
Generating Datasets for Real-Time Scheduling on 5G New Radio



{kind=link}
{kind=link}
{kind=link}
{kind=link}
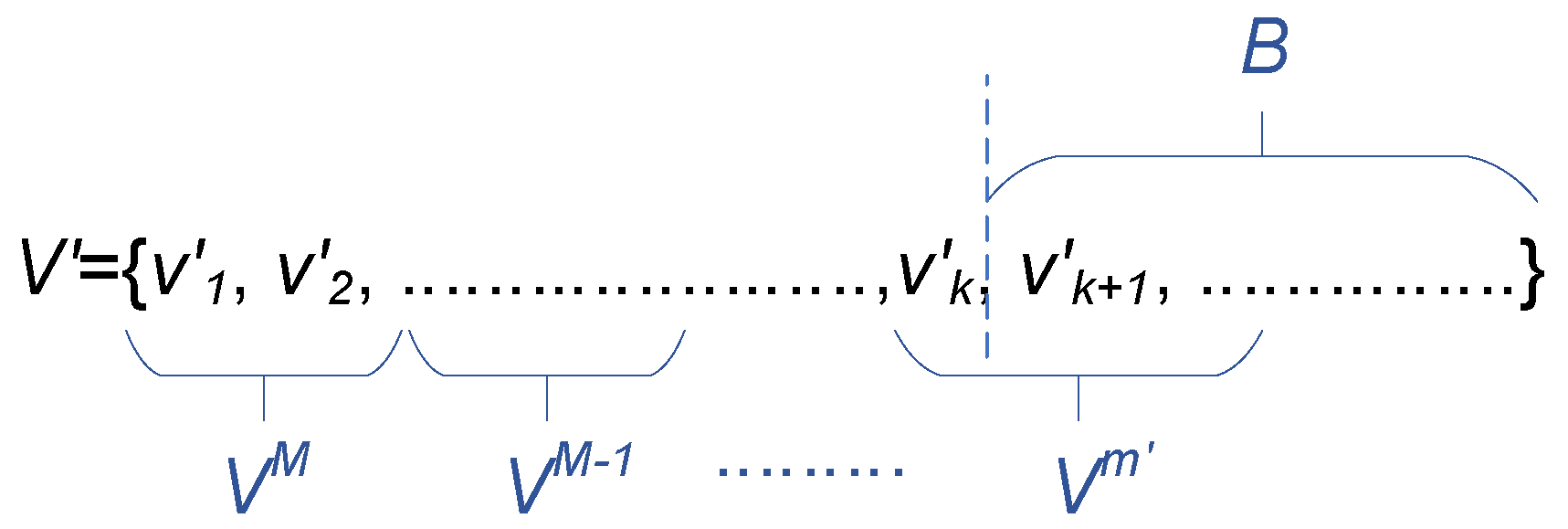{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- First, according to the requirements of 5G NR scheduling, we formulate the problem into an optimization–modulo-theories (OMT) problem, which reduces variables by increasing the formalization of the relationship between them.
- Second, to further reduce the difficulty of solving the problem, we transform the OMT problem into an satisfiability–modulo-theories (SMT) problem and then reduce the solution space by tightening the upper and lower bounds of the scheduling objective.
- Third, we use the SMT-based method to generate a large number of optimal solutions and then constitute the dataset for 5G NR scheduling. Compared to existing work, our proposed method reduces the solution time by .
- Finally, we use the generated dataset to train a pointer network model, and the evaluation results show that the model can achieve better scheduling performance than existing polynomial-time algorithms.
