
Authentication and Provenance of Walnut Combining Fourier Transform Mid-Infrared Spectroscopy with Machine Learning Algorithms



Abstract
:1. Introduction
2. Results
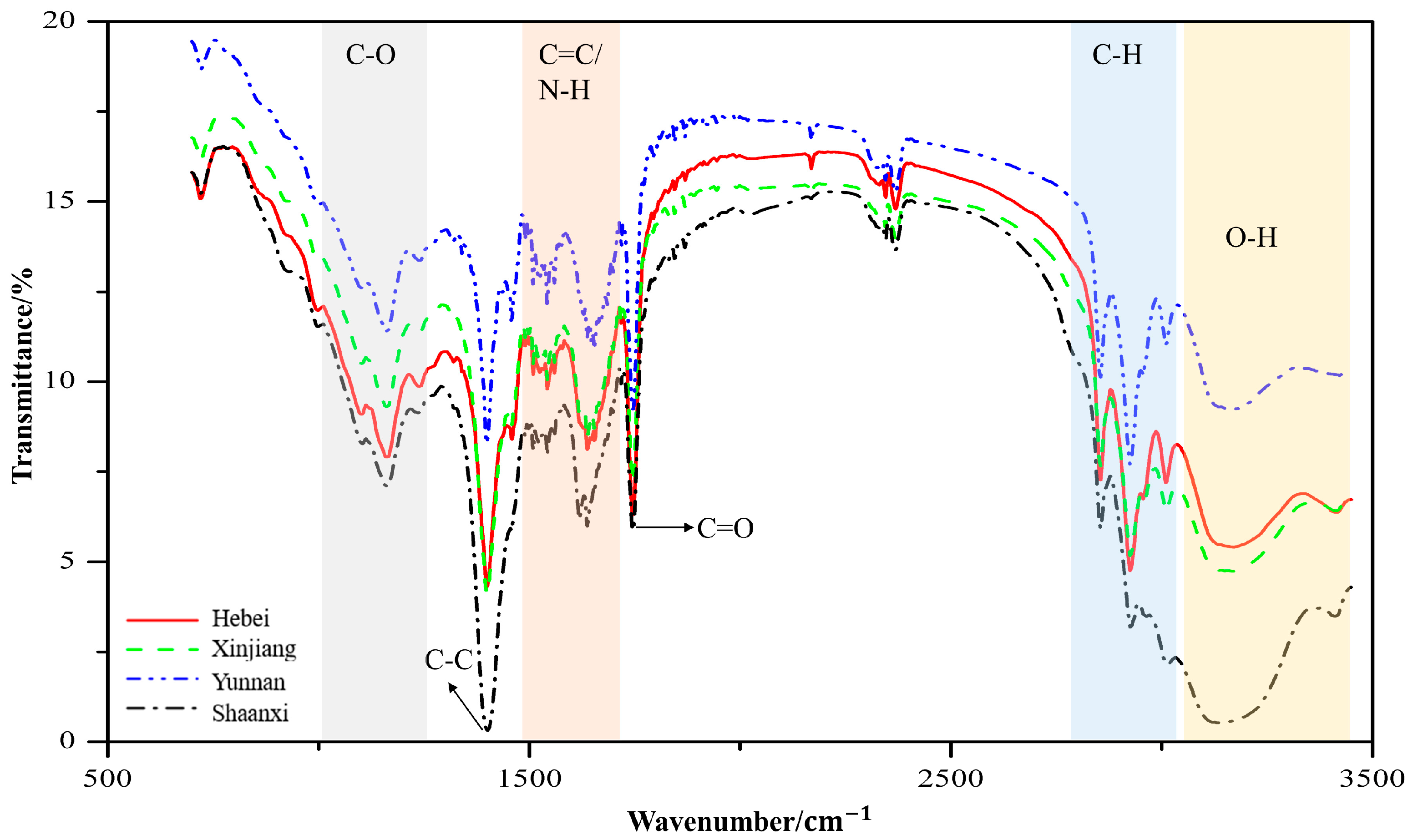
2.1. Spectral Profiles and Pre-Treatment
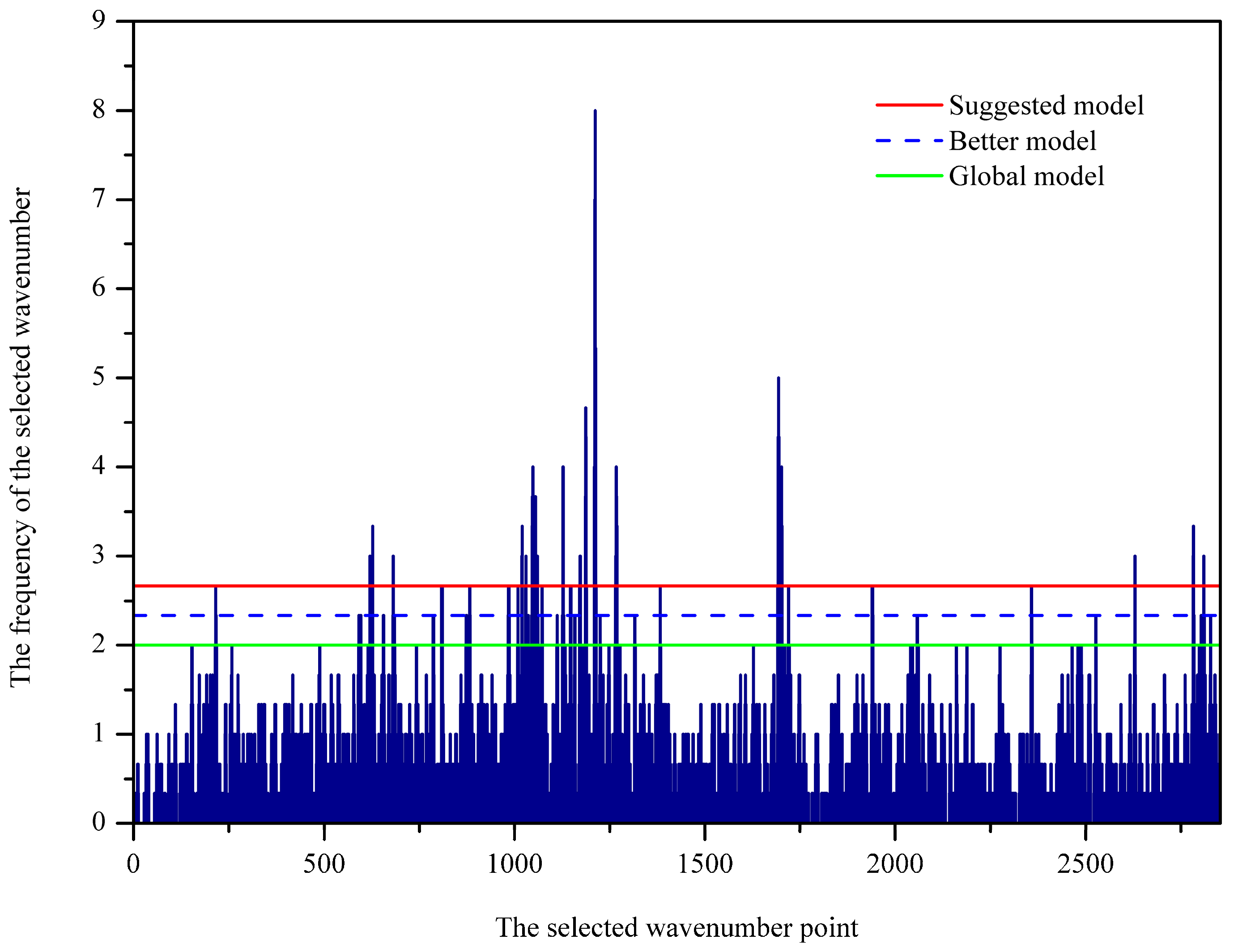
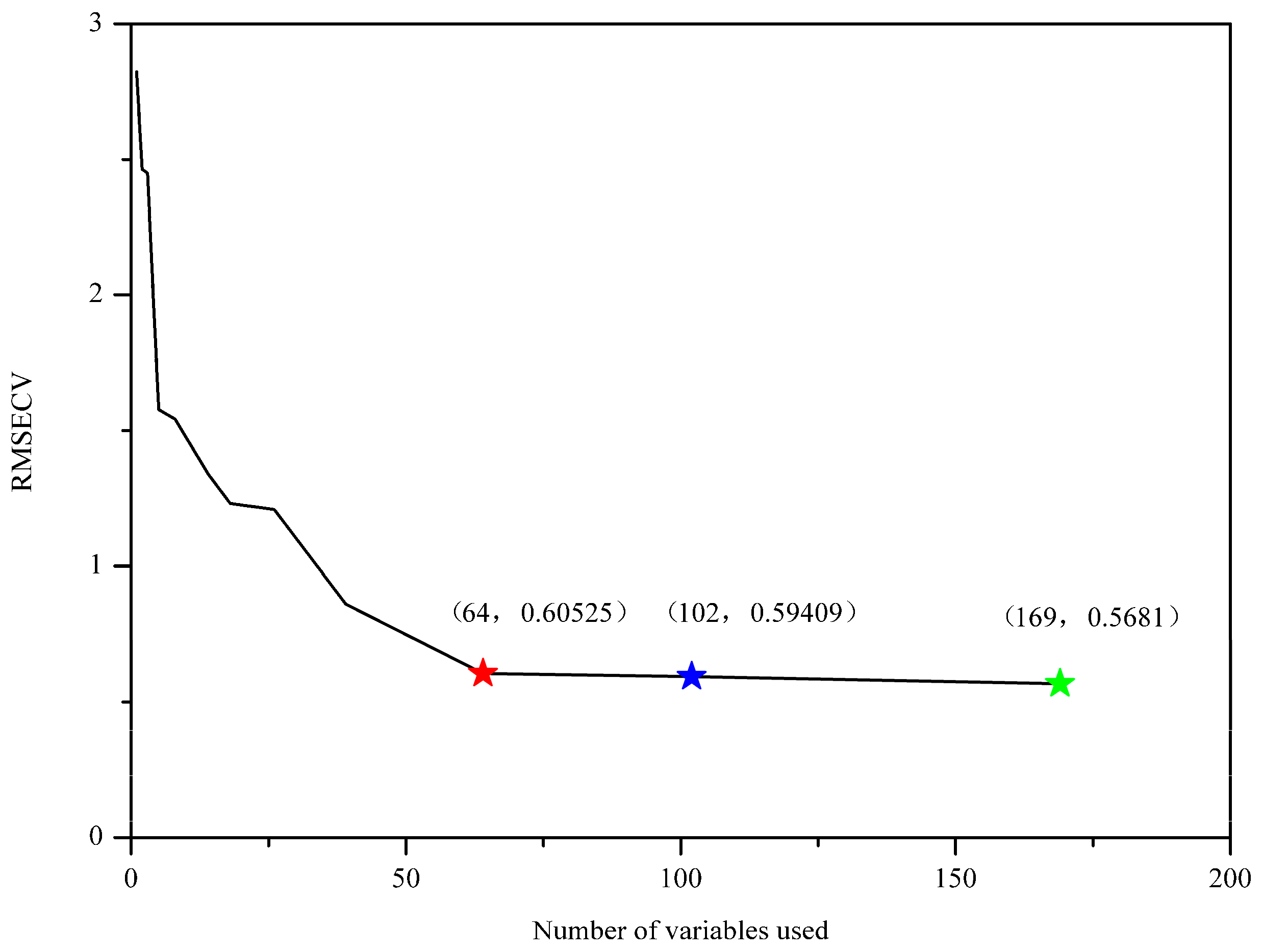
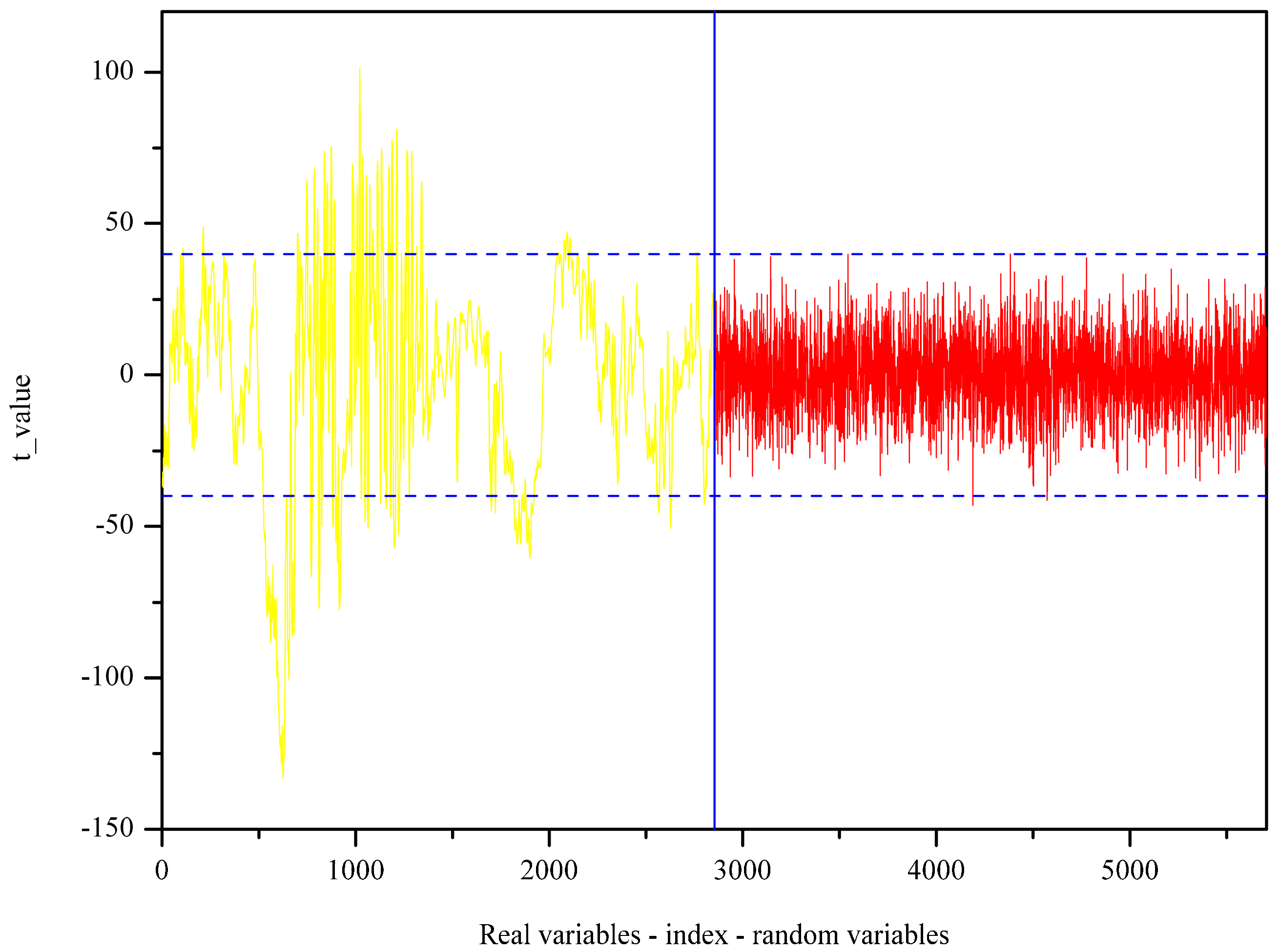
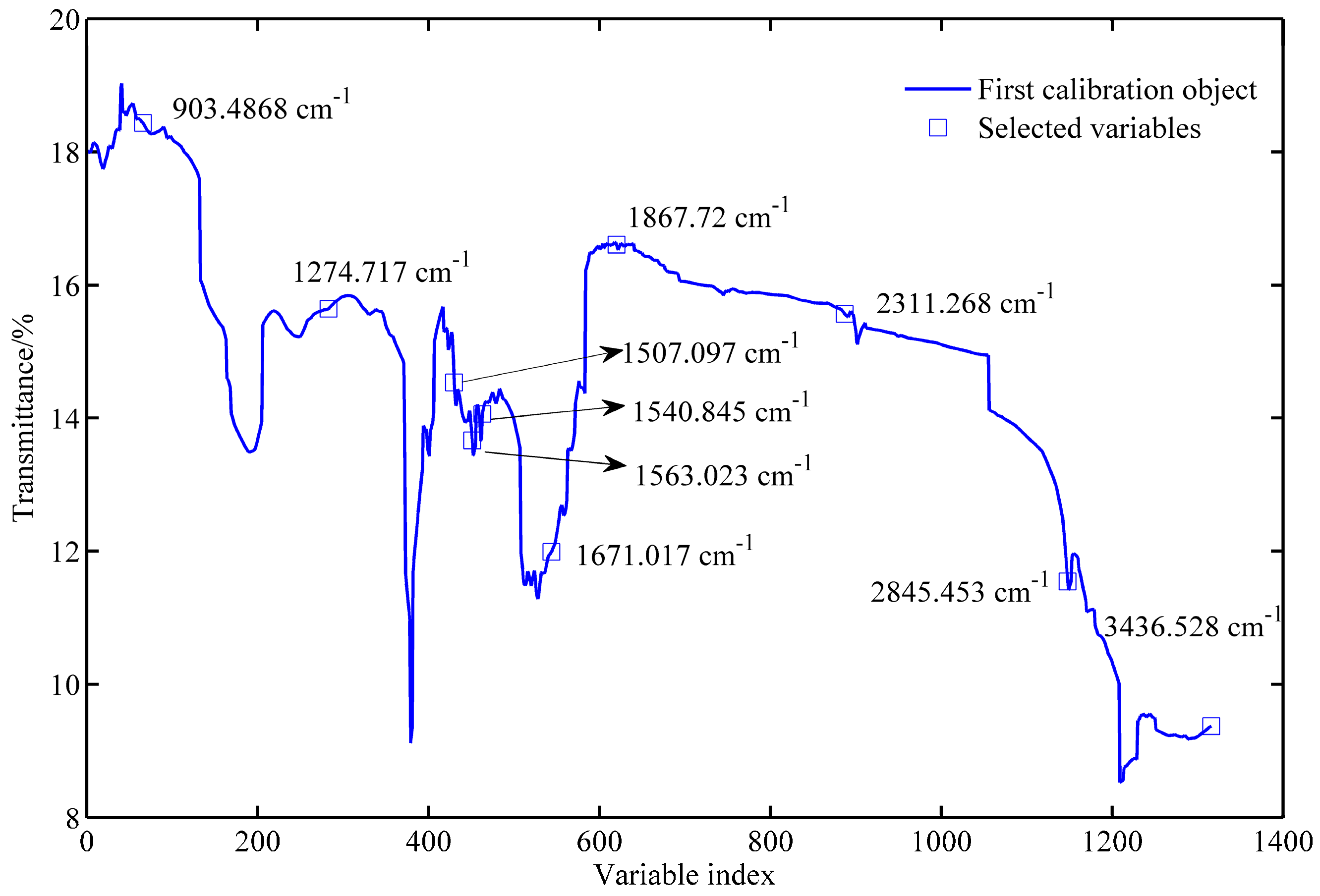
2.2. Optimal Wavenumbers Selection
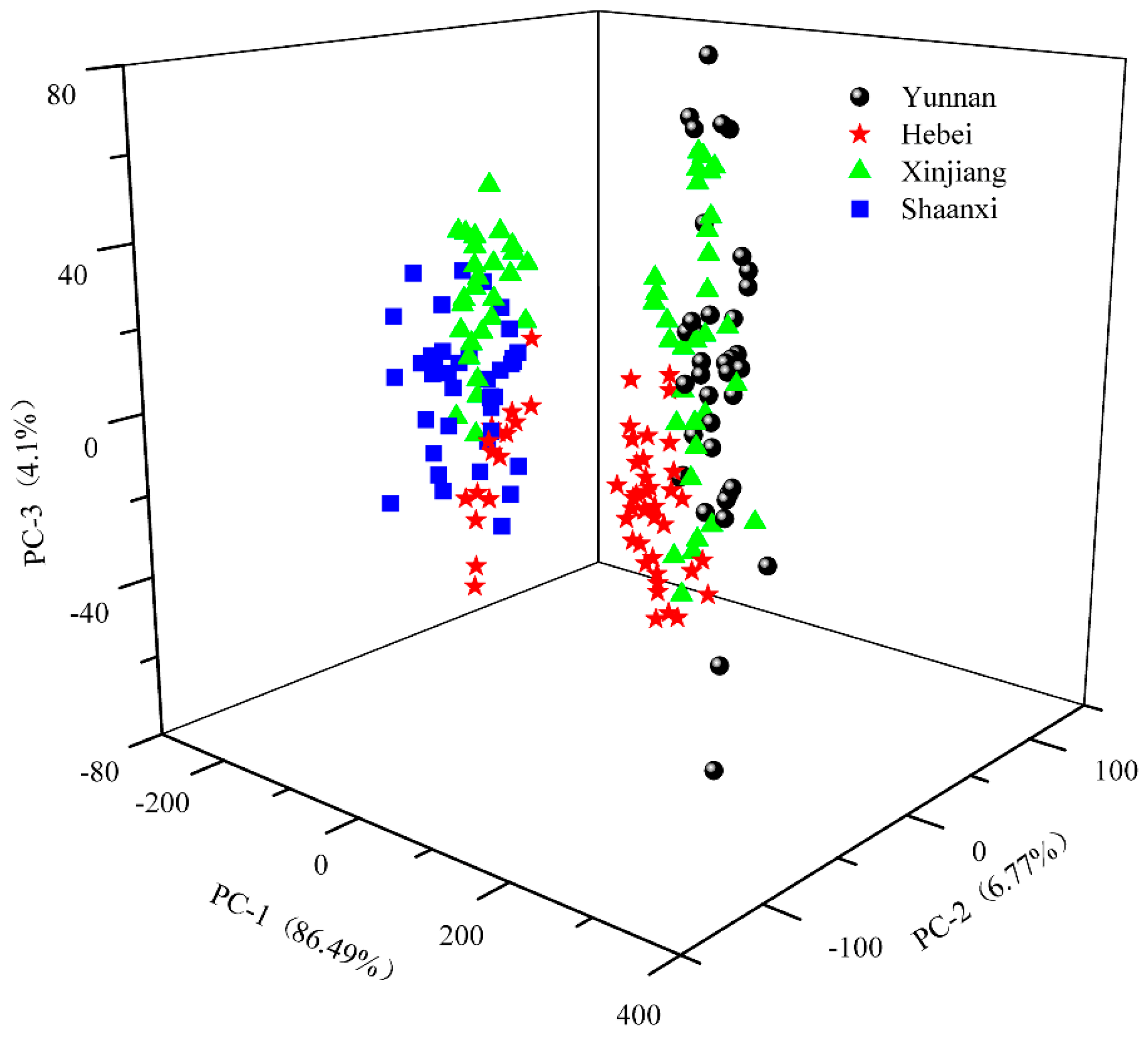
2.3. PCA Exploration
2.4. Classification of Geographic Origins
2.5. Classification of Varieties Under the Same Origin
2.6. Classification of All Varieties
3. Discussion
4. Materials and Methods
4.1. Walnut Sample Preparation
4.2. FT-MIR Spectroscopy Acquisition
4.3. Spectral Pre-Treatment
4.4. Optimal Spectral Variables Selection
4.5. Principal Component Analysis
4.6. Machine Learning Algorithms
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Şen, S.M.; Karadeniz, T. The nutritional value of walnut. J. Hyg. Eng. Des. 2015, 11, 68–71. [Google Scholar]
- Tao, K.W.C.; Sathe, S.K. Walnuts: Proximate composition, protein solubility, protein amino acid composition and pro-tein in vitro digestibility. J. Sci. Food Agric. 2000, 80, 1393–1401. [Google Scholar]
- Moser, B.R. Preparation of fatty acid methyl esters from hazelnut, high-oleic peanut and walnut oils and evaluation as biodiesel. Fuel 2012, 92, 231–238. [Google Scholar] [CrossRef]
- Papoutsi, Z.; Kassi, E.; Chinou, I.; Halabalaki, M.; Skaltsounis, L.A.; Moutsatsou, P. Walnut extract (Juglans regia L.) and its component ellagic acid exhibit anti-inflammatory activity in human aorta endothelial cells and osteoblastic activity in the cell line KS483. Br. J. Nutr. 2008, 99, 715–722. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Przekora, A.; Belcarz, A.; Kowalczyk, K.; Wójcik, M.; Wojciechowska, K.; Ginalska, G. UVB protective, anti-aging, and anti-inflammatory properties of aqueous extract of walnut (Juglans regia L.) seeds. Acta Pol. Pharm. 2018, 75, 1167–1176. [Google Scholar] [CrossRef]
