

Implicit Solutions of the Electrical Impedance Tomography Inverse Problem in the Continuous Domain with Deep Neural Networks
Abstract
:1. Introduction
1.1. Contributions
- We present a novel method to solve the EIT shape estimation problem in a continuous domain using machine learning.
- We introduce a constraint and a piece-wise gradient-based optimization problem by using the shape reconstruction from the proposed machine learning algorithm.
- We show that the proposed method using machine learning outperforms the benchmark approaches which do not involve machine learning.
1.2. Related Work
1.3. Rationale for Proposed Shape Reconstruction Using Machine Learning
2. Materials and Methods
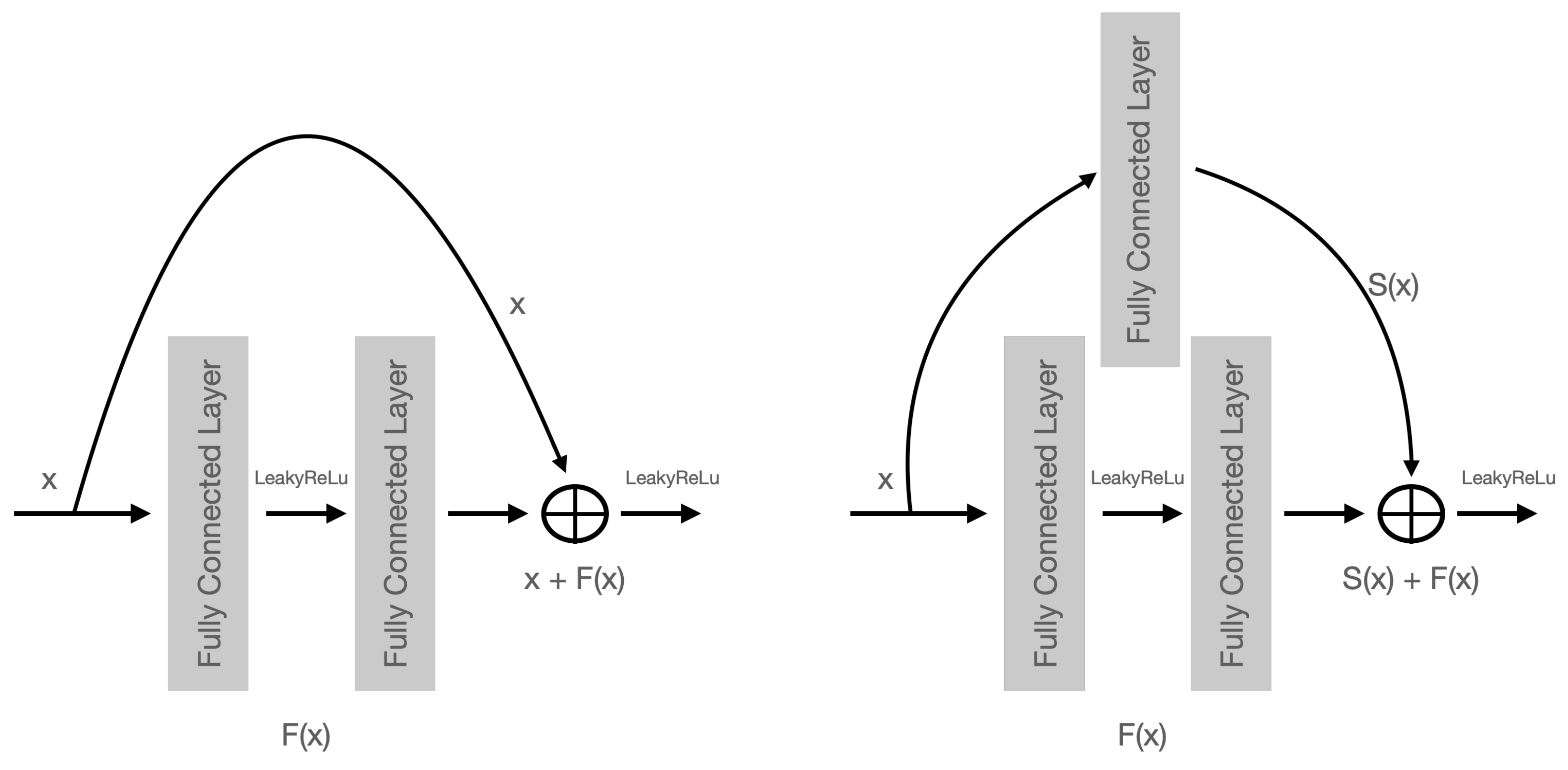
2.1. Leaky Rectified Linear Units
2.2. Residual Neural Network Blocks
2.3. Softmax
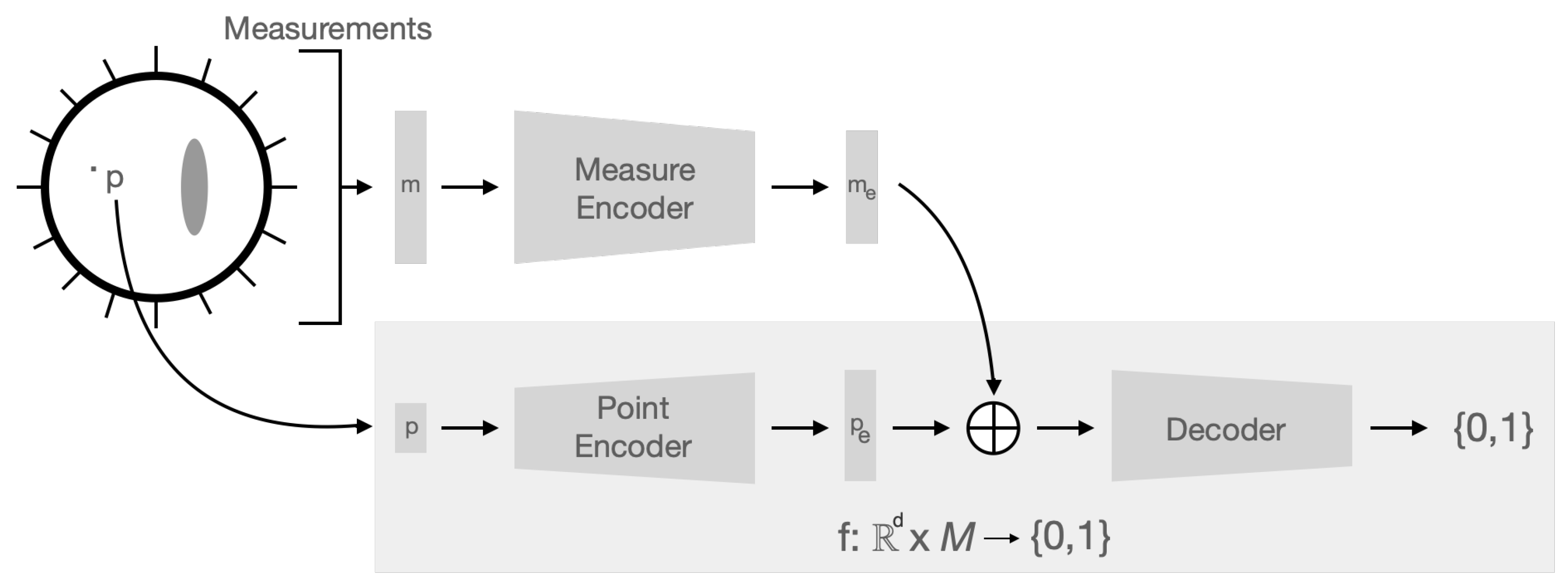
2.4. Implicit Network Architecture for EIT
2.5. Generating Training Data
2.6. The EIT Forward Problem
2.7. Sampling Point Clouds
2.8. Data Sets
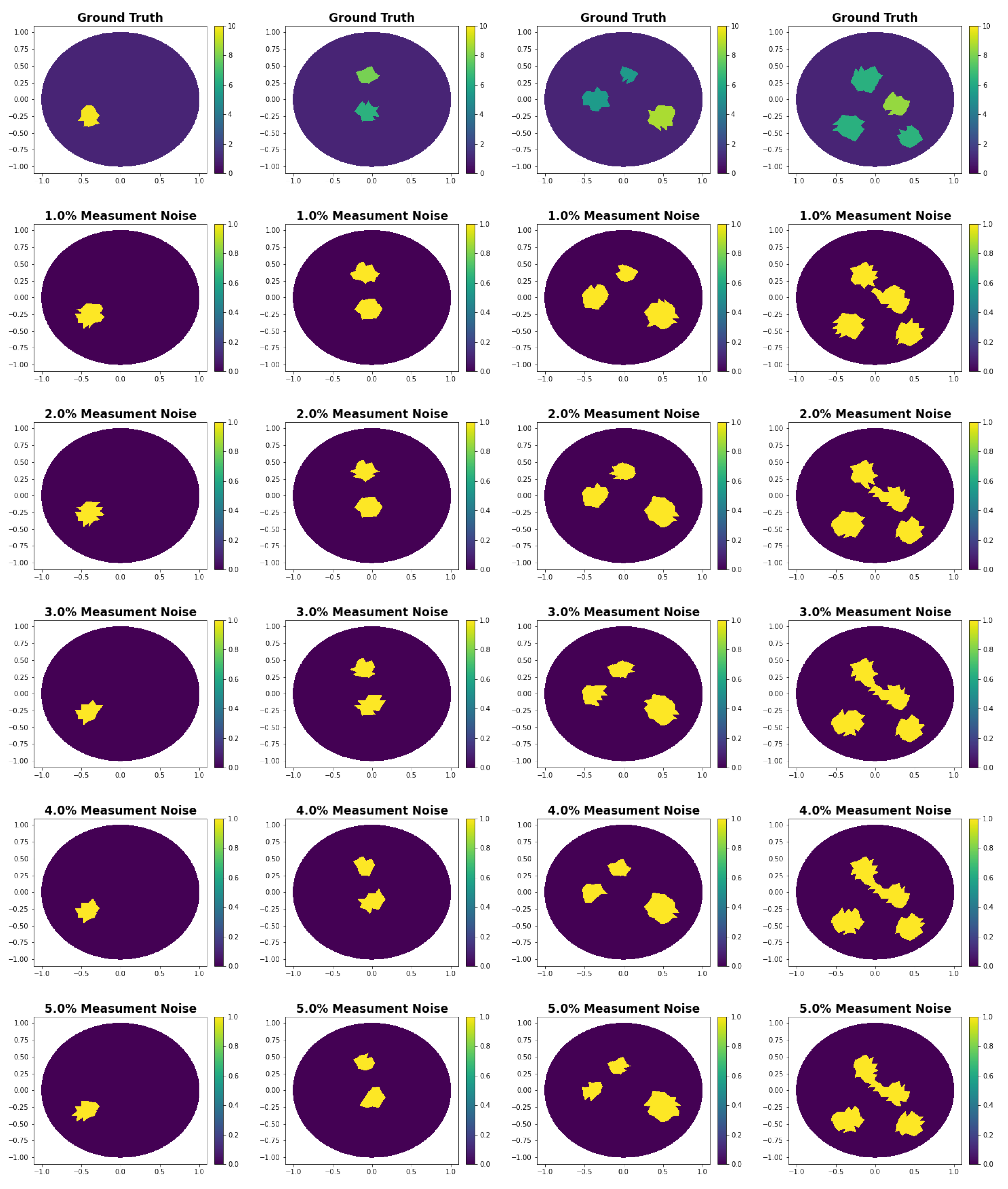
2.9. Noise
2.10. Training
3. Results
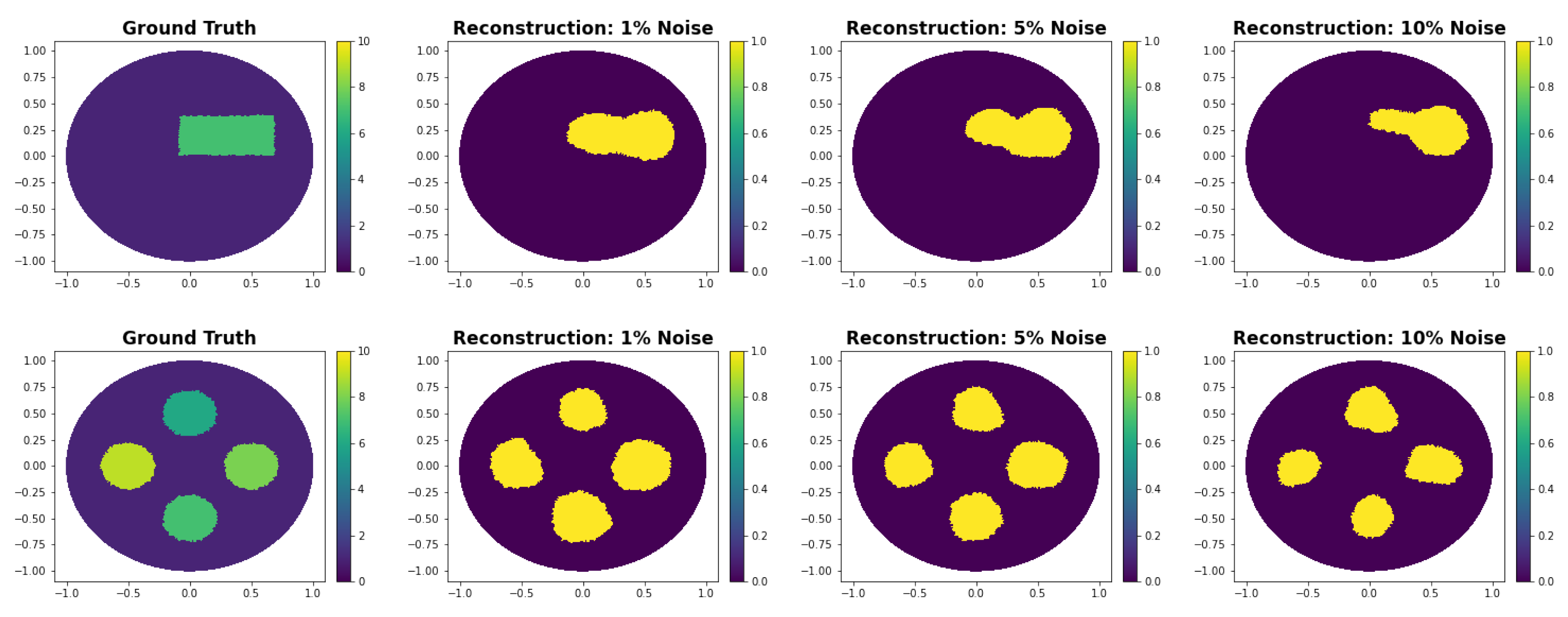
3.1. Noise Study
3.2. Ablation Study
3.3. Comparison with Baseline Approaches
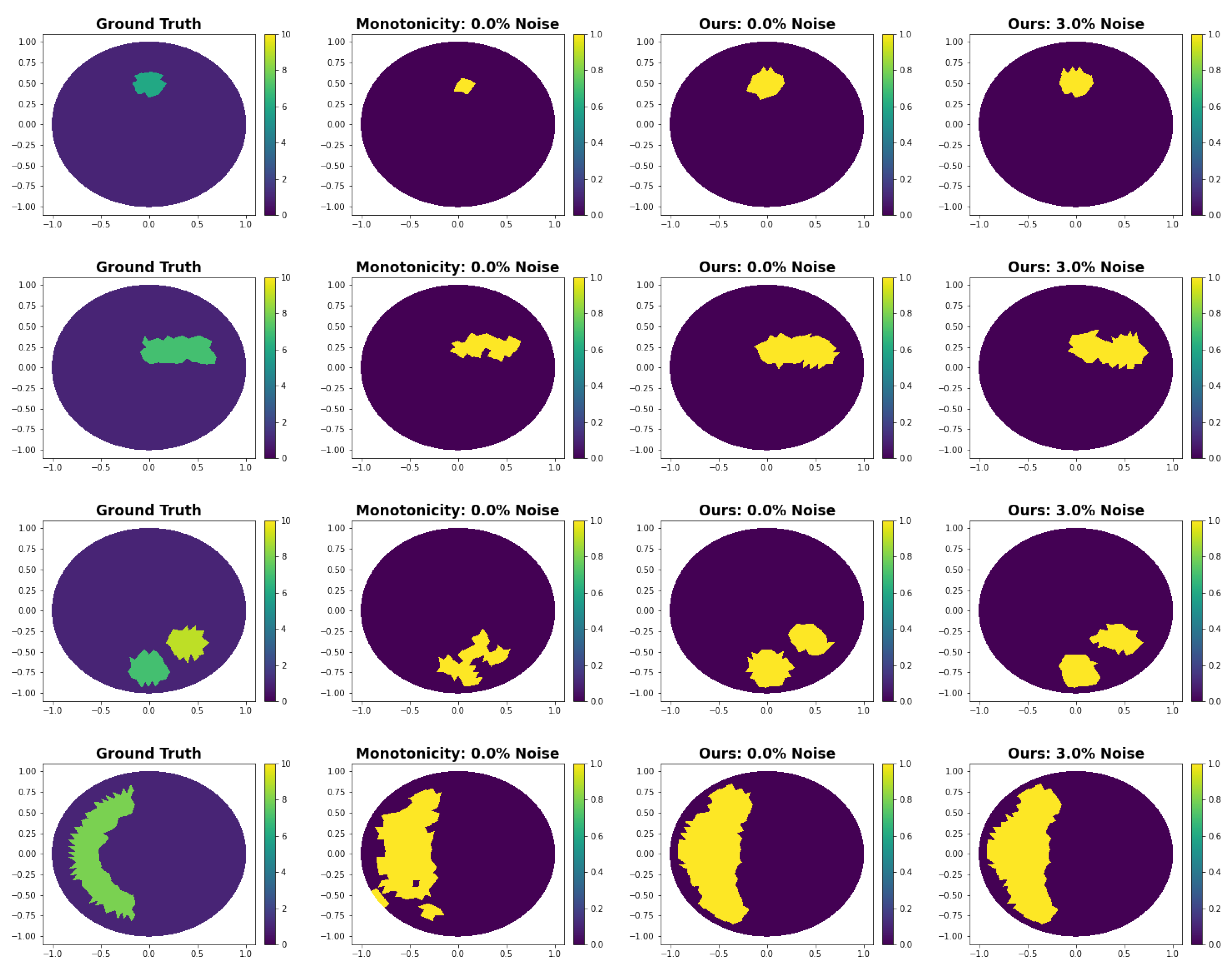
3.3.1. Comparison with Monotonicity-Based Shape Reconstruction
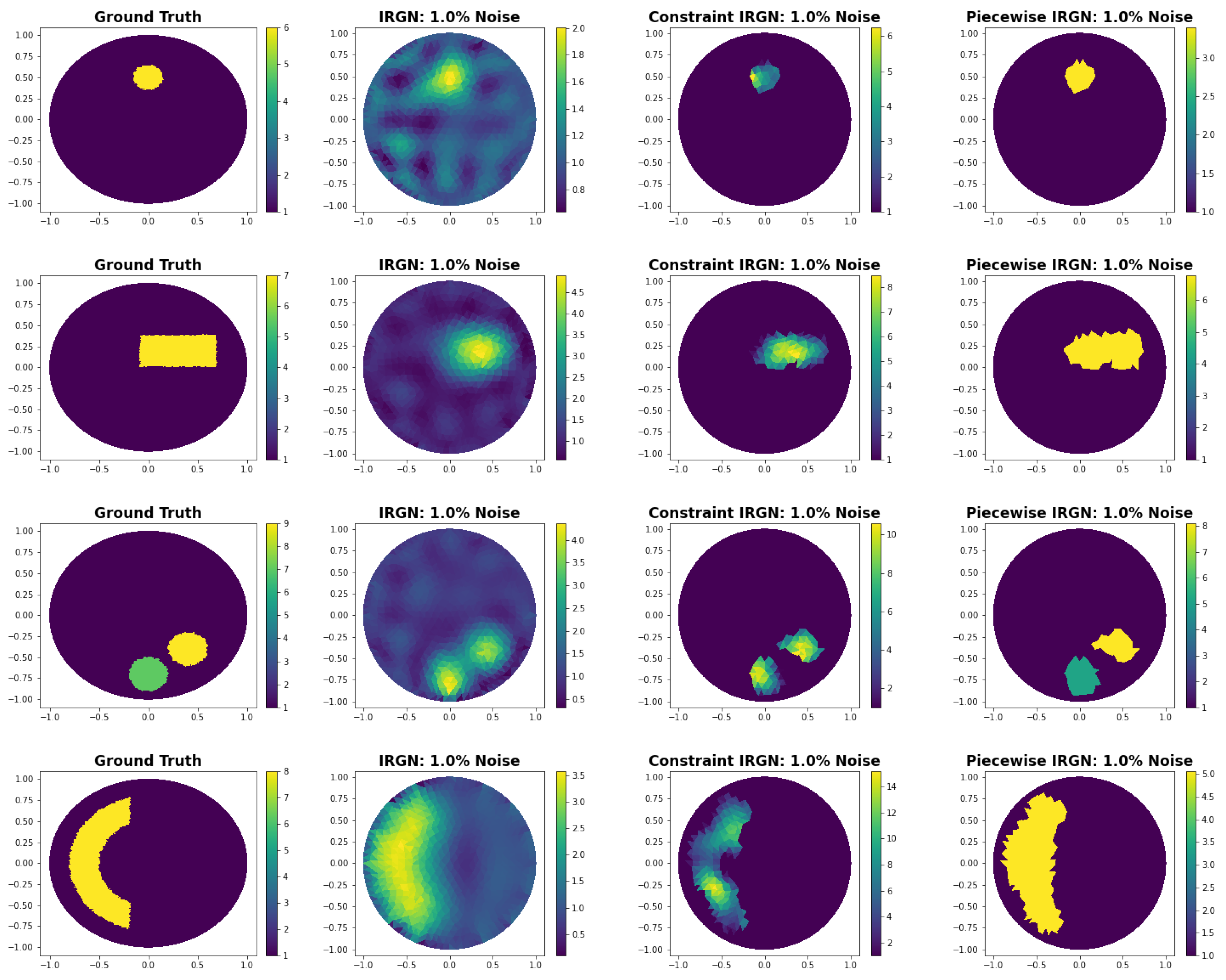
