1. Introduction
As an important nonverbal cue for emotional understanding, facial micro-expressions (MEs) are very brief and involuntary facial expressions that usually last from 0.04 to 0.2 s [
1]. In contrast to ordinary expressions, MEs are considered the unconscious leakage of genuine feelings when people try to hide them. Therefore, MEs can help reveal hidden emotions and have promising applications in many fields, such as clinical diagnosis [
2] and national security [
3].
Micro-expression recognition (MER) has attracted more and more attention from researchers in recent decades as a critical way of understanding human emotions [
4]. In addition to traditional human-based psychological studies, many researchers have tried to investigate automatic MER methods based on computer vision techniques. In recent years, research on MER has gradually progressed with the development of published ME datasets [
5,
6,
7,
8,
9,
10,
11,
12]. There are two main approaches: methods based on Hand-crafted features [
13,
14,
15,
16,
17,
18] and methods based on Deep learning [
19,
20,
21,
22,
23,
24,
25]. However, a crucial research issue for these two methods is extracting salient and discriminative features from MEs. Firstly, the subtle and fleeting properties of MEs require improvement in the representativeness of both manual features and deep learning-based features. Secondly, while deep learning has demonstrated strong capabilities of feature learning, it relies on extensive data for training. The number of spontaneous annotated ME samples is limited to only just over 2000, which limits the ability of deep learning networks to extract high-level features related to MEs. Thus, extracting discriminative features of MEs remains an area of ongoing exploration.
Enhancing MER performance by expanding the data scale is highly challenging. The data collection and annotation for ME is especially complicated. With limited data, single-scale features may not be sufficient for discriminating different categories of MEs. Combining multiple channels and effectively integrating various scale features, it is possible to improve the model’s ability to learn ME features.
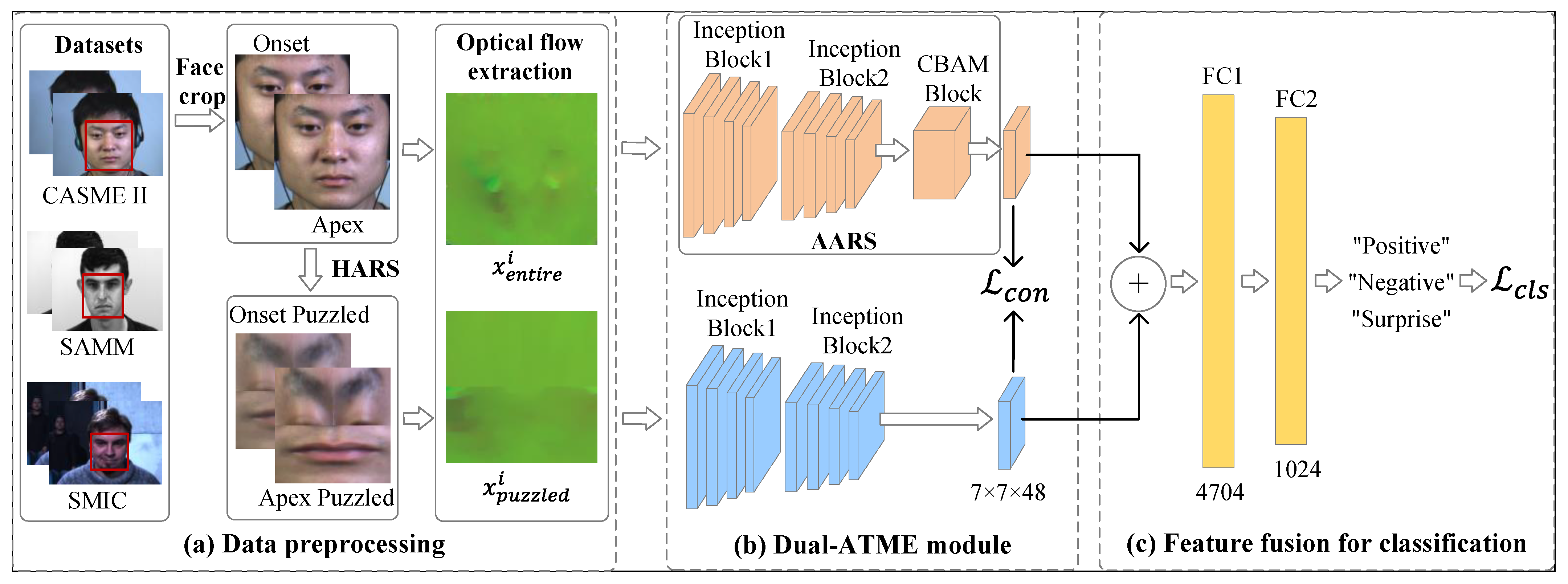
In order to learn ME characteristics efficiently, we propose a simple and effective method called Dual -branch ATtention network for Micro-Expression recognition (Dual-ATME), which uses feature selection, based on both Hand-crafted Attention Region Selection (HARS) and Automated Attention Region Selection (AARS), for MER. Our proposed method includes three sub-modules: Data preprocessing, Dual-ATME module and Feature fusion for ME classification.
In data preprocessing, to better capture the ME motion information, we computed dual-scale optical flow features between the onset and apex frames. Precisely, one scale feature is from the full face and the other is from the HARS-based puzzled counterpart. In the Dual-ATME module phase, in order to simultaneously learn global and local ME features, we utilize the bi-Inception network for HARS-based and AARS-based (full-face) feature extraction, respectively. Furthermore, in order to be able to better focus on ME-related features in the full-face learning network, we employ a combined channel and spatial attention mechanism module. After obtaining the features at both scales, we narrow the distance between them by means of similarity comparison, which empowers the network to refine the ME features common to both. Finally, emotional category prediction is performed by fusing the HARS-based and AARS-based features.
The main contributions of our work are as follows:
We propose the Dual-ATME framework, which extracts HARS- and AARS-based features to perform MER. By adding a parallel artificially-selected ROI ME feature learning module to a standalone deep attention mechanism, we enable the proposed Dual-ATME to effectively learn more discriminative ME features. In particular, based on experimental results, we find that manual feature extraction, based on prior knowledge, is essential for MER with limited data size.
