
Statistical Analysis of Chemical Element Compositions in Food Science: Problems and Possibilities


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
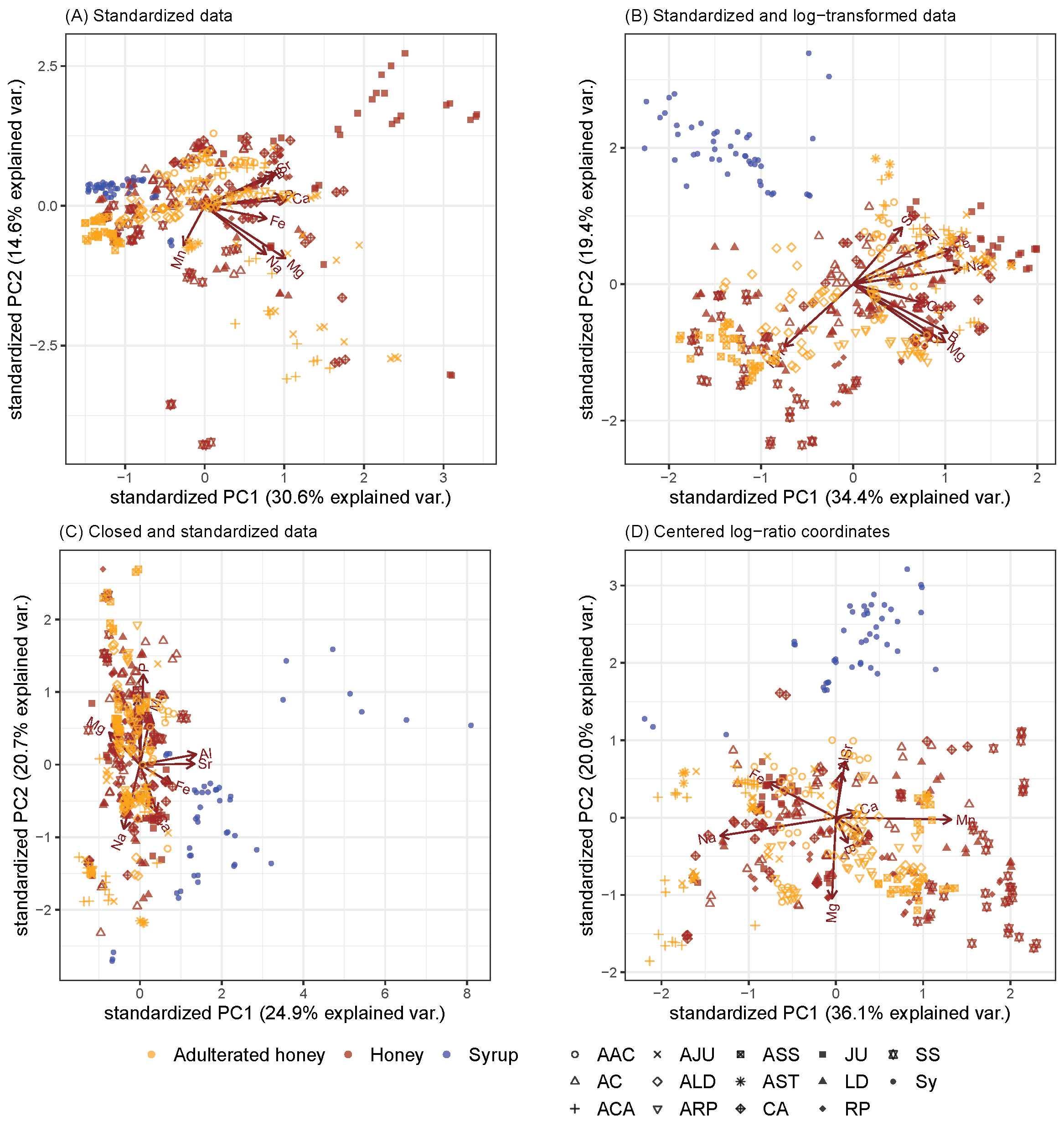
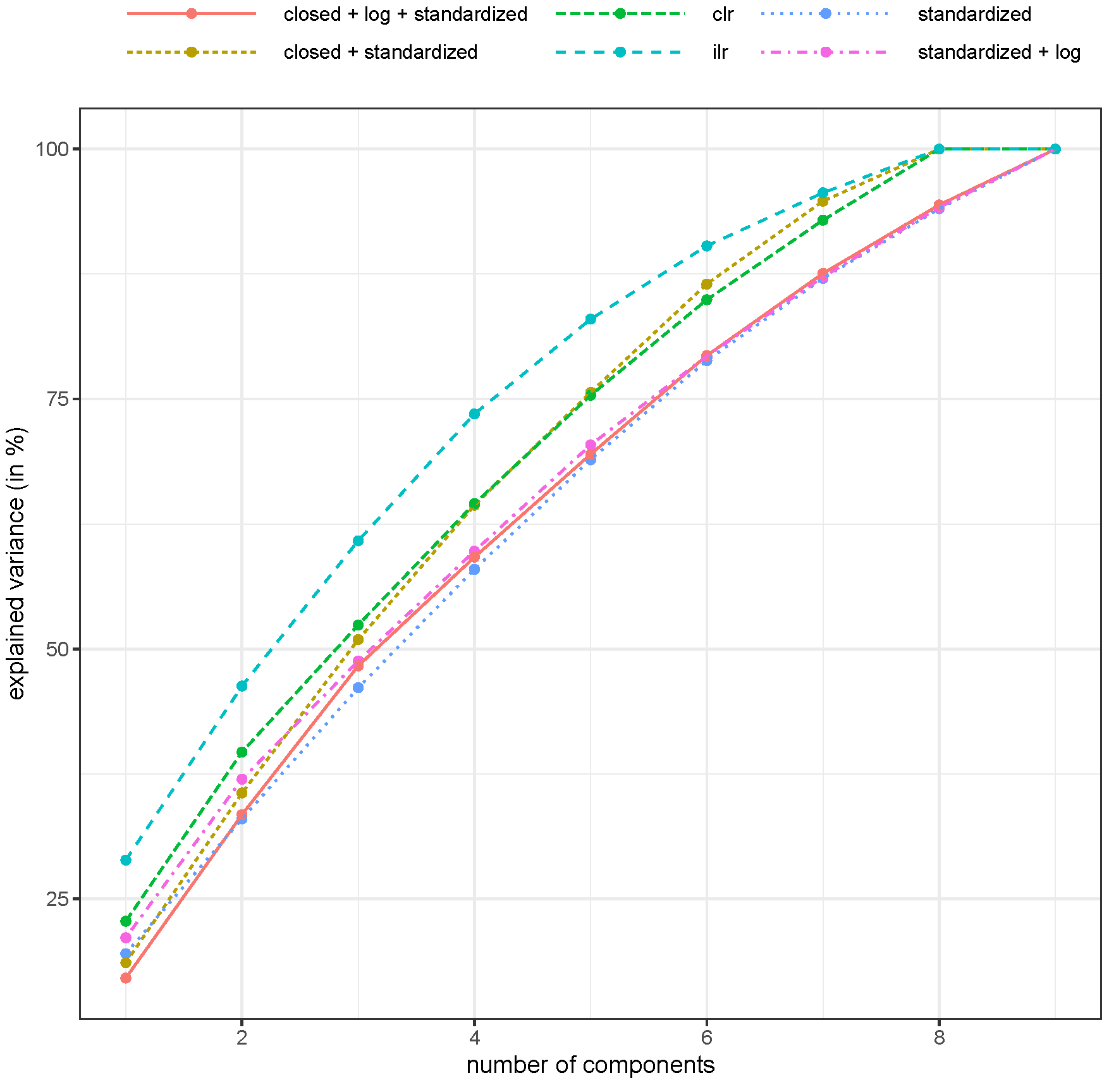
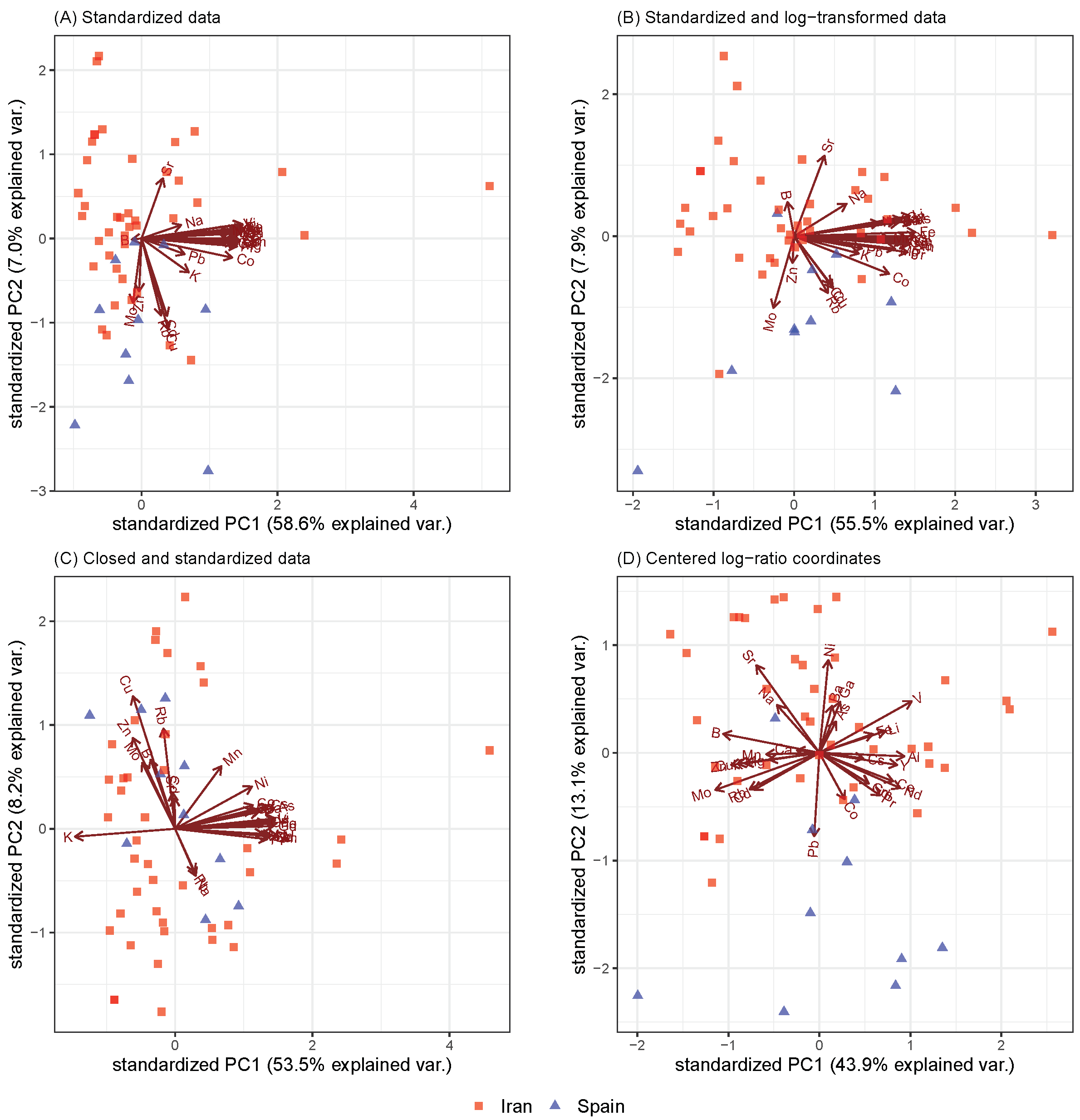
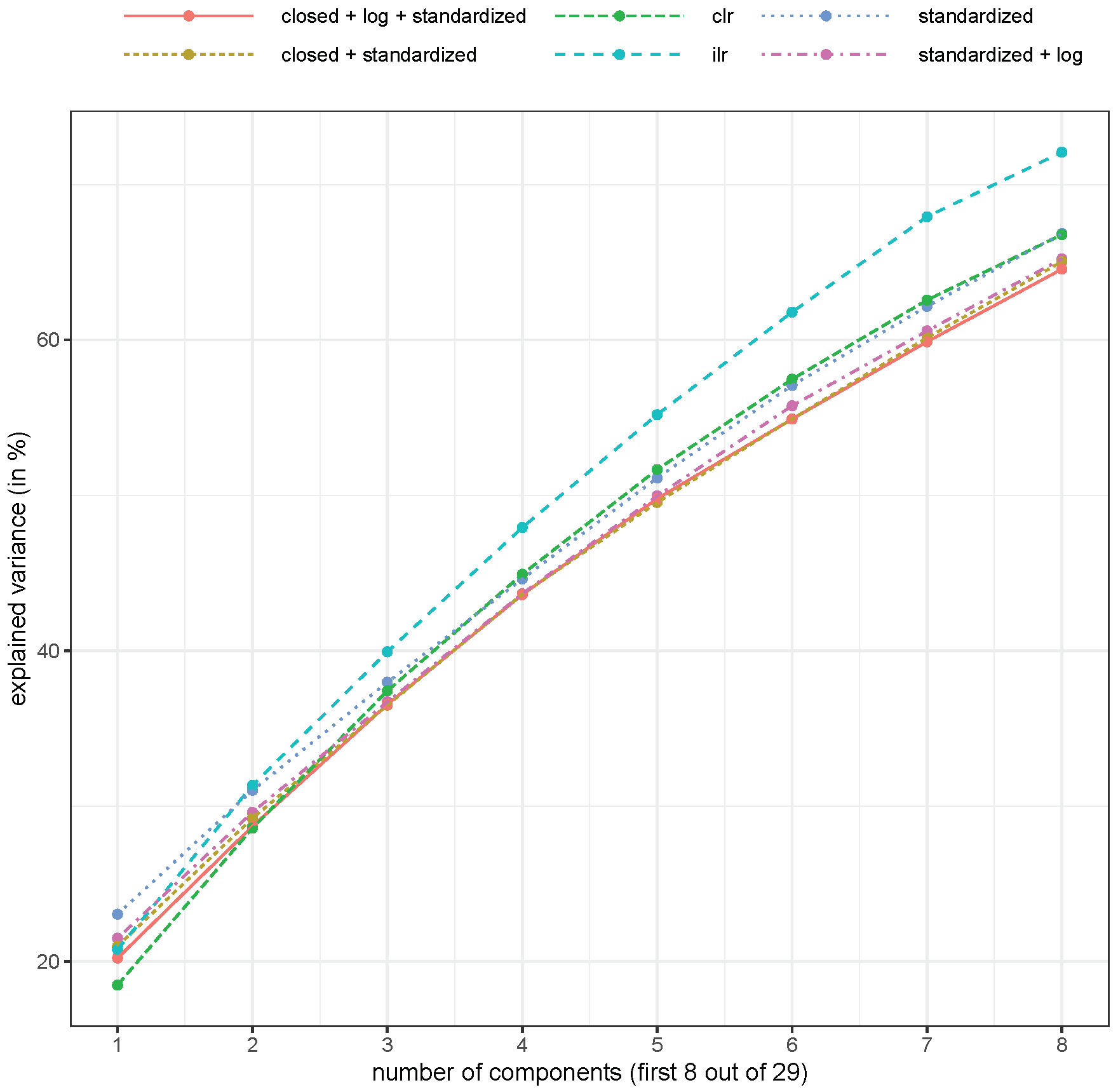
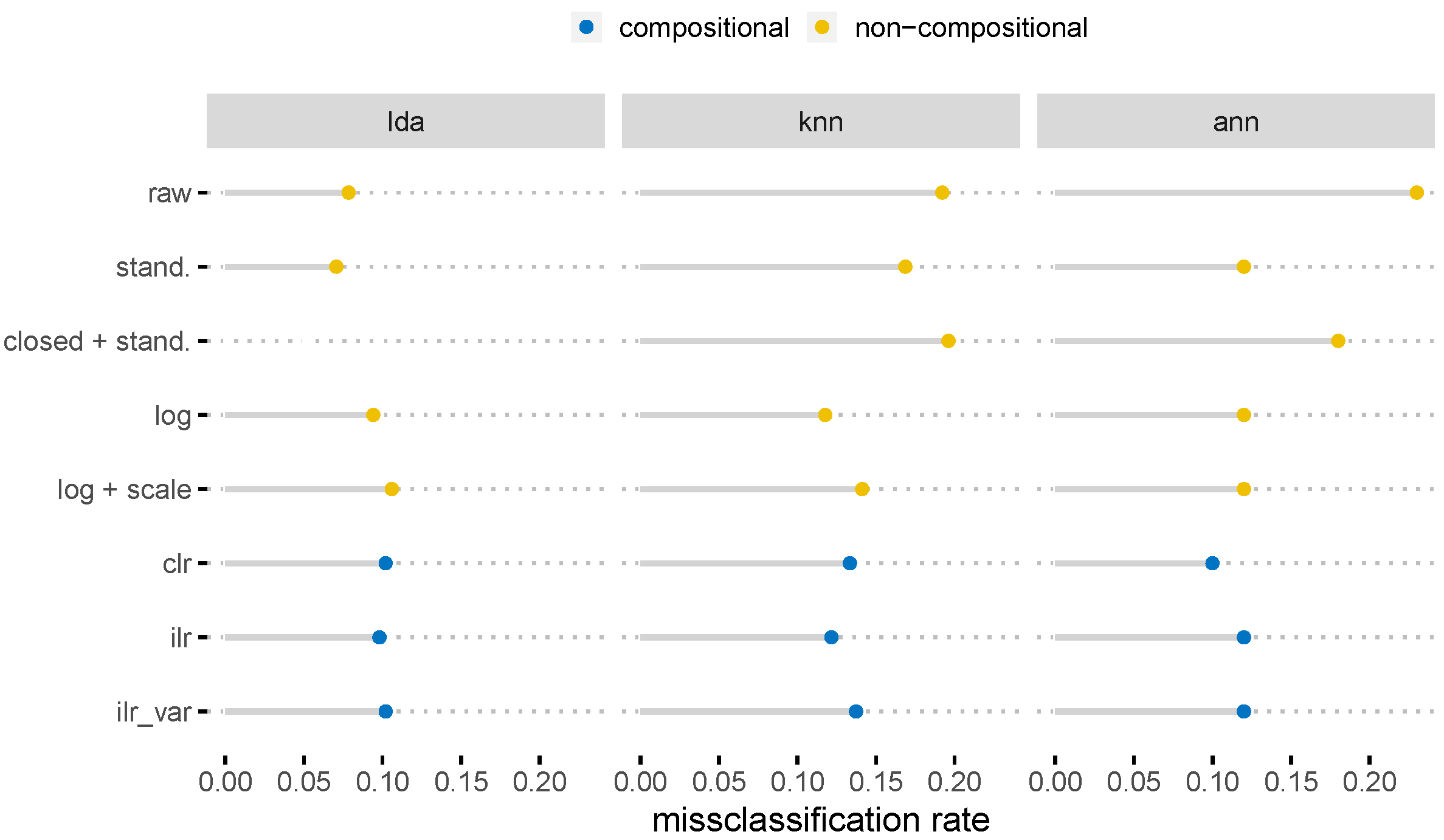
2. Results
3. Discussion
4. Materials and Methods
4.1. Mineral Element Data of Honey Samples
4.2. Stable Isotope Ratio and Trace Element Concentration Data of Saffron Samples
5. Data Analysis
5.1. Non-Compositional Standardization of Variables
5.2. Non-Compositional Standardization of Observations
5.3. Non-Compositional Transformation
5.4. Compositional Analysis
5.5. Standardization and Transformation by Means of Log-Ratios
5.6. Replacement of Missing Values and Non-Detects
- const:
- Any rounded zero value is replaced by a constant value of . Note that it is not a good strategy to impute rounded zeros. However, this method should serve as a benchmark, among other things.
- dl23:
- This comparatively equally simple method also replaces all zeros with a constant value smaller than the two-thirds of the detection limit. Martín-Fernández et al. [58] found that the detection limit minimizes the distortion in the covariance structure.
- unif:
- A zero is replaced in a variable by drawing a random uniform number between the interval , with , the smallest positive value of variable j. It prevents a zero being imputed to close to 0 and ensures imputation below an unknown detection limit.
- bdls_pls:
- (below-detection-limit using (censored) partial least squares regression) A zero is replaced by an iterative EM-algorithm based on a censored partial least squares estimation on sequential log-ratio coordinate representations. For details, see [40].
