
Control of the von Neumann Entropy for an Open Two-Qubit System Using Coherent and Incoherent Drives †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Control the behavior of thermodynamic quantities, such as Helmholtz free energy, not only at the final time instant but over some time range;
- Control of the degree of entanglement of a bipartite system over time;
- To not only maximize or minimize but rather control the rate of entropy production.
- For finite-dimensional optimization under various classes of parameterized controls, e.g., gradient ascent pulse engineering (GRAPE)-type methods (e.g., [25,26], [27] Section 3, [62]) (GRAPE-type methods operate with piecewise-constant controls, matrix exponentials, and gradients), CRAB ansatz [46,63] (coherent control is considered in terms of sine, cosine, etc.), genetic algorithm (GA) [21,64,65], dual annealing [24], etc.
2. Incoherent Control and Time-Dependent Decoherence Rates
3. Control Objective Functionals Involving Entropy
- Minimizing or maximizing the von Neumann entropy, or more general thermodynamic quantities (O is a Hermitian observable, for example, the Hamiltonian of the system, in this case, it is Helmholtz free energy) at a final time, as defined in [54]:Case corresponds to the minimization or maximization of the entropy itself. Based on this objective, one can define the problem of keeping the thermodynamic observable invariant at the whole time range, steering the entropy to a given target level, making it follow a predefined trajectory, etc.
- For the problem of keeping the required invariant at the whole time range , we considerwhere the penalty coefficient and the final time T are fixed. Although one can expect such a case that making the integral close to zero does not provide at the whole ; however, (4) is of interest, because, first, it can be useful and, second, it is appropriate for the described below gradient approach (GPMs). Moreover, as a variant, one can formulate the problemwhich is considered below together with piecewise linear controls and GA.
- For the problem of steering the von Neumann entropy to a given target value , we considerwhere T is fixed, as necessary for the considered GPMs. In extension, one can analyze a series of such steering problems for various values T and look for such an approximately minimal T for which the required value is reached.
- In addition to the steering problem with , we consider the pointwise state constraint for a given at the whole by adding to the integral term, taking into account the constraint:Here, the final time T and the penalty coefficient are fixed. Moreover, as a variant, one can consider non-fixed T and take into account the state constraint as follows:where T is considered free at a given range . As for , we consider for piecewise linear controls and perform finite-dimensional optimization using GA.
4. Markovian Two-Qubit System
- The system state as a density matrix (positive semi-definite, , with unit trace, ) and a given initial density matrix ;
- Scalar coherent control u, vector incoherent control , and the corresponding vector control considered in this work, in general, as piecewise continuous functions on ;
- being the free Hamiltonian defined below;
- The controlled Hamiltonian , consisting of the effective Hamiltonian , which represents the Lamb shift and depends on , and of the Hamiltonian , which describes interaction of the system with and contains a Hermitian matrix V specified below as in [24];
- being the controlled superoperator of dissipation, where we consider a special form of a Lindblad superoperator known in the weak coupling limit (see [21], etc.);
- The parameter describing the coupling strength between the system and the environment;
- The system of units with the Planck constant .
5. Numerical Optimization Tools: Markovian Two-Qubit Case
5.1. Gradient-Based Optimization Approach for the Problems with
5.1.1. Pontryagin Function and Krotov Lagrangian
5.1.2. Unified Adjoint System and Gradient
5.1.3. Projection Form of the PMP
5.1.4. One- and Two-Step Gradient Projection Methods
- GPM-1. The iteration process in the vector form is as follows and is reminiscent of (34):In detail, we have
- GPM-2. The iteration process in the vector form is as follows:where is obtained using GPM-1 for a given initial guess .
