
Task-Decoupled Knowledge Transfer for Cross-Modality Object Detection

Abstract
:1. Introduction
- We rethink the generally used visible classification pre-training approaches and propose the TDP method by decoupling classification and localization features to obtain a pre-training model that is more conducive to cross-modalities.
- Further, we propose the TRHE method to adjust the hyperparameters related to classification and localization during the training process and improve the adaptability of the network to the modulated pre-training model.
- We investigate the influence of modality changes on the detection network’s classification and localization components and validate the effectiveness of our methods on MSOD and FLIR datasets while achieving state-of-the-art accuracy on the FLIR dataset, surpassing most multi-spectral object-detection benchmarks.
2. Related Works
2.1. Multi-Spectral Object Detection
2.2. Cross-Modality Knowledge Transfer Based on Pre-Training Model and Fine-Tuning
2.3. Hyperparameter Optimization
3. Method
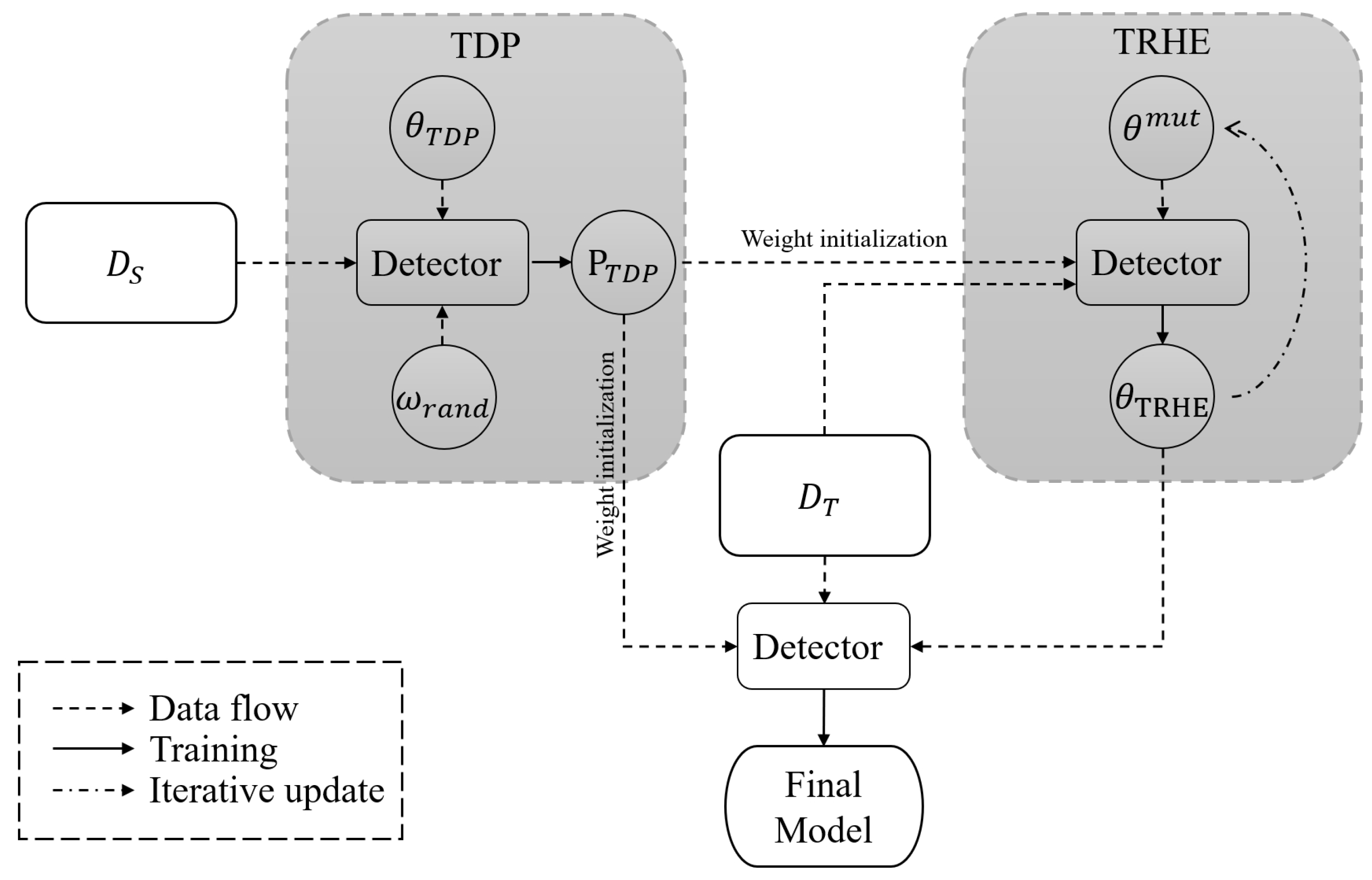
3.1. Overview
3.2. Task-Decoupled Pre-Training
3.3. Task-Related Hyperparameter Evolution
3.4. The Algorithm Combining TDP and TRHE Methods
- Line 1: Modulate the training process of the pre-training model based on the TDP method, and the source domain data come from a large visible detection dataset.
