

On the Lift, Related Privacy Measures, and Applications to Privacy–Utility Trade-Offs †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Contributions
2. Preliminaries
2.1. Notation
2.2. System Model and Privacy Measures
3. Asymmetric Local Information Privacy
- 1.
- ;
- 2.
- and ;
- 3.
- and ;
- 4.
- ε-LDP is satisfied where ;
3.1. ALIP Privacy–Utility Trade-Off
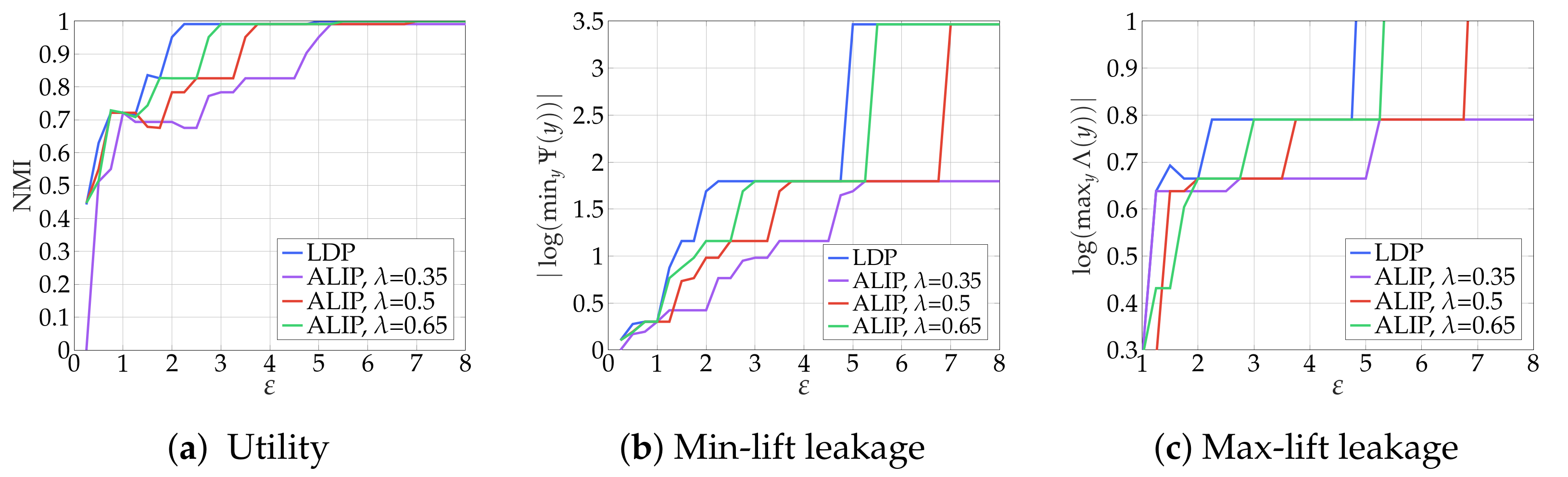
3.1.1. Watchdog Mechanism
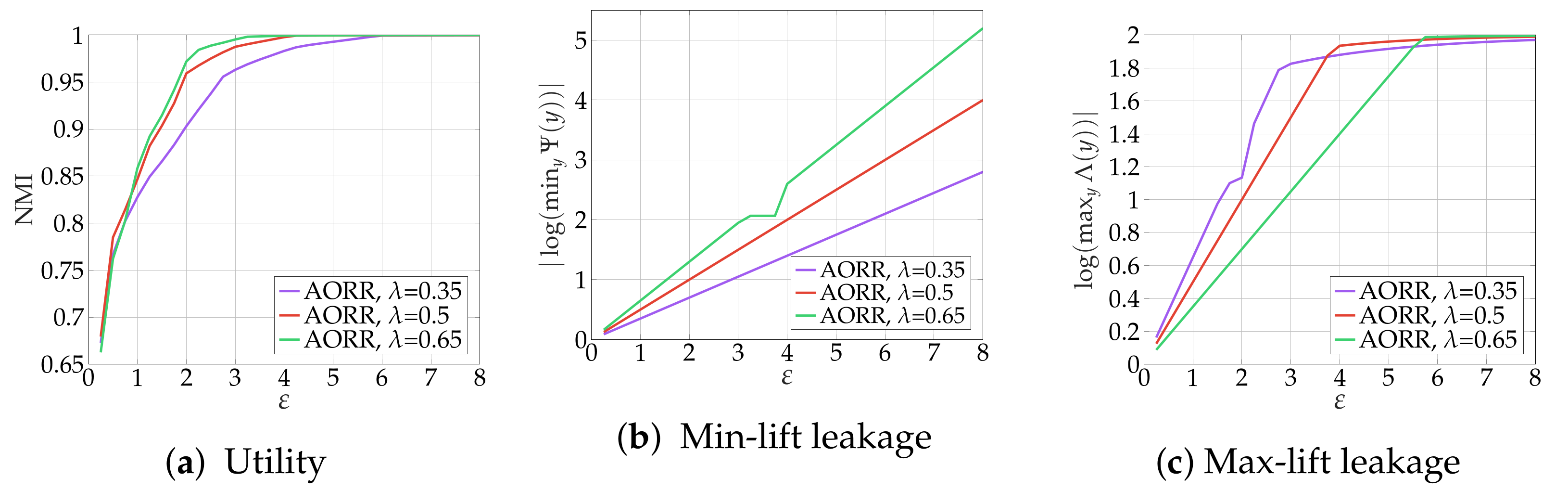