- Rajaram, S.; Haddad, E.H.; Mejia, A.; Sabate, J. Walnuts and fatty fish influence different serum lipid fractions in normal to mildly hyperlipidemic individuals: A randomized controlled study. Am. J. Clin. Nutr. 2009, 89, 1657S–1663S. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gharibzahedi, S.M.T.; Mousavi, S.M.; Hamedi, M.; Rezaei, K.; Khodaiyan, F. Evaluation of physicochemical properties and antioxidant activities of Persian walnut oil obtained by several extraction methods. Ind. Crops Prod. 2013, 45, 133–140. [Google Scholar] [CrossRef]
- Tapp, H.S.; Defernez, M.; Kemsley, E.K. FTIR spectroscopy and multivariate analysis can distinguish the geographic origin of extra virgin olive oils. J. Agric. Food Chem. 2003, 51, 6110–6115. [Google Scholar] [CrossRef]
- Luykx, D.M.; Van Ruth, S.M. An overview of analytical methods for determining the geographical origin of food products. Food Chem. 2008, 107, 897–911. [Google Scholar] [CrossRef]
- Esteki, M.; Farajmand, B.; Amanifar, S.; Barkhordari, R.; Ahadiyan, Z.; Dashtaki, E.; Mohammadlou, M.; Vander Heyden, Y. Classification and authentication of Iranian walnuts according to their geographical origin based on gas chromatographic fatty acid fingerprint analysis using pattern recognition methods. Chemom. Intell. Lab. 2017, 171, 251–258. [Google Scholar] [CrossRef]
- Xiong, C.; Zheng, Y.; Xing, Y.; Chen, S.; Zeng, Y.; Ruan, G. Discrimination of two kinds of geographical origin protected Chinese vinegars using the characteristics of aroma compounds and multivariate statistical analysis. Food Anal. Methods 2016, 9, 768–776. [Google Scholar] [CrossRef]
- Troya, F.; Lerma-García, M.J.; Herrero-Martínez, J.M.; Simó-Alfonso, E.F. Classification of vegetable oils according to their botanical origin using n-alkane profiles established by GC–MS. Food Chem. 2015, 167, 36–39. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Zhao, Y.; Wu, H.; Dong, J.; Feng, J. Origin identification and quantitative analysis of honeys by nuclear magnetic resonance and chemometric techniques. Food Anal. Methods 2016, 9, 1470–1479. [Google Scholar] [CrossRef]
