
Higher-Order Interactions and Their Duals Reveal Synergy and Logical Dependence beyond Shannon-Information

1
MRC Human Genetics Unit, Institute of Genetics & Cancer, University of Edinburgh, Edinburgh EH8 9YL, UK
2
Higgs Centre for Theoretical Physics, School of Physics & Astronomy, University of Edinburgh, Edinburgh EH8 9YL, UK
3
Biomedical AI Lab, School of Informatics, University of Edinburgh, Edinburgh EH8 9YL, UK
Entropy 2023, 25(4), 648; https://doi.org/10.3390/e25040648
Submission received: 23 February 2023
/
Revised: 6 April 2023
/
Accepted: 7 April 2023
/
Published: 12 April 2023
(This article belongs to the Section Information Theory, Probability and Statistics)
Abstract
:Information-theoretic quantities reveal dependencies among variables in the structure of joint, marginal, and conditional entropies while leaving certain fundamentally different systems indistinguishable. Furthermore, there is no consensus on the correct higher-order generalisation of mutual information (MI). In this manuscript, we show that a recently proposed model-free definition of higher-order interactions among binary variables (MFIs), such as mutual information, is a Möbius inversion on a Boolean algebra, except of surprisal instead of entropy. This provides an information-theoretic interpretation to the MFIs, and by extension to Ising interactions. We study the objects dual to mutual information and the MFIs on the order-reversed lattices. We find that dual MI is related to the previously studied differential mutual information, while dual interactions are interactions with respect to a different background state. Unlike (dual) mutual information, interactions and their duals uniquely identify all six 2-input logic gates, the dy- and triadic distributions, and different causal dynamics that are identical in terms of their Shannon information content.
Keywords:
higher-order; information; entropy; synergy; triadic; Möbius inversions; Ising model; lattices1. Introduction
1.1. Higher-Order Interactions
All non-trivial structures in data or probability distributions correspond to dependencies among the different features, or variables. These dependencies can be present among pairs of variables, i.e., pairwise, or can be higher-order. A dependency, or interaction, is called higher-order if it is inherently a property of more than two variables and if it cannot be decomposed into pairwise quantities. The term has been used more generally to refer simply to complex interactions, as for example in [1] to refer to changes in gene co-expression over time; in this article, however, it is used only in the stricter sense defined in Section 2.
The reason such higher-order structures are interesting is twofold. First, higher-order dependence corresponds to a fundamentally different kind of communication and interaction among the components of a system. If a system contains higher-order interactions, then its dependency structure cannot be represented by a graph and requires a hypergraph, where a single ‘hyperedge’ can connect more than two nodes. It is desirable to be able to detect and describe such systems accurately, which requires a good understanding of higher-order interactions. Second, higher-order interactions might play an important role in nature, and have been identified in various interaction networks, including genetic [2,3,4,5], neuronal [6,7,8,9,10], ecological [11,12,13], drug interaction [14], social [15,16,17], and physical [18,19] networks. Furthermore, there is evidence that higher-order interactions are responsible for the rich dynamics [20] or bistability [21] in biological networks; for example, synthetic lethality experiments have shown that the trigenic interactions in yeast form a larger network than the pairwise interactions [4].
Despite this, purely pairwise descriptions of nature have been remarkably successful, which the authors of [22,23] attribute to the fact that there are regimes in terms of the strength and density of coupling among the variables within which pairwise descriptions are sufficient. Alternatively, it may be attributed to the fact that higher-order interactions have been understudied and their effects underestimated. Currently, perhaps the most promising method of quantifying higher-order interactions is information theory. The two most commonly used quantities are mutual information and its higher-order generalisation (used in, e.g., [24,25]) and the total correlation (introduced in [26] and recently used in [27]). However, one particular problem of interest that total correlation and mutual information do not address is that of synergy and redundancy. Given a set of variables with an nth-order dependency, what part of that is exclusively nth-order (called the synergistic part), and what part can be found in a subset of variables as well (the redundant part)? Quantifying the exact extent to which shared information is synergistic is an open problem, and is most commonly addressed using partial information decomposition [28], which has been applied mainly in the context of theoretical neuroscience [29]. In this article, a different more statistical approach to identifying synergy is taken, which is ultimately shown to be intimately related to information theory while offering significant advantages beyond classical entropy-based quantities.
1.2. Model-Free Interactions and the Inverse Ising Problem
In 1957, E.T. Jaynes famously showed that statistical equilibrium mechanics can be seen as a maximum entropy solution to the inverse problem of constructing a probability distribution that best reproduces a sample distribution [30]. More precisely, the equilibrium dynamics of the (inhomogeneous, or glass-like) generalised Ising model with interactions up to the nth order arise naturally as the maximum entropy distribution compatible with a dataset after observing the first n moments among binary variables. This means that in order to reproduce the moments in the data in a maximally non-committal way, it is necessary to introduce higher-order interactions, i.e., terms that involve more than two variables, in the description of the system. Fitting such a generalised Ising model to data is nontrivial; while the log-likelihood of the Ising model is concave in the the coupling parameters, the cost of evaluating it is exponential in the total number of variables N, which is often intractable in practice [31]. In [32], the authors introduced an estimator of model-free interactions (MFIs) that exactly coincides with the solution to the inverse generalised Ising problem. Moreover, the cost of estimating all nth-order model-free interactions among N variables from M observations scales as (i.e., polynomially) in the total system size N. However, this is true only when sufficient data is available. With limited data, certain interactions might require inferring the conditional dependencies from the data, which in the worst case scales exponentially in N again. The definition of MFIs offered in [32] seems to be a general one; in addition to offering a solution to the inverse generalised Ising problem, MFIs are expressible in terms of average treatment effects (ATEs) or regression coefficients. Throughout this article, the general term ‘MFI’ is used, and may be read simply as referring to the maximum entropy or Ising interaction.
1.3. Outline
In Section 2.1, the definition of the MFIs is stated along with a number of their properties. To explicitly link the MFIs to information theory, a redefinition of mutual information in terms of Möbius inversions is provided in Section 2.2, which is then linked to a similar redefinition of the MFIs in Section 3.1 and Section 3.2. A definition in terms of Möbius inversions naturally leads to dual definitions of all objects, which are subsequently explored in Section 3.3. Then, in Section 4, simple fundamental examples are used to demonstrate that MFIs can differentiate distributions that entropy-based quantities cannot. Finally, the results are summarised and reflected upon in Section 5.
2. Background
2.1. Model-Free Interactions
We start by re-defining the interactions introduced in [32]. We define the isolated effect (or 1-point interaction) of a variable on an observable Y as
where the effect of on Y is isolated by conditioning on all other variables being zero. This expression is well-defined, as the restriction of a derivative is the derivative of the restriction. A pair of variables and has a 2-point interaction when the value of changes the 1-point interaction of on Y:
A third variable can modulate this 2-point interaction through what we call a 3-point interaction, :
This process of taking derivatives with respect to an increasing number of variables can be repeated to define n-point interactions.
Definition 1 (n-point interaction with respect to outcome Y).
Let p be a probability distribution over a set X of random variables and let Y be a function . Then, the n-point interaction between variables is provided by
where .
This definition of interaction makes explicit the fact that interactions are defined with respect to some outcome. The authors of [32] refer to the interactions from Definition 1 as additive, which they distinguish from multiplicative interactions. However, when the outcome is chosen to be the log of the joint distribution over all variables X, then the additive and multiplicative interactions are equivalent and simply related through a logarithm [32]. Setting the outcome to be has other nice properties as well. First, while probabilities are restricted to the non-negative reals, a log-transformation removes this restriction and makes the outcome and subsequent interactions take both positive and negative values, which can have different interpretations. Second, it is this outcome that makes the interactions interpretable as maximum entropy interactions, as they exactly coincide with Ising interactions. Finally, this can be considered the most general outcome possible, as all marginal and conditional probabilities are encoded in this joint distribution. This leads to the following definition of a model-free interaction.
Definition 2 (model-free n-point interaction between binary variables).
A model-free n-point interaction (MFI) is an n-point interaction between binary random variables with respect to the logarithm of their joint probability
where .
If the variables are binary, then a definition for a derivative with respect to a binary variable is needed.
Definition 3 (derivative of a function with respect to a binary variable).
Let be a real-valued function of a set X of n binary variables, labelled as , . Then, the derivative operator with respect to acts on as follows:
The linearity of the derivative operator then immediately and uniquely defines the higher-order derivatives.
Using this definition, the n-point interactions become model-free in the sense that they are ratios of probabilities that do not involve the functional form of the joint probability distribution. For example, writing for , the first three orders can be written out as follows (recall that the notation here refers to the derivative operator from Definition 3):
where Bayes’ rule is used to replace joint probabilities with conditional probabilities. This definition of interaction has the following properties:
- It is symmetric in terms of the variables, as for any set of variables S and any permutation .
- Conditionally independent variables do not interact: .
- The interactions are model-free; no knowledge of the functional form of is required, and the probabilities can be directly estimated from i.i.d. samples.
- The MFIs are exactly the Ising interactions in the maximum entropy model after observing moments of the data. This can be readily verified by settingand using Definition 2.
Furthermore, in Appendix A.2 the following two useful properties are introduced and proved:
- An n-point interaction can only be non-zero if all n variables are in each other’s minimal Markov blanket.
- If does not include the full complement of the interacting variables, the bias this induces in the estimate of the interaction is proportional to the pointwise mutual information of states where the omitted variables are 0.
