


Joint Detection and Communication over Type-Sensitive Networks
Department of Electrical and Computer Engineering, University of Southern California, Los Angeles, CA 90089, USA
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(9), 1313; https://doi.org/10.3390/e25091313
Submission received: 30 May 2023
/
Revised: 7 August 2023
/
Accepted: 24 August 2023
/
Published: 8 September 2023
(This article belongs to the Collection Feature Papers in Information Theory)
{kind=link}
{kind=link}
Abstract
:Due to the difficulty of decentralized inference with conditional dependent observations, and motivated by large-scale heterogeneous networks, we formulate a framework for decentralized detection with coupled observations. Each agent has a state, and the empirical distribution of all agents’ states or the type of network dictates the individual agents’ behavior. In particular, agents’ observations depend on both the underlying hypothesis as well as the empirical distribution of the agents’ states. Hence, our framework captures a high degree of coupling, in that an individual agent’s behavior depends on both the underlying hypothesis and the behavior of all other agents in the network. Considering this framework, the method of types, and a series of equicontinuity arguments, we derive the error exponent for the case in which all agents are identical and show that this error exponent depends on only a single empirical distribution. The analysis is extended to the multi-class case, and numerical results with state-dependent agent signaling and state-dependent channels highlight the utility of the proposed framework for analysis of highly coupled environments.
1. Introduction
Decentralized detection is an important element in a wide range of modern applications, such as the Internet of Things [1], smart grids [2], cognitive radio [3], and millimeter-wave communications [4]. However, many classical results in decentralized detection assume that agents’ observations are independent, conditioned on the underlying hypothesis. This assumption fails to hold in many of these recent applications, such as human decision-making [5], sensor networks with correlated observations [6], and quorum sensing in microbial communities [7]. Unfortunately, the problem of decentralized detection with correlated observations is NP-Hard [8], and many of the classical results are not applicable in this case (for examples, see [9,10,11]). Recent work in decentralized detection has placed greater attention on the case of correlated observations [12,13,14,15]. Although recent advancements have been promising, the inherent difficulty of the problem has resulted in approximations and relaxations [13,15]. In this work, we build upon the state-dependent formulation introduced in [16] by allowing agents’ observations to depend on both the underlying hypothesis as well as the empirical distribution, or type, of their states. The notion of type has a rich history in information theory and statistics, being first introduced by Csiszar [17]. Today, the method of types has been further developed [18] and is used in a variety of fields, such as control [19], machine learning [20], statistics [21], and even DNA storage channels [22].
Conditionally correlated observations can be handled under specific signal models [15] and assumptions [12,16,23,24,25]. In particular, ref. [15] studied bandwidth-constrained detection under the Neyman–Pearson criterion and solved a relaxation of the problem. Several works [23,24,25] have studied the problem under communication constraints, with [23] showing that the network learns the hypothesis exponentially quickly under constrained [23] and randomized [24] communication. Moreocer, [25] developed a deep learning algorithm for real-time industry constraints. Other works have attempted to decouple agents’ observations via algorithms [13] and specific models [12,16,26]. In [12], a hidden variable was introduced that allows the observations of the agents to be independent, conditioned on the hidden variable, and it was proved that threshold-based decisions are optimal under certain model assumptions. Unfortunately, even if a problem of interest falls under this framework, the assumptions are rather strong and fail in a number of applications. In our prior work [16,26], we introduced a state variable for each agent and allowed the agents’ observations to be independent conditioned on both the hypothesis and the agent’s state. We proved similar results to those of [12,27] under much weaker conditions. However, the model proposed in [16,26] grants each agent its own individual state, whereas in [12] agents may share a common hidden variable.
The framework was extended in [16,26]; herein agents’ observations, depend on a common variable, i.e., the type of the agents’ states. In [16], it was assumed that agents know their individual state and that the fusion center knows the states of all agents. We strongly relax this assumption; agents do not know their state, and the fusion center only knows the empirical distribution of the agents’ states. Another key difference is that in [16,26] the state variable is sufficient to decouple agents’ observations, whereas in this work all agent states are necessary to decouple observations, allowing this formulation to handle stronger forms of coupling. The need for the empirical distribution calls for different analysis techniques from those in [12,16,26] via the method of types. We further introduce a communication link between the agents and the centralized decision-maker (called the fusion center) which is not present in [12,16,26].
Many works in decentralized detection include a communication link between the agents and the fusion center; the idea itself is not new [28,29,30]. However, in prior works the statistical properties of the communication channel were assumed to be independent of the network’s behavior. A contribution of our current work is that we allow the quality of the communication channel to vary with the network’s behavior. This is again accomplished by allowing the channel to vary with the type of the agents’ states. The concept of a channel with state-dependent noise has been previously considered in information theory [31], and is in use today [32,33,34]. However, most of the aforementioned works involving the notion of state have focused primarily on communication over channels with state, and have not examined joint detection and communication. While recent works on estimation exist, they were the context of estimating the channel state to improve communication performance [34,35,36]. Notably, signal-dependent noise [37] can be accommodated in our proposed model. In particular, these models are relevant to visible light communication [38], magnetic recording [39,40], and imaging applications [41,42].
As an example, we may consider the occurrence of such forms of coupling in microbial systems. Microbial communities synthesize signaling molecules [7]; when sensed in the environment, these can result in individual gene expressions that lead to new collective behaviors through a process called quorum sensing. Specifically, cell i only engages in quorum sensing when the received number of autoinducer molecules from the environment exceeds a certain threshold . A common model involves assuming that follows a Poisson distribution conditioned on the total number of synthases (synthases are enzymes within a cell that are responsible for the production of autoinducer molecules) in the community and the number of receptors in a cell i, provided as [43]:
where is the number of synthases present in cell i and is a normalizing term. Hence, we can think of the number of synthases and receptors in cell i as being the state of cell i. Then, the observation of cell i depends on the states of all other cells through the summed total of synthases across the cells. This example illustrates the need for the current approach, as the models proposed in [12,16] cannot handle this form of coupling and do not lead to tractable asymptotic results.
In this work, we derive the error exponent as the network size grows. Assuming that all priors are known, the optimal asymptotic decay rate of the probability of error is provided by the Chernoff information [27,44,45], regardless of whether conditional independence holds. Using the Chernoff information, ref. [27] proved that identical rules are asymptotically optimal for identical agents, while [45] showed that identical binary quantizers are asymptotically optimal in power-constrained networks. The works in [27,45] both relied on conditional independence. A contribution of the present study is to remove the need for conditional independence through the development of a measure that is asymptotically equivalent to the Chernoff information and tractable in our scenario. The primary argument comes from the method of types, which, combined with a series of equicontinuity arguments, shows that asymptotic performance is dominated by a single distribution. Surprisingly, this dominating distribution is generally not the true distribution of the agents’ states.
Using the network type to decouple agents’ observations can be extended beyond pure decentralized detection. For instance, consensus algorithms used in blockchain applications often need to deal with faulty or nonconforming nodes [46]. Hence, it is possible to consider whether the node is conforming or not as the state and the total percentage of conforming nodes as the network type. Then, the problems of jointly estimating the network type (the consensus problem) and detecting the underlying hypothesis (the detection problem) can be considered. Much of the structure herein applies to such problems, as observations received by agents depend on the other agents’ states. Moreover, the hypothesis and network type are correlated; when more agents are faulty or nonconforming, an attack is more likely to be present.