2. Related Work
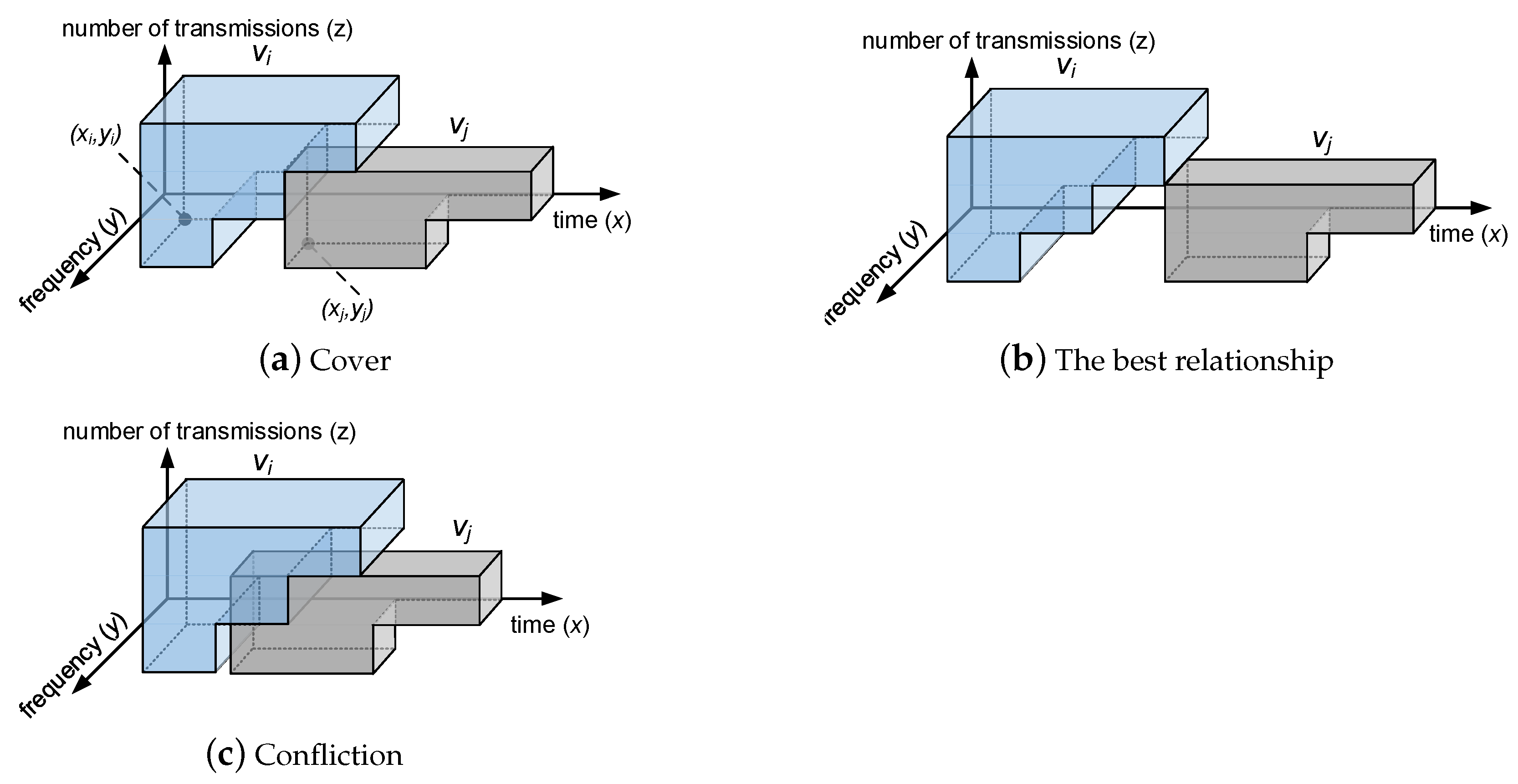
3. Problem Model
4. Formulation of the OMT Problem
5. Formulation of the SMT Problem
5.1. The Basic SMT Problem
5.2. Improvement
| Algorithm 1 Packet placement algorithm. |
Input: V, L, P Output: or FAIL
|
- (1)
- SMT(n) is satisfiable, and SMT() is satisfiable. Based on SMT(n), if an uncovered packet with can be placed under other packets, then SMT() is satisfiable.
- (2)
- SMT(n) is satisfiable, and SMT() is not satisfiable. Based on SMT(n), if there is no uncovered packet with , then SMT() must not be satisfiable.
- (3)
- SMT(n) is satisfiable, and SMT() is satisfiable. After SMT(n) is satisfied, if available resources are sufficient to make a covered packet with uncovered, then SMT() is satisfiable.
- (4)
- SMT(n) is satisfiable, and SMT() is not satisfiable. After SMT(n) is satisfied, if there are no resources available, and no packet can be covered anymore, then SMT() cannot be satisfiable.
