
DARE: Distill and Reinforce Ensemble Neural Networks for Climate-Domain Processing


Abstract
:1. Introduction
2. Related Work
2.1. Bert-Based Knowledge Distillation
2.2. Data Augmentation and Domain Adaptation
2.3. NLP of Climate Change-Related Text
3. Model
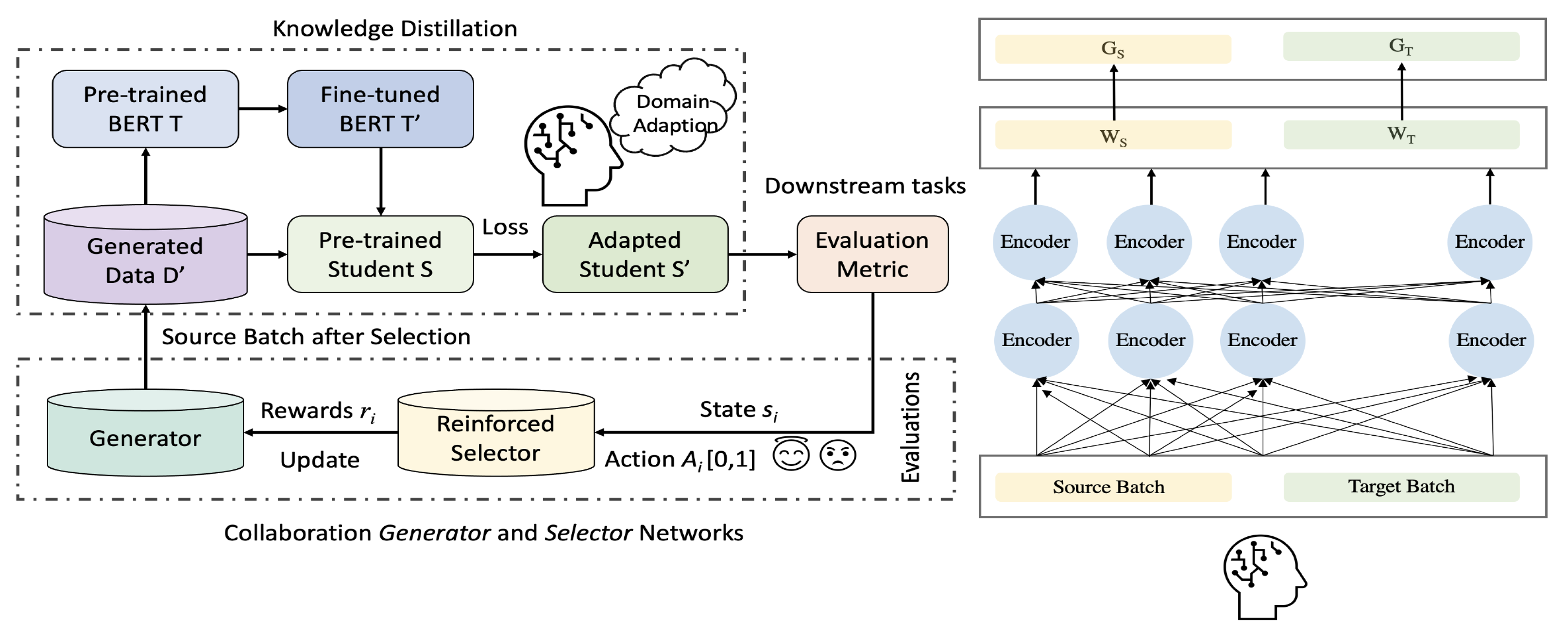