- Batun, P.; Bakkalbaşı, E.; Kazankaya, A.; Cavidoğlu, İ. Fatty acid profiles and mineral contents of walnuts from different provinces of Van Lake. GIDA J. Food 2017, 42, 155–162. [Google Scholar] [CrossRef]
- Bujdoso, G.; Konya, E.; Berki, M.; Nagy-Gasztonyi, M.; Bartha-Szuegyi, K.; Marton, B.; Izsepi, F.; Adanyi, N. Fatty acid composition, oxidative stability, and antioxidant properties of some Hungarian and other Persian walnut cultivars. Turk. J. Agric. For. 2016, 40, 160–168. [Google Scholar] [CrossRef]
- Xu, J.L.; Riccioli, C.; Sun, D.W. Development of an alternative technique for rapid and accurate determination of fish caloric density based on hyperspectral imaging. J. Food Eng. 2016, 190, 185–194. [Google Scholar] [CrossRef]
- Dankar, I.; Haddarah, A.; Omar, F.E.; Pujolà, M.; Sepulcre, F. Characterization of food additive-potato starch complexes by FTIR and X-ray diffraction. Food Chem. 2018, 260, 7–12. [Google Scholar] [CrossRef]
- Tsakanikas, P.; Karnavas, A.; Panagou, E.Z.; Nychas, G.J. A machine learning workflow for raw food spectroscopic classification in a future industry. Sci. Rep. 2020, 10, 11212. [Google Scholar] [CrossRef]
- Amendola, L.; Firmani, P.; Bucci, R.; Marini, F.; Biancolillo, A. Authentication of Sorrento Walnuts by NIR Spectroscopy Coupled with Different Chemometric Classification Strategies. Appl. Sci. 2020, 10, 4003. [Google Scholar] [CrossRef]
- Türker-Kaya, S.; Huck, C.W. A review of mid-infrared and near-infrared imaging: Principles, concepts and applications in plant tissue analysis. Molecules 2017, 22, 168. [Google Scholar] [CrossRef] [Green Version]
- Bevilacqua, M.; Bucci, R.; Magrì, A.D.; Magrì, A.L.; Marini, F. Data fusion for food authentication. Combining near and mid infrared to trace the origin of extra virgin olive oils. NIR News 2013, 24, 12–15. [Google Scholar] [CrossRef]
- Lan, W.; Renard, C.M.; Jaillais, B.; Leca, A.; Bureau, S. Fresh, freeze-dried or cell wall samples: Which is the most appropriate to determine chemical, structural and rheological variations during apple processing using ATR-FTIR spectroscopy? Food Chem. 2020, 330, 127357. [Google Scholar] [CrossRef]