2.2. Mutual Information as a Möbius Inversion
The definition of an n-point interaction as a derivative of a derivative is reminiscent of Gregory Bateson’s view of information as a difference which makes a difference [35]; however, the relationship between information theory and model-free interactions rests on more than a linguistic coincidence. It turns out that interactions and information are generalised derivatives of similar functions on Boolean algebras. To see this, consider the definition of pairwise mutual information and its third-order generalisation:
Note that all MI-based quantities can be written thusly as sums of marginal entropies of subsets of the set of variables. Given a finite set of variables S, its powerset can be assigned a partial ordering as follows:
This poset is called a Boolean algebra, and because each pair of sets has a unique supremum (their union) and infimum (their intersection), it is a lattice. This lattice structure is visualised for two and three variables in Figure 1. In general, the lattice of an n-variable Boolean algebra forms an n-cube. Furthermore, for any finite n, the n-variable Boolean algebra forms a bounded lattice, which means that it has a greatest element, denoted as , and a least element, denoted as .
On a poset P, we define the Möbius function as
This function type makes an element of the incidence algebra of P. In fact, is the inverse of the zeta function , and 0 otherwise. On a Boolean algebra, such as a powerset ordered by inclusion, the Möbius function takes the simple form [36,37]. This definition allows the mutual information among a set of variables to be written as follows [38,39]:
where P is the Boolean algebra with and is the marginal entropy of the set of variables . Indeed, this coincides with Equation (11) for and with Equation (13) for . Equation (15) is a convolution known as a Möbius inversion.
Definition 4
The Möbius inversion is a generalisation of the derivative to posets. If , Equation (18) is just a discrete version of the fundamental theorem of calculus [36]. Equation (18) additionally implies that we can express joint entropy as a sum over mutual information:
For example, in the case of three variables,
Instead of starting with entropy, we could start with a quantity known as surprisal, or self-information, defined as the negative log probability of a certain state or realisation:
Surprisal plays an important role in information theory; indeed, the expected surprisal across all possible realisations is the entropy of the variable X:
As we are often interested in the marginal surprisal of a realisation summed over Y, we can write this explicitly as
With this, consider the Möbius inversion of the marginal surprisal over the lattice P:
This is a generalised version of the pointwise mutual information, which is usually defined on just two variables:
Summary
- Mutual information is the Möbius inversion of marginal entropy.
- Pointwise mutual information is the Möbius inversion of marginal surprisal.
3. Interactions and Their Duals
3.1. MFIs as Möbius Inversions
With mutual information defined in terms of Möbius inversions, the same can be done for the model-free interactions. Again, we start with (negative) surprisal. However, on Boolean variables a state is just a partition of the variables into two sets: one in which the variables are set to 1, and another in which they are set to 0. That means that the surprisal of observing a particular state is completely specified by which variables are set to 1 while keeping all other variables at 0, which can be written as
Definition 5 (interactions as Möbius inversions).
Let p be a probability distribution over a set T of random variables and let , the powerset of a set ordered by inclusion. Then, the interaction among variables τ is provided by
For example, when contains a single variable , then
which coincides with the 1-point interaction in Equation (7). Similarly, when contains two variables , then
which coincides with the 2-point interaction in Equation (8). In fact, this pattern holds in general.
Theorem 1 (equivalence of interactions).
The interaction from Definition 5 is the same as the model-free interaction from Definition 2, that is, for any set of variables it is the case that
Proof.
We have to show that
Both sides of this equation are sums of ±, where s is some binary string; thus, we have to show that the same strings appear with the same sign.
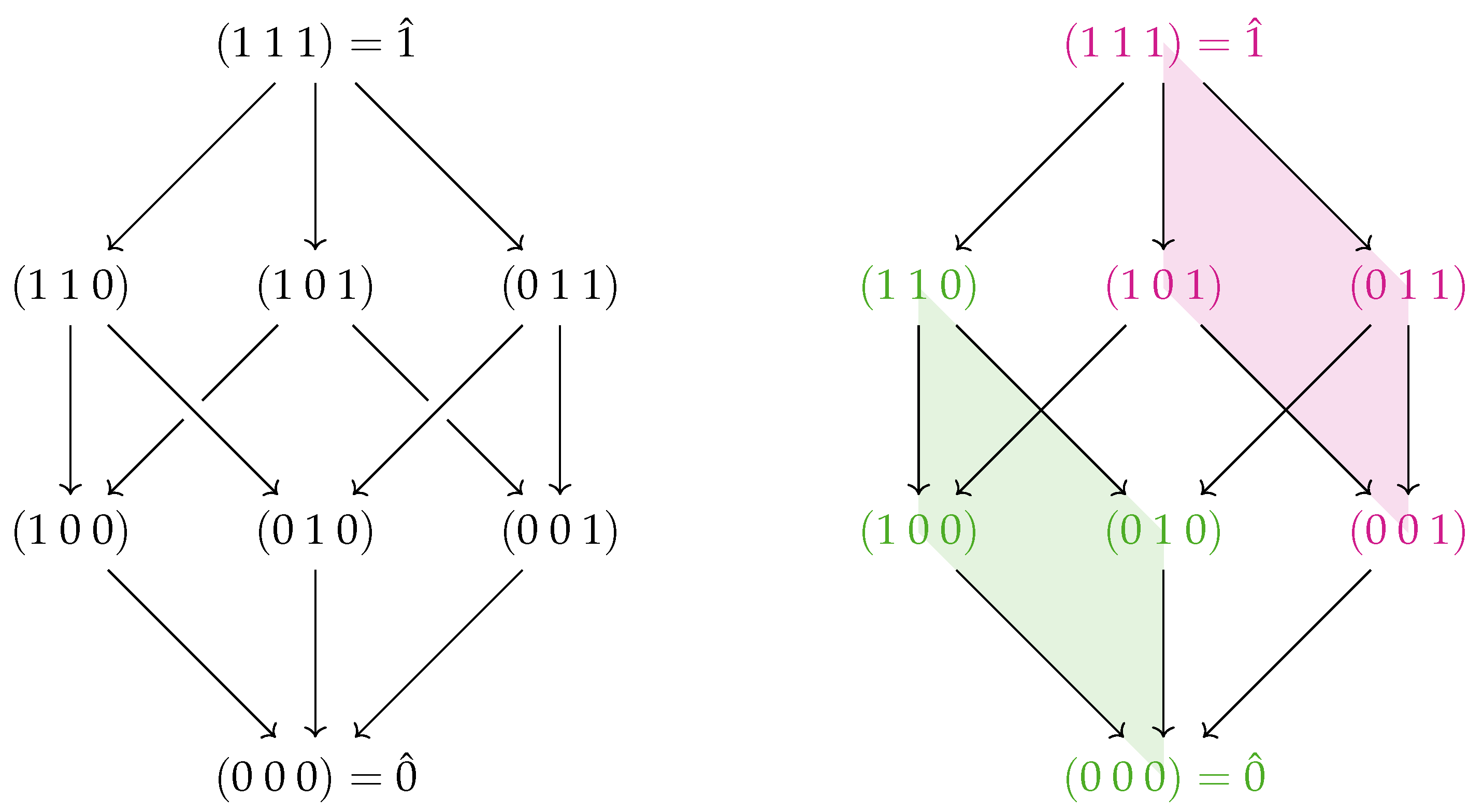
First, note that the Boolean algebra of sets ordered by inclusion (as in Figure 1) is equivalent to the poset of binary strings where for any two strings a and b, . The equivalence follows immediately upon setting each element to the string where and . This map is one-to-one and monotonic with respect to the partial order, as . This means that Definition 5 can be rewritten as a Möbius inversion on the lattice of Boolean strings (shown for the three-variable case on the left side of Figure 2):
Note that for any pair ( where with respective string representations , we have the following:
Thus, we can write
To see that this exactly coincides with Definition 2, we can define a map
where is the set of functions from n Boolean variables to . This map is defined as
With this map, the Boolean derivative of a function (see Definition 3) can be written as
In this way, the derivative with respect to a set S of m variables becomes function composition:
From this, it is clear that a term appears with a minus sign iff has been applied an odd number of times. Therefore, terms for which s contains an odd number of 0s receive a minus sign. This can be summarised as
Therefore, we can write
The sums and contain exactly the same terms, meaning that Equations (38) and (45) are equal. This completes the proof. □
Note that the structure of the lattice reveals structure in the interactions, as previously noted in [32]. On the right-hand side of Figure 2, two faces of the three-variable lattice are shaded. The green region corresponds to the 2-point interaction between the first two variables. The red region contains a similar interaction between the first two variables, except this time in the context of the third variable fixed to 1 instead of 0. This illustrates the interpretation of a 3-point interaction as the difference in two 2-point interactions (; note that is usually written as just ). The symmetry of the cube reveals the three different (though equivalent) choices as to which variable to set to 1. Treating the Boolean algebra as a die, where the sides facing up are ⚀, ⚁, and ⚂, we have
As before, we can invert Definition 5 and express the surprise of observing a state with all ones in terms of interactions, as follows:
For example, in the case where and
which illustrates that when X and Y tend to be off ( and ) and X and Y tend to be different (), observing the state (1, 1, 0) is very surprising.