5.7. Principal Component Analysis
5.8. Classification
- zeros replaced with const, dl23, unif, and bdls_pls (see Section 5.6).
- no transformation, standardization, log-transformation, log-transformation and standardization, rescaling by closure, or pivot coordinate or centered coordinate representation.
- 20% validation/80% training data,
- 3 layers, 300 neurons in the first layer, followed by 128 and 64 neurons in the next layer,
- 10% dropout in the first 2 layers,
- mean squared error as a loss function and mean absolute error as an evaluation metric, and
- 500 epochs with break whenever 50 epochs do not improve the result
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Elmadfa, I.; Meyer, A.L. Importance of food composition data to nutrition and public health. Eur. J. Clin. Nutr. 2010, 64, S4–S7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Granato, D.; de Araújo Calado, V.M.; Jarvis, B. Observations on the use of statistical methods in Food Science and Technology. Food Res. Int. 2014, 55, 137–149. [Google Scholar] [CrossRef]
- Nunes, C.A.; Alvarenga, V.O.; de Souza Sant’Ana, A.; Santos, J.S.; Granato, D. The use of statistical software in food science and technology: Advantages, limitations and misuses. Food Res. Int. 2015, 75, 270–280. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Granato, D.; Santos, J.S.; Escher, G.B.; Ferreira, B.L.; Maggio, R.M. Use of principal component analysis (PCA) and hierarchical cluster analysis (HCA) for multivariate association between bioactive compounds and functional properties in foods: A critical perspective. Trends Food Sci. Technol. 2018, 72, 83–90. [Google Scholar] [CrossRef]
