
Utility–Privacy Trade-Offs with Limited Leakage for Encoder
Department of Computer and Network Engineering, The University of Electro-Communications, 1-5-1 Chofugaoka, Chofu 182-8585, Tokyo, Japan
*
Author to whom correspondence should be addressed.
†
These authors contributed equally to this work.
Entropy 2023, 25(6), 921; https://doi.org/10.3390/e25060921
Submission received: 10 April 2023
/
Revised: 28 May 2023
/
Accepted: 6 June 2023
/
Published: 11 June 2023
(This article belongs to the Special Issue Advances in Information and Coding Theory)
Abstract
:The utilization of databases such as IoT has progressed, and understanding how to protect the privacy of data is an important issue. As pioneering work, in 1983, Yamamoto assumed the source (database), which consists of public information and private information, and found theoretical limits (first-order rate analysis) among the coding rate, utility and privacy for the decoder in two special cases. In this paper, we consider a more general case based on the work by Shinohara and Yagi in 2022. Introducing a measure of privacy for the encoder, we investigate the following two problems: The first problem is the first-order rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder, in which utility is measured by the expected distortion or the excess-distortion probability. The second task is establishing the strong converse theorem for utility–privacy trade-offs, in which utility is measured by the excess-distortion probability. These results may lead to a more refined analysis such as the second-order rate analysis.
1. Introduction
1.1. Background
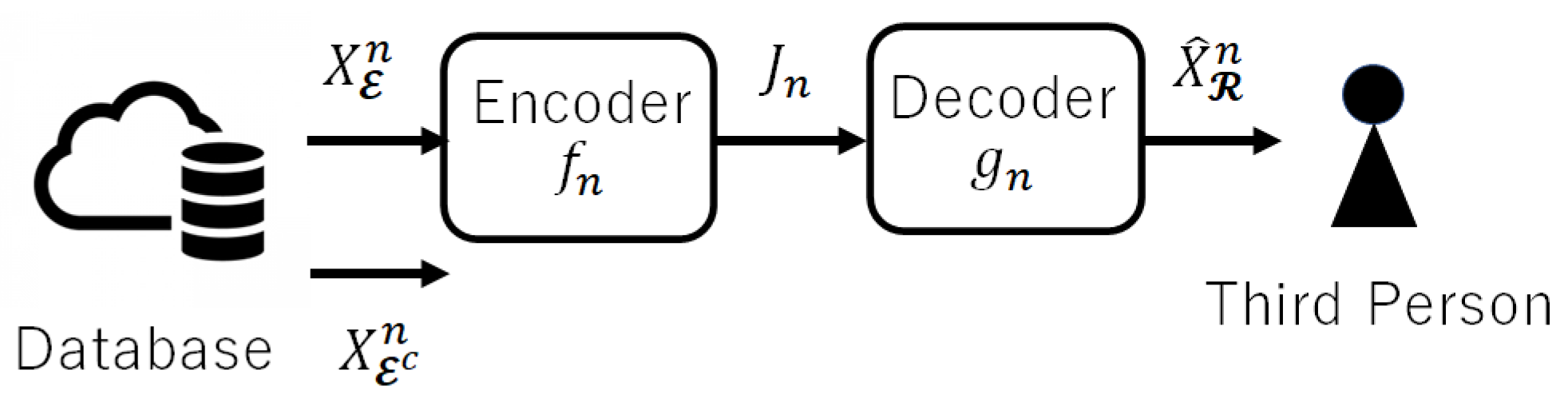
The utilization of database has progressed in our society and includes autonomous cars and the congestion data service over the Internet. At the same time, the risk of accidental or intentional leakage of private information has also increased rapidly. To protect private information, coding with a privacy constraint has been analyzed via an information-theoretic approach. In 1983, Yamamoto [1] introduced a framework to quantify the utility of databases and the privacy of personal information and analyzed the trade-offs between them. Decades later, in 2013, Sankar et al. [2] claimed the necessity of converting databases to protect privacy while maintaining the utility of data. Then, Yamamoto’s framework [1] was re-recognized by Sankar et al. and other researchers. Using the rate-distortion theory in information theory, he revealed the optimal relationships (theoretical limits) among coding rate, utility, and privacy in two cases; (i) public information that can be open to the public and private information that should be protected from a third party are encoded, and (ii) only public information is encoded. However, since a more general case, i.e., where (iii) public information and a part of private information is encoded, had not been clarified, Shinohara and Yagi [3] derived the theoretical limits in such a case (see Figure 1). As a result, our characterization of the achievable region gives a “unified expression” because it includes the characteristics given in [1] in cases (i) and (ii) as special cases.
1.2. Motivation and Contributions
By investigating case (iii), one can compare the theoretical limits corresponding to a variety of patterns of the encoded information. One can see that the achievable region in case (i) is the largest among all patterns. However, this may not be the case if privacy leakage for the encoder is constrained. Motivated by this observation, in this paper, we characterize the optimal trade-offs among coding rate, utility, privacy for the decoder, and privacy for the encoder in Section 3. The addressed problem corresponds to the case where there are some aggregators between the source and the encoder and the aggregator controls the data (source sequence) passing to the encoder. The obtained results indeed suggest that the best-encoded information can be in case (iii) if some restriction is imposed on the privacy leakage for the encoder.
One of the most important tasks in information-theoretic analysis for utility–privacy trade-offs is second-order rate analysis (e.g., [4,5,6]). In general, in second-order rate analysis, the excess-distortion probability is used as a measure of utility [4,5,6]. However, in the first-order rate analysis shown in [3], utility is measured by the expected distortion, so for second-order rate analysis, we need first to conduct first-order rate analysis, which replaces the expected distortion with the excess-distortion probability as the measure of utility. In Section 4, the theoretical limits coincide with the one in which utility is measured by expected distortion.
There is one more problem to solve before tackling second-order rate analysis: we need to clarify whether the boundary of the achievable region may vary or not, depending on the value of the excess-distortion probability. In Section 5, we establish the strong converse theorem, provided that utility is measured by the probability of excess distortion. For the sake of simplicity, we focus on the achievable region of utility and privacy for the decoder or a third party, which reveals an aspect of utility–privacy trade-offs. In the proof, we adopt a change in measure argument developed by Tyagi and Watanabe [7]. Contrary to the standard rate-distortion problem, the alphabets of the encoder’s input and the decoder’s output are different, so we extend the argument to incorporate this discrepancy. Although the strong converse theorem is shown for the rate region of utility and privacy, we can also derive the same result when the privacy of the encoder is involved.
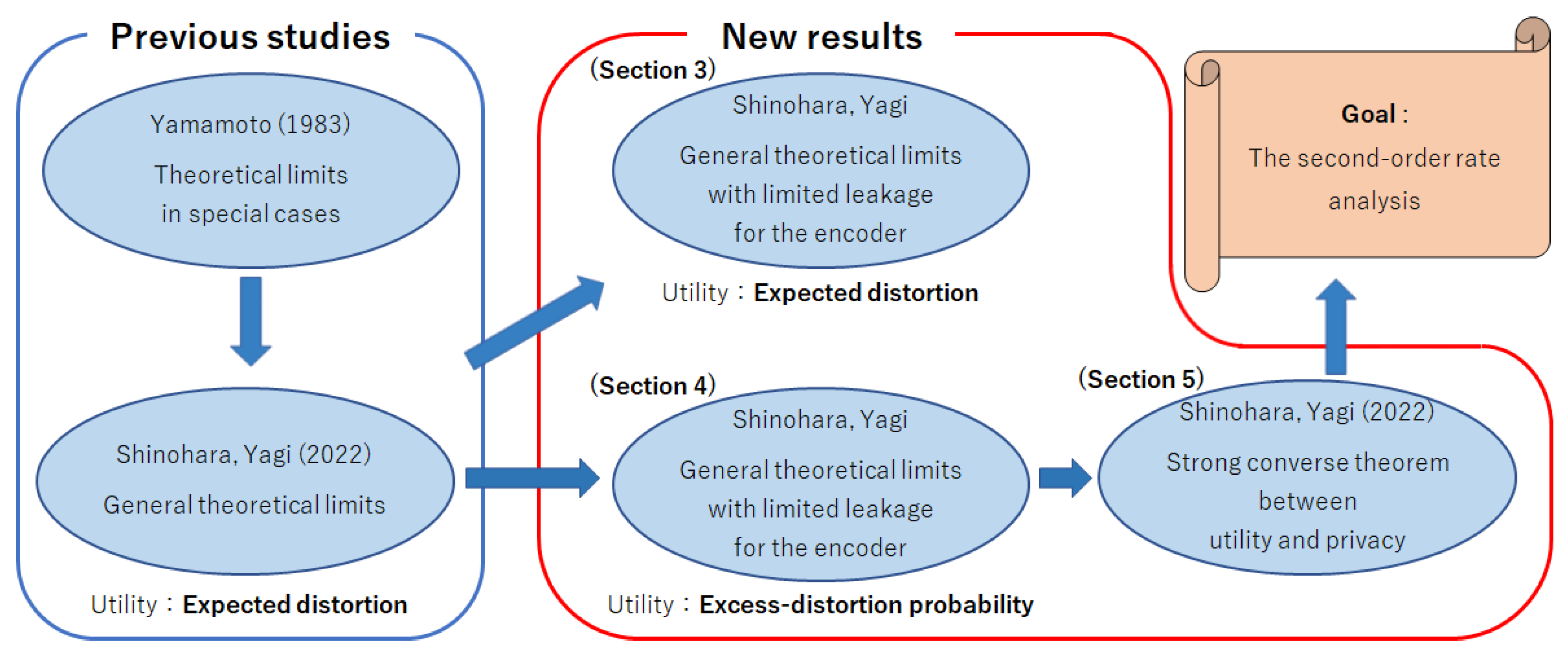
For readers’ convenience, Figure 2 shows the road map to the most important task: the second-order rate analysis. In summary, three contributions of this paper are as follows:
- The rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder in which utility is measured using the expected distortion (Section 3).
- The rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder in which utility is measured using the excess-distortion probability (Section 4).
