In this study, we want to determine both the maximum information transferred between the environment (as coded by the mutation rate and selection coefficient) and the population’s allele frequencies and how Nature can achieve that maximum information transfer.
For organisms, information transfer occurs from generation to generation. The information is packed within DNA and transferred to the next generation, and this information transfer is affected by the environment. According to “survival of the fittest”, the genes transferred ensure the highest survivability rate in an environment. The information transfer we are concerned with is not the information transfer from generation to generation, but the overall information transfer from the environment (as coded by mutation rates and selection coefficients) to the population’s allele frequencies over time.
2.1. Mutual Information
How can we measure the amount of information transferred from environment (as coded by the mutation rate and selection coefficient) to allele frequencies? We turn to Claude E. Shannon’s information theory. In his paper
A Mathematical Theory of Communication [
21], information theory is developed by conceptualizing communication systems such as electrical circuitry, telecommunication, or everyday human communication in the same framework. A communication system can be broken down into the following: the source of information, an encoder, a channel, a decoder, a receiver, and a destination. The
information source is the sender of a message or messages. A message can be a letter, a word, or really any combination of symbols. The
encoder is a device or any mechanism that converts the message into a signal suitable for the channel. The
channel is the medium in which the message passes through in order to reach the receiver. The
decoder is the opposite of an encoder. It is a device or mechanism that converts the signal back into the original message. The
destination is the end-point. The message has finally reached its goal. Throughout the signal’s path it will encounter noise.
Noise is a distortion that affects the message at any point in communication. Noise can occur at the transmitter if there is an error when the message is converted into a signal. In the channel, noise occurs when an external force (outside of the system) interrupts the signal. In the decoder, the signal does not convert back to the original message. For our system, the noise in the channel is fixed, and we attempt to encode the signal so that it can maximally transmit information through the channel.
Now that we have the foundation for finding the information transferred, how can we compute the amount? Let us consider a general communication system with a sender and a receiver. Suppose that there is a set of possible messages
that correspond to the random variable
X with realizations
x who have a probability distribution
. We know the set of possible messages, but we do not know at each iteration what message was sent. Therefore, we can define the uncertainty of the random variable as:
In information theory, Shannon defines
H as a measure of information produced. In order to see this, let us consider a coin. A fair coin has the probability
of landing on heads. We would not be able to reliably choose one outcome over the other. The entropy of the fair coin comes out to
bit. However, let us now consider a weighted coin with probability
landing on heads where
q is the probability of landing tails. We can now predict that the side weighted in favor of it will land more often. When we choose any value for q, we see that
. The less certain about an event, the more information we need to describe the event. In contrast, if we know what outcome is most likely, then we need less information to describe the event.
Thus far, we only know the information in the original signal. In order to find the measure for information transferred, we need to consider noise in the channel. As mentioned, noise creates disturbances. In the channel, we cannot be certain of what these disturbances are. However, we know what message the decoder receives. If we know the message received, then we can compute the remaining uncertainty after we receive the message sent. Let us suppose that we know the message received
Y, we can define the uncertainty of random variable
X when we know random variable
Y with condition probability distribution
as the conditional entropy:
Let us get an intuitive sense of what the conditional entropy tells us. If conditional entropy is zero, then we are certain that the message received is the original message sent. This scenario entails that we can confirm both messages are identical. Hence, why there is no uncertainty. If conditional entropy is greater than zero, then there is some uncertainty. Perhaps the decoder made an error or the signal was disrupted as it traveled to the decoder. Either way we are no longer certain if the message received is identical to the original message. The smaller the conditional entropy, the less uncertain we are. The larger the conditional entropy, the more uncertain we are. With this intuition of conditional entropy, we can now find a measure for the information transferred.
In Shannon’s seminal thesis [
21], he proposes that if 1000 bits are transferred and 10 bits are lost due to noise, then the information transfer would just be the bits transferred minus expected errors (990 bits). Because we lack the knowledge of the errors, we focus on what we know. The information transferred can be defined both as the number of bits transferred minus the number of bits lost to noise, and as as the reduction in the uncertainty about what was originally sent. Shannon defines this difference as
mutual information and is denoted as:
In order to understand mutual information, let us consider two cases: when mutual information is zero and when it is greater than zero. When mutual information is zero, then the message received and message sent are independent of one another. When mutual information is large, the channel is nearly noiseless, and nearly all information about the original signal is retained. The evolutionary channel will be somewhere in between these two extremes.
