4.1. (Unconstrained) Streaming Algorithm
We first present the streaming algorithm of [
14] for (unconstrained) diversity maximization in Algorithm 1. Let
,
and
. Obviously, it always holds that
. First, it maintains a sequence
of values for guessing
within a relative error of
and initializes an empty solution
for each
before processing the stream (Lines 1 and 2). Then, for each
and each
, if
contains less than
k elements and the distance between
x and
is at least
, it will add
x to
(Lines 3–6). After processing all elements in
X, the candidate solution that contains
k elements and maximizes the diversity is returned as the solution
S for DM (Line 7). Algorithm 1 is proven to be a
-approximation algorithm for max–min diversity maximization [
14]. In Theorem 1, its approximation ratio is improved to
by refining the analysis of [
14].
| Algorithm 1 SDM |
- Input:
Stream X, distance metric , parameter , solution size - Output:
A set with - 1:
- 2:
Initialize for each - 3:
for all do - 4:
for all do - 5:
if and then - 6:
- 7:
return
|
Theorem 1.
Algorithm 1 is a -approximation algorithm for max–min diversity maximization.
Proof. For each
, there are two cases for
after processing all elements in
X: (1) If
, the condition of Line 5 guarantees that
; (2) If
, it holds that
for every
since the fact that
x is not added to
implies that
, as
. Let us consider a candidate solution
with
. Suppose that
is the optimal solution for DM on
X. We define a function
that maps each element in
to its nearest neighbor in
. As is shown above,
for each
. Because
and
, two distinct elements
with
must exist. For such
, we have
according to the triangle inequality. Thus,
if
. Let
be the smallest
with
. We obtained
from the above results. Additionally, for
, we must have
and
. Therefore, we have
. □
In terms of complexity, Algorithm 1 stores elements and takes time per element, since it makes guesses for , keeps, at most, k elements in each candidate and requires, at most, k distance computations to decide whether to add an element to a candidate.
4.2. Fair Streaming Algorithm for
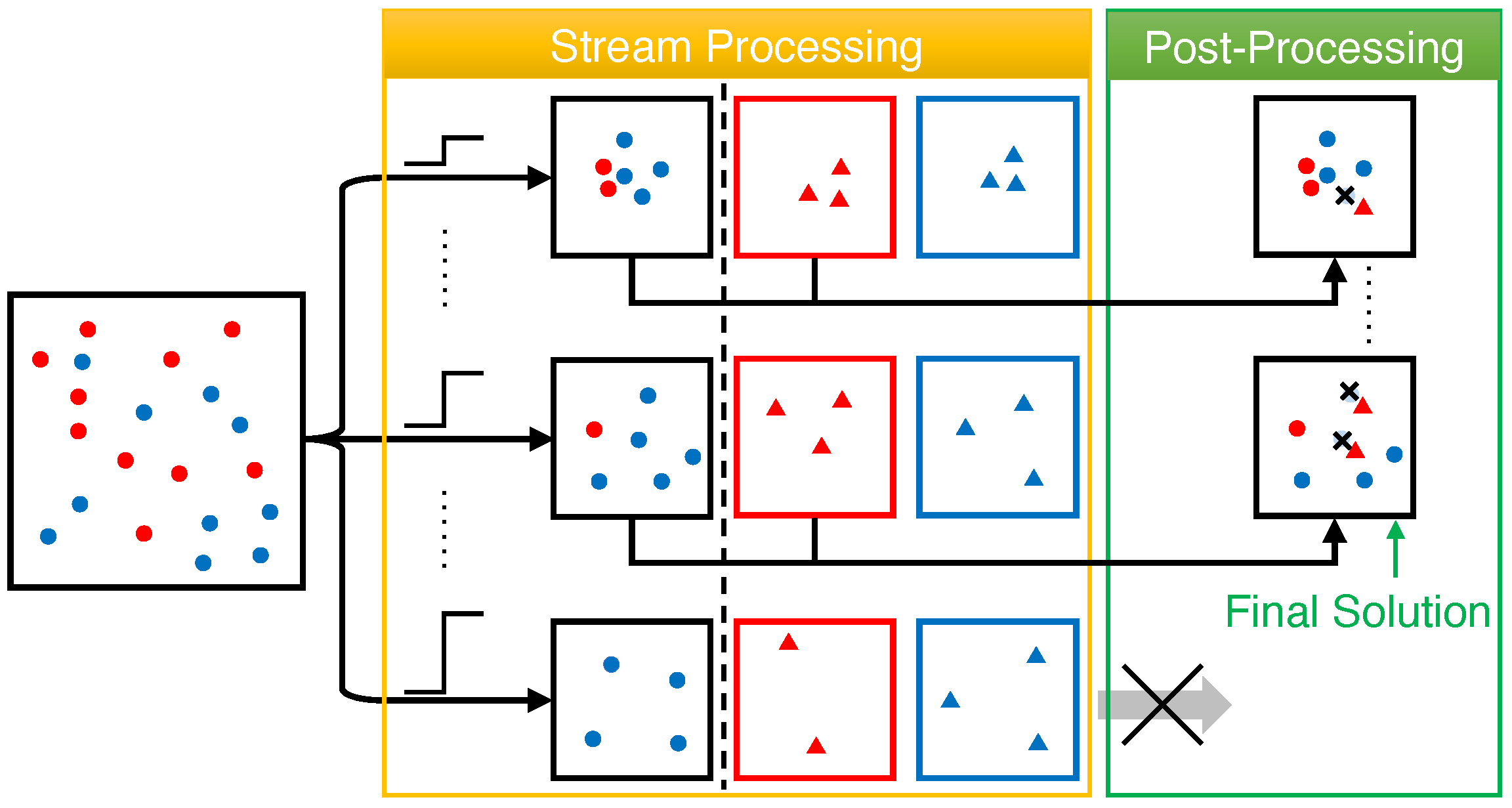
The procedure of our streaming algorithm in case of
, called
SFDM1, is described in Algorithm 2 and illustrated in
Figure 3. In general, the algorithm runs in two phases: stream processing and post-processing. In the stream processing (Lines 1–6), for each guess
of
, it utilizes Algorithm 1 to keep a group-blind candidate
with size constraint
