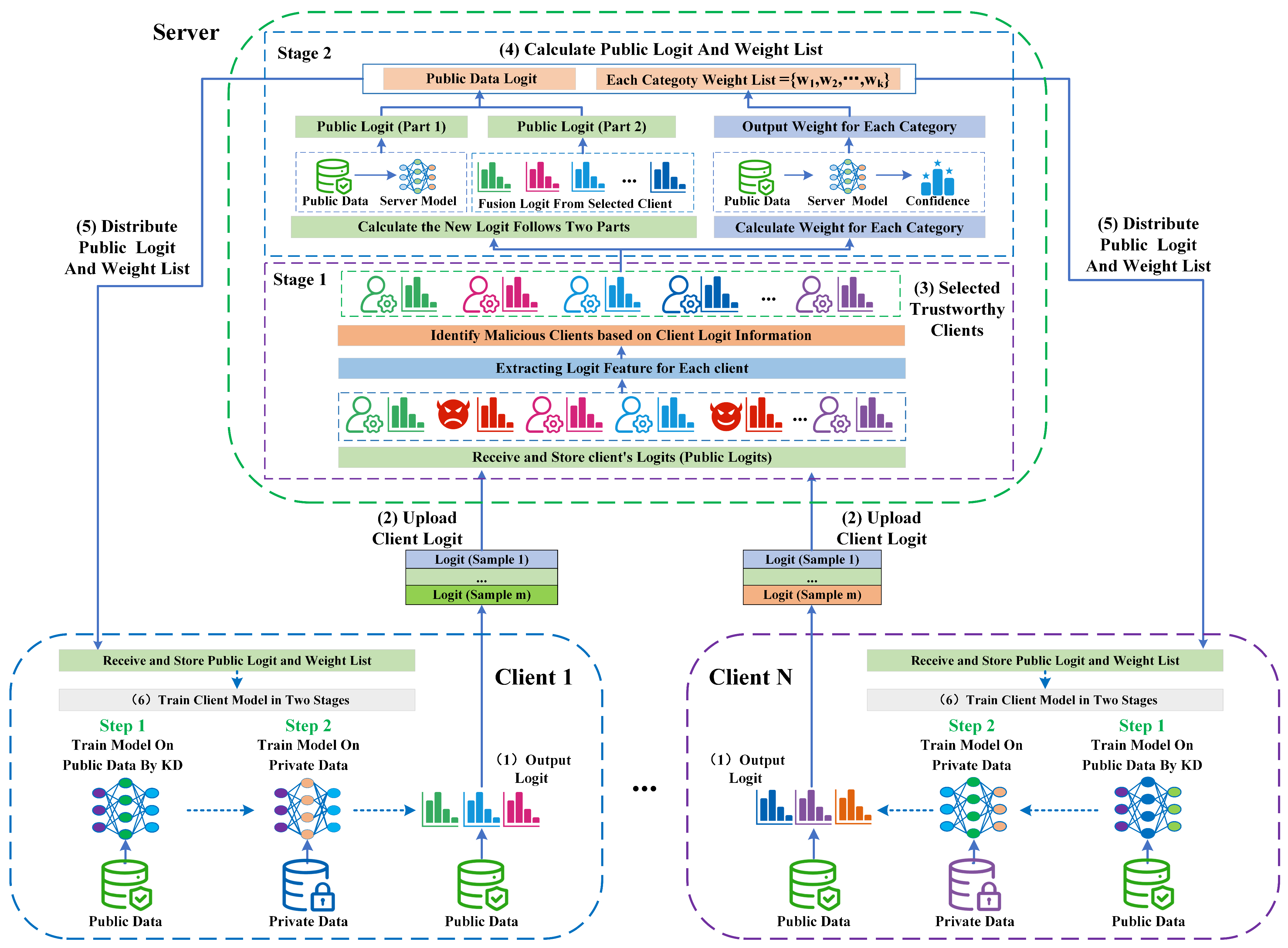
Our experiments are structured into four parts to validate the performance and reliability of our algorithm: malicious client identification, attack experiments, different data distribution experiments, and framework performance analysis. Notably, the malicious client attack experiments are crucial in evaluating our algorithm’s robustness. We also compare our algorithm against other baselines in both attack and normal scenarios.
