2.1. Study Area and Data Sources
Situated on the southeastern coast of China, the Hong Kong Special Administrative Region lies on the eastern bank of the Pearl River Estuary, across the sea to the west from its counterpart, Macao. Encompassing an area of approximately 1114 square kilometers, Hong Kong comprises Hong Kong Island, the Kowloon Peninsula, the New Territories, and an additional 262 islands. Home to a population of about 7.33 million, it boasts a per capita GDP of USD49,800. Conversely, the Macao Special Administrative Region also resides on China’s southeastern coast, positioned on the western bank of the Pearl River Estuary, with the sea separating it from Hong Kong to the east. Macao, with an area of about 33 square kilometers, comprises the Macao Peninsula, Taipa Island, Coloane Island, and Cotai City. It sustains a population of approximately 670,000 and yields a per capita GDP of USD43,900. Both Hong Kong and Macao are nestled within the subtropical region and experience a marine monsoon climate characterized by high heat, ample water vapor, elevated temperatures, and frequent rain. The annual average temperature in Hong Kong is 23.9 °C, accompanied by an annual precipitation of 2205.4 mm. Macao, in contrast, maintains an average annual temperature of 22.7 °C and sees an annual precipitation of 2030.8 mm. The typhoon season in both Hong Kong and Macao typically extends from June to October.
Hong Kong’s air quality monitoring network, consisting of 18 stations—15 general and 3 roadside—tracks the concentrations of major air pollutants. The primary source of coarse particulate matter (PM10) and fine particulate matter (PM2.5) emissions in Hong Kong originates from combustion processes. They encompass a range of sources, namely traffic and marine emissions, industrial and power generation activities, culinary processes, as well as biomass and open burning. PM10, associated with chronic or acute effects on lung function, can instigate respiratory problems. However, due to its diminutive size, PM2.5, capable of penetrating deep into the lungs, poses a more severe impact on human health. The highest annual average concentration of PM10 was registered at the Causeway Bay Roadside Monitoring Station, whereas the highest 24 h average for PM2.5 was recorded at the Yuen Long General Monitoring Station, and its highest annual average was noted at the Causeway Bay roadside station. Additionally, vehicular exhaust constitutes the principal source of carbon monoxide (CO) emissions in Hong Kong. CO, upon entering human blood vessels, may lessen the oxygen supply to various organs and tissues, resulting in symptoms akin to poisoning such as dyspnea, chest pain, headaches, and coordination loss—posing a heightened risk to individuals with heart diseases. The highest 8 h average of CO was detected at the Central Roadside Monitoring Station. Similarly, combustion processes are the leading sources of NO2 emissions in the city. NO2 is known to diminish the human respiratory system’s resilience to diseases and exacerbate the condition of those with chronic respiratory illnesses. The Causeway Bay Roadside Monitoring Station reported the highest 1 h average (301 μg/m3) and annual average (71 μg/m3) for NO2. Notably, all three roadside monitoring stations failed to meet the 1 h and annual air quality targets for NO2.
Macao’s air quality monitoring network, encompassing 6 stations, assesses the concentrations of primary air pollutants. The construction industry and land transportation contribute significantly to the emission of PM10 and PM2.5 in Macao, accounting for approximately 40% and 25% of these particulates, respectively. The annual average concentration of PM10 at the Taipa High Density Residential Area Station is measured at 52.3 (μg/m3), surpassing the established standard of 50 (μg/m3). Meanwhile, the annual average concentration of PM2.5 at the Taipa General Station is measured at 14.9 (μg/m3), reflecting a year-on-year increase of 9.6%. Land transportation predominates as the principal source of CO emissions in Macao. Notably, O3 pollution remains significant in Macao, broadly impacting air quality within the Guangdong–Hong Kong–Macao Greater Bay Area. O3 is generated via a photochemical reaction involving oxygen (O2), nitrogen oxides (NOx), and volatile organic compounds (VOC) under sunlight. Controlling VOC emissions emerges as a critical approach to managing O3 and photochemical pollution. The primary emission sources of non-methane volatile organic compounds (NMVOC) in Macao include organic solvents, land transportation, fuel supply, marine transportation, and sewage treatment. O3 can exert chronic or acute effects on human lung function, leading to breathing problems, diminished lung functionality, reduced immune system function, and cardiovascular issues. The annual average concentration of O3 at the Taipa High Density Residential Area Station is measured at 42.7 (μg/m3), reflecting a year-on-year increase of 25.2%. Meanwhile, the annual average concentration at the Taipa General Station is measured at 63.9 (μg/m3), reflecting a year-on-year increase of 5.8%.