- Lines 2–15: The TRHE method is used to obtain effective hyperparameters, and the training is performed on the target domain dataset using the pre-training model obtained in the previous process. In the method with N iterations, the initial hyperparameters are changed using the genetic mutation algorithm and evaluated using the fitness functions. Finally, better hyperparameters are produced.
- Line 16: The final detector is trained on the target domain dataset using the modulated pre-training model and hyperparameters obtained in the previous two processes.
| Algorithm 1: Complete algorithm with TDP and TRHE. |
 |
4. Experiments
4.1. Experimental Configuration
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Main Results
4.3. Ablation Study
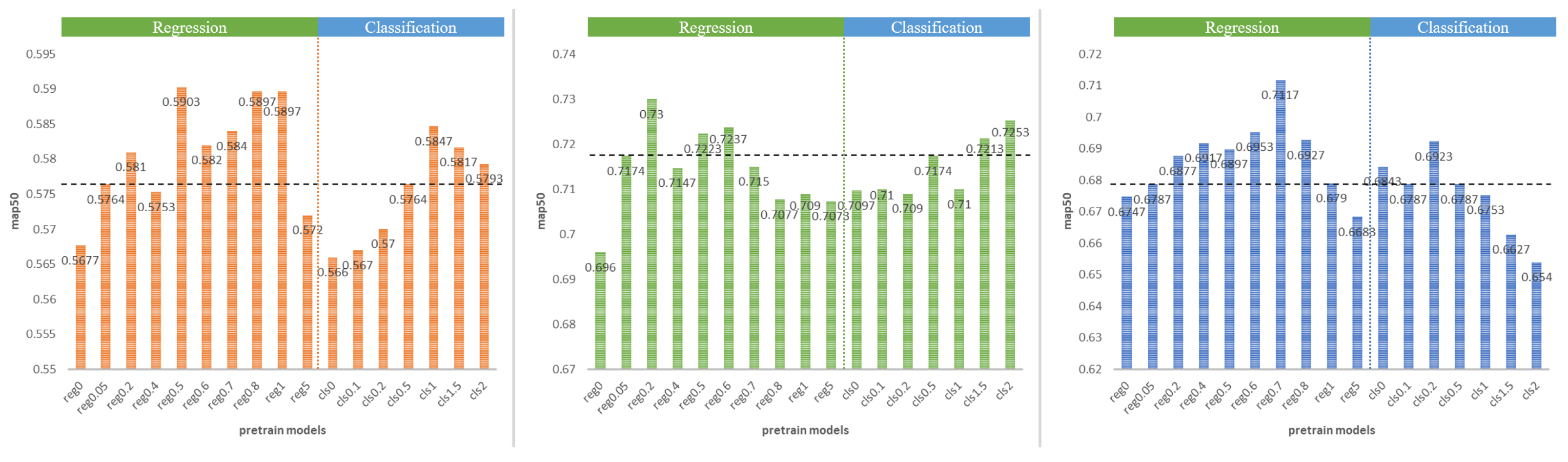
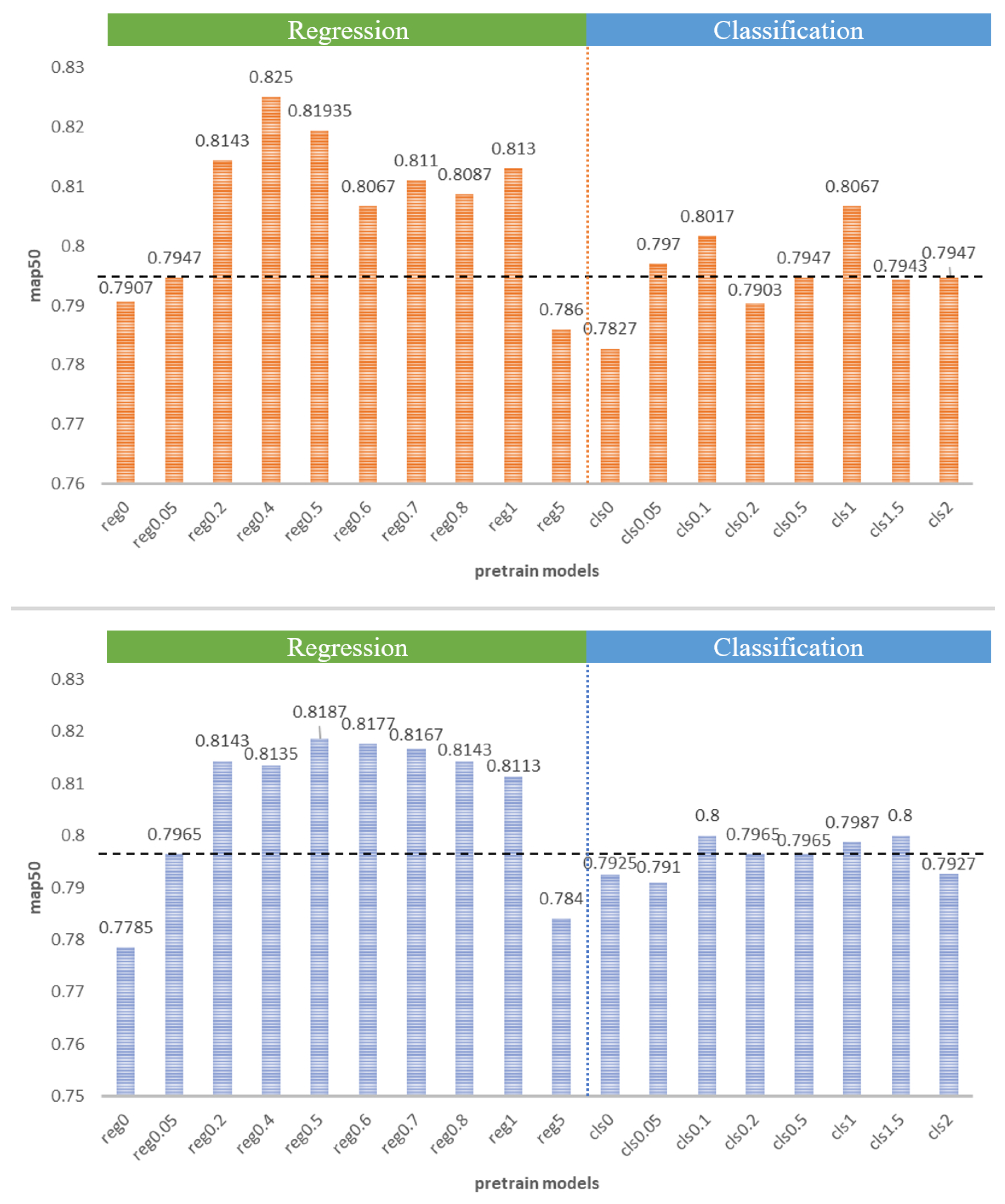
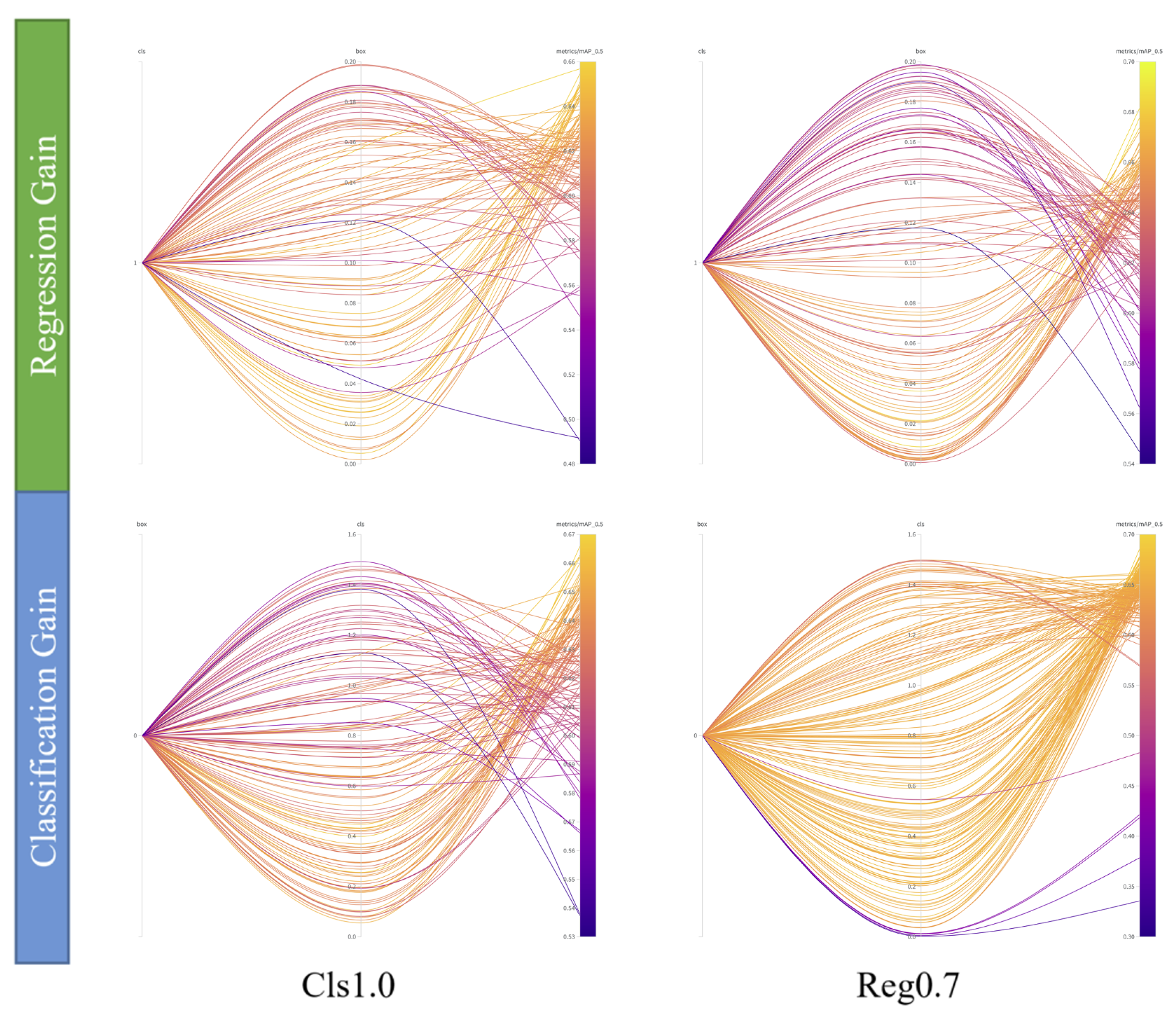
4.3.1. Results and Discussion of the TDP Method
4.3.2. Comparison of Different Pre-Training Models and Hyperparameter Training Results
4.3.3. Results and Discussion of the TRHE Method
4.3.4. Ablation Experiments on the TDP and TRHE Methods
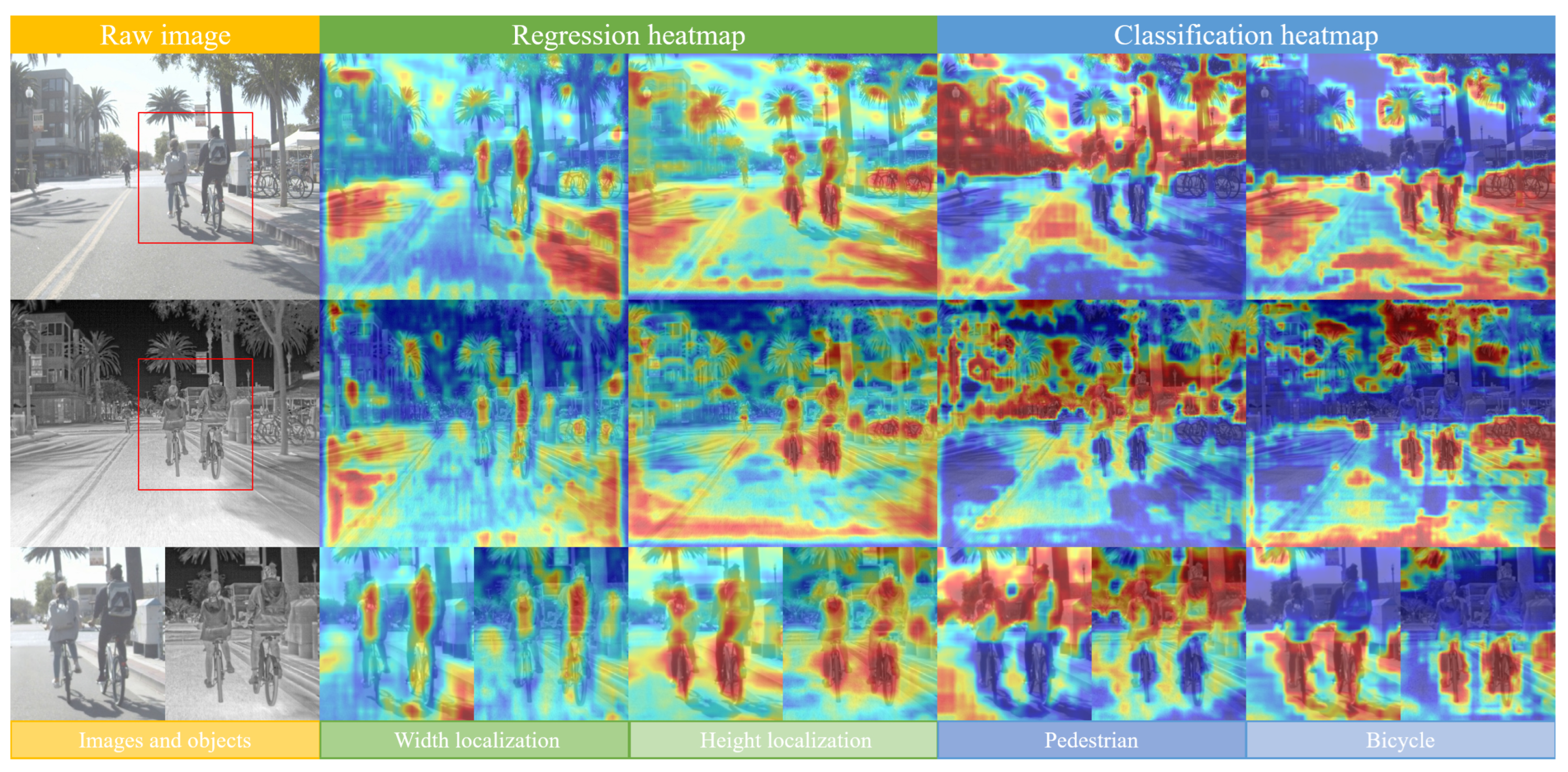
4.4. Discussion of the Idea of Task Decoupling
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Teledyne FLIR LLC. FREE FLIR Thermal Dataset for Algorithm Training. Available online: https://www.flir.com/oem/adas/adas-dataset-form/ (accessed on 1 May 2021).
- Takumi, K.; Watanabe, K.; Ha, Q.; Tejero-De-Pablos, A.; Ushiku, Y.; Harada, T. Multispectral object detection for autonomous vehicles. In Proceedings of the Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 35–43. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Sun, H.; Bai, X.; Guo, S.; Jin, D. Traffic thermal infrared texture generation based on siamese semantic CycleGAN. Infrared Phys. Technol. 2021, 116, 103748. [Google Scholar] [CrossRef]
