1. Introduction
Variable selection is an automatic method for finding a small subset of covariates that explain most of the variation in the response of interest. In addition to identifying the most predictive covariates, there is a growing interest in exploring the low-rank structure between the covariates and the response, especially in genetic mapping problems where the objective is to find the expressed genes that are associated with a specific disease the most. In the frequentist framework, model selection is based on maximising the penalised log-likelihood [
1] or minimising information criteria such as AIC [
2] and BIC [
3]. Other approaches, such as the deviance information criterion (DIC) [
4] and widely applicable information criterion (WAIC) [
5], which are generalisations of the AIC, are also popular in model selection.
A natural alternative to these frequentist approaches is Bayesian variable selection (BVS). In the Bayesian approach, a prior is imposed on all candidate models, and the resulting posterior distribution naturally captures model uncertainty. In this work, we consider a spike-and-slab prior [
6,
7], which introduces indicator variables denoting the inclusion or exclusion of every covariate. Therefore, the spike-and-slab prior leads to a model posterior distribution that lies in a lattice with the same dimension as the number of covariates. We can understand the dependency between the importance of covariates and response using natural measures of the posterior distribution such as posterior model probability (PMP) and marginal posterior inclusion probability (PIP). The computation of the exact posterior distribution requires a full search over the whole model space, which is computationally infeasible when a high-dimensional data-set is analysed. In these settings, Markov Chain Monte Carlo (MCMC) algorithms are often used to explore the model space and estimate the posterior distribution. For “large
n, large
p” data-sets, which are now often encountered in some problems in genetics/genomics (such as genetic mapping studies), such algorithms must be carefully designed. In this work, we mainly consider Bayesian variable selection in generalised linear models and survival models and focus on three popular models: the logistic regression model [
8,
9], the Cox proportional hazards model with partial likelihood [
10,
11,
12,
13,
14] and the Weibull regression model [
15]. In each case, we illustrate how carefully designed algorithms can facilitate effective posterior computation.
A natural challenge of Bayesian variable selection methods in the above settings is that the marginal likelihood (or the integrated likelihood in [
16]) is not analytically available. One set of solutions are Reversible Jump MCMC schemes (RJMCMC) [
17], which sample from the joint space of models and regression coefficients by jointly proposing moves between models and regression coefficients. But it is often difficult to construct efficient proposals for these trans-dimensional jumps and design an MCMC scheme that mixes well [
18]. For some specific models, data-augmentation methods [
19] are available and result in closed-form marginal likelihood conditioned on latent variables, for instance, Pólya-gamma data augmentation [
20] for logistic regression. For other models where no suitable data-augmentation scheme exists, the most popular approaches are the Laplace approximation and the correlated pseudo-marginal method [
21], which rely on finding the maximum a posteriori (MAP) estimate of the regression coefficients. A novel scalable estimation method for marginal likelihood, approximate Laplace approximation (ALA), is introduced in [
16] and relies on defining an initial value for the coefficient parameters. ALA can save computational time during the optimisation process of finding the MAP estimate, but it does not yield an asymptotically consistent estimate. A detailed discussion of these approaches will be given in
Section 3.
Assuming that the marginal likelihood has been estimated, several MCMC algorithms can be used for simulation starting from the posterior distribution of BVS. The widely used add–delete–swap proposal [
22] can be employed here. The add–delete–swap proposal generates a new model by randomly selecting one of three possible moves: addition/deletion of a covariate into/from the model or swapping one covariate that is included with another that is not. Although it has been proved in [
23] that the add–delete–swap proposal can produce a rapidly mixing Markov Chain, the chains may still converge slowly, particularly when dealing with large-
p problems. Adaptive MCMC schemes [
24], which involve updating tuning parameters on the fly, are found to be valuable in addressing the issue of poor convergence. Lamnisos et al. [
25] describe an adaptive add–delete–swap proposal that allows for simultaneous changes to multiple variables at a time. Griffin et al. [
26] introduce the Adaptively Scaled Individual adaptation proposal (ASI), which simulates a new model with probability proportional to the product of PIPs. Wan and Griffin [
27] extend the ASI proposal to logistic regression and accelerated failure time models. Other popular MCMC approaches include the Hamming ball sampler (HBS) [
28], which proposes a new model within a Hamming neighbourhood using the PMPs as proposal weights, and the tempered Gibbs sampler [
29,
30], which uses tempering to efficiently sample from the multi-modal posteriors that commonly arise due to highly correlated covariates.