- Gottardo, P.; Penasa, M.; Lopez-Villalobos, N.; De Marchi, M. Variable selection procedures before partial least squares regression enhance the accuracy of milk fatty acid composition predicted by mid-infrared spectroscopy. J. Dairy Sci. 2016, 99, 7782–7790. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kamruzzaman, M.; ElMasry, G.; Sun, D.W.; Allen, P. Non-destructive prediction and visualization of chemical composition in lamb meat using NIR hyperspectral imaging and multivariate regression. Innov. Food Sci. Emerg. Technol. 2012, 16, 218–226. [Google Scholar] [CrossRef]
- Fakhlaei, R.; Selamat, J.; Khatib, A.; Razis, A.F.A.; Sukor, R.; Ahmad, S.; Babadi, A.A. The Toxic Impact of Honey Adulteration: A Review. Foods 2020, 9, 1538. [Google Scholar] [CrossRef]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman & Hall: London, UK, 1986. [Google Scholar]
- Filzmoser, P.; Hron, K.; Templ, M. Applied Compositional Data Analysis. With Worked Examples in R; Springer Series in Statistics; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Pesenson, M.Z.; Suram, S.K.; Gregoire, J.M. Statistical Analysis and Interpolation of Compositional Data in Materials Science. ACS Comb. Sci. 2015, 17, 130–136. [Google Scholar] [CrossRef] [PubMed]
- Buccianti, A.; Pawlowsky-Glahn, V. New Perspectives on Water Chemistry and Compositional Data Analysis. Math. Geol. 2005, 37, 703–727. [Google Scholar] [CrossRef]
- Buccianti, A.; Grunsky, E. Compositional data analysis in geochemistry: Are we sure to see what really occurs during natural processes? J. Geochem. Explor. 2014, 141, 1–5. [Google Scholar] [CrossRef]
- Meier, M.F.; Mildenberger, T.; Locher, R.; Rausch, J.; Zünd, T.; Neururer, C.; Ruckstuhl, A.; Grobèty, B. A model based two-stage classifier for airborne particles analyzed with Computer Controlled Scanning Electron Microscopy. J. Aerosol Sci. 2018, 123, 1–16. [Google Scholar] [CrossRef]
