1. Introduction
Phonation is a complex bio-mechanical process wherein the glottal airflow, mediated by the muscles in the larynx and driven by an intricate balance of aerodynamic and mechanical forces across the glottis, maintains the vocal folds in a state of self-sustained vibration [
1,
2]. During this process, depending on the physical state of the vocal folds, their eigenmodes of vibration synchronize, or strive to do so. This self-sustained motion of the vocal folds during phonation is highly sensitive to perturbations caused by many possible influencing factors, which may affect the speaker during speech production. In recent years, there has been a surge of interest in building voice-based diagnostic aids—computational models based on artificial intelligence and machine learning that can infer the speaker’s state (and thereby the factors that are affecting the speaker) from voice. Such applications can benefit greatly from being able to deduce the fine-level nuances in the motion of the vocal folds, and being able to measure the response to various perturbing factors to infer their nature. However, doing this using traditional methods on an individual basis for each speaker is very difficult. Traditional methods to observe and record vocal fold oscillations (VFOs) are based on actual physical measurements taken using various instruments in clinical settings, e.g., [
3,
4,
5].
The primary focus of this paper is to derive the VFOs for a speaker directly from recorded voice signals, alleviating the need for taking physical measurements. The solution we propose is an analysis-by-synthesis approach, based on physical models of phonation. We propose a methodology to deduce the parameters of a chosen phonation model from a speaker’s voice recording, which can then be substituted into a VFO model to obtain speaker-specific solutions, which represent the vocal fold oscillations of the speaker.
In the paragraphs below, we first review some relevant facts about the process of phonation. In the sections that follow, we present our proposed methodology in two stages: in the first, we show how we can infer the parameters of a physics-based model of phonation from measurements of glottal excitation. Since the parameters of such models represent the physical properties of the speaker’s vocal folds, using them to obtain solutions to the models gives us an estimate of the speaker’s VFOs. We subsequently show how to extend the model to include the physics of mucosal wave propagation in the vocal tract, and propose a forward-backward algorithm to estimate the parameters of the joint model. These can then be used in the corresponding phonation model to obtain its solutions.
Later on, we also explain how the solutions of these models (which are the deduced VFOs) can be characterized from a dynamical systems perspective to derive discriminative information in the form of features that are useful for classification tasks.
In this context, it is important to note at the outset that the models we use to demonstrate our methodology are simple and well-established models in the literature. It is not the goal of this paper to propose new models of phonation, but rather to propose a novel methodology to derive their parameters from speech signals, so that they can be solved to yield VFOs on a speaker-by-speaker basis. The main contribution of this paper lies in the derivation of the parameters of these models, and their individualized VFO solutions. The viability of these solutions is demonstrated experimentally using classification experiments.
1.1. The Bio-Mechanical Process of Phonation
By the myoelastic-aerodynamic theory of phonation, the forces in the laryngeal region that initiate and maintain phonation relate to (a) pressure balances and airflow dynamics within the supra-glottal and sub-glottal regions and (b) muscular control within the glottis and the larynx. The balance of forces necessary to cause self-sustained vibrations during phonation is created by physical phenomena such as the Bernoulli effect and the Coandǎ effect [
6,
7,
8].
Figure 1 illustrates the interaction between these effects that is largely thought to drive the oscillations of the vocal folds.
The process of phonation begins with the closing of the glottis. This closure is voluntary and facilitated by the laryngeal muscles. Once closed, the muscles do not actively play a role in sustaining the vibrations. Glottal closure is followed by a contraction of the lungs which pushes out air and causes an increase in pressure just below the glottis. When this subglottal pressure crosses a threshold, the vocal folds are pushed apart, and air rushes out of the narrow glottal opening into the much wider supra-glottal region, creating negative intra-glottal pressure (with reference to atmospheric air pressure) [
9].
The exact physics of the airflow through the glottis during phonation is well studied, e.g., [
2,
10,
11,
12,
13,
14]. The current understanding from these, from the airflow perspective, is that the glottis forms a flow separation plane. The air expansion in this region and the low pressure created in the vicinity of the glottis through the Coandǎ effect-induced entrainment cause a lowering of pressure close to the glottis and a net downward force on the glottis. At the same time, lowered pressure in the glottal region due to the Bernoulli effect that ensues from the high-velocity air volume flow through the glottis exerts a negative force on the glottis. The negative Bernoulli pressure causes elastic recoil, causing it to begin to close again. The closing reduces the volume flow through the glottis, diminishing the downward forces acting on it. Increased pressure build-up in the sub-glottal region causes the glottis to open again. This chain of oscillations continues in a self-sustained fashion throughout phonation until voluntary muscle control intervenes to alter or stop it or as the respiratory volume of air in the lungs is exhausted.
1.2. General Approaches to Phonation Modeling
Physical models of phonation, e.g., [
9,
11,
15,
16,
17,
18,
19,
20], attempt to explain this complex physical process using relations derived from actual physics, especially aerodynamics and the physics of mechanical structures.