- Liu, X.; Wang, R.; Huo, H.; Yang, X.; Li, J. An attention-guided and wavelet-constrained generative adversarial network for infrared and visible image fusion. Infrared Phys. Technol. 2023, 129, 104570. [Google Scholar] [CrossRef]
- Hou, Y.L.; Song, Y.; Hao, X.; Shen, Y.; Qian, M.; Chen, H. Multispectral pedestrian detection based on deep convolutional neural networks. Infrared Phys. Technol. 2018, 94, 69–77. [Google Scholar] [CrossRef]
- Bongini, F.; Berlincioni, L.; Bertini, M.; Del Bimbo, A. Partially fake it till you make it: Mixing real and fake thermal images for improved object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 5482–5490. [Google Scholar]
- Zheng, X.; Yang, Q.; Si, P.; Wu, Q. A Multi-Stage Visible and Infrared Image Fusion Network Based on Attention Mechanism. Sensors 2022, 22, 3651. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Chi, Y.; Shen, T.; Song, J.; Zhang, Z.; Zhu, Y. Improving RGB-Infrared Object Detection by Reducing Cross-Modality Redundancy. Remote Sens. 2022, 14, 2020. [Google Scholar] [CrossRef]
- Liu, X.; Gao, H.; Miao, Q.; Xi, Y.; Ai, Y.; Gao, D. MFST: Multi-Modal Feature Self-Adaptive Transformer for Infrared and Visible Image Fusion. Remote Sens. 2022, 14, 3233. [Google Scholar] [CrossRef]
- He, K.; Girshick, R.; Dollár, P. Rethinking imagenet pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4918–4927. [Google Scholar]
- Song, G.; Liu, Y.; Wang, X. Revisiting the sibling head in object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11563–11572. [Google Scholar]