6. Evaluation
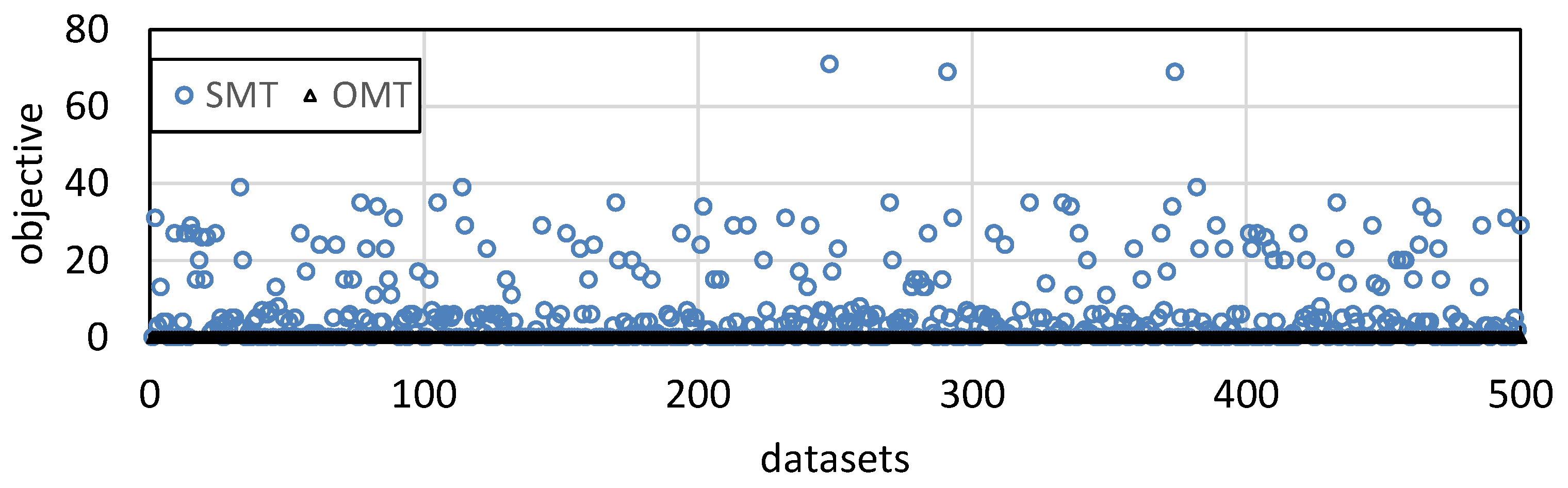
6.1. Generating Scheduling Problems
6.2. Solving Scheduling Problems
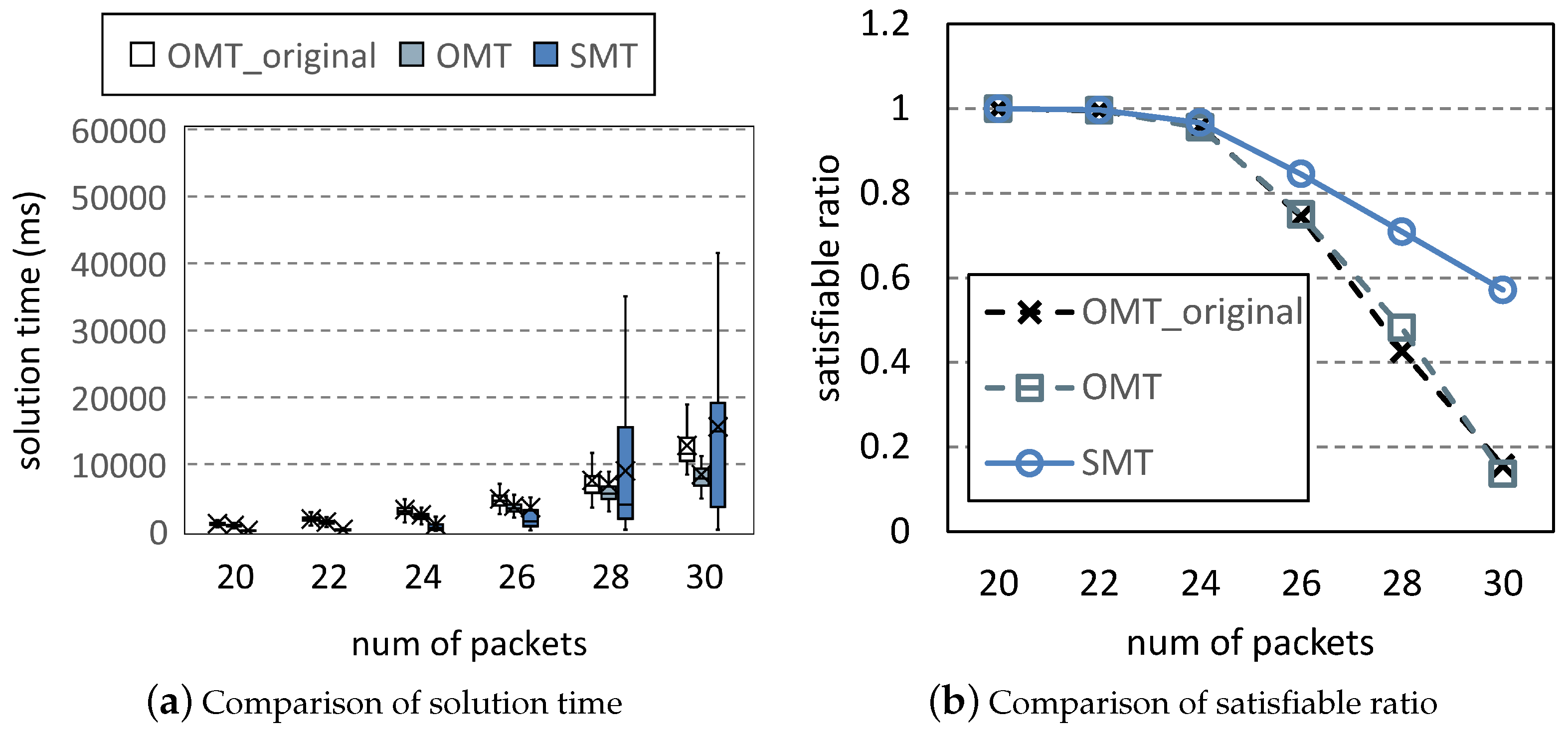
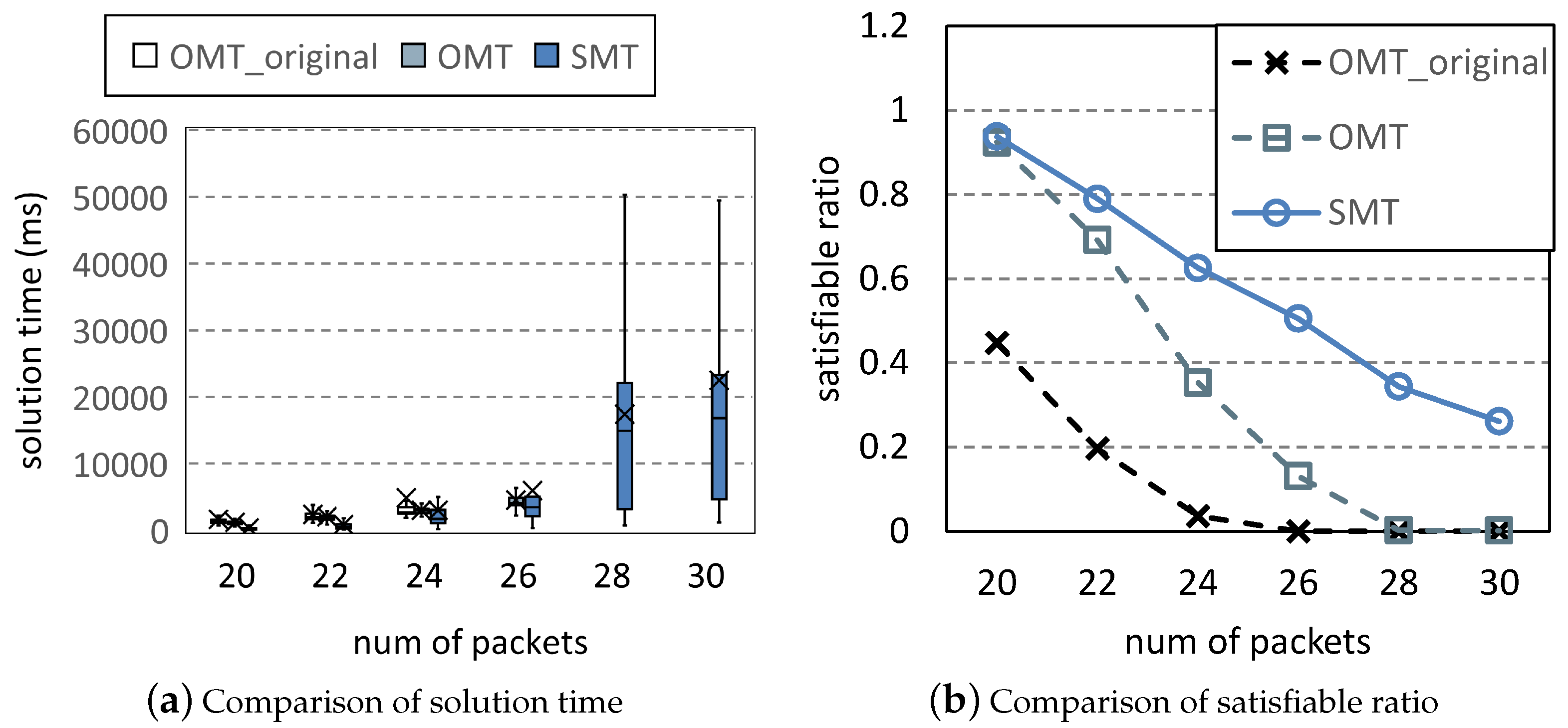
6.2.1. Performance Comparison
6.2.2. Scalability of the SMT-Based Method
6.3. Pointer Networks
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shan, Z.; Wang, J.; Zhang, Q. Development of digital, intelligent and networked manufacturing for batch customized flexible production. Chin. J. Internet Things 2021, 5, 1–9. [Google Scholar]
- Wang, Q.; Jin, G.; Li, Q.; Wang, K.; Yang, Z.; Wang, H. Research status and prospect of industrial edge computing. Inf. Control 2021, 50, 18. [Google Scholar]
- Hampel, G.; Li, C.; Li, J. 5G Ultra-Reliable Low-Latency Communications in Factory Automation Leveraging Licensed and Unlicensed Bands. IEEE Commun. Mag. 2019, 57, 117–123. [Google Scholar] [CrossRef]
- Lu, C.; Saifullah, A.; Li, B.; Sha, M.; Gonzalez, H.; Gunatilaka, D.; Wu, C.; Nie, L.; Chen, Y. Real-Time Wireless Sensor-Actuator Networks for Industrial Cyber-Physical Systems. Proc. IEEE 2016, 104, 1013–1024. [Google Scholar] [CrossRef]
- Sachs, J.; Andersson, L.A.A.; Araújo, J.; Curescu, C.; Lundsjö, J.; Rune, G.; Steinbach, E.; Wikström, G. Adaptive 5G Low-Latency Communication for Tactile InternEt Services. Proc. IEEE 2019, 107, 325–349. [Google Scholar] [CrossRef]
- Taleb, T.; Nadir, Z.; Flinck, H.; Song, J. Extremely Interactive and Low-Latency Services in 5G and Beyond Mobile Systems. IEEE Commun. Stand. Mag. 2021, 5, 114–119. [Google Scholar] [CrossRef]
- Saifullah, A.; Xu, Y.; Lu, C.; Chen, Y. Real-Time Scheduling for WirelessHART Networks. In Proceedings of the 2010 31st IEEE Real-Time Systems Symposium, San Diego, CA, USA, 30 November–3 December 2010; pp. 150–159. [Google Scholar]
