
Wasserstein Distance-Based Deep Leakage from Gradients

Abstract
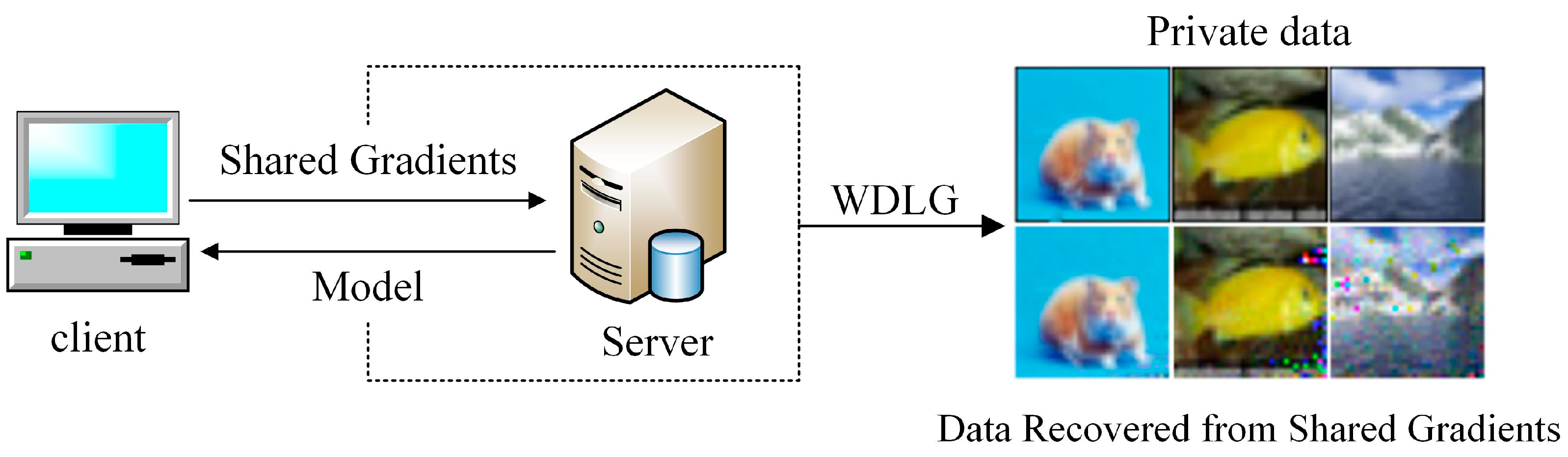
:1. Introduction
- This paper proposes a gradient inversion attack algorithm based on DLG, which uses the Wasserstein distance to measure the distance between the virtual gradient and the real gradient.
- Theoretical analysis is given about continuity and differentiability of Wasserstein distance; the analysis results show that Wasserstein distance substitution for Euclidean as a loss function of gradient is feasible in gradient inversion.
- Experiments are carried on image data in public data set, and the result verifies that WDLG algorithm can invert images with better performance.
2. Related Work
2.1. Distributed Training
2.2. Wasserstein (Earth-Mover) Distance
2.3. Gradient Inversion
| Algorithm 1: Deep Leakage from Gradients. | |
| Input: : gradients calculated by training data. | |
| Output: private training data x, y | |
| 1:) | |
| 2: | Initialize dummy inputs and labels. |
| 3: for 1 to do | |
| 4: | Compute dummy gradients. |
| 5: | Second norm loss function. |
| 6: | Update data to match gradients. |
| 7: end for | |
| 8: return | |
| 9:end procedure | |
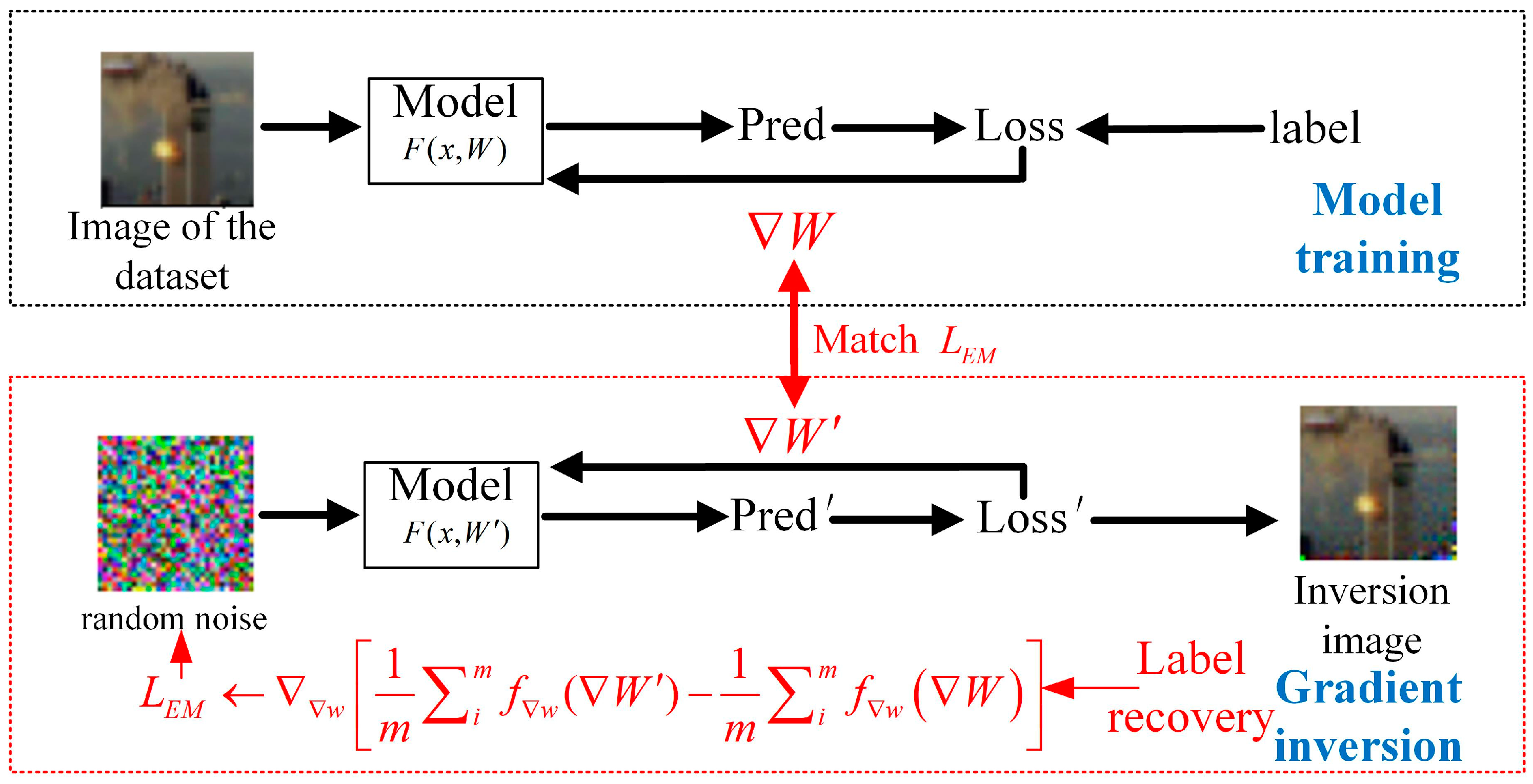
3. Method
3.1. Wasserstein DLG (WDLG)
| Algorithm 2: Wasserstein Deep Leakage from Gradients. | |