- He, Y.; Bai, X.; Xiao, Q.; Liu, F.; Zhou, L.; Zhang, C. Detection of adulteration in food based on nondestructive analysis techniques: A review. Crit. Rev. Food Sci. 2020, 1–21. [Google Scholar] [CrossRef]
- Karunakaran, C.; Vijayan, P.; Stobbs, J.; Bamrah, R.K.; Arganosa, G.; Warkentin, T.D. High throughput nutritional profiling of pea seeds using Fourier transform mid-infrared spectroscopy. Food Chem. 2020, 309, 125585. [Google Scholar] [CrossRef]
- Defernez, M.; Kemsley, E.K.; Wilson, R.H. Use of infrared spectroscopy and chemometrics for the authentication of fruit purees. J. Agric. Food Chem. 1995, 43, 109–113. [Google Scholar] [CrossRef]
- Kelly, J.D.; Petisco, C.; Downey, G. Application of Fourier transform midinfrared spectroscopy to the discrimination between Irish artisanal honey and such honey adulterated with various sugar syrups. J. Agric. Food Chem. 2006, 54, 6166–6171. [Google Scholar] [CrossRef]
- Mandrile, L.; Barbosa-Pereira, L.; Sorensen, K.M.; Giovannozzi, A.M.; Zeppa, G.; Engelsen, S.B.; Rossi, A.M. Authentication of cocoa bean shells by near-and mid-infrared spectroscopy and inductively coupled plasma-optical emission spectroscopy. Food Chem. 2019, 292, 47–57. [Google Scholar] [CrossRef] [PubMed]
- Formosa, J.P.; Lia, F.; Mifsud, D.; Farrugia, C. Application of ATR-FT-MIR for tracing the geographical origin of honey produced in the Maltese islands. Foods 2020, 9, 710. [Google Scholar] [CrossRef]
- Mashkoor, F.; Nasar, A.; Asiri, A.M. Exploring the reusability of synthetically contaminated wastewater containing crystal violet dye using Tectona grandis sawdust as a very low-cost adsorbent. Sci. Rep. 2018, 8, 8314. [Google Scholar] [CrossRef] [Green Version]
- Mashkoor, F.; Nasar, A. Polyaniline/Tectona grandis sawdust: A novel composite for efficient decontamination of synthetically polluted water containing crystal violet dye. Groundw. Sustain. Dev. 2019, 8, 390–401. [Google Scholar] [CrossRef]