We design a simple and effective joint loss to optimize feature discrimination in our proposed framework. In particular, in addition to the traditional loss for ME classification, we use a similarity comparison loss to close the distance of the dual-scale ME features in the embedding space.
Our Dual-ATME method is extensively evaluated on multiple ME datasets. The experimental results showed that our method demonstrates superior, or comparable, MER performance to state-of-the-art (SOTA) methods on the composite dataset benchmark and single dataset evaluation.
The rest of this paper is organized as follows.
Section 2 introduces related work on MER.
Section 3 presents the details of our proposed algorithm.
Section 4 reports the experimental results on the composite dataset benchmark and single dataset evaluation, as well as ablation studies and visual analysis of our proposed modules. Finally,
Section 5 discusses the conclusions and future research directions.
3. Proposed Method
3.1. Framework Overview
Figure 1 illustrates the overview of our proposed Dual-ATME framework, which consists of three modules: Data preprocessing, Dual-ATME module and Feature fusion for classification module. The Dual-ATME utilizes a dual-branch Inception network as the backbone. It employs Hand-crafted Attention Region Selection (HARS) and Automated Attention Region Selection (AARS) to focus on facial discriminative features in manual and automated manners, respectively.
In particular, during data preprocessing, for each original ME clip, we obtain the optical flow features for the full face and the puzzled counterpart after HARS. Next, in the Dual-ATME module, we feed and into the dual-branch backbone network for independent feature learning. Then, we execute the contrastive loss to pull the distance between HARS-based and AARS-based features from the same ME samples closer, while pushing away the distance between different ME samples. Finally, feature fusion for the ME classification module is performed for expression-refined feature fusion and label prediction.
3.2. Data Preprocessing
In this subsection, we introduce the processes of face cropping, HARS and optical flow-based feature extraction.
3.2.1. Face Cropping
In the ME clip, the ME movement starts at the onset frame and reaches its highest intensity at the apex frame. Studies have shown that by comparing these two frames, ME features can be effectively extracted while avoiding redundant information [
20,
22,
49]. Therefore, we only used the onset and apex frames to capture ME movement changes and to simplify the process. In other words, a pair of onset and apex represented one ME sample in our study.
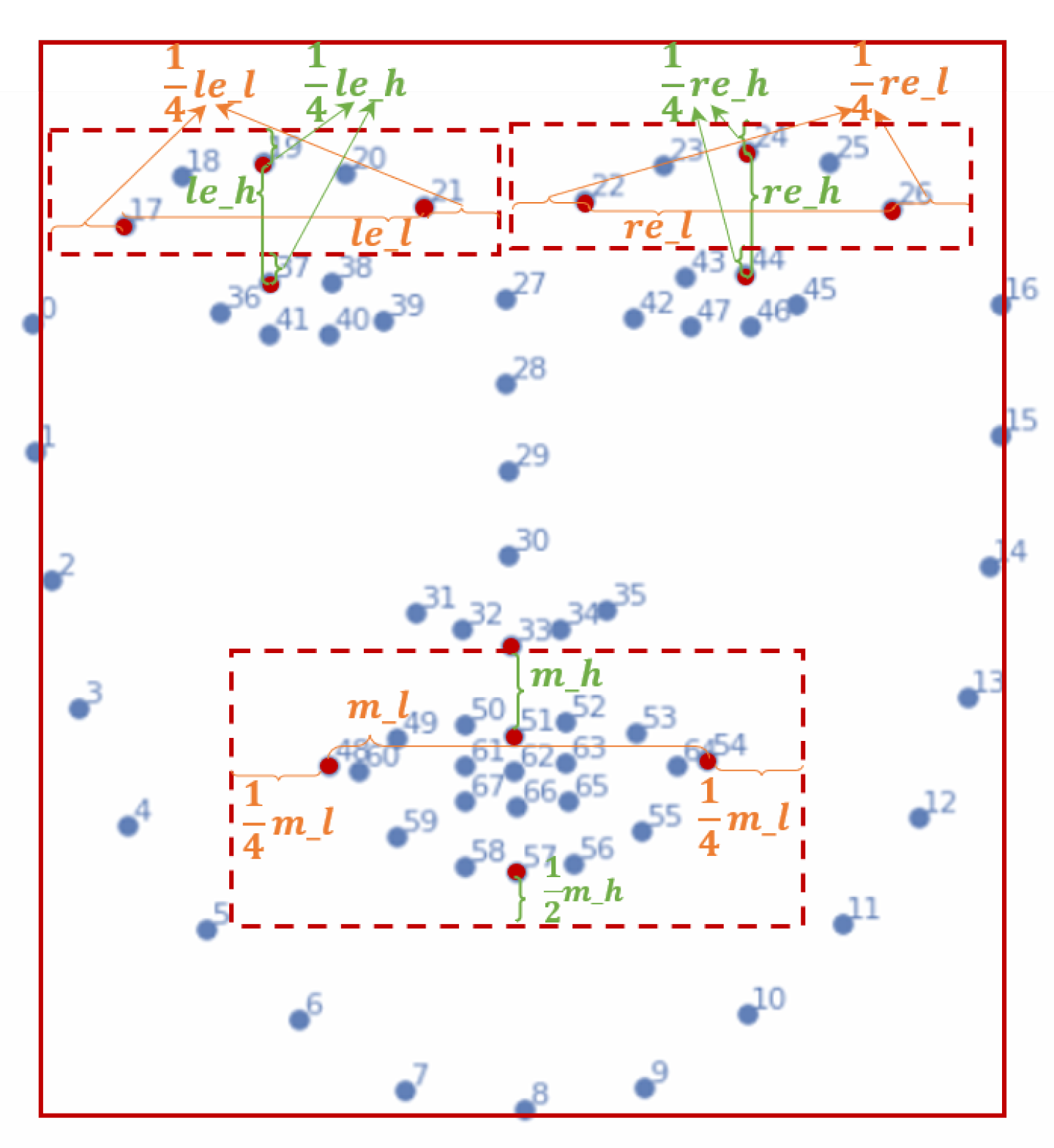
For each pair of onset and apex frames, we first used the Dlib tool [
50] to detect 68 facial landmarks for the onset frame, denoted as
, where
N represents the total number of ME samples and the range of
j represents the 68 facial landmarks, as shown in
Figure 2.