- Lee, S.; Baek, H.; Woo, H.; Shin, K.G.; Lee, J. ML for RT: Priority Assignment Using Machine Learning. In Proceedings of the 2021 IEEE 27th Real-Time and Embedded Technology and Applications Symposium (RTAS), Nashville, TN, USA, 18–21 May 2021; pp. 118–130. [Google Scholar]
- Jin, X.; Tian, Y.; Xu, C.; Xia, C.; Li, D.; Zeng, P. Mixed-Criticality Industrial Data Scheduling on 5G NR. IEEE Internet Things J. 2022, 9, 10306–10318. [Google Scholar] [CrossRef]
- Eisen, M.; Rashid, M.M.; Ribeiro, A.; Cavalcanti, D. Scheduling Low Latency Traffic for Wireless Control Systems in 5G Networks. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Chen, Y.; Wu, Y.; Hou, Y.T.; Lou, W. mCore: Achieving Sub-millisecond Scheduling for 5G MU-MIMO Systems. In Proceedings of the IEEE INFOCOM 2021—IEEE Conference on Computer Communications, Vancouver, BC, Canada, 10–13 May 2021; pp. 1–10. [Google Scholar]
- Anand, A.; de Veciana, G.; Shakkottai, S. Joint Scheduling of URLLC and eMBB Traffic in 5G Wireless Networks. IEEE/ACM Trans. Netw. 2020, 28, 477–490. [Google Scholar] [CrossRef]
- Comşa, I.S.; Zhang, S.; Aydin, M.E.; Kuonen, P.; Lu, Y.; Trestian, R.; Ghinea, G. Towards 5G: A Reinforcement Learning-Based Scheduling Solution for Data Traffic Management. IEEE Trans. Netw. Serv. Manag. 2018, 15, 1661–1675. [Google Scholar] [CrossRef]
- Comșa, I.S.; Trestian, R.; Muntean, G.M.; Ghinea, G. 5MART: A 5G SMART Scheduling Framework for Optimizing QoS Through Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2020, 17, 1110–1124. [Google Scholar] [CrossRef]