5.2. Zeroth-Order Stochastic Optimization for the Problems with
6. Analytical and Numerical Analysis: Markovian Two-Qubit Case
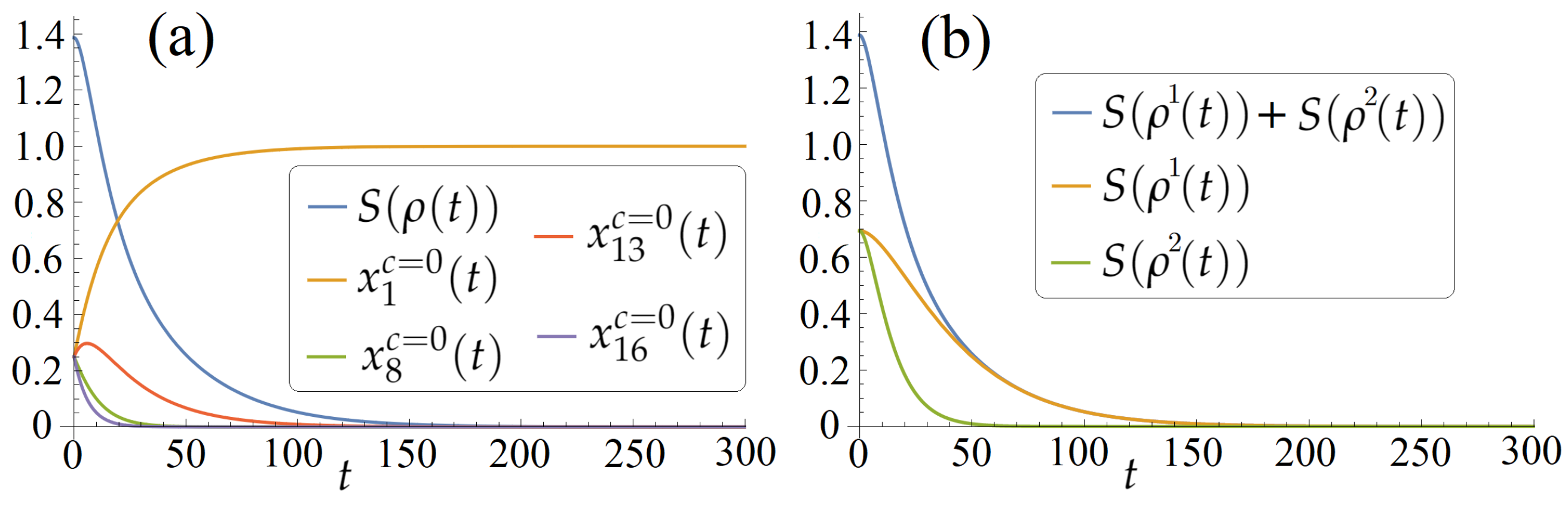
6.1. Results on the von Neumann Entropy under Zero Coherent and Incoherent Controls
6.2. The Problem of Keeping the Initial Entropy
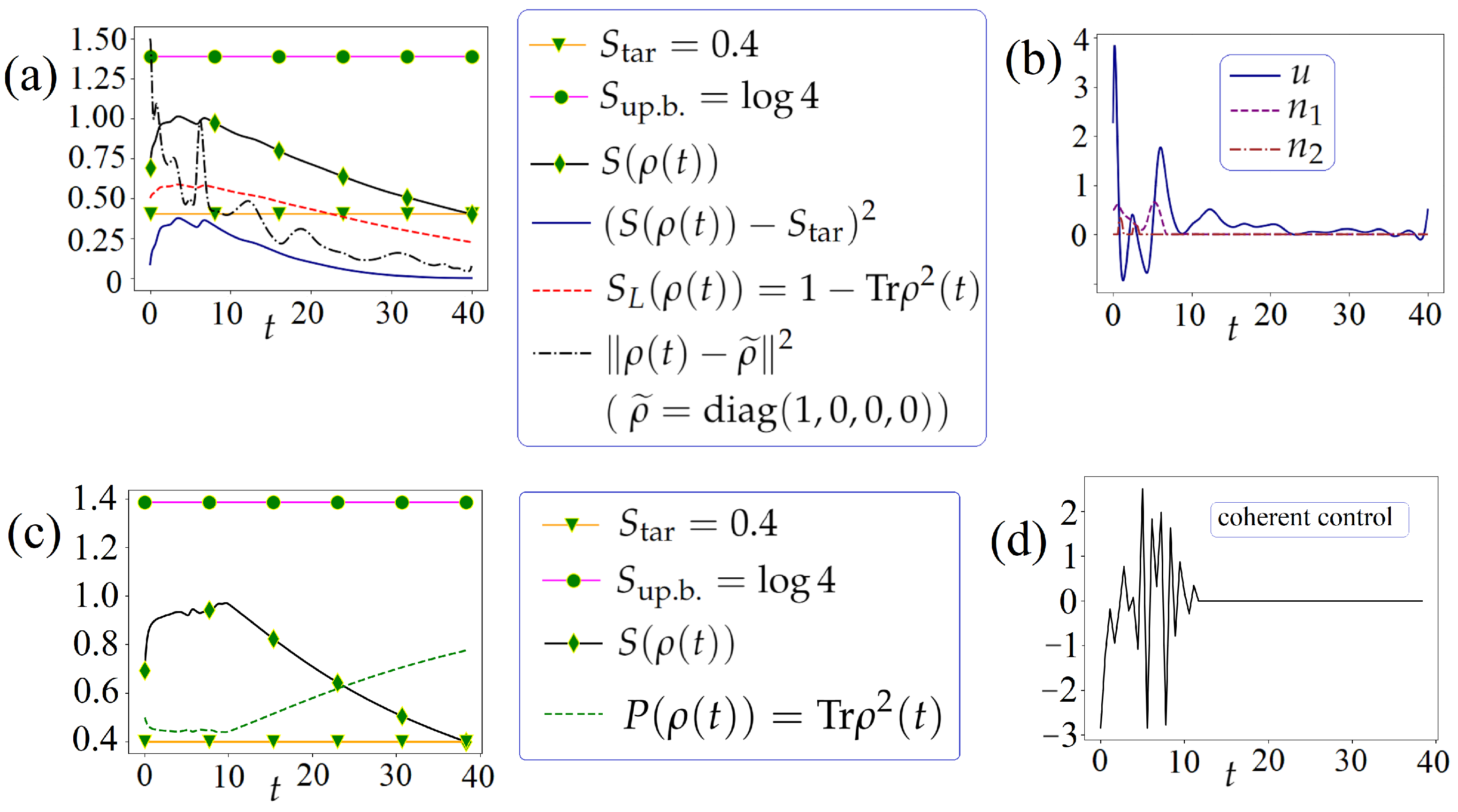
6.2.1. Using the Problem (4) and GPM
6.2.2. Using the Problem (5) and Genetic Algorithm
6.3. The Problem of Steering the von Neumann Entropy to a Predefined Value
6.4. The Steering Problem for the von Neumann Entropy under the Pointwise Constraint for This Entropy
6.4.1. Using the Problem (7) and GPM
6.4.2. Using the Problem (8) and Genetic Algorithm
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GKSL | Gorini–Kossakowski–Sudarshan–Lindblad |
| PMP | Pontryagin’s maximum principle |
| GPM-1, GPM-2 | one- and two-step gradient projection methods |
| GA | genetic algorithm |
References
- Dong, D.; Petersen, I.R. Learning and Robust Control in Quantum Technology; Springer: Cham, Switzerland, 2023. [Google Scholar] [CrossRef]
- Kuprov, I. Spin: From Basic Symmetries to Quantum Optimal Control; Springer: Cham, Switzerland, 2023. [Google Scholar] [CrossRef]
- Koch, C.P.; Boscain, U.; Calarco, T.; Dirr, G.; Filipp, S.; Glaser, S.J.; Kosloff, R.; Montangero, S.; Schulte-Herbrüggen, T.; Sugny, D.; et al. Quantum optimal control in quantum technologies. Strategic report on current status, visions and goals for research in Europe. EPJ Quantum Technol. 2022, 9, 19. [Google Scholar] [CrossRef]
- Kurizki, G.; Kofman, A.G. Thermodynamics and Control of Open Quantum Systems; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar] [CrossRef]
- D’Alessandro, D. Introduction to Quantum Control and Dynamics, 2nd ed.; Chapman & Hall: Boca Raton, Fl, USA, 2021. [Google Scholar] [CrossRef]
- Kwon, S.; Tomonaga, A.; Bhai, G.L.; Devitt, S.J.; Tsai, J.-S. Gate-based superconducting quantum computing. J. Appl. Phys. 2021, 129, 041102. [Google Scholar] [CrossRef]
- Bai, S.-Y.; Chen, C.; Wu, H.; An, J.-H. Quantum control in open and periodically driven systems. Adv. Phys. X 2021, 6, 1870559. [Google Scholar] [CrossRef]
- Acín, A.; Bloch, I.; Buhrman, H.; Calarco, T.; Eichler, C.; Eisert, J.; Esteve, D.; Gisin, N.; Glaser, S.J.; Jelezko, F.; et al. The quantum technologies roadmap: A European community view. New J. Phys. 2018, 20, 080201. [Google Scholar] [CrossRef]
