
Natural Language Generation and Understanding of Big Code for AI-Assisted Programming: A Review


Abstract
:1. Introduction
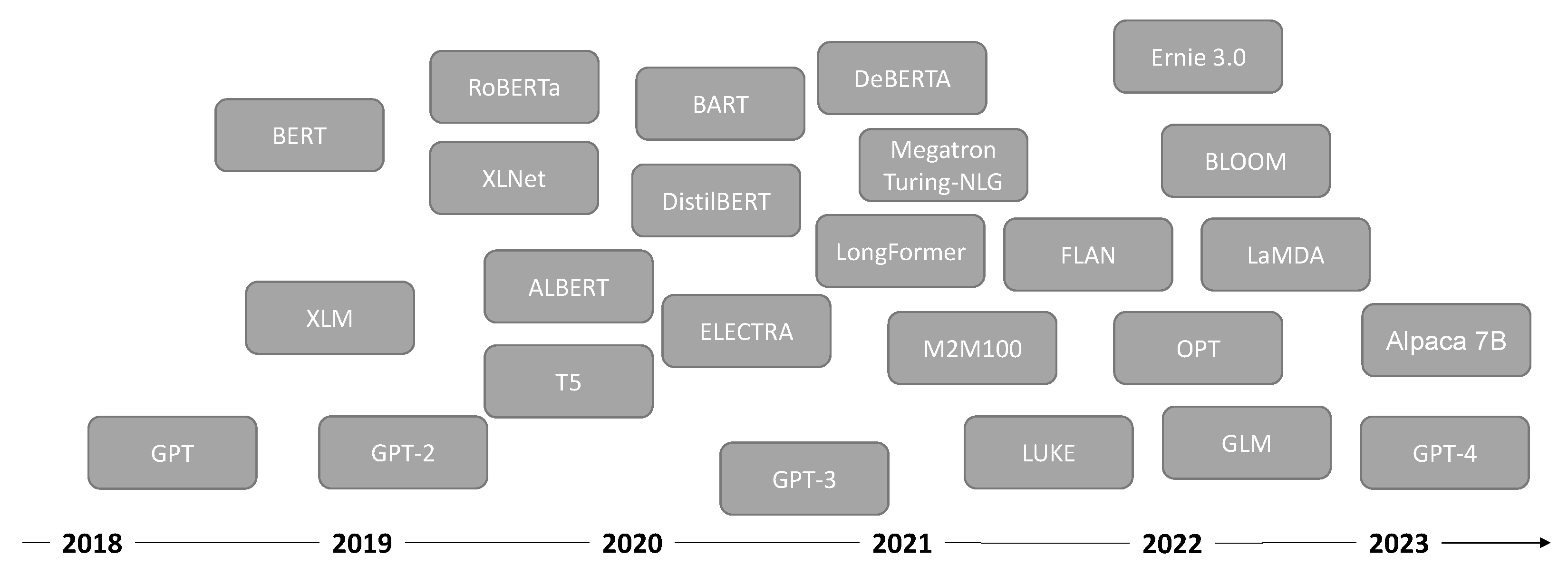
2. Background
2.1. Main Big Code Dataset
2.2. Tokenization
2.3. Language Models on Software Naturalness
2.4. Measurement of Language Models with Entropy
3. AI-Assisted Programming Tasks
3.1. Code Generation
3.2. Code Completion
3.3. Code Translation
3.4. Code Refinement
3.5. Code Summarization
3.6. Defect Detection
3.7. Clone Detection

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Framework | Year | Task(s) | Baseline(s) | Supported Language(s) | Open Sourced |
|---|---|---|---|---|---|
| Refactory [137] | 2019 | Defect Detection | BLEU | Java | ✗ |
| CuBERT [138] | 2020 | Code Refinement, Defect Detection | BERT | Python | ✓ |
| CugLM [139] | 2020 | Code Completion | BERT | Java, TypeScript | ✓ |
| Intellicode [140] | 2020 | Code Generation, Code Completion | GPT-2 | Python, C#, JavaScript, and TypeScrip | ✗ |
| Great [141] | 2020 | Defect Detection | Vanilla Transformers | Python | ✓ |
| TreeGEN [51] | 2020 | Code Generation | Vanilla Transformers | Python | ✓ |
| C-BERT [127] | 2020 | Defect Detection | BERT | C | ✗ |
| TransCoder [142] | 2020 | Code Translation | Vanilla Transformers | C++, Java, and Python | ✗ |
| GraphCodeBERT [143] | 2020 | Code Summarization, Code Refinement | BERT | Java | ✗ |
| Codex [35] | 2021 | Code Generation, Code Completion, Code Summarization, Benchmark | GPT-3 | JavaScript, Go, Perl, and 6 more | ✗ |
| Copilot [144] | 2021 | Code Generation, Code Completion | Codex | Java, PHP, Python, and 5 more | ✗ |
| CodeT5 [145] | 2021 | Code Summarization, Code Generation, Code Translation, Code Refinement, Defect Detection, Clone Detection | T5 | Python, Java | ✓ |
| Tfix [146] | 2021 | Code Refinement, Defect Detection | T5 | JavaScript | ✓ |
| CodeRL [147] | 2021 | Code Summarization, Code Generation, Code Translation, Code Refinement, Defect Detection, Clone Detection | T5 | Java | ✓ |
| TreeBERT [148] | 2021 | Code Summarization | Vanilla Transformers | Python, Java | ✓ |
| BUGLAB [149] | 2021 | Code Refinement, Defect Detection | GREAT | Python | ✓ |
| TBCC [150] | 2021 | Clone Detection | Vanilla Transformers | C, Java | ✓ |
| APPS [36] | 2021 | Benchmark | N/A | Python | ✓ |
| CodeXGLUE [34] | 2021 | Benchmark | N/A | Python | ✓ |
| CoTexT [151] | 2021 | Code Summarization, Code Generation, Code Refinement, Defect detection | T5 | Python, Java, Javascript, PHP, Ruby, Go | ✓ |
| SynCoBERT [152] | 2021 | Code Translation, Defect Detection, Clone Detection | BERT | Ruby, Javascript, Go, Python, Java, PHP | ✗ |
| TravTrans [153] | 2021 | Code Completion | Vanilla Transformers | Python | ✗ |
| CCAG [154] | 2021 | Code Completion | Vanilla Transformers | JavaScript, Python | ✗ |
| DeepDebug [155] | 2021 | Defect Detection | Reformer | Java | ✓ |
| Recoder [93] | 2021 | Defect Detection | TreeGen | Java | ✓ |
| PLBART [156] | 2021 | Code Summarization, Code Generation, Code Translation, Code Refinement, Clone Detection, Detect Detection | BART | Java, Python | ✗ |
| CODEGEN [157] | 2022 | Code Generation | GPT-NEO & GPT-J | Python | ✓ |
| GPT-2 for APR [158] | 2022 | Code Refinement | GPT-2 | JavaScript | ✓ |
| CERT [39] | 2022 | Code Generation | CODEGEN | Python | ✓ |
| PyCoder [87] | 2022 | Code Generation | GPT-2 | Python | ✓ |
| AlphaCode [38] | 2022 | Code Generation | GPT | Java | ✗ |
| InCoder [40] | 2022 | Code Generation, Code Completion, Code Summarization | GPT-3 | Java, JavaScript, Python | ✓ |
| RewardRepair [159] | 2022 | Code Refinement, Defect Detection | T5 | Java | ✓ |
| CodeParrot [37] | 2022 | Code Generation | GPT-2 | Python | ✓ |
| AlphaRepair [160] | 2022 | Code Refinement, Defect Detection | CodeBERT | Java | ✓ |
| CodeReviewer [128] | 2022 | Code Summarization, Code Refinement, Defect Detection | CodeT5 | Java | ✓ |
| TransRepair [161] | 2022 | Code Refinement, Defect Detection | BLEU | Java | ✗ |
| NatGen [162] | 2022 | Code Generation, Code Translation, Code Refinement | CodeT5 | Java, Python, Go, JavaScript, Ruby, PHP | ✓ |
| DualSC [163] | 2022 | Code Generation, Code Summarization | T5 | Shellcode | ✓ |
| VulRepair [164] | 2022 | Code Refinement, Defect Detection | T5 | C, C++ | ✓ |
| CoditT5 [165] | 2022 | Code Summarization, Defect Detection | CodeT5 | Java, Python, Ruby, PHP, Go, JavaScript | ✓ |
| C4 [166] | 2022 | Clone Detection | CodeBERT | C++, C#, Java, Python | ✓ |
| SPT-Code [167] | 2022 | Code Summarization, Code Completion, Code Refinement, Code Translation | CodeBERT & GraphCodeBERT | Python, Java, JavaScript, PHP, Go | ✓ |
| ExploitGen [168] | 2023 | Code Generation | CodeBERT | Python, Assembly | ✓ |