3.1.2. Asymmetric Optimal Random Response (AORR)
3.1.3. Numerical Results
4. Subset Merging in Watchdog Mechanism
4.1. Greedy Algorithm to Make Refined Subsets of High-Risk Symbols
| Algorithm 1: Subset merging in the watchdog mechanism. |
 |
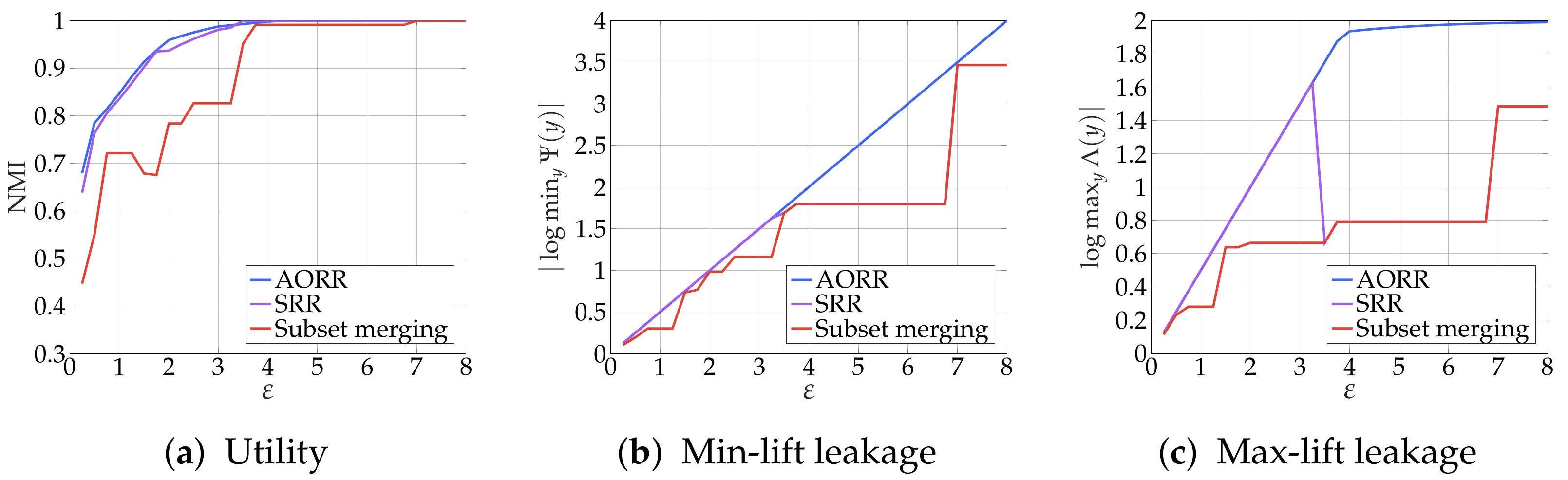
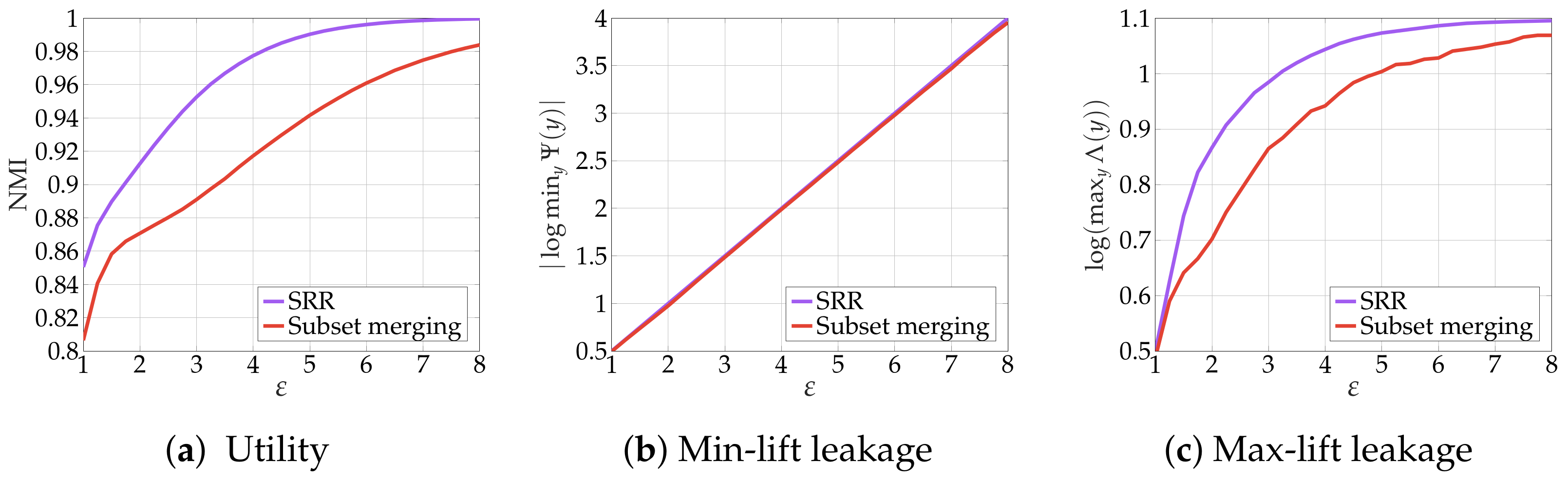
4.2. Numerical Results
5. Subset Random Response
5.1. Algorithm for Subset Random Response
| Algorithm 2: Subset random response. |
 |
5.2. Numerical Results
6. Lift-Based and Lift-Inverse Measures
- The -lift is given bythen the total variation distance will be
- The -lift is given bythen -divergence will be
- The α-lift is given bythen Sibson MI will be
- 1.
- ;
- 2.
- ;
- 3.
- .
- 1.
- If ;
- 2.
- If ;
- 3.
- If .
6.1. Lift-Inverse Measures
- The -lift-inverse is given by
- The -lift-inverse is given by
- The α-lift-inverse is given by
- 1.
- 2.
- 3.
- 1.
- If
- 2.
- If
- 3.