The recent work of [
31] provides useful insights into the design of efficient MCMC schemes in discrete spaces. The work introduces the locally informed proposal, which re-weights a given non-informed base kernel with a function of the PMPs. It is shown in [
31] that the locally informed proposal constructed with a balancing function that satisfies certain functional properties is asymptotically optimal compared with other choices of function in terms of Peskun ordering. Building upon the idea of locally informed proposal, Zhou et al. [
32] show that the locally informed and thresholded (LIT) proposal can achieve dimension-free mixing times under conditions similar to those mentioned in [
23] for BVS in linear regression models. Recent work in [
33] introduces a Point-wise implementation of the Adaptive Random Neighbourhood Informed proposal (PARNI), which combines the advantages of both adaptive schemes and locally informed proposals. The PARNI proposal outperforms other state-of-the-art algorithms in a wide range of high-dimensional data-sets for BVS in linear regression models.
Other computational approaches are also available for estimating the BVS posterior distribution. Hans et al. [
34] introduce a novel Shotgun Stochastic Search (SSS) approach that also explores the “local neighbourhood” idea and targets very high-dimensional model spaces to find high-probability regions. The integrated nested Laplace approximations (INLAs) [
35] can solve latent Gaussian models including generalised linear models and approximate the posterior marginals obtained from the continuous priors [
36]. Sara et al. [
37] view survival models as latent Gaussian models and also approximate the posterior marginals using INLAs. The posterior distribution can also be approximated using Variational Bayes (VB) [
38]. Ray et al. [
39] describe a scalable mean-field variational family to approximate the posterior distribution of BVS in linear regression and extended this VB approximation to the logistic regression model in [
40]. Komodromos et al. [
41] apply the Sparse Variational Bayes (SVB) method to approximate the posterior of proportional hazards models with partial likelihood. Other works develop a sampling strategy based on simulating piece-wise deterministic Markov processes (PDMPs) [
42,
43], which directly target the posterior distribution obtained from a spike-and-slab prior.
In this paper, we extend the PARNI proposal to sampling from the BVS posterior distribution in generalised linear models and survival models. To avoid the overwhelming computational costs of approximating the marginal likelihood in the locally informed proposals and motivated by ALA [
16], we introduce an ALA estimate of the marginal likelihood with a novel initial value. In contrast to the suggestion in [