| Input: : gradients calculated by training data; : tags recovered by tag recovery algorithm. | |
| Output: private training data x, y | |
| 1:) | |
| 2: | Initialize dummy inputs and labels. |
| 3: for 1 to do | |
| 4: | Compute dummy gradients. |
| 5: | Wasserstein distance loss function. |
| 6: | Update data to match gradients. |
| 7: end for | |
| 8: return | |
| 9:end procedure | |
3.2. Continuity and Differentiability of EM Distance
4. Experiment
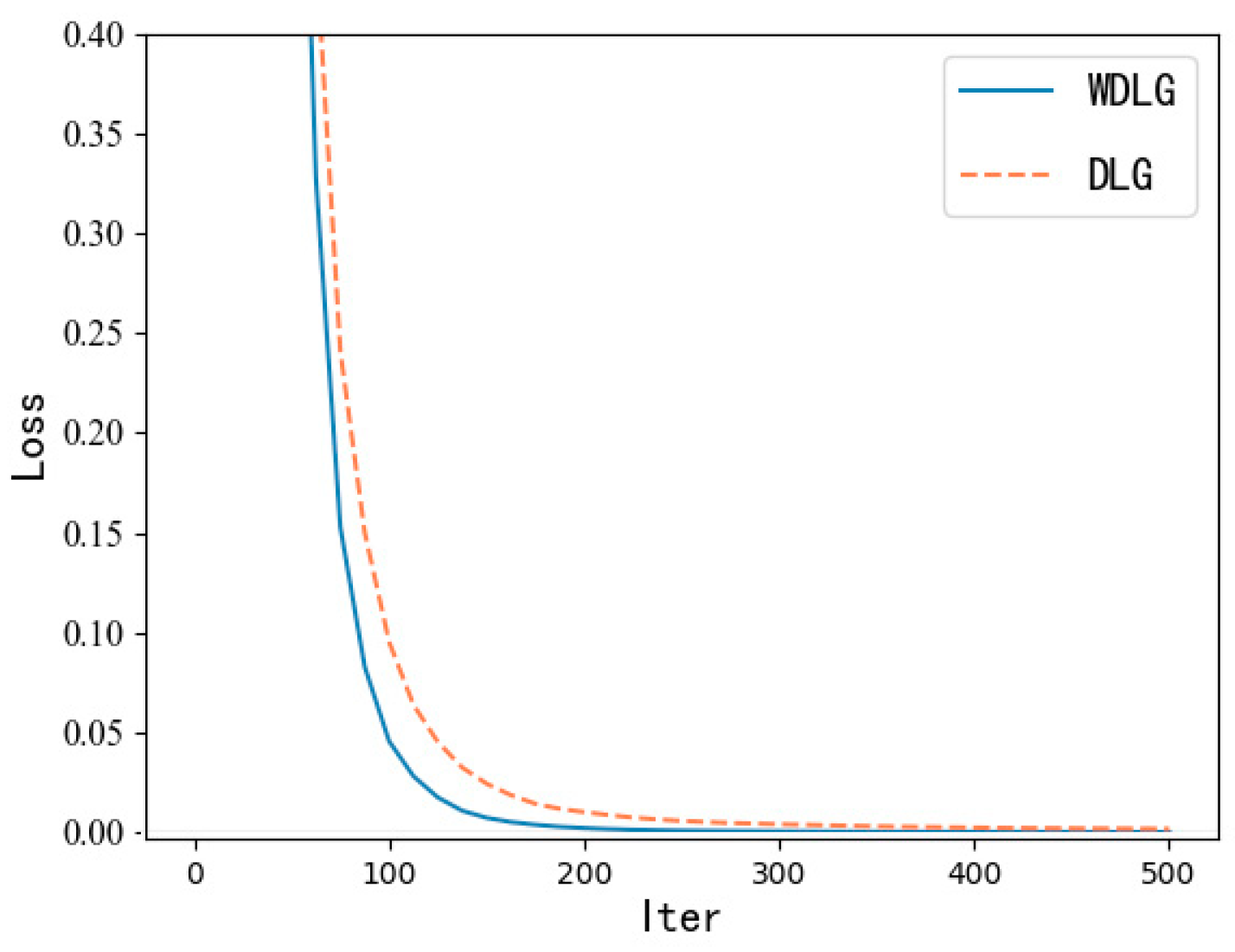
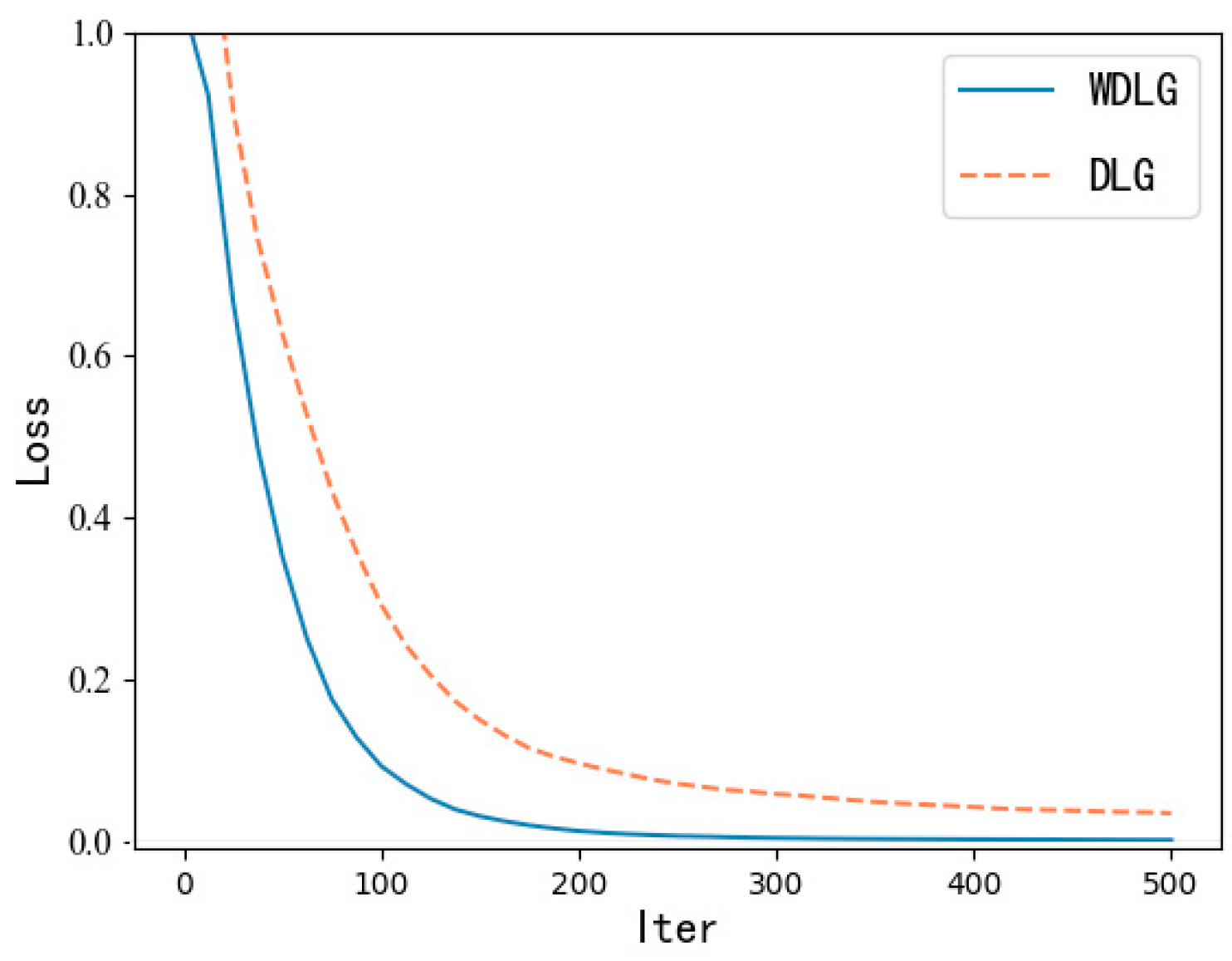
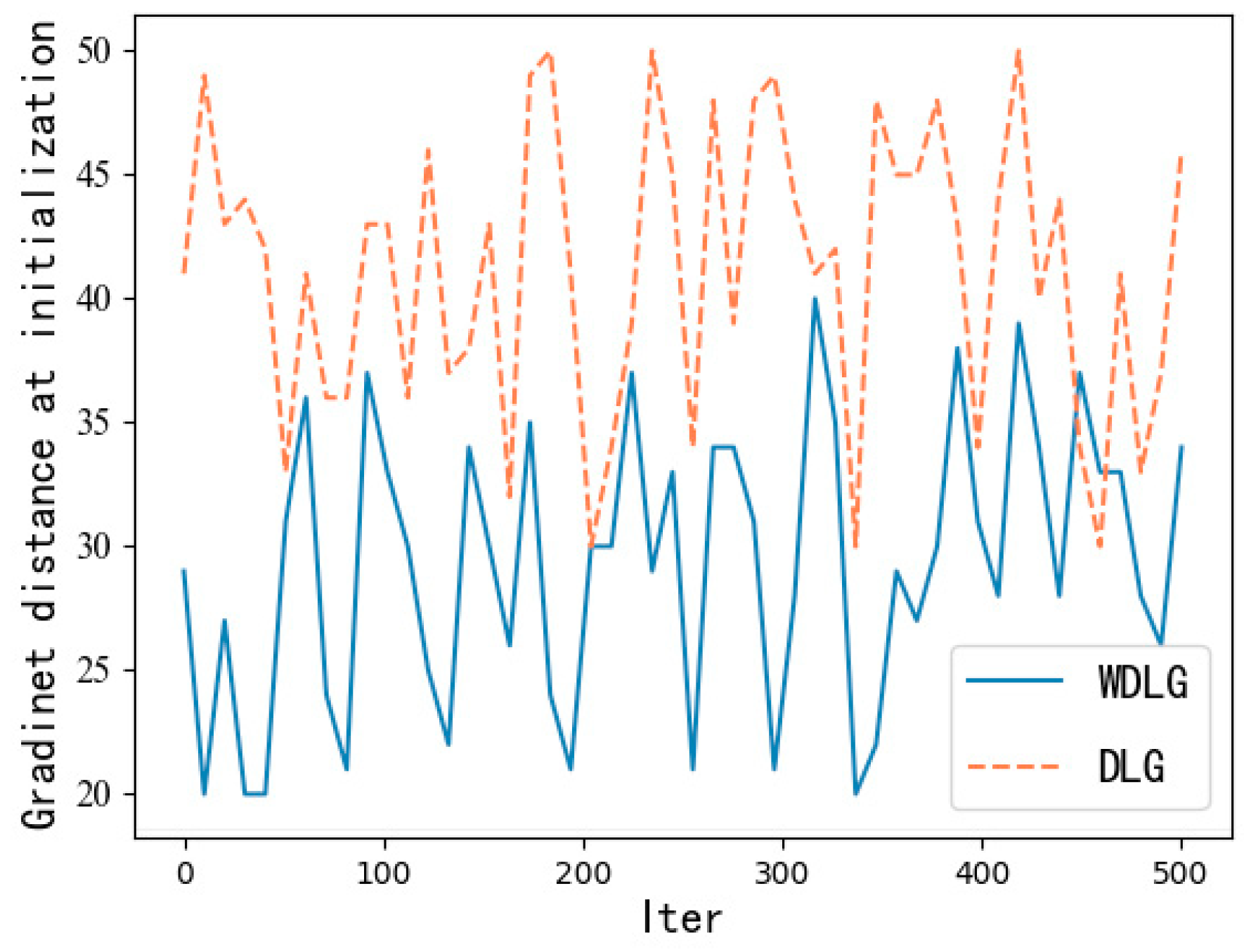
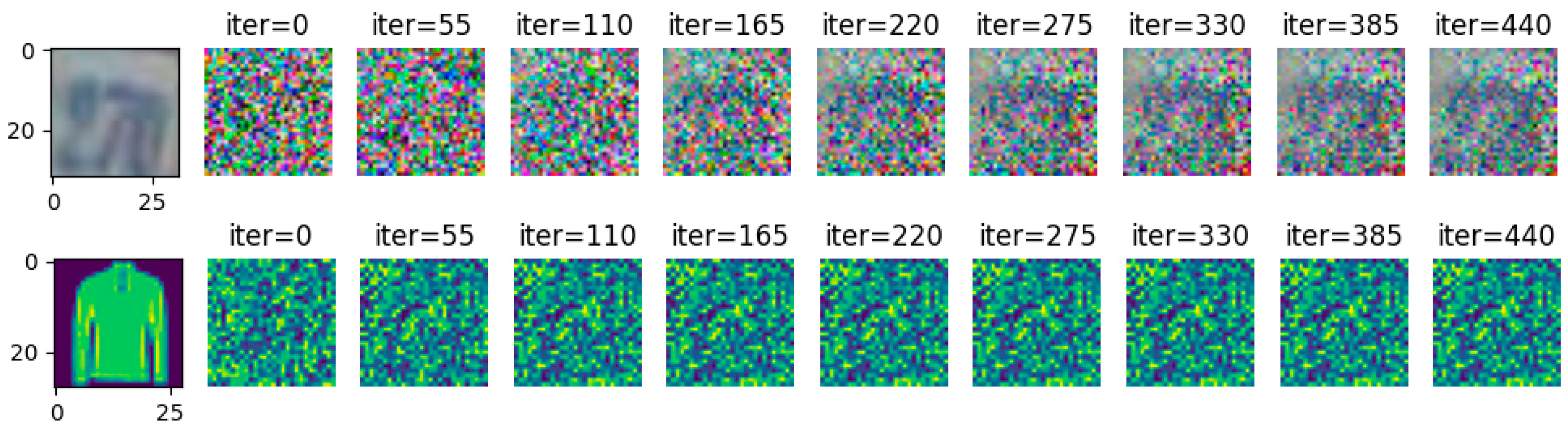
4.1. Inversion Effect of WDLG on Image Classification
4.2. Calculation Comparison
4.3. Experimental Results under Different Batches
4.4. Ablation Studies
4.5. Differential Privacy Disturbance Defense
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Konečný, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- McMahan, H.B.; Moore, E.; Ramage, D.; Arcas, B.A.Y. Federated learning of deep networks using model averaging. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Keutzer, K. FireCaffe: Near-Linear Acceleration of Deep Neural Network Training on Compute Clusters. arXiv 2016, arXiv:1511.00175. [Google Scholar]