- You, L.; Liao, Q.; Pappas, N.; Yuan, D. Resource Optimization With Flexible Numerology and Frame Structure for Heterogeneous Services. IEEE Commun. Lett. 2018, 22, 2579–2582. [Google Scholar] [CrossRef]
- Gu, Z.; She, C.; Hardjawana, W.; Lumb, S.; McKechnie, D.; Essery, T.; Vucetic, B. Knowledge-Assisted Deep Reinforcement Learning in 5G Scheduler Design: From Theoretical Framework to Implementation. IEEE J. Sel. Areas Commun. 2021, 39, 2014–2028. [Google Scholar] [CrossRef]
- Bonjorn, N.; Foukalas, F.; Cañellas, F.; Pop, P. Cooperative Resource Allocation and Scheduling for 5G eV2X Services. IEEE Access 2019, 7, 58212–58220. [Google Scholar] [CrossRef]
- Karimi, A.; Pedersen, K.I.; Mahmood, N.H.; Steiner, J.; Mogensen, P. 5G Centralized Multi-Cell Scheduling for URLLC: Algorithms and System-Level Performance. IEEE Access 2018, 6, 72253–72262. [Google Scholar] [CrossRef]
- Ou, X.; Xu, Y.; Hong, H.; He, D.; Wu, Y.; Huang, Y.; Zhang, W. A DRL-Based Joint Scheduling and Resource Allocation Scheme for Mixed Unicast–Broadcast Transmission in 5G. IEEE Trans. Broadcast. 2023, 1–14. [Google Scholar] [CrossRef]
- Zou, H.; Li, Y.; Chu, X.; Xu, C.; Wang, T. Improving Fairness in Coexisting 5G and Wi-Fi Network on Unlicensed Band with URLLC. In Proceedings of the 2023 IEEE/ACM 31st International Symposium on Quality of Service (IWQoS), Orlando, FL, USA, 19–21 June 2023; pp. 1–10. [Google Scholar]
- Lagen, S.; Bojovic, B.; Koutlia, K.; Zhang, X.; Wang, P.; Qu, Q. QoS Management for XR Traffic in 5G NR: A Multi-Layer System View & End-to-End Evaluation. IEEE Commun. Mag. 2023, 1–7. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27, Proceedings of the 2014 Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; NeurIPS: La Jolla, CA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Patel, M.; Wang, X.; Mao, S. Data Augmentation with Conditional GAN for Automatic Modulation Classification. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, New York, NY, USA, 13 July 2020; WiseML ’20. pp. 31–36. [Google Scholar]
