
Adaptive Dual Aggregation Network with Normalizing Flows for Low-Light Image Enhancement

Abstract
:1. Introduction
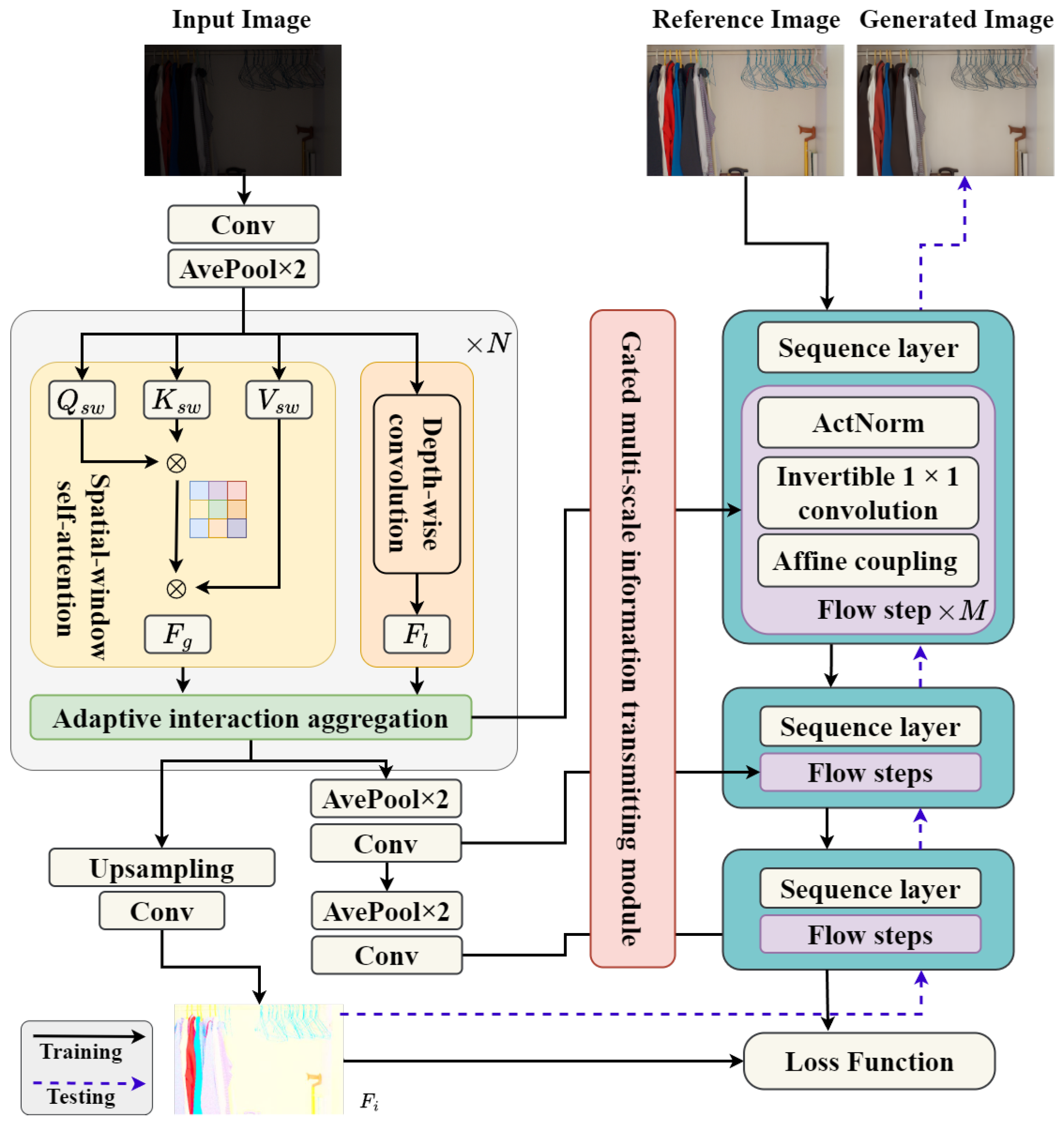
- An adaptive dual aggregation encoder is leveraged to fully capture the global properties and local details of low-light images for extracting illumination-robust features from low-light images.
- To measure real visual errors between enhanced and normally exposed images, a reversible normalizing flow decoder is used to map enhanced and normally exposed images to potential distributions, and the difference between the distributions is used as the objective function for training.