5.2.1. Malicious Client Attack Experiment
To verify the performance of each algorithm under different attack scenarios, we designed three attack-type scenarios. The details of each attack scenario are as follows.
Label Flipping Attack (Type-1): In the classification task, each sample’s logit information is a vector of K values, and the maximum of these values is the classification result of the model. We select this maximum value and swap it to a random location. We follow this strategy to replace 50% of the number of samples’ logit to form a label-flipping attack.
Noisy Data Attack (Type-2): We add a certain percentage of noisy data (e.g., Gaussian noise) to the client’s private dataset to train the local model, reducing the client’s model’s accuracy. Then, we use the low-quality model to output the logit in the public dataset, which generates inaccurate logits of the public dataset.
SecondMax Attack (Type-3): We tamper with the logit information corresponding to the sample. We first find the position of the largest value in the logit, then randomly select of the remaining positions, and modify the value of these positions to (MaxValue − ). For example, in a ten-classification task, the element at position 9 is the maximum value (). We modify the values of the elements at positions 0, 1, 5, 6, and 8 to ().
Federated Task Setup: Our experiments involved scenarios with 10, 15, and 20 clients participating in a federated task with 100 communication rounds. At the same time, each client performs one epoch of local model training. We divide the clients into two groups: malicious clients and normal clients. Client IDs 1, 3, 5, 7, 9, 11, 13, 15, 17, and 19 are normal clients, and client IDs 2, 4, 6, 8, 10, 12, 14, 16, 18, and 20 are malicious clients, where the malicious client group performs the specified attack method.
Dataset Setup: In all three attack experiments, clients were set up with independently homogeneous data distributions (IID). For instance, in a 10-client experiment, each client has 6000 samples for MNIST and Fashion-MNIST. Each client has 5000 samples for CIFAR-10.
In particular, in the noise attack experiments, we set different ratios of noise data for the malicious client groups, in which for the MNIST dataset, the noise data ratios of clients 2, 4, 6, 8, 10, 12, 14, 16, 18, 20 are , respectively. For the Fasion-MNIST dataset, the noise data ratios of malicious clients are , respectively. For the CIFAR-10 dataset, they are , respectively.
To evaluate the performance of the client identification module, we process logit information in the following three steps:
(1) Vector Conversion: We gathered the logit information from the client and server. Then, we group the logit for each category and transform each subgroup into a one-dimensional vector.
(2) Cosine Similarity Calculation: For each category vector, we calculated the cosine similarity between the client’s category vectors and the server’s corresponding category vectors. This similarity measurement serves as a pivotal metric in our evaluation.
(3) Feature Value Calculation: We regard the cosine similarity values for the various categories as the feature values for each client.
We take the CIFAR-10 dataset as an example and apply this methodology to this dataset. We conduct the experiment on the three specified attack scenarios. The feature values for each client under these scenarios are illustrated in
Figure 9. This figure reveals notable disparities in feature values between normal and malicious clients, particularly in Type-1 and Type-3 attack scenarios. In contrast, the Type-2 (noisy data attack) scenario demonstrates a variation in feature values across certain categories, though not as pronounced as in the other types.
After computing the feature values for each category of each client, we proceed with the following steps:
(1) Client Clustering: We take the cosine similarity value of each category as the feature values of each client. Then, we employ the K-means method to cluster clients into two subgroups.
(2) Accuracy Verification on Public Data: For each resulting cluster, we assess the accuracy of the logit on the public dataset. The subgroup exhibiting the highest accuracy is deemed the ’trusted client list,’ while the one with lower accuracy is classified as comprising malicious clients.
We follow the steps above for clustering analysis, and the clustering outcomes are presented in
Figure 10. In Attack Types 1 and 3, our method successfully identifies malicious clients from the first communication round. In later rounds, the difference between the feature values of normal and malicious clients will become larger and larger, and our method can more easily separate the client types. However, in Attack Type 2, our method requires up to six communication rounds to categorize the clients accurately. The initial rounds are marked by relatively low logit accuracy, which obscures the differences between normal and malicious clients. As a result, some malicious clients may initially be misclassified as normal. To mitigate this issue, we need to verify client logit accuracy further, as detailed in the fourth stage of our method. This additional step is crucial for ensuring accurate client categorization in scenarios where initial data may not be distinct enough for immediate classification.