| Santacoder [169] | 2023 | Code Summarization, Code Generation | GPT-2 | Python, Java, and Javascript | ✓ |
| xCodeEval [42] | 2023 | Benchmark | N/A | Python, Java, C++, PHP, and 8 more | ✓ |
| StarCoder [170] | 2023 | Code Generation, Code Completion, Code Summarization | BERT & SantaCoder | HTML, Python, Java, and 83 more | ✓ |
4. Challenges and Opportunities
4.1. Computational Expense
4.2. Quality Measurement
4.3. Software Security
4.4. Software Piracy
4.5. Integration with Existing Tools
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Vechev, M.; Yahav, E. Programming with “Big Code”. Found. Trends® Program. Lang. 2016, 3, 231–284. [Google Scholar] [CrossRef]
- Hindle, A.; Barr, E.T.; Su, Z.; Gabel, M.; Devanbu, P. On The Naturalness of Software. In Proceedings of the 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 837–847. [Google Scholar]
- Goodman, J.T. A bit of progress in language modeling. In Computer Speech & Language; Elsevier: Amsterdam, The Netherlands, 2001; pp. 403–434. [Google Scholar]
- Dijkstra, E.W. A Preliminary Investigation into Computer Assisted Programming; The University of Texas: Austin, TX, USA, 2007. [Google Scholar]
- Rajamani, S. AI Assisted Programming. In Proceedings of the 15th Annual ACM India Compute Conference, Jaipur, India, 9–11 November 2022; p. 5. [Google Scholar]
- Dijkstra, E.W. The Humble Programmer. Commun. ACM 1972, 15, 859–866. [Google Scholar] [CrossRef]
- Ji, Y.; Bosselut, A.; Wolf, T.; Celikyilmaz, A. The Amazing World of Neural Language Generation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: Tutorial Abstracts, Virtual, 19–20 November 2020; pp. 37–42. [Google Scholar]
- Surameery, N.M.S.; Shakor, M.Y. Use ChatGPT to Solve Programming Bugs. Int. J. Inf. Technol. Comput. Eng. (IJITC) 2023, 3, 17–22. [Google Scholar]
- Talamadupula, K. Applied AI Matters: AI4Code: Applying Artificial Intelligence to Source Code. AI Matters 2021, 7, 18–20. [Google Scholar] [CrossRef]
- Ross, S.I.; Martinez, F.; Houde, S.; Muller, M.; Weisz, J.D. The Programmer’s Assistant: Conversational Interaction with a Large Language Model for Software Development. In Proceedings of the 28th International Conference on Intelligent User Interfaces, Sydney, Australia, 27–31 March 2023; pp. 491–514. [Google Scholar]
- Mehrabi, N.; Morstatter, F.; Saxena, N.; Lerman, K.; Galstyan, A. A Survey on Bias and Fairness in Machine Learning. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A Survey on Explainable Artificial Intelligence (XAI): Toward Medical XAI. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef] [PubMed]
- Beigi, G.; Liu, H. A Survey on Privacy in Social Media: Identification, Mitigation, and Applications. ACM Trans. Data Sci. 2020, 1, 1–38. [Google Scholar] [CrossRef]
- Allamanis, M.; Barr, E.T.; Devanbu, P.; Sutton, C. A Survey of Machine Learning for Big Code and Naturalness. ACM Comput. Surv. (CSUR) 2018, 51, 1–37. [Google Scholar] [CrossRef]
- Lin, G.; Wen, S.; Han, Q.L.; Zhang, J.; Xiang, Y. Software Vulnerability Detection using Deep Neural Networks: A Survey. Proc. IEEE 2020, 108, 1825–1848. [Google Scholar] [CrossRef]
- Sharma, T.; Kechagia, M.; Georgiou, S.; Tiwari, R.; Vats, I.; Moazen, H.; Sarro, F. A Survey on Machine Learning Techniques for Source Code Analysis. arXiv 2022, arXiv:2110.09610. [Google Scholar]
- Sonnekalb, T.; Heinze, T.S.; Mäder, P. Deep Security Analysis of Program Code: A Systematic Literature Review. Empir. Softw. Eng. 2022, 27, 2. [Google Scholar] [CrossRef]
- Xu, Y.; Zhu, Y. A Survey on Pretrained Language Models for Neural Code Intelligence. arXiv 2022, arXiv:2212.10079. [Google Scholar]
- Niu, C.; Li, C.; Luo, B.; Ng, V. Deep Learning Meets Software Engineering: A Survey on Pre-trained Models of Source Code. In Proceedings of the 31st International Joint Conference on Artificia Intelligence (IJCAI-22), Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Ciancarini, P.; Farina, M.; Okonicha, O.; Smirnova, M.; Succi, G. Software as Storytelling: A Systematic Literature Review. Comput. Sci. Rev. 2023, 47, 100517. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. (CSUR) 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Allamanis, M.; Sutton, C. Mining Source Code Repositories at Massive Scale using Language Modeling. In Proceedings of the 10th Working Conference on Mining Software Repositories, San Francisco, CA, USA, 18–19 May 2013; pp. 207–216. [Google Scholar]
- Description2Code Dataset. 2016. Available online: https://github.com/ethancaballero/description2code (accessed on 18 May 2023).
- Svajlenko, J.; Roy, C.K. Description2Code Dataset. 2021. Available online: https://github.com/clonebench/BigCloneBench (accessed on 18 May 2023).
