

Spare Parts Demand Forecasting Method Based on Intermittent Feature Adaptation

Abstract
:1. Introduction
- (1)
- A domain partitioning scheme for intermittent time series is proposed, which is different from the existing classification methods for intermittent time series. The scheme adopts a clustering method to measure the differences in two dimensions: demand time and demand interval, thus enabling efficient and flexible differentiation of spare parts with different evolutionary trends.
- (2)
- A domain adaptive algorithm for intermittent time series is proposed, which uses the intermittent and temporal characteristics of demand series to construct weight vectors, and learns the common information between domains by weighting the distance between domains, and it can improve the accuracy of demand prediction from both the special evolution law of demand series and the common evolution law between demand series, and no similar study has been found yet.
2. Related Theories
2.1. Hierarchical Clustering
2.2. Intermittent Time Series
- (1)
- Smooth demand ();
- (2)
- Intermittent demand ();
- (3)
- Irregular demand ();
- (4)
- Lumpy demand ().
2.3. Maximum Mean Discrepancy
2.4. Predictive Performance Evaluation Metrics
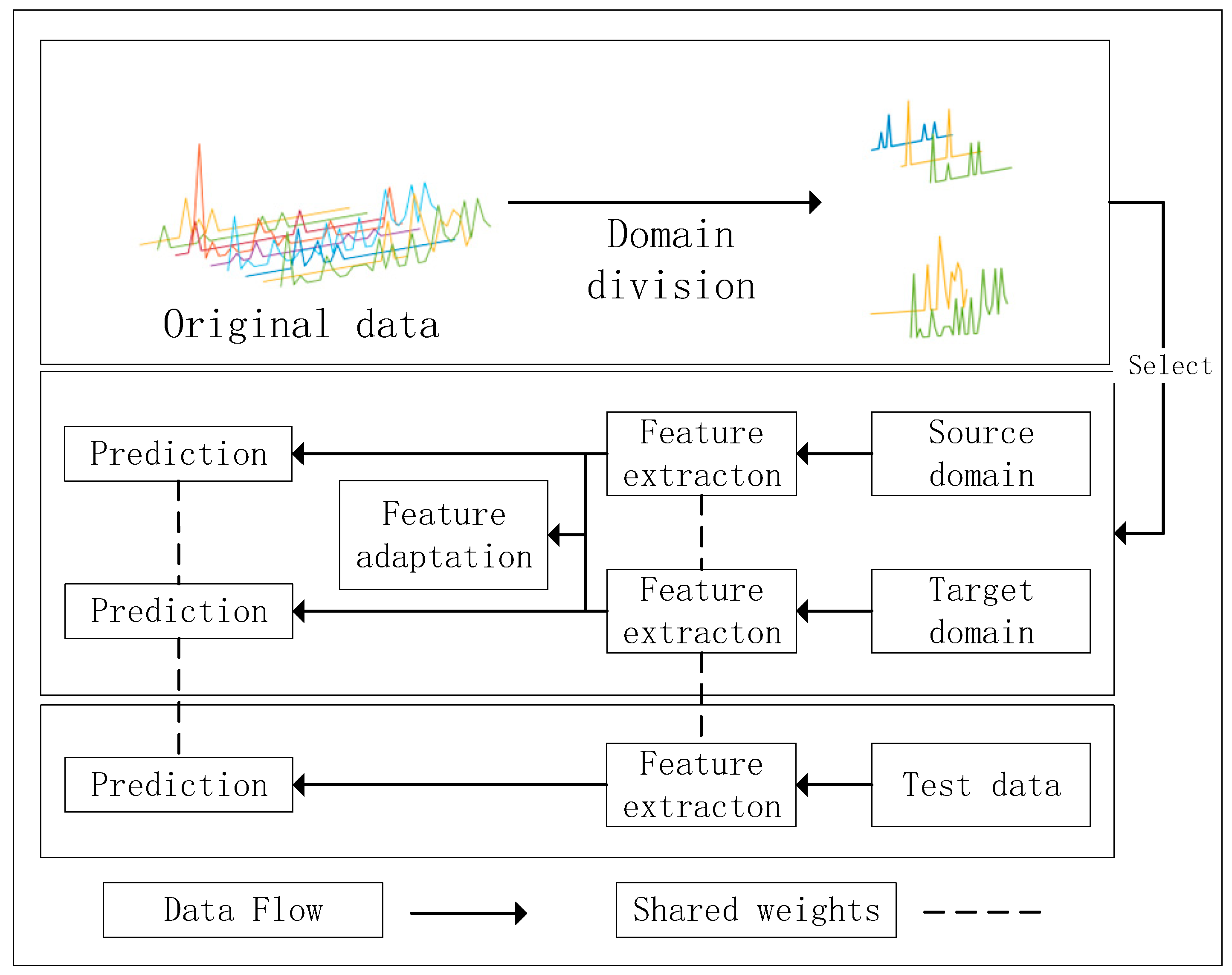
3. Intermittent Feature Adaptation-Based Spare Parts Demand Forecasting Method
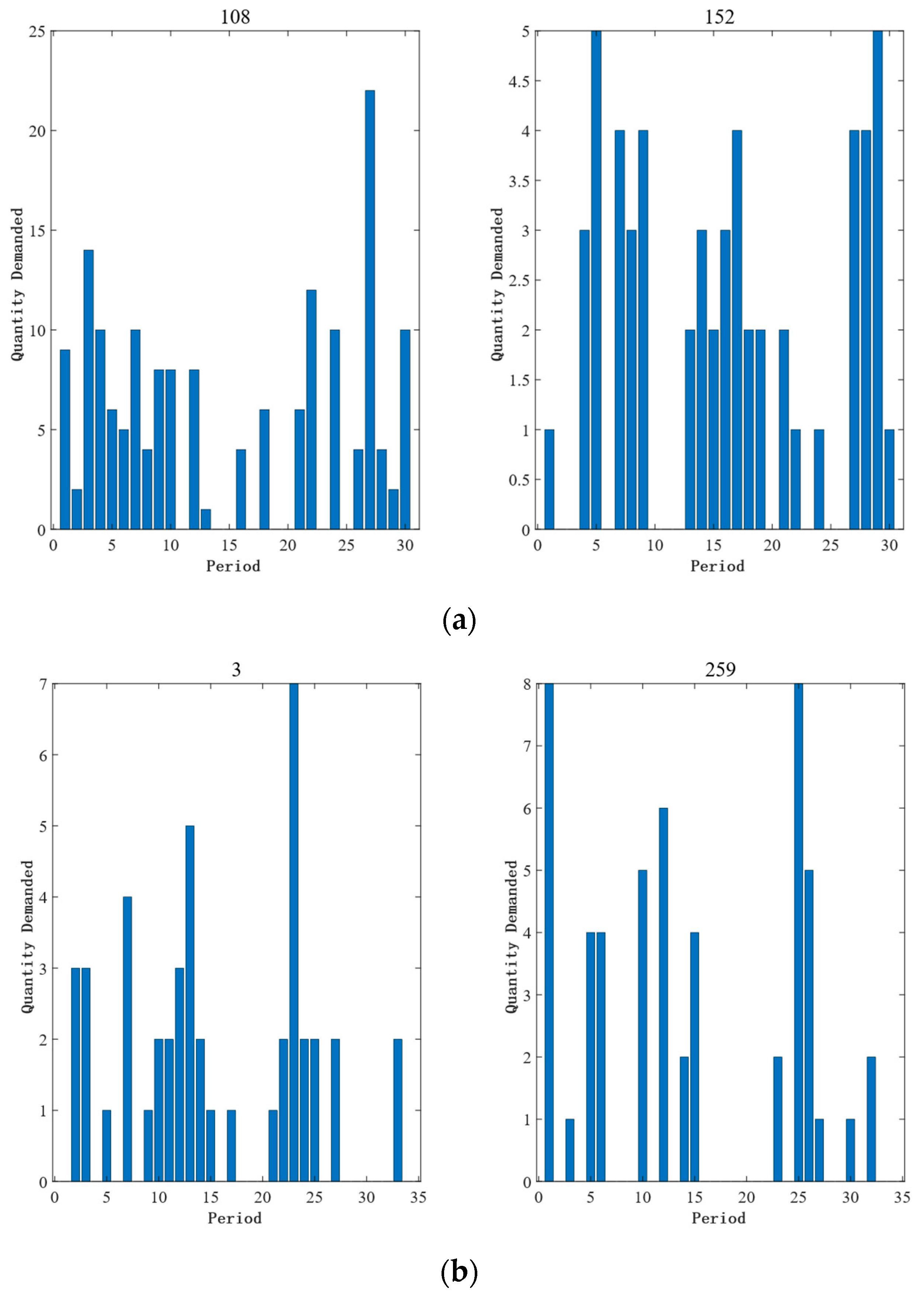
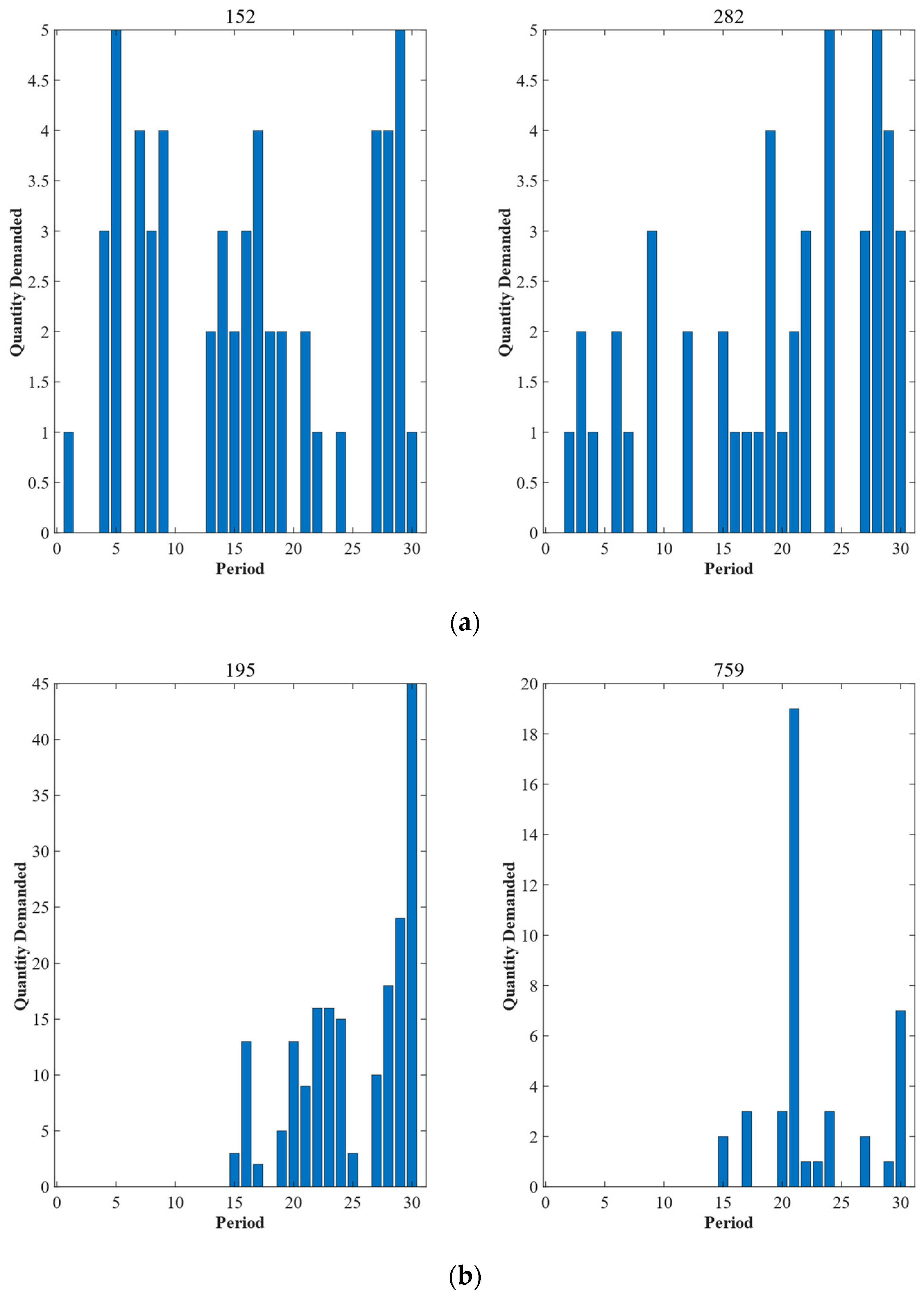
3.1. Domain Partitioning Algorithm for Intermittent Time Series
- (1)
- Extend the original sequence as , where denotes the th sequence; denotes the number of time series cycles; denotes the th sequence after extension; denotes the extended element of the th cycle, where denotes the 0 demand interval and denotes the last demand time.
- (2)
- Calculate the similarity between the spare parts using the distance function .
- (1)
- Initially, consider each sequence in the set of demand series a class cluster.
- (2)
- Calculate the distance between two clusters of classes, merge the two classes with the smallest distance into a new class, and delete these two classes. The distance calculation formula is as follows:
- (3)
- Repeat step 2 until the number of class clusters reaches a predetermined value.