- Koch, C.P. Controlling open quantum systems: Tools, achievements, and limitations. J. Phys. Condens. Matter 2016, 28, 213001. [Google Scholar] [CrossRef]
- Dong, W.; Wu, R.; Yuan, X.; Li, C.; Tarn, T.-J. The modelling of quantum control systems. Sci. Bull. 2015, 60, 1493–1508. [Google Scholar] [CrossRef]
- Cong, S. Control of Quantum Systems: Theory and Methods; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Altafini, C.; Ticozzi, F. Modeling and control of quantum systems: An introduction. IEEE Trans. Automat. Control 2012, 57, 1898–1917. [Google Scholar] [CrossRef]
- Bonnard, B.; Sugny, D. Optimal Control with Applications in Space and Quantum Dynamics; AIMS: Springfield, MA, USA, 2012. [Google Scholar]
- Gough, J.E. Principles and applications of quantum control engineering. Philos. Trans. R. Soc. A 2012, 370, 5241–5258. [Google Scholar] [CrossRef]
- Shapiro, M.; Brumer, P. Quantum Control of Molecular Processes, 2nd revised ed.; Enlarged Edition; Wiley–VCH Verlag: Weinheim, Germany, 2012. [Google Scholar] [CrossRef]
- Brif, C.; Chakrabarti, R.; Rabitz, H. Control of quantum phenomena: Past, present and future. New J. Phys. 2010, 12, 075008. [Google Scholar] [CrossRef]
- Fradkov, A.L. Cybernetical Physics: From Control of Chaos to Quantum Control; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar] [CrossRef]
- Letokhov, V. Laser Control of Atoms and Molecules; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Tannor, D.J. Introduction to Quantum Mechanics: A Time Dependent Perspective; University Science Books: Sausilito, CA, USA, 2007. [Google Scholar]
- Butkovskiy, A.G.; Samoilenko, Y.I. Control of Quantum–Mechanical Processes and Systems; Translated from the Edition Published in Russian in 1984; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1990. [Google Scholar]
- Pechen, A.; Rabitz, H. Teaching the environment to control quantum systems. Phys. Rev. A 2006, 73, 062102. [Google Scholar] [CrossRef]
- Pechen, A. Engineering arbitrary pure and mixed quantum states. Phys. Rev. A 2011, 84, 042106. [Google Scholar] [CrossRef]
- Morzhin, O.V.; Pechen, A.N. Optimal state manipulation for a two-qubit system driven by coherent and incoherent controls. Quantum Inf. Process. 2023, 22, 241. [Google Scholar] [CrossRef]
- Morzhin, O.V.; Pechen, A.N. Krotov type optimization of coherent and incoherent controls for open two-qubit systems. Bull. Irkutsk State Univ. Ser. Math. 2023, 45, 3–23. [Google Scholar] [CrossRef]