- Chen, Z.; Monperrus, M. The CodRep Machine Learning on Source Code Competition. arXiv 2018, arXiv:1807.03200. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Mapping Language to Code in Programmatic Context. arXiv 2018, arXiv:1808.09588. [Google Scholar]
- Zhong, V.; Xiong, C.; Socher, R. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning. arXiv 2017, arXiv:1709.00103. [Google Scholar]
- Tufano, M.; Watson, C.; Bavota, G.; Penta, M.D.; White, M.; Poshyvanyk, D. An Empirical Study on Learning Bug-fixing Patches in the Wild via Neural Machine Translation. ACM Trans. Softw. Eng. Methodol. (TOSEM) 2019, 28, 1–29. [Google Scholar] [CrossRef]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Husain, H.; Wu, H.H.; Gazit, T.; Allamanis, M.; Brockschmidt, M. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search. arXiv 2019, arXiv:1909.09436. [Google Scholar]
- Gao, L.; Biderman, S.; Black, S.; Golding, L.; Hoppe, T.; Foster, C.; Phang, J.; He, H.; Thite, A.; Nabeshima, N.; et al. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. arXiv 2020, arXiv:2101.00027. [Google Scholar]
- Puri, R.; Kung, D.S.; Janssen, G.; Zhang, W.; Domeniconi, G.; Zolotov, V.; Dolby, J.; Chen, J.; Choudhury, M.; Decker, L.; et al. CodeNet: A Large-scale AI for Code Dataset for Learning a Diversity of Coding Tasks. arXiv 2021, arXiv:2105.12655. [Google Scholar]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A.; Blanco, A.; Clement, C.B.; Drain, D.; Jiang, D.; Tang, D.; et al. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation. arXiv 2021, arXiv:2102.04664. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Hendrycks, D.; Basart, S.; Kadavath, S.; Mazeika, M.; Arora, A.; Guo, E.; Burns, C.; Puranik, S.; He, H.; Song, D.; et al. Measuring Coding Challenge Competence With APPS. arXiv 2021, arXiv:2105.09938. [Google Scholar]
- Tunstall, L.; Von Werra, L.; Wolf, T. Natural Language Processing with Transformers; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2022. [Google Scholar]
- Li, Y.; Choi, D.; Chung, J.; Kushman, N.; Schrittwieser, J.; Leblond, R.; Eccles, T.; Keeling, J.; Gimeno, F.; Dal Lago, A.; et al. Competition-level Code Generation with Alphacode. Science 2022, 378, 1092–1097. [Google Scholar] [CrossRef]
- Zan, D.; Chen, B.; Yang, D.; Lin, Z.; Kim, M.; Guan, B.; Wang, Y.; Chen, W.; Lou, J.G. CERT: Continual Pre-training on Sketches for Library-oriented Code Generation. In Proceedings of the 31st International Joint Conference on Artificia Intelligence (IJCAI-22), Vienna, Austria, 23–29 July 2022. [Google Scholar]
- Fried, D.; Aghajanyan, A.; Lin, J.; Wang, S.; Wallace, E.; Shi, F.; Zhong, R.; Yih, W.t.; Zettlemoyer, L.; Lewis, M. Incoder: A Generative Model for Code Infilling and Synthesis. arXiv 2022, arXiv:2204.05999. [Google Scholar]
- Xu, F.F.; Alon, U.; Neubig, G.; Hellendoorn, V.J. A Systematic Evaluation of Large Language Models of Code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, San Diego, CA, USA, 13 June 2022; pp. 1–10. [Google Scholar]
- Khan, M.A.M.; Bari, M.S.; Do, X.L.; Wang, W.; Parvez, M.R.; Joty, S. xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval. arXiv 2023, arXiv:2303.03004. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017.
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring The Limits of Transfer Learning with a Unified Text-to-text Transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Sun, Z.; Zhu, Q.; Xiong, Y.; Sun, Y.; Mou, L.; Zhang, L. Treegen: A Tree-based Transformer Architecture for Code Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8984–8991. [Google Scholar]
- Morin, F.; Bengio, Y. Hierarchical Probabilistic Neural Network Language Model. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, Bridgetown, Barbados, 6–8 January 2005; pp. 246–252. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. Code2Vec: Learning Distributed Representations of Code; ACM: New York, NY, USA, 2019; Volume 3, pp. 1–29. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing order into text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Allamanis, M.; Brockschmidt, M.; Khademi, M. Learning to Represent Programs with Graphs. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Wang, B.; Komatsuzaki, A. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. 2021. Available online: https://github.com/kingoflolz/mesh-transformer-jax (accessed on 18 May 2023).
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. In Proceedings of the International Conference on Learning Representations, Virtual, 26–30 April 2020. [Google Scholar]
- Black, S.; Gao, L.; Wang, P.; Leahy, C.; Biderman, S. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow. 2021. Available online: https://github.com/EleutherAI/gpt-neo (accessed on 18 May 2023).
- Jurafsky, D.; Martin, J.H. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, 1st ed.; Prentice Hall PTR: Hoboken, NJ, USA, 2000. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A Neural Probabilistic Language Model. In Proceedings of the Advances in Neural Information Processing Systems 13 (NIPS 2000), Denver, CO, USA, 27 November–2 December 2000. [Google Scholar]
- Katz, S. Estimation of Probabilities from Sparse Data for the Language Model Component of a Speech Recognizer. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 400–401. [Google Scholar] [CrossRef]
- Brown, P.F.; Della Pietra, V.J.; Desouza, P.V.; Lai, J.C.; Mercer, R.L. Class-based N-gram Models of Natural Language. Comput. Linguist. 1992, 18, 467–480. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Shannon, C.E. Prediction and Entropy of Printed English. Bell Syst. Tech. J. 1951, 30, 50–64. [Google Scholar] [CrossRef]
- Mozannar, H.; Bansal, G.; Fourney, A.; Horvitz, E. Reading Between the Lines: Modeling User Behavior and Costs in AI-Assisted Programming. arXiv 2022, arXiv:2210.14306. [Google Scholar]
- Ho, S.W.; Yeung, R.W. The Interplay between Entropy and Variational Distance. IEEE Trans. Inf. Theory 2010, 56, 5906–5929. [Google Scholar] [CrossRef]
- Kennel, M.B.; Shlens, J.; Abarbanel, H.D.; Chichilnisky, E. Estimating Entropy Rates with Bayesian Confidence Intervals. Neural Comput. 2005, 17, 1531–1576. [Google Scholar] [CrossRef]
- Feutrill, A.; Roughan, M. A Review of Shannon and Differential Entropy Rate Estimation. Entropy 2021, 23, 1046. [Google Scholar] [CrossRef] [PubMed]
- Paninski, L. Estimation of Entropy and Mutual Information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef]
- Waldinger, R.J.; Lee, R.C. PROW: A Step toward Automatic Program Writing. In Proceedings of the 1st International Joint Conference on Artificial Intelligence, Washington, DC, USA, 7–9 May 1969; pp. 241–252. [Google Scholar]
- Manna, Z.; Waldinger, R.J. Toward Automatic Program Synthesis. Commun. ACM 1971, 14, 151–165. [Google Scholar] [CrossRef]
- Manna, Z.; Waldinger, R. Knowledge and Reasoning in Program Synthesis. Artif. Intell. 1975, 6, 175–208. [Google Scholar] [CrossRef]
- Green, C. Application of Theorem Proving to Problem Solving. In Readings in Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 1981; pp. 202–222. [Google Scholar]
- Dong, L.; Lapata, M. Language to Logical Form with Neural Attention. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 33–43. [Google Scholar]
- Parisotto, E.; Mohamed, A.r.; Singh, R.; Li, L.; Zhou, D.; Kohli, P. Neuro-Symbolic Program Synthesis. arXiv 2016, arXiv:1611.01855. [Google Scholar]
- Lin, C.Y.; Och, F.J. Orange: A Method for Evaluating Automatic Evaluation Metrics for Machine Translation. In Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; pp. 501–507. [Google Scholar]
- Austin, J.; Odena, A.; Nye, M.; Bosma, M.; Michalewski, H.; Dohan, D.; Jiang, E.; Cai, C.; Terry, M.; Le, Q.; et al. Program Synthesis with Large Language Models. arXiv 2021, arXiv:2108.07732. [Google Scholar]
- Dong, Y.; Gu, T.; Tian, Y.; Sun, C. SnR: Constraint-based Type Inference for Incomplete Java Code Snippets. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 1982–1993. [Google Scholar]
- Amazon, C. AI Code Generator—Amazon CodeWhisperer. Available online: https://aws.amazon.com/codewhisperer (accessed on 18 May 2023).