3.3.2. Comparison with Iteratively Regularized Gauss-Newton Method
3.4. Super-Resolution Shape Reconstruction
3.5. Difficulties of the Proposed Method
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Holder, D.S. Electrical Impedance Tomography: Methods, History and Applications; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Bayford, R.H. Bioimpedance tomography (electrical impedance tomography). Annu. Rev. Biomed. Eng. 2006, 8, 63–91. [Google Scholar] [CrossRef]
- Daily, W.; Ramirez, A.; LaBrecque, D.; Nitao, J. Electrical resistivity tomography of vadose water movement. Water Resour. Res. 1992, 28, 1429–1442. [Google Scholar] [CrossRef]
- Hou, T.C.; Lynch, J.P. Electrical impedance tomographic methods for sensing strain fields and crack damage in cementitious structures. J. Intell. Mater. Syst. Struct. 2009, 20, 1363–1379. [Google Scholar] [CrossRef] [Green Version]
- Jin, B.; Khan, T.; Maass, P. A reconstruction algorithm for electrical impedance tomography based on sparsity regularization. Int. J. Numer. Methods Eng. 2012, 89, 337–353. [Google Scholar] [CrossRef]
- Jin, B.; Maass, P. An analysis of electrical impedance tomography with applications to Tikhonov regularization. ESAIM Control. Optim. Calc. Var. 2012, 18, 1027–1048. [Google Scholar] [CrossRef] [Green Version]