Then, based on Equation (
1), we performed face alignment:
where
is the azimuth calculation function,
and
denote the vertical and horizontal offsets of the line between the two eyes, respectively. We then flipped the face image in the opposite direction of
and, then, re-performed the face key point detection.
Next, we determined the cropping face region based on the updated coordinates of the facial landmarks. Specifically, for the left, right and bottom boundaries of the face region in
ith ME samples, we used the landmarks on the sides of the cheeks and the lower jaw, that is,
,
and
. In addition, for the top boundary, we first calculated the average distance between the left and right sides below the eyebrows and above the eyes, i.e.,
Then, the top boundary was defined as , conserving an expansion area above the eyebrows. Finally, we cropped the face region based on these landmarks.
3.2.2. Hand-Crafted Attention Region Selection (HARS)
The facial regions with the most muscle activity when MEs occur are the eyebrow and mouth regions [
31,
51,
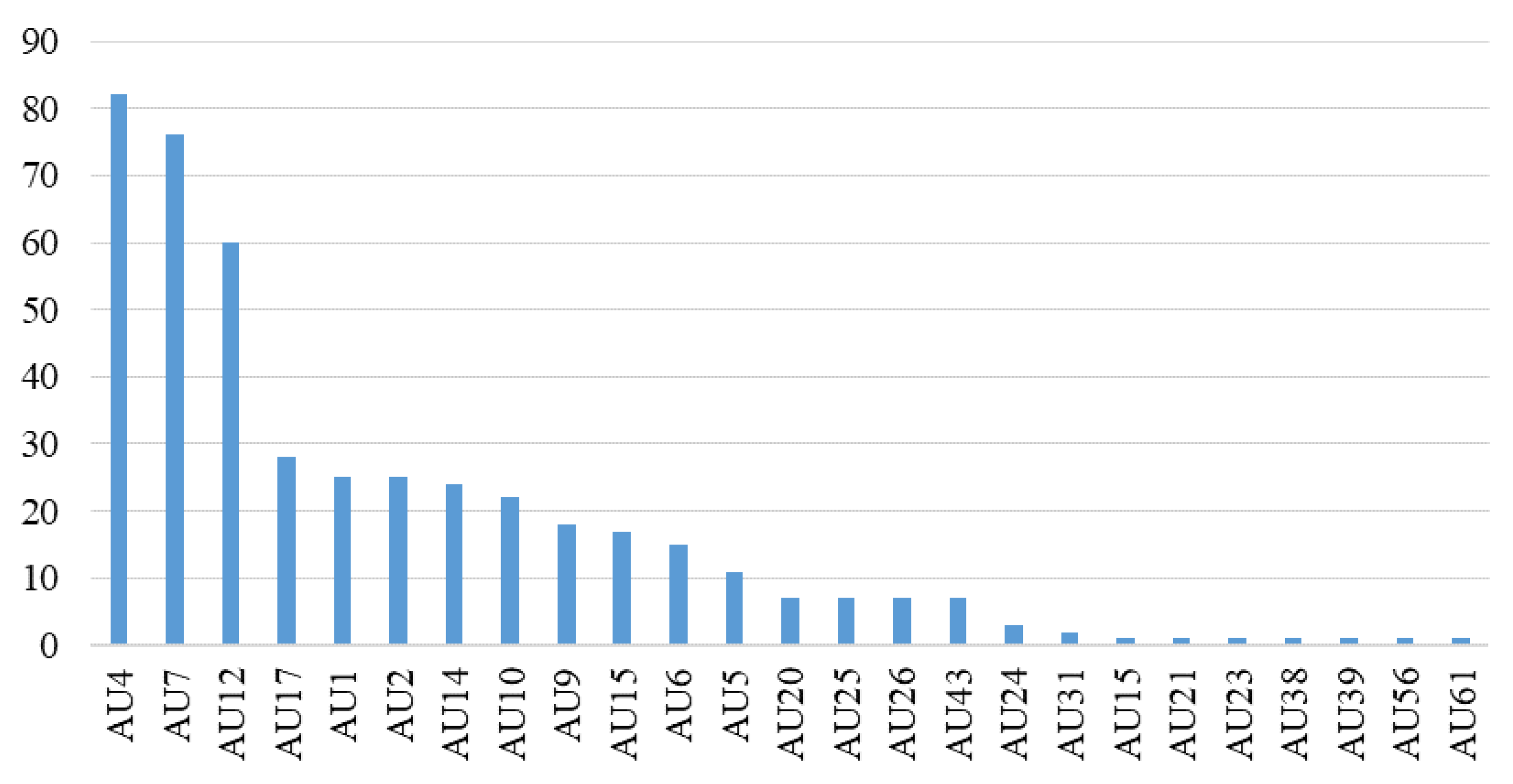
52]. In other words, these regions contribute most of the discriminative ME information. Furthermore, we conducted a statistical analysis of facial action units (AUs) on ME samples from the CASME II and SAMM datasets of MEGC2019. Based on the AU annotations provided for each ME sample by CASME II and SAMM, we counted and ranked the occurrences of AUs. As shown in
Figure 3, it was observed that AUs with higher frequencies were concentrated in the areas around the eyebrows and mouth. Therefore, to reduce the influence of interference from irrelevant regions on MER, our proposed HARS treats the eyebrow and mouth regions as ROIs for local feature extraction. In this way, we can extract more semantic ME-related information.