Our contributions in this paper are as follows:
- We formulate a framework for distributed inference in which the agents’ observations are correlated through both the hypothesis and the empirical distribution (or type) of the network state. This formulation captures a high level of coupling between agents.
- We consider a distributed inference problem with a communication link between the agents and the fusion center, with the additional caveat that the noise over the link is dependent on the agents. Hence, our framework captures joint sensing with correlated observations as well as joint communications with correlated noise.
- We derive expressions for the error exponent for a single class of agents, then extend our results to the case of heterogeneous groups of identical agents. In particular, assuming that identical agents use a common rule, the optimal error exponent depends only on the ratios of the groups, not on the actual size of the groups themselves. This allows a wide range of problems to be studied in which there are multiple classes of agents that interfere with each other.
- We present a numerical example for a three-class case to highlight the utility of the proposed expression for the error exponent. In particular, we show how this expression can be used to optimize the ratios of heterogeneous groups in the presence of cross-class interference. This example further illustrates the fact that the true distribution may not dominate the asymptotics. The effect of the channel is observed as well.
Notation
Random variables are denoted by capital letters X and specific realizations are denoted as lowercase letters x. Random vectors are denoted as boldface capital letters and specific realizations are denoted with lowercase boldface letters . Given a random vector (realization) (), () denotes the vector () with the kth element removed. Calligraphic letters denote sets. The symbol denotes probabilities of events, and denotes expectations with respect to the random variable X.
2. Materials and Methods
The details concerning how plots are generated are provided in Section 5, along with a discussion of a specific example.
3. Problem Formulation, Definitions, and Assumptions
3.1. Problem Setup
Consider a set of n agents. The global environmental variable H is the binary . Agent k () receives a signal , with being the signal space. The probability density of conditioned on is denoted as . In addition, each agent takes a state , where m is a finite integer. The prior for the state of agent k is , and we define the vector . The collection of states is called the network state, with joint density . For a given network state, we denote the empirical distribution (or the type) of as , that is,
where is the indicator that agent k is in state i. Let denote the set of all empirical distributions corresponding to sequences of length n; then, for a given , is the type-class of , i.e.,
where is the Cartesian product of with itself n times. Note that is a random vector with realization , that is,
The joint probability distribution of and the network type under hypothesis is provided by . The associated conditional density is denoted as . Let denote the probability simplex in :
For , the conditional density is called the signal model for agent k. When we write densities conditioned on , we are assuming that these densities have a functional dependence on in order to avoid issues with measurability, as certain types may not be observable regardless of the size of the network. For a simple example, consider , which is never in for any n due to the fact that is irrational. We define , while the joint density of and and the density of conditioned on under are denoted as and , respectively. The joint density is called the joint signal model. For brevity, we call the conditional distribution the hypothesis model. It is important to note that we do not assume conditional independence of the agents’ observations, i.e., we can have for ; we do, however, assume that the structure described below holds.
Assumption 1.
The joint signal model obeys the following: , , ,
Assumption 2.
, , , ; the joint densities have the same support under both hypotheses.
Upon receiving observation , agent k makes a decision according to a rule, which is a (possibly randomized) function from to the decision space . We denote the possibly randomized rule used by agent k as ,
The collection of rules is called a strategy. After agent k has made its decision, it sends to the fusion center through a noisy communication link which is allowed to depend on the type . Upon sending , the fusion center receives the message with
Given , the conditional density is the channel model for agent k. We define , and the joint conditional density is called the joint channel model.
Assumption 3.
The joint channel model obeys the following: , , ,
Assumption 4.
, , , .
The fusion center does not know the network state , however, we assume that it knows . This assumption is not strong, as the empirical distribution can be estimated via consensus methods [47]. Upon receiving messages and , the fusion center makes an inference as to which hypothesis is true, denoted by . We seek to minimize the asymptotic decay rate of the probability of the error (as defined in Equation (10)). We assume that the fusion center is using the maximum a posterori (MAP) rule, i.e.,
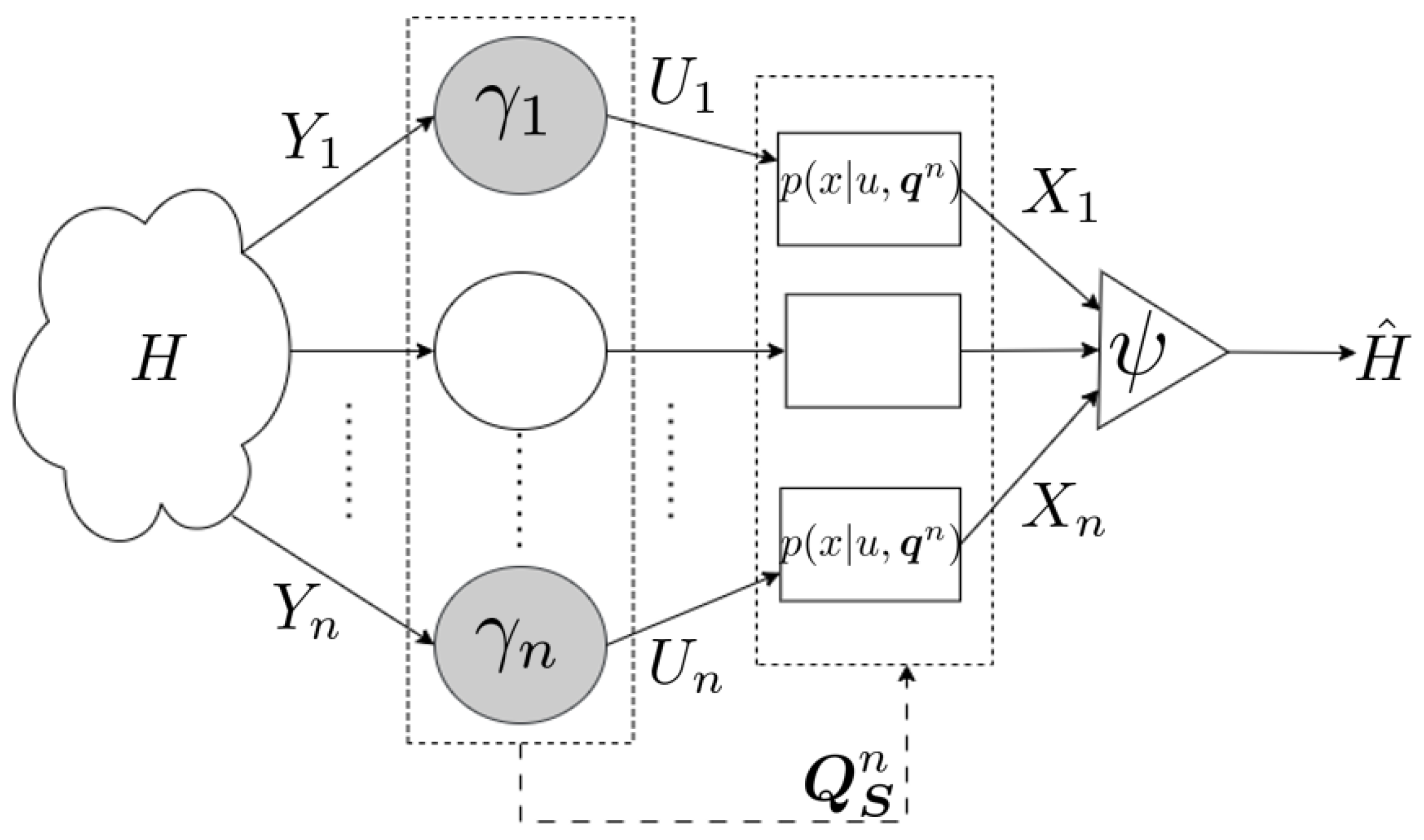
which minimizes the probability of error for a given strategy . The set depends on the specific strategy selected; given , it is possible to compute the optimal inference rule as a deterministic function of using Equation (9). The complete problem setup is summarized in Figure 1.