- Templ, M.; Templ, B. Analysis of chemical compounds in beverages—Guidance for establishing a compositional analysis. Food Chem. 2020, 325, 126755. [Google Scholar] [CrossRef] [PubMed]
- Greenacre, M. Compositional Data Analysis in Practice; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- van den Boogaart, G.K.; Tolosana-Delgado, R. Analyzing Compositional Data with R; Use R! Book Series; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J.; Tolosana-Delgado, J. Lecture Notes on Compositional Data Analysis. 2007. Available online: http://www.sediment.uni-goettingen.de/staff/tolosana/extra/CoDa.pdf (accessed on 3 September 2021).
- Hron, K.; Templ, M.; Filzmoser, P. Estimation of a proportion in survey sampling using the logratio approach. Metrika 2013, 76, 799–818. [Google Scholar] [CrossRef]
- Cayuela-Sánchez, J.A.; Palarea-Albaladejo, J.; Zira, T.P.; Moriana-Correro, E. Compositional method for measuring the nutritional label components of industrial pastries and biscuits based on Vis/NIR spectroscopy. J. Food Compos. Anal. 2020, 92, 103572. [Google Scholar] [CrossRef]
- Cayuela-Sánchez, J.A.; Palarea-Albaladejo, J.; García-Martín, J.F.; del Carmen Pérez-Camino, M. Olive oil nutritional labeling by using Vis/NIR spectroscopy and compositional statistical methods. Innov. Food Sci. Emerg. Technol. 2019, 51, 139–147. [Google Scholar] [CrossRef] [Green Version]
- Parent, L.; Dafir, M. A Theoretical Concept of Compositional Nutrient Diagnosis. J. Am. Soc. Hortic. Sci. 1992, 117, 239–242. [Google Scholar] [CrossRef] [Green Version]
- Parent, L.E. Diagnosis of the nutrient compositional space of fruit crops. Rev. Bras. Frutic. 2011, 33, 321–334. [Google Scholar] [CrossRef]
- Parent, L.E.; Rozane, D.E.; de Deus, J.A.L.; Natale, W. Diagnosis of nutrient composition in fruit crops: Major developments. In Fruit Crops; Srivastava, A., Hu, C., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; Chapter 12; pp. 145–156. [Google Scholar] [CrossRef]