3.2. Categorical Interactions
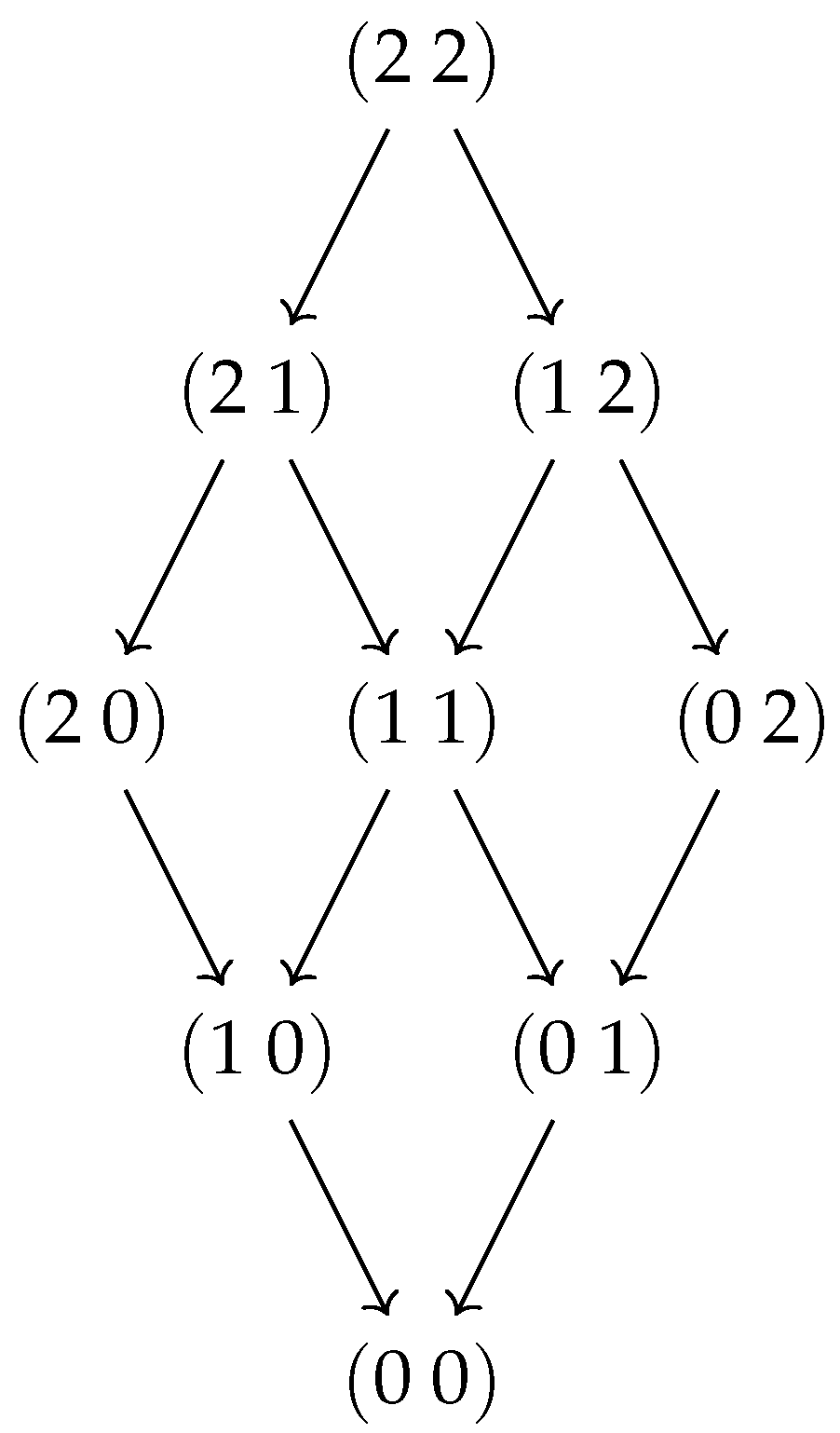
Taking seriously the definition of interactions as the Möbius inversion of surprisal, one might ask what happens when surprisal is inverted over a different lattice instead of using a Boolean algebra. One example is shown in Figure 3; it corresponds to variables that can take three values—0, 1, or 2—where states are ordered by . To calculate interactions on this lattice, we need to know the value of Möbius functions of type . It can be readily verified that most Möbius functions of this type are zero, with the exceptions of and , which provide the exact terms in the interactions between two categorical variables changing from (as defined in [32]). Calculating interactions on different sublattices with or provides us with the other categorical interactions. The transitivity property of the interactions, i.e., , follows immediately from the structure of the lattice in Figure 3 and the alternating signs of the Möbius functions on a Boolean algebra.
3.3. Information and Interactions on Dual Lattices
Lattices have the property that a set with the reverse order remains a lattice; that is, if is a lattice, then (where ) is a lattice. This raises the question of what corresponds to mutual information and interaction on such dual lattices. Recognising that a poset is a category with objects S and a morphism iff , these become definitions in the opposite category , meaning that they define dual objects.
Let us start with mutual information. We can calculate the dual mutual information, denoted , by first noting that the dual to a Boolean algebra is another Boolean algebra, meaning that we have . Simply replacing P with in Equation (15) yields
The dual mutual information of is simply , that is, the mutual information among all variables. However, the dual mutual information of a singleton set X is
where is known as the differential mutual information and describes the change in mutual information when leaving out X [40], i.e., when marginalising over the variable X. Note that a similar construction was already anticipated in [41] and that the differential mutual information has previously been used to describe information structures in genetics [39]. On the Boolean algebra of three variables , the dual mutual information of X can be written out as follows:
Because is the dual of mutual information, it should arguably be called the mutual co-information; however, the term co-information is unfortunately already in use to refer to normal higher-order mutual information.
To find the dual to the interactions, we start from Equation (36) and construct , the dual to the lattice of binary strings . A dual interaction of variables is denoted as , and is defined as follows:
Again, when , this is simply (, while the dual interaction of a singleton set X is
For example, on the three variable lattice in Figure 2, the dual interaction of X is
Writing for , it can be seen that this is equal to
which is similar to the 2-point interaction defined in Equation (8), now conditioned on instead of 0. Note the difference between dual mutual information and dual interactions here; the dual mutual information of X describes the effect on the mutual information from marginalising over X, whereas the dual interaction of X describes the effect on an interaction when fixing. This reflects a fundamental difference between mutual information and the interactions, in that the former is an averaged quantity and the latter a pointwise quantity.
Dual interactions should probably be called co-interactions; however, to avoid confusion with the term co-information, we instead refer to them simply as dual interactions. Dual interactions are interactions that are conditioned on certain variables being 1 instead of 0. This makes them no longer equal to the Ising interactions between Boolean variables; however, there are situations in which an interaction is more interesting in the context of instead of , for example, if Z is always 1 in the data under consideration.
Summary
- Mutual information is the Möbius inversion of marginal entropy on the lattice of subsets ordered by inclusion.
- Differential (or conditional) mutual information is the Möbius inversion of marginal entropy on the dual lattice.
- Model-free interactions are the Möbius inversion of surprisal on the lattice of subsets ordered by inclusion.
- Model-free dual interactions are the Möbius inversion of surprisal on the dual lattice.
- Dual interactions of a variable X are interactions between the other variables where X is set to 1 instead of 0.
To summarise these relationships diagrammatically, note that surprisals form a vector space as follows. Let be the powerset of a set of variables T and let . This forms a lattice ordered by inclusion, meaning that can be assigned a topological ordering indexed by i as . Let be the set of linear combinations of surprisals of subsets of T:
This set is assigned a vector space structure over by the usual scalar multiplication and addition. Note that the set
forms a basis for this vector space, because has no non-trivial solutions and a . Only when two variables a and b are independent do we have linear dependencies in , as it is then the case that . To define a map from , we only need to specify its action on and extend the definition linearly. This means that we can fully define the map by specifying
Similarly, we can define the expectation map as
which outputs the expected surprise over all realisations . Finally, note that the Möbius inversion over a poset P is an endomorphism of the set of functions over P, defined as
Together, these three maps ensure that the following diagram commutes:

For the case where and , this explicitly amounts to

4. Results and Examples
While mutual information and model-free interactions are related, there are several important differences in terms of how they capture dependencies. Note, for example, that higher-order information quantities are not independent of the lower-order quantities. The mutual information of three variables is bounded by the pairwise quantities as follows:
This means that there are no systems with zero pairwise mutual information and positive higher-order information. This is not true for the interactions. For example, a distribution with 3-point interactions and no pairwise interactions can trivially be constructed as . While this distribution has 3-point interactions with strength for triplets , all pairwise interactions among vanish when conditioning on . In fact, any positive discrete distribution can be written as a Boltzmann distribution with an energy function that is unique up to a constant, and as such is uniquely defined by its interactions; in other words, each interaction, at any order, can be freely varied to define a unique and valid probability distribution, namely, the Boltzmann distribution of the corresponding generalised Ising model. Note that this is closely related to the fact that a class of neural networks known as restricted Boltzmann machines are universal approximators [42,43,44] and exactly (though not uniquely) encode the Boltzmann distribution of a generalised Ising model in one of their layers [31,45]. Therefore, each distribution is uniquely determined by its set of interactions, and should be distinguishable by them. This is famously not true for entropy-based information quantities, as illustrated below through several examples.