- A gated multi-scale information transmitting module is designed to introduce the multi-scale features from the adaptive dual aggregation encoder into the normalizing flow decoder to further improve the quality of enhanced images.
2. Related Work
2.1. Traditional Methods
2.2. Deep-Learning-Based Methods
3. Methods
3.1. Adaptive Dual Aggregation Encoder
3.1.1. Preprocessing
3.1.2. Global–Local Adaptive Aggregation Module
3.2. Normalizing Flow Decoder
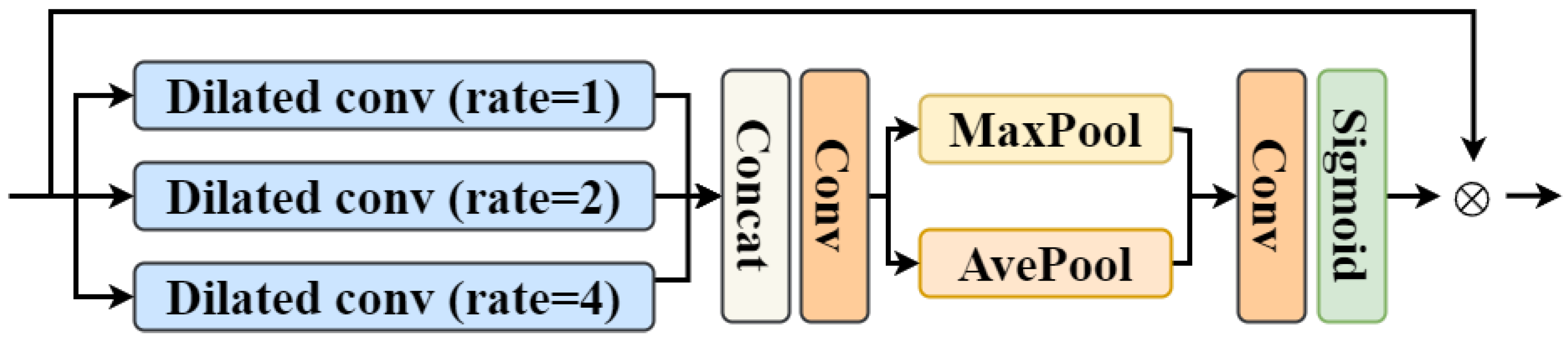
3.3. Mapping Learning Aided by Multi-Scale Features
3.4. Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implement Details
4.3. Comparisons with the State-of-the-Art Methods on Paired Datasets
4.4. Comparisons with the State-of-the-Art Methods on Unpaired Datasets
4.5. Visualization
4.6. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, K.; Yuan, C.; Li, J.; Gao, X.; Li, M. Multi-Branch and Progressive Network for Low-Light Image Enhancement. IEEE Trans. Image Process. 2023, 32, 2295–2308. [Google Scholar] [CrossRef]
- Fan, G.D.; Fan, B.; Gan, M.; Chen, G.Y.; Chen, C.L.P. Multiscale Low-Light Image Enhancement Network With Illumination Constraint. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7403–7417. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef]
- Sun, H.; Li, Q.; Yu, J.; Zhou, D.; Chen, W.; Zheng, X.; Lu, X. Deep Feature Reconstruction Learning for Open-Set Classification of Remote-Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.M.; Gu, J.; Loy, C.C. Low-Light Image and Video Enhancement Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9396–9416. [Google Scholar] [CrossRef]
- Brateanu, A.; Balmez, R.; Avram, A.; Orhei, C. LYT-Net: Lightweight YUV Transformer-based Network for Low-Light Image Enhancement. arXiv 2024, arXiv:2401.15204. [Google Scholar]
- Kong, N.S.P.; Ibrahim, H. Color image enhancement using brightness preserving dynamic histogram equalization. IEEE Trans. Consum. Electron. 2008, 54, 1962–1968. [Google Scholar] [CrossRef]
- Ibrahim, H.; Pik Kong, N.S. Brightness Preserving Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Jeong, I.; Lee, C. An optimization-based approach to gamma correction parameter estimation for low-light image enhancement. Multimed. Tools Appl. 2021, 80, 18027–18042. [Google Scholar] [CrossRef]
- Kim, W. Low-Light Image Enhancement: A Comparative Review and Prospects. IEEE Access 2022, 10, 84535–84557. [Google Scholar] [CrossRef]
- Bertalmío, M.; Caselles, V.; Provenzi, E. Issues about retinex theory and contrast enhancement. Int. J. Comput. Vis. 2009, 83, 101–119. [Google Scholar] [CrossRef]
- Ren, X.; Yang, W.; Cheng, W.H.; Liu, J. LR3M: Robust Low-Light Enhancement via Low-Rank Regularized Retinex Model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef]
- Gu, Z.; Li, F.; Fang, F.; Zhang, G. A Novel Retinex-Based Fractional-Order Variational Model for Images With Severely Low Light. IEEE Trans. Image Process. 2020, 29, 3239–3253. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yu, Y.; Yang, W.; Guo, L.; Chau, L.P.; Kot, A.C.; Wen, B. Exposurediffusion: Learning to expose for low-light image enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12438–12448. [Google Scholar]