3.1. Knowledge Distillation
3.1.1. Teacher Model
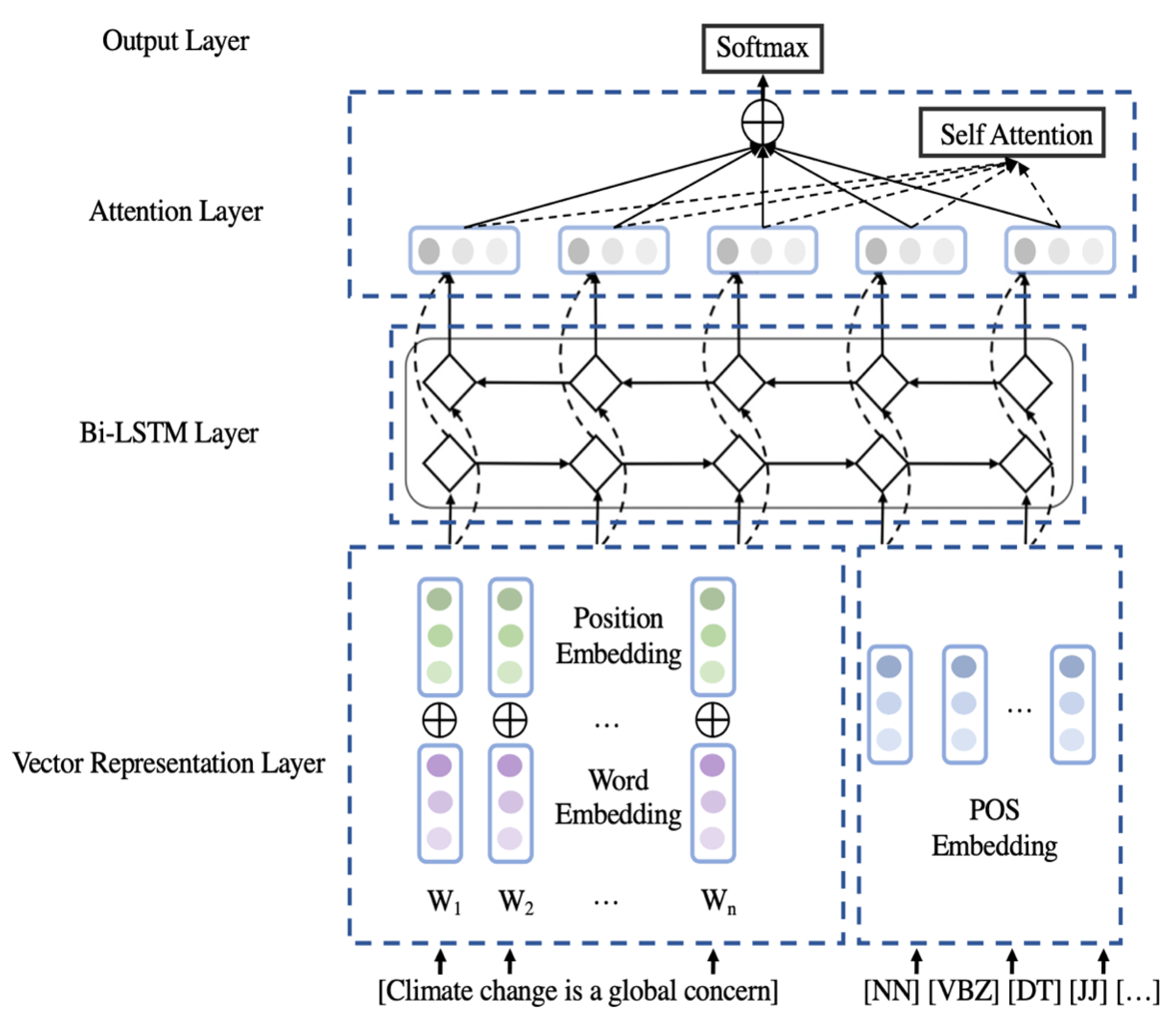
3.1.2. Student Model
- (1)
- Part-of-Speech Tagging
- (2)
- Structure of POS-Bi-LSTM-Attention

3.1.3. Distillation Goal
- (1)
- Output prediction layer distillationwhere is the status of the output of the teacher model.