- Li, M.; Andersen, D.G.; Park, J.W.; Smola, A.J.; Ahmed, A.; Josifovski, V.; Su, B.Y. Scaling distributed machine learning with the parameter server. In Proceedings of the 2014 International Conference on Big Data Science and Computing, Beijing, China, 4–7 August 2014; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Jochems, A.; Deist, T.M.; El Naqa, I.; Kessler, M.; Mayo, C.; Reeves, J.; Jolly, S.; Matuszak, M.; Haken, R.T.; van Soest, J.; et al. Developing and validating a survival prediction model for NSCLC patients through distributed learning across 3 countries. Int. J. Radiat. Oncol. Biol. Phys. 2017, 99, 344–352. [Google Scholar] [CrossRef] [PubMed]
- Jochems, A.; Deist, T.M.; Van Soest, J.; Eble, M.; Bulens, P.; Coucke, P.; Dries, W.; Lambin, P.; Dekker, A. Distributed learning: Developing a predictive model based on data from multiple hospitals without data leaving the hospital-A real life proof of concept. Radiother. Oncol. 2016, 121, 459–467. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Liu, Z.; Han, S. Deep leakage from gradients. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 3–9. [Google Scholar]
- Panaretos, V.M.; Zemel, Y. Statistical aspects of Wasserstein distances. Annu. Rev. Stat. Its Appl. 2019, 6, 405–431. [Google Scholar] [CrossRef]
- Iandola, F. Exploring the Design Space of Deep Convolutional Neural Networks at Large Scale; University of California, Berkeley: Berkeley, CA, USA, 2016; pp. 81–93. [Google Scholar]