- The strong converse theorem for utility–privacy trade-offs in which utility is measured using the excess-distortion probability (Section 5).
1.3. Related Work
The analysis of the utility–privacy trade-offs using an information-theoretic approach was initiated by [2], which translates the rate-distortion problem with an equivocation constraint in [1] into the privacy and utility trade-off problem. In information-theoretic studies on coding with privacy and utility constraints, several measures for privacy and utility are adopted. One of the strong measures for privacy is differential privacy [8,9], and an extension and relaxation of differential privacy have been proposed in [10,11]. A weaker but useful privacy measure is the mutual information between the codeword and private information [1,2,12,13,14], which guarantees the average amount of leaked private information. Other examples of well-known privacy measures are maximal leakage [15], maximal -leakage [16,17,18], and total variation [19]. Relationships among several measures for privacy have been revealed in [20]. On the other hand, well-known utility measures are average distortion [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25], hard distortion [16,17], and log-loss distortion [26].
Coding systems in the utility–privacy problem are extended to the ones with the encoder’s side information [2] and with the decoder’s side information [25]. In [14], a related coding problem has been investigated, where both the encoder and the decoder can access a uniform secret key and the decoder can also access side information. Utility–privacy trade-off schemes are applied, for example, to the Internet of Energy [23] and to a system with informational self-determination [24].
A closely related study to this paper was given by Basciftci et al. [13], in which several release mechanisms of encoded information from the database were discussed. In particular, utility–privacy trade-offs (without the coding rate) were compared when the encoded information was (i) both private and public information, (ii) only public information, and (iv) only private information (see also the three cases described in Section 1.1). A sufficient condition under which the utility–privacy trade-offs coincide for cases (i) and (ii) was given.
1.4. Organization
This paper is organized as follows: In Section 2, we begin by introducing the notation and system model that are used in this paper. In Section 3, we give the first-order rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder in which utility is measured by the expected distortion. In Section 4, we tackle the first-order rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder in which utility is measured by the excess-distortion probability. Section 5 focuses on the strong converse theorem for utility–privacy trade-offs in which utility is measured by the excess-distortion probability. In Section 6, we discuss the significance of the encoded information with limited leakage for the encoder. Finally, in Section 7, the conclusion and future work are stated.
2. Notation and System Model
2.1. Information Source
Database d is described by a matrix whose rows represent K attributes and columns represent n entries of data. Let be the set of indexes of K attributes. The random variable for the lth attribute is denoted by , which takes a value in a finite alphabet . For any subset , the tuple of random variables is abbreviated as . Similarly, the Cartesian product of alphabets is abbreviated as .
The K attributes can be divided into two groups; one may be open to the public and the other should be kept secret from a third party. Then, the set is divided into disjoint sets and . That is,
where is the set of values that public (revealed) source symbols take and is the set of values that private (hidden) source symbols take.
We assume that the source sequence is generated from a stationary and memoryless source . That is,
where . Taking the partition of attributes in (1) into account, the source sequence is described as
where
are referred to as the revealed source sequence and the hidden source sequence, respectively. In the addressed coding system introduced in [22], the revealed symbols and a part of the hidden symbols are input to the encoder, and thus the encoded alphabet satisfies . Similar to (3), is sometimes described as
where is the source sequence observed by the encoder and .
2.2. Encoder and Decoder
The coding system consists of encoder and decoder as in Figure 1. When the source sequence is generated from the stationary and memoryless source , the codeword is generated by the encoder
and the reproduced sequence is produced by decoder
where denotes the number of codewords.
3. First-Order Rate Analysis with Expected Distortion
3.1. Performance Measures
In this section, we mention the measure of the coding rate, utility, privacy for the decoder, and privacy for the encoder. Hereafter, let a pair of the encoder and decoder be fixed.
For a given , the coding rate is defined as
Let be a distortion function between and . The distortion between sequences and is defined as
Then, the measure of utility is defined as
where represents the expectation by the joint distribution of .
In this system, the privacy of the hidden source sequence should be protected when the codeword is observed by decoder . The measure of privacy for the decoder is defined as
where is the mutual information between and .
The privacy of the hidden source sequence should be protected when the encoded information is observed by encoder . The measurement of privacy for the encoder is defined as
where is the mutual information between and .
3.2. Achievable Region and Theorem
We define the achievable region for the first-order rate analysis with the expected distortion and state the obtained results.
Definition 1.
A tuple is said to be -achievable (with respect to the expected distortion measure) if, for any given , there exists a sequence of codes satisfying
for all sufficiently large n.
The technical meanings of each constraint in Definition 1 can be interpreted as follows: Equation (14) evaluates how much the source sequence is compressed, so this rate should be decreased. Equation (15) is the constraint corresponding to distortion being less than . The smaller the distortion is, the better the utility is, so this condition should also be decreased. Equation (16) constrains the amount of leaked private information to the decoder. Since private information should be kept secret for the receiver, this quantity should be decreased as well. Equation (17) constrains the amount of private information leaked to the encoder. For the same reason as (16), this quantity should also be decreased.
Remark 1.
The minimum coding rate R for a fixed D corresponds to the rate-distortion function (Section 10 in [27]). Thus, in the proof of achievability, we evaluate the coding rate and the distortion with the argument in rate-distortion theory. This view is also important to correctly understand the numerical results in Section 6.1.
Definition 2.
The closure of the set of ϵ-achievable tuples is referred to as the -achievable region and is denoted by and defines
To characterize the achievable region, we define the following informational region.
Definition 3.
For any such that , is defined as
We establish the next theorem. For the proof of this theorem, please refer to Section 3.3, Section 3.4 and Section 3.5.
Theorem 1.
For any such that , the achievable region of the coding system is given by
To clarify the relationship with the conventional result of Shinohara and Yagi [3], we mention the achievable region among the coding rate, utility, and privacy, which is derived by projecting the result of Theorem 1 onto the hyperplane.
Definition 4.
For any such that , we define
and
Definition 5.
For any such that , we define
Corollary 1.
For any such that , the region is given by
Remark 2.
Corollary 1 suggests that the conventional result [3] can be obtained from .
Remark 3.
The derived characterization in (24) reduces to the characterization given in [1] when the encoded attribute is either or . Thus, (24) gives its generalization for .
Examples to illustrate this result are shown in Section 6.1.
3.3. Proof Preliminaries for First-Order Rate Analysis
For preliminaries for coding theorems by the first-order rate analysis, we define strongly typical sequences that are necessary for the proof and show some properties. These proof preliminaries are also used in Section 4.
Definition 6
(Definition 2.1, [28]). The type of a sequence of length n is the distribution on defined by
where represents the number of occurrences of symbol in . Likewise, the joint type of and is the distribution on defined by
where represents the number of the occurrences of in the pair of sequences .
Definition 7
((Conditional Type), [28], Definition 2.2). We define the conditional type of given as a stochastic matrix satisfying
In particular, the conditional type of given is uniquely determined and given by
if for any .
Definition 8
((Strongly Typical Sequences), [29], Definition 1.2.8). For any distribution P on , a sequence is said to be P-typical with constant if
and, in addition, no with occurs in . The set of such sequences is denoted by . If X is a random variable with values in , we also refer to P-typical sequences as X-typical sequences and write .
Definition 9
((Conditional Strongly Typical Sequences), [29], Definition 1.2.9). For a stochastic matrix , a sequence is said to be W-typical given with constant if
and, in addition, whenever . The set of such sequences is denoted by . Further, if X and Y are random variables with values in and , respectively, and , then they are also said to be -typical and written as .
Hereafter, the set of conditional strongly typical sequences is abbreviated as .
We state some lemmas that are used in this proof.
Lemma 1
([29], Lemma 1.2.13). For any positive sequences and such that and as , there exists a sequence such that for every distribution P on and stochastic matrix ,
Lemma 2
([29], Lemma 1.2.7). Let the variational distance between two distributions P and Q on be defined as
If , then
Lemma 3
([29], Lemma 1.2.10). If and , then and, consequently, for .
Lemma 4.
If , then and, consequently, for and .
Lemma 5.
If and , then .
Lemma 6
([29], Lemma 1.2.12 and Remark). For arbitrarily fixed and every distribution P on and stochastic matrix
3.4. Proof of Converse Part
In this part, we shall prove .
Let a tuple be arbitrarily fixed. Then, there exists an code that satisfies (14)–(17). Let Q be a uniform random variable over and let be the conditional distribution given . Evaluating the inequalities for R, we obtain
- (a)
- follows from (14),
- (b)
- follows because ,
- (c)
- is due to the fact that ,
- (d)
- follows because each is independent and is a function of ,
- (e)
- follows because conditioning reduces entropy,
- (f)
- is due to the definition of Q,
- (g)
- follows because , and
- (h)
- follows because conditioning reduces entropy, where .
Similarly, evaluating D, L, and E, respectively, we obtain
where
- (i)
- is due to (15),
- (j)
- is derived from the definition of Q,
- (k)
- follows because ,
- (l)
- is due to (16),
- (m)
- follows because ,
- (n)
- follows because ,
- (o)
- follows from the fact that conditioning reduces entropy,
- (p)
- is derived from the definition of Q, and
- (q)
- follows because conditioning reduces entropy, where ,
- (r)
- is due to chain rule for mutual information,
- (s), (t)
- follow because .
It is readily shown that the Markov chain –– holds (cf. Appendix A). We complete the proof of the converse part.
3.5. Proof of Direct Part
In this part, we provide a sketch of the proof of .
Under an arbitrarily fixed distribution , any tuple is chosen such that
From (42) and (43), we can choose a sufficiently small such that
In addition, with this , some constant is fixed such that
We can also choose positive numbers such that
as , where and . Let where c is a constant, and obviously (50) and (51) are satisfied.
Generation of codebook: Randomly generate from the strongly typical sequences for . Reveal the codebook to the encoder and decoder.
Encoding: If a sequence satisfies with some , we write . Given , the encoder finds j such that and sets where is the conditional strongly typical sequences. If there exist multiple such j, is set as the minimum one. If there are no such j, then .
Decoding: When j is observed, the decoder sets the reproduced sequence as .