- (2)
- Hidden layer distillation
- (3)
- Embedding layer distillation
3.2. Data Augmentation
3.2.1. State
3.2.2. Action
3.2.3. Reward
4. Experiments
4.1. Dataset
4.2. Implement Details
4.2.1. Parameter Settings
4.2.2. Downstream Tasks
4.2.3. Baselines
4.3. Experimental Results
4.3.1. Sentiment Analysis
4.3.2. Fact-Checking
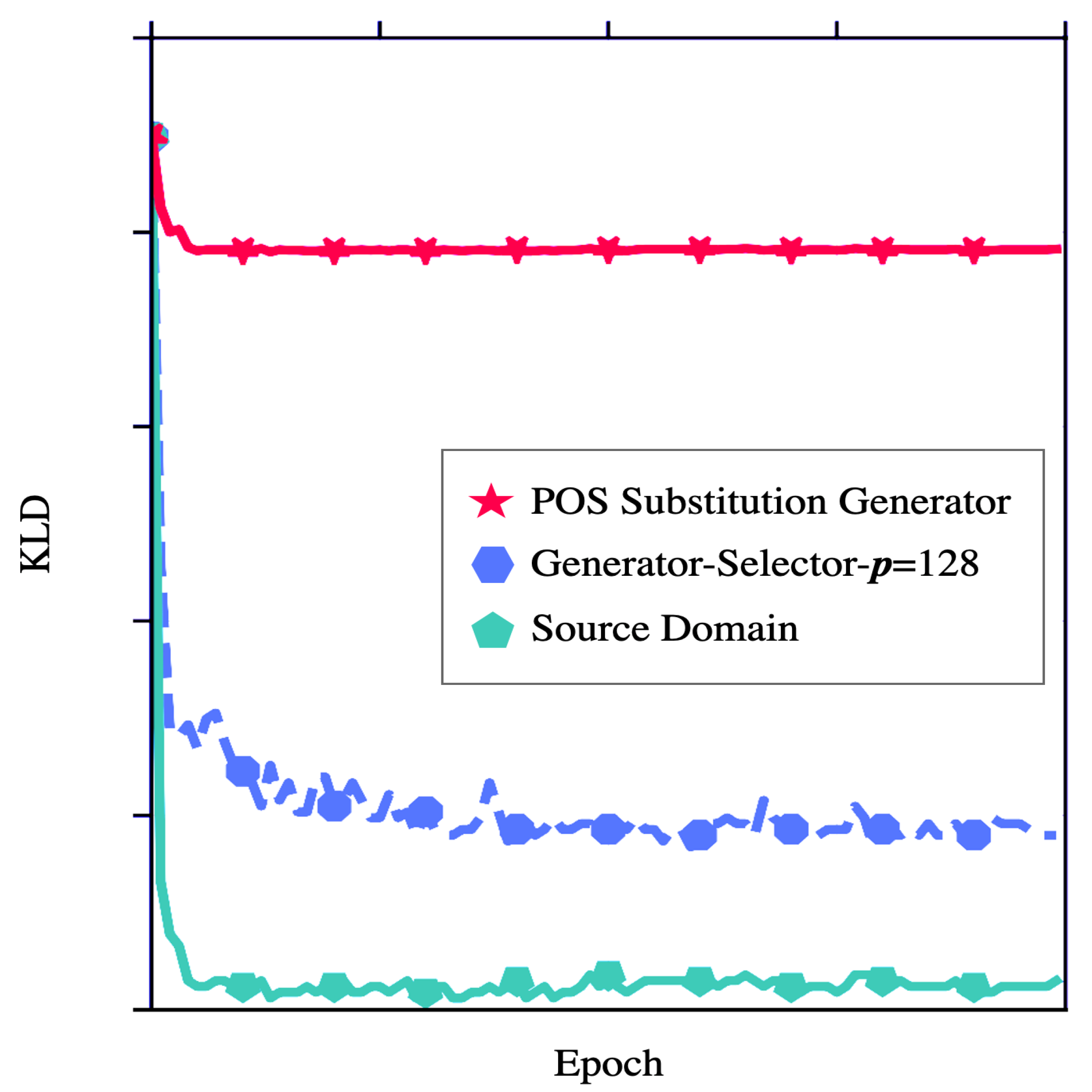
4.3.3. Additional Exploring Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POS Replacement | 32 | 64 | 128 | 256 | 512 |
|---|---|---|---|---|---|
| 81.45 | 82.78 | 85.33 | 84.21 | 83.10 | |
| 85.74 | 86.14 | 86.77 | 85.39 | 84.32 | |
| 84.65 | 86.34 | 88.94 | 85.76 | 85.23 | |
| 88.56 | 87.43 | †89.27 | 86.32 | 85.88 |
Appendix B

Appendix C
| Label | Example |
| Opportunity | We use a case study of the Australian island-state of Tasmania to demonstrate the importance and particularity of place in the formation of climate change adaptation issues, problem definition and framing, and the dynamics of knowledge and praxis development across a range of research and industry sectors. We describe the significance of the place Tasmania with regard to its geographical location; its portrayal as an island place; and its cultural meaning and relations. Through a synthesis of climate change adaptation research, policy literature and engagement with researchers and stakeholders, we identify three emergent thematic place characterisations of Tasmania. We find that these characterisations have contributed directly or indirectly to the: initiation and extent of research and practical activities; the framing of adaptation issues and perspectives on potential adaptation responses in different sectors including the marine biodiversity and resources sector, small business and human health sectors. Exposing these influences is essential for focusing future adaptation activities, including research, planning, investment and practice, in Tasmania and other locations where place is a central issue. |
| Opportunity | Adoption and adaptation of the approach used may be valuable for public health organizations to assist their communities. Through completing a vulnerability assessment, an evidentiary base was generated for public health to inform adaptation actions to reduce negative health impacts and increase resiliency. Challenges in completing vulnerability assessments at the local level include the framing and scoping of health impacts and associated indicators, as well as access to internal expertise surrounding the analysis of data. While access to quantitative data may be limiting at the local level, qualitative data can enhance knowledge of local impacts, while also supporting the creation of key partnerships with community stakeholders which can ensure climate action continues beyond the scope of the vulnerability assessment. |