For modeling purposes, we note that phonation is not the only source of excitation of the the vocal tract in producing speechsounds, which comprise both voiced and unvoiced sounds. However, phonation is indeed the primary source of excitation of the vocal tract in the production of voiced sounds, wherein the oscillation of the vocal folds modulates the pressure of the airflow to produce a (quasi-) periodic glottal flow wave at a fundamental frequency (the pitch), which in turn results in the occurrence of higher order harmonics. The resultant glottal flow further excites the vocal tract, which comprises the laryngeal cavity, the pharynx, and the oral and nasal cavities, to produce individual sounds. The vocal tract serves as a resonance chamber that produces formants. The identities of the different sounds produced within it are derived from these resonances, which in turn are largely dependent on the configurations of the vocal tract specified by their time-varying cross-sectional area.
From this perspective, phonation modeling has typically involved the modeling of two sub-processes: the self-sustained vibration of the vocal folds, and the propagation of the resultant pressure wave through the vocal tract [
21]. Each sub-process model has associated parameters that determine the model output, given an input.
Following the above division of the process, we identify the two following model types, each modeling one of the sub-processes: (i) Vocal fold oscillation (VFO) models (also called vocal folds models, or oscillation models), and (ii) vocal tract (VT) models.
The VFO models describe the vibration of vocal folds and their aerodynamic interaction with airflow. Such models are of four broad types: one-mass models, e.g., [
2,
16,
22,
23,
24], two-mass models, e.g., [
11,
15], multi-mass models [
18], and finite element models, e.g., [
17]. Each of these has proven to be useful in different contexts. The
VT models describe the interaction of the glottal pressure wave with the vocal tract, which is turn has been described in the literature by varied models, such as statistical models, e.g., [
25], geometric models, e.g., [
26] and biomechanical models, e.g., [
27].
In addition, different models are also applied to describe the aero-acoustic interaction of the glottal airflow and the vocal tract. Some examples of these are reflection-type line analog models and transmission line circuit analog models, e.g., [
28], hybrid time-frequency domain models, e.g., [
29] and finite-element models, e.g., [
30].
2. The Problem of Parameter Estimation
Each of the models mentioned in
Section 1.2 includes a set of parameters that determine its
state, and
output, given an input. For instance, given the parameters for a VFO model, the glottal flow waveform can be determined; given the glottal flow waveform as an input, and the parameters for a VFO model, the acoustic signal can be determined.
The problem we tackle in this paper is the inverse problem: given a model output, we must estimate the model parameters from it.
This can be of great practical use. For example, with speaker-specific parameter setting, the output of these models can be used as a proxy for the actual vocal fold motion of the corresponding speaker. To obtain the parameters of such models, the traditional solution has been to take actual physical measurements of the vocal fold oscillations, or of the glottal flow using techniques such as high-speed videostroboscopy, as mentioned in
Section 1. This is not always feasible.
On the other hand, the inverse problem of parameter estimation of phonation models is quite difficult to solve through purely computational means. For example, in order to estimate the parameters of a vocal tract (VT) model, one must take into account the vocal tract coupling, the effect of the lossy medium that comprises the walls of the vocal tract, lip radiation, etc. Without serious approximations, the inverse problem in this case becomes eventually intractable. Some approaches simplify the solution by discretizing the vocal tract as a sequence of consecutive tubes of varying cross-sectional area, or with a mesh-grid. However, these approximations invariably increase the estimation error.
This paper proposes a methodology for solving the inverse problem of phonation models through purely computational means. As mentioned earlier, the methodology follows an analysis-by-synthesis approach. We explain this by first reviewing our previously proposed Adjoint Least Squares Estimation (ADLES) algorithm [
31] that estimates the parameters of a VFO model by minimizing the error between a reference glottal flow waveform and the signal generated by the physical VFO model. We then describe our proposed ADLES-VFT algorithm to estimate the parameters of a
joint VFO and VT model (also called a body-cover model). Instead of comparing the model-generated excitation at the glottis to a reference glottal flow, the flow is propagated through the vocal tract to generate a signal at the lips, which is compared to a recorded voice signal which is used as a reference. The algorithm proposed iteratively re-estimates the model parameters by minimizing the error between the reference voice sample and this generated signal.
Once estimated, these parameters are used with the VFO model to generate the speaker’s VFOs.
3. Vocal Folds, Vocal Tract and Joint Models
In this section we describe the VFO and VT models that we use as examples in this paper. We also explain the formulation of the joint model that we ultimately use to solve the inverse problem of parameter estimation.
3.1. The VFO Model
A schematic illustration of a general mass-spring oscillator model for the vocal folds is shown in
Figure 2. This is used to model the phonation process as described below.
One-mass models describe the vibration of the vocal folds as that of a single mass-damper-spring oscillator.
where
x is lateral displacement of a mass
M,
B and
K are damping and stiffness coefficients, respectively,
f is the driving force, and
t is time [
2]. The driving force is velocity-dependent and can be estimated by Bernoulli’s energy law:
where
is the mean glottal pressure,
is sub-glottal pressure,
is air density, and
v is the air particle velocity. The kinetic pressure in the supra-glottal region is neglected [
2].