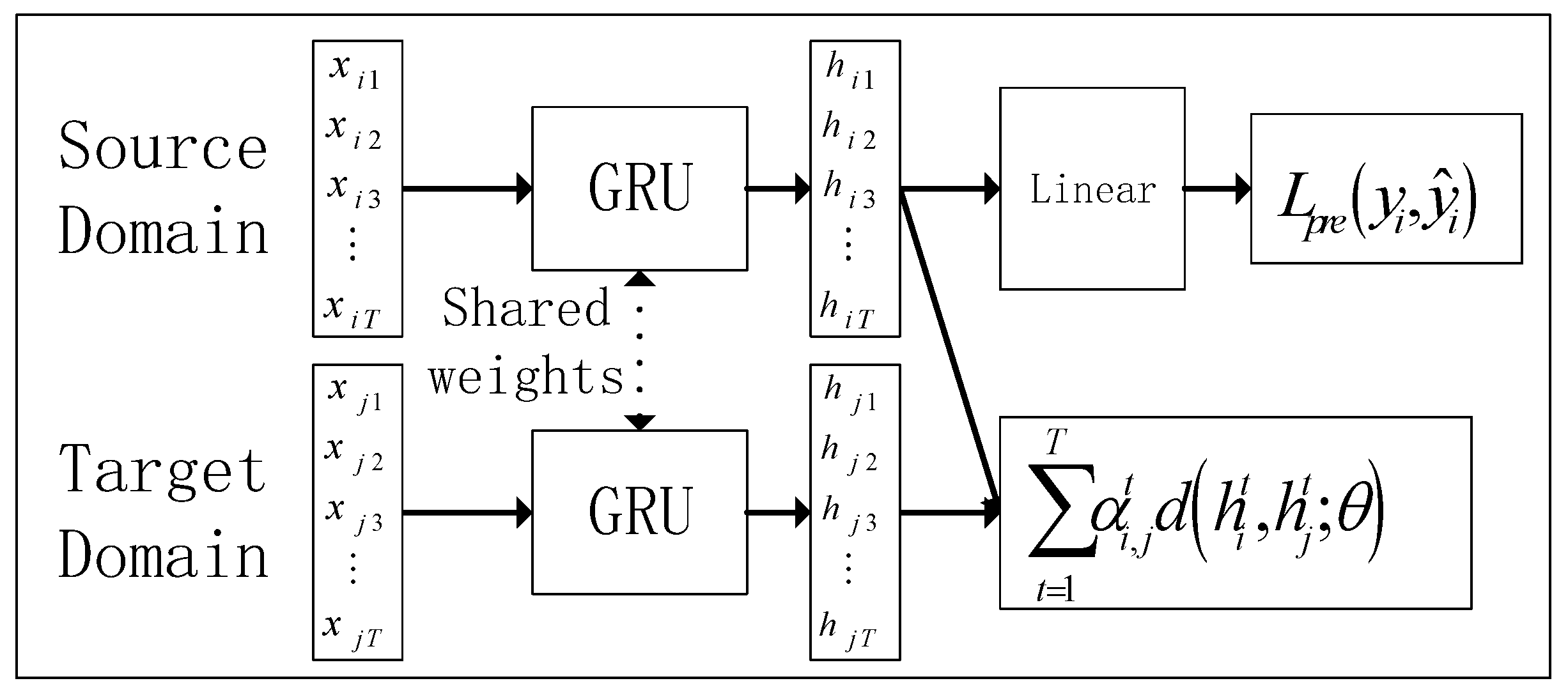
3.2. Intermittent Feature Adaptation Algorithm
- (1)
- At the beginning of training, the hidden layer features change a lot. To make the update process of more smooth, the pretraining times are set here as . Before the training times reach , will be adjusted by the network adaptively; the adjustment rule is , where is the output of the fully connected layer.
- (2)
- When the model has completed pretraining times, the parameter is updated by the boosting method; where is not updated when the distribution loss in the new round does not increase compared to the previous round, and vice versa, the is updated with the following rules:
4. Experimental Analysis
4.1. Dataset Introduction
4.2. Comparison Method
4.3. Analysis of the Results of Intermittent Time Series Domain Segmentation Algorithm
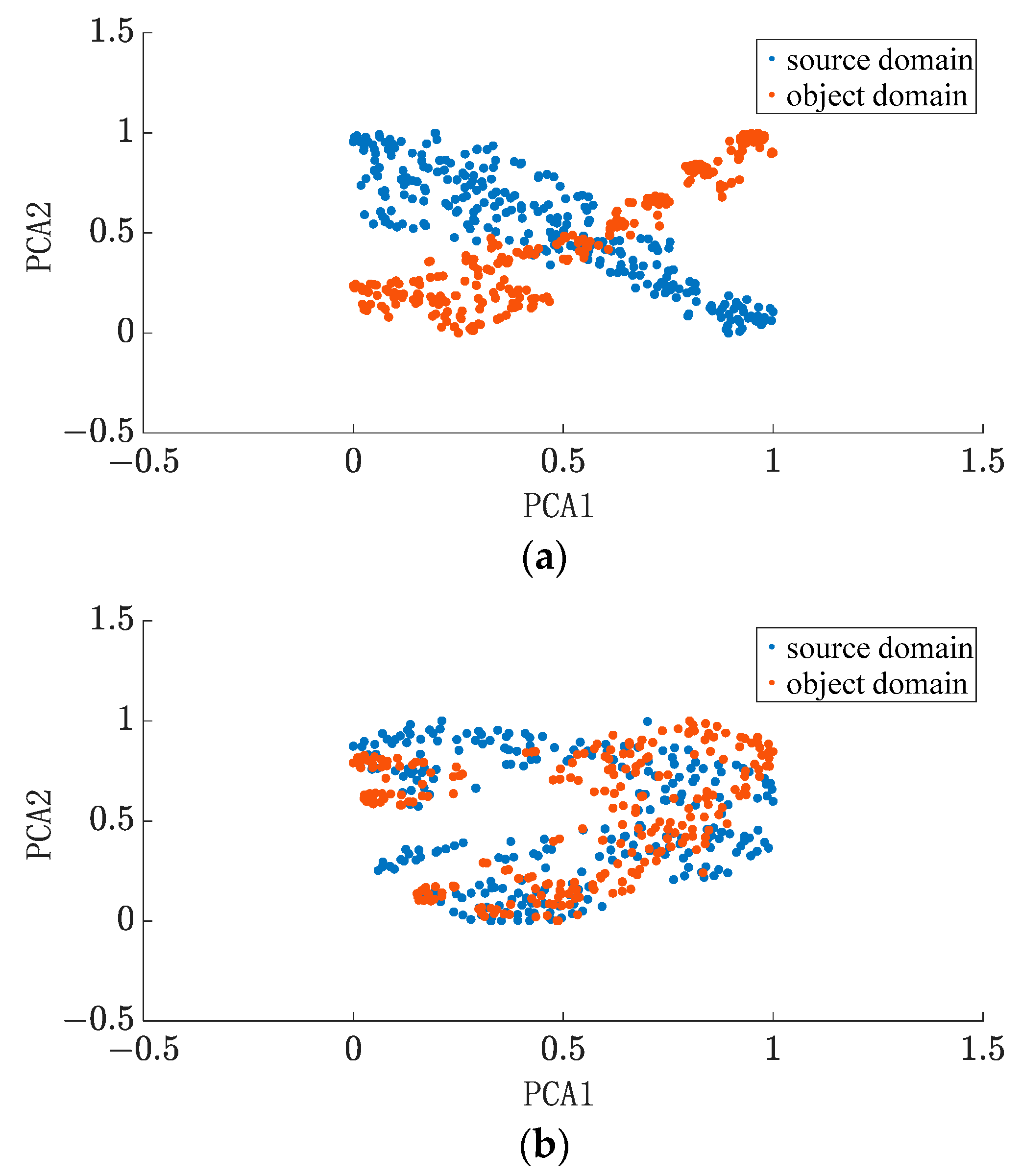
4.4. Analysis of Intermittent Feature Adaptation Algorithm Results
4.5. Ablation Experiments
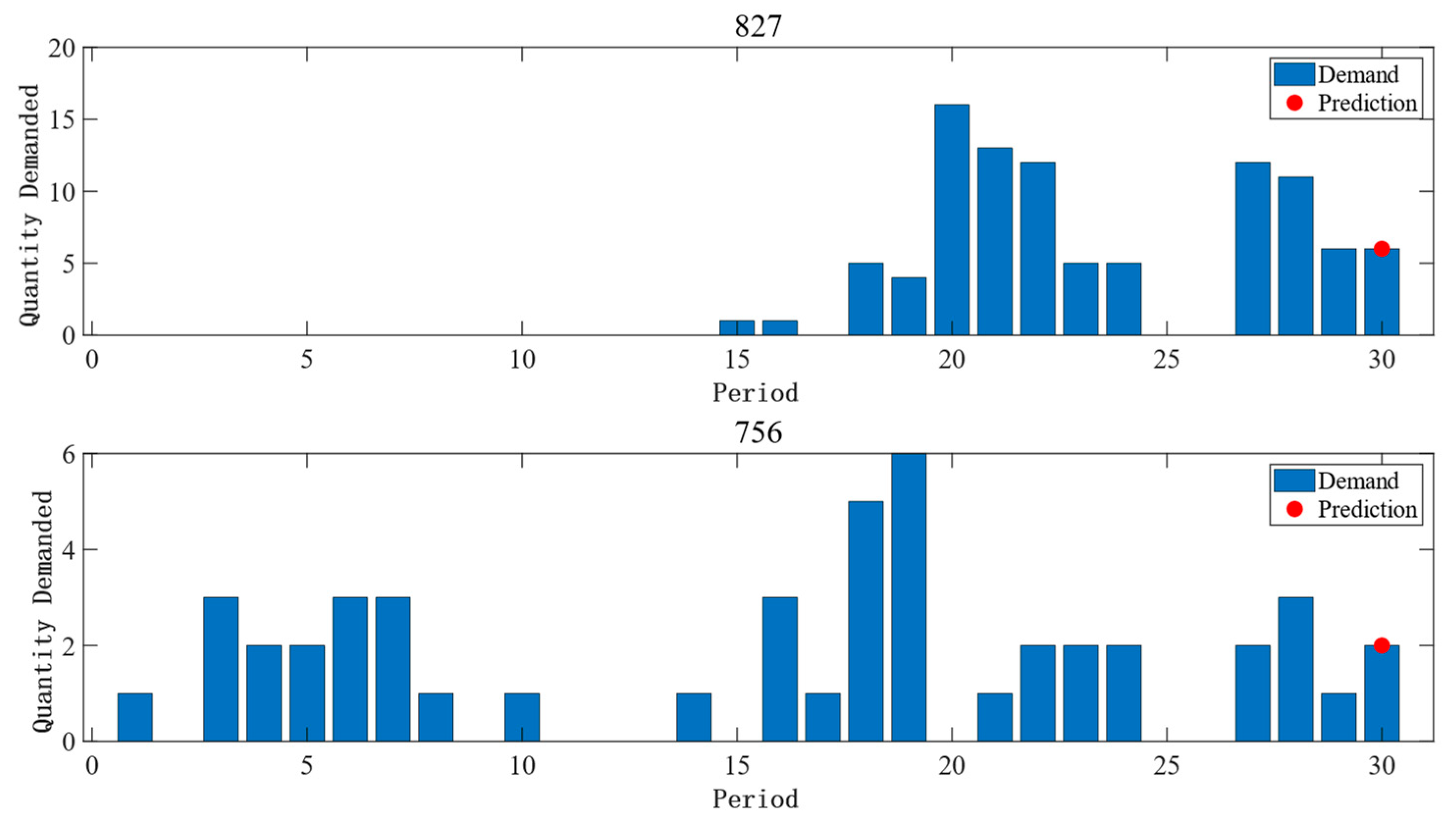
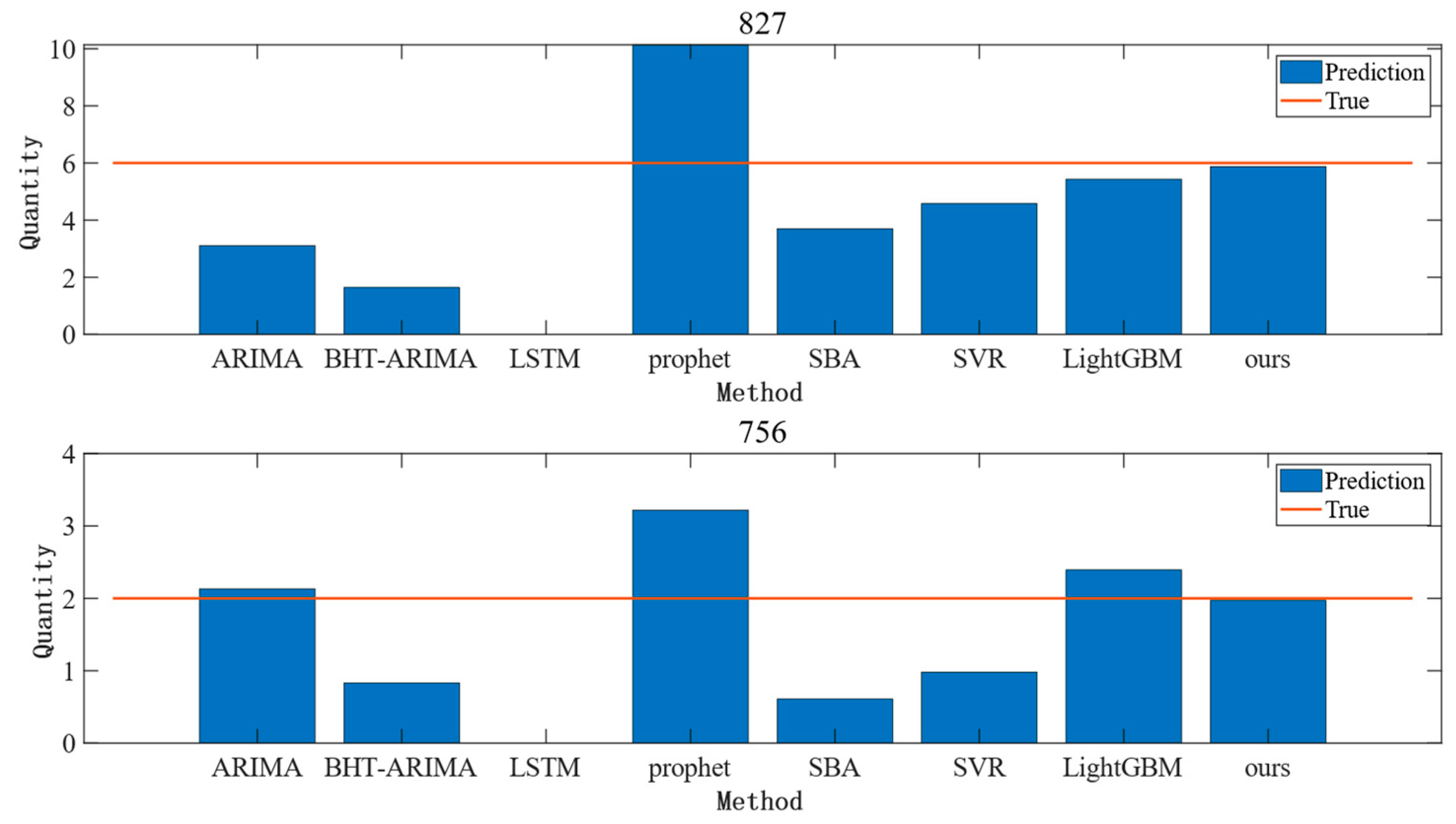
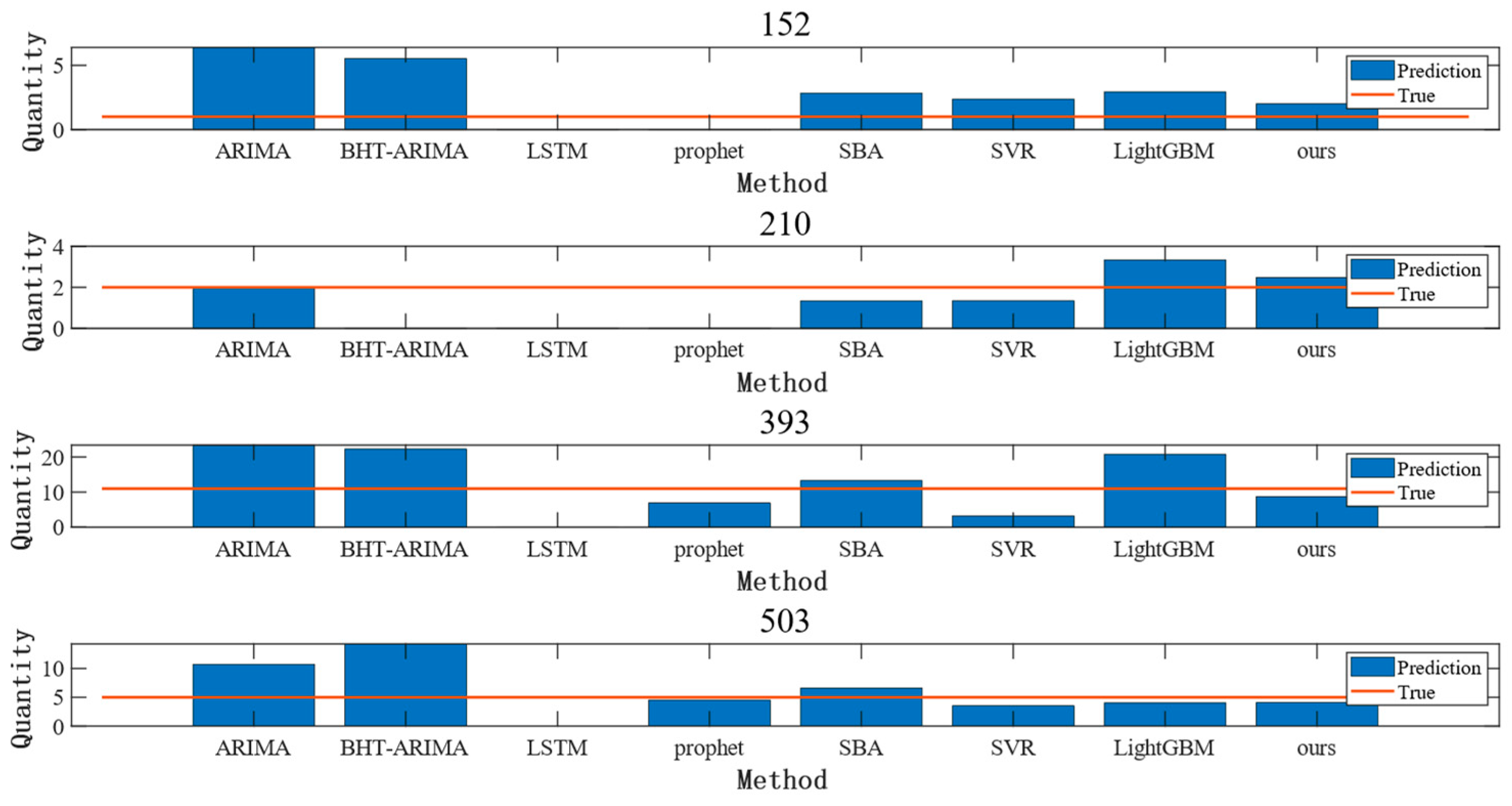
4.6. Comparison Experiment