| Opportunity | Coordinated adaptation efforts can reduce heat’s adverse health impacts, however. To address this concern in Ahmedabad (Gujarat, India), a coalition has been formed to develop an evidence-based heat preparedness plan and early warning system. This paper describes the group and initial steps in the plan’s development and implementation. Evidence accumulation included extensive literature review, analysis of local temperature and mortality data, surveys with heat-vulnerable populations, focus groups with health care professionals, and expert consultation. The findings and recommendations were encapsulated in policy briefs for key government agencies, health care professionals, outdoor workers, and slum communities, and synthesized in the heat preparedness plan. A 7-day probabilistic weather forecast was also developed and is used to trigger the plan in advance of dangerous heat waves. The pilot plan was implemented in 2013, and public outreach was done through training workshops, hoardings/billboards, pamphlets, and print advertisements. Evaluation activities and continuous improvement efforts are ongoing, along with plans to explore the program’s scalability to other Indian cities, as Ahmedabad is the first South Asian city to address heat-health threats comprehensively. |
| Risk | The article concludes that climate change reduces access to drinking water, negatively affects the health of people and poses a serious threat to food security. |
| Risk | Dengue is a major international public health concern, one of the most important arthropod-borne diseases. More than 3.5 billion people are at risk of dengue infection and there are an estimated 390 million dengue infections annually. This prolific increase has been connected to societal changes such as population growth and increasing urbanization generating intense agglomeration leading to proliferation of synanthropic mosquito species. |
| Risk | Agriculture in Africa is not only exposed to climate change impacts but is also a source of greenhouse gases (GHGs). While GHG emissions in Africa are relatively minimal in global dimensions, agriculture in the continent constitutes a major source of GHG emissions. In Ghana, agricultural emissions are accelerating, mainly due to ensuing deforestation of which smallholder cocoa farming is largely associated. The sector is also be devilled by soil degradation, pests, diseases and poor yields coupled with poor agronomic practices. |
| Neutral | This is a preliminary investigation on the environmental quality of the city of Pujili, made from the collection of samples of particulate matter and vehicular traffic counts on six points of the city. The methodology is based on the provisions of the Unified Text of Secondary Environmental Legislation for measuring atmospheric particulate matter, and the use of count tables for vehicle registration. The results reflect the impact of vehicular traffic, the characteristics of the rolling road layer, soil erosion, and climate on air pollution and its impact on the health of the population. |
| Neutral | The aim of the present study is to analyse the age effect on the lag patterns of relative risk of hospitalization for acute myocardial infarction and NO2, PM10 and O-3. Daily hospitalizations for AMI during the period 2008–2011 were extracted from administrative data. Analyses were performed using the quasi-Poisson regression model adjusted for seasonality, long-term trend, day of the week and temperature. We observed very different patterns depending on age. For NO2 and PM10, the younger group (25–54years) shows a more delayed effect in comparison with the two older age groups (55–64 and >=65 years). Overall, the associations between NO2 and AMI are higher compared to PM10. There are no associations between O-3 and AMI. This study indicates that age plays a major role in the lag pattern. Younger people have delayed effects, but they are nevertheless sensitive to air pollution. |