- Wang, T.; Li, Y. Rotation-Invariant Task-Aware Spatial Disentanglement in Rotated Ship Detection Based on the Three-Stage Method. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609112. [Google Scholar] [CrossRef]
- Huang, Z.; Li, W.; Xia, X.G.; Wang, H.; Tao, R. Task-wise Sampling Convolutions for Arbitrary-Oriented Object Detection in Aerial Images. arXiv 2022, arXiv:2209.02200. [Google Scholar]
- Ren, S.; He, K.; Ross, G.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Ghose, D.; Desai, S.M.; Bhattacharya, S.; Chakraborty, D.; Fiterau, M.; Rahman, T. Pedestrian detection in thermal images using saliency maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Cao, Y.; Zhou, T.; Zhu, X.; Su, Y. Every feature counts: An improved one-stage detector in thermal imagery. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1965–1969. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Zheng, Y.; Izzat, I.H.; Ziaee, S. GFD-SSD: Gated fusion double SSD for multispectral pedestrian detection. arXiv 2019, arXiv:1903.06999. [Google Scholar]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly aligned cross-modal learning for multispectral pedestrian detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5127–5137. [Google Scholar]
- Zhou, K.; Chen, L.; Cao, X. Improving multispectral pedestrian detection by addressing modality imbalance problems. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 787–803. [Google Scholar]
- Zoph, B.; Ghiasi, G.; Lin, T.Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q. Rethinking pre-training and self-training. Adv. Neural Inf. Process. Syst. 2020, 33, 3833–3845. [Google Scholar]