- Kim, H.; Park, J.; Jang, J.; Yoon, S. Deepspark: Spark-based deep learning supporting asynchronous updates and caffe compatibility. arXiv 2016, arXiv:1602.08191. [Google Scholar]
- Sergeev, A.; Del Balso, M. Horovod: Fast and easy distributed deep learning in TensorFlow. arXiv 2018, arXiv:1802.05799. [Google Scholar]
- Jia, X.; Song, S.; He, W.; Wang, Y.; Rong, H.; Zhou, F.; Chu, X. Highly scalable deep learning training system with mixed-precision: Training imagenet in four minutes. arXiv 2018, arXiv:1807.11205. [Google Scholar]
- You, Y.; Gitman, I.; Ginsburg, B. Scaling sgd batch size to 32k for imagenet training. arXiv 2017, arXiv:1708.03888. [Google Scholar]
- Recht, B.; Re, C.; Wright, S.; Niu, F. Hogwild!: A lock-free approach to parallelizing stochastic gradient descent. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 3–5. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lerer, A. Automatic differentiation in pytorch. In Proceedings of the NIPS 2017 Autodiff Workshop, Long Beach, CA, USA, 28 October 2017; pp. 1–4. [Google Scholar]
- Ketkar, N.; Moolayil, J. Deep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorch; Apress: New York, NY, USA, 2021; pp. 243–285. [Google Scholar]
