy of Anti-Biofilm Agents in Targeting ESKAPE Pathogens with a Focus on Antibiotic Drug Resistance. In Quorum Sensing: Microbial Rules of Life; ACS Symposium Series; American Chemical Society: Washington, DC, USA, 2020; Volume 1374, pp. 177–199. ISBN 9780841298606. [Google Scholar]
- Chung, P.Y.; Toh, Y.S. Anti-Biofilm Agents: Recent Breakthrough against Multi-Drug Resistant Staphylococcus Aureus. Pathog. Dis. 2014, 70, 231–239. [Google Scholar] [CrossRef] [Green Version]
- Roy, R.; Tiwari, M.; Donelli, G.; Tiwari, V. Strategies for Combating Bacterial Biofilms: A Focus on Anti-Biofilm Agents and Their Mechanisms of Action. Virulence 2018, 9, 522–554. [Google Scholar] [CrossRef]
- Taylor, P.K.; Yeung, A.T.Y.; Hancock, R.E.W. Antibiotic Resistance in Pseudomonas Aeruginosa Biofilms: Towards the Development of Novel Anti-Biofilm Therapies. J. Biotechnol. 2014, 191, 121–130. [Google Scholar] [CrossRef]
- Elchinger, P.-H.; Delattre, C.; Faure, S.; Roy, O.; Badel, S.; Bernardi, T.; Taillefumier, C.; Michaud, P. Effect of Proteases against Biofilms of Staphylococcus Aureus and Staphylococcus Epidermidis. Lett. Appl. Microbiol. 2014, 59, 507–513. [Google Scholar] [CrossRef] [Green Version]
- Sharma, A.; Gupta, P.; Kumar, R.; Bhardwaj, A. dPABBs: A Novel in Silico Approach for Predicting and Designing Anti-Biofilm Peptides. Sci. Rep. 2016, 6, 21839. [Google Scholar] [CrossRef]
- Gupta, S.; Sharma, A.K.; Jaiswal, S.K.; Sharma, V.K. Prediction of Biofilm Inhibiting Peptides: An In Silico Approach. Front. Microbiol. 2016, 7, 949. [Google Scholar] [CrossRef]
- Fallah Atanaki, F.; Behrouzi, S.; Ariaeenejad, S.; Boroomand, A.; Kavousi, K. BIPEP: Sequence-Based Prediction of Biofilm Inhibitory Peptides Using a Combination of NMR and Physicochemical Descriptors. ACS Omega 2020, 5, 7290–7297. [Google Scholar] [CrossRef]
- Srivastava, G.N.; Malwe, A.S.; Sharma, A.K.; Shastri, V.; Hibare, K.; Sharma, V.K. Molib: A Machine Learning Based Classification Tool for the Prediction of Biofilm Inhibitory Molecules. Genomics 2020, 112, 2823–2832. [Google Scholar] [CrossRef]
- Xue, Y.; Li, Z.R.; Yap, C.W.; Sun, L.Z.; Chen, X.; Chen, Y.Z. Effect of Molecular Descriptor Feature Selection in Support Vector Machine Classification of Pharmacokinetic and Toxicological Properties of Chemical Agents. J. Chem. Inf. Comput. Sci. 2004, 44, 1630–1638. [Google Scholar] [CrossRef] [Green Version]
- Ebalunode, J.O.; Zheng, W.; Tropsha, A. Application of QSAR and Shape Pharmacophore Modeling Approaches for Targeted Chemical Library Design. Methods Mol. Biol. 2011, 685, 111–133. [Google Scholar]
- Qureshi, A.; Kaur, G.; Kumar, M. AVCpred: An Integrated Web Server for Prediction and Design of Antiviral Compounds. Chem. Biol. Drug Des. 2017, 89, 74–83. [Google Scholar] [CrossRef]
- Browne, M.W. Cross-Validation Methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [Green Version]
- Rajput, A.; Gupta, A.K.; Kumar, M. Prediction and Analysis of Quorum Sensing Peptides Based on Sequence Features. PLoS ONE 2015, 10, e0120066. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajput, A.; Kumar, A.; Kumar, M. Computational Identification of Inhibitors Using QSAR Approach Against Nipah Virus. Front. Pharmacol. 2019, 10, 71. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thakur, N.; Qureshi, A.; Kumar, M. AVPpred: Collection and Prediction of Highly Effective Antiviral Peptides. Nucleic Acids Res. 2012, 40, W199–W204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rajput, A.; Kumar, M. Anti-Flavi: A Web Platform to Predict Inhibitors of Flaviviruses Using QSAR and Peptidomimetic Approaches. Front. Microbiol. 2018, 9, 3121. [Google Scholar] [CrossRef]
- Rajput, A.; Thakur, A.; Mukhopadhyay, A.; Kamboj, S.; Rastogi, A.; Gautam, S.; Jassal, H.; Kumar, M. Prediction of Repurposed Drugs for Coronaviruses Using Artificial Intelligence and Machine Learning. Comput. Struct. Biotechnol. J. 2021, 19, 3133–3148. [Google Scholar] [CrossRef]