5.2.2. Experimental Analysis of Different Attack Scenarios
This experiment mainly evaluates our algorithm’s robustness across various attack scenarios. We benchmark our algorithm against five baseline methods, using two key performance metrics: the accuracy of the global logit on the public dataset and the average client model’s accuracy.
We tested the algorithms under predefined attack scenarios, adhering to our experimental configuration. As the FedDistill+ and FedHe methods do not necessitate a public dataset, our comparison of the accuracy of the global logitis is limited to the three algorithms (FedMD, FedDF, FedDistill). The experimental results are shown in
Table 2. The experiment shows that our algorithms consistently outperform others across three datasets.
Notably, in Attack Types 1 and 2, the global logit accuracy of FedMD, FedDF, and FedDistill exhibited a significant decline. This observation suggests that these algorithms may not be as effective in mitigating the impact of Attack Types 1 and 2.
To illustrate the influence of the malicious client’s logit accuracy on the overall global logit, we meticulously tracked the logit accuracy of each client across all communication rounds. The results are shown in
Figure 11. We analyze the impact of different attack scenarios on each algorithm as follows:
Attack Type 1: In this scenario, malicious clients significantly compromised the global logit accuracy of methods such as FedMD, FedDF, and FedDistill. The primary reason for this degradation is that these methods do not filter out malicious clients during the fusion process of the global logit.
Attack Type 2: In this scenario, FedMD, FedDF, and FedDistill methods use a simplistic weighted calculation for fusing global logit. Consequently, they fail to discern low-quality model outputs, leading to a reduction in logit accuracy.
Attack Type 3: The FedMD and FedDF methods are particularly vulnerable to tampered logit information, resulting in diminished global knowledge accuracy.
Contrastingly, our method consistently maintains high accuracy across all three attack scenarios. This resilience stems from our method’s capability to exclude malicious information from the fusion process and our server’s function to detect and ensure the fusion of high-quality logit information.
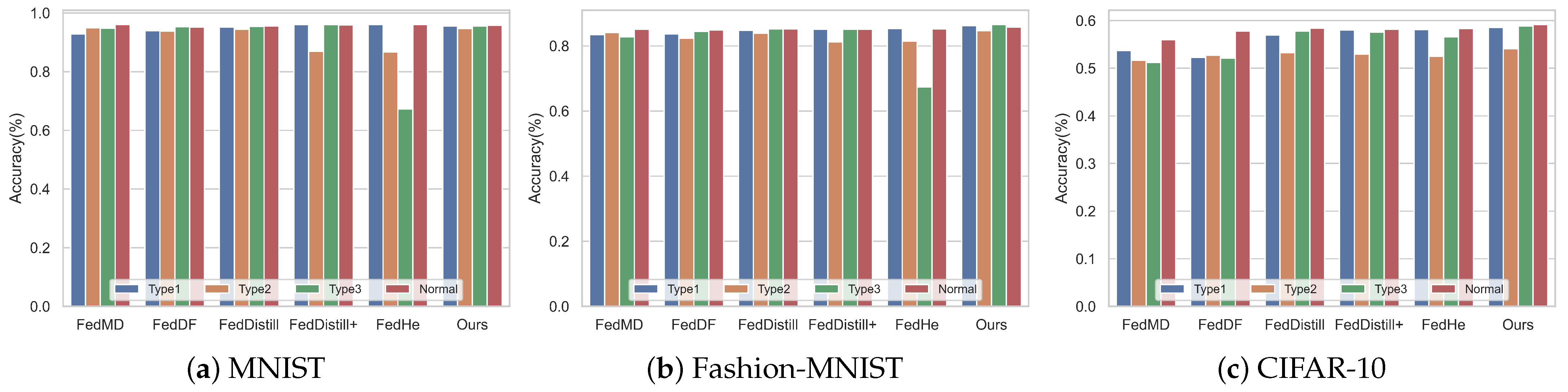
Furthermore, we evaluated the impact of different algorithms on average client accuracy. To assess how malicious clients affect federated tasks, we also introduce the scenarios without malicious clients (denoted as ’normal type’). These results are detailed in
Table 3. our algorithm demonstrates superior accuracy on both the Fashion-MNIST and CIFAR-10 datasets. On the MNIST dataset, our algorithm slightly trails behind the FedHe algorithm in Attack Type 1 and FedDistill in Attack Type 3. This outcome can be attributed to the relative simplicity of the MNIST dataset, where methods like FedDistill+ and FedHe, which regularize categories, tend to achieve higher accuracy.