- Uddin, M.K.; Nasar, A. Walnut shell powder as a low-cost adsorbent for methylene blue dye: Isotherm, kinetics, thermodynamic, desorption and response surface methodology examinations. Sci. Rep. 2020, 10, 7983. [Google Scholar] [CrossRef]
- Fan, Y.; He, X.; Zhou, S.; Luo, A.; He, T.; Chun, Z. Composition analysis and antioxidant activity of polysaccharide from Dendrobium denneanum. Int. J. Biol. Macromol. 2009, 45, 169–173. [Google Scholar] [CrossRef]
- Vichi, S.; Pizzale, L.; Conte, L.S.; Buxaderas, S.; López-Tamames, E. Solid-phase microextraction in the analysis of virgin olive oil volatile fraction: Characterization of virgin olive oils from two distinct geographical areas of northern Italy. J. Agric. Food Chem. 2003, 51, 6572–6577. [Google Scholar] [CrossRef]
- Youssef, O.; Guido, F.; Manel, I.; Youssef, N.B.; Luigi, C.P.; Mohamed, H.; Daoud, D.; Mokhtar, Z. Volatile compounds and compositional quality of virgin olive oil from Oueslati variety: Influence of geographical origin. Food Chem. 2011, 124, 1770–1776. [Google Scholar] [CrossRef]
- Vermeulen, P.; Fernández Pierna, J.A.; Abbas, O.; Dardenne, P.; Baeten, V. Origin identification of dried distillers grains with solubles using attenuated total reflection Fourier transform mid-infrared spectroscopy after in situ oil extraction. Food Chem. 2015, 189, 19–26. [Google Scholar] [CrossRef]
- Durand, A.; Devos, O.; Ruckebusch, C.; Huvenne, J.P. Genetic algorithm optimisation combined with partial least squares regression and mutual information variable selection procedures in near-infrared quantitative analysis of cotton–viscose textiles. Anal. Chim. Acta 2007, 595, 72–79. [Google Scholar] [CrossRef]
- Leardi, R.; González, A.L. Genetic algorithms applied to feature selection in PLS regression: How and when to use them. Chemom. Intell. Lab. 1998, 41, 195–207. [Google Scholar] [CrossRef]
- Leardi, R. Application of genetic algorithm–PLS for feature selection in spectral data sets. J. Chemom. 2000, 14, 643–655. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvao, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Wu, D.; Chen, X.; Zhu, X.; Guan, X.; Wu, G. Uninformative variable elimination for improvement of successive projections algorithm on spectral multivariable selection with different calibration algorithms for the rapid and non-destructive determination of protein content in dried laver. Anal. Methods 2011, 3, 1790–1796. [Google Scholar] [CrossRef]