4.1. Interactions and Their Duals Quantify and Distinguish Synergy in Logic Gates
Under the assumption of a causal collider structure , nonzero 3-point interactions can be interpreted as logic gates. A positive 3-point interaction means that the numerator in Equation (10) is larger than the denominator. Under the sufficient (though not necessary) assumption that each term in the numerator is larger than each term in the denominator, we obtain the following truth table as :
which describes an XNOR gate. Let be the probability of each of the four states in the truth table for a gate , and let be the probability of all other states. Then, the 3-point interaction of an XNOR gate can be written as
Similarly, the truth tables of AND and OR gates imply that
If we consider equally noisy gates such that and , the gates can be directly compared. Note that when a gate has a 3-point interaction I, its logical negation will have a 3-point interaction . This determines the 3-point interactions of all six non-trivial logic gates on two inputs, as summarised in Table 1. The two gates with the strongest absolute interactions, XNOR and XOR, are the only two gates that are purely synergistic, i.e., knowing only one of the two inputs provides no information about the output. This relationship to synergy holds for three-input gates as well. The three-input gate with the strongest 4-point interaction has the following truth table:
This is a three-input XOR gate, i.e., , and is again maximally synergistic, as observing only two of the three inputs provides zero bits of information on the output. Setting this maximum 4-point interaction to I, the three-input OR and AND gates receive a 4-point interaction ; thus, the hierarchies of interaction and synergy continue to match.
| A | B | C |
| 0 | 0 | 1 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
| A | B | C | D |
| 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 |
| 1 | 1 | 1 | 1 |
The 3-point interactions are able to separate most two-input logic gates by sign or value, leaving only AND∼NOR and OR∼NAND. Mutual information has less resolving power. Assuming a uniform distribution over all four allowed states from a gate’s truth table, a brief calculation yields
That is, higher-order mutual information resolves strictly fewer logical gates by value and none by sign. In fact, the higher-order mutual information of a logic gate can never be positive, because it is bounded from above by the minimum of the pairwise mutual information, which is always zero for the pair of inputs. Because all entropy-based quantities inherit the degeneracy summarised in Table 2, neither the mutual information nor its dual can increase the resolving power (see Table 3).
The logic gate interactions and their duals are summarised in Table 3, where it can be seen that neither nor improve the resolution beyond that of the 3-point interaction. However, the 3-point interaction requires probabilities to achieve this resolving power, whereas achieves the same resolving power with just four probabilities.
However, note that because of a difference in sign convention dual mutual information is a difference between two mutual information quantities, while dual interactions are a sum of two interactions. Based on this, we can consider the difference of two interactions and define a new quantity . We refer to this as a J-interaction. When the MFIs are interpreted in the context of an energy-based model, such as an Ising model or a restricted Boltzmann machine, then the interactions have dimensions of energy, meaning that the J-interactions correspond to the difference in the energy contribution between a triplet and a pair. These J-interactions of the input nodes A and B assign a different value to each logic gate , and the symmetric J-interaction , analogous to the symmetric deltas from [40], inherits the perfect resolution from .
Note that while both have perfect resolution, does not improve the resolution beyond that of the 3-point interaction. This results from the fact that in logic gates we have , meaning that and contain the same information. To see this, note that
Because the logic gates are symmetric in their inputs, i.e., , this can be rewritten as
Each of these terms in brackets has the form . Because these are two contradicting states, this product reduces to regardless of the truth table of :
Note that this pattern could already be observed in Table 3, though it was not yet explained.
Thus, the J-interactions of the input nodes uniquely assign a value to each gate proportional to the synergy of its logic. The hierarchy is , which is mirrored for the respective logical complements. XNOR is indeed the most synergistic, while NOR is more synergistic than AND with respect to observing a 0 in one of the inputs; in a NOR gate, a 0 in the input provides no information on the output, while it completely fixes the output of an AND gate. Because the interactions are defined in a context of 0s, they order the synergy accordingly.
4.2. Interactions Distinguish Dynamics and Causal Structures
To illustrate how different association metrics reflect the underlying causal dynamics, consider data generated from a selection of three-node causal DAGs as follows. On a given DAG , first denote the set of nodes without parents, the orphan nodes, by . Each orphan node in receives a random value drawn from a Bernoulli distribution, i.e., and . Next, denote the set of children of orphan nodes as . Each node in is then set to either the product of its parent nodes (for multiplicative dynamics) or the mean of its parent nodes (for additive dynamics), plus some zero-mean Gaussian noise with variance . Note that for the fork and the chain this simply amounts to a noisy copying operation. All nodes are then rounded to a 0 or 1. A set is then defined as the set of all children of nodes in , and these receive values using the same dynamics as before. As long as the causal structure is acyclic, this algorithm terminates on a set of nodes that has no children. For example, the chain graph has , , , and , at which point the updating terminates.
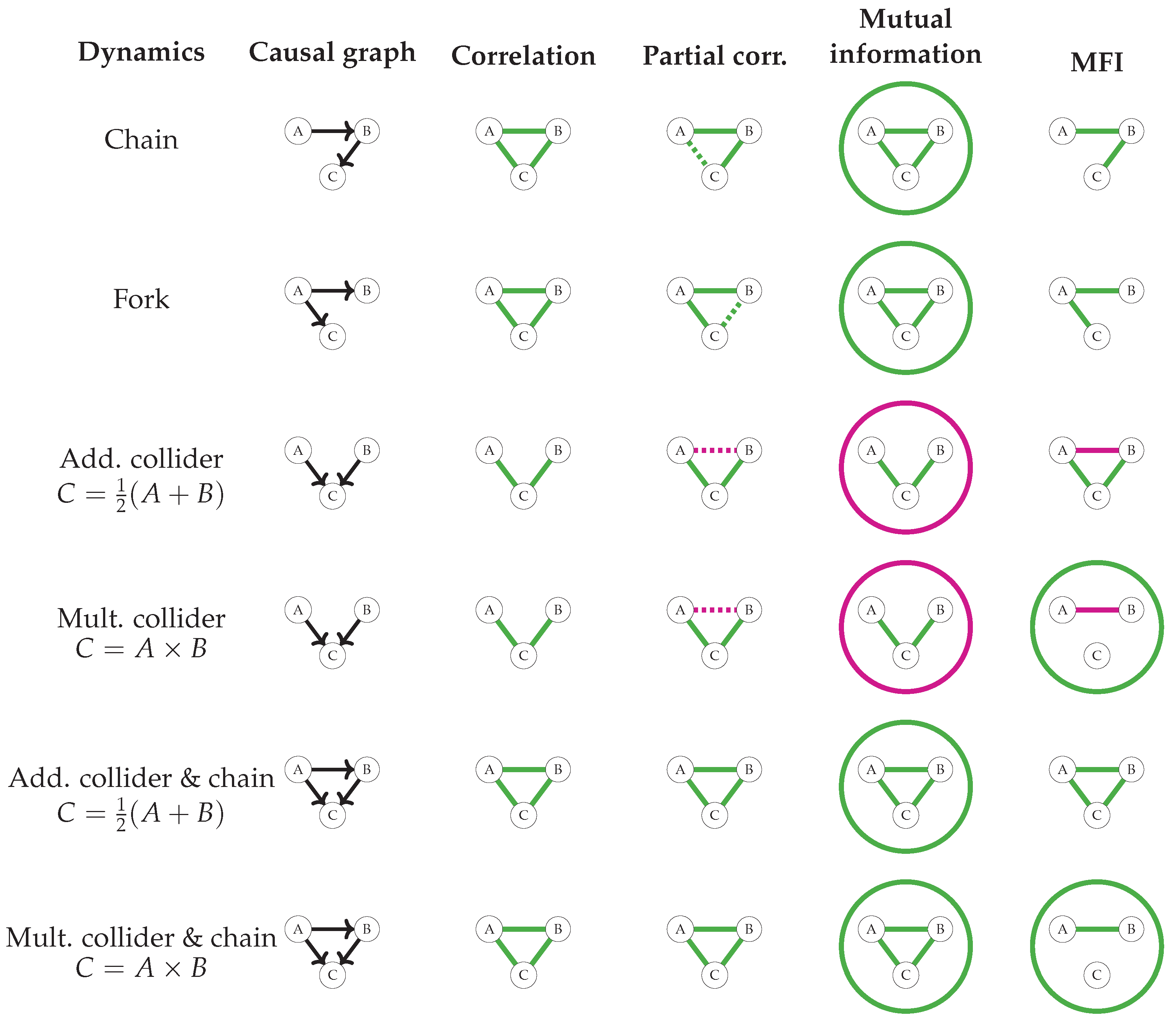
Figure 4 shows the results for four different DAGs with multiplicative and additive dynamics (though these are the same for forks and chains). The six different dynamics are represented in four different DAGs, two different (Pearson) correlations, four different partial correlations, and two different mutual information structures, which means that each of these descriptions is degenerate in some of the dynamics. The shown pairwise partial correlations are the correlations among the residuals after a linear regression against the third variable. Because this is similar to conditioning on the third variable, it is somewhat analogous to the MFIs; in fact, when the variables are multivariate normal the partial correlations are encoded in the inverse covariance matrix and are equivalent to pairwise Ising interactions [31]. Indeed, it can be seen that the partial correlations are somewhat able to disentangle direct effects from indirect effects, although they fail to distinguish additive from multiplicative dynamics. Note that only the sign of the association and its significance are represented, as the precise value depends on the noise level . The rightmost column shows that the MFIs assign a unique association structure to each of the dynamics, distinguish between direct and indirect effects, and reveal multiplicative dynamics as a 3-point interaction while identifying additive dynamics as a purely pairwise process. Finally, note that both the partial correlation and the MFIs assign a negative association to the parent nodes in a collider structure. This reflects that two nodes become dependent when conditioned on a common effect (cf. Berkson’s paradox), a phenomenon already found in partial correlations of metabolomic data in [46]. The mutual information is affected by Berkson’s paradox as well, revealed through the negative three-point mutual information. This negative three-point is a direct effect from conditioning on the common effect C, as on colliders , because the mutual information among the independent inputs A and B vanishes by definition.