We conducted a comparative analysis of different algorithms to evaluate their performance under various attack scenarios. we take the CIFAR-10 as an example, and the results are shown in
Figure 12. Notably, algorithm performance varies significantly depending on the type of attack:
Attack Type 1: Both FedDistill+ and FedHe methods experienced a notable decrease in accuracy. This suggests that these methods may be more vulnerable or less equipped to handle the specific challenges posed by this attack type.
Attack Type 2: The FedMD and FedDF methods showed a marked decline in performance. This indicates that these methods, while possibly effective in other scenarios, struggle to maintain accuracy under the conditions of Attack Type 2.
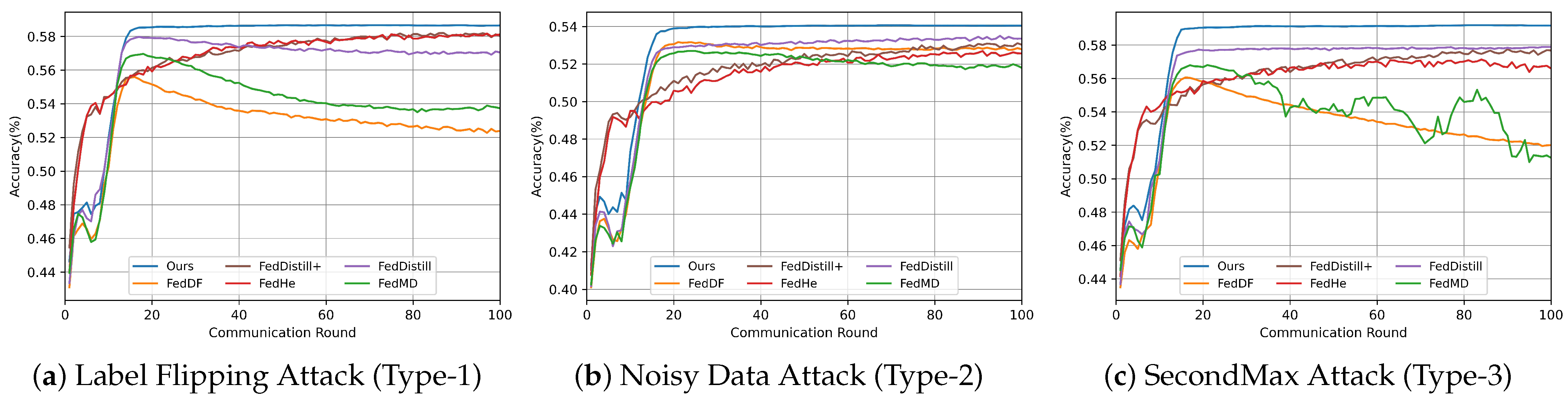
To illustrate how the accuracy of different algorithms fluctuates across communication rounds, we conducted an in-depth analysis using the CIFAR-10 dataset. We calculated the average client model accuracy at each communication round, as shown in
Figure 13.
In Attack Types 1 and 3, the accuracy of the FedMD and FedDF algorithms showed a significant decrease with increasing communication rounds. This decline is attributed to their reliance on a simple weighted average method for global logit fusion. Such a method proves ineffective in excluding the erroneous logit information from malicious clients, thereby diminishing the overall accuracy of the global logit. As a result, clients utilizing this compromised information for local model training experience a reduction in their model’s accuracy.
Our algorithm consistently achieves the highest accuracy rates across all three attack scenarios. The strength of our method lies in its ability to prevent malicious information from influencing the model fusion process. Additionally, it empowers the server to fuse high-quality knowledge from the client selectively. This capability ensures that our approach remains stable and effective under various attack scenarios.
5.2.3. Experimental Analysis of Different Data Distribution Scenarios
In this section, we focus on assessing each algorithm’s performance in different data distribution scenarios. The experimental setup is as follows:
Federated Task Configuration: We set different numbers of clients (10, 15, and 20) to participate in the federated task with 100 communication rounds. Each client completed one training epoch, while the server conducted two on the public dataset.
Network Model Configuration: We follow
Table 1 of the previous section to set up the client-side and server-side models in each scenario.
Dataset Division: We divided each dataset using the Dirichlet method of the previous subsection. This involved creating three Non-IID data scenarios () and one IID data distribution scenario.