Evaluation: We define , , and as
It is easily verified that for (also, and ) is disjoint. From the definitions of , , and ,
For sufficiently large n, we can prove (cf. Appendix B)
For sufficiently large n, we can show that there exists a code such that (cf. Appendix C)
For this code , we evaluate the privacy leakage against the decoder as
where
- (a)
- follows because of ,
- (b)
- is due to the inequality proved in Appendix D,
- (c)
- follows by removing the term for .
Here, for any satisfying with some , we can show that
where
- (d)
- follows from the fact that
- (e)
- is due to the inequality proved in Appendix E, and
- (f)
- follows because of the number of strongly typical sequences.
Therefore, from Equations (61), (64) and (66) we can obtain
Since constants , , and are fixed to satisfy (45)–(48), from (44), (57)–(59) and (67), we obtain
Therefore, for the fixed distribution any tuple
is achievable. Consequently, . Taking the closure for the left-hand side (l.h.s.), we obtain because is a closed set. We conclude that because the distribution is fixed arbitrarily. We complete the proof of the direct part.
4. First-Order Rate Analysis with Excess-Distortion Probability
4.1. Performance Measures
Hereafter, let the pair of the encoder and decoder be fixed.
For a given , the coding rate is defined as
Let be a distortion function between and . The distortion between sequences and is defined as
Then, the measure of utility is defined as
This measurement is called excess-distortion probability for .
In this system, the privacy of the hidden source sequence should be protected when the codeword is observed by decoder . The measure of privacy for the decoder is defined as
where is the mutual information between and .
The privacy of the hidden source sequence should be protected when the encoded information is observed by encoder . The measurement of privacy for the encoder is defined as
where is the mutual information between and .
4.2. Achievable Region and Theorem
We define the achievable region for the first-order rate analysis with the excess-distortion probability and state the obtained results.
Definition 10.
A tuple is said to be -achievable (with respect to the excess-distortion probability) if, for any given , there exists a sequence of codes satisfying
for all sufficiently large n.
The technical meanings of each constraint in Definition 10 can be interpreted as follows: Equation (78) evaluates how much the source sequence is compressed, so this rate should be decreased. Equation (79) is the constraint corresponding to the excess-distortion probability being less than , so this condition should also be decreased. Equation (80) constrains the amount of leaked private information to the decoder. Since private information should be kept secret for the receiver, this quantity should be decreased as well. Equation (81) constrains the amount of leaked private information to the encoder. For the same reason as (80), this quantity should also be decreased.
Definition 11.
The closure of the set of ϵ-achievable tuples is referred to as the -achievable region and is denoted by and define
We establish the following theorem. For the proof of this theorem, please refer to Section 4.3 and Section 4.4.
Theorem 2.
For any such that , the achievable region of the coding system is given by
Remark 4.
From Theorems 1 and 2, we find that the achievable region in which utility is measured by the expected distortion is equal to the one in which utility is measured by the excess-distortion probability.
Because in Section 6 we discuss the achievable region among coding rate, utility, and privacy, a characterization of the achievable region is derived by projecting the characterization in Theorem 2 onto the hyperplane.
Definition 12.
For any such that , we define
and
Definition 13.
For any such that , we define
Corollary 2.
For any such that , the region is given by
Examples of numerical calculation of this result are shown in Section 6.1.
Since we focus on the achievable region between utility and privacy in the next section, a characterization of the achievable region is derived by further projecting the result of Theorem 2 onto the plane.
Definition 14.
For any such that , we define
and
Definition 15.
For any such that , we define
Corollary 3.
For any such that , the region is given by
4.3. Proof of Converse Part
From Section 3.4 (proof of the converse part), we have
Let a tuple be arbitrarily fixed and and be given. From the argument of the method of types, the sequences are divided into two categories: distortion-typical or non-distortion-typical with some . The sequences of the former categories satisfy and the sequences of the latter one satisfy where . Then, the expected distortion is bounded from above as
where (a) follows from (79) of -achievable in which utility is measured by the excess-distortion probability. Since can be arbitrarily small with proper choices of and , (15) can be derived. This means
From both inclusion relations,
is evidently satisfied.
4.4. Proof of the Direct Part
In this part, we provide a sketch of the proof of .
Under an arbitrarily fixed distribution , any tuple is chosen such that
From (97) and (98) , we can choose a sufficiently small such that
In addition, with this , some constant is fixed such that
We can also choose positive numbers such that
as . Let where c is a constant, and obviously (104) and (105) are satisfied.
Generation of codebook: Randomly generate from the strongly typical sequences for . Reveal the codebook to the encoder and decoder.
Encoding: If a sequence satisfies with some , we write . Given , the encoder finds j such that and sets where is the conditional strongly typical sequences. If there exist multiple such j, is set as the minimum one. If there are no such j, then .
Decoding: When j is observed, the decoder sets the reproduced sequence as .
Evaluation: We define , , and as
It is easily verified that for (and also and ) is disjoint. From the definitions of , , and ,
For sufficiently large n, we can prove (cf. Appendix B)
For sufficiently large n, we can show that there exists a code such that (cf. Appendix F)
For this code , we evaluate the privacy leakage against the decoder as
where
- (a)
- follows because of ,
- (b)
- is due to the inequality proved in Appendix D, and
- (c)
- follows by removing the term for .
Here, for any satisfying with some , we can show that
where
- (d)
- follows from the fact that
- (e)
- is due to the inequality proved in Appendix E, and
- (f)
- follows because of the number of strongly typical sequences.
Therefore, from Equations (115), (119), and (121), we can obtain
Since constants , , and are fixed to satisfy (100)–(102), from (111), (113), and (122), we obtain
Therefore, for the fixed distribution , any tuple
is achievable. Consequently, . Taking the closure for the l.h.s., we obtain because is a closed set. We conclude that because the distribution is fixed arbitrarily. We complete the proof of the direct part.
5. Strong Converse Theorem for Utility–Privacy Trade-Offs
5.1. Another Expression of the Achievable Region
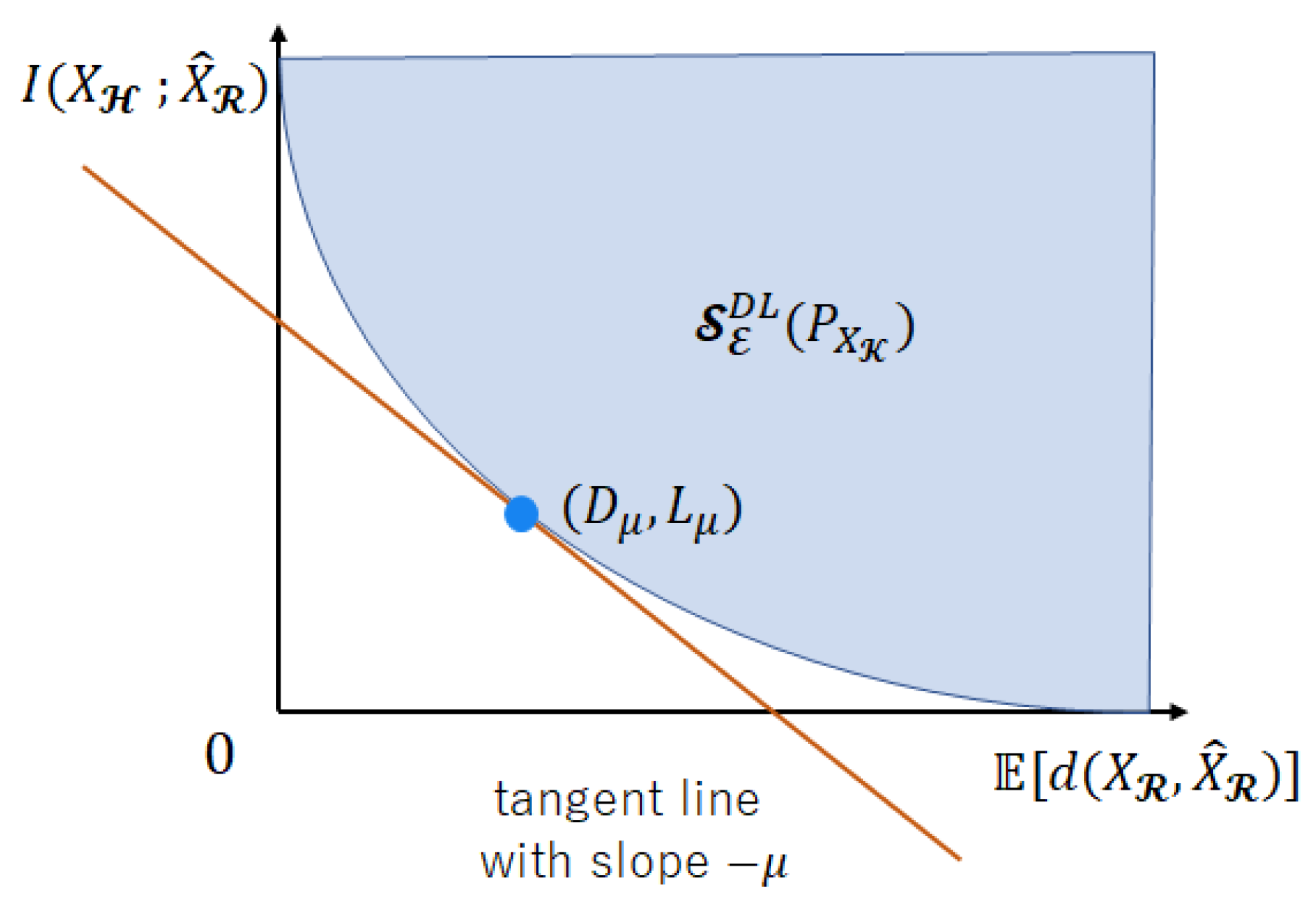
In Section 5.1, we clarify that the achievable region defined in (89) coincides with the region expressed with a tangent plane.
Definition 16.
For any such that , the region is defined as
Theorem 3.
For any such that , the region defined in (90) is given by
and the achievable region , which is the projection region of the achievable region onto the plane, is given by
Proof.
Figure 3 illustrates the proof image using a graph. Let a constance be fixed arbitrarily. Like in Figure 3, there exists a boundary point of tangent to the line with slope . The intercept of this tangent line is .