- Robbes, R.; Lanza, M. How Program History Can Improve Code Completion. In Proceedings of the 23rd IEEE/ACM International Conference on Automated Software Engineering, L’aquila, Italy, 15–16 September 2008; pp. 317–326. [Google Scholar]
- Bruch, M.; Monperrus, M.; Mezini, M. Learning from Examples to Improve Code Completion Systems. In Proceedings of the 7th Joint Meeting of The European Software Engineering Conference and The ACM SIGSOFT Symposium on The Foundations of Software Engineering, Amsterdam, The Netherlands, 24–28 August 2009; pp. 213–222. [Google Scholar]
- Svyatkovskiy, A.; Zhao, Y.; Fu, S.; Sundaresan, N. Pythia: Ai-assisted code completion system. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2727–2735. [Google Scholar]
- Takerngsaksiri, W.; Tantithamthavorn, C.; Li, Y.F. Syntax-Aware On-the-Fly Code Completion. arXiv 2022, arXiv:2211.04673. [Google Scholar]
- Koehn, P.; Federico, M.; Shen, W.; Bertoldi, N.; Bojar, O.; Callison-Burch, C.; Cowan, B.; Dyer, C.; Hoang, H.; Zens, R.; et al. Open Source Toolkit for Statistical Machine Translation: Factored Translation Models and Confusion Network Decoding. In Proceedings of the CLSP Summer Workshop Final Report WS-2006, Baltimore, MD, USA, 1 June–1 August 2007. [Google Scholar]
- Artetxe, M.; Labaka, G.; Agirre, E. Unsupervised Statistical Machine Translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Allamanis, M.; Barr, E.T.; Bird, C.; Sutton, C. Learning Natural Coding Conventions. In Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, Hong Kong, China, 16–21 November 2014; pp. 281–293. [Google Scholar]
- Acharya, M.; Xie, T.; Pei, J.; Xu, J. Mining API Patterns as Partial Orders from Source Code: From Usage Scenarios to Specifications. In Proceedings of the 6th Joint Meeting of The European Software Engineering Conference and The ACM SIGSOFT Symposium on The Foundations of Software Engineering, Dubrovnikm, Croatia, 3–7 September 2007; pp. 25–34. [Google Scholar]
- Jiang, N.; Lutellier, T.; Tan, L. Cure: Code-aware Neural Machine Translation for Automatic Program Repair. In Proceedings of the IEEE/ACM 43rd International Conference on Software Engineering, Madrid, Spain, 22–30 May 2021; pp. 1161–1173. [Google Scholar]
- Zhu, Q.; Sun, Z.; Xiao, Y.a.; Zhang, W.; Yuan, K.; Xiong, Y.; Zhang, L. A Syntax-guided Edit Decoder for Neural Program Repair. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2021; pp. 341–353. [Google Scholar]
- Jiang, J.; Xiong, Y.; Zhang, H.; Gao, Q.; Chen, X. Shaping Program Repair Space with Existing Patches and Similar Code. In Proceedings of the 27th ACM SIGSOFT International Symposium On Software Testing And Analysis, Amsterdam, The Netherlands, 16–21 July 2018; pp. 298–309. [Google Scholar]
- Liu, K.; Koyuncu, A.; Kim, D.; Bissyandé, T.F. TBar: Revisiting Template-based Automated Program Repair. In Proceedings of the 28th ACM SIGSOFT International Symposium on Software Testing and Analysis, Beijing China, 15–19 July 2019; pp. 31–42. [Google Scholar]
- Yuan, Y.; Banzhaf, W. Arja: Automated Repair of Java Programs via Multi-objective Genetic Programming. IEEE Trans. Softw. Eng. 2018, 46, 1040–1067. [Google Scholar] [CrossRef]
- Wen, M.; Chen, J.; Wu, R.; Hao, D.; Cheung, S.C. Context-aware patch generation for better automated program repair. In Proceedings of the 40th International Conference on Software Engineering, Gothenburg, Sweden, 27 May–3 June 2018; pp. 1–11. [Google Scholar]
- Saha, R.K.; Lyu, Y.; Yoshida, H.; Prasad, M.R. Elixir: Effective Object-oriented Program Repair. In Proceedings of the 32nd IEEE/ACM International Conference on Automated Software Engineering, Urbana-Champaign, IL, USA, 30 October–3 November 2017; pp. 648–659. [Google Scholar]
- Xiong, Y.; Wang, J.; Yan, R.; Zhang, J.; Han, S.; Huang, G.; Zhang, L. Precise Condition Synthesis for Program Repair. In Proceedings of the IEEE/ACM 39th International Conference on Software Engineering, Buenos Aires, Argentina, 20–28 May 2017; pp. 416–426. [Google Scholar]
- Xuan, J.; Martinez, M.; Demarco, F.; Clement, M.; Marcote, S.L.; Durieux, T.; Le Berre, D.; Monperrus, M. Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs. IEEE Trans. Softw. Eng. 2016, 43, 34–55. [Google Scholar] [CrossRef]
- Just, R.; Jalali, D.; Ernst, M.D. Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs. In Proceedings of the International Symposium on Software Testing and Analysis, San Jose, CA, USA, 21–25 July 2014; pp. 437–440. [Google Scholar]
- Lin, D.; Koppel, J.; Chen, A.; Solar-Lezama, A. QuixBugs: A Multi-lingual Program Repair Benchmark Set Based on The Quixey Challenge. In Proceedings of the ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software for Humanity, Vancouver, BC, Canada, 22–27 October 2017; pp. 55–56. [Google Scholar]
- Jiang, N.; Liu, K.; Lutellier, T.; Tan, L. Impact of Code Language Models on Automated Program Repair. In Proceedings of the IEEE/ACM 45th International Conference on Software Engineering, Melbourne, Australia, 14–20 May 2023. [Google Scholar]
- Sridhara, G.; Hill, E.; Muppaneni, D.; Pollock, L.; Vijay-Shanker, K. Towards Automatically Generating Summary Comments for Java Methods. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering, Antwerp, Belgium, 20–24 September 2010; pp. 43–52. [Google Scholar]
- Moreno, L.; Aponte, J.; Sridhara, G.; Marcus, A.; Pollock, L.; Vijay-Shanker, K. Automatic Generation of Natural Language Summaries for Java Classes. In Proceedings of the 21st International Conference on Program Comprehension, San Francisco, CA, USA, 20–21 May 2013. [Google Scholar]
- Sridhara, G.; Pollock, L.; Vijay-Shanker, K. Generating Parameter Comments and Integrating with Method Summaries. In Proceedings of the IEEE 19th International Conference on Program Comprehension, Kingston, ON, Canada, 22–24 June 2011; pp. 71–80. [Google Scholar]
- Ahmad, W.; Chakraborty, S.; Ray, B.; Chang, K.W. A Transformer-based Approach for Source Code Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Virtual, 5–10 July 2020; pp. 4998–5007. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Zettlemoyer, L. Summarizing Source Code Using a Neural Attention Model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 2073–2083. [Google Scholar]
- Allamanis, M.; Peng, H.; Sutton, C. A Convolutional Attention Network for Extreme Summarization of Source Code. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 2091–2100. [Google Scholar]
- Chen, Q.; Zhou, M. A Neural Framework for Retrieval and Summarization of Source Code. In Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering, Montpellier, France, 3–7 September 2018; pp. 826–831. [Google Scholar]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolutional Neural Networks Over Tree Structures for Programming Language Processing. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Liang, Y.; Zhu, K. Automatic Generation of Text Descriptive Comments for Code Blocks. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Tufano, M.; Watson, C.; Bavota, G.; Di Penta, M.; White, M.; Poshyvanyk, D. Deep Learning Similarities From Different Representations of Source Code. In Proceedings of the 15th International Conference on Mining Software Repositories, Gothenburg, Sweden, 27 May–3 June 2018. [Google Scholar]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric Transitivity Preserving Graph Embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1105–1114. [Google Scholar]