- Kaipio, J.P.; Kolehmainen, V.; Somersalo, E.; Vauhkonen, M. Statistical inversion and Monte Carlo sampling methods in electrical impedance tomography. Inverse Probl. 2000, 16, 1487. [Google Scholar] [CrossRef] [Green Version]
- Nissinen, A.; Heikkinen, L.; Kaipio, J. The Bayesian approximation error approach for electrical impedance tomography—experimental results. Meas. Sci. Technol. 2007, 19, 015501. [Google Scholar] [CrossRef]
- Nissinen, A.; Heikkinen, L.; Kolehmainen, V.; Kaipio, J. Compensation of errors due to discretization, domain truncation and unknown contact impedances in electrical impedance tomography. Meas. Sci. Technol. 2009, 20, 105504. [Google Scholar] [CrossRef]
- Ahmad, S.; Strauss, T.; Kupis, S.; Khan, T. Comparison of statistical inversion with iteratively regularized Gauss Newton method for image reconstruction in electrical impedance tomography. Appl. Math. Comput. 2019, 358, 436–448. [Google Scholar] [CrossRef]
- Borcea, L. Electrical impedance tomography. Inverse Probl. 2002, 18, R99. [Google Scholar] [CrossRef]
- Cheney, M.; Isaacson, D.; Newell, J.C. Electrical impedance tomography. SIAM Rev. 1999, 41, 85–101. [Google Scholar] [CrossRef] [Green Version]
- Hanke, M.; Brühl, M. Recent progress in electrical impedance tomography. Inverse Probl. 2003, 19, S65. [Google Scholar] [CrossRef] [Green Version]