If X is a continuous random variable, then probability distributions are replaced by probability density functions.
2.2. Channel Capacity and Blahut-Arimoto Algorithm
In the previous section we found a measure for the information transferred through a channel. What if we were to shape the input so that as much information was transferred as possible? Shannon’s second theorem shows that the maximum rate of information transfer is the channel capacity:
According to Shannon’s second theorem, if the rate of information transfer is greater than the channel capacity, then there is a lot of error in decoding the information received. Minimal, vanishingly small error occurs when information is transferred below the channel capacity.
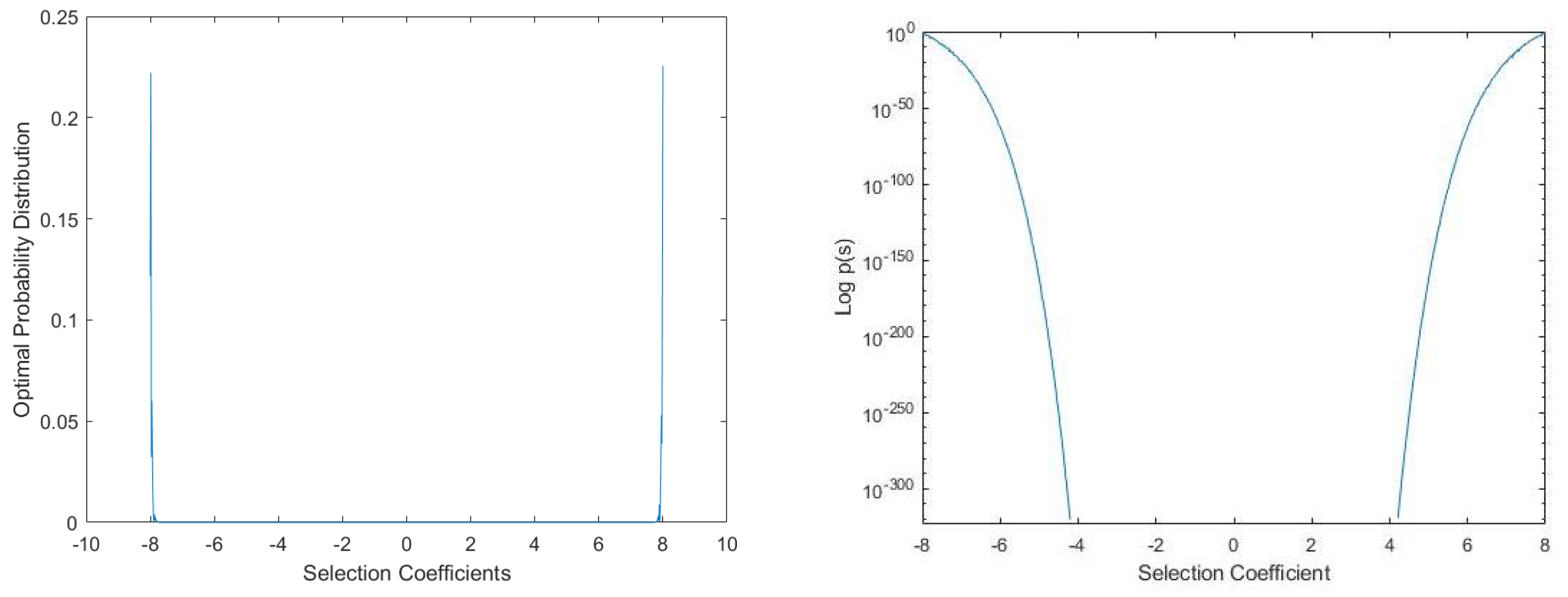
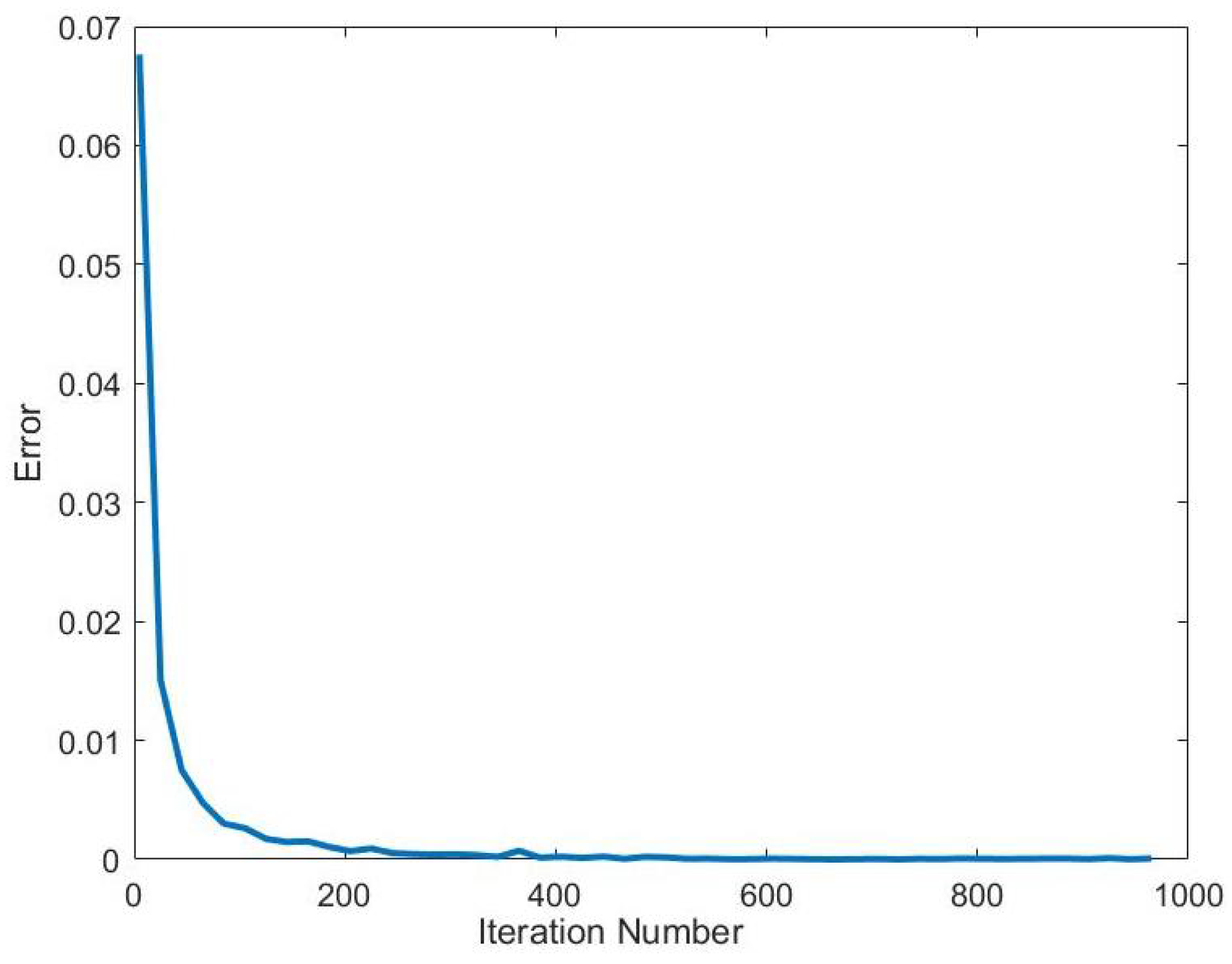
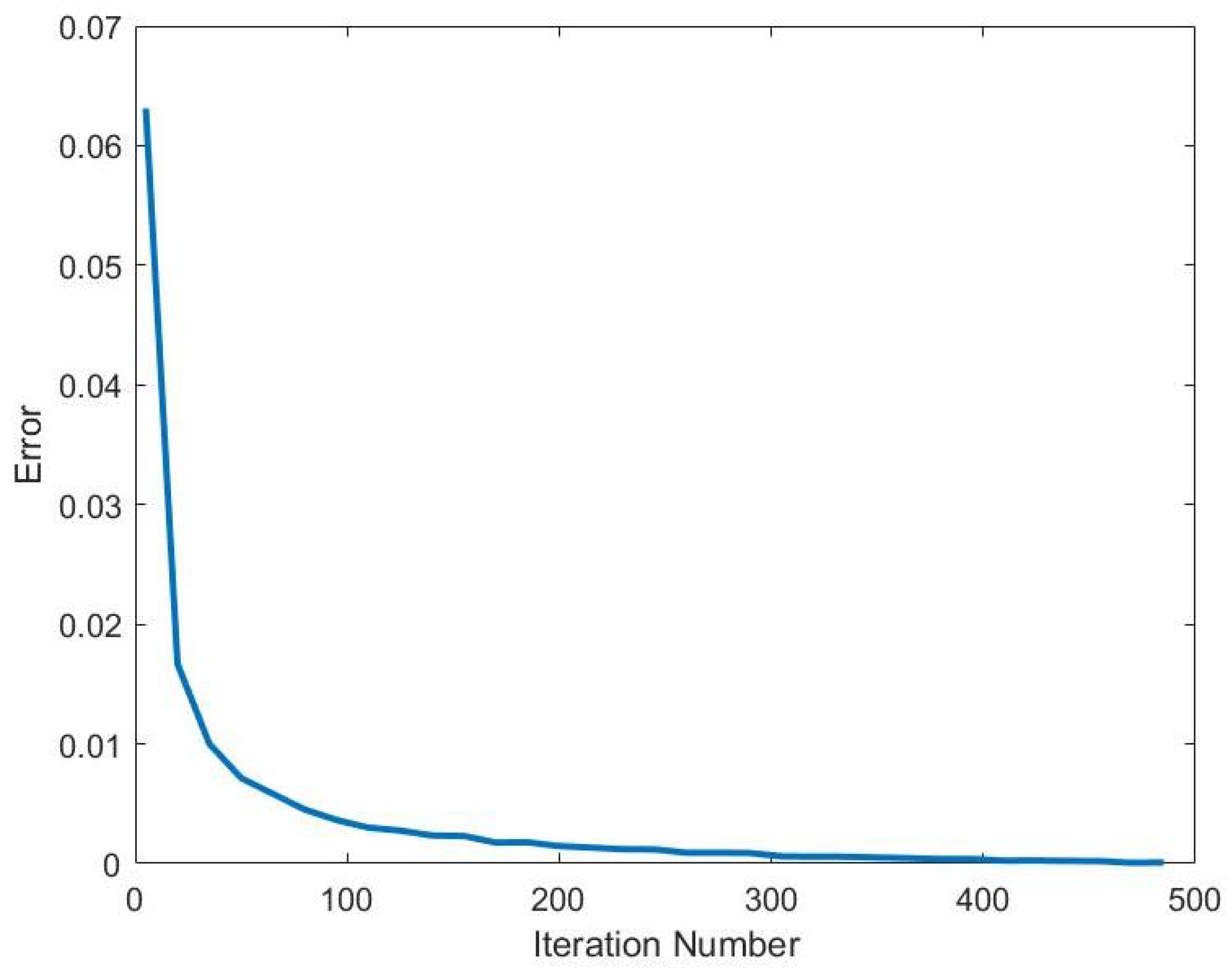
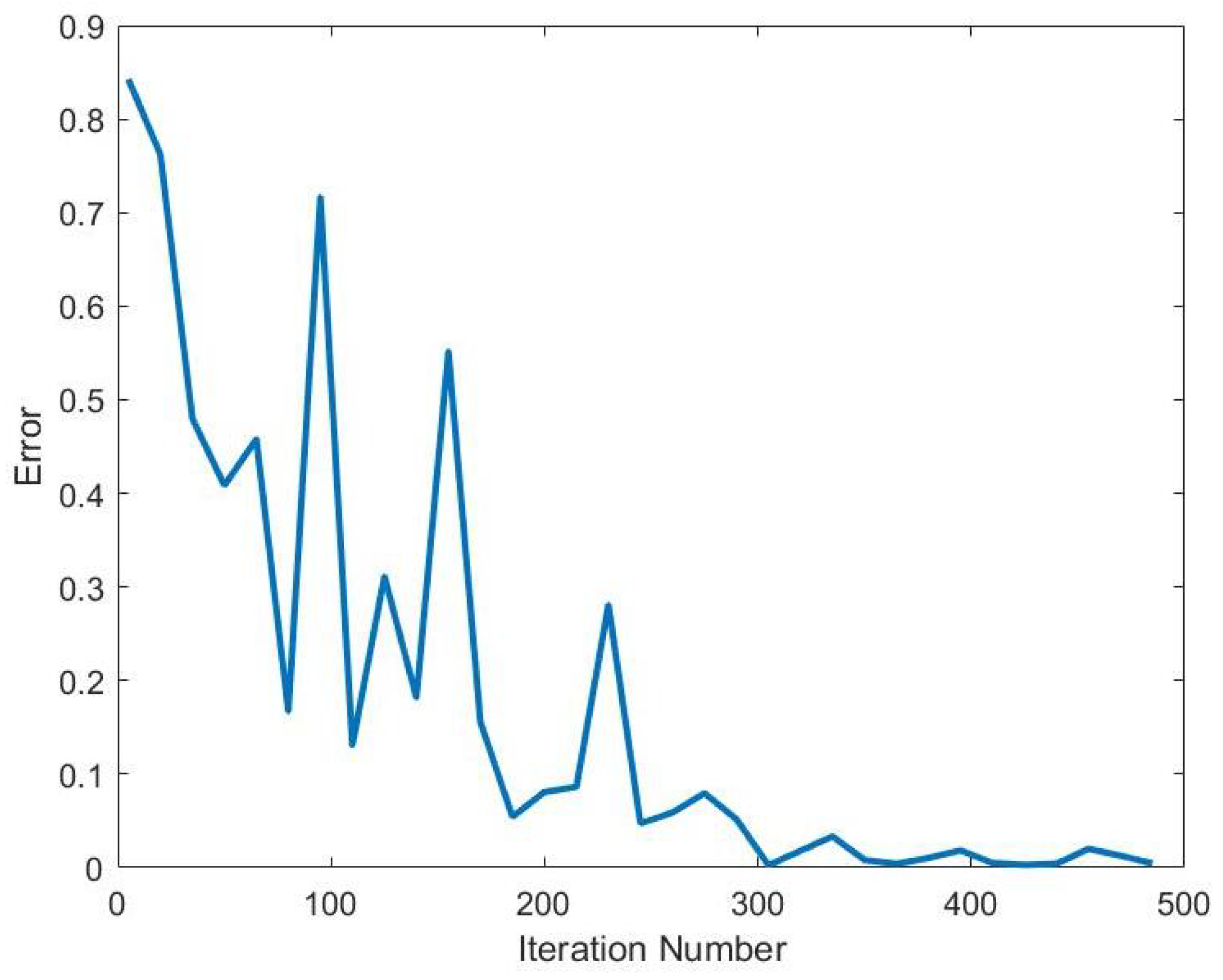
The Blahut-Arimoto algorithm will be our method of numerically computing the channel capacity. The Blahut-Arimoto algorithm is an optimization method for finding the channel capacity
C. In Shannon’s definition of channel capacity, we are finding the supremum over
. This entails that
is a fixed value. The Blahut-Arimoto uses an alternating maximization of
over
and
, where
is still fixed, so that
is now a parameter. Convergence of the algorithm was proven by Csiszar and Tusnady [
22].
With this in mind we can define the steps of the Blahut-Arimoto algorithm. The algorithm starts with a random
. Next, it computes
using the the formula:
After this step, the algorithm alternates to compute for a new
using the formula:
Next the algorithm will determine if channel capacity has been met by iterating Equations (
5) and (
6). If it did not reach the maximum channel capacity, it will continue to alternate Equations (
5) and (
6) until it finds the optimal input probability distribution
.