- Livshits, B.; Zimmermann, T. Dynamine: Finding Common Error Patterns by Mining Software Revision Histories. ACM SIGSOFT Softw. Eng. Notes 2005, 30, 296–305. [Google Scholar] [CrossRef]
- Wasylkowski, A.; Zeller, A.; Lindig, C. Detecting Object Usage Anomalies. In Proceedings of the 6th Joint Meeting of The European Software Engineering Conference and The ACM SIGSOFT Symposium on The Foundations of Software Engineering, Dubrovnik, Croatia, 3–7 September 2007; pp. 35–44. [Google Scholar]
- Charniak, E. Statistical Language Learning; MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Nessa, S.; Abedin, M.; Wong, W.E.; Khan, L.; Qi, Y. Software Fault Localization Using N-gram Analysis. In Proceedings of the Wireless Algorithms, Systems, and Applications: 3rd International Conference, Dallas, TX, USA, 26–28 October 2008; pp. 548–559. [Google Scholar]
- Wang, S.; Chollak, D.; Movshovitz-Attias, D.; Tan, L. Bugram: Bug Detection with N-gram Language Models. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 708–719. [Google Scholar]
- Lin, G.; Zhang, J.; Luo, W.; Pan, L.; Xiang, Y.; De Vel, O.; Montague, P. Cross-project Transfer Representation Learning for Vulnerable Function Discovery. IEEE Trans. Ind. Inform. 2018, 14, 3289–3297. [Google Scholar] [CrossRef]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A Deep Learning-based System for Vulnerability Detection. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Russell, R.; Kim, L.; Hamilton, L.; Lazovich, T.; Harer, J.; Ozdemir, O.; Ellingwood, P.; McConley, M. Automated Vulnerability Detection in Source Code Using Deep Representation Learning. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018; pp. 757–762. [Google Scholar]
- Le, T.; Nguyen, T.; Le, T.; Phung, D.; Montague, P.; De Vel, O.; Qu, L. Maximal Divergence Sequential Autoencoder for Binary Software Vulnerability Detection. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Chen, Z.; Kommrusch, S.; Tufano, M.; Pouchet, L.N.; Poshyvanyk, D.; Monperrus, M. Sequencer: Sequence-to-sequence Learning for End-to-end Program Repair. IEEE Trans. Softw. Eng. 2019, 47, 1943–1959. [Google Scholar] [CrossRef]
- Gupta, R.; Pal, S.; Kanade, A.; Shevade, S. Deepfix: Fixing Common C Language Errors by Deep Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N.; Feng, X.; Gong, M.; Shou, L.; Qin, B.; Liu, T.; Jiang, D.; et al. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Proceedings of the Findings of the Association for Computational Linguistics (EMNLP 2020), Virtual, 16–20 November 2020; pp. 1536–1547. [Google Scholar]
- Buratti, L.; Pujar, S.; Bornea, M.; McCarley, S.; Zheng, Y.; Rossiello, G.; Morari, A.; Laredo, J.; Thost, V.; Zhuang, Y.; et al. Exploring Software Naturalness through Neural Language Models. arXiv 2020, arXiv:2006.12641. [Google Scholar]
- Li, Z.; Lu, S.; Guo, D.; Duan, N.; Jannu, S.; Jenks, G.; Majumder, D.; Green, J.; Svyatkovskiy, A.; Fu, S.; et al. Automating Code Review Activities by Large-scale Pre-training. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; pp. 1035–1047. [Google Scholar]
- Bellon, S.; Koschke, R.; Antoniol, G.; Krinke, J.; Merlo, E. Comparison and Evaluation of Clone Detection Tools. IEEE Trans. Softw. Eng. 2007, 33, 577–591. [Google Scholar] [CrossRef]
- Roy, C.K.; Cordy, J.R. A Survey on Software Clone Detection Research. Queen’s Sch. Comput. TR 2007, 541, 64–68. [Google Scholar]
- Kontogiannis, K.A.; DeMori, R.; Merlo, E.; Galler, M.; Bernstein, M. Pattern Matching for Clone and Concept Detection. Autom. Softw. Eng. 1996, 3, 77–108. [Google Scholar] [CrossRef]
- Ducasse, S.; Rieger, M.; Demeyer, S. A Language Independent Approach for Detecting Duplicated Code. In Proceedings of the IEEE International Conference on Software Maintenance, Oxford, UK, 30 August–3 September 1999; pp. 109–118. [Google Scholar]
- Baxter, I.D.; Yahin, A.; Moura, L.; Sant’Anna, M.; Bier, L. Clone Detection using Abstract Syntax Trees. In Proceedings of the International Conference on Software Maintenance, Bethesda, MD, USA, 16–19 November 1998; pp. 368–377. [Google Scholar]
- Chen, K.; Liu, P.; Zhang, Y. Achieving Accuracy and Scalability Simultaneously in Detecting Application Clones on Android Markets. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 175–186. [Google Scholar]
- Sajnani, H.; Saini, V.; Svajlenko, J.; Roy, C.K.; Lopes, C.V. Sourcerercc: Scaling code clone detection to big-code. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; pp. 1157–1168. [Google Scholar]
- Yu, H.; Lam, W.; Chen, L.; Li, G.; Xie, T.; Wang, Q. Neural Detection of Semantic Code Clones via Tree-based Convolution. In Proceedings of the IEEE/ACM 27th International Conference on Program Comprehension, Montreal, QC, Canada, 25–26 May 2019; pp. 70–80. [Google Scholar]
- Hu, Y.; Ahmed, U.Z.; Mechtaev, S.; Leong, B.; Roychoudhury, A. Re-factoring based Program Repair applied to Programming Assignments. In Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering, San Diego, CA, USA, 11–15 November 2019; pp. 388–398. [Google Scholar]
- Kanade, A.; Maniatis, P.; Balakrishnan, G.; Shi, K. Learning and Evaluating Contextual Embedding of Source Code. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 5110–5121. [Google Scholar]
- Liu, F.; Li, G.; Zhao, Y.; Jin, Z. Multi-task Learning Based Pre-trained Language Model for Code Completion. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, Virtual, 21–25 September 2020; pp. 473–485. [Google Scholar]
- Svyatkovskiy, A.; Deng, S.K.; Fu, S.; Sundaresan, N. Intellicode Compose: Code Generation Using Transformer. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual, 8–13 November 2020; pp. 1433–1443. [Google Scholar]
- Hellendoorn, V.J.; Sutton, C.; Singh, R.; Maniatis, P.; Bieber, D. Global Relational Models of Source Code. In Proceedings of the International Conference on Learning Representations, Virtual, 26–30 April 2020. [Google Scholar]
- Roziere, B.; Lachaux, M.A.; Chanussot, L.; Lample, G. Unsupervised Translation of Programming Languages. Adv. Neural Inf. Process. Syst. 2020, 33, 20601–20611. [Google Scholar]
- Guo, D.; Ren, S.; Lu, S.; Feng, Z.; Tang, D.; Liu, S.; Zhou, L.; Duan, N.; Svyatkovskiy, A.; Fu, S.; et al. GraphCodeBERT: Pre-training Code Representations with Data Flow. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Friedman, N. Introducing GitHub Copilot: Your AI Pair Programmer. 2021. Available online: https://github.com/features/copilot (accessed on 18 May 2023).