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Croston, J.D. Forecasting and stock control for intermittent demands. J. Oper. Res. Soc. 1972, 23, 289–303. [Google Scholar] [CrossRef]
- Gencay, R. Non-linear prediction of security returns with moving average rules. J. Forecast. 1996, 15, 165–174. [Google Scholar] [CrossRef]
- Li, X.; Zhao, X.; Pu, W. Battle damage-oriented spare parts forecasting method based on wartime influencing factors analysis and ε-support vector regression. Int. J. Prod. Res. 2020, 58, 1178–1198. [Google Scholar] [CrossRef]
- Van Steenbergen, R.M.; Mes, M.R.K. Forecasting demand profiles of new products. Decis. Support Syst. 2020, 139, 113401. [Google Scholar] [CrossRef]
- Huang, L.; Xie, G.; Zhao, W.; Gu, Y.; Huang, Y. Regional logistics demand forecasting: A BP neural network approach. Complex Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Syntetos, A.A.; Boylan, J.E. The accuracy of intermittent demand estimates. Int. J. Forecast. 2005, 21, 303–314. [Google Scholar] [CrossRef]
- Teunter, R.H.; Syntetos, A.A.; Babai, M.Z. Intermittent demand: Linking forecasting to inventory obsolescence. Eur. J. Oper. Res. 2011, 214, 606–615. [Google Scholar] [CrossRef]
- Montero-Manso, P.; Athanasopoulos, G.; Hyndman, R.J.; Talagala, T.S. FFORMA: Feature-based forecast model averaging. Int. J. Forecast. 2020, 36, 86–92. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. M5 accuracy competition: Results, findings, and conclusions. Int. J. Forecast. 2022, 38, 1346–1364. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. Lightgbm: A highly efficient gradient boosting deci-sion tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Muhaimin, A.; Prastyo, D.D.; Lu, H.H.S. Forecasting with recurrent neural network in intermittent demand data. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 802–809. [Google Scholar]
- Syntetos, A.A.; Boylan, J.E.; Croston, J.D. On the categorization of demand patterns. J. Oper. Res. Soc. 2005, 56, 495–503. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep Domain Confusion: Maximizing for Domain Invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Petropoulos, F.; Makridakis, S.; Assimakopoulos, V.; Nikolopoulos, K. ‘Horses for Courses’ in demand forecasting. Eur. J. Oper. Res. 2014, 237, 152–163. [Google Scholar] [CrossRef]