4.3. Higher-Order Categorical Interactions Distinguish Dyadic and Triadic Distributions
That the interactions have such resolving power over distributions of binary variables is perhaps not very surprising in light of the universality of RBMs with respect to this class of distributions. More surprisingly, their resolving power extends to the case of categorical variables. In [47], the authors introduced two distributions, the dyadic and triadic distributions, which are indistinguishable by almost all commonly used information measures (i.e., Shannon, Renyi(2), residual, and Tsallis entropy, co-information, total correlation, CAEKL mutual information, interaction information, Wyner, exact, functional, and MSS common information, perplexity, disequilibrium, and LMRP and TSE complexities).
Figure 4.
Different causal dynamics lead to different association metrics. Green edges denote positive values, red edges denote negative values, circles denote a three-point quantity, and dashed lines show edges with marginal significance (depending on ). Correlations and mutual information cannot distinguish between most dynamics, and while partial correlation can identify the correct pairwise relationships for certain noise levels, it falls short of distinguishing additive from multiplicative dynamics. Only MFIs can distinguish between all six scenarios and reveal the combinatorial effect of the multiplicative dynamics as a 3-point interaction. See Appendix A.3 for the simulation parameters and raw numbers. This figure is reproduced with permission from the author of [48].
Figure 4.
Different causal dynamics lead to different association metrics. Green edges denote positive values, red edges denote negative values, circles denote a three-point quantity, and dashed lines show edges with marginal significance (depending on ). Correlations and mutual information cannot distinguish between most dynamics, and while partial correlation can identify the correct pairwise relationships for certain noise levels, it falls short of distinguishing additive from multiplicative dynamics. Only MFIs can distinguish between all six scenarios and reveal the combinatorial effect of the multiplicative dynamics as a 3-point interaction. See Appendix A.3 for the simulation parameters and raw numbers. This figure is reproduced with permission from the author of [48].

The two distributions are defined on three variables, each taking a value in a four-letter alphabet . The joint probabilities are summarised in Table 4. To construct the distributions, each category is represented as a binary string (), leading to new variables . The dyadic distribution is constructed by linking these new variables with pairwise rules , while the triadic distribution is constructed with triplet rules and . The resulting binary strings are then reinterpreted as categorical variables to produce Table 4.
The authors of [47] found that no Shannon-like measure can distinguish between the two distributions, and argued that the partial information decomposition, which is different for the two distributions, is not a natural information measure, as it has to single out one of the variables as an output. To calculate model-free categorical interactions between the variables, we can set the probabilities of the states in Table 4 uniformly to and those of the other states to (i.e., a normalised uniform distribution over legal states). There are a total of interactions such that . Each of these can be written as
Of particular interest here are the two quantities and , where the sum is over all values such that , as all possible pairs necessarily sum to zero because . For the dyadic distribution, we have
while for the triadic distribution we have
Thus, this particular 3-point interaction is zero for the dyadic distribution and negative for the triadic distribution. The sum over all three points (see Appendix A.4 for details) is provided by
That is, the additively symmetrised 3-point interaction is zero for the dyadic distribution and strongly negative for the triadic distribution. These two distributions, which are indistinguishable in terms of their information structure, are distinguishable by their model-free interactions, which accurately reflect the higher-order nature of the triadic distribution.
5. Discussion
In this paper, we have related the model-free interactions introduced in [32] to information theory by defining them as Möbius inversions of surprisal on the same lattice that relates mutual information to entropy. We then invert the order of the lattice and compute the order-dual to the mutual information, which turns out to be a generalisation of differential mutual information. Similarly, the order-dual of interaction turns out to be interaction in a different context. Both the interactions and the dual interactions are able to distinguish all six logic gates by value and sign. Moreover, their absolute strength reflects the synergy within the logic gate. In simulations, the interactions were able to perfectly distinguish six kinds of causal dynamics that are partially indistinguishable to Pearson/partial correlations, causal graphs, and mutual information. Finally, we considered dyadic and triadic distributions constructed using pairwise and higher-order rules, respectively. While these two distributions are indistinguishable in terms of their Shannon information, they have different categorical MFIs that reflect the order of the construction rules.
One might wonder why the interactions enjoy this advantage over entropy-based quantities. The most obvious difference is that the interactions are defined in a pointwise way, i.e., in terms of the surprisal of particular states, whereas entropy is the expected surprisal across an ensemble of states. Furthermore, the MFIs can be interpreted as interactions in an Ising model and as effective couplings in a restricted Boltzmann machine. As both these models are known to be universal approximators with respect to positive discrete probability distributions, the MFIs should be able to characterise all such distributions. What is not immediately obvious is that the kinds of interactions that characterise a distribution should reflect properties of that distribution, such as the difference between direct and indirect effects and the presence of higher-order structure. However, in the various examples covered in this manuscript the interactions turn out to intuitively align with properties of the process used to generate the data. While the stringent conditioning on variables not considered in the interaction might make it tempting to interpret an MFI as a causal or interventional quantity, it is important to be very careful when doing this. Assigning a causal interpretation to statistical inferences, whether in Pearl’s graphical do-calculus [49] or in Rubin’s potential outcomes framework [50], requires further (often untestable) assumptions and analysis of the system in order to determine whether a causal effect is identifiable and which variables to control for. In contrast, an MFI is simply defined by conditioning on all observed variables, makes no reference to interventions or counterfactuals, and does not specify a direction of the effect. While in a controlled and simple setting the MFIs can be expressed in terms of causal average treatment effects [32], a causal interpretation is not justifiable in general.
Moreover, the stringency in the conditioning might worry the attentive reader. Estimating directly from data means counting states such as , which for sufficiently large N are rare in most datasets. Appendix A.1 shows how to use the causal graph to construct Markov blankets, making such estimation tractable when full conditioning is too stringent. In an upcoming paper, we address this issue by estimating the graph of conditional dependencies, allowing for successful calculation of MFIs up to the fifth order in gene expression data.
One major limitation of MFIs is that they are only defined on binary or categorical variables, whereas many other association metrics are defined for ordinal and continuous variables as well. As states of continuous variables no longer form a lattice, it is hard to see how the definition of MFIs could be extended to include these cases.
Finally, it is worth noting that the structure of different lattices has guided much of this research. That Boolean algebras are important in defining higher-order structure is not surprising, as they are the stage on which the inclusion–exclusion principle can be generalised [36]. However, it is not only their order-reversed duals that lead to meaningful definitions; completely unrelated lattices do as well. For example, the Möbius inversion on the lattice of ordinal variables from Figure 3 and the redundancy lattices in the partial information decomposition [28] both lead to new and sensible definitions of information-theoretic quantities. Furthermore, the notion of Möbius inversion has been generalised to a more general class of categories [51], of which posets are a special case. A systematic investigation of information-theoretic quantities in this richer context would be most interesting.
Funding
This research was funded by Medical Research Council grant number MR/N013166/1.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
The author is grateful for the insightful discussions of model-free interactions, causality, and RBMs with Ava Khamseh, Sjoerd Beentjes, Chris Ponting, and Luigi Del Debbio. The author also thanks John Baez for a helpful conversation on the role of surprisal in information theory. The author further thanks Sjoerd Beentjes for reading and commenting on an early version of this work, and the reviewers for their helpful suggestions. A.J. is supported by an MRC Precision Medicine Grant (MR/N013166/1).
Conflicts of Interest
The funders had no role in the design of the study, in the collection, analysis, or interpretation of data, in the writing of the manuscript, or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| MI | Mutual Information |
| MFI | Model-Free Interaction |
| DAG | Directed Acyclic Graph |
| MB | Markov Blanket |
| PID | Partial Information d=Decomposition |
| i.i.d. | independent and identically distributed |
Appendix A
Appendix A.1. Markov Blankets
Estimating the interaction in Definition 2 from data involves estimating the probabilities of certain states occurring. While we do not have access to the true probabilities, we can rewrite the interactions in terms of expectation values. Note that all interactions involve factors of the type
because
This allows us to write the 2-point interaction, e.g., as follows:
Although expectation values are theoretical quantities, not empirical ones, sample means can be used as unbiased estimators to estimate each term in (A5). The stringent conditioning in this estimator can make the number of samples that satisfy the conditioning very small, which results in the estimates having large variance on different finite samples. Note that if we can find a subset of variables such that and (in causal language, a set of variables that d-separates from the rest), then we only have to condition on in (A5), reducing the variance of our estimator. Such a set is called a Markov Blanket of the node . There has recently been a certain degree of confusion around the notion of Markov blankets in biology, specifically with respect to their use in the free energy principle in neuroscience contexts. Here, a Markov blanket refers to the notion of a Pearl blanket in the language of [52]. Because conditioning on fewer variables should reduce the variance of the estimate by increasing the number of samples that can be used for the estimation, we are generally interested in finding the smallest Markov blanket. This minimal Markov blanket is called the Markov boundary.
Finding such minimal Markov blankets is hard; in fact, because it requires testing each possible conditional dependency between the variables, we claim here (without proof) that it is causal discovery-hard, i.e., if such a graph exists it is at least as computationally complex as constructing a causal DAG consistent with the joint probability distribution.
Appendix A.2. Proofs
Markov blankets are not only a computational trick; in theory, only variables that are in each other’s Markov blanket can share a nonzero interaction. To illustrate this, first note that the property of being in a variable’s Markov blanket is symmetric:
Proposition A1 (symmetry of Markov blankets).