16], which initialises ALA at origin, the novel initial value is adaptively updated on the fly using previously sampled models. The new method is computationally less complex than the Laplace approximation or correlated pseudo-marginal scheme as a result of avoiding iterative optimisation and provides a more accurate estimate than the original ALA approach initialised at the origin. We also consider new approaches to adapt the tuning parameters in the PARNI proposal. The new adaptation scheme replaces the Rao-Blackwellised estimates of PIPs using the combination of a warm-start estimate and the ergodic average calculated using previously sampled models.
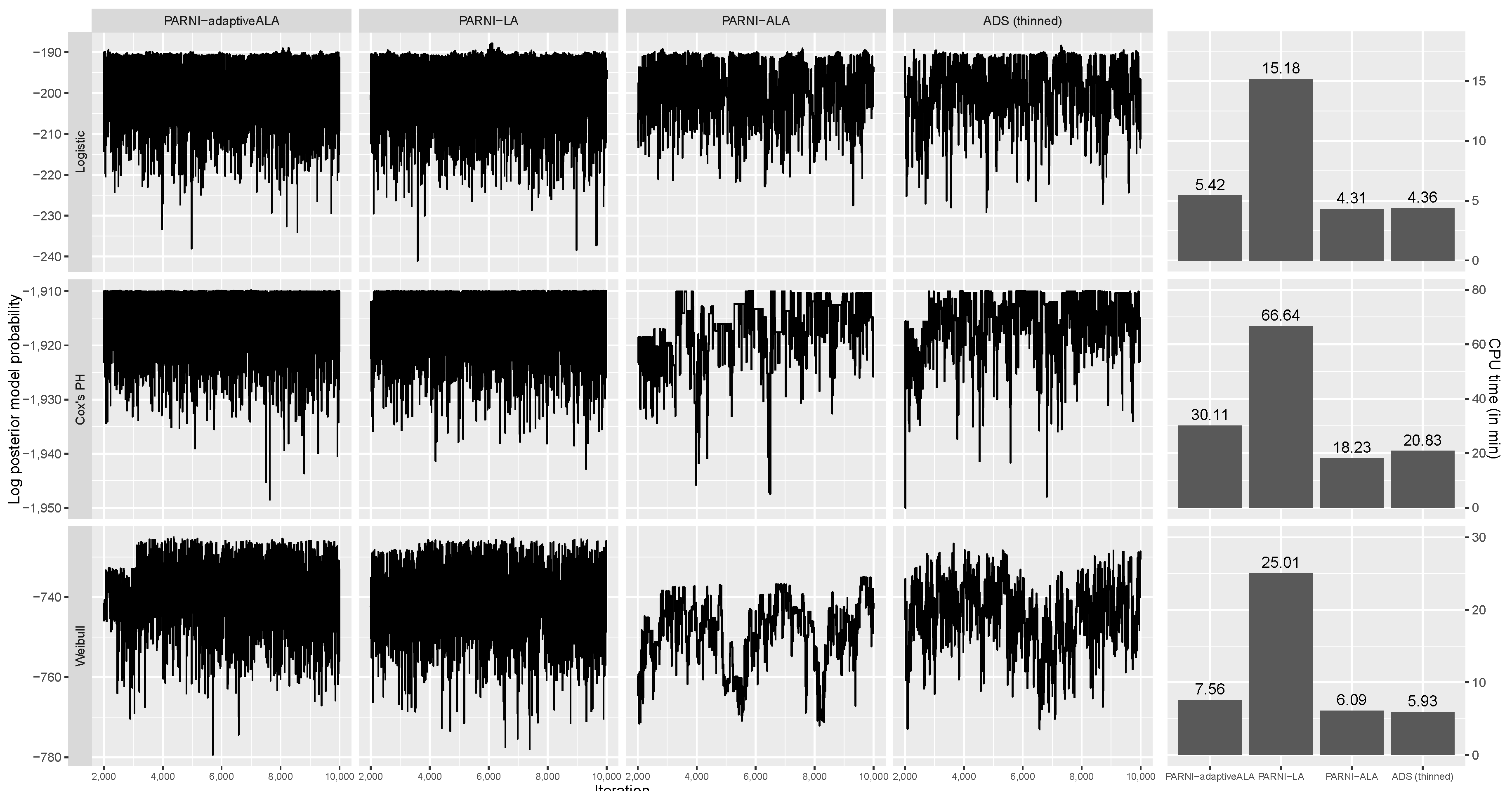
To illustrate the performance of the new PARNI scheme in real-life high-dimensional problems, we perform BVS on eight genetic mapping data-sets (four for the logistic regression model and four for survival analysis) and compare the output of the PARNI proposal with the add–delete–swap proposal as a baseline. For the logistic model with binary outcome, we consider the problem of finding expressed genes that are related the most to the presence of Systemic Lupus Erythematosus in a case-control study with 10,995 observations and various numbers of SNPs, from 5771 to 42,430, on four different chromosomes. In survival analysis, we consider four cancer-related data-sets (two for breast cancer and two for lung cancer), containing patients ranging from 130 to 1904 and genetic covariates varying from 662 to 54,675.
This paper is organised as follows: In
Section 2, we review the model setup and prior specification for BVS in generalised linear models, Cox proportional hazards and Weibull survival models. In
Section 3, we introduce four computational methods to estimate the marginal likelihood.
Section 4 describes the PARNI proposal, highlighting the novelties in the adaption of algorithmic tuning parameters and the calculation of the accurate and efficient marginal likelihood estimates. We implement these MCMC algorithms in
Section 5 and compare their performance with the add–delete–swap proposal on several real data-sets. We include a discussion in
Section 6, highlighting some possible future research directions.
3. Computation of Marginal Likelihood
Let
be the collection of all coefficient parameters associated with model
. We are interested in simulating samples from the posterior distribution
, where
represents the marginal likelihood, given by
In generalised linear models and survival analysis, a closed-form solution to (
18) is typically not analytically available.
Assuming that an estimate of marginal likelihood
can be obtained, we consider MCMC algorithms with random neighbourhood proposals as described in [
33], which is a sub-class of Metropolis–Hastings (MH) schemes [
54,
55]. The random neighbourhood proposal consists of the following three stages:
Around the current model, , randomly generate a neighbourhood .
Propose a new model, , within random neighbourhood according to .
Accept the new proposal,
, with the MH acceptance probability
where
is the neighbourhood used in the reverse move of the MH scheme.