- Petruhanov, V.N.; Pechen, A.N. Optimal control for state preparation in two-qubit open quantum systems driven by coherent and incoherent controls via GRAPE approach. Int. J. Mod. Phys. B 2022, 37, 2243017. [Google Scholar] [CrossRef]
- Petruhanov, V.N.; Pechen, A.N. GRAPE optimization for open quantum systems with time-dependent decoherence rates driven by coherent and incoherent controls. J. Phys. A Math. Theor. 2023, 56, 305303. [Google Scholar] [CrossRef]
- Morzhin, O.V.; Pechen, A.N. On optimization of coherent and incoherent controls for two-level quantum systems. Izv. Math. 2023, 87, 1024–1050. [Google Scholar] [CrossRef]
- Morzhin, O.V.; Pechen, A.N. Minimal time generation of density matrices for a two-level quantum system driven by coherent and incoherent controls. Int. J. Theor. Phys. 2021, 60, 576–584. [Google Scholar] [CrossRef]
- Holevo, A.S. Quantum Systems, Channels, Information: A Mathematical Introduction, 2nd revised ed.; Expanded Edition; De Gruyter: Berlin, Germany; Boston, MA, USA, 2019. [Google Scholar] [CrossRef]
- Wilde, M.M. Quantum Information Theory, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Shirokov, M.E. Continuity of the von Neumann entropy. Commun. Math. Phys. 2010, 296, 625–654. [Google Scholar] [CrossRef]
- Nielsen, M.; Chuang, I. Quantum Computation and Quantum Information, 10th anniversary ed.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Petz, D. Entropy, von Neumann and the von Neumann entropy. In John von Neumann and the Foundations of Quantum Physics; Rédei, M., Stöltzner, M., Eds.; Springer: Dordrecht, The Netherlands, 2001; pp. 83–96. [Google Scholar] [CrossRef]
- Ohya, M.; Petz, D. Quantum Entropy and Its Use; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Ohya, M.; Volovich, I. Mathematical Foundations of Quantum Information and Computation and Its Applications to Nano- and Bio-Systems; Springer: Dordrecht, The Netherlands, 2011. [Google Scholar] [CrossRef]
- Ohya, M.; Watanabe, N. Quantum entropy and its applications to quantum communication and statistical physics. Entropy 2010, 12, 1194–1245. [Google Scholar] [CrossRef]
- Bracken, P. Classical and quantum integrability: A formulation that admits quantum chaos. In A Collection of Papers on Chaos Theory and Its Applications; Bracken, P., Uzunov, D.I., Eds.; IntechOpen: London, UK, 2020. [Google Scholar] [CrossRef]
- Vera, J.; Fuentealba, D.; Lopez, M.; Ponce, H.; Zariquiey, R. On the von Neumann entropy of language networks: Applications to cross-linguistic comparisons. EPL 2021, 136, 68003. [Google Scholar] [CrossRef]