- Mao, W.; Liu, J.; Chen, J.; Liang, X. An interpretable deep transfer learning-based remaining useful life prediction approach for bearings with selective degradation knowledge fusion. IEEE Trans. Instrum. Meas. 2022, 71, 1–16. [Google Scholar] [CrossRef]
- Mao, W.; Liu, K.; Zhang, Y.; Liang, X.; Wang, Z. Self-supervised Deep Tensor Domain-Adversarial Regression Adaptation for Online Remaining Useful Life Prediction Across Machines. IEEE Trans. Instrum. Meas. 2023, 72. [Google Scholar] [CrossRef]
- Du, Y.; Wang, J.; Feng, W.; Pan, S.; Qin, T.; Xu, R.; Wang, C. Adarnn: Adaptive learning and forecasting of time series. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, Queensland, Australia, 1–5 November 2021; pp. 402–411. [Google Scholar]
- Shi, Q.; Yin, J.; Cai, J.; Cichocki, A.; Yokota, T.; Chen, L.; Yuan, M.; Zeng, J. Block Hankel tensor ARIMA for multiple short time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5758–5766. [Google Scholar]
- Saiktishna, C.; Sumanth, N.S.V.; Rao, M.M.S.; Thangakumar, J. Historical Analysis and Time Series Forecasting of Stock Market using FB Prophet. In Proceedings of the 2022 6th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 25–27 May 2022; pp. 1846–1851. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Periods | Number of Spare Parts | Attributes |
|---|---|---|---|
| Dataset 1 | 30 | 1200 | Quantity, equipment working hours, equipment type |
| Dataset 2 | 34 | 999 | Part numbers, number of spare part failures |
| Method Type | Method Name |
|---|---|
| Traditional Method | SBA [6], ARIMA |
| Machine Learning | SVR [3], BHT_ARIMA [20], Prophet [21], LightGBM [11] |
| Deep Learning | LSTM [22] |
| Option | Dataset 1 | Dataset 2 | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | RMSSE | MAE | RMSE | RMSSE | |
| Option 1 | 0.3477 | 0.6382 | 0.3082 | 0.1476 | 0.2853 | 0.0445 |
| Option 2 | 0.3414 | 0.6324 | 0.2986 | 0.1179 | 0.2786 | 0.0458 |
| Ours | 0.3297 | 0.5996 | 0.2813 | 0.1058 | 0.2685 | 0.0399 |
| Method | Dataset 1 | Dataset 2 | ||||
|---|---|---|---|---|---|---|
| MAE | RMSE | RMSSE | MAE | RMSE | RMSSE | |