First, based on the landmarks of the mouth and the eyebrows, we performed region detection and cropping to obtain the boundary borders of each ROI (shown as red dotted boxes in
Figure 2). Specifically, for the left eyebrow of the
i-th ME sample, we calculated the distance between
and
as
le_h and the distance between
and
as
le_l. Then, in order to capture a richer set of information around the left eyebrow, we expanded
to the left and right sides of the left eyebrow, while expanding
upwards to the top of the left eyebrow. Additionally, to reduce interference from the eye area, we set the lower boundary of the left eyebrow area to
. We obtained the boundary of the left eyebrow region through these steps, i.e.,
Symmetrically, the boundary of the right eyebrow region was
For the mouth area, we calculated the distance between the bottom of the nose (
) and the top of the lips (
) as
m_h and the distance between the two corners of the mouth (
and
) as
m_l. Given the four basic landmarks of the lip (
,
,
and
), we expanded
horizontally and
vertically. Finally, the boundary of the mouth region was
Second, after obtaining the boundary coordinates of the eyebrow and mouth regions, we cropped three ROIs for each ME sample: the left eyebrow, right eyebrow and mouth region. Finally, we concatenated the resized left and right eyebrows horizontally and then vertically concatenated them with the mouth. The final puzzled counterpart of the ME sample was formed, as shown in the middle part of
Figure 1b.
It is worth noting that, as shown in
Figure 1, HARS-based and AARS-based feature extraction are parallel in our proposed network. That is, in addition to the ROI-based puzzled counterpart obtained by HARS, we introduce full face-based AARS, described in
Section 3.3.2, thus, achieving MER under the similarity comparison of the two kinds of features.
3.2.3. Optical Flow Extraction
As previously mentioned, the action information in ME is very subtle and it is difficult to extract features of RGB ME samples for MER directly. Based on the theory of brightness constancy [
53], optical flow is an appropriate feature to represent action information. We used the TV-L1 [
54] algorithm to extract the optical flow features.
Specifically, we estimated and extracted the optical flow information for each ME clip between their onset and apex frames. Inspired by Liong et al. [
19], we extracted horizontal and vertical optical flows (
) and further added optical strain to form the final optical flow image, which enriches the motion variations of MEs. Specifically, optical strain, as a derivative of optical flow, is capable of approximating the intensity of facial deformation and is less affected by factors such as lighting conditions and skin color. It can be defined as:
where
denotes the optical flow vector, including horizontal and vertical components and ∇ denotes the derivative of
.
In sum, the final constructed optical flow feature in our study was
. For the whole face, we estimated the optical flow feature
between the onset and apex frames (
,
) using the
TV-L1 algorithm as follows:
Similarly, for HARS-based puzzled counterparts of onset and apex frames (
,
), the optical flow feature
was obtained as:
3.3. Dual-ATME Module
The Dual-ATME consists of two components: the Dual-branch Inception feature extraction module and the ME feature similarity estimation module. The Dual-branch Inception feature extraction module extracts multi-scale features from the ME sample (full face) and its puzzled counterpart. In particular, we apply AARS on full face-based sub-network to learn ME features effectively. Subsequently, the ME feature similarity estimation module estimates the similarity between extracted features and constrains the similarity of the same group of features to be as high as possible.
3.3.1. Backbone: Dual-Branch Inception Feature Extraction Module
Differences in emotion types and individual expressions for ME can lead to diverse distribution of ME movements on the face. Hence, it is challenging to adapt fixed-size convolution kernels in traditional CNNs to each ME sample. Larger kernels are more suitable for extracting global information, while smaller kernels perform better in extracting local information. To learn both local and global ME features, we used the Dual-branch Inception module as the backbone to extract multi-scale features of MEs based on optical flow input.
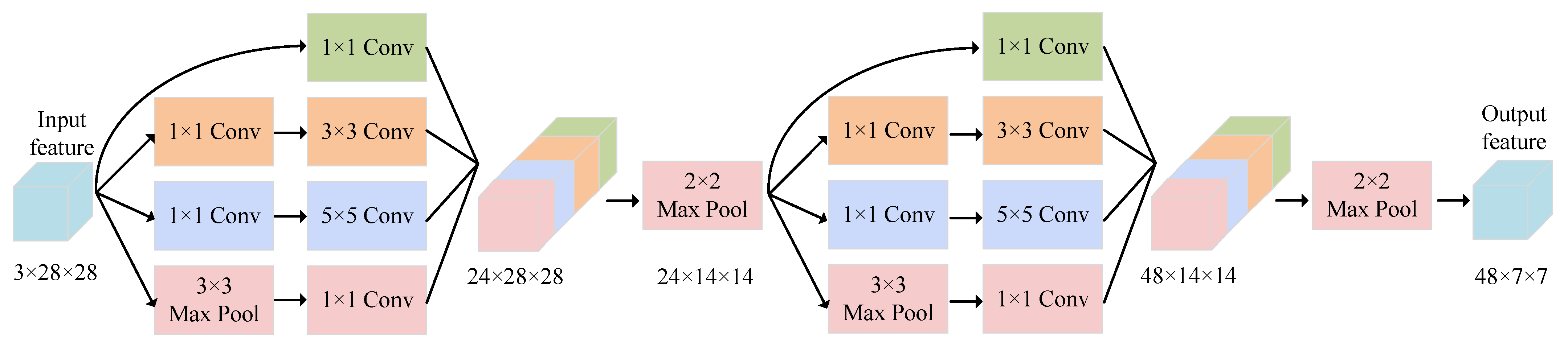
As shown in
Figure 4, each branch of our Dual-branch Inception module consists of a bi-Inception module, composed of two Inception blocks [
55]. An Inception block combines feature maps of different sizes and receptive fields, enabling the network to capture richer information. Specifically, the single Inception block uses three different sizes of convolution kernels, namely
,
and
, to obtain feature maps of various sizes. Additionally,
convolution layers are inserted between the
and
convolution layers to reduce the number of channels in the feature map, thus reducing the computational cost. In our Dual-branch Inception module, the filters for the first and second layers were set to 6 and 12, respectively. Furthermore, we used max-pooling to aggregate the information from the feature maps after each Inception block in each layer. Therefore, in our constructed bi-Inception module, the dimension of the output from the first and the second Inception blocks were
and
, respectively.