- Kosloff, R. Quantum thermodynamics: A dynamical viewpoint. Entropy 2013, 15, 2100–2128. [Google Scholar] [CrossRef]
- Sklarz, S.E.; Tannor, D.J.; Khaneja, N. Optimal control of quantum dissipative dynamics: Analytic solution for cooling the three-level Λ system. Phys. Rev. A 2004, 69, 053408. [Google Scholar] [CrossRef]
- Pavon, M.; Ticozzi, F. On entropy production for controlled Markovian evolution. J. Math. Phys. 2006, 47, 063301. [Google Scholar] [CrossRef]
- Bartana, A.; Kosloff, R.; Tannor, D.J. Laser cooling of molecules by dynamically trapped states. Chem. Phys. 2001, 267, 195–207. [Google Scholar] [CrossRef]
- Kallush, S.; Dann, R.; Kosloff, R. Controlling the uncontrollable: Quantum control of open system dynamics. Sci. Adv. 2022, 8, eadd0828. [Google Scholar] [CrossRef] [PubMed]
- Dann, R.; Tobalina, A.; Kosloff, R. Fast route to equilibration. Phys. Rev. A 2020, 101, 052102. [Google Scholar] [CrossRef]
- Ohtsuki, Y.; Mikami, S.; Ajiki, T.; Tannor, D.J. Optimal control for maximally creating and maintaining a superposition state of a two-level system under the influence of Markovian decoherence. J. Chin. Chem. Soc. 2023, 70, 328–340. [Google Scholar] [CrossRef]
- Caneva, T.; Calarco, T.; Montangero, S. Chopped random-basis quantum optimization. Phys. Rev. A 2011, 84, 022326. [Google Scholar] [CrossRef]
- Uzdin, R.; Levy, A.; Kosloff, R. Quantum heat machines equivalence, work extraction beyond Markovianity, and strong coupling via heat exchangers. Entropy 2016, 18, 124. [Google Scholar] [CrossRef]
- Abe, T.; Sasaki, T.; Hara, S.; Tsumura, K. Analysis on behaviors of controlled quantum systems via quantum entropy. IFAC Proc. 2008, 41, 3695–3700. [Google Scholar] [CrossRef]
- Sahrai, M.; Arzhang, B.; Seifoory, H.; Navaeipour, P. Coherent control of quantum entropy via quantum interference in a four-level atomic system. J. Sci. Islam. Repub. Iran 2013, 24, 2. [Google Scholar]
- Xing, Y.; Wu, J. Controlling the Shannon entropy of quantum systems. Sci. World J. 2013, 2013, 381219. [Google Scholar] [CrossRef] [PubMed]
- Xing, Y.; Wu, J. Shannon-entropy control of quantum systems. In Proceedings of the World Congress on Engineering and Computer Science 2013, San Francisco, CA, USA, 23–25 October 2013; Available online: https://www.iaeng.org/publication/WCECS2013/WCECS2013_pp862-867.pdf (accessed on 20 December 2023).