Other models, namely two-mass, multi-mass and finite element models can also be used as the basis for the VFO model, and are described briefly in the
Appendix A for reference.
For our paper, we adopt the version of the one-mass model of the vocal folds proposed in [
24], illustrated in
Figure 3. This is an asymmetric body-cover model which models the left and right vocal folds individually as one-mass components of a coupled dynamical system. It incorporates an asymmetry parameter, which can emulate the asymmetry in the vibratory motions of left and right vocal folds, and hence is also ideally suited to modeling pathological or atypical phonation [
32].
The key assumptions made in formulating this model are:
- (a)
The degree of asymmetry is independent of the oscillation frequency;
- (b)
The glottal flow is stationary, frictionless, and incompressible;
- (c)
All subglottal and supraglottal loads are neglected, eliminating the effect of source-vocal tract interaction;
- (d)
There is no glottal closure and hence no vocal fold collision during the oscillation cycle;
- (e)
The small-amplitude body-cover assumption is applicable (see definition below).
Assumption 1 (Body-cover assumption).
The body-cover assumption assumes that a glottal flow-induced mucosal wave travels upwards within the transglottal region, causing a small displacement of the mucosal tissue, which attenuates down within a few millimeters into the tissue as an energy exchange happens between the airstream and the tissue [2]. This assumption allows us to represent the mucosal wave as a one-dimensional surface wave on the mucosal surface (the cover) and treat the remainder of the vocal folds (the body) as a single mass or safely neglect it. As a result, the oscillation model can be linearized, and the oscillatory conditions are much simplified while maintaining the model’s accuracy.
In the one-mass asymmetric model proposed in [
24], with reference to
Figure 3, the center-line of the glottis is denoted as the
z-axis. At the midpoint (
) of the thickness of the vocal folds, the left and right vocal folds oscillate with lateral displacement
and
, resulting in a pair of coupled Van der Pol oscillators:
where
is the coefficient incorporating mass, spring and damping coefficients,
is the glottal pressure coupling coefficient, and
is the asymmetry coefficient. For a male adult with normal voice, the reference values for the model parameters (from clinical measurements) are usually approximately set to
,
and
.
3.2. The VT Model
The literature describes a number of different approaches to modeling the vocal-tract, including bio-mechanical models, statistical models, and geometric models. For reference, they are described briefly in the
Appendix B.
In our work we use an acoustic wave propagation model described by PDEs for the vocal tract. The vocal tract itself is represented as tube of length
L, beginning at the glottis and ending at the lips. Representing the distance along the central axis of the vocal tract as
x,
(where
at the glottis and
at the lips) and the time-varying volume velocity of air at any position
x along the vocal tract as
, it can be shown that the PDE that describes
is given by
where
represents the
vocal tract profile, which models the characteristics of the vocal tract, including the effect of the nonuniform yielding wall on the acoustic flow dynamics, the effect of vocal tract coupling, lip radiation, etc., and must also be estimated by our algorithm. The derivation of Equation (
4) is given in
Appendix B. Note that if the vocal tract is assumed to be a rigid tube
and Equation (
4) reduces to the well-known Webster-Horn equation [
33]. In deriving Equation (
4) we have assumed a static vocal tract, i.e., that the cross-sectional area
of the vocal tract at any position
x is constant. This assumption is valid during phonation, in particular during the steady state of sustained phonation; however our solution can also be extended to consider time-varying vocal tracts
, although we have not done so in this paper.
The oscillation of the vocal folds results in the movement of air with a time-varying volume velocity
at the glottis. The vocal tract modulates this to result in the volume velocity
at the lips and the corresponding pressure wave
, where [
34]
where
is the opening area at the lip,
c is the speed of sound, and
is the ambient air density.
4. Estimation of Model Parameters: Solving the Inverse Problem
Our objective is to derive vocal fold oscillations during phonation directly from the speech signal. In order to do so, we will utilize the VFO and VT models.
The
VFO model represents the actual dynamics of the vocal folds. Given the model parameters, which are
,
and
for the coupled one-mass model of Equation (
3), it can be used to compute the vocal fold oscillations and the volume velocity of air at the glottis. The
VT model represents the dynamics of the vocal tract. Given an excitation (at the glottis), it can be used to compute the pressure wave at the lips, which manifests as sound.
Ours is the inverse problem: given the the pressure wave at the output of the vocal tract (i.e., the recorded speech signal) we must estimate the VFO parameters that could generate it. This is an analysis-by-synthesis problem: in order to analyze the given voice signal, we must identify the model parameters that synthesize the closest (in a metric sense) facsimile to it.