- Wang, Y.; Wang, W.; Joty, S.; Hoi, S.C. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 8696–8708. [Google Scholar]
- Berabi, B.; He, J.; Raychev, V.; Vechev, M. Tfix: Learning to Fix Coding Errors with a Text-to-text Transformer. In Proceedings of the International Conference on Machine Learning. PMLR, Virtual, 18–24 July 2021; pp. 780–791. [Google Scholar]
- Le, H.; Wang, Y.; Gotmare, A.D.; Savarese, S.; Hoi, S. CodeRL: Mastering Code Generation through Pretrained Models and Deep Reinforcement Learning. In Proceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS 2022), New Orleans, LA, USA, 28 November 2022. [Google Scholar]
- Jiang, X.; Zheng, Z.; Lyu, C.; Li, L.; Lyu, L. TreeBERT: A Tree-based Pre-trained Model for Programming Language. In Proceedings of the Uncertainty in Artificial Intelligence, Virtual, 27–30 July 2021; pp. 54–63. [Google Scholar]
- Allamanis, M.; Jackson-Flux, H.; Brockschmidt, M. Self-supervised Bug Detection and Repair. In Proceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]
- Hua, W.; Liu, G. Transformer-based Networks Over Tree Structures for Code Classification. Appl. Intell. 2022, 52, 8895–8909. [Google Scholar] [CrossRef]
- Phan, L.; Tran, H.; Le, D.; Nguyen, H.; Annibal, J.; Peltekian, A.; Ye, Y. CoTexT: Multi-task Learning with Code-Text Transformer. In Proceedings of the 1st Workshop on Natural Language Processing for Programming, Virtual, 6 August 2021; pp. 40–47. [Google Scholar]
- Wang, X.; Wang, Y.; Mi, F.; Zhou, P.; Wan, Y.; Liu, X.; Li, L.; Wu, H.; Liu, J.; Jiang, X. SynCoBERT: Syntax-Guided Multi-Modal Contrastive Pre-Training for Code Representation. arXiv 2021, arXiv:2108.04556. [Google Scholar]
- Kim, S.; Zhao, J.; Tian, Y.; Chandra, S. Code Prediction by Feeding Trees to Transformers. In Proceedings of the IEEE/ACM 43rd International Conference on Software Engineering, Madrid, Spain, 22–30 May 2021; pp. 150–162. [Google Scholar]
- Wang, Y.; Li, H. Code Completion by Modeling Flattened Abstract Syntax Trees as Graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 14015–14023. [Google Scholar]
- Drain, D.; Clement, C.B.; Serrato, G.; Sundaresan, N. Deepdebug: Fixing Python Bugs Using Stack Traces, Backtranslation, and Code Skeletons. arXiv 2021, arXiv:2105.09352. [Google Scholar]
- Ahmad, W.; Chakraborty, S.; Ray, B.; Chang, K.W. Unified Pre-training for Program Understanding and Generation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Virtual, 6–11 June 2021; pp. 2655–2668. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Lajkó, M.; Csuvik, V.; Vidács, L. Towards Javascript Program Repair with Generative Pre-trained Transformer (GPT-2). In Proceedings of the 3rd International Workshop on Automated Program Repair, Pittsburgh, PA, USA, 19 May 2022; pp. 61–68. [Google Scholar]
- Ye, H.; Martinez, M.; Monperrus, M. Neural Program Repair with Execution-based Backpropagation. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 1506–1518. [Google Scholar]
- Xia, C.S.; Zhang, L. Less Training, More Repairing Please: Revisiting Automated Program Repair via Zero-shot Learning. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; pp. 959–971. [Google Scholar]
- Li, X.; Liu, S.; Feng, R.; Meng, G.; Xie, X.; Chen, K.; Liu, Y. TransRepair: Context-aware Program Repair for Compilation Errors. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022; pp. 1–13. [Google Scholar]
- Chakraborty, S.; Ahmed, T.; Ding, Y.; Devanbu, P.T.; Ray, B. NatGen: Generative Pre-training by “Naturalizing” Source Code. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; pp. 18–30. [Google Scholar]
- Yang, G.; Chen, X.; Zhou, Y.; Yu, C. Dualsc: Automatic Generation and Summarization of Shellcode via Transformer and Dual Learning. In Proceedings of the International Conference on Software Analysis, Evolution and Reengineering, Honolulu, HI, USA, 15–18 March 2022. [Google Scholar]
- Fu, M.; Tantithamthavorn, C.; Le, T.; Nguyen, V.; Phung, D. VulRepair: A T5-based Automated Software Vulnerability Repair. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–18 November 2022; pp. 935–947. [Google Scholar]
- Zhang, J.; Panthaplackel, S.; Nie, P.; Li, J.J.; Gligoric, M. CoditT5: Pretraining for Source Code and Natural Language Editing. In Proceedings of the International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022. [Google Scholar]
- Tao, C.; Zhan, Q.; Hu, X.; Xia, X. C4: Contrastive Cross-language Code Clone Detection. In Proceedings of the 30th IEEE/ACM International Conference on Program Comprehension, Virtual, 16–17 May 2022; pp. 413–424. [Google Scholar]
- Niu, C.; Li, C.; Ng, V.; Ge, J.; Huang, L.; Luo, B. SPT-code: Sequence-to-sequence Pre-training for Learning Source Code Representations. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 2006–2018. [Google Scholar]
- Yang, G.; Zhou, Y.; Chen, X.; Zhang, X.; Han, T.; Chen, T. ExploitGen: Template-augmented Exploit Code Generation based on CodeBERT. J. Syst. Softw. 2023, 197, 111577. [Google Scholar] [CrossRef]
- Allal, L.B.; Li, R.; Kocetkov, D.; Mou, C.; Akiki, C.; Ferrandis, C.M.; Muennighoff, N.; Mishra, M.; Gu, A.; Dey, M.; et al. SantaCoder: Don’t Reach for the Stars! arXiv 2023, arXiv:2301.03988. [Google Scholar]
- Li, R.; Allal, L.B.; Zi, Y.; Muennighoff, N.; Kocetkov, D.; Mou, C.; Marone, M.; Akiki, C.; Li, J.; Chim, J.; et al. StarCoder: May the source be with you! arXiv 2023, arXiv:2305.06161. [Google Scholar]
- Zhang, M.; He, Y. Accelerating Training of Transformer-based Language Models with Progressive Layer Dropping. Adv. Neural Inf. Process. Syst. 2020, 33, 14011–14023. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained Models: Past, Present and Future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Lin, H.; Bilmes, J. How to Select a Good Training-Data Subset for Transcription: Submodular Active Selection for Sequences; Technical report; Washington University: Washington, DC, USA, 2009. [Google Scholar]
- Liang, W.; Zou, J. MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Yin, Y.; Chen, C.; Shang, L.; Jiang, X.; Chen, X.; Liu, Q. AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 5146–5157. [Google Scholar]
- OpenAI. CHATGPT: Optimizing Language Models for Dialogue. 2023. Available online: https://online-chatgpt.com/ (accessed on 16 May 2023).
- Serban, I.V.; Sankar, C.; Germain, M.; Zhang, S.; Lin, Z.; Subramanian, S.; Kim, T.; Pieper, M.; Chandar, S.; Ke, N.R.; et al. A Deep Reinforcement Learning Chatbot. arXiv 2017, arXiv:1709.02349. [Google Scholar]
- Christiano, P.F.; Leike, J.; Brown, T.; Martic, M.; Legg, S.; Amodei, D. Deep Reinforcement Learning from Human Preferences. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ling, L.; Tan, C.W. Human-assisted Computation for Auto-grading. In Proceedings of the IEEE International Conference on Data Mining Workshops, Singapore, 17–20 November 2018; pp. 360–364. [Google Scholar]
- Ziegler, D.M.; Stiennon, N.; Wu, J.; Brown, T.B.; Radford, A.; Amodei, D.; Christiano, P.; Irving, G. Fine-tuning Language Models from Human Preferences. arXiv 2019, arXiv:1909.08593. [Google Scholar]
- Stiennon, N.; Ouyang, L.; Wu, J.; Ziegler, D.; Lowe, R.; Voss, C.; Radford, A.; Amodei, D.; Christiano, P.F. Learning to Summarize with Human Feedback. Adv. Neural Inf. Process. Syst. 2020, 33, 3008–3021. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training Language Models to Follow Instructions with Human Feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Hendler, J. Understanding the Limits of AI coding. Science 2023, 379, 548. [Google Scholar] [CrossRef] [PubMed]
- Chen, B.; Zhang, F.; Nguyen, A.; Zan, D.; Lin, Z.; Lou, J.G.; Chen, W. CodeT: Code Generation with Generated Tests. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- White, A.D.; Hocky, G.; Ansari, M.; Gandhi, H.A.; Cox, S.; Wellawatte, G.P.; Sasmal, S.; Yang, Z.; Liu, K.; Singh, Y.; et al. Assessment of Chemistry Knowledge in Large Language Models That Generate Code. Digit. Discov. 2023, 2, 368–376. [Google Scholar] [CrossRef] [PubMed]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 328–339. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned Language Models are Zero-Shot Learners. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Settles, B. Active Learning Literature Survey; University of Wisconsin: Madison, WI, USA, 2009. [Google Scholar]
- Cohn, D.A.; Ghahramani, Z.; Jordan, M.I. Active Learning with Statistical Models. J. Artif. Intell. Res. 1996, 4, 129–145. [Google Scholar] [CrossRef]
- Settles, B.; Craven, M.; Friedland, L. Active Learning with Real Annotation Costs. In Proceedings of the NIPS Workshop on Cost-sensitive Learning, Vancouver, BC, Canada, 8–13 December 2008. [Google Scholar]
- He, J.; Vechev, M. Large Language Models for Code: Security Hardening and Adversarial Testing. arXiv 2023, arXiv:2302.05319. [Google Scholar]
- Pearce, H.; Ahmad, B.; Tan, B.; Dolan-Gavitt, B.; Karri, R. Asleep at the Keyboard? Assessing the Security of Github Copilot’s Code Contributions. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 22–26 May 2022; pp. 754–768. [Google Scholar]
- Peace, A.G.; Galletta, D.F.; Thong, J.Y. Software Piracy in the Workplace: A Model and Empirical Test. J. Manag. Inf. Syst. 2003, 20, 153–177. [Google Scholar]
- Reavis Conner, K.; Rumelt, R.P. Software piracy: An Analysis of Protection Strategies. Manag. Sci. 1991, 37, 125–139. [Google Scholar] [CrossRef]
- Limayem, M.; Khalifa, M.; Chin, W.W. Factors Motivating Software Piracy: A Longitudinal Study. IEEE Trans. Eng. Manag. 2004, 51, 414–425. [Google Scholar] [CrossRef]
- De Laat, P.B. Copyright or Copyleft?: An Analysis of Property Regimes for Software Development. Res. Policy 2005, 34, 1511–1532. [Google Scholar] [CrossRef]
- Kelty, C.M. Culture’s Open Sources: Software, Copyright, and Cultural Critique. Anthropol. Q. 2004, 77, 499–506. [Google Scholar] [CrossRef]
- The United States Copyright Office, Library of Congress. Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence. 2023. Available online: https://www.federalregister.gov/d/2023-05321 (accessed on 26 April 2023).