Let X be a set of variables with joint distribution and let and such that . We denote the minimal Markov blanket of X by . Then, , and we can say that A and B are Markov-connected.
Proof.
Let . Then,
Consider that
which means that . Because holds, its negation holds as well, which completes the proof. □
This definition of Markov connectedness allows us to state the following.
Theorem A1 (only Markov-connected variables can interact).
A model-free n-point interaction can only be nonzero when all variables are mutually Markov-connected.
Proof.
Let X be a set of variables with joint distribution , let , and let . Consider the definition of an n-point interaction among S:
Now, if such that , we do not need to condition on and can write this as
as the probabilities no longer involve . Because was chosen arbitrarily, this must hold for all variables in S, which means that if any variable in S is not in the Markov blanket of then the interaction vanishes:
Furthermore, as the indexing we chose for our variables was arbitrary, this must hold for any re-indexing, which means that
This in turn means that all variables in S must be Markov-connected in order for the interaction to be nonzero. □
Thus, knowledge of the causal graph aids estimation in two ways: it shrinks the variance of the estimates by relaxing the conditioning, and it identifies the interactions that could be nonzero.
When knowledge of the causal graph is imperfect, it is possible to accidentally exclude a variable from a Markov blanket and thereby undercondition the relevant probabilities. The resulting error can be expressed in terms of the mutual information between the variables, as follows.
Proposition A2 (underconditioning bias).
Let S be a set of random variables with probability distribution , let , and let Z be three disjoint subsets of S. Then, omitting Y from the conditioning set results in a bias determined by (and linear in) the pointwise mutual information that provides about the states of X:
Proof.
The pointwise mutual information (pmi) is defined as
Note that
meaning that we can write
That is, not conditioning on results in an error in the estimate of that is exponential in the Z-conditional pmi of X and Y. However, consider the interaction among X,
That is, the error in the interaction as a result of not conditioning on the right variables is linear in terms of the difference between the pmi values of different states. □
Appendix A.3. Numerics of Causal Structures
Table A1, Table A2, Table A3, Table A4, Table A5 and Table A6 are taken from [48] with permission from the author, and list the precise values leading to Figure 4. From each graph, 100k samples were generated using and . To quantify the significance value of the interactions, the data were bootstrap resampled 1k times, resulting in the definition of F as the fraction of resampled interactions having a different sign from the original interaction. The smaller F is, the more significant the interaction.

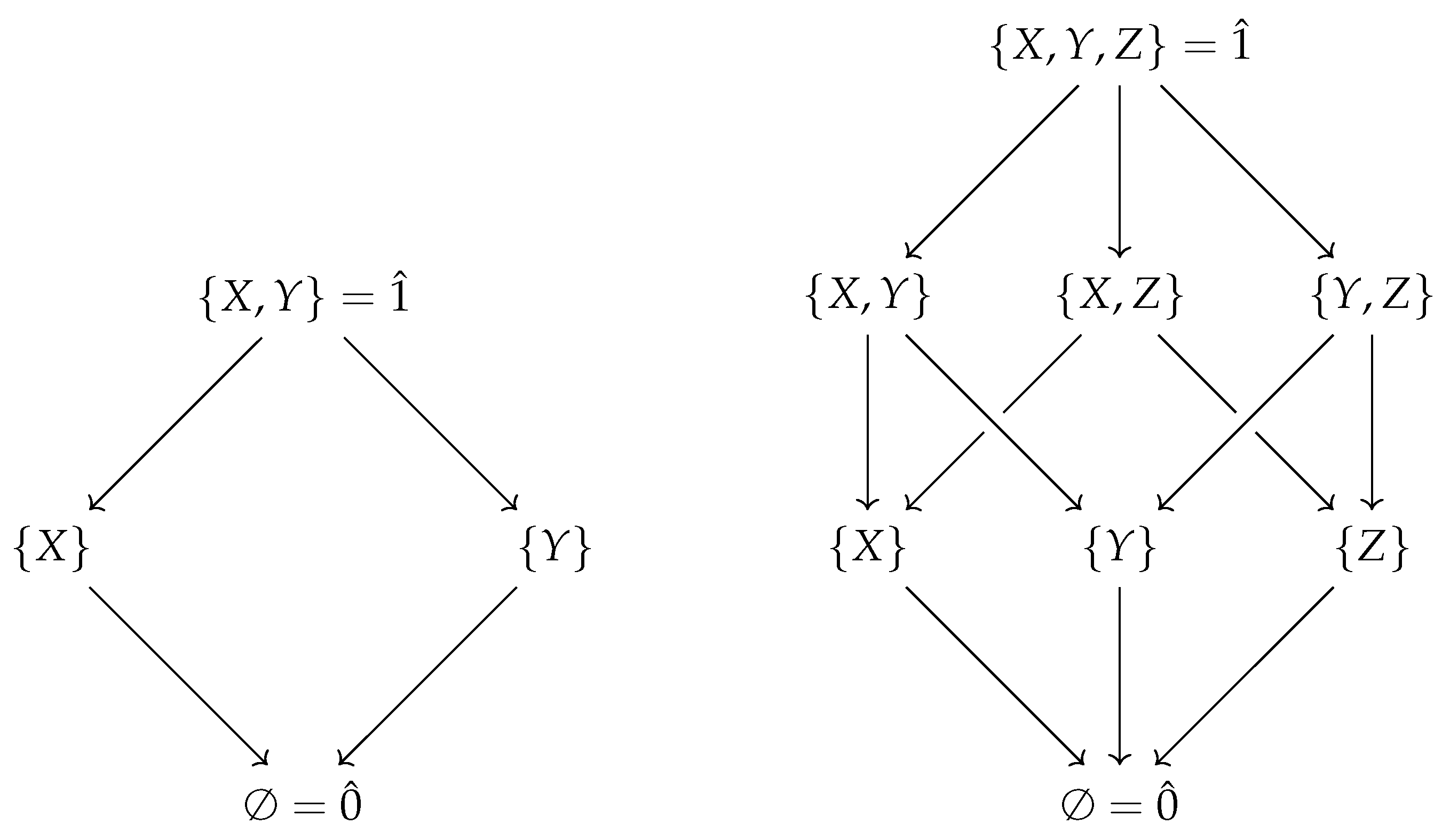{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table A1.
Chain.

| Genes | Interaction | F | Pearson cor. | Pearson cor. p | Partial cor. | Partial cor. p | MI | |
|---|---|---|---|---|---|---|---|---|
| 0 | [0, 1] | 4.281 | 0.000 | 0.790 | 0.0 | 0.635 | 0.000 × 10 | 0.515 |
| 1 | [0, 2] | 0.056 | 0.117 | 0.622 | 0.0 | 0.031 | 2.261 × 10 | 0.301 |
| 2 | [1, 2] | 4.249 | 0.000 | 0.786 | 0.0 | 0.628 | 0.000 × 10 | 0.510 |
| 3 | [0, 1, 2] | −0.052 | 0.217 | NaN | NaN | NaN | NaN | 0.300 |
Table A2.
Fork.

| Genes | Interaction | F | Pearson cor. | Pearson cor. p | Partial cor. | Partial cor. p | MI | |
|---|---|---|---|---|---|---|---|---|
| 0 | [0, 1] | 4.268 | 0.000 | 0.789 | 0.0 | 0.634 | 0.000 × 10 | 0.514 |
| 1 | [0, 2] | 4.257 | 0.000 | 0.788 | 0.0 | 0.632 | 0.000 × 10 | 0.512 |
| 2 | [1, 2] | −0.014 | 0.376 | 0.622 | 0.0 | 0.028 | 6.518 × 10 | 0.300 |
| 3 | [0, 1, 2] | 0.020 | 0.376 | NaN | NaN | NaN | NaN | 0.300 |
Table A3.
Additive collider.

| Genes | Interaction | F | Pearson cor. | Pearson cor. p | Partial cor. | Partial cor. p | MI | |
|---|---|---|---|---|---|---|---|---|
| 0 | [0, 1] | 2.144 | 0.000 | 0.395 | 0.000 | 0.505 | 0.000 × 10 | 1.154 × 10 |
| 1 | [0, 2] | −0.989 | 0.000 | −0.002 | 0.593 | −0.070 | 5.172 × 10 | 2.059 × 10 |
| 2 | [1, 2] | 2.144 | 0.000 | 0.395 | 0.000 | 0.505 | 0.000 × 10 | 1.154 × 10 |
| 3 | [0, 1, 2] | 0.003 | 0.438 | NaN | NaN | NaN | NaN | −2.678 × 10 |
Table A4.
Multiplicative collider.

| Genes | Interaction | F | Pearson cor. | Pearson cor. p | Partial cor. | Partial cor. p | MI | |
|---|---|---|---|---|---|---|---|---|
| 0 | [0, 1] | 0.032 | 0.140 | 0.427 | 0.000 | 0.478 | 0.000 × 10 | 1.403 × 10 |
| 1 | [0, 2] | −2.156 | 0.000 | −0.005 | 0.145 | −40.087 | 1.463 × 10 | 1.529 × 10 |
| 2 | [1, 2] | 0.036 | 0.109 | 0.429 | 0.000 | 0.480 | 0.000 × 10 | 1.415 × 10 |
| 3 | [0, 1, 2] | 4.237 | 0.000 | NaN | NaN | NaN | NaN | −1.150 × 10 |
Table A5.
Additive collider + chain.