- Feng, Y.; Jiang, J.; Tang, M.; Jin, R.; Gao, Y. Rethinking supervised pre-training for better downstream transferring. arXiv 2021, arXiv:2110.06014. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Ma, W.; Tian, T.; Xu, H.; Huang, Y.; Li, Z. Aabo: Adaptive anchor box optimization for object detection via bayesian sub-sampling. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 560–575. [Google Scholar]
- Gagneja, A.; Gupta, A.K.; Lall, B. Statistical Optimization of FPN Hyperparameters for improved Pedestrian Detection. In Proceedings of the 2022 1st International Conference on Informatics (ICI), Noida, India, 14–16 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 126–131. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Fang, J.; Michael, K.; Montes, D.; Nadar, J.; Skalski, P.; et al. Ultralytics/Yolov5: v6. 1-Tensorrt, Tensorflow Edge TPU and Openvino Export and Inference; Zenodo: Geneve, Switzerland, 2022; Volume 6222936. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 276–280. [Google Scholar]
- Devaguptapu, C.; Akolekar, N.; M Sharma, M.; N Balasubramanian, V. Borrow from anywhere: Pseudo multi-modal object detection in thermal imagery. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Munir, F.; Azam, S.; Jeon, M. Sstn: Self-supervised domain adaptation thermal object detection for autonomous driving. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 206–213. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefèvre, S.; Avignon, B. Guided attentive feature fusion for multispectral pedestrian detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 72–80. [Google Scholar]
- Chen, Y.T.; Shi, J.; Ye, Z.; Mertz, C.; Ramanan, D.; Kong, S. Multimodal object detection via probabilistic ensembling. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 139–158. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Data | Person | Bicycle | Car | mAP50 |