- Li, R.; Ding, Y. A network encryption traffic classification and balancing method based on DCGAN. Commun. Technol. 2022, 55, 926–934. [Google Scholar]
- Chazelle, B. The Bottomn-Left Bin-Packing Heuristic: An Efficient Implementation. IEEE Trans. Comput. 1983, C-32, 697–707. [Google Scholar] [CrossRef]
- Bini, E.; Buttazzo, G.C. Measuring the Performance of Schedulability Tests. Real-Time Syst. 2005, 30, 129–154. [Google Scholar] [CrossRef]
- Beijing Yunzhisoftcom Information Technology Co., Ltd. 5G-uRLLC Test Platform. 2022. Available online: http://yunzhiruantong.com/?m=home&c=View&a=index&aid=176 (accessed on 1 June 2023).
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Advances in Neural Information Processing Systems 28, Proceedings of the 2015 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; NeurIPS: La Jolla, CA, USA, 2015; pp. 2692–2700. [Google Scholar]




















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, X.; Chai, H.; Xia, C.; Xu, C. Generating Datasets for Real-Time Scheduling on 5G New Radio. Entropy 2023, 25, 1289. https://doi.org/10.3390/e25091289
Jin X, Chai H, Xia C, Xu C. Generating Datasets for Real-Time Scheduling on 5G New Radio. Entropy. 2023; 25(9):1289. https://doi.org/10.3390/e25091289
Chicago/Turabian StyleJin, Xi, Haoxuan Chai, Changqing Xia, and Chi Xu. 2023. "Generating Datasets for Real-Time Scheduling on 5G New Radio" Entropy 25, no. 9: 1289. https://doi.org/10.3390/e25091289