- Lionheart, W.R. EIT reconstruction algorithms: Pitfalls, challenges and recent developments. Physiol. Meas. 2004, 25, 125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kassanos, P.; Triantis, I.F.; Demosthenous, A. A CMOS magnitude/phase measurement chip for impedance spectroscopy. IEEE Sens. J. 2013, 13, 2229–2236. [Google Scholar] [CrossRef]
- Kirsch, A.; Grinberg, N. The Factorization Method for Inverse Problems; Number 36; Oxford University Press: Oxford, UK, 2008. [Google Scholar]
- Isaacson, D.; Mueller, J.L.; Newell, J.C.; Siltanen, S. Reconstructions of chest phantoms by the D-bar method for electrical impedance tomography. IEEE Trans. Med. Imaging 2004, 23, 821–828. [Google Scholar] [CrossRef] [PubMed]
- Khan, T.; Smirnova, A. 1D inverse problem in diffusion based optical tomography using iteratively regularized Gauss–Newton algorithm. Appl. Math. Comput. 2005, 161, 149–170. [Google Scholar] [CrossRef]
- Kaipio, J.; Seppänen, A.; Somersalo, E.; Haario, H. Posterior covariance related optimal current patterns in electrical impedance tomography. Inverse Probl. 2004, 20, 919. [Google Scholar] [CrossRef]
- Strauss, T.; Khan, T. Statistical inversion in electrical impedance tomography using mixed total variation and non-convex ℓp regularization prior. J. Inverse -Ill-Posed Probl. 2015, 23, 529–542. [Google Scholar] [CrossRef]