Following the suggestion in [
19], the inputs of the two bi-Inception blocks are optical flow features, including
and its corresponding puzzled counterpart
, respectively. In particular, as presented in the Dual-ATME module in
Figure 1,
enters the upper branch, where the bi-Inception network automatically extracts discriminative facial features with the help of the AARS module (See
Section 3.3.2).
enters the lower branch. As mentioned before, the puzzled counterparts are manually obtained with good discriminability through HARS. Moreover, experiments also demonstrated that adding an attention block to this branch did not significantly improve performance (See
Table 1). Thus, we did not implement an Attention block in the lower branch to reduce the model parameters.
The core of the Dual-branch Inception module extracts different feature maps by using two deep convolutional layers simultaneously, improving the robustness and classification performance of the model. For the two feature maps extracted by the Dual-branch Inception module, on the one hand, we conducted ME feature comparison learning (described in
Section 3.3.3) to pull the ME sample and its puzzled counterpart closer. On the other hand, the two feature maps were cascaded after the Dual-branch Inception module by channel dimension and then sent to the classification module (described in
Section 3.4).
3.3.2. Automated Attention Region Selection (AARS)
As introduced in
Section 3.2.2, we propose two Attention Region Selection modules, i.e., HARS and AARS. Contrary to manual ROI selection in HARS, AARS exploits the attention mechanism to automatically focus on the crucial features of the original facial region from the channel and spatial dimensions, respectively and assigns higher weights to these features.
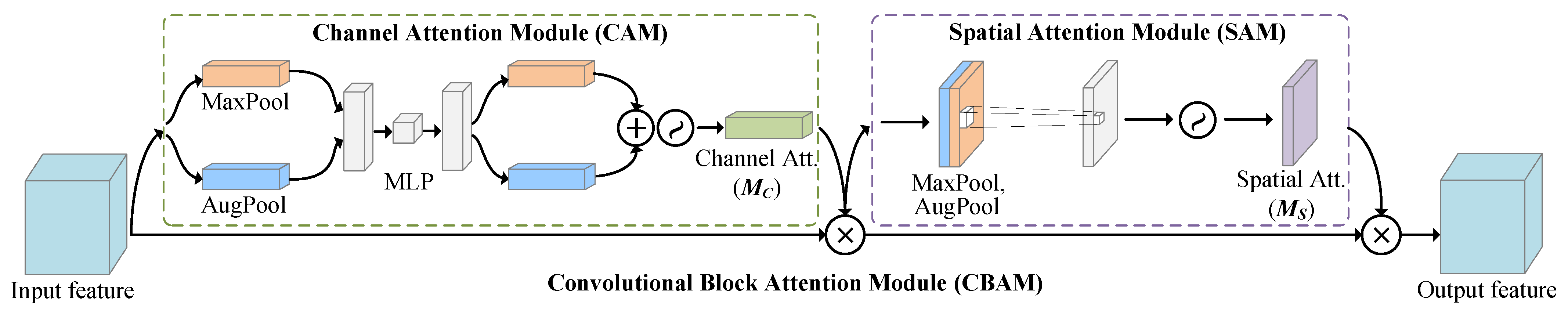
Precisely, we deployed the Convolutional Block Attention Module (CBAM) [
42] attention mechanism module. CBAM was chosen because it includes not only channel attention but also spatial attention to further enhance valuable features in the feature map and suppresses unnecessary features.
The architecture of CBAM in our study is illustrated in
Figure 5. The output of the bi-Inception Module
is given as the input to CBAM. We fed
through the Channel Attention Module (CAM) and the Spatial Attention Module (SAM) in sequence, to obtain the refined features
.
In detail, CAM outputs the channel attention map using the max-pooling and average-pooling in a weight-shared network, as well as the output of a Multi-layer Perceptron (MLP). SAM pools the output of CAM along the channel axis and passes it through a convolutional layer to obtain the spatial attention map. The CAM and SAM are as follows:
CAM. As shown in the left of
Figure 5, we first extracted the spatial context information from
by passing through the max-pooling and the average-pooling layers. Then, the features were fed into a weight-shared MLP with two hidden layers. Finally, the two features output from the MLP were summed element-wise and the result activated by sigmoid to obtain the channel attention features
. The channel attention weight function
can be represented as:
where
denotes the
function and
and
denote max-pooling and average-pooling, respectively.
SAM. Subsequently, as shown in the right of
Figure 5, the input feature for SAM was
. Then, we applied max-pooling and average-pooling to
along the channel dimension. Next, we concatenated the generated feature maps along the channel dimension and applied convolutional and sigmoid operations to obtain the final spatial attention feature map
. The spatial attention weight function
can be represented as:
where
denotes stacking two feature maps along channel dimension.
Finally, the final output feature (
) of the CBAM module (
) can be expressed as:
3.3.3. ME Feature Similarity Estimation
Cosine similarity [
56] can be used to measure the similarity or dissimilarity between two embedding vectors and is commonly used in fields such as machine learning, natural language processing and computer vision. In our study, we wanted to measure the similarity between the ME feature maps of the full face and its puzzled counterpart. Hence, we used
normalized cosine similarity for the comparison. First, we normalized the two feature maps from
to 1. Then, the
normalized cosine similarity
was calculated as follows:
where
and
. The value of
varies from −1 to 1, where 1 indicates a perfect match and
indicates a complete mismatch. If the value is 0, it suggests that the two vectors are orthogonal (perpendicular) to each other and have no correlation. Therefore, to evaluate the difference between two features, we set the contrastive loss as:
This way, different versions of the same ME sample (full-face and puzzled) were matched in the high-level representation space to achieve instance-level approximation.