- Rasheed, M.T.; Shi, D.; Khan, H. A comprehensive experiment-based review of low-light image enhancement methods and benchmarking low-light image quality assessment. Signal Process. 2023, 204, 108821. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2654–2662. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Liu, X.; Ma, W.; Ma, X.; Wang, J. LAE-Net: A locally-adaptive embedding network for low-light image enhancement. Pattern Recognit. 2023, 133, 109039. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. In Proceedings of the British Machine Vision Conference 2018, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse Gradient Regularized Deep Retinex Network for Robust Low-Light Image Enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef]
- Guo, X.; Hu, Q. Low-light image enhancement via breaking down the darkness. Int. J. Comput. Vis. 2023, 131, 48–66. [Google Scholar] [CrossRef]
- HU, X.; WANG, J.; XU, S. Lightweight and Fast Low-Light Image Enhancement Method Based on PoolFormer. IEICE Trans. Inf. Syst. 2024, 107, 157–160. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Ma, L.; Liu, R.; Zhang, J.; Fan, X.; Luo, Z. Learning deep context-sensitive decomposition for low-light image enhancement. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5666–5680. [Google Scholar] [CrossRef]
- Liu, X.; Xie, Q.; Zhao, Q.; Wang, H.; Meng, D. Low-Light Image Enhancement by Retinex-Based Algorithm Unrolling and Adjustment. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. Uretinex-net: Retinex-based deep unfolding network for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5901–5910. [Google Scholar]
- Fan, M.; Wang, W.; Yang, W.; Liu, J. Integrating Semantic Segmentation and Retinex Model for Low-Light Image Enhancement. In Proceedings of the 28th ACM International Conference on Multimedia (MM 2020), Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery, Inc.: New York, NY, USA, 2020; pp. 2317–2325. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Xu, X.; Wang, R.; Fu, C.W.; Jia, J. SNR-aware low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17714–17724. [Google Scholar]
- Li, J.; Feng, X.; Hua, Z. Low-light image enhancement via progressive-recursive network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4227–4240. [Google Scholar] [CrossRef]
- Yang, S.; Zhou, D.; Cao, J.; Guo, Y. LightingNet: An Integrated Learning Method for Low-Light Image Enhancement. IEEE Trans. Comput. Imaging 2023, 9, 29–42. [Google Scholar] [CrossRef]
- Zhang, Z.; Jiang, Z.; Liu, J.; Fan, X.; Liu, R. Waterflow: Heuristic normalizing flow for underwater image enhancement and beyond. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 7314–7323. [Google Scholar]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-light image enhancement with normalizing flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; Volume 36, pp. 2604–2612. [Google Scholar]
- Lugmayr, A.; Danelljan, M.; Van Gool, L.; Timofte, R. Srflow: Learning the super-resolution space with normalizing flow. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part V 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 715–732. [Google Scholar]
- Jähne, B. Digital Image Processing; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal Process. Syst. Signal Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Lee, C.; Lee, C.; Kim, C.S. Contrast Enhancement Based on Layered Difference Representation of 2D Histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef] [PubMed]
- Gu, K.; Wang, S.; Zhai, G.; Ma, S.; Yang, X.; Lin, W.; Zhang, W.; Gao, W. Blind quality assessment of tone-mapped images via analysis of information, naturalness, and structure. IEEE Trans. Multimed. 2016, 18, 432–443. [Google Scholar] [CrossRef]
- Kimmel, R.; Elad, M.; Shaked, D.; Keshet, R.; Sobel, I. A variational framework for retinex. Int. J. Comput. Vis. 2003, 52, 7–23. [Google Scholar] [CrossRef]