Appendix C.1
| Claim: More than 100 percent of the warming over the past century is due to human actions |
| Claim Verdict Label: SUPPORTS |
| Evidence #1 The view that human activities are likely responsible for most of the observed increase in global mean temperature (“global warming”) since the mid-20th century is an accurate reflection of current scientific thinking. [wiki/Kyoto_Protocol] |
| Evidence #2 The dominant cause of the warming since the 1950s is human activities. [wiki/Scientific_consensus_on_climate_change] |
| Claim: Extreme weather isn’t caused by global warming |
| Claim Verdict Label: REFUTES |
| Evidence #1 Researchers have for the first time attributed recent floods, droughts and heat waves, to human induced climate change. [wiki/Extreme_weather] |
| Evidence #2 The effects of global warming include rising sea levels, regional changes in precipitation, more frequent extreme weather events such as heat waves, and expansion of deserts. [wiki/Global_warming] |
References
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient knowledge distillation for bert model compression. arXiv 2019, arXiv:1908.09355. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. Tinybert: Distilling bert for natural language understanding. arXiv 2019, arXiv:1909.10351. [Google Scholar]
- Tang, R.; Lu, Y.; Liu, L.; Mou, L.; Vechtomova, O.; Lin, J. Distilling task-specific knowledge from bert into simple neural networks. arXiv 2019, arXiv:1903.12136. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. Distilbert, a distilled version of bert: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Aguilar, G.; Ling, Y.; Zhang, Y.; Yao, B.; Fan, X.; Guo, C. Knowledge distillation from internal representations. Proc. AAAI Conf. Artif. Intell. 2020, 34, 7350–7357. [Google Scholar] [CrossRef]
- Feng, L.; Qiu, M.; Li, Y.; Zheng, H.-T.; Shen, Y. Learning to augment for data-scarce domain bert knowledge distillation. Proc. AAAI Conf. Artif. Intell. 2021, 35, 7422–7430. [Google Scholar] [CrossRef]
- Ma, X.; Xu, P.; Wang, Z.; Nallapati, R.; Xiang, B. Domain adaptation with bert-based domain classification and data selection. In Proceedings of the 2nd Workshop on Deep Learning Approaches for Low-Resource NLP (DeepLo 2019), Hong Kong, China, 3 November 2019; pp. 76–83. [Google Scholar]
- Du, C.; Sun, H.; Wang, J.; Qi, Q.; Liao, J. Adversarial and domain-aware bert for cross-domain Sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4019–4028. [Google Scholar]
- Rietzler, A.; Stabinger, S.; Opitz, P.; Engl, S. Adapt or get left behind: Domain adaptation through bert language model finetuning for aspect-target sentiment classification. arXiv 2019, arXiv:1908.11860. [Google Scholar]
- Zhuge, M.; Gao, D.; Fan, D.-P.; Jin, L.; Chen, B.; Zhou, H.; Qiu, M.; Shao, L. Kaleido-bert: Vision-language pre-training on fashion domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12647–12657. [Google Scholar]