- Ding, S.; Zhao, H.; Zhang, Y.; Xu, X.; Nie, R. Extreme learning machine: Algorithm, theory and applications. Artif. Intell. Rev. 2015, 44, 103–115. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar]
- Wang, L.; Lee, F.S.; Wang, X.; He, Y. Feasibility study of quantifying and discriminating soybean oil adulteration in camellia oils by attenuated total reflectance MIR and fiber optic diffuse reflectance NIR. Food Chem. 2006, 95, 529–536. [Google Scholar] [CrossRef]
- Luna, A.S.; da Silva, A.P.; Pinho, J.S.; Ferré, J.; Boqué, R. Rapid characterization of transgenic and non-transgenic soybean oils by chemometric methods using NIR spectroscopy. Spectrochim. Acta A 2013, 100, 115–119. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Wang, L.; He, Y.; Jiang, Y.H. Discrimination of varieties of yellow wines using Vis/NIR spectroscopy. Spectrosc. Spect. Anal. 2008, 28, 586–589. [Google Scholar]
- Gong, A.; Qiu, Z.; He, Y.; Wang, Z. A non-destructive method for quantification the irradiation doses of irradiated sucrose using Vis/NIR spectroscopy. Spectrochim. Acta A 2012, 99, 7–11. [Google Scholar] [CrossRef]
- Wythoff, B.J. Backpropagation neural networks: A tutorial. Chemom. Intell. Lab. 1993, 18, 115–155. [Google Scholar] [CrossRef]
- Jain, L.C.; Halici, U.; Hayashi, I.; Lee, S.B.; Tsutsui, S. Intelligent Biometric Techniques in Fingerprint and Face Recognition; CRC press: Boca Raton, FL, USA, 1999; pp. 3–34. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Parameter | Yunnan | Xinjiang | Shaanxi | Hebei | Overall |
|---|---|---|---|---|---|---|
| ELM | 62 | 84.62 | 70.00 | 100.00 | 52.63 | 74.24 |
| RF | 40 | 61.54 | 65.00 | 57.14 | 89.47 | 69.70 |
| RBF | 66 | 69.23 | 100.00 | 64.29 | 94.74 | 84.85 |
| PLS-DA | 12 | 69.23 | 50.00 | 71.43 | 84.21 | 68.18 |
| UVE-SPA-ELM | 56 | 61.54 | 90.00 | 71.43 | 94.74 | 81.82 |