3.4. Feature Fusion for ME Classification
In the feature fusion stage, two dimensional features and from the dual-ATME module are concatenated along the channel dimension to get a feature. Next, we flatten the feature into a one-dimensional vector and feed it into the final classification module, which consists of two fully-connected layers. To prevent overfitting, we include a Dropout layer with a probability of 0.5 after the first fully-connected layer. The output of the last fully-connected layer is passed through a softmax activation to obtain the ME category predictions.
3.5. Joint Loss Function
In the proposed Dual-ATME, the ME feature similarity estimation (contrastive module) and the classification module are jointly trained. Thus, the joint loss function of the entire network is represented as follows:
where
and
denote the classification loss and contrastive loss, respectively.
represents the regularization parameter, which determines the weight of
in the overall loss. Following the setting in [
22], we perform the Focal loss [
57] as the classification loss. Focal loss could effectively reduce the loss weight for well-classified examples and focus on complex examples with higher losses, improving the recognition performance on unbalanced datasets. By optimizing the joint loss, Dual-ATME can extract discriminative features for MER.
4. Experiments
In this section, we first describe our experimental configuration, which includes datasets, validation protocols and experimental settings. Next, we compare Dual-ATME with SOTA MER methods. We also conducted adequate ablation studies to demonstrate the effectiveness of each module in our framework. Finally, we provide an attention visualization analysis of Our Dual-ATME.
4.1. Datasets and Validation Protocols
4.1.1. Datasets
MEGC2019-CD. A 3DB-combined dataset called MEGC2019-CD was proposed by Micro-Expression Grand Challenge (MEGC2019) for Composite Dataset Evaluation (CDE). It is a composite of three spontaneous datasets: SMIC, CASME II and SAMM, with three emotion categories: Negative (containing Repression, Anger, Contempt, Disgust, Fear and Sadness), Positive (i.e., Happiness) and Surprise). The detailed information of these three datasets is described as follows and shown in
Table 2.
SMIC. The Spontaneous Micro-Expression Corpus (SMIC) consists of three different portions captured by different types of cameras: a conventional visual camera (VIS), a near-infrared camera (NIR) and a high-speed camera (HS). We only used the HS subset of SMIC, captured by a high-speed camera and consistent with CASME II and SAMM. The SMIC-HS subset contains 164 video clips from 16 subjects, recorded using a 100 fps high-speed camera with a resolution of 640 × 480. All MEs in SMIC are divided into three categories: Negative (70), Positive (51) and Surprise (43).
CASME II. The Chinese Academy of Sciences Micro-Expression II (CASME II) dataset contains 255 ME samples from 26 participants, captured using a 200 fps high-speed camera. The raw resolution of each frame is 640 × 480 and the facial region is pixels. The CASME II dataset is divided into seven categories: Disgust (63), Fear (2), Happiness (32), Repression (27), Sadness (7), Surprise (25) and Others (99). In MEGC2019-CD, it is re-classified into three classes: Negative (88, including Disgust and Repression), Positive (32) and Surprise (25).
SAMM. The Spontaneous Actions and Micro-Movement (SAMM) dataset consists of 159 ME clips from 29 participants, captured using a high-speed camera at 200 fps. The original resolution for each ME frame in SAMM is and the facial area is approximately pixels. This dataset includes eight raw emotion classes: Anger (57), Contempt (12), Disgust (9), Fear (8), Happiness (26), Sadness (6), Surprise (15) and Others (26). In MEGC2019-CD, it is re-grouped into three categories: Negative (92, including Anger, Contempt, Disgust, Fear and Sadness), Positive (26) and Surprise (15).
4.1.2. Validation Protocols
Validation Protocol: Leave-one-subject-out (LOSO) cross-validation is a type of cross-validation where each subject in a dataset is used as the test set once, while the remaining subjects are used as the training set. This method is useful when the subjects in the datasets may have inherent differences. Considering the small sample size in MEGC2019-CD and the significant variation in subjects, we used the LOSO cross-validation method to evaluate the model’s performance.
Evaluation Metrics: To evaluate the performance of different methods on the CDE benchmark, we used three metrics: accuracy (Acc), unweighted average recall (UAR) and unweighted F1-score (UF1). These metrics were used to measure the performance on both the composite and individual datasets. The Acc, UAR and UF1 are defined as follows:
where C is the number of classes,
is the number of samples with the
c-th class,
is the total samples and
,
and
are the number of true positive, false positive and false negative samples in the
c-th class, respectively.
4.2. Experimental Setting
For each dataset, we used the Dlib [
50] tool to detect 68 facial landmarks and used these landmarks to crop the facial regions. During training, the facial images were resized to
to serve as the input to the network, with random horizontal flipping applied for data augmentation. During testing, the input images were only resized to
and then fed into the trained model. Our Dual-ATME method was implemented using the Pytorch toolbox, with the backbone network being bi-Inception blocks [
55].
The number of training epochs in our Dual-ATME framework was set as 60. The Adam optimizer was employed, with
and
set to 0.5 and 0.999, respectively. The initial learning rate was 0.001 and a cosine learning rate schedule was applied. For each training iteration, 128 ME samples were used in a mini-batch. All experiments were conducted on a single NVIDIA-RTX-4090 GPU. Our code is available at
https://github.com/HaoliangZhou/Dual-ATME (accessible since 27 February 2023).
4.3. Experimental Results
We compared our proposed method with hand-crafted feature extraction methods and classical deep learning methods on the widely used ME datasets SMIC-HS, CASME II and SAMM. We also performed CDE on their combined dataset MEGC2019-CD.
In terms of the choice of comparison methods, among the hand-crafted feature-based methods, we compared our proposed method with LBP-TOP [
13] and Bi-WOOF [
18]. Among the deep learning methods, we chose the SOTA methods from the MEGC2019 and MER projects with open source code, including STSTNet [
19], Dual-Inception [
20], RCN(_a,_w,_c and _f) [
22], KFC-MER [
43] and MMNet [
44]. Given the transient and subtle nature of ME samples, preprocessing operations on the images can significantly affect the results. To ensure comparability and fairness, we reproduced all these methods using the same inputs and data configuration, including the same number of samples, classes and cross-validation protocol. In addition, we used full-face images as the model input when implementing these methods.