Following these specified configurations, the experiments were conducted separately for each data distribution scenario. The accuracy results of each algorithm under these conditions are compiled and presented in
Table 4.
The experiment demonstrates that our algorithms consistently achieve the highest accuracy across all data distribution scenarios on the three datasets. Notably, the performance of the FedMD and FedDF algorithms exhibits a decline in Non-IID scenarios , a trend that is particularly pronounced in the CIFAR-10 dataset.
To further explore the relationship between client and global logit accuracy, we meticulously tracked and analyzed the accuracy of each client and the global logit for every communication round, as shown in
Figure 14. The accuracy of the FedMD and FedDF algorithms diminishes as the disparity in Non-IID data distribution increases. This trend underscores that the performance of algorithms relying on average weighting methods, such as FedMD and FedDF, is significantly hindered in Non-IID scenarios. In contrast, our algorithm and FedDistill demonstrate robustness against the variation in data distribution, maintaining consistent accuracy irrespective of the data scenario.
To verify the performance of each algorithm under different data distribution scenarios, we also calculated the average client model accuracy metrics, and the experimental results are shown in
Table 5. The experiment results show that our algorithms obtain the highest values on both Fashion-MNIST and CIFAR-10 datasets. The FedDistill+ and FedHe algorithms show a serious drop in accuracy in Non-IID (
) scenarios, which indicates that these two algorithms do not work stably in Non-IID scenarios.
To compare the accuracy of each algorithm on different rounds, we take the CIFAR-10 dataset as an example and compare the accuracy of five algorithms under different data distribution scenarios. The results are shown in
Figure 15. The experiments show that our algorithms obtain the highest accuracy under different data scenarios.
We utilized the CIFAR-10 dataset to assess the effectiveness of the adaptive knowledge distillation method. This involved monitoring the weight values assigned to each category over each communication round. We adjusted the hyperparameters for different data distribution scenarios for optimal performance. Specifically, in Non-IID scenarios (), we set the parameter to 0.8. For the Non-IID scenario () and the IID scenario, we set the parameter to 0.75.
The weight values of each category for different data scenarios are shown in
Figure 16. The results show that the weight values of each scenario no longer change after 15 communication rounds. This is because when our communication rounds reach a certain number of rounds, our algorithm has fully integrated the knowledge of each client. At the same time, the prediction of the samples of each category in the public dataset reaches the best accuracy, so after 15 rounds, the weight values of each category no longer change.
5.2.4. Performance Validation of the FedTKD Framework
We evaluated the computational efficiency of four main modules within our federated learning framework. These modules are Client-Side Identification, Server-Side Model Training, Global Logit Information Computation, and Category Weight Computation.
Experimental Setup: We set the number of communication rounds in the federated task to 50 for this evaluation. We meticulously recorded the computation time of each module across every communication round under each attack scenario. These results are presented in
Figure 17.
Experimental Analysis: The experimental result reveals that the computation times of each round for each module are generally consistent, with only occasional variations. These inconsistencies are attributed to the high-performance workstations used for the experiments, which ran other tasks concurrently. This multitasking environment led to fluctuating resource allocation, resulting in sporadic peaks in computation time.
To gain a more comprehensive understanding of computational efficiency, we also calculated the average computation time for each module throughout the entire federated task. The detailed results are tabulated in
Table 6. We differentiate between ‘total time 1’ and ‘total time 2’. The ‘total time 1’ is the aggregate time for all modules. The ‘total time 2’ is the cumulative time of all modules, excluding the server-side training model module.
The experiment shows that the number of clients does not influence the training model and logit calculation computation times. The training model times depend on network parameters, epochs, and the number of samples. The logit calculation time depends on the number of samples in the public dataset. The computation time of these two modules does not increase with the number of nodes because the factors affecting these modules are independent of the number of nodes. The time required for client identification and weight calculation increases with the number of clients. For server-side computational efficiency, the ‘total time 2’ is more relevant as server-side model training is independent of client-side tasks. We assume the server has sufficient computational resources to pre-train the model before receiving the client’s logit. Thus, the ‘total time 2’ can reflect the efficiency of our algorithm in processing client logit messages. Notably, in scenarios with 20 clients, our framework can complete essential steps in under 10 s, which is crucial for the real-time detection of client type.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}