| Genes | Interaction | F | Pearson cor. | Pearson cor. p | Partial cor. | Partial cor. p | MI | |
|---|---|---|---|---|---|---|---|---|
| 0 | [0, 1] | 2.103 | 0.000 | 0.705 | 0.0 | 0.362 | 0.0 | 0.396 |
| 1 | [0, 2] | 3.288 | 0.000 | 0.790 | 0.0 | 0.599 | 0.0 | 0.515 |
| 2 | [1, 2] | 2.113 | 0.000 | 0.706 | 0.0 | 0.364 | 0.0 | 0.397 |
| 3 | [0, 1, 2] | 0.050 | 0.162 | NaN | NaN | NaN | NaN | 0.335 |
Table A6.
Multiplicative collider + chain.

| Genes | Interaction | F | Pearson cor. | Pearson cor. p | Partial cor. | Partial cor. p | MI | |
|---|---|---|---|---|---|---|---|---|
| 0 | [0, 1] | −0.017 | 0.342 | 0.709 | 0.0 | 0.365 | 0.0 | 0.403 |
| 1 | [0, 2] | 2.094 | 0.000 | 0.786 | 0.0 | 0.596 | 0.0 | 0.510 |
| 2 | [1, 2] | −0.057 | 0.092 | 0.707 | 0.0 | 0.361 | 0.0 | 0.401 |
| 3 | [0, 1, 2] | 4.359 | 0.000 | NaN | NaN | NaN | NaN | 0.293 |
Appendix A.4. Python Code for Calculating Categorical Dyadic and Triadic Interactions
dyadicStates = [[’a’, ’a’, ’a’], [’a’, ’c’, ’b’], [’b’, ’a’, ’c’], [’b’, ’c’, ’d’],
[’c’, ’b’, ’a’], [’c’, ’d’, ’b’], [’d’, ’b’, ’c’], [’d’, ’d’, ’d’]]
triadicStates = [[’a’, ’a’, ’a’], [’a’, ’c’, ’c’], [’b’, ’b’, ’b’], [’b’, ’d’, ’d’],
[’c’, ’a’, ’c’], [’c’, ’c’, ’a’], [’d’, ’b’, ’d’], [’d’, ’d’, ’b’]]
stateDict = {0: ’a’, 1: ’b’, 2:’c’, 3: ’d’}
def catIntSymb(x0, x1, y0, y1, z0, z1, states):
prob = lambda x, y, z: ’p’ if [x, y, z] in states else~’e’
num = prob(x1, y1, z1) + prob(x1, y0, z0) + prob(x0, y1, z0) + prob(x0, y0, z1)
denom = prob(x1, y1, z0) + prob(x1, y0, z1) + prob(x0, y1, z1) + prob(x0, y0, z0)
return (num, denom)
numDy = ’’
denomDy = ’’
numTri = ’’
denomTri = ’’
for x0 in range(4):
for x1 in range(x0+1, 4):
for y0 in range(4):
for y1 in range(y0+1, 4):
for z0 in range(4):
for z1 in range(z0+1, 4):
nDy, dDy = catIntSymb(*[stateDict[x] for x in [x0, x1, y0, y1, z0, z1]], dyadicStates)
numDy += nDy
denomDy += dDy
nTri, dTri = catIntSymb(*[stateDict[x] for x in [x0, x1, y0, y1, z0, z1]], triadicStates)
numTri += nTri
denomTri += dTri
print(f’Dyadic interaction: log (p^{numDy.count("p") - denomDy.count("p")} e^{numDy.count("e") - denomDy.count("e")})’)
print(f’Triadic interaction: log (p^{numTri.count("p") - denomTri.count("p")} e^{numTri.count("e") - denomTri.count("e")})’)
// Output:
>> Dyadic interaction: log (p^0 e^0)
>> Triadic interaction: log (p^-64 e^64)
References
- Ghazanfar, S.; Lin, Y.; Su, X.; Lin, D.M.; Patrick, E.; Han, Z.G.; Marioni, J.C.; Yang, J.Y.H. Investigating higher-order interactions in single-cell data with scHOT. Nat. Methods 2020, 17, 799–806. [Google Scholar] [CrossRef] [PubMed]
- Lezon, T.R.; Banavar, J.R.; Cieplak, M.; Maritan, A.; Fedoroff, N.V. Using the principle of entropy maximization to infer genetic interaction networks from gene expression patterns. Proc. Natl. Acad. Sci. USA 2006, 103, 19033–19038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Watkinson, J.; Liang, K.C.; Wang, X.; Zheng, T.; Anastassiou, D. Inference of regulatory gene interactions from expression data using three-way mutual information. Ann. N. Y. Acad. Sci. 2009, 1158, 302–313. [Google Scholar] [CrossRef] [PubMed]
- Kuzmin, E.; VanderSluis, B.; Wang, W.; Tan, G.; Deshpande, R.; Chen, Y.; Usaj, M.; Balint, A.; Usaj, M.M.; Van Leeuwen, J.; et al. Systematic analysis of complex genetic interactions. Science 2018, 360, eaao1729. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weinreich, D.M.; Lan, Y.; Wylie, C.S.; Heckendorn, R.B. Should evolutionary geneticists worry about higher-order epistasis? Curr. Opin. Genet. Dev. 2013, 23, 700–707. [Google Scholar]
- Panas, D.; Maccione, A.; Berdondini, L.; Hennig, M.H. Homeostasis in large networks of neurons through the Ising model—Do higher order interactions matter? BMC Neurosci. 2013, 14, P166. [Google Scholar] [CrossRef] [Green Version]
- Tkačik, G.; Marre, O.; Amodei, D.; Schneidman, E.; Bialek, W.; Berry, M.J. Searching for Collective Behavior in a Large Network of Sensory Neurons. PLoS Comput. Biol. 2014, 10, e1003408. [Google Scholar] [CrossRef] [Green Version]
- Ganmor, E.; Segev, R.; Schneidman, E. Sparse low-order interaction network underlies a highly correlated and learnable neural population code. Proc. Natl. Acad. Sci. USA 2011, 108, 9679–9684. [Google Scholar] [CrossRef] [Green Version]
- Yu, S.; Yang, H.; Nakahara, H.; Santos, G.S.; Nikolić, D.; Plenz, D. Higher-order interactions characterized in cortical activity. J. Neurosci. 2011, 31, 17514–17526. [Google Scholar]
- Gatica, M.; Cofré, R.; Mediano, P.A.; Rosas, F.E.; Orio, P.; Diez, I.; Swinnen, S.P.; Cortes, J.M. High-order interdependencies in the aging brain. Brain Connect. 2021, 11, 734–744. [Google Scholar]
- Sanchez, A. Defining Higher-Order Interactions in Synthetic Ecology: Lessons from Physics and Quantitative Genetics. Cell Syst. 2019, 9, 519–520. [Google Scholar] [CrossRef] [Green Version]
- Grilli, J.; Barabás, G.; Michalska-Smith, M.J.; Allesina, S. Higher-order interactions stabilize dynamics in competitive network models. Nature 2017, 548, 210–213. [Google Scholar]
- Li, Y.; Mayfield, M.M.; Wang, B.; Xiao, J.; Kral, K.; Janik, D.; Holik, J.; Chu, C. Beyond direct neighbourhood effects: Higher-order interactions improve modelling and predicting tree survival and growth. Natl. Sci. Rev. 2021, 8, nwaa244. [Google Scholar]
- Tekin, E.; White, C.; Kang, T.M.; Singh, N.; Cruz-Loya, M.; Damoiseaux, R.; Savage, V.M.; Yeh, P.J. Prevalence and patterns of higher-order drug interactions in Escherichia coli. NPJ Syst. Biol. Appl. 2018, 4, 1–10. [Google Scholar]
- Alvarez-Rodriguez, U.; Battiston, F.; de Arruda, G.F.; Moreno, Y.; Perc, M.; Latora, V. Evolutionary dynamics of higher-order interactions in social networks. Nat. Hum. Behav. 2021, 5, 586–595. [Google Scholar]
- Cencetti, G.; Battiston, F.; Lepri, B.; Karsai, M. Temporal properties of higher-order interactions in social networks. Sci. Rep. 2021, 11, 1–10. [Google Scholar]
- Grabisch, M.; Roubens, M. An axiomatic approach to the concept of interaction among players in cooperative games. Int. J. Game Theory 1999, 28, 547–565. [Google Scholar]
- Matsuda, H. Physical nature of higher-order mutual information: Intrinsic correlations and frustration. Phys. Rev. E 2000, 62, 3096. [Google Scholar]
- Cerf, N.J.; Adami, C. Entropic bell inequalities. Phys. Rev. A 1997, 55, 3371. [Google Scholar]
- Battiston, F.; Amico, E.; Barrat, A.; Bianconi, G.; Ferraz de Arruda, G.; Franceschiello, B.; Iacopini, I.; Kéfi, S.; Latora, V.; Moreno, Y.; et al. The physics of higher-order interactions in complex systems. Nat. Phys. 2021, 17, 1093–1098. [Google Scholar]
- Skardal, P.S.; Arenas, A. Higher order interactions in complex networks of phase oscillators promote abrupt synchronization switching. Commun. Phys. 2020, 3, 1–6. [Google Scholar]
- Merchan, L.; Nemenman, I. On the Sufficiency of Pairwise Interactions in Maximum Entropy Models of Networks. J. Stat. Phys. 2016, 162, 1294–1308. [Google Scholar] [CrossRef] [Green Version]
- Tkacik, G.; Schneidman, E.; Berry, M.J., II; Bialek, W. Ising models for networks of real neurons. arXiv 2006, arXiv:q-bio/0611072. [Google Scholar]
- Margolin, A.A.; Nemenman, I.; Basso, K.; Wiggins, C.; Stolovitzky, G.; Favera, R.D.; Califano, A. ARACNE: An algorithm for the reconstruction of gene regulatory networks in a mammalian cellular context. BMC Bioinform. 2006, 7, S7. [Google Scholar] [CrossRef] [Green Version]
- Nemenman, I. Information theory, multivariate dependence, and genetic network inference. arXiv 2004, arXiv:q-bio/0406015. [Google Scholar]
- Watanabe, S. Information theoretical analysis of multivariate correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar]