- Subramanian, V. Deep Learning with PyTorch: A Practical Approach to Building Neural Network Models Using PyTorch; Packt Publishing Ltd.: Birmingham, UK, 2018; pp. 193–224. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial intelligence and statistics PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Konečný, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 16 September 2019; pp. 691–706. [Google Scholar]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 3–18. [Google Scholar]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2512–2520. [Google Scholar]
- Song, M.; Wang, Z.; Zhang, Z.; Song, Y.; Wang, Q.; Ren, J.; Qi, H. Analyzing user-level privacy attack against federated learning. IEEE J. Sel. Areas Commun. 2020, 38, 2430–2444. [Google Scholar] [CrossRef]
- Ghoussoub, N. Optimal ballistic transport and Hopf-Lax formulae on Wasserstein space. arXiv 2017, arXiv:1705.05951. [Google Scholar]
- Arjovsky, M.; Chintala, S. Leon Bottou, Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Geiping, J.; Bauermeister, H.; Drge, H.; Moeller, M. Inverting gradients-how easy is it to break privacy in federated learning? arXiv 2020, arXiv:2003.14053. [Google Scholar]
- Zhao, B.; Mopuri, K.R.; Bilen, H. idlg: Improved deep leakage from gradients. arXiv 2020, arXiv:2001.02610. [Google Scholar]
- Wei, W.; Liu, L.; Loper, M.; Chow, K.-H.; Gursoy, M.E.; Truex, S.; Wu, Y. A framework for evaluating gradient leakage attacks in federated learning. arXiv 2020, arXiv:2004.10397. [Google Scholar]