|---|---|---|---|---|---|
| MMTOD-UNIT [36] | RGB + Thermal | 64.5 | 49.4 | 70.8 | 61.5 |
| CFR [35] | RGB + Thermal | 74.49 | 55.77 | 84.91 | 72.39 |
| SSTN101 [37] | RGB + Thermal | - | - | - | 77.57 |
| GAFF [38] | RGB + Thermal | - | - | - | 72.90 |
| ProbEn [39] | RGB + Thermal | 87.65 | 73.49 | 90.14 | 83.76 |
| ThermalDet [23] | Thermal | 78.24 | 60.04 | 85.52 | 74.60 |
| [8] | Thermal | 78.24 | 60.04 | 85.52 | 74.60 |
| Ours(yolom) | Thermal | 86.23 | 71.78 | 90.5 | 82.83 |
| Ours(yolox) | Thermal | 86.93 | 75.05 | 91.2 | 84.4 |
| mAP50 | Person | Car | Bike | Improvement | ||
|---|---|---|---|---|---|---|
| 0.5 | 0 | 67.47 | 83.87 | 61.5 | 57.07 | −0.4 |
| 0.5 | 0.05 | 67.87 | 83.87 | 62.3 | 57.43 | - |
| 0.5 | 0.2 | 68.77 | 84.17 | 61.93 | 60.17 | 0.9 |
| 0.5 | 0.4 | 69.17 | 84.67 | 63.03 | 59.73 | 1.3 |
| 0.5 | 0.5 | 68.97 | 84.8 | 60.97 | 61.23 | 1.1 |
| 0.5 | 0.6 | 69.53 | 85.53 | 61.67 | 60.23 | 1.66 |
| 0.5 | 0.7 | 71.17 | 85.43 | 66.27 | 61.8 | 3.3 |
| 0.5 | 0.8 | 69.27 | 86.53 | 60.67 | 60.63 | 1.4 |
| 0.5 | 1.0 | 67.9 | 85.07 | 62.83 | 55.93 | 0.03 |
| 0.5 | 5.0 | 66.83 | 84.93 | 61.57 | 54 | −1.04 |
| mAP50 | Person | Car | Bike | Improvement | ||
|---|---|---|---|---|---|---|
| 0 | 0.05 | 68.43 | 84.07 | 62.4 | 58.77 | 0.56 |
| 0.1 | 0.05 | 67.87 | 84.2 | 61.23 | 58.23 | 0 |
| 0.2 | 0.05 | 69.23 | 84.6 | 62.33 | 60.8 | 1.36 |
| 0.5 | 0.05 | 67.87 | 83.87 | 62.3 | 57.43 | - |
| 1.0 | 0.05 | 67.53 | 83.08 | 61.48 | 58.08 | −0.34 |
| 1.5 | 0.05 | 66.27 | 81.33 | 62.1 | 55.27 | −1.6 |
| 2.0 | 0.05 | 65.4 | 80.73 | 61.77 | 53.67 | −2.47 |