We present the solution in a two-step manner. In the first, given the actual excitation of the vocal tract to produce the voice signal, the parameters of the VFO model are estimated to minimize the error between its output and the reference excitation signal. We refer to this as the
backward approach (and the corresponding estimation as the “backward” problem), since the reference excitation signal itself must first be derived by passing the voice signal through an inverse model of the vocal tract, i.e., “backward” through the vocal tract. We have previously described our solution to the backward problem in [
31], and restate it in
Section 4.1 for completeness.
The second, more complete solution considers the joint model, i.e., both the motions of the vocal folds and the propagation of the resulting air flow (the excitation) through the vocal tract. The model parameters are estimated by comparing the signal produced at the lips by the joint model to the recorded voice signal. We refer to this as the “forward-backward” approach since this requires forward propagating the output of the VFO through the VT model, prior to applying the backward approach. The solution to this problem is the primary contribution of this paper.
The two approaches are illustrated in
Figure 4.
Once estimated, the VFO model parameters can be used to compute the oscillations of the vocal folds and their phase-space trajectories.
4.1. Estimating VFO Parameters from the Excitation Signal: The Backward Approach (ADLES)
As the first step, we describe the backward problem: how to derive the VFO model parameters that best explain the glottal excitation for a given phonated signal. We use the approach proposed in [
31]—we estimate the VFO model parameters to minimize the error between the volume velocity of air predicted by the model and a reference signal representing the actual glottal excitation to the vocal tract. If the VFO model were to be considered in isolation, this reference could be obtained through actual physical measurements, e.g., through photography [
5], physical or numerical simulations [
7,
17], or by inverse filtering the speech signal using a technique such as [
35] (the approach used in [
31]).
For the purpose of our discussion in this section, however, we do not specify where this reference excitation is obtained from, since the estimation of VFO model parameters from a given glottal excitation is only a waypoint towards estimation from the joint model that includes both the VFO and VT components. As we will see in
Section 4.2, this does not in fact require explicit knowledge of the reference signal at the glottis.
Let
be the reference signal representing the
true air-volume velocity at the glottis that excites the vocal tract. The volume velocity of air
(we remind the reader that
) at the glottis can also be computed from the vocal fold opening at the glottis as
where
is the half glottal width at rest,
is the complete glottal opening,
d is the length of the vocal fold, and
is the air particle velocity at the midpoint of the vocal folds.
We assume that the movement of the vocal folds follows the VFO model of
Section 3.1. Correspondingly,
and
must obey Equation (
3), subject to boundary conditions. The model parameters
,
and
can hence be computed to minimize the difference between the air volume velocity
predicted by the model and the reference
.
We define the instantaneous
residual R as the error between
and
:
The overall
error between
and
is given by the integral
where
represents the parameters of the VFO model, and
T represents the complete length of the reference signal.
The actual estimation can now be stated as
where
and
are constants representing the quiescent positions of the vocal folds, and the folds are assumed to be at rest prior to the onset of phonation. For the computation we set
to a typical value of 0.1 cm. The length of the vocal folds
d may be set to 17.5 mm (which is within the range of normal lengths for both male and female subjects), and the air particle velocity
to 5000 cm/s [
2].
Note that given
and
the differential equations of model Equations (11)–(15) (the constraints) can be solved by any ODE solver to obtain
and
. So, in principle, we could solve the constrained optimization problem of Equation (
9)–(15) by a grid search over
to identify the specific values that minimize the squared error of Equation (
8). This would, however, be highly inefficient.
Instead we propose the ADLES (“ADjoint LEast Squares”) algorithm, which restates the constraints (11)–(15) as Lagrangians on the objective, and derives a gradient descent solution. The detailed derivation of ADLES is given in
Appendix C. We summarize the key steps below.
Incorporating constraints (11)–(15) into the objective, we define the Lagrangian:
where
,
,
,
and
are Lagrangian multipliers. Note that
and
are also functions of time (we have not explicitly shown the “
” above for brevity of notation).
We obtain the Lagrangian parameters
and
as the solution to the following equations: For
:
with initial conditions at
:
Note that given
,
,
,
and
, Equations (
17)–(24) represent a differential-algebraic system of equations and can be solved by any DAE solver to obtain
and
.
Given
,
,
and
, the derivatives of
w.r.t.
,
and
can now be obtained as:
The derivatives from Equation (
25) are plugged into a gradient descent update rule for the model parameters:
where
is the step-size.
The overall ADLES algorithm is summarized in Algorithm 1:
| Algorithm 1 ADLES algorithm |
- 1:
Initialize , and - 2:
while F not converged do ▹ Iterate until the error converges - 3:
Solve (11)–(10) with initial conditions (12)–(15), using the current estimates of , and , obtaining , , and . - 4:
Solve ( 17)–(20) with the initial conditions ( 21)–(24), using the current values of , , , and , obtaining , , and . - 5:
Compute , and from Equation ( 25). - 6:
Update , and with ( 26). - 7:
end while
|
4.2. Estimating VFO Parameters from the Speech Signal: The Forward-Backward Approach (ADLES-VFT)
The backward approach, solved by the ADLES algorithm in
Section 4.1, derives the VFO parameters by minimizing the error between the output of the VFO model
and the glottal excitation
. However, in general,
is not available, and this error cannot actually be computed.