3.2. Definitions
We now introduce several definitions and concepts that are used throughout the paper.
Definition 1.
Let be the probability of error under strategy γ. We define the error exponent Λ (provided the limit exists) as:
The limit depends on the strategy . Thus, the strategy that achieves the infimum may be such that the limit does not exist. Moreover, (10) makes no assumption as to how the statistical properties of the agents vary with n; in general, it is not possible to say anything about the existence of . However, in many practical settings, such as homogeneous networks and power-constrained networks, exists and has a nice closed-form solution [16,27,45]. The main result of this work is an equivalent characterization of the error exponent defined above, showing that in our scenario the limit does exist. This equivalent expression has several desirable properties, and we can directly optimize the equivalent expression.
Definition 2.
The Kullback–Leibler Divergence between two distributions and is provided as follows:
Here, we are interested in understanding the interactions between different classes of agents, where members of a given class are identical, defined as follows.
Definition 3.
Given a collection of n agents, these agents are identical if the following conditions hold:
- 1.
- for all , , , .
- 2.
- for all , , , .
- 3.
- The agent states are i.i.d. a priori, i.e., .
Condition (1) states that, conditioned on the hypothesis H and the network type , the probability distributions on the received signals for all agents are the same. Similarly, Condition (2) states that, conditioned on the network type and for all , the probability distributions on the received messages are the same for all agents.
Definition 4.
A class is a collection of agents that are all identical.
3.3. Key Assumptions
We first derive the error exponent for the single-class case in Theorem 1, which is then generalized to the case of multiple classes.
Assumption 5.
Our key assumptions for Theorem 1 are as follows:
- (a)
- All agents are identical, as provided in Definition 3. Hence, we remove the notational dependence on k in the sequel.
- (b)
- The hypothesis model obeys the following:
- (c)
- The signal model is continuous in for all agents, that is, if is a sequence in such that , then ,
- (d)
- The channel model is continuous in for all agents. That is, if is a sequence in such that , then , ,
Remark 1.
Recall that the fusion center knows the empirical distribution and that the optimal rule is provided by (9). Hence, if (33) does not hold, then the threshold may either grow or decay exponentially quickly, biasing the fusion center to the point that the decisions become irrelevant. Hence, if the empirical distribution of the state carries too much information about the hypothesis, then the probability of error can be driven to zero exponentially quickly by simply looking at the network state, regardless of the rules used by the agents, leading to the need for Assumption 5.b. Assumptions 5.c and 5.d imply that if two distributions in are close with respect to the standard Euclidean metric, then the resulting signal and channel models should be close for all y and x, respectively.
4. Main Results and Important Corollaries
We first consider the single-class result (Theorem 1). We discuss its implications and outline the needed proof techniques, then turn our attention to the multi-class case, which begins by extending Theorem 1 to Lemma 1 and then stating Theorem 2 and its implications. For the main theorems, we provide proof outlines in this section and the complete proofs in Section 6. The extension of Theorem 1 to Lemma 1 is provided in Appendix A.2.
4.1. Single-Class Results
Theorem 1.
Subject to Assumptions 5.a–5.d,
where is the Kullback–Leibler (KL) divergence between the distribution and the true state distribution .
Theorem 1 provides an alternative asymptotically equivalent expression for the error exponent. In particular, Theorem 1 states that a single distribution dominates the asymptotic performance. Interestingly, the dominating distribution is in general not the true distribution of the agents’ states, despite the fact that the empirical distribution of the states converges towards the true distribution. We then extend Theorem 1 to multiple classes; if agents with a single class use a common rule, the error exponent for each class depends only on the ratios of numbers of agents between classes.
We underscore why the Chernoff information is challenging to compute for our problem framework:
As n grows, so does the space of potential strategies , possible messages , and possible types . Even if we have identical agents using the same rule, the complexity and coupling due to the summation over remains. If agents use the same rule
where is due to the fact that agents are identical and use the same rule, then all terms in the product are identical. Note that due to the summation over , as previously stated, the complexity of calculating the Chernoff information grows with n, leading to the need for Theorem 1.
There are a few key remarks that must be made here about Theorem 1:
- The maximization occurs over instead of ; hence, we have directly removed the dependence on . Because the expression in Theorem 1 is continuous over the compact set , it always achieves its maximum (versus supremum). This is due to Assumptions 5.c and 5.d.
- Note that the second term is the classical Chernoff information corresponding to the fixed distributions , and that the KL divergence term can be thought of as a bias. Hence, we only need to consider the m-dimensional probability vector that yields the worst Chernoff information biased by the KL divergence. In a certain sense, is sufficiently close to the true state distribution p, such that its poor performance (under strategy ) cannot be ignored even in asymptotically large networks. Only one distribution in dominates the asymptotic performance, as expected, although it may not be the true distribution p. An instantiation of this is provided in the numerical results.
- The maximization for takes place over all of ; however, it is only necessary to search a subset of to find the maximum, thereby reducing the computational cost. To determine the subset of interest, observe thatwhere both and are due to Hölder’s inequality. Using the fact that the Chernoff information is non-negative [44], it can be seen that the distribution that achieves the maximum over must satisfyThe right-hand side of (24) is the Chernoff information for the signal model under distribution p; hence, the maximizing must live in a ball defined by the Kullback–Leibler divergence centered at the distribution p with radius , thereby reducing the search space for the optimization. In fact, the Chernoff information admits a closed-form solution for a wide range of distributions, such as members of the exponential family [48]
We next sketch the proof of Theorem 1. We start from the classical Chernoff information and use it to show that
To prove the result, we wish to show that
uniformly in λ and γ, that is, we wish to show that for any there exists an integer that is independent of λ and γ such that (29) holds for all . Uniform convergence in and enables determination of the minimum and infimum, respectively, yielding
as , which is the desired assertion. Equivalently, it can be shown that
uniformly in and .