The minimum characterized by some distribution coincides with . Therefore,
From (130), we obtain
Taking the intersection by on the both sides of (131),
The l.h.s. of (131) shows the upper-right region in the first quadrant drawn by the tangent line with a slope for . Since the l.h.s. of (132) is the intersection of the l.h.s. of (131), the l.h.s. of (132) represents . From Definition 16, the right-hand side (r.h.s.) of (132) is . As a result, (128) holds. Since from Corollary 3, likewise, (129) holds. □
5.2. Proof Preliminaries
In Section 5.2, we derive two fundamental properties of the minimization about two values and the inequalities about entropy and divergence to prove the strong converse theorem. In Proposition 1, we change the objective function of the region expressed with the tangent plane introduced in Section 5.1 onto the region expressed with divergence.
Proposition 1.
Let be fixed arbitrarily. For any such that ,
where
and is the distribution induced from each .
Proof.
First, it is clear that for all . To prove for some , for , let be the distribution that minimizes the r.h.s. of (134) and be the estimated distribution. Since is non-negative and is bounded above, by setting , it must hold that
and thus
Notice that any set of probability distributions on a finite alphabet forms a compact set. Because is a continuous function over a compact set, it is also uniformly continuous. Then, there exists a function satisfying as such that
Consequently, we obtain the desired inequality by taking . □
In the following proposition, we show the inequalities satisfied between source and arbitrary source .
Proposition 2.
For source , which has the common distribution and arbitrary distribution , it holds that
where is the uniformly random variable over the set for time-sharing and is assumed to be independent of all the other random variables involved.
Proof.
The l.h.s. of (135) can be represented as
The sum of the first and second terms satisfies the following equation:
where
- (a)
- follows from the memoryless property of source ;
- (b)
- holds because .
The third term can be bounded from below as
where
- (c)
- follows from the data processing inequality and
- (d)
- holds because of Jensen’s inequality.
From (137) and (138), (135) can be derived.
Likewise, the l.h.s. of (136) can be represented as
The sum of the first and second terms satisfies
where
- (e)
- holds because .
For the third term, it holds that
where
- (f)
- follows from the log sum inequality.
From (139) and (140), we obtain (136). □
5.3. Strong Converse Theorem
We shall establish the strong converse theorem, which is the main result of this section. Before proving the theorem, we state the lemma of the key tool in the proof about a single-letterized and a , which are introduced in Proposition 1.
Lemma 7.
For any such that , all , and , it holds that
As the main theorem of this section, we show the strong converse theorem for the utility–privacy trade-offs.
Theorem 4.
Strong converse theorem: For any such that and all , it holds that
Remark 5.
Theorem 4 suggests that regardless of the value of ϵ, the region is equal to .
5.4. Proof of Lemma 7
Lemma 7 indicates that the function , whose argument is a probability distribution over , can be lower-bounded by the n-fold of a single-letterized function . Before describing the detailed proof, we state the outline of the proof: (i) We first express the function as the maximum of the difference of two functions denoted by and as in (142). (ii) Then, we show that the first function can be lower-bounded by the n-fold of its single-letterized function as in (143), while the second function can be upper-bounded by the n-fold of its single-letterized function as in (147). This outline of the proof is similar to the Proof of Theorem 4, 16 with a slight modification of the function .