In this section, we will describe four methods commonly used to estimate marginal likelihood
: data augmentation, Laplace approximation, correlated pseudo-marginal and approximate Laplace approximation. Before introducing these methods, it is necessary to define the following terms for convenience. Let
be a
matrix which contains all necessary covariates for model
and is given by
, and let
be the variance–covariance matrix of the prior distribution of
, defined by
3.1. Data Augmentation
The data-augmentation scheme [
19] introduces latent variables
into the model such that the posterior distribution of variables of interest becomes analytically tractable given
. The Pólya-gamma data-augmentation scheme [
20] can be utilised for the logistic regression model to evaluate the marginal likelihood. Given real numbers
,
,
and a set of latent variables
, in which each individual
follows a Pólya-gamma distribution
, the application of Pólya-gamma data augmentation exploits the following identity:
where
. The above identity implies that the posterior distribution of the coefficients can be represented as a multivariate normal distribution:
where
,
,
is an
n-dimensional vector with entries
and
W is a diagonal matrix with
appearing along its diagonal. By integrating out coefficient
, analytically conditioned on Pólya-gamma random variables
, we obtain the conditional marginal likelihood
In each iteration of the MCMC algorithm, we update
and
alternatively. To refresh
, we can perform a simulation directly from its posterior distribution, which also follows a Pólya-gamma distribution given by
where linear predictor
involves coefficient
simulated from (
22). Efficient samples from the Pólya-gamma random variables can be simulated using the R package pgdraw (version 1.1) [
56]. In addition, Zens et al. described the ultimate Pólya-gamma sampler [
57] to address the slow mixing rate for categorical imbalanced data, as illustrated in [
58].
In general, the data-augmentation schemes may not be applicable to all generalised linear models and survival models. Specifically, for the Cox proportional hazards with partial likelihood or the Weibull model, there is currently no suitable data augmentation to directly yield a parametric posterior distribution for the regression coefficients.
3.2. Laplace Approximation
Assuming a unimodal posterior distribution of the regression coefficients, the Laplace approximation estimates the marginal likelihood with a second-order Taylor approximation. This method leads to a Gaussian integral, with the solution of the marginal likelihood being given by
where
is the posterior mode of
and
is the negated Hessian of
evaluated at mode
. Additionally, the Laplace approximation provides a normal approximation to the posterior distribution of coefficient
as
To incorporate the Laplace approximation in MH sampling, we replace marginal likelihood
in (
19) with the approximate
as described above.
Laplace approximation has been shown to be asymptotically consistent for estimating Bayes factors [
59] and Bayesian variable selection on generalised linear models [
60]. In finite-sample problems, however, Laplace approximation introduces biases, so
is not an unbiased estimate of true marginal likelihood
. The resulting MCMC scheme, which involves the step of Laplace approximation, targets a different distribution compared with the true posterior
. Instead, it targets the distribution
.
3.3. Correlated Pseudo-Marginal Method
We can alternatively make use of normal approximation
to derive an importance sampling estimate of marginal likelihood
. This estimator is unbiased and given by
where
are
N samples from
. As in Laplace approximation, we can replace marginal likelihood
in (
19) with estimated marginal likelihood
. This leads to the pseudo-marginal scheme in [
61,
62]. Andrieu and Roberts [
62] show that the resulting Markov Chain preserves
-reversibility as long as estimated marginal likelihood
is an unbiased estimator of the true marginal likelihood,
.
It is possible to extend a pseudo-marginal method to a correlated pseudo-marginal method [
21], with the aim of reducing the estimation variance of the ratio of estimated marginal likelihoods
. The correlated pseudo-marginal method is applied to Bayesian variable selection for the logistic regression model in [
27], which provides an implementation that we also adopt in this work.
3.4. Approximate Laplace Approximation
The above Laplace approximation and correlated pseudo-marginal methods are computationally intensive due to the optimisation process required to obtain the normal approximation in (
26), especially for dealing with large-
n data. To avoid the overwhelming computational cost associated with the optimisation process, Rossell et al. [
16] introduce the approximate Laplace approximation method (ALA), which is more computationally tractable for large-
n problems. In this work, we consider the alternative formula described in supplementary material S.1. of [
16], as it offers better computational stability when inverting the Hessian under the independent prior in (
7).
In ALA, a Taylor expansion of log-posterior density
is performed at initial value
. Solving the resulting Gaussian integral leads to
where
and
are the gradient and Hessian of the negative log-posterior density evaluated at
, respectively. It is suggested in [
16] to set initial value
to
for convenience.
By applying ALA to the MH acceptance probability in (
19), we obtain an MCMC algorithm that targets the ALA posterior distribution
as the equilibrium distribution. Although Ref. [
16] shows that ALA can recover the optimal model with respect to a mean squared loss, it is important to note that ALA is not consistent with respect to the marginal likelihood (in contrast to the classical Laplace approximation) and
is not an unbiased estimator of the true marginal likelihood,
.





{kind=link}