- Whang, T.; Lee, D.; Lee, C.; Yang, K.; Oh, D.; Lim, H. An effective domain adaptive post-training method for bert in response selection. arXiv 2019, arXiv:1908.04812. [Google Scholar]
- Sung, C.; Dhamecha, T.; Saha, S.; Ma, T.; Reddy, V.; Arora, R. Pre-training bert on domain resources for short answer grading. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 6071–6075. [Google Scholar]
- Lin, C.; Bethard, S.; Dligach, D.; Sadeque, F.; Savova, G.; Miller, T.A. Does bert need domain adaptation for clinical negation detection? J. Am. Med. Inform. Assoc. 2020, 27, 584–591. [Google Scholar] [CrossRef]
- Cody, E.M.; Reagan, A.J.; Mitchell, L.; Dodds, P.S.; Danforth, C.M. Climate change sentiment on twitter: An unsolicited public opinion poll. PLoS ONE 2015, 10, e0136092. [Google Scholar] [CrossRef] [Green Version]
- Diakopoulos, N.; Zhang, A.X.; Elgesem, D.; Salway, A. Identifying and analyzing moral evaluation frames in climate change blog discourse. In Proceedings of the Eighth International AAAI Conference on Weblogs and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 583–586. [Google Scholar]
- Pathak, N.; Henry, M.J.; Volkova, S. Understanding social media’s take on climate change through large-scale analysis of targeted opinions and emotions. AI Mag. 2017, 38, 99–106. [Google Scholar]
- Salway, A.; Elgesem, D.; Hofland, K.; Reigem, Ø.; Steskal, L. Topically-focused blog corpora for multiple languages. In Proceedings of the 10th Web as Corpus Workshop, Berlin, Germany, 7–12 August 2016; pp. 17–26. [Google Scholar]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. Semeval-2016 task 6: Detecting stance in tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar]
- Jiang, Y.; Song, X.; Harrison, J.; Quegan, S.; Maynard, D. Comparing attitudes to climate change in the media using sentiment analysis based on latent dirichlet allocation. In Proceedings of the 2017 EMNLP Workshop: Natural Language Processing Meets Journalism, Copenhagen, Denmark, 7 September 2017; pp. 25–30. [Google Scholar]
- Luo, Y.; Card, D.; Jurafsky, D. Detecting stance in media on global warming. arXiv 2020, arXiv:2010.15149. [Google Scholar]
- Koenecke, A.; Feliu-Faba, J. Learning twitter user sentiments on climate change with limited labeled data. arXiv 2019, arXiv:1904.07342. [Google Scholar]
- Kölbel, J.F.; Leippold, M.; Rillaerts, J.; Wang, Q. Ask Bert: How Regulatory Disclosure of Transition and Physical Climate Risks Affects the Cds Term Structure; Swiss Finance Institute Research Paper no. 21-19; University of Zurich: Zurich, Switzerland, 2020. [Google Scholar]
- Luccioni, A.; Baylor, E.; Duchene, N. Analyzing sustainability reports using natural language processing. arXiv 2020, arXiv:2011.08073. [Google Scholar]
- Webersinke, N.; Kraus, M.; Bingler, J.A.; Leippold, M. Climatebert: A pretrained language model for climate-related text. arXiv 2021, arXiv:2110.12010. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bayer, M.; Kaufhold, M.-A.; Reuter, C. A survey on data augmentation for text classification. ACM Comput. Surv. 2021, 55, 1–39. [Google Scholar] [CrossRef]
- Li, B.; Hou, Y.; Che, W. Data augmentation approaches in natural language processing: A survey. AI Open 2022, 3, 71–90. [Google Scholar] [CrossRef]