| UVE-SPA-RF | 88 | 58.85 | 75.00 | 50.00 | 89.47 | 69.70 |
| UVE-SPA-RBF | 70 | 76.92 | 35.00 | 28.57 | 78.95 | 54.55 |
| UVE-SPA-PLS-DA | 6 | 53.85 | 90.00 | 100.00 | 89.47 | 84.85 |
| UVE-SPA-BPNN | 8 | 100.00 | 100.00 | 93.33 | 94.74 | 96.97 |
| GA-PLS-ELM | 108 | 69.23 | 85.00 | 71.43 | 78.95 | 77.27 |
| GA-PLS-RF | 60 | 58.85 | 75.00 | 50.00 | 89.47 | 69.70 |
| GA-PLS-RBF | 15 | 61.54 | 90.00 | 64.29 | 94.74 | 80.30 |
| GA-PLS-PLS-DA | 9 | 84.62 | 85.00 | 92.86 | 94.74 | 89.39 |
| GA-PLS-BPNN | 6 | 92.31 | 95.00 | 92.86 | 100.00 | 95.45 |
| Origin | Variable Input | ELM | RF | RBF | PLS-DA | BPNN |
|---|---|---|---|---|---|---|
| Yunnan (No.1 No.2) | Full | 84.62 | 84.62 | 92.31 | 84.62 | - |
| GA-PLS | 92.31 | 84.62 | 92.31 | 92.31 | 100.00 | |
| UVE-SPA | 92.31 | 84.62 | 100.00 | 92.31 | 100.00 | |
| Xinjiang (No.3 No.4 No.5) | Full | 70.00 | 65.00 | 90.00 | 70.00 | - |
| GA-PLS | 90.00 | 65.00 | 90.00 | 65.00 | 94.74 | |
| UVE-SPA | 100.00 | 70.00 | 85.00 | 65.00 | 100.00 | |
| Shaanxi (No.6 No.7) | Full | 85.71 | 92.31 | 100.00 | 100.00 | - |
| GA-PLS | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| UVE-SPA | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | |
| Hebei (No.8 No.9 No.10) | Full | 73.68 | 68.42 | 68.42 | 78.95 | - |
| GA-PLS | 78.95 | 73.68 | 73.68 | 78.95 | 94.74 | |
| UVE-SPA | 84.21 | 68.42 | 63.16 | 73.68 | 89.47 |
| Classifier | ELM | RF | RBF | PLS-DA | BPNN | |
|---|---|---|---|---|---|---|
| Variable Input | ||||||
| Full | 60.61 | 54.55 | 68.18 | 42.42 | - | |
| GA-PLS | 68.18 | 53.03 | 71.21 | 60.61 | 87.88 | |
| UVE-SPA | 66.67 | 48.48 | 60.61 | 51.52 | 83.33 | |
| Province | Geographical Location | Variety | Characteristic | Sample Size | Data Partition (Training/Test Samples) |
|---|---|---|---|---|---|
| Yunnan | Southwest of China; 97°32′ ≈ 106°12′ E, 21°08′ ≈ 29°15′ N | No. 1: Yangbi Dapao | As the most planted variety in Yunnan, it is mainly distributed on the western slope of Cangshan Mountain in Yunnan, accounting for about 80% of Yangbi walnuts. | 20 | 13/7 |