Instead, in the forward-backward approach, we further
propagate the generated excitation
through the vocal tract, represented by the VT model of Equation (
4) to obtain a signal
at the lips. This is the output of the joint VFO and VT models. We compute the error between the generated signal
and the air velocity measurement derived from the recorded voice signal, which
is available, and propagate this error backward through the vocal tract, to obtain the error at the glottis. The VT and VFO model parameters are estimated to minimize this error. Thus, the algorithm itself proceeds through iterations of two steps: a forward step in which the VFO-generated excitation is propagated through the VT model to generate an output signal, and a backward step in which the error between the generated signal and the recorded speech is propagated backward through the VT to adjust the model parameters. We explain the entire procedure below.
The recorded voice signal is, in fact, a pressure wave and records the pressure wave emitted at the lips. Let
be the measured acoustic pressure at the lip. The corresponding volume velocity is given by [
34]
is now our reference signal at the lips to which
must be matched, in order to estimate model parameters.
The propagation of
through the vocal tract is assumed to follow the dynamics of Equation (
4). Let
be the nonlinear operator representing acoustic wave propagation through the vocal tract from the glottis to the lip. The subscript
f in
represents the vocal-tract profile
in Equation (
4) and indicates the dependence of
on
. Thus the vocal-tract output
is given by
Our objective is to minimize the difference between the measured volume velocity
and the predicted volume velocity
near the lip subject to constraint that the dynamics of the vocal folds must follow the VFO model of Equation (
3). Note that the parameters of the joint model include the VFO model parameters
,
and
, and the vocal tract profile
required by the VT model. Although we only require the VFO model parameters to determine vocal fold oscillation, the minimization must be performed against all of these. Thus the estimation problem becomes
subject to
where, as before, (
30) and (31) represent the asymmetric vocal folds displacement model (
3), I.C. stands for initial condition, and
Cs are constants. The minimization is performed against the complete set of parameters of the joint VFO-VT model, i.e.,
,
,
and
.
Unlike in Equations (11)–(15), this cannot be solved, even in principle, by simply scanning for the optimal , and , since is characterized by which is also unknown and must be determined.
To solve the optimization problem of (
29)–(35), we derive an efficient gradient-descent solution which we term the ADLES-VFT algorithm. The essential steps of the solution are given below. The details of the derivation are in
Appendix D.
4.2.1. Forward Pass
First, note that, as before, the constraint Equations (
30)–(35) are ordinary differential equations with initial conditions that, given
,
and
, can be solved by any ODE solver. The solution will give us the VFO model generated glottal excitation
.
Next, we propagate the generated excitation
through the VT model. For this, we must solve
where B.C. stands for boundary condition, and I.C. stands for initial condition. The vocal tract is assumed to be circular at the glottis and the lips. Here,
is the outward unit normal to the vocal tract boundary
, at the glottis.
Equations (
36)–(40) represent a set of partial differential equations. The boundary conditions relate to the air volume velocity at the glottal end of the vocal tract. The initial conditions relate to air volume velocity at the initial time,
, when the generated glottal signal
enters the vocal tract. Given
and
(
36)–(40) can be solved using a PDE solver. In our work we use the finite-element method described in
Appendix E.
Solving (
36)–(40) gives us
at all positions
and time
. In the process, it also gives us
.
4.2.2. Backward Pass
The backward pass updates all model parameters including the VT term , and VFO parameters based on the error at the output.
We denote the estimation residual as:
We must propagate this residual backward through the VT model. To do so, we use a time reversal technique [
36] and backpropagate the difference (
41) into the vocal tract, which gives:
where
z is the time reversal of
u. Note that the boundary conditions and initial conditions in (
42)–(45) are now defined at the lip, and the equation itself propagates backward through the vocal tract.
As before, Equations (
42)–(45) can be solved by the finite-element method of
Appendix E to give us
. The gradient update rule for
is then obtained as
where
is a learning rate parameter (see
Appendix D).
As in the case of the backward approach of
Section 4.1 we define a residual
Note that unlike in
Section 4.1 the residual in Equation (
47) is defined at the lips, rather than at the glottis. As before, we can define the total squared residual error as
where
are the parameters of the vocal folds model (
3).
F must be minimized with respect to
, subject to the constraints imposed by the VFO model.
Once again, as in
Section 4.1 we fold in the constraints into the objective through Lagrangian multipliers as
where
,
,
and
are multipliers, and
and
are themselves functions of time. Optimization requires minimization of
with respect to
,
and
.
This leads us (
Appendix D) to the following set of equations for
and
:
with initial conditions (at
, i.e., at the lips):
Given
,
and
Equations (
50)–(57) represent a set of differential-algebraic equations and can be solved with a DAE solver.
We finally obtain the derivative of
F w.r.t.