Table 3 provides a comprehensive experimental results overview of all methods on the MEGC2019-CDE dataset. Among the hand-crafted MER methods, the best algorithm was LBP-TOP, which had a UAR and UF1 of 0.5753 and 0.5857, respectively. The RCN_a method achieved the highest UAR and UF1 performance of 0.6351 and 0.6339 among the deep learning methods. Besides these methods, our proposed Dual-ATME, combining HARS and AARS, achieved the best performance on the MEGC2019-CD dataset. In addition, it performed the best on all datasets, except CASME II (n.b. shown in bold) and was second best on CASME II, slightly behind RCN_a. In most cases, our method outperformed its competitors significantly, with a UAR and UF1 that were 4.42% and 4.49% higher than the second-best method (RCN_a), respectively.
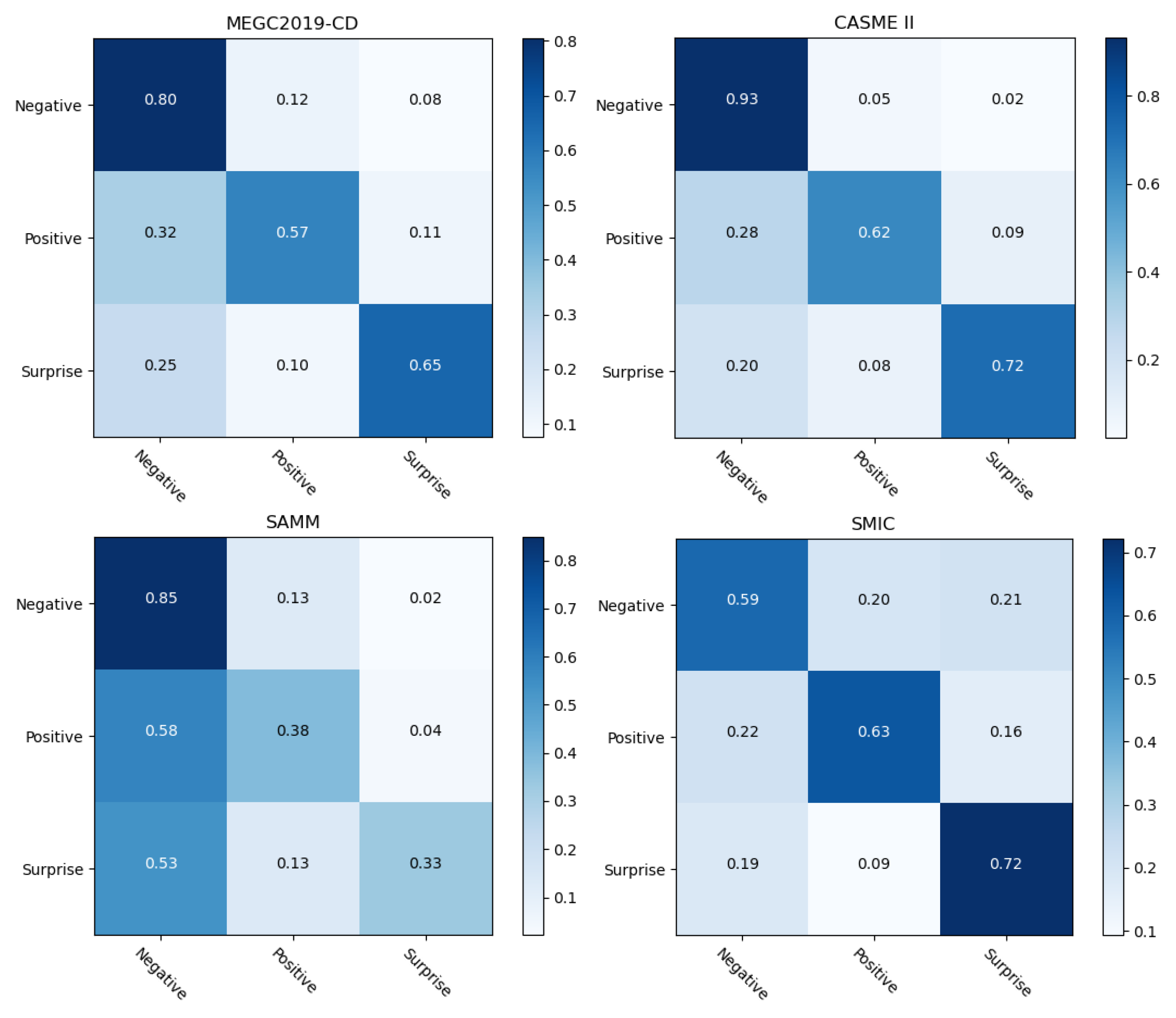
In addition,
Figure 6 shows the confusion matrix of our Dual-ATME on CASME II, SAMM, SMIC and the MEGC2019-CD datasets. On the MEGC2019-CD datasets, Dual-ATME obtained accuracies of 0.80, 0.57 and 0.65 for “Negative”, “Positive” and “Surprise”, respectively. In addition, by comparing the three single datasets, we found that Dual-ATME achieved the highest performance in CASME II, i.e., obtaining 0.93, 0.62 and 0.72 for “Negative”, “Positive” and “Surprise”, respectively. However, in SAMM, Dual-ATME showed the lowest accuracy values in recognizing positive and surprise emotion categories. The reason was that the SAMM dataset had fewer samples than the other two datasets. Moreover, SAMM contains 13 ethnic groups. The rich diversity of subjects, i.e., differences in subjects, can affect the experimental results of LOSO-cross-validation.