| Image Type | mAP50 | Person | Bicycle | Car |
|---|---|---|---|---|
| RGB | 67.2 | 67 | 52.6 | 82 |
| IR | 78.1 | 82.4 | 62.1 | 89.9 |
| RGT | 76.1 | 80.6 | 58.9 | 88.9 |
| RTB | 77.5 | 83.4 | 59.4 | 89.6 |
| TGB | 76.7 | 81.8 | 59.7 | 88.6 |
| RTT | 79.5 | 84.1 | 63.9 | 90.5 |
| TGT | 78.6 | 82 | 64.5 | 89.3 |
| TTB | 81 | 83.3 | 69.4 | 90.2 |
| mAP50 | Person | Bicycle | Car | Improvement | ||
|---|---|---|---|---|---|---|
| 0.5 | 0 | 79.07 | 82.4 | 65.2 | 89.7 | −0.4 |
| 0.5 | 0.05 | 79.47 | 83.73 | 64.63 | 90.33 | - |
| 0.5 | 0.2 | 81.43 | 85.6 | 68.3 | 90.33 | 1.96 |
| 0.5 | 0.4 | 82.5 | 85.9 | 71 | 90.63 | 3.03 |
| 0.5 | 0.5 | 81.67 | 85.5 | 68.83 | 90.77 | 2.2 |
| 0.5 | 0.6 | 80.67 | 85.3 | 66.23 | 90.5 | 1.2 |
| 0.5 | 0.7 | 81.1 | 85.43 | 67.37 | 90.47 | 1.63 |
| 0.5 | 0.8 | 80.87 | 84.83 | 67.3 | 90.6 | 1.4 |
| 0.5 | 1.0 | 81.3 | 85.53 | 67.6 | 90.77 | 1.83 |
| 0.5 | 5.0 | 78.6 | 84.87 | 61.2 | 89.7 | −0.87 |
| mAP50 | Person | Bicycle | Car | Improvement | ||
|---|---|---|---|---|---|---|
| 0 | 0.05 | 78.27 | 84.17 | 60.3 | 90.47 | −1.36 |
| 0.1 | 0.05 | 79.7 | 84.5 | 64.63 | 89.97 | 0.07 |
| 0.1 | 0.05 | 80.17 | 83.13 | 67.47 | 89.9 | 0.54 |
| 0.2 | 0.05 | 79.03 | 83.47 | 63.33 | 90.27 | −0.6 |
| 0.5 | 0.05 | 79.47 | 83.73 | 64.63 | 90.33 | - |
| 1.0 | 0.05 | 80.67 | 83.67 | 68.1 | 90.17 | 1.04 |
| 1.5 | 0.05 | 79.43 | 83.03 | 65.13 | 90.07 | −0.2 |
| 2.0 | 0.05 | 79.47 | 83 | 65.5 | 89.87 | −0.16 |
| Method | Initial | Initial | Final | Final | Parents Select | mAP50 | mAP | Fitness |
|---|---|---|---|---|---|---|---|---|
| Baseline | 0.2 | 0.02 | 0.2 | 0.02 | - | 82.4 | 42 | 46.04 |
| TRHE | 0.2 | 0.02 | 0.22955 | 0.02101 | Random | 82.4 | 41.97 | 46.013 |