- Liang, Z.; Liu, W.; Yao, R. Contrast Enhancement by Nonlinear Diffusion Filtering. IEEE Trans. Image Process. 2016, 25, 673–686. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the Darkness: A Practical Low-Light Image Enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Ren, W.; Liu, S.; Ma, L.; Xu, Q.; Xu, X.; Cao, X.; Du, J.; Yang, M.H. Low-Light Image Enhancement via a Deep Hybrid Network. IEEE Trans. Image Process. 2019, 28, 4364–4375. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Yang, X.; Yin, B.; Lau, R.W. Learning to restore low-light images via decomposition-and-enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2281–2290. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a Deep Single Image Contrast Enhancer from Multi-Exposure Images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1780–1789. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Yao, H.; Chen, R.; Chen, W.; Sun, H.; Xie, W.; Lu, X. Pseudolabel-Based Unreliable Sample Learning for Semi-Supervised Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–16. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. Adv. Neural Inf. Process. Syst. 2018, 31, 1–10. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, Z.; Ran, W.; Liu, S.; Li, K.; Lu, J.; Xie, C.; Liu, Y.; Lu, H. Low-Light Image Enhancement with Multi-Scale Attention and Frequency-Domain Optimization. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Orhei, C.; Vasiu, R. An Analysis of Extended and Dilated Filters in Sharpening Algorithms. IEEE Access 2023, 11, 81449–81465. [Google Scholar] [CrossRef]
- Lee, C.; Lee, C.; Kim, C.S. Contrast enhancement based on layered difference representation. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 965–968. [Google Scholar]
- Li, M.; Liu, J.; Yang, W.; Sun, X.; Guo, Z. Structure-Revealing Low-Light Image Enhancement Via Robust Retinex Model. IEEE Trans. Image Process. 2018, 27, 2828–2841. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, J.; Hu, H.M.; Li, B. Naturalness Preserved Enhancement Algorithm for Non-Uniform Illumination Images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From Fidelity to Perceptual Quality: A Semi-Supervised Approach for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond Brightening Low-light Images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Learning Enriched Features for Fast Image Restoration and Enhancement. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 1934–1948. [Google Scholar] [CrossRef] [PubMed]
- Yi, X.; Xu, H.; Zhang, H.; Tang, L.; Ma, J. Diff-retinex: Rethinking low-light image enhancement with a generative diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 12302–12311. [Google Scholar]
- Yang, S.; Zhou, D.; Cao, J.; Guo, Y. Rethinking low-light enhancement via transformer-GAN. IEEE Signal Process. Lett. 2022, 29, 1082–1086. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Zhang, Z.; Zheng, H.; Hong, R.; Xu, M.; Yan, S.; Wang, M. Deep Color Consistent Network for Low-Light Image Enhancement. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1889–1898. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | LOLv1 | Complexity | ||||
|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | GFLOPs | Params/M | ||
| LIME [3] | 16.76 | 0.560 | 0.350 | - | - | |
| Zero-DCE [47] | 14.86 | 0.562 | 0.335 | - | 0.33 | |
| RetinexNet [21] | 16.77 | 0.462 | 0.474 | 587.47 | 0.84 | |
| DRBN [60] | 19.86 | 0.834 | 0.155 | 48.61 | 5.27 | |