- If
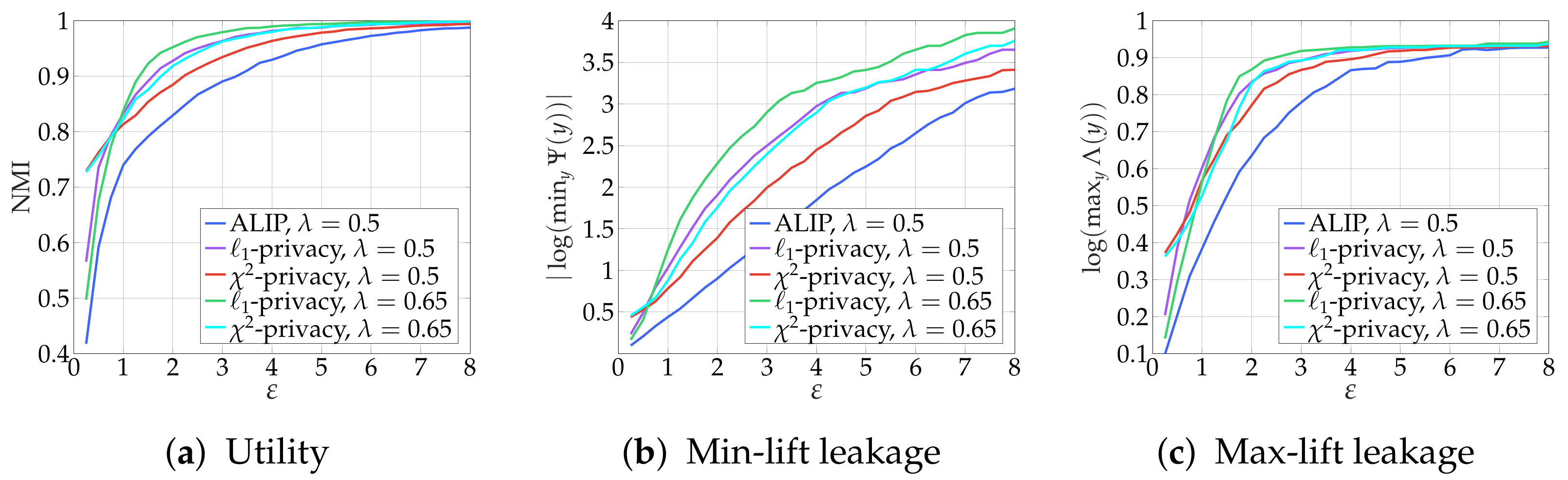
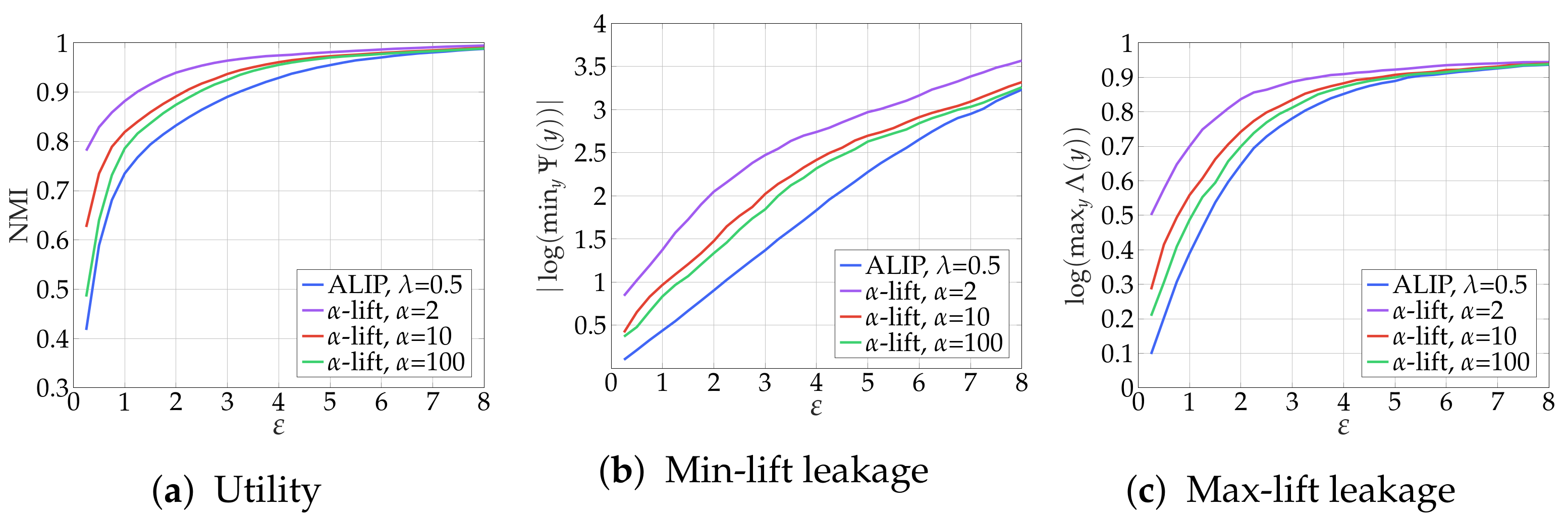
6.2. PUT and Numerical Results
- -privacy: and
- -privacy: and
- -lift-privacy: and
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B
- For MI, we have
- For the total variation distance, we have
- For -divergence, we have
- For Sibson MI, we have
- For Arimoto MI, we havewhere
- In LDP, for all , we have
Appendix C
Appendix D
- For -lift, we have
- For -lift, we have
- For the -lift, we have
Appendix E
- When , for all , we havewhich results in
- When , for all , we havewhich results in
- When , for all , we havewhich results in
Appendix F
- For -lift-inverse, we have
- For -lift-inverse, we have
- For -lift-inverse, we have
Appendix G
- When , for all , we havewhich results in
- When , for all , we havewhich results in
- When , for all , we havewhich results in
References
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography; Halevi, S., Rabin, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 265–284. [Google Scholar]
- Dwork, C. Differential Privacy. In Proceedings of the 33rd International Colloquium on Automata, Languages and Programming, part II (ICALP 2006), Venice, Italy, 10–14 July 2006; Volume 4052, pp. 1–12. [Google Scholar]
- Dwork, C. Differential privacy. In Encyclopedia of Cryptography and Security; Springer: Boston, MA, USA, 2011; pp. 338–340. [Google Scholar] [CrossRef]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Kasiviswanathan, S.P.; Lee, H.K.; Nissim, K.; Raskhodnikova, S.; Smith, A. What can we learn privately? SIAM J. Comput. 2011, 40, 793–826. [Google Scholar] [CrossRef]