- Xing, Y.; Huang, W.; Zhao, J. Continuous controller design for quantum Shannon entropy. Intell. Control Autom. 2016, 7, 63–72. [Google Scholar] [CrossRef]
- Abbas Khudhair, D.; Fathdal, F.; Raheem, A.-B.F.; Hussain, A.H.A.; Adnan, S.; Kadhim, A.A.; Adhab, A.H. Spatially control of quantum entropy in a three-level medium. Int. J. Theor. Phys. 2022, 61, 252. [Google Scholar] [CrossRef]
- Pechen, A.; Rabitz, H. Unified analysis of terminal-time control in classical and quantum systems. EPL 2010, 91, 60005. [Google Scholar] [CrossRef]
- Landau, L. Das Daempfungsproblem in der Wellenmechanik. Z. Phys. 1927, 45, 430–464. [Google Scholar] [CrossRef]
- Von Neumann, J. Mathematische Grundlagen der Quantenmechanik; Springer: Berlin, Germany, 1932. [Google Scholar]
- Boscain, U.; Sigalotti, M.; Sugny, D. Introduction to the Pontryagin maximum principle for quantum optimal control. PRX Quantum 2021, 2, 030203. [Google Scholar] [CrossRef]
- Buldaev, A.; Kazmin, I. Operator methods of the maximum principle in problems of optimization of quantum systems. Mathematics 2022, 10, 507. [Google Scholar] [CrossRef]
- Goerz, M.H.; Reich, D.M.; Koch, C.P. Optimal control theory for a unitary operation under dissipative evolution. New J. Phys. 2014, 16, 055012. [Google Scholar] [CrossRef]
- Krotov, V.F.; Morzhin, O.V.; Trushkova, E.A. Discontinuous solutions of the optimal control problems. Iterative optimization method. Autom. Remote Control 2013, 74, 1948–1968. [Google Scholar] [CrossRef]
- Krotov, V.F. Global Methods in Optimal Control Theory; Marcel Dekker: New York, NY, USA, 1996. [Google Scholar]
- Khaneja, N.; Reiss, T.; Kehlet, C.; Schulte-Herbrüggen, T.; Glaser, S.J. Optimal control of coupled spin dynamics: Design of NMR pulse sequences by gradient ascent algorithms. J. Magn. Reson. 2005, 172, 296–305. [Google Scholar] [CrossRef] [PubMed]
- Müller, M.M.; Said, R.S.; Jelezko, F.; Calarco, T.; Montangero, S. One decade of quantum optimal control in the chopped random basis. Rep. Prog. Phys. 2022, 85, 076001. [Google Scholar] [CrossRef] [PubMed]
- Judson, R.S.; Rabitz, H. Teaching lasers to control molecules. Phys. Rev. Lett. 1992, 68, 1500. [Google Scholar] [CrossRef] [PubMed]
- Brown, J.; Paternostro, M.; Ferraro, A. Optimal quantum control via genetic algorithms for quantum state engineering in driven-resonator mediated networks. Quantum Sci. Technol. 2023, 8, 025004. [Google Scholar] [CrossRef]
- Trushechkin, A. Unified Gorini-Kossakowski-Lindblad-Sudarshan quantum master equation beyond the secular approximation. Phys. Rev. A 2021, 103, 062226. [Google Scholar] [CrossRef]
- Trushechkin, A. Quantum master equations and steady states for the ultrastrong-coupling limit and the strong-decoherence limit. Phys. Rev. A 2022, 106, 042209. [Google Scholar] [CrossRef]
- McCauley, G.; Cruikshank, B.; Bondar, D.I.; Jacobs, K. Accurate Lindblad-form master equation for weakly damped quantum systems across all regimes. NPJ Quantum Inf. 2020, 6, 74. [Google Scholar] [CrossRef]
- Wu, R.; Pechen, A.; Brif, C.; Rabitz, H. Controllability of open quantum systems with Kraus-map dynamics. J. Phys. A 2007, 40, 5681–5693. [Google Scholar] [CrossRef]
- Zhang, W.; Saripalli, R.; Leamer, J.; Glasser, R.; Bondar, D. All-optical input-agnostic polarization transformer via experimental Kraus-map control. Eur. Phys. J. Plus 2022, 137, 930. [Google Scholar] [CrossRef]