| TRHE | 0.2 | 0.02 | 0.2042 | 0.02216 | Best | 81.87 | 42.5 | 46.437 |
| TRHE* | 0.2 | 0.02 | 0.24544 | 0.02454 | Best | 81.87 | 42.5 | 46.437 |
| Baseline | 0.5 | 0.05 | 0.5 | 0.05 | - | 81.935 | 42.285 | 46.25 |
| TRHE | 0.5 | 0.05 | 0.5 | 0.05 | Random | 81.2 | 42.97 | 46.793 |
| TRHE | 0.5 | 0.05 | 0.47716 | 0.05937 | Best | 81.97 | 42.03 | 46.024 |
| TRHE* | 0.5 | 0.05 | 0.48879 | 0.04888 | Best | 82 | 43.27 | 47.143 |
| Baseline | 0.8 | 0.08 | 0.8 | 0.08 | - | 81.55 | 42.15 | 46.09 |
| TRHE | 0.8 | 0.08 | 0.8 | 0.08 | Random | 81.4 | 42.9 | 46.75 |
| TRHE | 0.8 | 0.08 | 0.8 | 0.08 | Best | 82.2 | 42.97 | 46.893 |
| TRHE* | 0.8 | 0.08 | 0.8 | 0.08 | Best | 81.5 | 42.5 | 46.4 |
| Method | MSOD Dataset | FLIR Dataset | |||||||
|---|---|---|---|---|---|---|---|---|---|
| TDP | TRHE | mAP50 | Improvement | mAP | Fitness | mAP50 | Improvement | mAP | Fitness |
| 67.87 | - | 37.8 | 40.807 | 79.47 | - | 40.67 | 44.55 | ||
| √ | 71.17 | 3.3 | 39.67 | 42.82 | 82.5 | 3.03 | 42.53 | 46.527 | |
| √ | 69.57 | 1.7 | 39.3 | 42.327 | 79.67 | 0.2 | 42.03 | 45.794 | |
| √ | √ | 71.33 | 3.46 | 40.2 | 43.313 | 82.83 | 3.36 | 42.78 | 46.785 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Bai, L.; Chen, X.; Han, J. Task-Decoupled Knowledge Transfer for Cross-Modality Object Detection. Entropy 2023, 25, 1166. https://doi.org/10.3390/e25081166
Wei C, Bai L, Chen X, Han J. Task-Decoupled Knowledge Transfer for Cross-Modality Object Detection. Entropy. 2023; 25(8):1166. https://doi.org/10.3390/e25081166
Chicago/Turabian StyleWei, Chiheng, Lianfa Bai, Xiaoyu Chen, and Jing Han. 2023. "Task-Decoupled Knowledge Transfer for Cross-Modality Object Detection" Entropy 25, no. 8: 1166. https://doi.org/10.3390/e25081166