- Neto, A.; Deus, J.; Filho, V.; Natale, W.; Parent, L.E. Nutrient Diagnosis of Fertigated prata and Cavendish banana (Musa spp.) at Plot-Scale. Plants 2020, 9, 1467. [Google Scholar] [CrossRef] [PubMed]
- Rozane, D.E.; Mattos, D., Jr.; Parent, S.É.; Natale, W.; Parent, L.E. Meta-analysis in the Selection of Groups in Varieties of Citrus. Commun. Soil Sci. Plant Anal. 2015, 46, 1948–1959. [Google Scholar] [CrossRef]
- Wang, J.; Li, Q.X. Chapter 3—Chemical Composition, Characterization, and Differentiation of Honey Botanical and Geographical Origins. Adv. Food Nutr. Res. 2011, 62, 89–137. [Google Scholar] [CrossRef] [PubMed]
- Santos-Buelga, C.; González-Paramás, A.M. Chemical Composition of Honey. In Bee Products-Chemical and Biological Properties; Alvarez-Suarez, J.M., Ed.; Springer: Cham, Switzerland, 2017; pp. 43–82. [Google Scholar] [CrossRef]
- Maggi, L.; Carmona, M.; Kelly, S.D.; Marigheto, N.; Alonso, G.L. Geographical origin differentiation of saffron spice (Crocus sativus L. stigmas)—Preliminary investigation using chemical and multi-element (H, C, N) stable isotope analysis. Food Chem. 2011, 128, 543–548. [Google Scholar] [CrossRef] [PubMed]
- Wakefield, J.; McComb, K.; Ehtesham, E.; Van Hale, R.; Barr, D.; Hoogewerff, J.; Frew, R. Chemical profiling of saffron for authentication of origin. Food Control 2019, 106, 106699. [Google Scholar] [CrossRef]
- da Silva, P.M.; Gauche, C.; Gonzaga, L.V.; Costa, A.C.O.; Fett, R. Honey: Chemical composition, stability and authenticity. Food Chem. 2016, 196, 309–323. [Google Scholar] [CrossRef] [PubMed]