- Duchi, J.C.; Jordan, M.I.; Wainwright, M.J. Local Privacy and Statistical Minimax Rates. In Proceedings of the 2013 IEEE 54th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 26–29 October 2013; pp. 429–438. [Google Scholar] [CrossRef]
- Kairouz, P.; Oh, S.; Viswanath, P. Extremal mechanisms for local differential privacy. Adv. Neural Inf. Process. Syst. 2014, 4, 2879–2887. [Google Scholar]
- Sarwate, A.D.; Sankar, L. A rate-disortion perspective on local differential privacy. In Proceedings of the 2014 52nd Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 30 September–3 October 2014; pp. 903–908. [Google Scholar] [CrossRef]
- Kalantari, K.; Sankar, L.; Sarwate, A.D. Robust Privacy-Utility Tradeoffs Under Differential Privacy and Hamming Distortion. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2816–2830. [Google Scholar] [CrossRef]
- Sankar, L.; Rajagopalan, S.R.; Poor, H.V. Utility-privacy tradeoffs in databases: An information-theoretic approach. IEEE Trans. Inf. Forensics Secur. 2013, 8, 838–852. [Google Scholar] [CrossRef]
- Jiang, B.; Li, M.; Tandon, R. Context-aware Data Aggregation with Localized Information Privacy. In Proceedings of the 2018 IEEE Conference on Communications and Network Security (CNS), Beijing, China, 30 May–1 June 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Makhdoumi, A.; Salamatian, S.; Fawaz, N.; Médard, M. From the Information Bottleneck to the Privacy Funnel. In Proceedings of the 2014 IEEE Information Theory Workshop (ITW 2014), Hobart, TAS, Australia, 2–5 November 2014; pp. 501–505. [Google Scholar] [CrossRef]
- Salamatian, S.; du Pin Calmon, F.; Fawaz, N.; Makhdoumi, A.; Médard, M. Privacy-Utility Tradeoff and Privacy Funnel. 2020. Available online: http://www.mit.edu/~salmansa/files/privacy_TIFS.pdf (accessed on 16 January 2020).