- Haroush, M.; Hubara, I.; Hoffer, E.; Soudry, D. The knowledge within: Methods for data-free model compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8494–8502. [Google Scholar]
- Cai, Y.; Yao, Z.; Dong, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. Zeroq: A novel zero shot quantization framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13169–13178. [Google Scholar]
- Yin, H.; Molchanov, P.; Alvarez, J.M.; Li, Z.; Mallya, A.; Hoiem, D.; Kautz, J. Dreaming to distill: Data-free knowledge transfer via deepinversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8715–8724. [Google Scholar]
- Yin, H.; Mallya, A.; Vahdat, A.; Alvarez, J.M.; Kautz, J.; Molchanov, P. See through gradients: Image batch recovery via gradinversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16337–16346. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Parameter Setting | |
|---|---|
| Learning rate | 0.1 |
| Number of iterations training | 500 |
| Number of images generated | 300 |
| Inverted network model | LeNet |
| Random initialization weights | |
| Data set | MNIST, Fashion MINIST, SVHN, CIFAR-10, CIFAR-100 |
| Number of Iteration | Success Rate of Attack | Running Time | ||
|---|---|---|---|---|
| MNIST | DLG | 448 | 0.82 | 1345 |
| WDLG | 448 | 0.86 | 842 | |
| Fashion MNIST | DLG | 448 | 0.84 | 1874 |
| WDLG | 448 | 0.88 | 1026 | |