For a given distribution , let functions and be defined as
Using these functions, and in view of (134), can be written as
For fixed , from Proposition 2, it holds that
Next, we consider the function . For the first term on the r.h.s. of (141), it holds that
The second term of (141) can be expressed as follows:
where
- (a)
- follows from .
Moreover, for the third term of (141), it holds that
From (144)–(146), we obtain
Consequently, since (143) and (147) are satisfied for an arbitrary , the proof is completed.
5.5. Proof of Strong Converse Theorem
For any given , fix the rate pair arbitrarily. Then, by definition, there exists a code satisfying (79) and (80). For this code , a set is defined as
We derive a distribution as
It is obvious that the excess-distortion probability measured by is 0; that is, and satisfy . Thus, by imitating the proof approach of the standard weak converse theorem, it holds that
From (148), the following equation is obtained:
where
- (a)
- follows from (149) and ,
- (b)
- is due to (134).
Since from Lemma 7, we have
and therefore
Because from Proposition 1, it holds that for an arbitrary ,
Hence, it holds that
For the set of satisfying (150), varying arbitrarily and taking the intersection, we have
From Theorem 3, the r.h.s. of (151) is equal to . This proof is completed.
6. Discussion
6.1. Numerical Calculation of Coding Rate, Utility, and Privacy for Decoder
In this section, we show some numerical calculations of the achievable region and in Corollaries 1 and 2, respectively. In general, it is difficult to compute the achievable region and . Nevertheless, to obtain some insight, let us consider the three tractable but essential cases. In these calculations, the number of public attributes is one and the number of private attributes is two . We assume that each of the attributes is binary. Here, note again that the coding rate R acts like the rate-distortion function in rate-distortion theory (cf. (Section 10 in [27])). For fixed D and L, a smaller coding rate is better.
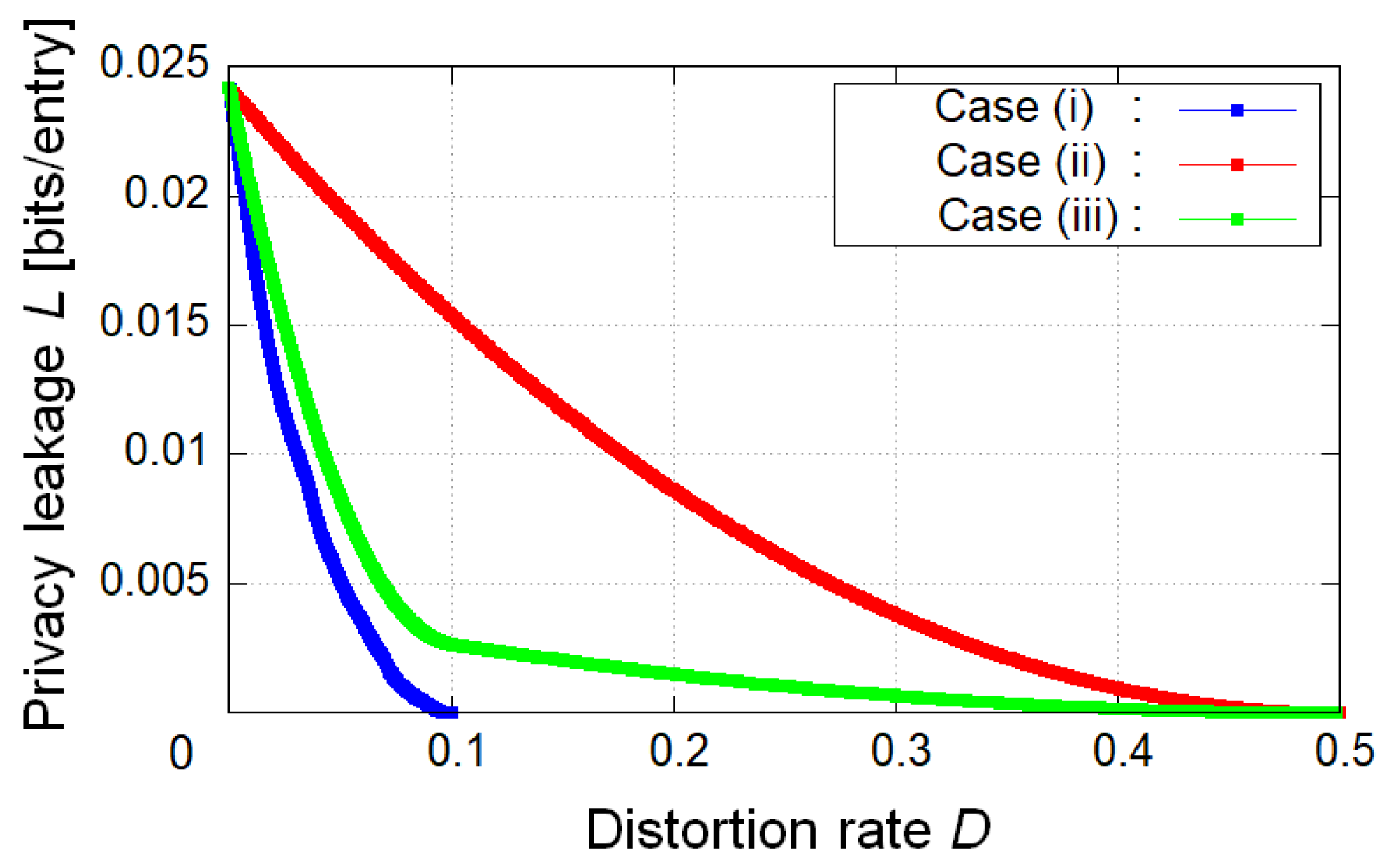
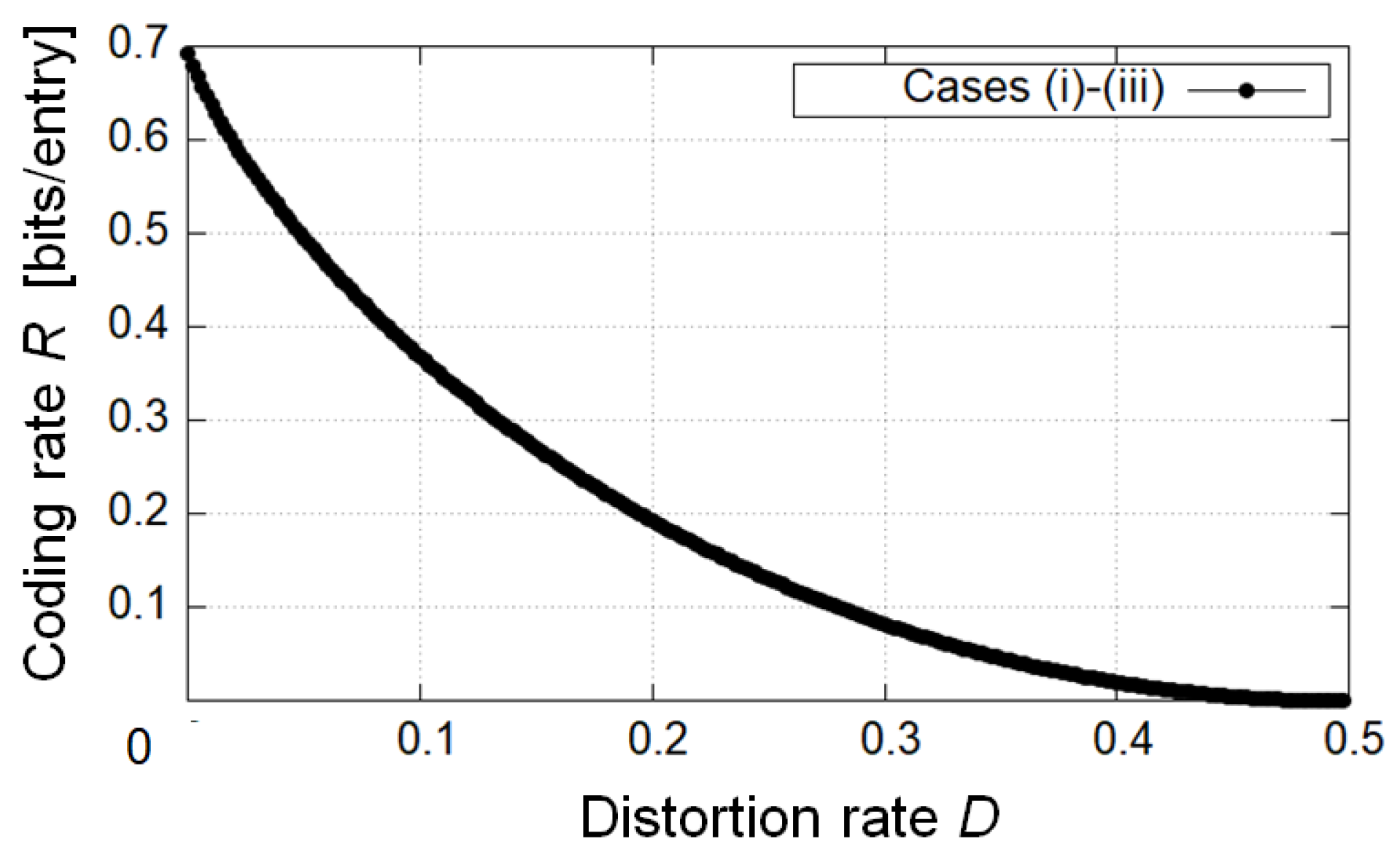
In the first example, we calculated the L-D graph of theoretical limits in case (i) , case (ii) , and case (iii) (Figure 4). As a result, the achievable privacy leakage L becomes small as D becomes large if we do not impose any restrictions on the value of R. For a given D, the privacy leakage for the decoder in case (i) is the smallest, and the one in case (ii) is the largest in all cases. The second example calculated the R-D graph of theoretical limits in cases (i), (ii), and (iii) (Figure 5). We can see that the minimum coding rates for a given D coincide in all cases if we do not impose any restrictions on the value of L. In the third example, we calculated the optimal privacy leakage L for fixed D and the corresponding coding rates R in cases (i), (ii), and (iii) (Table 1, Table 2 and Table 3). As a result, the optimal privacy leakage in cases (i) and (iii) is smaller than the one in case (ii), whereas for the optimal privacy leakage, the achievable coding rates in cases (i) and (iii) is larger than the one in case (ii).
Next, we discuss these results. In Figure 4, in comparison with each case, we can verify that for a given D, the more private information is encoded, the smaller the achievable minimum privacy leakage is. Figure 5 suggests that if the coding rate should be minimized, it suffices to encode only the public attributes. This result is evident from Corollaries 1 and 2 because the condition on the choice of test channel in case (i) is weaker than the one in case (ii), and if an appropriate test channel is taken in case (i), it is also appropriate in case (ii). It is indicated that the achievable region in case (ii) is also the one in cases (i) and (iii). The opposite is not the case. From Table 1, Table 2 and Table 3, we can confirm the trade-off between the optimal privacy leakage L for a fixed D and the corresponding coding rate R in comparison with each case.