| No. 2: Yangbi Caoguo | It is mostly found in Meiji Village, West Town of Cangshan, Yunnan. The inner folds are well developed, and whole kernels can be collected. | 19 | 13/6 | ||
| Xinjiang | Northwest of China; 34°22′ ≈ 49°33′ E, 73°41′ ≈ 96°18′ N | No. 3: Hetian 185 | It is the main walnut variety cultivated in Xinjiang, mostly found in southern Xinjiang. | 19 | 13/6 |
| No. 4: Xinfeng | Grown at the altitude of 1700–2400 m, it is named after the skin, which is as thin as paper, and the whole kernel is easy to collect. | 20 | 13/7 | ||
| No. 5: Xinxin 2 | It is an early-maturing variety with the characteristics of high yield and good stability. | 20 | 13/7 | ||
| Shaanxi | Northwest of China; 105°29′ ≈ 111°15′ E, 31°42′ ≈ 39°35′ N | No. 6: Liao 4 | As a crossbreed, this variety has strong adaptability, cold and drought tolerance, making it suitable for northern cultivation areas. | 20 | 13/7 |
| No. 7: Xiangling | It is a mid-ripening variety, ideal for cultivation in thick and fertile soil conditions. | 20 | 13/7 | ||
| Hebei | Northern China; 113°04′ ≈ 119°53′ E, 36°01′ ≈ 42°37′ N | No.8: Qingxiang | It belongs to the late-maturing type, which was introduced from Japan. | 16 | 10/6 |
| No.9: Liao 1 | It is the main variety of walnut cultivated in Hebei. | 18 | 12/6 | ||
| No.10: Liao 8 | As one of the early-fruiting walnut varieties cultivated by hybridization, it gets mature in mid-September. | 20 | 13/7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Xu, J.-L. Authentication and Provenance of Walnut Combining Fourier Transform Mid-Infrared Spectroscopy with Machine Learning Algorithms. Molecules 2020, 25, 4987. https://doi.org/10.3390/molecules25214987
Zhu H, Xu J-L. Authentication and Provenance of Walnut Combining Fourier Transform Mid-Infrared Spectroscopy with Machine Learning Algorithms. Molecules. 2020; 25(21):4987. https://doi.org/10.3390/molecules25214987
Chicago/Turabian StyleZhu, Hongyan, and Jun-Li Xu. 2020. "Authentication and Provenance of Walnut Combining Fourier Transform Mid-Infrared Spectroscopy with Machine Learning Algorithms" Molecules 25, no. 21: 4987. https://doi.org/10.3390/molecules25214987