4.2. Multi-Class Results
We now discuss extending the results in the previous section to the case of multiple classes. Consider a set of classes. For a given class , let be the number of agents that belong to class c. Then, let and be the signal and state, respectively, of the kth agent in class c. Without loss of generality, assume that the signal space and state space are the same for all classes. Furthermore, for a given network state , let denote the type of the states of the agents belonging to class c, i.e.,
For given realizations of the class types , the signal model and state prior for class c are denoted as and , respectively, and with . Recall that per Definition 4, all agents in a given class are identical; thus, the signal models and state priors are the same within the class. Let be the decision made by the kth agent in class c distributed according to , with being the rule of the kth agent in class c (again assuming that, without loss of generality, the decision space is the same for all classes). The message of the kth agent in class c received by the fusion center is denoted as and distributed according to . Again, because agents in the same class are identical, the channel model is the same throughout the class. Moreover, let be the vector of received messages from all agents in class c. We can then extend Assumption 5 to the case of c classes.
Assumption 6.
The following assumptions hold for all classes. Hence, for notational simplicity, when referring to class c we remove the k superscript.
- (a)
- The hypothesis model obeys the following.
- (b)
- The signal model is continuous in for all classes, that is, if ; are sequences in such that , , then ,
- (c)
- The channel model is continuous in for all classes, that is, if ; are sequences in such that , , then , ,
The conditions of Assumption 6 closely resemble those of Assumption 5. Namely, Assumption 6.a retains the assumption that the network type for each class should not carry too much information about the hypothesis, while Assumptions 6.b and 6.c extend the assumption that the signal and channel models are continuous in the univariate case to the multi-dimensional case. Before, the models were continuous only in , whereas we now assume that are continuous in .
Lemma 1.
Assume that and ; then, under Assumptions 6.a–6.c,
Lemma 1 implies that all agents within a given class c use the same rule . When referring to the rule used by all agents in class c, we use superscripts to avoid confusion with previously defined notation, where a subscript indicates the rule used by a specific agent. Then, the error exponent takes on a form that allows heterogeneous networks with a high degree of interference to be examined. The details of the extensions of Theorem 1 are provided in Appendix A.2; Lemma 1 leads to the following theorem.
Theorem 2.
Let be the fraction of agents that belong to class , i.e., , with and where denotes the largest integer that is less than or equal to x. Moreover, suppose that all are held constant as and that agents in the same class use a common rule. Then, under Assumptions 6.a–6.c,
Because identical agents with a common rule may not be optimal, Theorem 2 provides a lower bound on the optimal error exponent. We highlight several important points of Theorem 2 below:
- Observe that all agents are coupled through the distributions , and recall that for a given class c, depends on all agents in class c through their states . Hence, the distributions collectively depend on all agents in the network, meaning that the received signal, decision, and message for a given agent are dependent on all agents in the network. As a result, Theorem 2 captures a very strong form of coupling.
- Note that the expression in Theorem 2 is not expressed as a limit, does not depend on n, and does not depend on the actual size of the classes. Hence, Theorem 2 provides an objective function that can be used to design rules that do not depend on the size of the network.
- Theorem 2 depends only on the ratios of the classes; that is, Theorem 2 provides an explicit objective function to find the optimal ratios for asymptotically large networks. Specifically, to find the optimal ratios we can solveIn the next section, we present a numerical example that highlights the utility of the proposed framework.
5. Numerical Example
We design an example that highlights the different forms of coupling captured by our framework. Note that the total number of agents is never specified, as it is only the fraction of agents in each class (ratio) that matters. However, considering our asymptotic analysis, the network size must be sufficiently large. Consider a three-class system where all agents take one of two states (1 or 2) with and , under each hypothesis all classes observe a Gaussian random variable with signal models
and
where is the mean of the signal model when , is the empirical distribution of Class 2, is a constant that determines the separation between the means of the two hypotheses, and is the ratio for Class i.
Important notes about the signal models are as follows:
- When , the signal model for Class 1 depends only on the number of agents in Class 2 that are in State 1.
- The signal models for Classes 2 and 3 are constant with respect to the underlying hypothesis as well as the distributions , , and ; hence, agents in Class 2 or 3 cannot distinguish between the two hypotheses.
Upon receiving the signal, each agent in class 1 makes a binary decision according to a threshold test, i.e., . Observe that because agents in the other two classes cannot distinguish between hypotheses, their decisions do not matter. Note that the agents belonging to class 1 use identical thresholds; while these may not be optimal, they simplify both design and analysis. Each agent then sends its decision over a binary symmetric channel with the following crossover probability:
The parameter governs the minimum achievable crossover probability of the channel. Note that because , the crossover probability can never be lower than ; thus, as increases the channel becomes worse. It can be seen that while Class 2 aids Class 1 in distinguishing between the two hypotheses, Class 3 controls the quality of the channel between the agents and the fusion center. Moreover, if then agents cannot distinguish the two hypotheses; thus, the error exponent is zero. Similarly, if , the crossover probability for all channels becomes ; thus, the channel output becomes random and the error exponent becomes zero. This example underscores the impact of cross-class interference on proper optimization of the system. To determine the optimal class ratios, we can solve
with . For computational simplicity, we set and These values can be further optimized.