Summarizing the foregoing arguments, we have discussed the relationship between utility and privacy in Figure 4, the one between utility and coding rate in Figure 5, and the one between privacy and coding rate in Table 1, Table 2 and Table 3. From the discussion about Figure 5, some readers may suspect that case (i) is the best-encoded information because the achievable region in cases (ii) and (iii) is the one in case (i). This is true if we do not consider the leakage for the encoder. However, this is not true if we consider the leakage for the encoder, that is, the measurement of privacy for the encoder (see (12) or (76)). In the next section, we discuss this point in detail.
6.2. Significance of Limited Leakage for Encoder
In this section, we discuss the significance of evaluating the leakage for the encoder. Our goal of this discussion is to show that the best-encoded information may be case (iii) if we take the limited leakage for the encoder into consideration.
The first issue is the amount of encoded information. Some readers may think that it is better that more encoded information is inputted into the encoder. However, there are pros and cons.
- Pros:
- The achievable regions and become larger.
- Cons:
- The leakage for the encoder increases.
From this point of view, we can come up with the idea that there exists the best-encoded information in case (iii) if we impose some constraint on the leakage for the encoder. This idea is the key point of this paper.
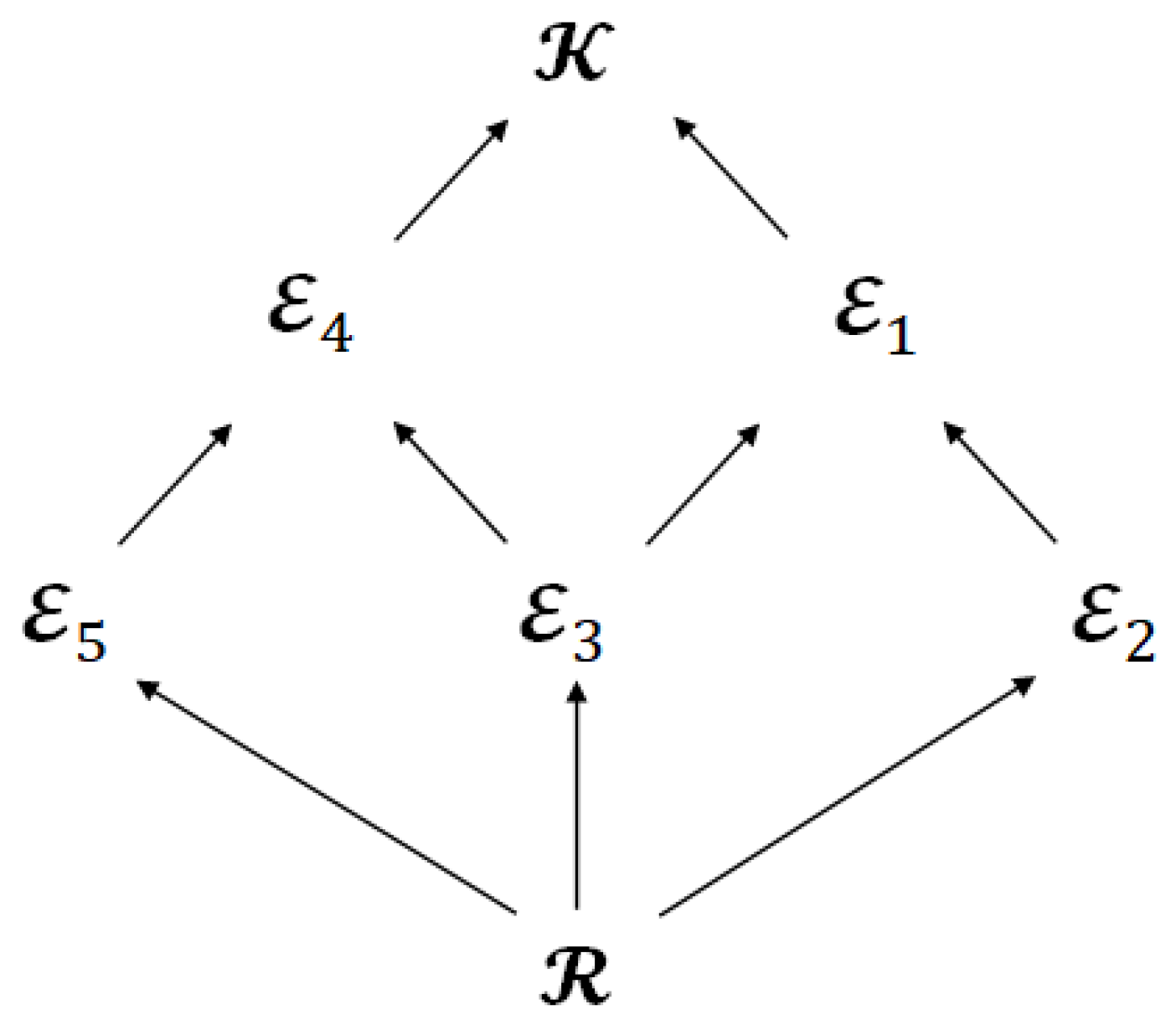
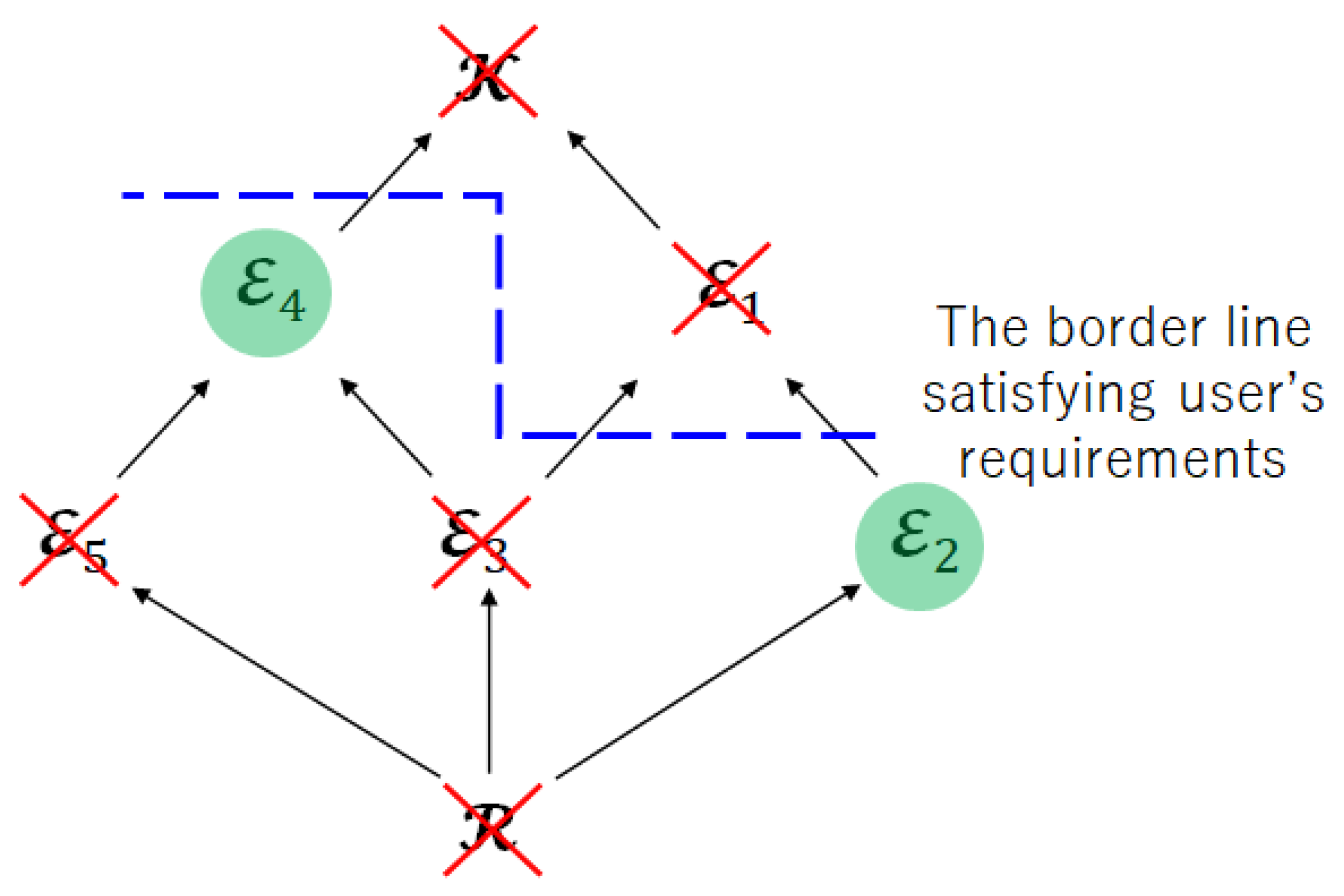
The second issue is the significance of the limited leakage for the encoder. Figure 6 shows the Hasse diagram, which represents the inclusion relation about the index sets of attributes. The Hasse diagram is often used to represent inclusion relations, for example, .
We can also regard Figure 6 as the Hasse diagram that represents the inclusion relation for the achievable regions and because the index sets of attributes () corresponds to the encoded information () and the encoded information corresponds to the achievable region ( and ). In addition, the diagram in Figure 6 has another property, which is that the superordinate sets have a larger amount of privacy leakage for the encoder than the subordinate sets since the index sets of attributes correspond to the privacy leakage for the encoder.
Let us consider a practical application. We assume that the data aggregator, that is, the encoder, tries to gather encoded information from some application user and hopes to develop the utility of the application while limiting the amount of leakage for by , that is, . More precisely, for a given E, we want to find which subsets of are sufficient to characterize
where and are defined in Definitions 2 and 11, respectively. The process is as follows.
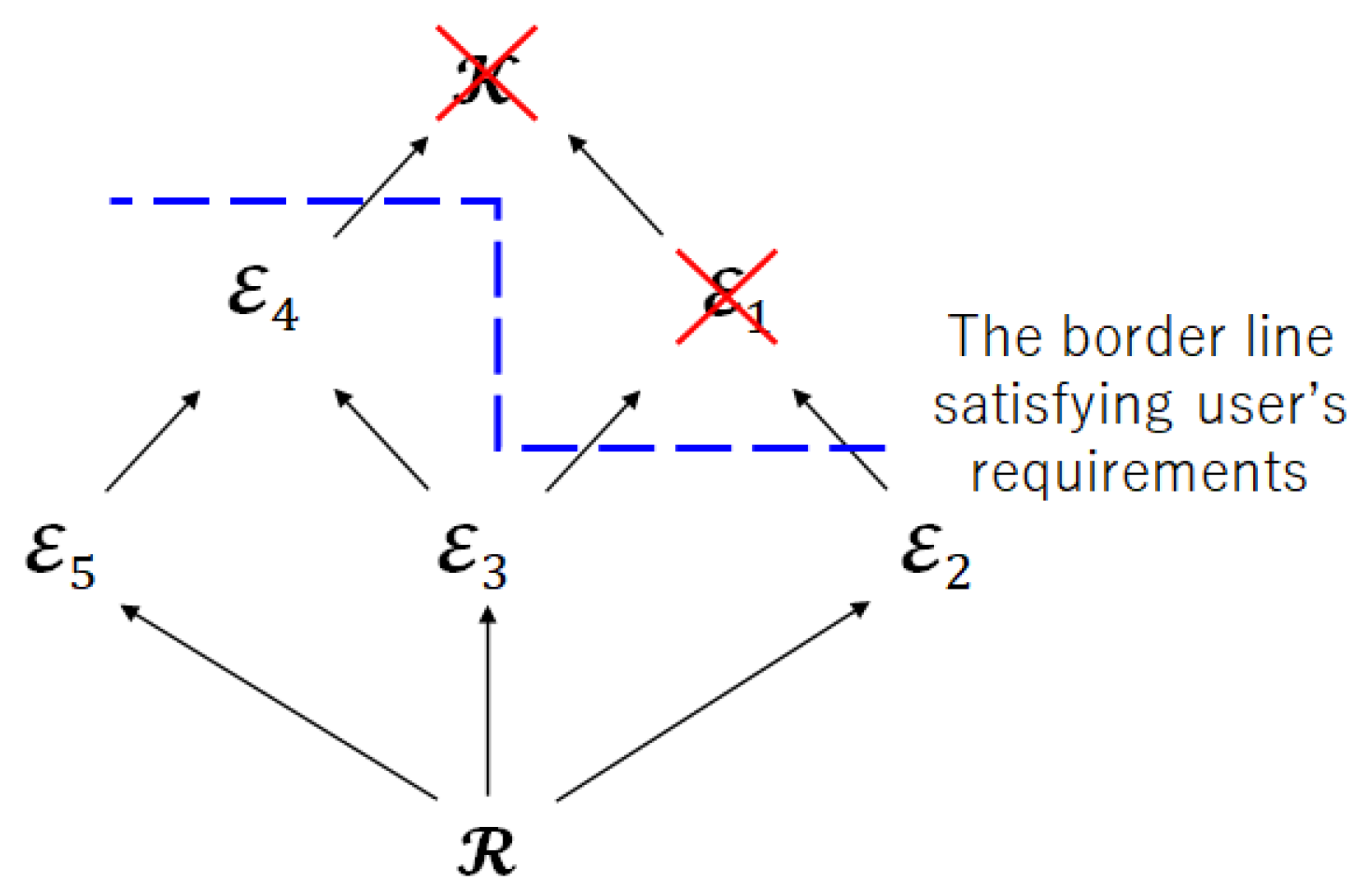
- Step 1:
- Check the user’s requirements and impose the restriction on the privacy leakage for the encoder.
Figure 7 shows the Hasse diagram for Step 1. The blue dotted line means the border line satisfies the restriction of the privacy leakage for the encoder. Therefore, the index sets and are not suitable as the index sets of encoded information.
- Step 2:
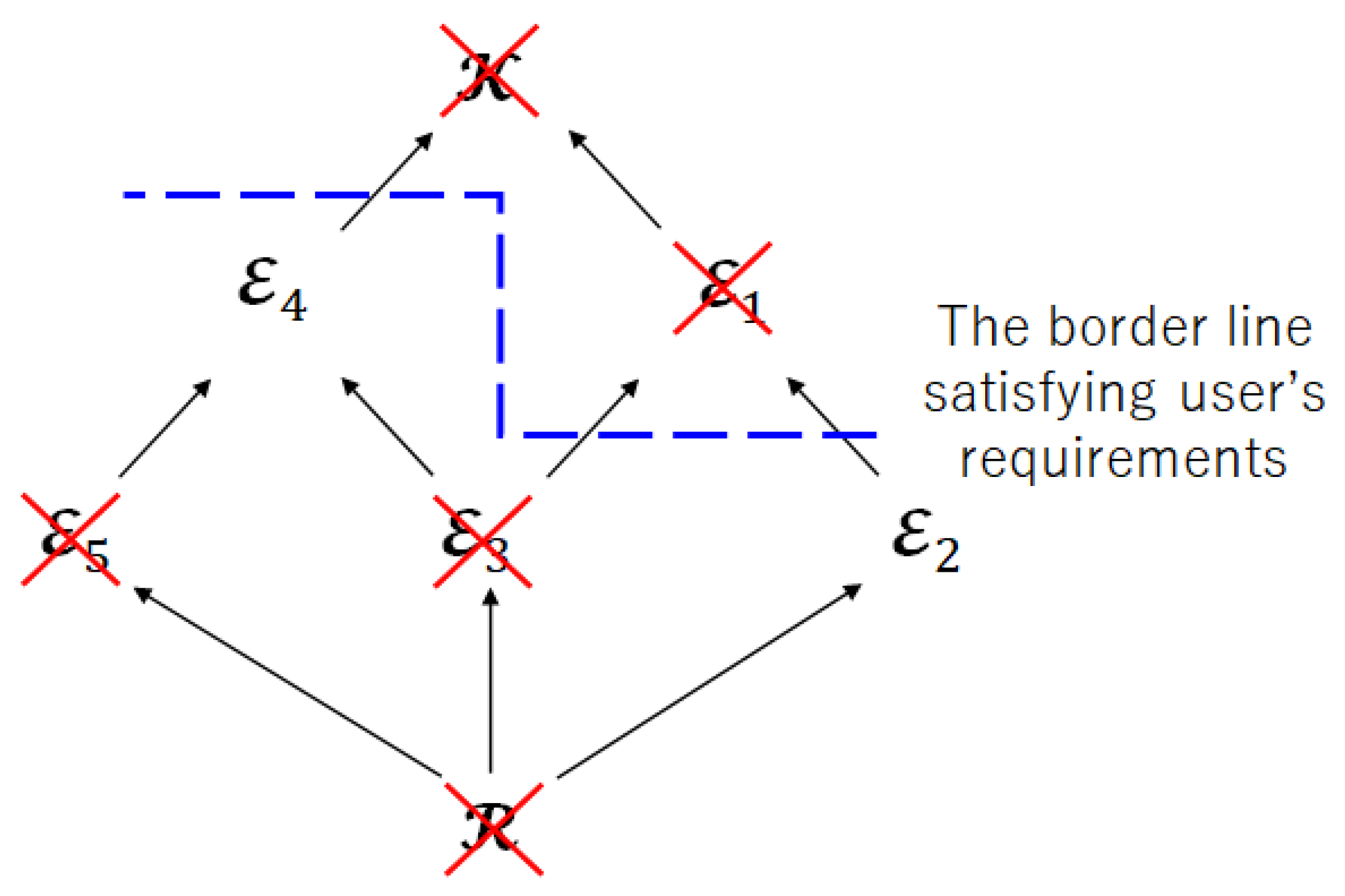
- Check the inclusion relation between index sets.