The air quality in Hong Kong and Macao is influenced by a multitude of complex factors. Firstly, their geographical positioning at the junction of the tropics and subtropics, bordering the Asian continent to the north and the tropical ocean to the south, exposes them to both mid- and high-latitude atmospheric circulation from the mainland as well as low-latitude circulation from the ocean. This distinct geographical location results in conspicuous winter–summer circulation transitions, characterizing these regions as typical monsoon climate zones. Secondly, topographical features such as hills, valleys, and coastlines in Hong Kong, and plains, hills, and the predominantly low and flat urban areas in Macao, affect wind flow patterns and the distribution of air pollutants. For instance, valleys can generate a “tailpipe” effect, concentrating vehicle emissions and amplifying air pollution in specific areas. Furthermore, fluctuations in air pressure, temperature, and humidity also significantly impact air quality. High air pressure stabilizes the air, allowing pollutants to linger, whereas low air pressure induces instability, enabling the dispersion of pollutants. Concurrently, high temperature and humidity can augment surface photochemical reactions, fostering the formation of O
3. Hong Kong and Macao, regions abundant in sunshine, experience intensified photochemical reactions due to strong sunlight, further affecting air quality. Wind patterns also affect air quality, with the winter monsoon importing transboundary air pollutants from the Pearl River Delta industrial zone, while the summer monsoon, bringing frequent rainfall, aids in enhancing air quality. Lastly, factors like urbanization, population density, industrial and energy consumption, traffic congestion, and extensive construction activities exert substantial pressure on the air quality of both Hong Kong and Macao. The Hong Kong air quality monitoring network is shown in
Figure 1. The Macao air quality monitoring network is shown in
Figure 2.
The present study utilized a composite dataset comprising meteorological parameters, air quality indices, and ancillary data, gathered from Hong Kong and Macao between 2016 and 2022. Meteorological measures from both regions encompass mean sea level pressure (MSLP)(hPa), highest, mean, and lowest temperatures (HT, MT, LT)(°C), dew point temperature (Td)(°C), relative humidity (RH)(%), average wind speed (AWS)(km/h), and precipitation (PR)(mm). In terms of air quality, Hong Kong’s dataset includes average concentrations of PM10, PM2.5, CO, and NO2 (μg/m3), whereas Macao’s dataset features average concentrations of PM10, PM2.5, CO, and O3 (μg/m3). Other data from both regions incorporate the sunshine duration (SSI)(h). In sum, this collective data pool provided a comprehensive resource for a granular understanding of the regional atmospheric conditions over the period of interest.
The data for Hong Kong were sourced from the Hong Kong Observatory and the Hong Kong Environmental Protection Department. The latter included readings from the Central Roadside Monitoring Station, the Yuen Long General Monitoring Station, and the Causeway Bay Roadside Monitoring Station. Correspondingly, the Macao dataset was obtained from the Macao Meteorological and Geophysical Bureau and the Macao Environmental Protection Bureau, which involved measurements from the Macao High Density Residential Area Station, the Taipa General Station, and the Coloane General Station. The data type and source and variable selection and description is shown in
Table 1.
2.2. Dynamic Bayesian Network
BN is formulated on the foundations of the Bayesian theorem, intricately integrating probability theory and the graphical model theory of probability [
17,
18]. DBN, a derivative of BN, is a probabilistic graphical model specifically tailored to process time series data [
19]. The term ‘dynamic’ in this context refers to a temporal sequence or process where interdependencies among variables may extend across varying time steps, providing a powerful tool to model and make sense of random processes that unfold over time. The fundamental architecture of DBN comprises two structures: the internal structure and the transfer structure [
20]. The internal structure presupposes the existence of a BN at every ‘time slice’, succinctly describing the probabilistic interrelationships among all the random variables present at that point in time. On the other hand, the transfer structure encapsulates the modelling of transitions from one time slice to the subsequent one, elucidating the temporal evolution of variables. DBN inherently possess a Markovian property, implying that the current state, given a preceding state, is effectively independent of all past states [
21]. The learning methodology within DBN is bifurcated into structure learning and parameter learning. While structural learning aims at establishing causal linkages among variables, parametric learning is responsible for discerning the probabilistic relationships among them. Given their capabilities, DBNs serve as vital theoretical apparatuses for the representation and reasoning of uncertain knowledge.