- Zheng, L.; Joe-Wong, C.; Tan, C.W.; Chiang, M.; Wang, X. How to Bid the Cloud. In Proceedings of the ACM Conference on Special Interest Group on Data Communication (SIGCOMM), London, UK, 17–21 August 2015; pp. 71–84. [Google Scholar]
- Zheng, L.; Joe-Wong, C.; Brinton, C.; Tan, C.W.; Ha, S.; Chiang, M. On the Viability of a Cloud Virtual Service Provider. In Proceedings of the ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Science, Antibes Juan–les–Pins, France, 14–18 June 2016; pp. 235–248. [Google Scholar]
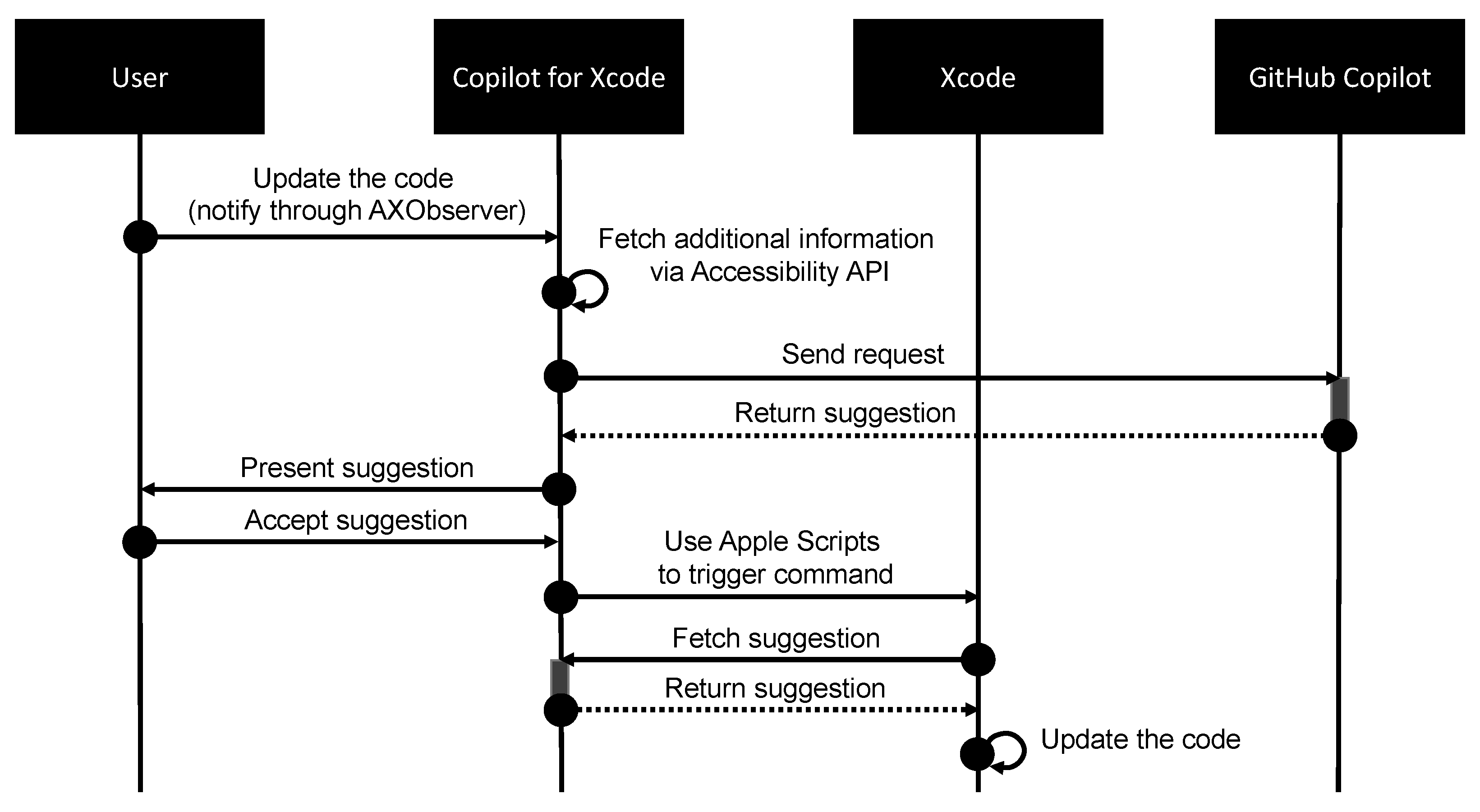
- Guo, S. INTITNI/CopilotForXcode: The Missing GitHub Copilot and ChatGPT Xcode Source Editor Extension. Available online: https://github.com/intitni/CopilotForXcode (accessed on 18 May 2023).