| SVHN | DLG | 448 | 0.79 | 2115 |
| WDLG | 448 | 0.86 | 1231 | |
| CIFAR-100 | DLG | 448 | 0.76 | 2315 s |
| WDLG | 448 | 0.81 | 1510 s | |
| LeNet + MNIST | CNN6 + MNIST | LeNet + CIFAR10 | CNN6 + CIFAR10 | |
|---|---|---|---|---|
| DLG | 0.0037 ± 0.00082 | 0.015 ± 0.0053 | 0.013 ± 0.0012 | 0.0513 ± 0.034 |
| RGAP | 0.0012 ± 0.00054 | 0.0068 ± 0.0012 | 0.0048 ± 0.00081 | 0.0258 ± 0.016 |
| WDLG | 0.0014 ± 0.00069 | 0.0057 ± 0.0029 | 0.0045 ± 0.00075 | 0.028 ± 0.0064 |
| Learning Rate | Batch Size | Loss | MSE |
|---|---|---|---|
| Batch size 1 | |||
| Batch size 4 | |||
| Batch size 1 | |||
| Batch size 4 |
| Loss | Image Quality | Number of Iteration | Success Rate of Attack | |
|---|---|---|---|---|
| DLG | 300 | 0.74 | ||
| +Label recovery algorithm | 150 | 0.78 | ||
| +Wasserstein Distance | 140 | 0.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Peng, C.; He, X.; Tan, W. Wasserstein Distance-Based Deep Leakage from Gradients. Entropy 2023, 25, 810. https://doi.org/10.3390/e25050810
Wang Z, Peng C, He X, Tan W. Wasserstein Distance-Based Deep Leakage from Gradients. Entropy. 2023; 25(5):810. https://doi.org/10.3390/e25050810
Chicago/Turabian StyleWang, Zifan, Changgen Peng, Xing He, and Weijie Tan. 2023. "Wasserstein Distance-Based Deep Leakage from Gradients" Entropy 25, no. 5: 810. https://doi.org/10.3390/e25050810