- Harrach, B.; Ullrich, M. Monotonicity-based shape reconstruction in electrical impedance tomography. SIAM J. Math. Anal. 2013, 45, 3382–3403. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.; Khambampati, A.K.; Du, J. A parametric level set method for electrical impedance tomography. IEEE Trans. Med. Imaging 2017, 37, 451–460. [Google Scholar] [CrossRef]
- Liu, D.; Smyl, D.; Du, J. A parametric level set-based approach to difference imaging in electrical impedance tomography. IEEE Trans. Med. Imaging 2018, 38, 145–155. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef] [Green Version]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [Green Version]
- Senior, A.W.; Evans, R.; Jumper, J.; Kirkpatrick, J.; Sifre, L.; Green, T.; Qin, C.; Žídek, A.; Nelson, A.W.; Bridgland, A.; et al. Improved protein structure prediction using potentials from deep learning. Nature 2020, 577, 706–710. [Google Scholar] [CrossRef]
- Dimas, C.; Uzunoglu, N.; Sotiriadis, P.P. An efficient point-matching method-of-moments for 2D and 3D electrical impedance tomography using radial basis functions. IEEE Trans. Biomed. Eng. 2021, 69, 783–794. [Google Scholar] [CrossRef]
- Fernández-Fuentes, X.; Mera, D.; Gómez, A.; Vidal-Franco, I. Towards a fast and accurate eit inverse problem solver: A machine learning approach. Electronics 2018, 7, 422. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, S.J.; Hauptmann, A. Deep D-bar: Real-time electrical impedance tomography imaging with deep neural networks. IEEE Trans. Med. Imaging 2018, 37, 2367–2377. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Ying, L. Solving electrical impedance tomography with deep learning. J. Comput. Phys. 2020, 404, 109119. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, S.J.; Hänninen, A.; Hauptmann, A.; Kolehmainen, V. Beltrami-net: Domain-independent deep D-bar learning for absolute imaging with electrical impedance tomography (a-EIT). Physiol. Meas. 2019, 40, 074002. [Google Scholar] [CrossRef] [Green Version]
- Oechsle, M.; Mescheder, L.; Niemeyer, M.; Strauss, T.; Geiger, A. Texture fields: Learning texture representations in function space. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4531–4540. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4460–4470. [Google Scholar]
- Hu, P.; Shuai, B.; Liu, J.; Wang, G. Deep level sets for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2300–2309. [Google Scholar]
- Oechsle, M.; Niemeyer, M.; Reiser, C.; Mescheder, L.; Strauss, T.; Geiger, A. Learning implicit surface light fields. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Virtual, 25–28 November 2020; pp. 452–462. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 405–421. [Google Scholar]