,
and
(represented below as
,
and
, respectively) as
The gradient descent update rules for the VFO model parameters are finally obtained as
4.2.3. The ADLES-VFT Algorithm Summarized
The overall ADLES-VFT algorithm for solving the parameter estimation problem (
29)–(35) is summarized in Algorithm 2.
In this solution, we have adopted the simple gradient descent method. However, other gradient-based optimization approaches, such as the conjugate gradient method, can also be used.
We note here that Algorithm 2 requires several terms to be specified. In our implementation, the quiescent positions of the vocal folds,
and
were set to 0. We initialize
—these values were empirically found to work best.
is initialized to 0. This effectively initializes Equation (
4) to the Webster Horn equation. The step sizes
and
are all adaptively set to
, and
is set to 1. The actual objective minimize, Equation (
29), requires scaling
by
prior to comparison to
. In practice, since
is derived from a voice signal recorded at a distance from the lips, the unknown transmission loss between the lips and the microphone must also be considered. To deal with this, we simply normalize both sequences to 0 mean and unit variance, and do not apply any additional scaling.
| Algorithm 2 ADLES-VFT algorithm |
- 1:
Initialize , , and . - 2:
while F not converged do ▹ Iterate until the error converges - 3:
Solve ( 30)–(31) with initial conditions (32)–(35) with an ODE solver, using the current estimates of , and , obtaining , , and and . - 4:
Using current estimate of and , solve the forward propagation model ( 36)–(40) for with a PDE solver, e.g., the finite-element method of Appendix E. - 5:
Calculate the estimation difference using ( 41). - 6:
Using the current estimate of and , solve the backward propagation model ( 42)–(45) for with a PDE solver ( Appendix E). - 7:
Update using ( 46). - 8:
Solve ( 50)–(53) with initial conditions ( 54)–(57) using a DAE solver to obtain , , and . - 9:
Compute ( 58)–(60) through numerical integration to obtain derivatives , and from - 10:
Update , and with (63). - 11:
end while
|
In the next section, we demonstrate the usefulness of the ADLES and ADLES-VFT algorithms experimentally.
5. Experimental Results and Interpretation
Unfortunately, until the time of writing this paper, we could not obtain actual electroglottographic measurements or video data of vocal fold motion to compare our derived VFOs to. However, from a computational perspective the algorithms proposed can still be validated in different ways. We explain these below.
5.1. Validation 1
Our first validation approach is to use the proxy of showing that the solutions obtained are indeed discriminative of fine-level changes in glottal flow dynamics of the phonation process.
Having recovered the model parameters by our backward or forward approach, we can solve the models to obtain the time-series corresponding to the oscillations of each vocal fold, as estimated from recorded speech samples. We note that the models we have discussed in this paper are essentially dynamical systems represented by coupled nonlinear equations that may not have closed-form solutions, but can be numerically solved.
To interpret these in discriminative settings, we can utilize some well-established methods for characterizing dynamical systems, borrowing them from chaos theory and other areas of applied mathematics (e.g., flow, orbit, attractor, stability, Poincaré map, bifurcation, Lyapunov exponents, etc.). These are described in
Appendix F.
Interpreting a System’s Phase Portraits Using Its Bifurcation Map
Appendix F describes the concepts and tools used to study the behaviors (e.g., flow, orbit, attractor, stability, Poincaré map, bifurcation) of nonlinear dynamical systems such as Equation (
3). The phase space of the system in Equation (
3) (representing vocal fold motion) is four-dimensional and includes states
.
For this nonlinear system, it is expected that attractors such as limit cycles or toruses will appear in the phase space. Such phenomena are consequences of specific parameter settings. Specifically, the parameter
determines the periodicity of oscillations; the parameter
and
quantify the asymmetry of the displacement of left and right vocal folds and the degree to which one of the vocal folds is out of phase with the other [
24,
37]. We can visualize them by plotting the left and right displacements and the phase space portrait.
The coupling of right and left oscillators is described by their
entrainment; they are in
n:
m entrainment if their phases
,
satisfy
where
are integers, and
C is a constant [
24]. Such entrainment can be revealed by the Poincaré map, where the number of trajectory crossings of the right or left oscillators within the Poincaré section indicates the periodicity of its limit cycles. Therefore, their ratio represents the entrainment. We can use the bifurcation diagram to visualize how the entrainment changes with parameters. An example of such a bifurcation diagram is shown in
Figure 5 [
15,
37].
As we will see later (and as indicated in
Figure 5), model parameters can characterize voice pathologies, and these can be visually evident in in phase portraits and bifurcation plots.
We use the backward algorithm to estimate the asymmetric model parameters for clinically acquired pathological speech data. The data comprise speech samples collected from subjects suffering from three different vocal pathologies. Our goal is to demonstrate that the individualized phase space trajectories of the asymmetric vocal fold model are discriminative of these disorders.
The data used in our experiments is the FEMH database [
38]. It comprises 200 recordings of the sustained vowel
/a:/. The data were obtained from a voice clinic in a tertiary teaching hospital, and the complete database includes 50 normal voice samples (control set) and 150 samples that represent common voice pathologies. Specifically, the set contains
samples for glottis neoplasm, phonotrauma (including vocal nodules, polyps, and cysts), and unilateral vocal paralysis, respectively.