- Issa, I.; Kamath, S.; Wagner, A.B. An operational measure of information leakage. In Proceedings of the 2016 Annual Conference on Information Science and Systems (CISS), Princeton, NJ, USA, 16–18 March 2016; pp. 234–239. [Google Scholar]
- Issa, I.; Kamath, S.; Wagner, A.B. Maximal leakage minimization for the Shannon cipher system. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 520–524. [Google Scholar] [CrossRef]
- Issa, I.; Wagner, A.B.; Kamath, S. An Operational Approach to Information Leakage. IEEE Trans. Inf. Theory 2020, 66, 1625–1657. [Google Scholar] [CrossRef]
- Liao, J.; Kosut, O.; Sankar, L.; Calmon, F.P. A tunable measure for information leakage. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 701–705. [Google Scholar]
- Du Pin Calmon, F.; Fawaz, N. Privacy against statistical inference. In Proceedings of the 50th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 1–5 October 2012; pp. 1401–1408. [Google Scholar]
- Jiang, B.; Li, M.; Tandon, R. Local Information Privacy with Bounded Prior. In Proceedings of the 2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Seif, M.; Tandon, R.; Li, M. Context Aware Laplacian Mechanism for Local Information Privacy. In Proceedings of the 2019 IEEE Information Theory Workshop (ITW), Visby, Sweden, 25–28 August 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Jiang, B.; Li, M.; Tandon, R. Local Information Privacy and Its Application to Privacy-Preserving Data Aggregation. IEEE Trans. Dependable Secur. Comput. 2020, 19, 1918–1935. [Google Scholar] [CrossRef]
- Jiang, B.; Seif, M.; Tandon, R.; Li, M. Context-Aware Local Information Privacy. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3694–3708. [Google Scholar] [CrossRef]
- Ding, N.; Liu, Y.; Farokhi, F. A Linear Reduction Method for Local Differential Privacy and Log-lift. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, VIC, Australia, 12–20 July 2021; pp. 551–556. [Google Scholar] [CrossRef]
- Hsu, H.; Asoodeh, S.; Calmon, F.P. Information-Theoretic Privacy Watchdogs. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 552–556. [Google Scholar]
- Sadeghi, P.; Ding, N.; Rakotoarivelo, T. On Properties and Optimization of Information-theoretic Privacy Watchdog. In Proceedings of the 2020 IEEE Information Theory Workshop (ITW), Riva del Garda, Italy, 11–15 April 2020. [Google Scholar]
- Zarrabian, M.A.; Ding, N.; Sadeghi, P.; Rakotoarivelo, T. Enhancing utility in the watchdog privacy mechanism. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Virtual, 7–13 May 2022; pp. 2979–2983. [Google Scholar]
- Razeghi, B.; Calmon, F.; Gunduz, D.; Voloshynovskiy, S. On Perfect Obfuscation: Local Information Geometry Analysis. arXiv 2020, arXiv:2009.04157. [Google Scholar]
- Lopuhaä-Zwakenberg, M.; Tong, H.; Škorić, B. Data Sanitisation Protocols for the Privacy Funnel with Differential Privacy Guarantees. Int. J. Adv. Secur. 2021, 13, 162–174. [Google Scholar]