DBNs offer significant advantages in tackling the timing, multi-dimensionality, instability, and uncertainty associated with the atmospheric environment system, facilitating both systematic visualization and quantification [
22,
23]. Firstly, DBNs provide a comprehensive framework to comprehend and elucidate intricate atmospheric environmental systems in atmospheric modeling. These systems are composed of multiple, interrelated subsystems, each with its unique spatio-temporal dynamics. DBNs empower us to formulate and test hypotheses addressing these complex interactions, fostering a profound understanding of atmospheric environmental systems. Secondly, DBNs present an efficacious strategy to grapple with the uncertainties inherent in atmospheric environmental data [
24]. Such data are frequently influenced by a myriad of factors, including measurement errors, model inaccuracies, and natural variability. The robustness of the model is enhanced by DBNs through the incorporation of prior probabilities and the application of Bayesian inference to accommodate these uncertainties. Lastly, DBNs also underpin decision-making processes related to the atmospheric environment. They are capable of predicting and quantifying the potential ramifications of specific decisions. Consequently, DBNs emerge as indispensable tools for air-quality modeling and analysis. They not only aid in demystifying the complexity of atmospheric environmental systems but also support decision-making management in the atmospheric environment.
2.3. Dynamic Bayesian Network Modeling Process
During the development of DBN models, the role of data preprocessing is paramount. Regarded as the preliminary phase of data analysis, the purpose of data preprocessing is to convert raw data into a format apt for subsequent analysis. The primary responsibilities encompassed by data preprocessing consist of handling missing data and performing data discretization.
Handling missing data is an essential aspect of data preprocessing. Missing data is a prevalent issue in real-world data collection, with potential causes ranging from equipment failure and lack of information to incomplete data acquisition. If such missing data remains unaddressed, it may induce bias within the data distribution, adversely impacting the accuracy of model training and prediction. The objective of missing data processing is to maintain data integrity, thereby offering a more precise and comprehensive basis for ensuing data analysis and model training. In this study, the K-nearest neighbor (KNN) interpolation method was selected for processing missing data. KNN is an instance-based learning approach that leverages data similarities to predict missing values. KNN interpolation surpasses mean or median interpolation in efficiency as it captures the local structural information inherent in the data, yielding more accurate predictions.
Data discretization is another pivotal step in data preprocessing. It aims to convert continuous numerical data into discrete categorical data, thereby simplifying the computational process of the model and enhancing computational efficiency. DBNs are ideally suited to process discrete data, operating under the assumption that input data are discrete. Data discretization can diminish the influence of data noise to a certain degree and is more adept at capturing nonlinear relationships. For data discretization in this study, the K-means algorithm was employed, discretizing each variable into three status categories: low (L), medium (M), and high (H). The K-means algorithm, a commonly used clustering method, partitions the data into K clusters via an iterative process. This process minimizes the sum of the distances from each data point to the centroid of its respective cluster. During data discretization, each cluster is treated as a discrete category. The K-means based discretization method effectively accounts for the data distribution and can automatically define the range of each category. It is well-suited to handle complex, non-uniformly distributed data, thereby exhibiting excellent performance.
Structure learning in DBNs forms the nucleus of the DBN modeling process, dictating the basic architecture of the model. DBN structures are trained to infer causality from data, typically employing either score-based or constraint-based methodologies. In this study, we opted for the score-based approach, utilizing the Bayesian Information Criterion (BIC) scoring method in conjunction with the hill-climbing algorithm for learning the DBN structure. The fundamental principle of the BIC scoring method involves scoring potential network structures. This scoring system strikes a balance between the goodness of fit and the model dimension to avert overfitting, thereby facilitating a faster understanding of the real network. BIC is represented by
where
is the BIC score of the DBN structure
and data
,
is the log likelihood score,
is the sample size, and
is the complexity penalty item. However, pinpointing the highest scoring network structure is a computationally challenging task, as the number of possible network structures escalates exponentially with the count of variables. The hill-climbing algorithm, a local search algorithm, seeks a state with a superior score in the vicinity of the current state, subsequently relocating the current state to this newly found state. This process is repeated until a better state cannot be identified. Although the hill-climbing algorithm may encounter local optima, it generally delivers satisfactory results in practical applications.
Parameter learning in DBN represents a critical task within the DBN modeling process. This study opted for the Bayesian estimation method and the Bayesian Dirichlet Equivalent Uniform Prior (BDeu) as the prior distribution to learn the parameters of the DBN. The Bayesian estimation approach incorporates prior knowledge, and despite its higher computational complexity, it effectively circumvents the issue of overfitting, thereby bolstering the stability and robustness of the model. BDeu priors are particularly beneficial for discrete variables, operating under the assumption that all parameter values are equally probable. As this prior does not rely on specific data, it proves suitable for scenarios characterized by limited data or substantial data missingness. The basis of Bayesian estimation method is Bayesian theorem, and its calculation formula is:
2.4. Dynamic Bayesian Network Evaluation and Validation
While modeling the dynamic causality of air quality in Hong Kong and Macao, the complexity is underscored by the characteristics of time series, multi-dimensionality, instability, and uncertainty. Accordingly, this study employed specific evaluation and validation techniques for the DBN, including predictive performance and sensitivity analysis.