After completing the computation, the Blahut-Arimoto algorithm is able to provide a channel capacity and an optimal input probability distribution that maximizes mutual information.
If X is a continuous random variable, then probability distributions are replaced by probability density functions.
2.3. Wright-Fisher Model
In order to use these ideas to study the mutual information between environment (as coded by the mutation rates and selection coefficients) and a population’s allele frequencies, we need a model to describe frequency of the population f with allele A and allele B at generation t. The Wright-Fisher model aims to consider the forces of random genetic drift, mutation, and selection pressure that affect an allele’s frequency over generations. Each organism in generation t is replaced by the offspring in generation . For this model, we are allowing allele A to be beneficial or deleterious relative to allele B. To avoid switching the label of the allele in the middle of the calculation, we allow instead s to be negative or positive.
Let’s suppose that for a fixed population size N, the fraction of the population with allele A is f. The population will under go through two processes in order to create the new generation: reproduction with selection, and mutation. Let’s consider the reproduction stage to be a half step before generation is created, . In the reproduction stage, the probability of allele A’s reproduction is influenced by the previous generations frequency f of allele A and selection pressure. The selection pressure determines which allele is beneficial to survive and reproduce in the environment. This selection pressure can be quantified by the selection coefficient s. The reproduction of allele A is set by the probability . When , the allele A is said to be beneficial. Meanwhile, indicates a deleterious allele. Now let us consider the second stage to produce a new generation: mutation. The frequency of allele A for generation , which undergoes mutation, is dependent on the frequency of allele A for generation . The mutation rate can also influence frequency of allele A in generation . The mutation rate is the probability that allele A changes to allele B or vice versa.
We want to consider the diffusion approximation which is valid when
N is large meaning
and
. As such,
s and
can now have arbitrarily large magnitude. For instance, a
of 80 actually corresponds to a mutation rate of
, and in the limit that
which we take here, the mutation rate remains between 0 and 1. According, to the Central Limit Theorem, as
N gets larger, the binomial random sampling is well approximated by a normal distribution. Therefore, if we combine both the selection and mutation stages, the Wright-Fisher model provides us with the following relation:
where
is zero-mean, unit-variance Gaussian noise and
is the frequency of allele
A at generation
t. This equation tells us what the frequency of allele
A will look like after going through one generation of reproduction with selection and mutation.
We used the above frequency equation
in order to create the Langevin equation with time
being a generation. Thus, we are working with the stochastic differential equation
where
is Gaussian noise with zero mean and variance
. The Langevin equation maps to a Fokker-Planck equation. The Fokker-Planck equation is used to study the time evolution of a probability density function. In our case, it is the probability of producing a frequency dependent on the selection coefficient and mutation rates.
where the drift term is
, so that mutation drives one towards a mixed population
and selection drives one towards having only one allele, and the diffusion term is
. When
, the probability favors the frequency of allele
A to be around
if
and probability favors the frequency of allele
A to be around
if
. When
and
, the probability promotes the frequency of allele
A to be near
. When
and
, we find that the probability of seeing a particular frequency of allele
A is uniform. When
and
, diffusion is the only force driving fixation with equal probability of either allele fixating. These limiting cases can be seen in
Figure 1.
We solve for the steady state solution for the Fokker-Planck equation. The solution provides the probability of getting a frequency
f for generation
given selection coefficient and mutation is known. This solution can be derived by noting that the steady-state solution satisfies
and so can be solved by setting the expression in parentheses, or the probability current, to 0:
which leads to
Some straightforward integration gives a steady state solution as follows:
where the denominator normalizes the probability density function.
This probability density function allow us to compute the channel capacity and optimal probability distribution of the Blahut-Arimoto algorithm:
The relationship states that Nature is maximizing information if experimental probability distribution over mutation rates and selection coefficients matches the optimal probability distribution over mutation rates and selection coefficients. We consider the case that a large population of organisms is divided into subpopulations of size
N that all feel different
combinations, so that there can be repeated channel uses with different inputs without having to worry about transients associated with switching from one combination of
to the next.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