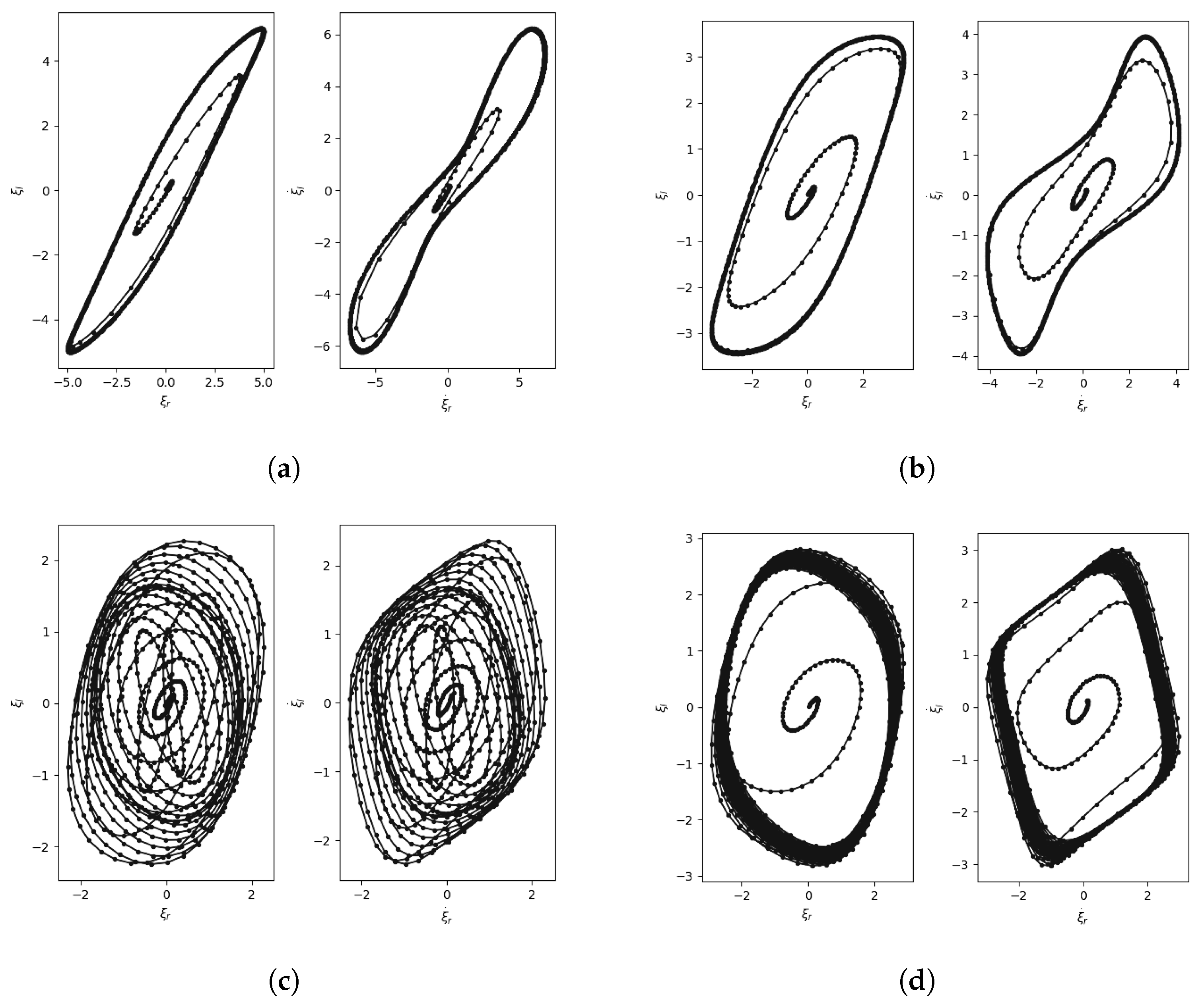
Figure 6 shows some phase portraits showing the coupling of the right and left vocal folds obtained using the ADLES solution. We observe that the attractor behaviors are typical and even visually differentiable for different types of pathologies.
Table 1 shows the results of deducing voice pathologies by simple thresholding of parameter ranges. Specifically, the ranges of model parameters in each row of
Table 1 correspond to regions in the bifurcation diagram in
Figure 5. Each region has distinctive attractors and phase entrainment, representing distinct vocal fold behaviors and thereby indicating different voice pathologies. By extracting the phase trajectories for the speech signal and, thereby, the underlying system parameters, the ADLES algorithm can place the vocal-fold oscillations in voice production on the bifurcation diagram and thus deduce the pathology.
5.2. Validation 2
Our second validation approach is to compare the excitation signal obtained through inverse filtering with the glottal flow signal (VFO) obtained through the backward or forward-backward algorithm. The rationale behind this is that within reasonable bounds of error, the glottal flow signal obtained through our model is expected to conform to the oscillation patterns seen in the excitation signal for each speaker.