From the perspective of different emotional categories, the ME recognition performance on specific emotion type would be empirically improved with more sample data. This is because the deep learning-based model is data-driven, meaning that representational features need to be learned from as much data as possible. As shown in
Figure 6, the number of “Negative” samples outnumbered the “Positive” and “Surprise” in each dataset. Thus, the model consistently achieved the highest recognition performance in the “Negative” category compared to the other two categories.
4.4. Ablation Study
To demonstrate the effectiveness of our method, we conducted ablation studies to assess the contribution of the proposed modules and components to the final performance. For all experiments, we evaluated the performance using the MEGC2019-CD dataset.
4.4.1. Effectiveness of the Proposed Modules
To evaluate the performance of the crucial modules in Dual-ATME, we conducted ablation studies for HARS and AARS on the MEGC2019-CD dataset. As reported in
Table 1, standalone HARS and AARS only achieved sub-optimal performance. Moreover, HARS obtained higher performance than AARS on MER, demonstrating that manual feature extractionm based on prior experiencem plays an essential role in cases of limited data size. The reason is that with limited data, neural networks may not have enough samples to learn complex representations from raw data. In contrast, hand-crafted features, based on prior experience, are more likely to capture the salient information for emotion category identification.
As shown in
Figure 7, the Grad-CAM-based [
59] feature visualization also proved the above conclusion. Specifically, AU12 represents the upturned corners of the mouth and it was found that the network focused better on the mouth region in the puzzled counterpart. Additionally, the combination of HARS and AARS could achieve collaborative enhancement. As shown in the first row of
Figure 7, for this ME sample, AARS only focused on the left corner of the mouth in the full-face image (column (b)). However, the Puzzled image of HARS, based on prior knowledge, was less disturbed, so it not only focused on the left corner of the mouth, but also on the right corner (column (d)). Thus, better MER performance was achieved by fusing the features of HARS and AARS in parallel.
Overall, Dual-ATME combines HARS and AARS and achieved the best results among all variations. HARS-based features are designed to capture concrete, human-understandable concepts, while AARS-based features automatically capture more abstract and data-driven concepts. Combining these two types of features can achieve collaborative enhancement and improve overall performance.
4.4.2. Different Combinations of Face Regions
To validate the effectiveness of the HARS selection strategy based on the eyebrows and mouth regions, we conducted experiments on different combinations of facially discrete areas, including eyebrows, cheeks, nose and mouth. Specifically, we designed the following four combinations: (a) eyebrows + nose, (b) eyebrows + mouth, (c) cheeks + nose, (d) cheeks + mouth and (e) full-face. Thus, the inputs of our Dual-ATME framework were full-face.
As shown in
Table 4, the combination of eyebrows and mouth achieved the best performance on MEGC2019CD, SMIC and SAMM datasets, indicating that variations in the eyebrows and mouth regions are more prominent when ME occurs. This result was further supported by the statistical results based on psychological AU annotation shown in
Figure 3, which demonstrated the reasonableness and effectiveness of our HARS selection strategy focusing on the eyebrows and mouth regions.
4.4.3. Different Values of Weight Coefficient
To evaluate the recognition performance of the proposed method, we varied the value of
in Equation (
11), as listed in
Table 5. A larger value of
meant that the contrastive loss (
) played a more significant proportion of the overall loss and vice versa. Since ME classification is the main task of our model, the classification loss should have the highest weight factor. At the same time, the contrastive loss has an auxiliary role, serving to close the distance between two features in the same group, so we chose a smaller value of
. In this way, we could balance the effects of both losses and obtain the optimal contrastive performance without sacrificing the classification performance. Specifically, we fixed the weight coefficient of the classification loss to 1 and ranged
from 0 to 0.1.
The results in
Table 5 show that the highest performance was achieved when
was set to 0.01. It performed the best in all datasets, except for CASME II and SAMM, which still achieved suboptimal competitive performance. This was because if the value of
is too large, the contrastive loss affects the joint loss function too much, degrading the classification performance. Conversely, a miserly value of
causes the effect of the contrastive loss to be insignificant, resulting in ineffectiveness in closing the distance between two features.
4.4.4. Different Loss Functions and Optimizers
We also evaluated the performance of different classification loss functions and optimizers. Concretely, we compared the performance of standard CE loss, weighted CE loss and Focal loss, respectively. When deciding the weights of weighted CE loss, we calculated the weights of Negative, Positive and Surprise emotions as 0.2857, 0.1329 and 0.1695, respectively, based on the sample sizes of the three types of MEs in the MEGC2019-CD dataset. We also investigated the improvement of model accuracy by different optimizers, i.e., SGD and Adam.
Table 6 shows the results for Acc, UAR and UF1 using various classification loss functions and optimizers. Focal loss achieved the best performance in MEGC2019-CD, SMIC and SAMM datasets and the competitive sub-optimal performance in the CASME II dataset. It automatically focuses on the categories with the fewest samples and gives these features a higher weight. Meantime, the standard cross-entropy loss achieved the best performance on the CASME II dataset. In our experiments, the Adam optimizer was used by default because it performs better than SDG.
5. Conclusions and Perspective
In this paper, we proposed a Dual-branch Attention Network (Dual-ATME) for MER, which consists of three stages: Data preprocessing, Dual-ATME module and Feature fusion for ME classification. In particular, in our Dual-ATME framework, HARS and AARS were combined to extract identity features. Priori experience-based HARS captures noteworthy information about human-understandable concepts. Meantime, Attention mechanism-based AARS automatically captures the complex abstract hidden information within the data. Finally, the above two components were combined to achieve collaborative enhancement and extract discriminative features for MER effectively. The recognition performance of the model was further improved by adding contrast loss in our joint loss to close the two types of features of the same ME sample. Experimental results showed the superiority of our proposed method for performing MER.
In the future, we will further explore automated ROI selection based on large-scale datasets that may help improve MER performance. Specifically, the selection of ROIs is optimized by drawing on the hotspot regions of the attention mechanism. Moreover, we will focus more on spatio-temporal dynamic information to further learn the dynamic representational features of MEs by using the temporal attention mechanism.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}