- Rosas, F.E.; Mediano, P.A.; Luppi, A.I.; Varley, T.F.; Lizier, J.T.; Stramaglia, S.; Jensen, H.J.; Marinazzo, D. Disentangling high-order mechanisms and high-order behaviours in complex systems. Nat. Phys. 2022, 18, 476–477. [Google Scholar]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Zecchina, R.; Berg, J. Inverse statistical problems: From the inverse Ising problem to data science. Adv. Phys. 2017, 66, 197–261. [Google Scholar] [CrossRef] [Green Version]
- Beentjes, S.V.; Khamseh, A. Higher-order interactions in statistical physics and machine learning: A model-independent solution to the inverse problem at equilibrium. Phys. Rev. E 2020, 102, 053314. [Google Scholar] [CrossRef]
- Glonek, G.F.; McCullagh, P. Multivariate logistic models. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 533–546. [Google Scholar]
- Bartolucci, F.; Colombi, R.; Forcina, A. An extended class of marginal link functions for modelling contingency tables by equality and inequality constraints. Stat. Sin. 2007, 17, 691–711. [Google Scholar]
- Bateson, G. Steps to an Ecology of Mind; Chandler Publishing Company: San Francisco, CA, USA, 1972. [Google Scholar]
- Stanley, R.P. Enumerative Combinatorics, 2nd ed.; Cambridge Studies in Advanced Mathematics; Cambridge University Press: Cambridge, UK, 2011; Volume 1. [Google Scholar]
- Rota, G.C. On the foundations of combinatorial theory I. Theory of Möbius functions. Z. Wahrscheinlichkeitstheorie Verwandte Geb. 1964, 2, 340–368. [Google Scholar]
- Bell, A.J. The co-information lattice. In Proceedings of the Fifth International Workshop on Independent Component Analysis and Blind Signal Separation, ICA, Nara, Japan, 1–4 April 2003; Volume 2003. [Google Scholar]
- Galas, D.J.; Sakhanenko, N.A. Symmetries among multivariate information measures explored using Möbius operators. Entropy 2019, 21, 88. [Google Scholar]
- Galas, D.J.; Sakhanenko, N.A.; Skupin, A.; Ignac, T. Describing the complexity of systems: Multivariable “set complexity” and the information basis of systems biology. J. Comput. Biol. 2014, 21, 118–140. [Google Scholar]
- Galas, D.J.; Kunert-Graf, J.; Uechi, L.; Sakhanenko, N.A. Towards an information theory of quantitative genetics. J. Comput. Biol. 2019, 28, 527–559. [Google Scholar] [CrossRef]
- Freund, Y.; Haussler, D. Unsupervised learning of distributions on binary vectors using two layer networks. Adv. Neural Inf. Process. Syst. 1991, 4, 912–919. [Google Scholar]
- Le Roux, N.; Bengio, Y. Representational power of restricted Boltzmann machines and deep belief networks. Neural Comput. 2008, 20, 1631–1649. [Google Scholar] [PubMed]
- Montufar, G.; Ay, N. Refinements of universal approximation results for deep belief networks and restricted Boltzmann machines. Neural Comput. 2011, 23, 1306–1319. [Google Scholar] [PubMed] [Green Version]
- Cossu, G.; Del Debbio, L.; Giani, T.; Khamseh, A.; Wilson, M. Machine learning determination of dynamical parameters: The Ising model case. Phys. Rev. B 2019, 100, 064304. [Google Scholar]
- Krumsiek, J.; Suhre, K.; Illig, T.; Adamski, J.; Theis, F.J. Gaussian graphical modeling reconstructs pathway reactions from high-throughput metabolomics data. BMC Syst. Biol. 2011, 5, 21. [Google Scholar]
- James, R.G.; Crutchfield, J.P. Multivariate dependence beyond Shannon information. Entropy 2017, 19, 531. [Google Scholar]
- Jansma, A. Higher-Order Interactions in Single-Cell Gene Expression. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2023. [Google Scholar]
- Pearl, J. Models, Reasoning and Inference; Cambridge University Press: Cambridge, UK, 2000; Volume 19. [Google Scholar]
- Imbens, G.W.; Rubin, D.B. Causal Inference in Statistics, Social, and Biomedical Sciences; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Leinster, T. Notions of Möbius inversion. Bull. Belg. Math. Soc.-Simon Stevin 2012, 19, 909–933. [Google Scholar]
- Bruineberg, J.; Dołęga, K.; Dewhurst, J.; Baltieri, M. The emperor’s new Markov blankets. Behav. Brain Sci. 2022, 45, e183. [Google Scholar]
Figure 1.
The lattices associated with (left) and (right) ordered by inclusion. An arrow indicates .
Figure 1.
The lattices associated with (left) and (right) ordered by inclusion. An arrow indicates .

Figure 2.
(Left) The lattice associated with ordered by inclusion as binary strings. Equivalently, the lattice of binary strings where for any two strings a and b, . (Right): The two shaded regions correspond to the decomposition of the 3-point interaction into two 2-point interactions.
Figure 2.
(Left) The lattice associated with ordered by inclusion as binary strings. Equivalently, the lattice of binary strings where for any two strings a and b, . (Right): The two shaded regions correspond to the decomposition of the 3-point interaction into two 2-point interactions.

Figure 3.
The lattice of two variables that can take three values, ordered by .

Table 1.
The 3-point interactions for all two-input logic gates at equal noise level are related through and degenerate in AND∼NOR and OR∼NAND.
Table 1.
The 3-point interactions for all two-input logic gates at equal noise level are related through and degenerate in AND∼NOR and OR∼NAND.
| XNOR | I |
| XOR | |
| AND | |
| OR | |
| NAND | |
| NOR |
Table 2.
The marginal entropies of variables in a logic gate are degenerate in XOR∼XNOR and AND∼OR∼NAND∼NOR.
Table 2.
The marginal entropies of variables in a logic gate are degenerate in XOR∼XNOR and AND∼OR∼NAND∼NOR.
| XNOR | 1 | 1 | 2 | 2 | 2 |
| XOR | 1 | 1 | 2 | 2 | 2 |
| AND | 1 | 2 | 2 | ||
| OR | 1 | 2 | 2 | ||
| NAND | 1 | 2 | 2 | ||
| NOR | 1 | 2 | 2 |
Table 3.
While the interactions leave certain gates indistinguishable, the dual J-interactions of the inputs are unique to each gate. The reported decimal values are rounded to three digits; as before, .
Table 3.
While the interactions leave certain gates indistinguishable, the dual J-interactions of the inputs are unique to each gate. The reported decimal values are rounded to three digits; as before, .
| XNOR | 0 | I | |||||||||
| XOR | 0 | ||||||||||
| AND | 0.311 | 0 | |||||||||
| OR | 0.311 | 0 | |||||||||
| NAND | 0.311 | 0 | |||||||||
| NOR | 0.311 | 0 | I |
Table 4.
The joint probability of the dyadic and triadic distributions [47]. All other states have a probability of zero.
Table 4.
The joint probability of the dyadic and triadic distributions [47]. All other states have a probability of zero.
| Dyadic | |||
|---|---|---|---|
| X | Y | Z | P |
| 0 | 0 | 0 | 1 / 8 |
| 0 | 2 | 1 | 1 / 8 |
| 1 | 0 | 2 | 1 / 8 |
| 1 | 2 | 3 | 1 / 8 |
| 2 | 1 | 0 | 1 / 8 |
| 2 | 3 | 1 | 1 / 8 |
| 3 | 1 | 2 | 1 / 8 |
| 3 | 3 | 3 | 1 / 8 |
| Triadic | |||
| X | Y | Z | P |
| 0 | 0 | 0 | 1 / 8 |
| 1 | 1 | 1 | 1 / 8 |
| 0 | 2 | 2 | 1 / 8 |
| 1 | 3 | 3 | 1 / 8 |
| 2 | 0 | 2 | 1 / 8 |
| 3 | 1 | 3 | 1 / 8 |
| 2 | 2 | 0 | 1 / 8 |
| 3 | 3 | 1 | 1 / 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Jansma, A. Higher-Order Interactions and Their Duals Reveal Synergy and Logical Dependence beyond Shannon-Information. Entropy 2023, 25, 648. https://doi.org/10.3390/e25040648
AMA Style
Jansma A. Higher-Order Interactions and Their Duals Reveal Synergy and Logical Dependence beyond Shannon-Information. Entropy. 2023; 25(4):648. https://doi.org/10.3390/e25040648
Chicago/Turabian StyleJansma, Abel. 2023. "Higher-Order Interactions and Their Duals Reveal Synergy and Logical Dependence beyond Shannon-Information" Entropy 25, no. 4: 648. https://doi.org/10.3390/e25040648
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.