- Laforge, F.O.; Kirschner, M.S.; Rabitz, H.A. Shaped incoherent light for control of kinetics: Optimization of up-conversion hues in phosphors. J. Chem. Phys. 2018, 149, 054201. [Google Scholar] [CrossRef]
- Pontryagin, L.S.; Boltyanskii, V.G.; Gamkrelidze, R.V.; Mishchenko, E.F. The Mathematical Theory of Optimal Processes; Translated from Russian; Interscience Publishers JohnWiley & Sons, Inc.: New York, NY, USA; London, UK, 1962. [Google Scholar]
- Petersen, K.B.; Pedersen, M.S. The Matrix Cookbook; Technical University of Denmark; 2012. Available online: https://www2.imm.dtu.dk/pubdb/pubs/3274-full.html (accessed on 20 December 2023).
- Polak, E. Computational Methods in Optimization: A Unified Approach; Academic Press: New York, NY, USA; London, UK, 1971. [Google Scholar]
- Srochko, V.A.; Mamonova, N.V. Iterative procedures for solving optimal control problems based on quasigradient approximations. Russ. Math. 2001, 45, 52–64. [Google Scholar]
- Levitin, E.S.; Polyak, B.T. Constrained minimization methods. USSR Comput. Math. Math. Phys. 1966, 6, 1–50. [Google Scholar] [CrossRef]
- Demyanov, V.F.; Rubinov, A.M. Approximate Methods in Optimization Problems; Translated from Russian; American Elsevier Pub. Co.: New York, NY, USA, 1970. [Google Scholar]
- Fedorenko, R.P. Approximate Solution of Optimal Control Problems; Nauka: Moscow, Russia, 1978. (In Russian) [Google Scholar]
- Polyak, B.T. Introduction to Optimization; Translated from Russian; Optimization Software Inc., Publ. Division: New York, NY, USA, 1987. [Google Scholar]
- Polyak, B.T. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 5, 1–17. [Google Scholar] [CrossRef]
- Antipin, A.S. Minimization of convex functions on convex sets by means of differential equations. Differ. Equat. 1994, 30, 1365–1375. [Google Scholar]
- Vasil’ev, F.P.; Amochkina, T.V.; Nedić, A. On a regularized version of the two-step gradient projection method. Moscow Univ. Comput. Math. Cybernet. 1996, 1, 31–37. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. PMLR 2013, 28, 1139–1147. Available online: https://proceedings.mlr.press/v28/sutskever13.html (accessed on 20 December 2023).
- TensorFlow, Machine Learning Platform: MomentumOptimizer. Available online: https://www.tensorflow.org/api_docs/python/tf/compat/v1/train/MomentumOptimizer (accessed on 20 December 2023).
- Solgi, R. Genetic Algorithm Package for Python. Available online: https://github.com/rmsolgi/geneticalgorithm, https://pypi.org/project/geneticalgorithm/ (accessed on 20 December 2023).





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morzhin, O.V.; Pechen, A.N. Control of the von Neumann Entropy for an Open Two-Qubit System Using Coherent and Incoherent Drives. Entropy 2024, 26, 36. https://doi.org/10.3390/e26010036
Morzhin OV, Pechen AN. Control of the von Neumann Entropy for an Open Two-Qubit System Using Coherent and Incoherent Drives. Entropy. 2024; 26(1):36. https://doi.org/10.3390/e26010036
Chicago/Turabian StyleMorzhin, Oleg V., and Alexander N. Pechen. 2024. "Control of the von Neumann Entropy for an Open Two-Qubit System Using Coherent and Incoherent Drives" Entropy 26, no. 1: 36. https://doi.org/10.3390/e26010036