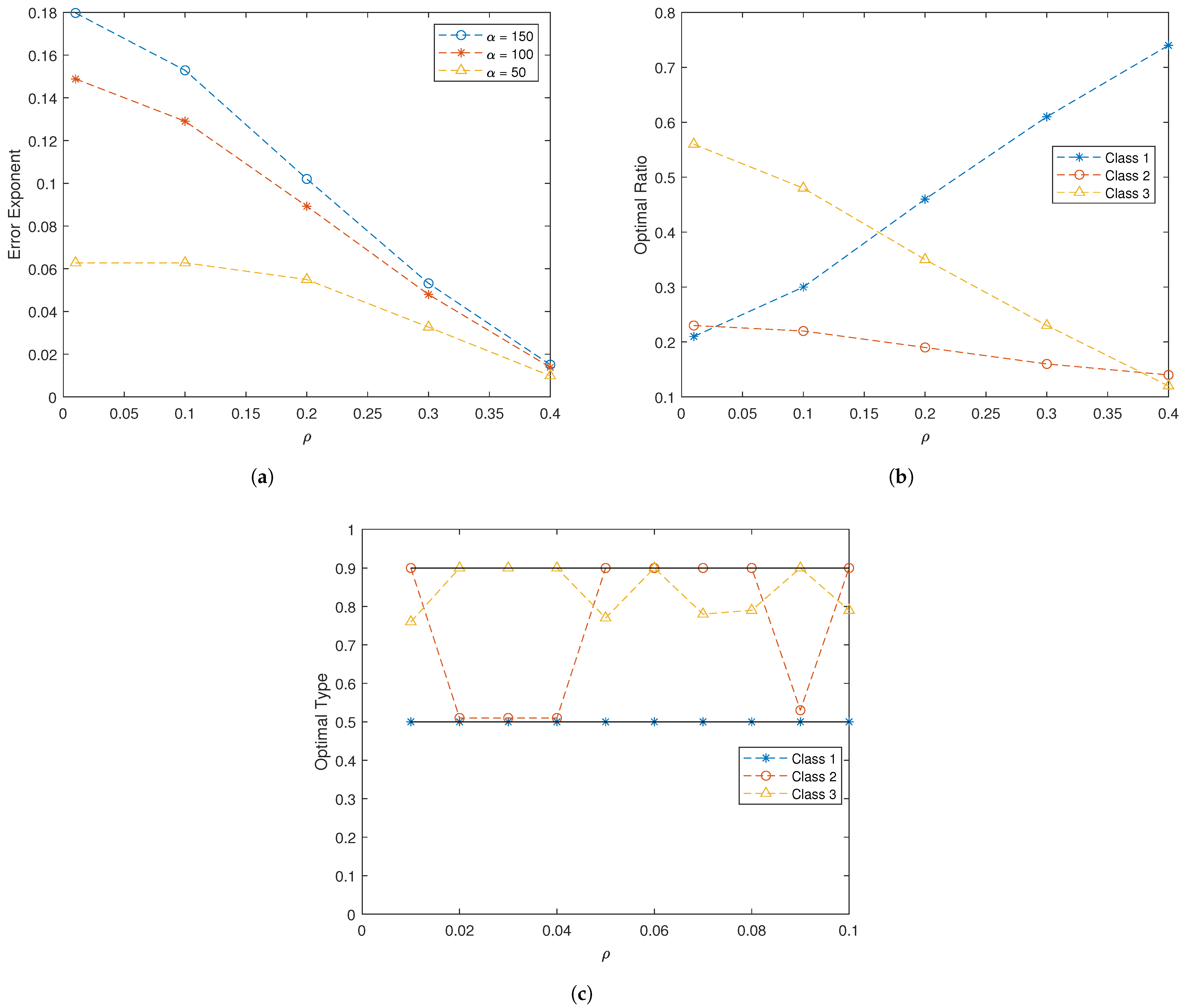
In Figure 2a, we compute the optimal error exponent as a function of the channel quality for various values of . Note that the class ratios are optimized for each data point. Recall that as increases, so does the interference, causing the channel to worsen. The importance of the channel on the overall system performance can be clearly seen. As increases, the minimum achievable crossover probability increases and the best-case quality of the channel decreases; hence, the optimal error exponent decreases along with the quality of the channel. In fact, when , the optimal error exponent is , an entire order of magnitude less than when . The impact of the signal mean for Class 1 is determined by Not surprisingly, as the mean increases, the error exponent increases as well; however, we begin to see diminishing returns as we move from to
In Figure 2b, the optimal ratio between the three classes is determined as a function of channel quality when . Figure 2b reveals the impact of cross-class interactions. Recall that each class serves a different purpose; Class 1 is the only class that can distinguish between hypotheses, Class 2 controls the sensing capabilities of Class 1, and Class 3 controls the channel quality for Class 1. Hence, the performance of the system relies on the interactions between the three classes. In particular, as increases Class 3 becomes less important to the overall system, as the quality of the channel degrades. This can be seen in Figure 2b by the decreasing and the fact that Class 1 becomes more important to the system, hence the increasing .
Finally, we examine the optimizing distribution for computing the error exponents when . As previously noted, the true class distributions of the states () do not necessarily dominate asymptotic performance. This can be seen in Figure 2c, which shows that the optimal types are sometimes different from the true distributions. Recall that under we have and ; thus, in this three-class example, it is only when that we see the optimizing distribution aligning with the true distribution. We underscore that the network type converges to the true state distribution. Recall that we assume the signal and channel models to be continuous; hence, as the network types converge to the true distributions, the performances of all other distributions in a neighborhood around the true distributions are relatively close. Then, it may be beneficial to design the rule to optimize detection for a distribution close to the true distributions, as the performance difference is small. This trade-off is captured by our result, where the closeness to is captured by the KL divergence and the asymptotic detection performance is captured by the Chernoff information term. Hence, the dominating distribution is the one that offers the best trade-off.
6. Proofs
6.1. Proof of Theorem 1
Before we begin the proof, we must introduce a number of important definitions and lemmas. There are two sets of lemmas. The first set of lemmas is a series of well-known mathematical facts. Because these are not our contributions but are necessary for the proof of Theorem 1, we omit the proofs, though we provide appropriate citations as necessary. The second set of lemmas is a series of results that, while necessary, are not major contributions of this work; these proofs are provided in Appendix A.1.
6.1.1. Definitions
Definition 5.
A family of functions defined on a common domain is equicontinuous at a point if for any there exists a (possibly a function of ϵ and ) such that whenever we have for all .
Observe that while the above may depend on and the specific point , it is not allowed to depend on the specific function f, i.e., the chosen must work for all functions in . The next definition removes the dependence on .
Definition 6.
A family of functions is uniformly equicontinuous if for any there exists a (possibly a function of ϵ) such that whenever we have for all .
The above definition states that the same must work for all functions at all points in the domain.
Definition 7.
Given a family of Lebesgue measurable functions with for all , the integrals are uniformly absolutely continuous if and such that for all Lebesgue measurable sets with
for all , where ν denotes the Lebesgue measure. Of course, these definitions can be extended to any general measure space; however, we focus on the Lebesque measure here for simplicity and to avoid endlessly defining notation. For a thorough discussion of abstract measure spaces, see [49].
Again, it is important to distinguish that the same must work for all functions for a given .
Definition 8.
Assume that we have a family of measurable functions with for all . Moreover, define . Then, the integrals are said to be uniformly absolutely convergent if
uniformly in .
This is a powerful property, stating that for a given there is a large enough a that all functions in satisfy
6.1.2. Key Lemmas
The following lemmas are needed to prove Theorem 1. However, because most are simply known mathematical facts (except Lemma 3, the proof of which is provided in Appendix A.1), we omit the proofs.
Lemma 2.
Let be an equicontinuous and pointwise-bounded family of functions defined on a common domain . If is compact, then is uniformly equicontinuous on .
Observe that is compact due to it being closed and bounded; because all of our functions (signal models, channel models, etc.) are defined on this space, Lemma 2 allows us to simplify the proof.
Lemma 3.
Let and be families of equicontinuous strictly positive functions defined on a common domain ; furthermore, assume that for each point we have , , , and . Then, the family for , , and is equicontinuous on .
The next lemma is taken from [49], Theorem 21.
Lemma 4.
Let be a sequence of real measurable functions with . Assume that the integrals are uniformly absolutely continuous and uniformly absolutely convergent. Moreover, assume that almost everywhere (a.e.); then, and
Lemma 4 provides a nice immediate result. In particular, suppose we have a function of two variables with for all y and with uniformly absolutely continuous and uniformly absolutely convergent with respect to y. In this case, Lemma 4 states that the integral is continuous in y. To see this, observe that if is a sequence with , then, per the triangle inequality,
6.2. Intermediate Lemmas
We next present several intermediate results. The proofs of all these results can be found in Appendix A.1. Moreover, recalling that we assume all agents to be identical, we consequently omit the k superscript in the following lemmas as well as in the proof.
Lemma 5.
Subject to Assumptions 5.a–5.d, the following two statements hold:
- (a)
- There exists a non-negative function such that and , , , , and
- (b)
- We have
Lemma 6.