- Escuredo, O.; Dobre, I.; Fernández-González, M.; Seijo, M.C. Contribution of botanical origin and sugar composition of honeys on the crystallization phenomenon. Food Chem. 2014, 149, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Se, K.W.; Wahab, R.A.; Syed Yaacob, S.N.; Ghoshal, S.K. Detection techniques for adulterants in honey: Challenges and recent trends. J. Food Compos. Anal. 2019, 80, 16–32. [Google Scholar] [CrossRef]
- Soares, S.; Amaral, J.S.; Oliveira, M.B.P.; Mafra, I. A Comprehensive Review on the Main Honey Authentication Issues: Production and Origin. Compr. Rev. Food Sci. Food Saf. 2017, 16, 1072–1100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hagh-Nazari, S.; Keifi, N. Saffron and Various Fraud Manners in Its Production and Trades. In Acta Horticulturae; International Society for Horticultural Science (ISHS): Leuven, Belgium, 2007; pp. 411–416. [Google Scholar] [CrossRef]
- Filzmoser, P.; Hron, K. Correlation Analysis for Compositional Data. Math. Geosci. 2008, 41, 905. [Google Scholar] [CrossRef]
- Pearson, K. Mathematical contributions to the theory of evolution. On a form of spurious correlation which may arise when indices are used in the measurement of organs. Proc. R. Soc. Lond. 1897, 60, 489–502. [Google Scholar]
- Liu, T.; Ming, K.; Wang, W.; Qiao, N.; Qiu, S.; Yi, S.; Huang, X.; Luo, L. Discrimination of honey and syrup-based adulteration by mineral element chemometrics profiling. Food Chem. 2021, 343, 128455. [Google Scholar] [CrossRef] [PubMed]
- Barceló-Vidal, C.; Martín-Fernández, J.; Mateu-Figueras, G. Compositional Differential Calculus on the Simplex. In Compositional Data Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; Chapter 13; pp. 176–190. [Google Scholar] [CrossRef]
- Aitchison, J. A Concise Guide to Compositional Data Analysis, 2nd ed.; Compositional Data Analysis Workshop: Girona, Spain, 2003. [Google Scholar]