- O’Boyle, N.M.; Banck, M.; James, C.A.; Morley, C.; Vandermeersch, T.; Hutchison, G.R. Open Babel: An Open Chemical Toolbox. J. Cheminform. 2011, 3, 33. [Google Scholar] [CrossRef] [Green Version]
- Frank, E.; Hall, M.; Trigg, L.; Holmes, G.; Witten, I.H. Data Mining in Bioinformatics Using Weka. Bioinformatics 2004, 20, 2479–2481. [Google Scholar] [CrossRef] [Green Version]
- Schäfer, T.; Kriege, N.; Humbeck, L.; Klein, K.; Koch, O.; Mutzel, P. Scaffold Hunter: A Comprehensive Visual Analytics Framework for Drug Discovery. J. Cheminform. 2017, 9, 28. [Google Scholar] [CrossRef] [Green Version]
- Ertl, P.; Rohde, B. The Molecule Cloud-Compact Visualization of Large Collections of Molecules. J. Cheminform. 2012, 4, 12. [Google Scholar] [CrossRef] [Green Version]
- Lebeaux, D.; Ghigo, J.-M.; Beloin, C. Biofilm-Related Infections: Bridging the Gap between Clinical Management and Fundamental Aspects of Recalcitrance toward Antibiotics. Microbiol. Mol. Biol. Rev. 2014, 78, 510–543. [Google Scholar] [CrossRef] [Green Version]
- Stewart, P.S.; Franklin, M.J. Physiological Heterogeneity in Biofilms. Nat. Rev. Microbiol. 2008, 6, 199–210. [Google Scholar] [CrossRef]
- Stewart, P.S.; Costerton, J.W. Antibiotic Resistance of Bacteria in Biofilms. Lancet 2001, 358, 135–138. [Google Scholar] [CrossRef]
- Krishnaiah, M.; de Almeida, N.R.; Udumula, V.; Song, Z.; Chhonker, Y.S.; Abdelmoaty, M.M.; do Nascimento, V.A.; Murry, D.J.; Conda-Sheridan, M. Synthesis, Biological Evaluation, and Metabolic Stability of Phenazine Derivatives as Antibacterial Agents. Eur. J. Med. Chem. 2018, 143, 936–947. [Google Scholar] [CrossRef]
- Lewis, K. Riddle of Biofilm Resistance. Antimicrob. Agents Chemother. 2001, 45, 999–1007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Høiby, N.; Bjarnsholt, T.; Givskov, M.; Molin, S.; Ciofu, O. Antibiotic Resistance of Bacterial Biofilms. Int. J. Antimicrob. Agents 2010, 35, 322–332. [Google Scholar] [CrossRef] [PubMed] [Green Version]



{kind=link}
{kind=link}
| Models Used | Data Sets | Features | Pearson’s Correlation Coefficient |
|---|---|---|---|
| Chemicals (Overall) | Training/Testing data set (T800) | 265 | 0.60 |
| Independent Validation data set (V84) | 0.53 | ||
| Gram-positive bacteria | Training/Testing data set (T350) | 177 | 0.77 |
| Independent Validation data set (V34) | 0.76 | ||
| Gram-negative bacteria | Training/Testing data set (T450) | 387 | 0.62 |
| Independent Validation data set (V48) | 0.60 | ||
| Fungus/Yeast | Training/Testing data set (T140) | 111 | 0.77 |
| Independent Validation data set (V18) | 0.71 | ||
| Pseudomonas aeruginosa | Training/Testing data set (T270) | 81 | 0.73 |
| Independent Validation data set (V31) | 0.78 | ||
| Staphylococcus aureus | Training/Testing data set (T210) | 90 | 0.83 |
| Independent Validation data set (V29) | 0.86 | ||
| Candida albicans | Training/Testing data set (T140) | 76 | 0.70 |
| Independent Validation data set (V12) | 0.82 | ||
| Escherichia coli | Training/Testing data set (T93) | 52 | 0.71 |
| Independent Validation data set (V10) | 0.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajput, A.; Bhamare, K.T.; Thakur, A.; Kumar, M. Biofilm-i: A Platform for Predicting Biofilm Inhibitors Using Quantitative Structure—Relationship (QSAR) Based Regression Models to Curb Antibiotic Resistance. Molecules 2022, 27, 4861. https://doi.org/10.3390/molecules27154861
Rajput A, Bhamare KT, Thakur A, Kumar M. Biofilm-i: A Platform for Predicting Biofilm Inhibitors Using Quantitative Structure—Relationship (QSAR) Based Regression Models to Curb Antibiotic Resistance. Molecules. 2022; 27(15):4861. https://doi.org/10.3390/molecules27154861
Chicago/Turabian StyleRajput, Akanksha, Kailash T. Bhamare, Anamika Thakur, and Manoj Kumar. 2022. "Biofilm-i: A Platform for Predicting Biofilm Inhibitors Using Quantitative Structure—Relationship (QSAR) Based Regression Models to Curb Antibiotic Resistance" Molecules 27, no. 15: 4861. https://doi.org/10.3390/molecules27154861