- Di Cristo, M.; Ren, Y. Stable determination of an inclusion in a layered medium. Math. Methods Appl. Sci. 2018, 41, 4602–4611. [Google Scholar] [CrossRef] [Green Version]
- Harrach, B. Uniqueness and Lipschitz stability in electrical impedance tomography with finitely many electrodes. Inverse Probl. 2019, 35, 024005. [Google Scholar] [CrossRef] [Green Version]
- Kawakami, H. Stabilities of shape identification inverse problems in a Bayesian framework. J. Math. Anal. Appl. 2020, 486, 123903. [Google Scholar] [CrossRef]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Liu, B.; Yang, B.; Xu, C.; Xia, J.; Dai, M.; Ji, Z.; You, F.; Dong, X.; Shi, X.; Fu, F. pyEIT: A python based framework for Electrical Impedance Tomography. SoftwareX 2018, 7, 304–308. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network Block | Input Dimension | Output Dimension |
|---|---|---|
| ResNet | 208 | 128 * scale |
| ResNet | 128 * scale | 128 * scale |
| ResNet | 128 * scale | 128 * scale |
| ResNet | 128 * scale | 64 * scale |
| ResNet | 64 * scale | 64 * scale |
| ResNet | 64 * scale | 64 * scale |
| Network Block | Input Dimension | Output Dimension |
|---|---|---|
| ResNet | 2 or 3 | 32 * scale |
| ResNet | 32 * scale | 64 * scale |