k and two group-specific candidates
and
with size constraints
and
for
and
, respectively. The only difference from Algorithm 1 is that the elements are filtered by group to maintain
and
. After processing all elements of
X in one pass, it will post-process the group-blind candidates to make them satisfy the fairness constraint (Lines 7–15). The post-processing is only performed on a subset
of
, where
contains
k elements and
contains
elements for each group
. For each
,
, either has satisfied the fairness constraint or has one over-filled group
and another under-filled group
. If
is not yet a fair solution,
will be balanced for fairness by first adding
elements, where
, from
to
, and then removing the same number of elements from
. The elements to be added and removed are selected greedily, as in
GMM [
39], to minimize the loss in diversity: the element in
that is the furthest from
is picked for each insertion; and the element in
that is the closest to
is picked for each deletion. Finally, the fair candidate with the maximum diversity after post-processing is returned as the final solution for FDM (Line 16). Next, we will theoretically analyze the approximation ratio and complexity of
SFDM1.
| Algorithm 2 SFDM1 |
- Input:
Stream , distance metric , parameter , size constraints () - Output:
A set s.t. for - ▹
Stream processing - 1:
- 2:
Initialize for every and - 3:
for all do - 4:
Run Lines 3–6 of Algorithm 1 to update w.r.t. x - 5:
if then - 6:
Run Lines 3–6 of Algorithm 1 to update w.r.t. x with size constraint - ▹
Post-processing - 7:
- 8:
for all do - 9:
if for some then - 10:
while do - 11:
- 12:
- 13:
while do - 14:
- 15:
- 16:
return
|
Theoretical Analysis: We prove that SFDM1 achieves an approximation ratio of for FDM, where , in Theorem 2. The proof is based on (i) the existence of such that (Lemma 1) and (ii) for each after post-processing (Lemma 2). Then, we analyze the complexity of SFDM1 in Theorem 3.
Lemma 1.
Let be the largest . It holds that , where is the optimal diversity of FDM on X.
Proof. First of all, we have , where is the optimal diversity of unconstrained DM with on X, since any valid solution for FDM must also be a valid solution for DM. Moreover, it holds that , where is the optimal diversity of unconstrained DM with size constraint on for both , because the optimal solution must contain elements from and is a monotonically non-increasing function—i.e., for any and . Therefore, we prove that .