| SBA | 0.3392 | 0.6365 | 0.2829 | 0.1606 | 0.2878 | 0.0432 |
| ARIMA | 0.3939 | 0.7081 | 0.3842 | 0.1391 | 0.3383 | 0.0484 |
| SVR | 0.3515 | 0.6530 | 0.3226 | 0.1184 | 0.2700 | 0.0414 |
| prophet | 0.5806 | 0.8320 | 0.4779 | 0.1627 | 0.2945 | 0.0479 |
| BHT_ARIMA | 0.7799 | 1.1119 | 0.6965 | 0.4006 | 0.8196 | 0.1039 |
| LightGBM | 0.3801 | 0.6094 | 0.3246 | 0.1482 | 0.2785 | 0.0421 |
| LSTM | 0.6718 | 0.8143 | 0.5648 | 0.1669 | 0.2746 | 0.0434 |
| Ours | 0.3298 | 0.5997 | 0.2814 | 0.1058 | 0.2686 | 0.0400 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, L.; Liu, X.; Mao, W.; Yang, K.; Song, Z. Spare Parts Demand Forecasting Method Based on Intermittent Feature Adaptation. Entropy 2023, 25, 764. https://doi.org/10.3390/e25050764
Fan L, Liu X, Mao W, Yang K, Song Z. Spare Parts Demand Forecasting Method Based on Intermittent Feature Adaptation. Entropy. 2023; 25(5):764. https://doi.org/10.3390/e25050764
Chicago/Turabian StyleFan, Lilin, Xia Liu, Wentao Mao, Kai Yang, and Zhaoyu Song. 2023. "Spare Parts Demand Forecasting Method Based on Intermittent Feature Adaptation" Entropy 25, no. 5: 764. https://doi.org/10.3390/e25050764