| KinD [43] | 20.87 | 0.799 | 0.207 | 34.99 | 8.02 | |
| KinD++ [61] | 21.30 | 0.823 | 0.175 | - | 9.63 | |
| EnlightenGAN [62] | 17.48 | 0.652 | 0.322 | 61.01 | 114.35 | |
| MIRNet [63] | 24.14 | 0.842 | 0.131 | 785 | 31.76 | |
| LLFlow [35] | 25.13 | 0.872 | 0.117 | - | 37.68 | |
| LLFormer [16] | 25.76 | 0.823 | 0.167 | - | 24.55 | |
| Diff-Retinex [64] | 21.98 | 0.863 | 0.048 | - | - | |
| Transformer-GAN [65] | 23.50 | 0.851 | - | - | - | |
| Restormer [66] | 22.43 | 0.823 | - | 144.25 | 26.13 | |
| SNR-Aware [31] | 26.72 | 0.851 | 0.152 | 26.35 | 4.01 | |
| ADANF (ours) | 26.67 | 0.873 | 0.120 | 252.39 | 117.59 | |
| Method | LOLv2-Real | Complexity | ||||
|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | GFLOPs | Params | ||
| LIME [3] | 15.24 | 0.470 | 0.415 | - | - | |
| Zero-DCE [47] | 18.06 | 0.580 | 0.313 | - | 0.33 | |
| RetinexNet [21] | 18.37 | 0.723 | 0.365 | 587.47 | 0.84 | |
| DRBN [60] | 20.13 | 0.830 | 0.147 | 48.61 | 5.27 | |
| KinD [43] | 17.54 | 0.669 | 0.375 | 34.99 | 8.02 | |
| KinD++ [61] | 19.09 | 0.817 | 0.180 | - | 9.63 | |
| EnlightenGAN [62] | 18.64 | 0.677 | 0.309 | 61.01 | 114.35 | |
| MIRNet [63] | 20.36 | 0.782 | 0.317 | 785 | 31.76 | |
| LLFlow [35] | 26.20 | 0.888 | 0.137 | - | 37.68 | |
| LLFormer [16] | 26.20 | 0.819 | 0.209 | - | 24.55 | |
| Restormer [66] | 19.94 | 0.827 | - | 144.25 | 26.13 | |
| SNR-Aware [31] | 27.21 | 0.871 | 0.157 | 26.35 | 4.01 | |
| ADANF(ours) | 28.01 | 0.891 | 0.134 | 252.39 | 117.59 | |
| Method | LOLv2-Synthetic | Complexity | ||||
|---|---|---|---|---|---|---|
| PSNR↑ | SSIM↑ | LPIPS↓ | FLOPs | Params | ||
| LIME [3] | 16.88 | 0.776 | 0.675 | - | - | |
| RetinexNet [21] | 17.13 | 0.798 | 0.754 | 587.47 | 0.84 | |
| DRBN [60] | 23.22 | 0.927 | - | 48.61 | 5.27 | |
| KinD [43] | 16.26 | 0.591 | 0.435 | 34.99 | 8.02 | |
| KinD++ [61] | - | - | - | - | 9.63 | |
| EnlightenGAN [62] | 16.57 | 0.734 | - | 61.01 | 114.35 | |
| MIRNet [63] | 21.94 | 0.846 | - | 785 | 31.76 | |
| LLFlow [35] | 24.81 | 0.919 | 0.067 | - | 37.68 | |
| LLFormer [16] | 28.01 | 0.927 | 0.061 | - | 24.55 | |
| Restormer [66] | 21.41 | 0.830 | - | 144.25 | 26.13 | |
| SNR-Aware [31] | 27.79 | 0.941 | 0.054 | 26.35 | 4.01 | |
| ADANF(ours) | 28.67 | 0.953 | 0.040 | 252.39 | 117.59 | |
| Methods | DICM | LIME | MEF | NPE | VV |
|---|---|---|---|---|---|
| Zero-DCE [47] | 4.58 | 5.82 | 4.93 | 4.53 | 4.81 |
| EnlightenGAN [62] | 4.06 | 4.59 | 4.70 | 3.99 | 4.04 |
| RetinexNet [21] | 4.33 | 5.75 | 4.93 | 4.95 | 4.32 |
| KinD [43] | 3.95 | 4.42 | 4.45 | 3.92 | 3.72 |
| KinD++ [61] | 3.89 | 4.90 | 4.55 | 3.91 | 3.82 |
| DCC-Net [67] | 3.70 | 4.42 | 4.59 | 3.70 | 3.28 |
| ADANF(ours) | 3.90 | 3.78 | 3.59 | 4.24 | 3.14 |
| ADAE | GMITM | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|
| 24.83 | 0.819 | 0.157 | ||
| √ | 26.05 | 0.822 | 0.134 | |
| √ | 25.91 | 0.845 | 0.126 | |
| √ | √ | 26.67 | 0.873 | 0.120 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Cao, J.; Huang, J. Adaptive Dual Aggregation Network with Normalizing Flows for Low-Light Image Enhancement. Entropy 2024, 26, 184. https://doi.org/10.3390/e26030184
Wang H, Cao J, Huang J. Adaptive Dual Aggregation Network with Normalizing Flows for Low-Light Image Enhancement. Entropy. 2024; 26(3):184. https://doi.org/10.3390/e26030184
Chicago/Turabian StyleWang, Hua, Jianzhong Cao, and Jijiang Huang. 2024. "Adaptive Dual Aggregation Network with Normalizing Flows for Low-Light Image Enhancement" Entropy 26, no. 3: 184. https://doi.org/10.3390/e26030184