Then, according to the results of Theorem 1, we have if and if for each . Note that is the largest such that , , and after stream processing. For , we have either or for some . Therefore, it holds that and we conclude the proof. □
Lemma 2.
For each , the candidate solution must satisfy and for both after post-processing.
Proof. The candidate before post-processing has exactly elements but may not contain elements from and elements from . If has exactly elements from and elements from , and thus the post-processing is skipped, we have according to Theorem 1. Otherwise, assuming that , we will add elements from to and remove elements from to ensure the fairness constraint. In Line 16, all the elements in can be selected for insertion. Since the minimum distance between any pair of elements in is at least , we can find, at most, one element , such that for each . This means that there are at least elements from whose distances to all the existing elements in are greater than . Accordingly, after adding elements from to greedily, it still holds that for any . In Line 14, for each element , there is, at most, one (newly added) element such that . Meanwhile, it is guaranteed that y is the nearest neighbor of x in in this case. Therefore, in Line 14, every with is removed, since there are, at most, such elements and the one with the smallest is removed at each step. Therefore, contains elements from and elements from and after post-processing. □
Theorem 2.
SFDM1returns a -approximate solution for FDM.
Proof. According to the results of Lemmas 1 and 2, we have , where . □
Theorem 3.
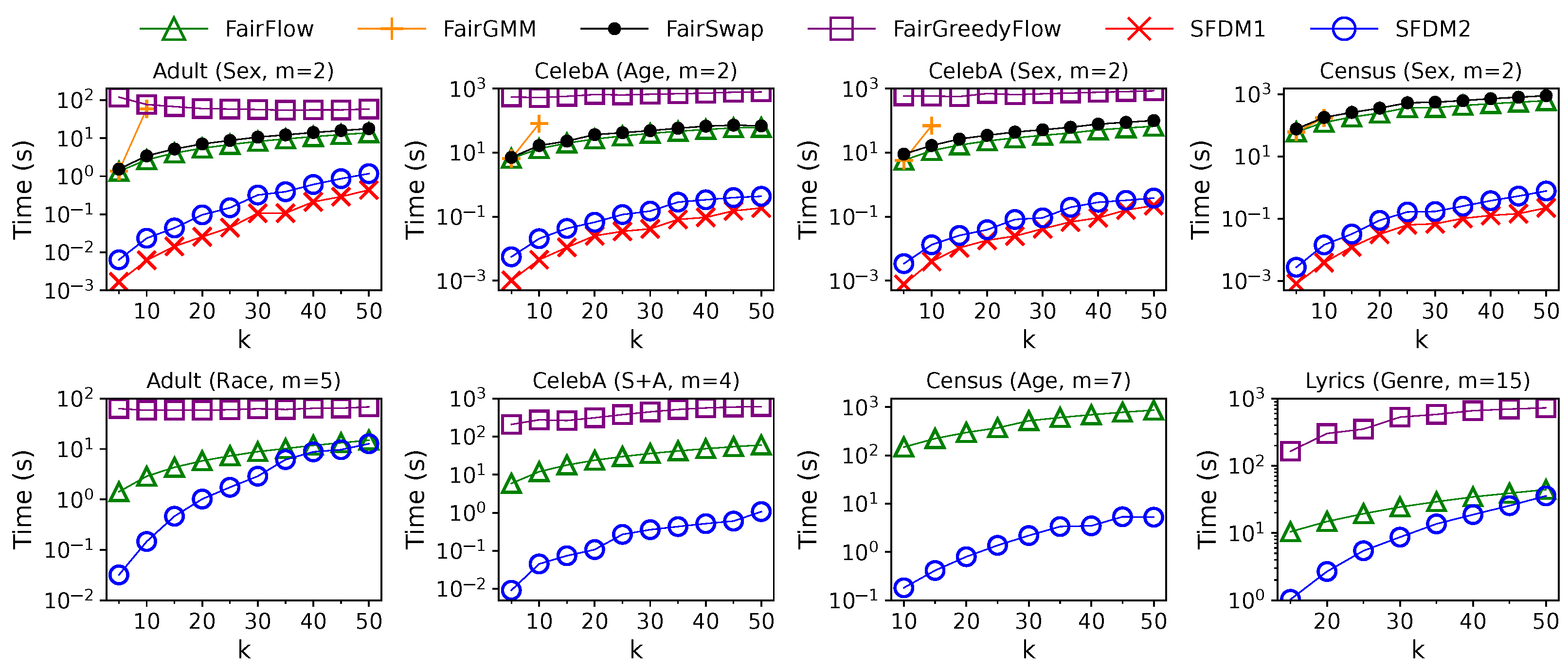
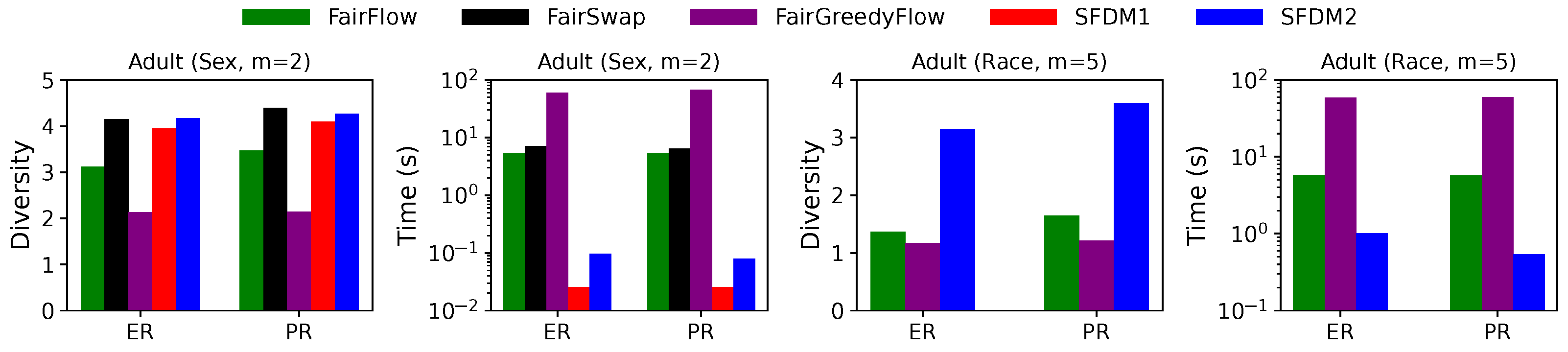
SFDM1stores elements in memory, takes time per element for stream processing, and time for post-processing.
Proof. SFDM1 keeps three candidates for each and elements in each candidate. Hence, the total number of stored elements is , since . The stream processing performs, at most, distance computations per element. Finally, for each in the post-processing, at most distance computations are performed to select the elements in that are to be added to . To find the elements that are to be removed, at most distance computations are needed. Thus, the time complexity for post-processing is as . □
Comparison with Prior Art: The idea of finding a solution and balancing it for fairness in
SFDM1 has also been used for
FairSwap [
17]. However,
FairSwap only works in the offline setting, which keeps the dataset in memory and requires random accesses for computation, whereas
SFDM1 works in the streaming setting, which scans the dataset in one pass and uses only the elements in the candidates for post-processing. Compared with
FairSwap,
SFDM1 reduces the space complexity from
to
and the time complexity from
to
at the expense of lowering the approximation ratio by a factor of
.