Figure 7 shows the glottal flow obtained by inverse filtering and those obtained by the asymmetric model with the parameters estimated by our ADLES method. We observe consistent matches, showing that the ADLES algorithm does achieve its objectives in individualizing the asymmetric model to each speaker instance.
5.3. Validation 3
Our third validation approach is to compare the estimation precision of the backward approach and the forward-backward approach.
Table 2 shows the mean absolute error (MAE) of calculating glottal flows and parameters for four voice types (normal, neoplasm, phonotrauma, vocal palsy) obtained by backward (ADLES) and forward-backward (ADLES-VFT) algorithms. The glottal flows obtained by inverse filtering the speech signals are treated as ground truths. Since there is no ground truth for model parameters, we treat the parameters obtained by ADLES as ground truth. These results suggest that our forward-backward algorithm can effectively recover the vocal tract profile, glottal flow, and model parameters.
5.4. Validation 4
Our fourth validation comes indirectly from prior studies. Information from a dynamical systems perspective can give insights about the underlying mechanisms and principles that govern the vocal fold dynamics. Examples of features in this category are recurrence analysis features, Lyapunov exponents, Hurst exponents, etc. These are mentioned in
Appendix F.
Some of these features have been used in real-world applications and proven to be effective. For example, in [
39], the authors hypothesize that since COVID-19 impairs the respiratory system, effects on the phonation process could be expected, and signatures of COVID-19 could manifest in the vibration patterns of the vocal folds. In this paper, features have been derived from a signal processing perspective.
This study used the ADLES method to estimate the asymmetric vocal folds model parameters. It further used the parameters and estimation residuals as features to other binary classifiers such as logistic regression, support vector machine, decision tree, and random forest, achieving around 0.8 ROC-AUC (area under the ROC curve) in discriminating positive COVID-19 cases from negative instances, on clinically collected and curated data. The data used contained recordings of extended vowel sounds from affected speakers and control subjects. The authors also discovered that COVID-19 positive individuals display different phase space behaviors from negative individuals: the phase space trajectories for negative individuals were found to be more regular and symmetric across the two vocal folds, while the trajectories for positive patients were more chaotic, implying a lack of synchronization and a higher degree of asymmetry in the vibrations of the left and right vocal folds.
In a companion study, the authors in [
40] used the ADLES-estimated glottal flows as features to CNN-based two-step attention neural networks. The neural model detects differences in the estimated and actual glottal flows and predicts two classes corresponding to COVID-19 positive and negative cases. This achieved 0.9 ROC-AUC (normalized) on clinically collected vowel sounds. Yet another study used higher order statistics derived from parameters, and Lyapunov and Hurst exponents derived from the phase space trajectories of the individualized asymmetric models, to detect Amyotrophic Lateral Sclerosis (ALS) from voice with high accuracy (normalized ROC-AUC of 0.82 to 0.99) [
41].
6. Conclusions and Future Directions
In this paper we have presented a dynamical system perspective for physical process modeling and phase space characterization of phonation, and proposed a framework wherein these can be derived for individual speakers from recorded speech samples. The oscillatory dynamics of vocal folds provide a tool to analyze different phonation phenomena in many real-world task settings. We have proposed a backward approach for modeling vocal fold dynamics, and an efficient algorithm (the ADLES algorithm) to solve the inverse problem of estimating model parameters from speech observations. Further, we have integrated the vocal tract and vocal folds models, and have presented a forward-backward paradigm (the ADLES-VFT algorithm) for effectively solving the inverse problem for the coupled vocal fold-tract model. Extensions of these approaches can use other physical models of voice production, and other physical processes including phonation.
We have shown that the parameters estimated by these algorithms allow the models to closely emulate the vocal fold motion of individual speakers. Features and statistics derived from the model dynamics are (at least) discriminative enough for use in regular machine-learning based classification algorithms to accurately identify various voice pathologies from recorded speech samples. In future, these approaches are expected to be helpful in deducing many other underlying influences on the speaker’s vocal production mechanism.
The phase space characterization presented in this paper is based on phase space trajectories (a topological perspective)—the left and right vocal fold oscillations, velocities or accelerations. Measurements can also be performed from statistical, signal processing, information-theoretic and other perspectives. Another direction of suggested research is characterizing the phase space from algebraic perspectives. We can recast the study of the topological structures of the phase space to the study of its algebraic constructs, such as homotopy groups and homology/cohomology groups, which are easier to classify. For example, algebraic invariants can characterize the homeomorphisms between phase spaces (e.g., evolution maps, Poincaré maps) and reveal large-scale structures and global properties (e.g., existence and structure of orbits). We can also build upon the deep connection between dynamical systems and deep neural models. We can study deep learning approaches for solving and analyzing dynamical systems, and explore the integration of dynamical systems with deep neural models to analyze and interpret the behaviors of the vocal folds. We delegate these explorations to future work.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}