Therefore, the index sets , , and are not suitable as the index sets of encoded information.
Figure 9 shows the Hasse diagram obtained after Step 2. From Figure 9, the remaining index sets are and . Therefore, if we impose restriction on privacy leakage for the encoder, the index sets or form the Pareto area in this multi-objective optimization problem. In other words, there exists a system that satisfies the user’s requirements E of the maximum amount of leakage to the encoder, and the achievable regions are given by and .
From the discussion above, we mention that the best-encoded information is case (iii) if we take the limited leakage for the encoder into account. This concept is one of the most important novelties in this paper.
6.3. Discussion on Measures for Privacy Leakage
This paper adopts the mutual information as the measure of privacy leakage as in (12), (13), (76), and (77). However, some less likely data can be leaked even though the database satisfies the theoretical limit of privacy leakage. For example, let be a pair of correlated random variables whose is very small. However, there may exist a pair of such that can imply with high probability. To put it differently, the receiver can tell the value of X if it observes . The theoretical limit evaluated with mutual information cannot prevent such a scenario. To circumvent this scenario, we suggest the other measurement adopted in related studies. A promising candidate to avoid this problem is to employ Rényi information of higher orders [30], maximal leakage [15], and maximal -leakage [16,17,18,21].
7. Conclusions
In this paper, we strengthened the results in [3] mainly by establishing three coding theorems in a privacy-constrained source coding problem. In Section 3 and Section 4, two theorems are made about the first-order rate analysis in which utility is measured by the expected distortion or the excess-distortion probability for case (iii), . The novelty is the introduction of the measure of privacy for the encoder along with the use of the excess-distortion probability. The obtained characterization reduces to the one given in [3] derived based on the expected distortion when the leakage for the encoder is not limited, and the result shows that employing an excess-distortion probability does not change the achievable region from the one with an expected distortion. In Section 5, we establish the strong converse theorem for utility–privacy trade-offs. Although the described result is for the projected plane of utility and privacy for the decoder for simplicity, we can also incorporate the measure of privacy for the encoder. Finally, we discuss the significance of the encoded information considering limited leakage for the encoder. The argument suggests that the best-encoded information can be case (iii) if some constraint is imposed on the privacy leakage for the encoder.
As future work, the second-order rate analysis for utility–privacy trade-offs is an interesting research topic [4,5,6]. Moreover, the strong converse theorem and the second-order rate analysis for the four-dimensional region of coding rate, utility, privacy for the decoder, and privacy for the encoder are more challenging tasks. It is also worth analyzing the achievable region with the other privacy measures such as Rényi information [30], maximal leakage [15], and maximal -leakage [16,17,18,21]. This paper analyzed the theoretical limits of coding, but understanding how to achieve the theoretical limits remains open. The construction of good codes is also an important subject. Extensions of this paper’s scenario to coding with side information [2,25] are also of interest.
Author Contributions
N.S. contributed to the conceptualization of the research goals and aims, the visualization, the formal analysis of the results, and the review and editing. H.Y. contributed to the conceptualization of the ideas, the validation of the results, and the supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by JSPS KAKENHI Grant Numbers JP20K04462 and JP18H01438.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of the Markov Chain –– in Converse Part of Theorem 1
Let be the conditional distribution given ,
where
- (a)
- is due to the Markov chain –– and
- (b)
- follows from the stationary memoryless source.
Therefore, we can obtain the Markov chain ––. For the marginal distribution, we can show that
where
- (c)
- follows because
- (d)
- is due to the Markov chain ––,
- (e)
- follows from the stationary memoryless source, and
- (f)
- follows because
Therefore, we can obtain the Markov chain ––. We complete the proof.
Appendix B. Proof of Equation (56)
From for ,
If , then and , and thus we have from Lemma 5. Then,
We can prove that
where
- (a)
- is due to the Markov chain –– and
- (b)
- follows from Lemma 6.
From Equations (A5) and (A7), we can obtain
We complete the proof of (56).
Appendix C. Proof of Existence of Code Satisfying Equations (57)–(62)
We first set and . Then, we obviously have (57).
From the union upper bound,
From Lemma 6, the first term in (A9) is bounded as
We consider the expectation of the second term in (A9) by random coding. Hereafter, we denote the random variable corresponding to the reproduced sequence as . For notational simplicity, we use the abbreviation
and then
where
- (a)
- is owing to (A11),
- (b)
- is due to the symmetry about indexes of random coding,
- (c)
- follows from the same way as in (Section 3.6.3 in [31]), and
- (d)
- because is fixed to satisfy (49).
From (A10) and (A12), we obtain
Therefore, there exists at least one codebook satisfying (60) in the ensembles obtained by random coding.
Hereafter, codebook is fixed to satisfy (60). That is, codebook satisfies
We evaluate the distortion function for each j.
- (i)
- :where
- (e)
- because from Lemma 4, if , then and from Lemma 3, if and , then .
- (ii)
- :where
- (f)
- is due to the definition of .
We consider . From (A14),
Therefore, we can confirm
From (i) and (ii), we can evaluate utility as below.
for all sufficiently large n, where
- (g)
- follows from (A18).
Thus, we obtain (58).
We can evaluate the privacy leakage against the encoder as shown below.
where
- (h)
- is due to chain rule for mutual information and
- (i), (j)
- follows because .
Thus, we have (59).
Next, we show that the probability that random vector is not included in the set is sufficiently small. First, notice that
where is the index such that for . Therefore, by the union upper bound,
We evaluate each term in (A22).
- (i)
- The first term:where
- (k)
- is because of (A14).
- (ii)
- The second term:If the event in the second term occurs, and . Therefore, from Lemma 5, holds. Hence,where
- (l)
- is due to the Markov chain ,
- (m)
- follows since and Lemma 6, and
- (n)
- follows because are disjoint for each j.
From (A22)–(A24),
Therefore, for sufficiently large n,
and we obtain (61).
From Lemma 1, for sufficiently large n to stochastic matrix and we can show that
We can also show from (A27) that
From the definition of and and Lemma 3, for , we have
This means
Therefore, from (A28) and (A31),
and we obtain (62).
Appendix D. Derivation of Inequality in Equation (63)
We derive the inequality in (63). To write notation concisely, for every and each , we define , , , and as follows:
Then, using the notation in [5], we can write each entropy as
The variational distance between distributions and is
We evaluate each term in (A41).
- (i)
- The first term:where
- (a)
- follows because is disjoint for each ,
- (b)
- is owing to (61).
- (ii)
- The second term:where
- (c)
- follows because and
- (d)
- follows from (61).
From (A42) and (A43), the variational distance between and is bounded from above as
Next, the variational distance between distributions and is
We evaluate each term in (A45).
- (i)
- The first term:where
- (e)
- follows since is disjoint for each ,
- (f)
- is due to (61).
- (ii)
- The second term:where
- (g)
- follows because and
- (h)
- is due to (61).
From (A46) and (A47), the variational distance between and is bounded from above as
As a result, from Lemma 2 and the relation of each entropy,
From (A49), (A50), and the chain rule of entropy,
where
- (i)
- is because of the triangle inequality.
Therefore, we obtain
where
- (j)
- follows from the definition that and .
We complete the derivation of (63).
Appendix E. Proof of Equation (65)
First of all, we shall show
By the definition of ,
Thus, from Lemma 4, any such that satisfies
That is, given and , and are conditional strongly typical sequences. Then, we obtain (A53), and
Therefore, we obtain (65).
Appendix F. Proof of the Existence of Code Satisfying Equations (111)–(116)
We first set and . Then, we obviously have (111).
From the union upper bound,
From Lemma 6, the first term in (A57) is bounded as
We consider the expectation of the second term in (A57) by random coding. Hereafter, we denote the random variable corresponding to the reproduced sequence as . For notational simplicity, we use the abbreviation
and then
where
- (a)
- is owing to (A59),
- (b)
- is due to the symmetry about indexes of random coding,
- (c)
- follows from the same way as in ([31], Section 3.6.3), and
- (d)
- because is fixed to satisfy (103).
From (A58) and (A60), we obtain
Therefore, there exists at least one codebook satisfying (112) in the ensembles obtained using random coding.
Hereafter, codebook is fixed to satisfy (112). That is, codebook satisfies
For a fixed codebook , we divide the sequences into three categories.