| Network Block | Input Dimension | Output Dimension |
|---|---|---|
| ResNet | 64 * scale | 32 * scale |
| ResNet | 32 * scale | 2 |
| Softmax | 2 | 2 |
| Accuracy: Mean ± Standard Deviation | ||||
|---|---|---|---|---|
| Noise | Training | Training | Training | Training |
| Validation | ||||
| Validation | ||||
| Validation | ||||
| Validation | ||||
| Validation | ||||
| Validation | ||||
| Accuracy: Mean ± Standard Deviation | |||
|---|---|---|---|
| Noise | Scale 1 | Scale 2 | Scale 4 |
| Validation | |||
| Validation | |||
| Validation | |||
| Validation | |||
| Validation | |||
| Validation | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strauss, T.; Khan, T. Implicit Solutions of the Electrical Impedance Tomography Inverse Problem in the Continuous Domain with Deep Neural Networks. Entropy 2023, 25, 493. https://doi.org/10.3390/e25030493
Strauss T, Khan T. Implicit Solutions of the Electrical Impedance Tomography Inverse Problem in the Continuous Domain with Deep Neural Networks. Entropy. 2023; 25(3):493. https://doi.org/10.3390/e25030493
Chicago/Turabian StyleStrauss, Thilo, and Taufiquar Khan. 2023. "Implicit Solutions of the Electrical Impedance Tomography Inverse Problem in the Continuous Domain with Deep Neural Networks" Entropy 25, no. 3: 493. https://doi.org/10.3390/e25030493