For all , there exists a (which depends only on ϵ and h) such that whenever α and β are two distributions in with , then for all .
Lemma 7.
For a fixed and , the family which is indexed by γ is uniformly equicontinuous on .
Lemma 8.
For a fixed , the family which is indexed by γ and is uniformly equicontinuous on .
Lemma 9.
For any , there exists a (which depends only on ϵ) such that whenever α and β are two distributions in with , then
for all γ and .
An immediate consequence of Lemma 9 follows.
Lemma 10.
For any , there exists a (which depends only on ϵ) such that, whenever α and β are two distributions in with , we have
for all γ and .
The final lemma provides us with a starting point for the proof.
Lemma 11.
Hence, rather than starting directly with the Chernoff information, we start from the expression in Lemma 11. We are now ready to begin the proof.
Proof of Theorem 1.
Define
and note that depends on n, , and ; then, for any , per Lemma 10, , which depends only on , such that whenever ,
for all and . Because the agents are identical, they differ only by the rules they use; hence, the same works for all agents. For this , define
that is, is the set of all types that are less than away from based on the Euclidean distance. There are two important points to make here regarding :
- Because both and depend on n, does as well; however, because depends only on , any type in satisfies Equation (52) regardless of n or .
- Observe that for any there exists a type such that . Hence, such that for all and for any , such that . That is, is non-empty for all . Because depends only on and depends only on , depends only on , and the same works for all agents and all .
The following argument holds for any . We begin by observing that
Then, we have the following:
where holds, as [17,50], where is due to the definition of and holds because for any n the number of types is upper-bounded by ([50], Theorem 11.1.1). Then, taking the n-th root yields the upper bound
Observe that ; thus, such that , . Turning our attention to the lower bound,
where holds because [17,50], is due to the definition of , and holds because is non-empty for . Taking the n-th root provides
Observe that ; thus, such that , . Then, we can take , meaning that for all we have
Because none of , , or depend on , , or , it is the case that does not depend on , , or ; hence, we have uniform convergence, which completes the proof. □
6.3. Proof of Theorem 2
Because we assume that agents of the same class use the same rule, if we focus on class c we have
which is a consequence of Equations (5) and (8). Then, we have
with
If all agents in Class c use rule , then every term in the sum of Equation (70) is equal. Hence,
We now turn our attention to the difference
which is equivalent to
Observe that
for all classes, which is a consequence of the non-negativity of the KL divergence [50] and the non-positivity of the Chernoff information [44]. Combining this with the fact that , we see that (74) is upper-bounded by zero. For a lower bound, observe that , which yields the result that Equation (74) is lower-bounded by
The KL divergence (for finite alphabets) is bounded, and repeating the proof of Lemma 5 for the multi-class case using Assumptions 6.b and 6.c guarantees that the logarithm terms are finite. Hence, Equation (77) goes to zero as . Moreover, note that this lower bound is independent of the strategies and and the distributions . This means that Equation (74) converges uniformly in and and the distributions , which allows us to take the infimum, minimum, and maximum, respectively. To see this, observe that the upper bound provides
As this is true for all , we have
The same argument can be repeated to obtain
Hence, the difference
goes to zero as . Repeating the same argument with the minimum over followed by the infimum over completes the proof.
7. Conclusions
In this paper, we have introduced a new framework for decentralized inference that captures a high degree of coupling between the agents. Under our framework, the empirical distribution of the network state induces a global coupling across agents. We find an asymptotically equivalent expression to the Chernoff information and unveil a number of interesting properties, such as the fact that the true state distribution does not always dominate asymptotic performance. For the multi-class case, we characterize how ratios of classes of agents affect performance. We further allow for a lossy communication link between the agents and the fusion center and investigate the effects of the channel on overall performance. Our work extends prior work on distributed detection, and is able to break the requirement of conditionally independent observations when correlation is present. In future work, we will remove the fusion center from the system and require agents to directly communicate with each other, as in a purely decentralized ad hoc system. In addition, we will consider the introduction of actions by the agents which can affect observations by other agents to enable the consideration of active hypothesis testing in a distributed setting.
Author Contributions
J.S. and U.M. made serious contributions to the work and have had thorough discussions together on the problem formulation, proof techniques, and technical challenges. All authors have read and agreed to the published version of the manuscript.
Funding
This work has been funded in part by one or more of the following grants: NSF CCF-1817200, ARO W911NF1910269, DOE DE-SC0021417, Swedish Research Council 2018-04359, NSF CCF-2008927, NSF CCF-2200221, ONR 503400-78050, ONR N00014-15-1-2550, USC + Amazon Center on Secure and Trusted Machine Learning.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Appendix A.1. Proofs of Lemmas for Theorem 1
Proof of Lemma 3.
Fix a point . For , let (which can depend on and ) be such that for all whenever . Assume w.l.o.g. that ; then,
where follows from
and follows from if and if . Hence, we have just shown that for every , (independent of and f) such that and , we have whenever . A similar argument holds for .
Then, for any let and be such that and for all f and g whenever and , respectively. Take ; then, if for all we have
where is due to the triangle inequality, is due to , and is due to the fact that if and if . □
Proof of Lemma 5.
The function will always satisfy part (a). To see this, first observe that
for all h, , and . Moreover, for each x and u, per Assumption 5.d the channel model is continuous in , and because is compact, attains its maximum, meaning that is a valid density; thus, . For , repeated use of Hölder’s inequality provides
where holds, as for any two numbers a and b we have for any . Per Assumption 5.c, the signal model is continuous in for h as well as all y; thus, is continuous and attains its minimum. Moreover, we assume that is always strictly positive for any h, y, and , meaning that
Because this lower bound holds for all , , and , part holds. □
Proof of Lemma 6.
Fix and let be any sequence that converges to . Per Assumption 5.c, for each y. Moreover, for all i; thus, per Scheffé’s lemma [51],
The remainder of the proof proceeds via proof by contradiction. Suppose that and that there exist two sequences and such that and that for all i,
Because is bounded, per the Bolzano–Weierstrass theorem [52], and have convergent subsequences and that converge to some point . Because is closed, must be in . Then, Equation (A17) provides
which contradicts Equation (A18). □
Proof of Lemma 7.
Recall that Assumption 5.d states that is continuous in for any x and ; thus, is continuous in for a fixed x. Moreover, because is compact, achieves its maximum on ; thus, . Then, per Lemma 6, for any such that whenever we have . Then, for all u and we have
where holds due to the triangle inequality and holds because for all u and . Moreover, because is uniformly continuous in for each , (which depends only on , x, and u) such that whenever , . For a fixed x, take ; thus, depends only on , h, and x, and does not depend on or u. Then, whenever ,
where and are due to the triangle inequality and is due to . Now, because is continuous in (for finite alphabets) and is compact, is uniformly continuous. Clearly, does not depend on ; hence, we may repeat the exact same argument with , providing the desired result. □
Proof of Lemma 8.
In order to use Lemma 3, we need to show that for each and it is the case that and . Because (due to being bounded for finite alphabets), it suffices to show that and . For any , observe that
where is due to Assumption 4. Taking the infimum over provides us with . A similar argument shows that . Then, Lemma 3 yields the desired assertion. □
Proof of Lemma 9.