In evaluating predictive performance, this study employed a multi-faceted and multi-tiered evaluation strategy to thoroughly assess the model’s performance. Firstly, data from 2016 to 2021 served as the training dataset, while the 2022 data functioned as the testing dataset, thereby providing a reliable estimate of the model’s generalization capability. This approach not only allowed for full data utilization, but it also ensured the model’s predictive performance on unfamiliar data. Secondly, a confusion matrix was used to elucidate the model’s predictive performance across different classes. The confusion matrix mirrored the model’s performance concerning true positives, true negatives, false positives, and false negatives, and was instrumental in evaluating key performance indicators such as precision, recall, specificity, and F1 scores of the model.
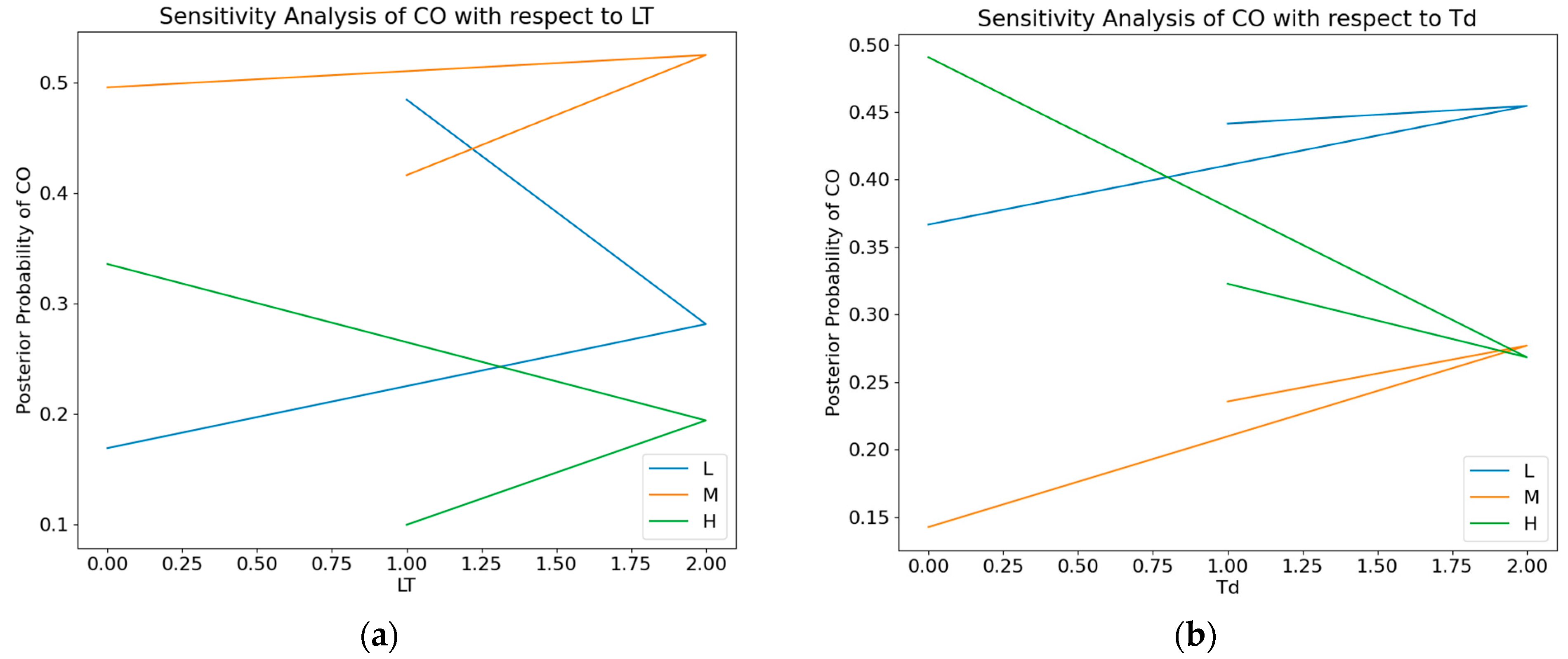
In conducting sensitivity analysis, this study adopted a comprehensive and systematic approach to quantify and comprehend the effect of changes in input parameters on the model’s output, and to identify the parameters that exert a decisive influence on model predictions. Initially, mutual information value analysis was employed to gauge the interdependence between two random variables, thereby quantifying the degree of correlation between the input and output of a DBN. Subsequently, the results from the mutual information value analysis were used to delve into the parameters exhibiting higher sensitivity, facilitating an understanding of these parameters’ influence mechanisms.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}