- Templ, M.; Hron, K.; Filzmoser, P.; Gardlo, A. Imputation of rounded zeros for high-dimensional compositional data. Chemom. Intell. Lab. Syst. 2016, 155, 183–190. [Google Scholar] [CrossRef]
- Rodionova, O.; Oliveri, P.; Pomerantsev, A. Rigorous and compliant approaches to one-class classification. Chemom. Intell. Lab. Syst. 2016, 159, 89–96. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M. SIMCA: A Method for Analyzing Chemical Data in Terms of Similarity and Analogy. In Chemometrics: Theory and Application; ACS Symposium Series; American Chemical Society: Washington, DC, USA, 1977; Volume 52, pp. 243–282. [Google Scholar] [CrossRef]
- Branden, K.V.; Hubert, M. Robust classification in high dimensions based on the SIMCA Method. Chemom. Intell. Lab. Syst. 2005, 79, 10–21. [Google Scholar] [CrossRef] [Green Version]
- Templ, M.; Hron, K.; Filzmoser, P. Exploratory tools for outlier detection in compositional data with structural zeros. J. Appl. Stat. 2017, 44, 734–752. [Google Scholar] [CrossRef]
- Templ, M. Artificial Neural Networks to Impute Rounded Zeros in Compositional Data. In Advances in Compositional Data Analysis: Festschrift in Honour of Vera Pawlowsky-Glahn; Filzmoser, P., Hron, K., Martín-Fernández, J.A., Palarea-Albaladejo, J., Eds.; Springer: Cham, Switzerland, 2021; pp. 163–187. [Google Scholar] [CrossRef]
- Filzmoser, P.; Walczak, B. What can go wrong at the data normalization step for identification of biomarkers? J. Chromatogr. A 2014, 1362, 194–205. [Google Scholar] [CrossRef]
- Malyjurek, Z.; de Beer, D.; Joubert, E.; Walczak, B. Working with log-ratios. Anal. Chim. Acta 2019, 1059, 16–27. [Google Scholar] [CrossRef] [PubMed]
- Luo, L. Data for: Discrimination of Honey and Adulteration by Elemental Chemometrics Profiling. Mendeley Data, V1. 2020. Available online: https://data.mendeley.com/datasets/tt6pp6pbpk/1 (accessed on 3 September 2021).