We proceed via proof by contradiction. Suppose that and that we have sequences , , and such that and
for all i. Then, let . Per Lemma 8, a.e.; then, in order to use Lemma 4 we must show the integrals are uniformly absolutely continuous, uniformly absolutely convergent, and for all i. Recall that per Lemma 5 there exists a function such that for all and h we have and . Then,
where is due to the triangle inequality, holds due to for any two real numbers , and . Furthermore, due to the absolute continuity of the Lebesgue integral, for any such that for any measurable set with Lebesgue measure we have . Then, we have
for all i, meaning that the integrals are uniformly absolutely continuous. Moreover, because , defining , we have from the Dominated Convergence theorem [52]. Let ; then, for all we have such that for all we have , which provides
for all i, making the integrals uniformly absolutely convergent. Then, per Lemma 4 we have , which contradicts Equation (A28). □
Proof of Lemma 10.
For any , per Lemma 9 we have , which does not depend on γ, λ, or , such that whenever we have
where the right side is strictly positive due to Lemma 5. This leads us to
□
Proof of Lemma 11.
As long as the fusion center implements the MAP rule, the error exponent is characterized by the Chernoff information [27,44]. Moreover, assuming that the fusion center knows the network type, the Chernoff information becomes
Then, for any strategy and ,
Now, we have
Because this argument holds for any and , we have
Turning our attention to the lower bound,
Because this argument holds for any and , we have
per Assumption 5.b. This completes the proof. □
Appendix A.2. Extension of Theorem 1
We begin by defining
Then, for any , in order for the argument in the proof of Theorem 1 to hold, there must exist an for each class such that the set
is non-empty for all . Recall that we assume for all classes, meaning that are guaranteed to exist. This means that is non-empty for all . Then, repeating the exact same argument as before for each class, we can show that there exists such that for all we have
References
- Shanthamallu, U.S.; Spanias, A.; Tepedelenlioglu, C.; Stanley, M. A brief survey of machine learning methods and their sensor and IoT applications. In Proceedings of the 2017 8th International Conference on Information, Intelligence, Systems & Applications (IISA), Larnaca, Cyprus, 27–30 August 2017; pp. 1–8. [Google Scholar]
- Tajer, A.; Kar, S.; Poor, H.V.; Cui, S. Distributed joint cyber attack detection and state recovery in smart grids. In Proceedings of the 2011 IEEE International Conference on Smart Grid Communications (SmartGridComm), Brussels, Belgium, 17–20 October 2011; pp. 202–207. [Google Scholar]
- Patel, A.; Ram, H.; Jagannatham, A.K.; Varshney, P.K. Robust cooperative spectrum sensing for MIMO cognitive radio networks under csi uncertainty. IEEE Trans. Signal Process. 2018, 66, 18–33. [Google Scholar] [CrossRef]
- Chawla, A.; Singh, R.K.; Patel, A.; Jagannatham, A.K.; Hanzo, L. Distributed detection for centralized and decentralized millimeter wave massive MIMO sensor networks. IEEE Trans. Veh. Technol. 2021, 70, 7665–7680. [Google Scholar] [CrossRef]
- Geng, B.; Cheng, X.; Brahma, S.; Kellen, D.; Varshney, P.K. Collaborative human decision making with heterogeneous agents. IEEE Trans. Comput. Soc. Syst. 2022, 9, 469–479. [Google Scholar] [CrossRef]
- Gupta, S.S.; Mehta, N.B. Ordered transmissions schemes for detection in spatially correlated wireless sensor networks. IEEE Trans. Commun. 2021, 69, 1565–1577. [Google Scholar] [CrossRef]
- Gangan, M.S.; Vasconcelos, M.M.; Mitra, U.; Câmara, O.; Boedicker, J.Q. Intertemporal trade-off between population growth rate and carrying capacity during public good production. iScience 2022, 25, 104117. [Google Scholar] [CrossRef]
- Tsitsiklis, J.; Athans, M. On the complexity of decentralized decision making and detection problems. IEEE Trans. Autom. Control 1985, 30, 440–446. [Google Scholar] [CrossRef]
- Aalo, V.; Viswanathou, R. On distributed detection with correlated sensors: Two examples. IEEE Trans. Aerosp. Electron. Syst. 1989, 25, 414–421. [Google Scholar] [CrossRef]
- Willett, P.; Swaszek, P.F.; Blum, R.S. The good, bad and ugly: Distributed detection of a known signal in dependent Gaussian noise. IEEE Trans. Signal Process. 2000, 48, 3266–3279. [Google Scholar]
- Gül, G. Minimax robust decentralized hypothesis testing for parallel sensor networks. IEEE Trans. Inf. Theory 2020, 67, 538–548. [Google Scholar] [CrossRef]
- Chen, H.; Chen, B.; Varshney, P.K. A new framework for distributed detection with conditionally dependent observations. IEEE Trans. Signal Process. 2012, 60, 1409–1419. [Google Scholar] [CrossRef]
- Hanna, O.A.; Li, X.; Fragouli, C.; Diggavi, S. Can we break the dependency in distributed detection? In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 2720–2725. [Google Scholar]
- Kasasbeh, H.; Cao, L.; Viswanathan, R. Soft-decision-based distributed detection with correlated sensing channels. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 1435–1449. [Google Scholar] [CrossRef]
- Maleki, N.; Vosoughi, A. On bandwidth constrained distributed detection of a known signal in correlated Gaussian noise. IEEE Trans. Veh. Technol. 2020, 69, 11428–114440. [Google Scholar] [CrossRef]
- Shaska, J.; Mitra, U. State-dependent decentralized detection. IEEE Trans. Inf. Theory 2023. submitted. [Google Scholar]
- Csiszar, I. The method of types [information theory]. IEEE Trans. Inf. Theory 1998, 44, 2505–2523. [Google Scholar] [CrossRef]
- Raginsky, M. Empirical processes, typical sequences, and coordinated actions in standard borel spaces. IEEE Trans. Inf. Theory 2013, 59, 1288–1301. [Google Scholar] [CrossRef]
- Schuurmans, M.; Patrinos, P. A general framework for learning-based distributionally robust mpc of markov jump systems. IEEE Trans. Autom. Control 2023, 68, 2950–2965. [Google Scholar] [CrossRef]
- Haghifam, M.; Tan, V.Y.; Khisti, A. Sequential classification with empirically observed statistics. IEEE Trans. Inf. Theory 2021, 67, 3095–3113. [Google Scholar] [CrossRef]
- Guo, F.R.; Richardson, T.S. Chernoff-type concentration of empirical probabilities in relative entropy. IEEE Trans. Inf. Theory 2021, 67, 549–558. [Google Scholar] [CrossRef]
- Weinberger, N.; Merhav, N. The dna storage channel: Capacity and error probability bounds. IEEE Trans. Inf. Theory 2022, 68, 5657–5700. [Google Scholar] [CrossRef]
- Lalitha, A.; Javidi, T.; Sarwate, A.D. Social learning and distributed hypothesis testing. IEEE Trans. Inf. Theory 2018, 64, 6161–6179. [Google Scholar] [CrossRef]