- Berrang-Ford, L.; Sietsma, A.J.; Callaghan, M.; Minx, J.C.; Scheelbeek, P.F.; Haddaway, N.R.; Haines, A.; Dangour, A.D. Systematic mapping of global research on climate and health: A machine learning review. Lancet Planet. Health 2021, 5, e514–e525. [Google Scholar] [CrossRef]
- Zhang, Y.; Zheng, J.; Jiang, Y.; Huang, G.; Chen, R. A text sentiment classification modeling method based on coordinated cnn-lstm-attention model. Chin. J. Electron. 2019, 28, 120–126. [Google Scholar] [CrossRef]
- Diggelmann, T.; Boyd-Graber, J.; Bulian, J.; Ciaramita, M.; Leippold, M. Climate-fever: A dataset for verification of real-world climate claims. arXiv 2020, arXiv:2012.00614. [Google Scholar]



| Source | Records w/o DA | Records w/DA |
|---|---|---|
| Web of Science | 21,734 | 43,292 |
| Scopus | 18,937 | 37,458 |
| Total Records | 40,671 | 80,750 (60,560 train/20,190 dev) |
| Downstream Tasks | Dataset Usage | Labels | Label Distribution |
|---|---|---|---|
| Sentiment Analysis | Hand-selected Domain-specific | Opportunity/Neutral/Risk | 872/900/448 |
| Fact-checking | CLIMATE-FEVER | Claim:Support/Refute | 1943/802 |
| Model | Loss Functions | External Data Usage |
|---|---|---|
| BERTbase | + | ✘ |
| BERTbase (Domain pretrained) | + | ✔(domain) |
| TinyBERT [3] | + + + | ✔(unlabeled + labeled) |
| DistilBERT [5] | + + | ✔(unlabeled) |
| ClimateBERT [25] | + | ✔(unlabeled + labeled) |
| CCLA + Max-Pooling [30] | ✔(unlabeled) | |
| Bi-LSTM-Attention | ✘ | |
| POS-Bi-LSTM-Attention | ✘ | |
| DARE (ours) | + + + | ✔(unlabeled + labeled + domain) |
| Model | Acc. | F1 |
|---|---|---|
| BERTbase | ◊0.947 | ◊0.931 |
| BERTbase (Domain pretrained) | ♣0.972 | ♣0.955 |
| TinyBERT | 0.871 | 0.870 |
| DistilBERT | 0.914 | 0.899 |
| ClimateBERT | 0.884 | 0.875 |
| CCLA+Max-Pooling | 0.824 | 0.829 |
| Bi-LSTM-Attention | ♡0.721 | ♡0.719 |
| POS-Bi-LSTM-Attention | ♠0.895 | ♠0.882 |
| DARE(ours) | 0.903 | 0.894 |
| Model | Pre. | Macro F1 | Pre. w/o NOT EI | Macro F1. w/o NOT EI |
|---|---|---|---|---|
| BERTbase | †0.812 | †0.807 | †0.801 | †0.791 |
| RoBERTa | 0.782 | 0.723 | 0.735 | 0.712 |
| DistilRoBERTa | 0.762 | 0.720 | 0.724 | 0.704 |
| ClimateBERT | 0.773 | 0.768 | 0.749 | 0.729 |
| DARE(ours) | ‡0.802 | ‡0.793 | ‡0.793 | ‡0.788 |
| Model | Of Param. (M) | Inference Time (s) | Speed-Up (Times) |
|---|---|---|---|
| BERTbase | 83.7/11.53× | 973.41 | 50.65× |
| DistilBERT | 20.9/2.88× | 243.35 | 12.66× |
| DARE (ours) | 7.26/1.00× | 19.22 | 1.00× |
| Model | Acc. | F1 |
|---|---|---|
| Basic DARE | †0.903 | †0.894 |
| w/o Knowledge Distillation | 0.887 | 0.871 |
| w/o Domain Pretraining | 0.862 | 0.858 |
| w/o Data Augmentation | 0.845 | 0.833 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, K.; Fujii, A. DARE: Distill and Reinforce Ensemble Neural Networks for Climate-Domain Processing. Entropy 2023, 25, 643. https://doi.org/10.3390/e25040643
Xiang K, Fujii A. DARE: Distill and Reinforce Ensemble Neural Networks for Climate-Domain Processing. Entropy. 2023; 25(4):643. https://doi.org/10.3390/e25040643
Chicago/Turabian StyleXiang, Kun, and Akihiro Fujii. 2023. "DARE: Distill and Reinforce Ensemble Neural Networks for Climate-Domain Processing" Entropy 25, no. 4: 643. https://doi.org/10.3390/e25040643