| Title | Year | Focus Area |
|---|---|---|
| A Survey of Machine Learning for Big Code and Naturalness [15] | 2019 | Big Code and Naturalness |
| Software Vulnerability Detection Using Deep Neural Networks: A Survey [16] | 2020 | Security |
| A Survey on Machine Learning Techniques for Source Code Analysis [17] | 2021 | Code Analysis |
| Deep Security Analysis of Program Code: A Systematic Literature Review [18] | 2022 | Security |
| A Survey on Pretrained Language Models for Neural Code Intelligence [19] | 2022 | Code Summarization and Generation, and Translation |
| Deep Learning Meets Software Engineering: A Survey on Pre-trained Models of Source Code [20] | 2022 | Software Engineering |
| Software as Storytelling: A Systematic Literature Review [21] | 2023 | Storytelling |
| Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing [22] | 2023 | Prompt-based Learning |
| Dataset Name | Year | Sample Size | Language(s) | Supported Task(s) | Online URL |
|---|---|---|---|---|---|
| GitHub Java Corpus [23] | 2013 | 14.7K | Java | Code Completion | https://groups.inf.ed.ac.uk/cup/javaGithub/ |
| Description2Code [24] | 2016 | 7.6K | Java, C# | Code Generation, Code Summarization | https://github.com/ethancaballero/description2code |
| BigCloneBench [25] | 2015 | 5.5K | Java | Defect Detection, Clone Detection | https://github.com/clonebench/BigCloneBench |
| CodRep [26] | 2018 | 58K | Java | Code Refinement, Defect Detection | https://github.com/ASSERT-KTH/CodRep-competition |
| CONCODE [27] | 2018 | 104K | Java | Code Generation | https://github.com/sriniiyer/concode |
| WikiSQL [28] | 2018 | 87K | SQL | Code Summarization | https://github.com/salesforce/WikiSQL |
| Bugs2Fix [29] | 2019 | 122K | Java | Defect Detection, Code Refinement | https://sites.google.com/view/learning-fixes |
| Devign [30] | 2019 | 26.4K | C | Code Generation, Defect Detection | https://sites.google.com/view/devign |
| CodeSearchNet [31] | 2019 | 2M | Python, Javascript, Ruby, Go, Java, PHP | Code Generation, Code Summarization, Code Translation | https://github.com/github/CodeSearchNet |
| The Pile [32] | 2020 | 211M | Python | Coder Generation | https://pile.eleuther.ai |
| CodeNet [33] | 2021 | 13M | C++, C, Python, Java | Code Generation, Code Refinement | https://github.com/IBM/Project_CodeNet |
| CodeXGLUE [34] | 2021 | 176K | Python, Java, PHP, JavaScript, Ruby, Go | Code Generation, Code Completion, Code Summarization, Defect Detection | https://github.com/microsoft/CodeXGLUE |
| HumanEval [35] | 2021 | 164 | Python | Code Generation | https://github.com/openai/human-eval |
| APPS [36] | 2021 | 10K | Python | Code Generation | https://github.com/hendrycks/apps |
| Codeparrot [37] | 2022 | 22M | Python | Code Generation | https://hf.co/datasets/transformersbook/codeparrot |
| CodeContests [38] | 2022 | 13.6K | C++, Java, JavaScript, C# and 8 more | Code Generation | https://github.com/deepmind/code_contests |
| CERT [39] | 2022 | 5.4M | Python | Code Generation | https://github.com/microsoft/PyCodeGPT |
| InCoder [40] | 2022 | 670K | Python, JavaScript, HTML and 24 more | Code Generation, Code Summarization | https://github.com/dpfried/incoder |
| PolyCoder [41] | 2022 | 1K | C, C++, Java, JavaScript, C#, Go and 6 more | Code Generation | https://github.com/VHellendoorn/Code-LMs |
| ExecEval [42] | 2023 | 58K | Ruby, Javascript, Go, C++, C and 6 more | Code Sumarization, Code Generation, Code Translation | https://github.com/ntunlp/xCodeEval |
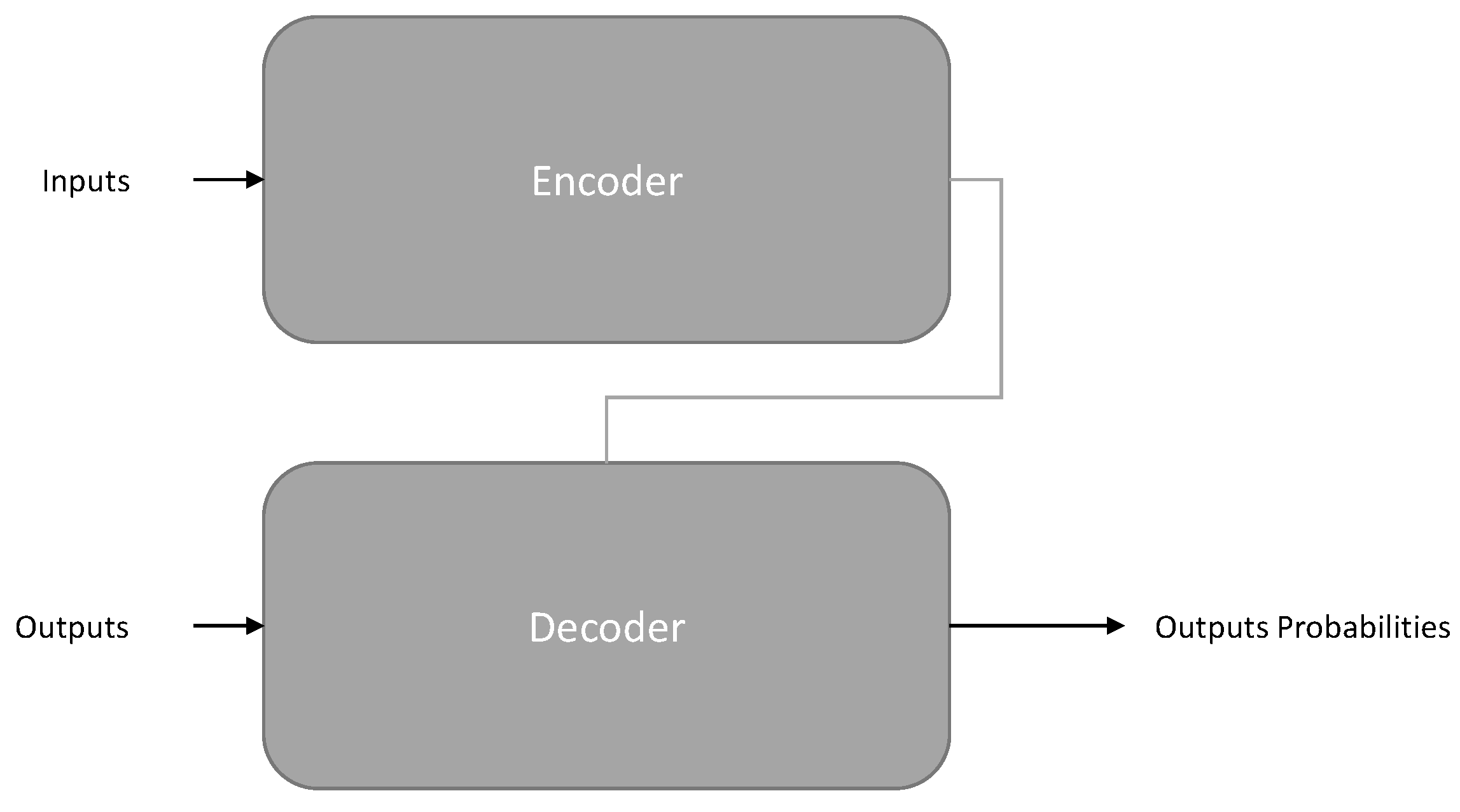
| Model | Type | AI-Assisted Programming Tasks |
|---|---|---|
| Encoder-only | Understanding | Code Summarization, Code Translation |
| Decoder-only | Generation | Code Generation, Code Completion |
| Encoder–decoder | Generation and Understanding | Code Generation, Code Refinement, Defect Detection, Clone Detection |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wong, M.-F.; Guo, S.; Hang, C.-N.; Ho, S.-W.; Tan, C.-W. Natural Language Generation and Understanding of Big Code for AI-Assisted Programming: A Review. Entropy 2023, 25, 888. https://doi.org/10.3390/e25060888
Wong M-F, Guo S, Hang C-N, Ho S-W, Tan C-W. Natural Language Generation and Understanding of Big Code for AI-Assisted Programming: A Review. Entropy. 2023; 25(6):888. https://doi.org/10.3390/e25060888
Chicago/Turabian StyleWong, Man-Fai, Shangxin Guo, Ching-Nam Hang, Siu-Wai Ho, and Chee-Wei Tan. 2023. "Natural Language Generation and Understanding of Big Code for AI-Assisted Programming: A Review" Entropy 25, no. 6: 888. https://doi.org/10.3390/e25060888