- Evfimievski, A.; Gehrke, J.; Srikant, R. Limiting Privacy Breaches in Privacy Preserving Data Mining. In Proceedings of the Twenty-Second ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, PODS ’03, San Diego, CA, USA, 9–12 June 2003; pp. 211–222. [Google Scholar] [CrossRef]
- Saeidian, S.; Cervia, G.; Oechtering, T.J.; Skoglund, M. Pointwise Maximal Leakage. arXiv 2022, arXiv:2205.04935. [Google Scholar]
- Fernandes, N.; McIver, A.; Sadeghi, P. Explaining epsilon in differential privacy through the lens of information theory. arXiv 2022, arXiv:2210.12916. [Google Scholar]
- Zamani, A.; Oechtering, T.J.; Skoglund, M. Data Disclosure With Non-Zero Leakage and Non-Invertible Leakage Matrix. IEEE Trans. Inf. Forensics Secur. 2022, 17, 165–179. [Google Scholar] [CrossRef]
- Zamani, A.; Oechtering, T.J.; Skoglund, M. A Design Framework for Strongly χ2-Private Data Disclosure. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2312–2325. [Google Scholar] [CrossRef]
- Ding, N.; Zarrabian, M.A.; Sadeghi, P. α-Information-theoretic Privacy Watchdog and Optimal Privatization Scheme. In Proceedings of the 2021 IEEE International Symposium on Information Theory (ISIT), Melbourne, VIC, Australia, 12–20 July 2021; pp. 2584–2589. [Google Scholar]
- Rassouli, B.; Gunduz, D. Optimal utility-privacy trade-off with total variation distance as a privacy measure. IEEE Trans. Inf. Forensics Secur. 2019, 15, 594–603. [Google Scholar] [CrossRef]
- Asoodeh, S.; Diaz, M.; Alajaji, F.; Linder, T. Estimation efficiency under privacy constraints. IEEE Trans. Inf. Theory 2018, 65, 1512–1534. [Google Scholar] [CrossRef]
- Rassouli, B.; Rosas, F.E.; Gunduz, D. Data Disclosure under Perfect Sample Privacy. arXiv 2019, arXiv:1904.01711. [Google Scholar] [CrossRef]
- Becker, B.; Kohavi, R. Adult. UC Irvine Machine Learning Repository. Available online: https://archive-beta.ics.uci.edu/dataset/2/adult (accessed on 5 January 1996).
- Liu, Y.; Sadeghi, P.; Arbabjolfaei, F.; Kim, Y.H. Capacity Theorems for Distributed Index Coding. IEEE Trans. Inf. Theory 2020, 66, 4653–4680. [Google Scholar] [CrossRef]
- Wang, H.; Vo, L.; Calmon, F.P.; Médard, M.; Duffy, K.R.; Varia, M. Privacy With Estimation Guarantees. IEEE Trans. Inf. Theory 2019, 65, 8025–8042. [Google Scholar] [CrossRef]













Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zarrabian, M.A.; Ding, N.; Sadeghi, P. On the Lift, Related Privacy Measures, and Applications to Privacy–Utility Trade-Offs. Entropy 2023, 25, 679. https://doi.org/10.3390/e25040679
Zarrabian MA, Ding N, Sadeghi P. On the Lift, Related Privacy Measures, and Applications to Privacy–Utility Trade-Offs. Entropy. 2023; 25(4):679. https://doi.org/10.3390/e25040679
Chicago/Turabian StyleZarrabian, Mohammad Amin, Ni Ding, and Parastoo Sadeghi. 2023. "On the Lift, Related Privacy Measures, and Applications to Privacy–Utility Trade-Offs" Entropy 25, no. 4: 679. https://doi.org/10.3390/e25040679