4.3. Fair Streaming Algorithm for General m
The detailed procedure of our streaming algorithm, which can work with an arbitrary
, called
SFDM2, is presented in Algorithm 3. Similar to
SFDM1, it also has two phases: stream processing and post-processing. In the stream processing (Lines 1–7), it utilizes Algorithm 1 to keep a group-blind candidate
and
m group-specific candidates
for all the
m groups. The difference from
SFDM1 is that the size constraint of each group-specific candidate for each group
i is
k instead of
. Then, after processing all elements in
X, a post-processing scheme is required to ensure the fairness of candidates. Nevertheless, the post-processing procedures are totally different from
SFDM1, since the swap-based balancing strategy cannot guarantee the validity of the solution with any theoretical bound. Like
SFDM1, the post-processing is performed on a subset
, where
has
k elements and
has at least
elements for each group
i (Line 8). For each
, it initializes with a subset
of
(Line 10). For an over-filled group
i, i.e.,
,
contains
arbitrary elements from
. For an under-filled or exactly filled group
i, i.e.,
,
contains all
elements from
. Next, new elements from under-filled groups should be added to
so that
is a fair solution. The method used to find the elements that are to be added is to divide the set
of elements in all candidates into a set
of clusters, which guarantees that
for any
and
(Lines 12–15), where
and
are two different clusters in
. Then,
is limited to contain, at most, one element from each cluster after new elements are added so that
. Meanwhile,
should still satisfy the fairness constraint. To meet both requirements, the problem of adding new elements to
is formulated as an instance of matroid intersection [
41,
42,
43], as will be discussed subsequently (Line 17). Finally, it returns
containing
k elements with maximum diversity after post-processing as the final solution for FDM (Line 18). An illustration of the post-processing procedure of
SFDM2 is given in
Figure 4.
| Algorithm 3 SFDM2 |
- Input:
Stream , distance metric d, parameter , size constraints () - Output:
A set s.t. , - ▹
Stream processing - 1:
- 2:
Initialize for every and - 3:
for all do - 4:
for all and do - 5:
Run Lines 3–6 of Algorithm 1 to update w.r.t. x - 6:
if then - 7:
Run Lines 3–6 of Algorithm 1 to update w.r.t. x - ▹
Post-processing - 8:
- 9:
for all do - 10:
For each group , pick elements arbitrarily from as - 11:
Let and - 12:
Create l clusters , each of which contains one element in - 13:
while there exist s.t. for some and do - 14:
Merge into a new cluster - 15:
- 16:
Let and be two matroids, where iff , and iff , - 17:
Run Algorithm 4 to augment such that is a maximum cardinality set in - 18:
return
|
Matroid Intersection: Next, we describe how to use matroid intersection for solution augmentation in
SFDM2. We define the first rank-
k matroid
based on the fairness constraint, where the ground set
V is
and
iff
,
. Intuitively, a set
S is fair if it is a maximal independent set in
. Moreover, we define the second rank-
l (
) matroid
on the set
of clusters, where the ground set
V is also
and
if
,
. Accordingly, the problem of adding new elements to
to ensure fairness is an instance of the matroid intersection problem, which aims to find a maximum cardinality set
for
and
. Here, we adopt Cunningham’s algorithm [
41], a well-known solution for the matroid intersection problem based on the augmentation graph in Definition 2.
Definition 2 (Augmentation Graph [
41]).
Given two matroids and , a set , such that , and two sets and , an augmentation graph is a digraph , where . There is an edge for each . There is an edge for each . There is an edge for each , , such that and . There is an edge for each , , such that and . Specifically, the Cunningham’s algorithm [
41] is initialized with
(or any
). At each step, it builds an augmentation graph
G for
,
, and
S. If there is no directed path from
a to
b in
G, then
S is already a maximum cardinality set. Otherwise, it finds the shortest path
from
a to
b in
G, and augments
S according to
. For each
, except
a and
b, add
x to
S; for each
, remove
x from
S. We adapt Cunningham’s algorithm [
41] for our problem, as shown in Algorithm 4. Our algorithm is initialized with
instead of
∅. In addition, to reduce the cost of building
G and maximize the diversity, it first adds the elements in
greedily to
until
. This is because a shortest path,
in
G, exists for any
, which is easy to verify from Definition 2. Finally, if
after the above procedures, the standard Cunningham’s algorithm will be used to augment
S to ensure the maximality of
S.
| Algorithm 4 Matroid Intersection |
- Input:
Two matroids , , distance metric d, initial set - Output:
A maximum cardinality set in - 1:
Initialize , , and - 2:
while do - 3:
and - 4:
for all do - 5:
if - 6:
for all do - 7:
if - 8:
Build an augmentation graph G for S - 9:
while there is a directed path from a to b in G do - 10:
Let be a shortest path from a to b in G - 11:
for all do - 12:
if - 13:
if - 14:
Rebuild G for the updated S - 15:
returnS
|
Theoretical Analysis: We prove that SFDM2 achieves an approximation ratio of for FDM. The high-level idea of the proof is to connect the clustering procedure in post-processing with the notion of matroid and then to utilize the geometric properties of the clusters and the theoretical results of matroid intersection for approximation. Next, we first show that the set of clusters has several important properties (Lemma 3). Then, we prove that Algorithm 4 can return a fair solution for a specific based on the properties of (Lemma 4). Finally, we analyze the time and space complexities of SFDM2 in Theorem 5.