- Strongly typical sequences such that there exists a codeword for some that is conditionally strongly typical with In this case, from Lemma 3, . Since the codeword is jointly strongly typical with , the continuity of the distortion as a function of the joint distribution ensures that they are also typical distortions (see [2], Chapters 10.5 and 10.6). Hence, the distortion between these and their codewords is bounded by where goes to 0 as . In the first-order analysis, that is, , we can regard as D.
- Strongly typical sequences such that .
- Non-strongly typical sequences .
The sequences in the second and third categories are encoded as The sequences of third categories are the sequences that can be bounded by such the distortion as in excess of D. Then, the excess-distortion probability is evaluated as
Hence, for an appropriate choice of and n, we can ensure the excess-distortion probability of all badly represented sequences are as small as we want. We obtain (113).
We can evaluate privacy leakage against the encoder as below.
where
- (e)
- is due to chain rule for mutual information and
- (f), (g)
- follows because .
Thus, we have (114).
Next, we show that the probability that random vector is not included in the set and is sufficiently small. First, notice that
where is the index such that for . Therefore, by the union’s upper bound,
We evaluate each term in (A68).
- (i)
- The first term:where
- (h)
- is because of (A62).
- (ii)
- The second term:If the event in the second term occurs, and . Therefore, from Lemma 5, holds. Hence,where
- (i)
- is due to the Markov chain ,
- (j)
- follows since and Lemma 6,
- (k)
- follows because is disjoint for each j.
From (A68)–(A70),
Therefore, for sufficiently large n,
and we obtain (115).
From Lemma 1, for sufficiently large n to stochastic matrix and we can show that
We can also show from (A73) that
From the definition of and and Lemma 4, for , we have
This means
Therefore, from (A74) and (A77),
and we obtain (116).
References
- Yamamoto, H. A source coding problem for sources with additional outputs to keep secret from the receiver or wiretappers. IEEE Trans. Inf. Theory 1983, 29, 918–923. [Google Scholar] [CrossRef] [Green Version]
- Sankar, L.; Rajagopalan, S.R.; Poor, H.V. Utility–Privacy tradeoff in databases: An information-theoretic approach. IEEE Trans. Inf. Forensics Secur. 2013, 8, 838–852. [Google Scholar] [CrossRef] [Green Version]
- Shinohara, N.; Yagi, H. Unified expression of utility–privacy trade-off in privacy-constrained source coding. In Proceedings of the 2022 International Symposium on Information Theory and Its Applications (ISITA2022), Tsukuba, Japan, 17–19 October 2022; pp. 198–202. [Google Scholar]
- Ingber, A.; Kochman, Y. The dispersion of lossy source coding. In Proceedings of the 2011 Data Compression Conference, Snowbird, UT, USA, 29–31 March 2011; pp. 53–62. [Google Scholar]
- Kostina, V.; Verdú, S. Fixed length lossy compression in the finite blocklength regime: Discrete memoryless sources. IEEE Trans. Inf. Theory 2012, 58, 3309–3338. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, S. Second-order region for Gray-Wyner network. IEEE Trans. Inf. Theory 2017, 63, 1006–1018. [Google Scholar] [CrossRef] [Green Version]
- Tyagi, H.; Watanabe, S. Strong converse using change of measure arguments. IEEE Trans. Inf. Theory 2020, 66, 689–703. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the 3rd Conference Theory Cryptograph (TCC), New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the 33rd International Conference Automata, Languages and Programming (ICALP), Venice, Italy, 10–14 July 2006; pp. 1–12. [Google Scholar]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sánchez, D.; Megías, D. Individual differential privacy: A utility-preserving formulation of differential privacy guarantees. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Kalantari, K.; Sankar, L.; Sarwate, A.D. Robust privacy-utility tradeoffs under differential privacy and hamming distortion. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2816–2830. [Google Scholar] [CrossRef] [Green Version]
- Makhdoumi, A.; Fawaz, N. Privacy-utility tradeoff under statistical uncertainty. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; pp. 1627–1634. [Google Scholar]
- Basciftci, Y.O.; Wang, Y.; Ishwar, P. On privacy-utility tradeoffs for constrained data release mechanisms. In Proceedings of the 2016 Information Theory and Applications Workshop (ITA), La Jolla, CA, USA, 31 January–5 February 2016; pp. 1–6. [Google Scholar]
- Günlü, O.; Schaefer, R.F.; Boche, H.; Poor, H.V. Secure and private source coding with private key and decoder side information. In Proceedings of the 2022 IEEE Information Theory Workshop (ITW), Mumbai, India, 6–9 November 2022; pp. 226–231. [Google Scholar]
- Issa, I.; Wagner, A.B.; Kamath, S. An operational approach to information leakage. IEEE Trans. Inf. Theory 2020, 66, 1625–1657. [Google Scholar] [CrossRef] [Green Version]
- Liao, J.; Kosut, O.; Sankar, L.; Calmon, F.P. Privacy under hard distortion constraints. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW2018), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar]
- Liao, J.; Kosut, O.; Sankar, L.; Calmon, F.P. Tunable measures for information leakage and applications to privacy-utility tradeoffs. IEEE Trans. Inf. Theory 2019, 65, 8043–8066. [Google Scholar] [CrossRef] [Green Version]
- Saeidian, S.; Cervia, G.; Oechtering, T.J.; Skoglund, M. Quantifying membership privacy via information leakage. IEEE Trans. Inf. Forensics Secur. 2020, 16, 3096–3108. [Google Scholar] [CrossRef]
- Rassouli, B.; Gündüz, D. Optimal utility–privacy trade-off with total variation distance as a privacy measure. IEEE Trans. Inf. Forensics Secur. 2019, 15, 594–603. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Ying, L.; Zhang, J. On the relation between identifiability, differential privacy, and mutual-information privacy. IEEE Trans. Inf. Theory 2016, 62, 5018–5029. [Google Scholar] [CrossRef] [Green Version]
- Liao, J.; Sankar, L.; Kosut, O.; Calmon, F.P. Maximal α-leakage and its properties. In Proceedings of the 2020 IEEE Conference on Communications and Network Security (CNS), Virtual, 29 June–1 July 2020; pp. 1–6. [Google Scholar]
- Shinohara, N.; Yagi, H. Strong converse theorem for utility–privacy trade-offs. In Proceedings of the 45th Symposium on Information Theory and Its Applications (SITA2022), Noboribetsu, Japan, 29 November–2 December 2022; pp. 338–343. [Google Scholar]
- Guan, Z.; Si, G.; Wu, J.; Zhu, L.; Zhang, Z.; Ma, Y. Utility–privacy tradeoff based on random data obfuscation in internet of energy. IEEE Access 2017, 5, 3250–3262. [Google Scholar] [CrossRef]
- Asikis, T.; Pournaras, E. Optimization of privacy-utility trade-offs under informational self-determination. Future Gener. Comput. Syst. 2020, 109, 488–499. [Google Scholar] [CrossRef]
- Lu, J.; Xu, Y.; Zhu, Z. On scalable source coding problem with side information privacy. In Proceedings of the 2022 14th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 1–3 November 2022; pp. 415–420. [Google Scholar]
- Makhdoumi, A.; Salamatian, S.; Fawaz, N.; Médard, M. From the information bottleneck to the privacy funnel. In Proceedings of the 2014 IEEE Information Theory Workshop (ITW), Hobart, Australia, 2–5 November 2014; pp. 501–505. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John & Wiley Sons, Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Uyematsu, T. Gendai Shannon Riron, 1st ed.; Baihukan: Tokyo, Japan, 1998. (In Japanese) [Google Scholar]
- Csizar, L.; Korner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems, 2nd ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Sason, I.; Verdú, S. Improved bounds on lossless source coding and guessing moments via Rényi measures. IEEE Trans. Inf. Theory 2018, 64, 4323–4346. [Google Scholar] [CrossRef] [Green Version]
- El Gamal, A.; Kim, Y.H. Network Information Theory, 1st ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
Figure 1.
Privacy-constrained coding system.


Figure 3.
The region expressed with a tangent plane using the Legendre transformation.

Figure 4.
Utility–privacy trade-off region in cases (i), (ii), and (iii).

Figure 5.
Utility–coding-rate trade-off region in cases (i), (ii), and (iii). The curves coincide in all cases.
Figure 5.
Utility–coding-rate trade-off region in cases (i), (ii), and (iii). The curves coincide in all cases.

Figure 6.
Hasse diagram that represents the inclusion relation for the index sets of attributes.

Figure 7.
Hasse diagram for Step 1.

Figure 8.
Hasse diagram for Step 2.

Figure 9.
Hasse diagram obtained after Step 2.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Minimum L and its corresponding R for .
| Cases | Leakage L | Coding Rate R |
|---|---|---|
| case (ii) | 0.019512 | 0.494629 |
| case (iii) | 0.008298 | 0.527700 |
| case (i) | 0.005107 | 0.539478 |
Table 2.
Minimum L and its corresponding R for .
| Cases | Leakage L | Coding Rate R |
|---|---|---|
| case (ii) | 0.015378 | 0.368062 |
| case (iii) | 0.002656 | 0.418826 |
| case (i) | 0.000000 | 0.429490 |
Table 3.
Minimum L and its corresponding R for .
| Cases | Leakage L | Coding Rate R |
|---|---|---|
| case (ii) | 0.011748 | 0.270436 |
| case (iii) | 0.002032 | 0.294424 |
| case (i) | 0.000000 | 0.382211 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Shinohara, N.; Yagi, H. Utility–Privacy Trade-Offs with Limited Leakage for Encoder. Entropy 2023, 25, 921. https://doi.org/10.3390/e25060921
AMA Style
Shinohara N, Yagi H. Utility–Privacy Trade-Offs with Limited Leakage for Encoder. Entropy. 2023; 25(6):921. https://doi.org/10.3390/e25060921
Chicago/Turabian StyleShinohara, Naruki, and Hideki Yagi. 2023. "Utility–Privacy Trade-Offs with Limited Leakage for Encoder" Entropy 25, no. 6: 921. https://doi.org/10.3390/e25060921
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.