- Frew, R. Data for: Chemical Profiling of Saffron for Authentication of Origin. Mendeley Data, V1. 2019. Available online: https://data.mendeley.com/datasets/5544tn9v6c/1 (accessed on 3 September 2021).
- Jolliffe, I. Principal Component Analysis; Springer Series in Statistics; Chapter Principal Component Analysis and Factor Analysis; Springer: New York, NY, USA, 1986. [Google Scholar] [CrossRef]
- Tukey, J.W. On the Comparative Anatomy of Transformations. Ann. Math. Stat. 1957, 28, 602–632. [Google Scholar] [CrossRef]
- Reimann, C.; Filzmoser, P.; Garrett, G. Factor analysis applied to regional geochemical data: Problems and possibilities. Appl. Geochem. 2002, 17, 185–206. [Google Scholar] [CrossRef]
- Egozcue, J.; Pawlowsky-Glahn, V.; Mateu-Figueras, G.; Barceló-Vidal, C. Isometric logratio transformations for compositional data analysis. Math. Geol. 2003, 35, 279–300. [Google Scholar] [CrossRef]
- Aitchison, J.; Greenacre, M. Biplots of compositional data. Appl. Stat. 2002, 51, 375–392. [Google Scholar] [CrossRef] [Green Version]
- Filzmoser, P.; Hron, K.; Reimann, C. Principal component analysis for compositional data with outliers. Environmetrics 2009, 20, 621–632. [Google Scholar] [CrossRef]
- Hron, K.; Templ, M.; Filzmoser, P. Imputation of missing values for compositional data using classical and robust methods. Comput. Stat. Data Anal. 2010, 54, 3095–3107. [Google Scholar] [CrossRef]
- Lubbe, S.; Templ, M.; Filzmoser, P. Comparison of Zero Replacement Strategies for Compositional Data with Large Numbers of Zeros. Chemom. Intell. Lab. Syst. 2021, 215, 104248. [Google Scholar] [CrossRef]
- Martín-Fernández, J.; Barceló-Vidal, C.; Pawlowsky-Glahn, V. Dealing with zeros and missing values in compositional data sets using nonparametric imputation. Math. Geol. 2003, 35, 253–278. [Google Scholar] [CrossRef]
- Martín-Fernández, J.; Hron, K.; Templ, M.; Filzmoser, P.; Palarea-Albaladejo, J. Bayesian-multiplicative treatment of count zeros in compositional data sets. Stat. Model. 2015, 15, 134–158. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, X.; Hron, K.; Templ, M.; Li, S. Regression imputation with Q-mode clustering for rounded zero replacement in high-dimensional compositional data. J. Appl. Stat. 2017, 45, 2067–2080. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 5th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2002. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 3 September 2021).
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar]
- R Development Core Team. An Introduction to R: A Programming Environment for Data Analysis and Graphics; Version 4.0.2; R Foundation for Statistical Computing: Vienna, Austria, 2020; ISBN 3-900051-12-7. [Google Scholar]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2009. [Google Scholar]
- Templ, M.; Hron, K.; Filzmoser, P. robCompositions: An R-package for Robust Statistical Analysis of Compositional Data. In Compositional Data Analysis; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2011; pp. 341–355. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. Artic. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Venables, W.; Ripley, B. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Allaire, J.; Chollet, F. Keras: R Interface to ’Keras’. R Package Version 2.4.0. 2019. Available online: https://CRAN.R-project.org/package=keras (accessed on 3 September 2021).






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Templ, M.; Templ, B. Statistical Analysis of Chemical Element Compositions in Food Science: Problems and Possibilities. Molecules 2021, 26, 5752. https://doi.org/10.3390/molecules26195752
Templ M, Templ B. Statistical Analysis of Chemical Element Compositions in Food Science: Problems and Possibilities. Molecules. 2021; 26(19):5752. https://doi.org/10.3390/molecules26195752
Chicago/Turabian StyleTempl, Matthias, and Barbara Templ. 2021. "Statistical Analysis of Chemical Element Compositions in Food Science: Problems and Possibilities" Molecules 26, no. 19: 5752. https://doi.org/10.3390/molecules26195752