Lemma 3.
The set of clusters has the following properties: (i) for any and (), ; (ii) each cluster C contains, at most, one element from and for any ; (iii) for any , .
Proof. First of all, Property (i) holds from Lines 12–15 of Algorithm 3, since all clusters that do not satisfy it have been merged. Then, we prove Property (ii) by contradiction. Let us construct an undirected graph for a cluster , where V is the set of elements in C and there exists an edge iff . Based on Algorithm 3, for any , there must exist some () such that . Therefore, G is a connected graph. Suppose that C contains more than one element from or for some . Let be the shortest path of G between x and y, where x and y are both from or . Next, we show that the length of is, at most, . If the length of is longer than , there will be a sub-path of where and are both from or , and this violates the fact that is the shortest. Since the length of is, at most, , we have , which contradicts the fact that , as they are both from or . Finally, Property (iii) is a natural extension of Property (ii): since each cluster C contains, at most, one element from and for any , C has, at most, elements. Therefore, for any two elements , the length of the path between them is, at most, m in G and . □
Lemma 4.
If , then Algorithm 4 returns a size-k subset , such that and .
Proof.
First of all, the initial
is a subset of
. According to Property (ii) of Lemma 3, all elements of
are in different clusters of
, and thus
. The theoretical results in [
41] guarantee that Algorithm 4 can find a size-
k set in
, as long as it exists. Next, we will show such a set exists when
. To verify this, we need to identify
clusters of
that contain at least one element from
for each
and show that all
clusters are distinct. Here, we consider two cases for each group
.
Case 1: For each , such that , we have for each . Given the optimal solution , we define a function f that maps each to its nearest neighbor in . For two elements in these groups, we have , , and . Therefore, . Since , . According to Property (iii) of Lemma 3, it is guaranteed that and are in different clusters. By identifying all the clusters that contain for all , we found clusters for each group such that . All the clusters that were found are guaranteed to be distinct.
Case 2: For all such that , we are able to find k clusters that contain one element from based on Property (ii) of Lemma 3. For such a group i, even though clusters have been identified for all other groups, there are still at least clusters available for selection. Therefore, we can always find clusters that are distinct from all the clusters identified by any other group for such a group .
Considering both cases, we have proven the existence of a size-k set in . Finally, for any set , we have according to Property (i) of Lemma 3. □
Theorem 4.
SFDM2is a -approximation algorithm for FDM.
Proof. Let be the smallest . It holds that (see Lemma 1). Thus, there is some in , such that , as for any . Therefore, SFDM2 provides a fair solution S, such that . □
Theorem 5.
SFDM2keeps elements in memory, takes time per element in the stream processing, and spends time for post-processing.
Proof. SFDM2 keeps
candidates for each
and
elements in each candidate. So, the total number of elements stored by
SFDM2 is
. Only two candidates are checked in streaming processing for each element and thus
distance computations are needed. In the post-processing of each
, we need
time to get the initial solution,
time to cluster
, and
time to augment the candidate using Lines 2–7 of Algorithm 4. The time complexity of Cunningham’s algorithm is
according to [
42,
43]. In sum, the overall time complexity of post-processing is
. □
Comparison with Prior Art: Existing methods have aimed to find a fair solution based on matroid intersection for fair
k-center [
21,
22,
44] and fair max–min diversity maximization [
17].
SFDM2 adopts a similar method to
FairFlow [
17] to construct the clusters and matroids. However,
FairFlow solves matroid intersection as a max-flow problem on a directed graph. Its solution is of poor quality in practice, particularly when
m is large. Therefore,
SFDM2 uses a different method for matroid intersection based on Cunningham’s algorithm, which initializes with a partial solution instead of an empty set for higher efficiency and adds elements greedily like
GMM [
39] for higher diversity. Hence,
SFDM2 has a significantly higher solution quality than
FairFlow in practice, though it has a slightly lower approximation ratio.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}