- Inan, Y.; Kayaalp, M.; Telatar, E.; Sayed, A.H. Social learning under randomized collaborations. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 115–120. [Google Scholar]
- Goetz, C.; Humm, B. Decentralized real-time anomaly detection in cyber-physical production systems under industry constraints. Sensors 2023, 23, 4207. [Google Scholar] [CrossRef]
- Shaska, J.; Mitra, U. Decentralized decision making in multi-agent networks: The state-dependent case. In Proceedings of the 2021 IEEE Global Communcations Conference, Madrid, Spain, 7–11 December 2021. [Google Scholar]
- Tsitsiklis, J.N. Decentralized detection by a large number of sensors. Math. Control Signals Syst. 1988, 1, 167–182. [Google Scholar] [CrossRef]
- Chen, B.; Tong, L.; Varshney, P.K. Channel-aware distributed detection in wireless sensor networks. IEEE Signal Process. Mag. 2006, 23, 16–26. [Google Scholar] [CrossRef]
- Duman, T.; Salehi, M. Decentralized detection over multiple-access channels. IEEE Trans. Aerosp. Electron. Syst. 1998, 34, 469–476. [Google Scholar] [CrossRef]
- Liu, B.; Chen, B. Channel-optimized quantizers for decentralized detection in sensor networks. IEEE Trans. Inf. Theory 2006, 52, 3349–3358. [Google Scholar]
- Gelfand, S.I.; Pinsker, M.S. Coding for channel with random parameters. Probl. Control Inf. Theory 1980, 9, 19–31. [Google Scholar]
- Choudhuri, C.; Kim, Y.H.; Mitra, U. Causal state communication. IEEE Trans. Inf. Theory 2013, 59, 3709–3719. [Google Scholar] [CrossRef]
- Miretti, L.; Kobayashi, M.; Gesbert, D.; De Kerret, P. Cooperative multiple-access channels with distributed state information. IEEE Trans. Inf. Theory 2021, 67, 5185–5199. [Google Scholar] [CrossRef]
- Zhang, W.; Vedantam, S.; Mitra, U. Joint transmission and state estimation: A constrained channel coding approach. IEEE Trans. Inf. Theory 2011, 57, 7084–7095. [Google Scholar] [CrossRef]
- Kobayashi, M.; Caire, G.; Kramer, G. Joint state sensing and communication: Optimal tradeoff for a memoryless case. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 111–115. [Google Scholar]
- Bross, S.I.; Lapidoth, A. The rate-and-state capacity with feedback. IEEE Trans. Inf. Theory 2018, 64, 1893–1918. [Google Scholar] [CrossRef]
- Moon, J.; Park, J. Pattern-dependent noise prediction in signal-dependent noise. IEEE J. Sel. Areas Commun. 2001, 19, 730–743. [Google Scholar] [CrossRef]
- Tsiatmas, A.; Baggen, C.P.; Willems, F.M.; Linnartz, J.P.M.; Bergmans, J.W. An illumination perspective on visible light communications. IEEE Commun. Mag. 2014, 52, 64–71. [Google Scholar] [CrossRef]
- Kavcic, A.; Moura, J.M. Correlation-sensitive adaptive sequence detection. IEEE Trans. Magn. 1998, 34, 763–771. [Google Scholar] [CrossRef]
- Hareedy, A.; Amiri, B.; Galbraith, R.; Dolecek, L. Non-binary ldpc codes for magnetic recording channels: Error floor analysis and optimized code design. IEEE Trans. Commun. 2016, 64, 3194–3207. [Google Scholar] [CrossRef]
- Kuan, D.T.; Sawchuk, A.A.; Strand, T.C.; Chavel, P. Adaptive noise smoothing filter for images with signal-dependent noise. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 2, 165–177. [Google Scholar] [CrossRef]
- JMeola, J.; Eismann, M.T.; Moses, R.L.; Ash, J.N. Modeling and estimation of signal-dependent noise in hyperspectral imagery. Appl. Opt. 2011, 50, 3829–3846. [Google Scholar]
- Michelusi, N.; Boedicker, J.; El-Naggar, M.Y.; Mitra, U. Queuing models for abstracting interactions in bacterial communities. IEEE J. Sel. Areas Commun. 2016, 34, 584–599. [Google Scholar] [CrossRef]
- Shannon, C.E.; Gallager, R.G.; Berlekamp, E.R. Lower bounds to error probability for coding on discrete memoryless channels. I. Inf. Control 1967, 10, 65–103. [Google Scholar] [CrossRef]
- Chamberland, J.-F.; Veeravalli, V. Asymptotic results for decentralized detection in power constrained wireless sensor networks. IEEE J. Sel. Areas Commun. 2004, 22, 1007–1015. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Li, S.; Zhao, S.; Yang, P.; Andriotis, P.; Xu, L.; Sun, Q. Distributed consensus algorithm for events detection in cyber-physical systems. IEEE Internet Things J. 2019, 6, 2299–2308. [Google Scholar] [CrossRef]
- Nielson, F. Revisiting Chernoff information with likelihood ratio exponential families. Entropy 2022, 24, 1400. [Google Scholar] [CrossRef] [PubMed]
- Graves, L.M. The Theory of Functions of Real Variables; Courier Corporation: North Chelmsford, MA, USA, 2012. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Williams, D. Probability with Martingales; Cambridge University Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Bartle, R.G.; Sherbert, D.R. Introduction to Real Analysis; Wiley: New York, NY, USA, 2000; Volume 2. [Google Scholar]
Figure 1.
A set of n agents receive signals and states . Each agent is characterized by a decision rule and sends a message to the fusion center, which outputs . The empirical distribution of the states governs the behavior of the signals as well as the communication channels.
Figure 1.
A set of n agents receive signals and states . Each agent is characterized by a decision rule and sends a message to the fusion center, which outputs . The empirical distribution of the states governs the behavior of the signals as well as the communication channels.

Figure 2.
Three-class example with coupled signaling and state-dependent channels: (a) the optimal error exponent as a function of , highlighting the importance of the channel on the overall system; (b) the optimal class ratios for (as increases, Class 3 becomes less important to the overall system); and (c) the dominating distributions , which may be different from the true distributions.
Figure 2.
Three-class example with coupled signaling and state-dependent channels: (a) the optimal error exponent as a function of , highlighting the importance of the channel on the overall system; (b) the optimal class ratios for (as increases, Class 3 becomes less important to the overall system); and (c) the dominating distributions , which may be different from the true distributions.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shaska, J.; Mitra, U. Joint Detection and Communication over Type-Sensitive Networks. Entropy 2023, 25, 1313. https://doi.org/10.3390/e25091313
AMA Style
Shaska J, Mitra U. Joint Detection and Communication over Type-Sensitive Networks. Entropy. 2023; 25(9):1313. https://doi.org/10.3390/e25091313
Chicago/Turabian StyleShaska, Joni, and Urbashi Mitra. 2023. "Joint Detection and Communication over Type-Sensitive Networks" Entropy 25, no. 9: 1313. https://doi.org/10.3390/e25091313
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.