
Network Coding Approaches for Distributed Computation over Lossy Wireless Networks


Abstract
:1. Introduction
- We first propose a random linear network coding (RLNC) [19] based approach. In this approach, the matrix to be multiplied is first split into multiple submatrices , and each worker node is assigned multiple submatrices, each of which is a random linear combination of the . Each worker node multiplies each assigned submatrix with the input , and it generates random linear combinations of submatrix-vector products that have been created for transmission. Once receiving enough packets with independent global encoding vectors, the master node can recover the desired result by Gaussian elimination. We model the computation and communication process as a continuous-time trellis, and by conducting a probabilistic analysis of the connectivity of the trellis, we theoretically show that the latency of RLNC approach converges to the optimum in probability when the matrix size grows to infinity.
- Since RLNC approach has high encoding and decoding costs, we further propose a practical variation of RLNC approach based on batched sparse (BATS) code [20] and show how to optimize the performance of the BATS approach.
- We conducted numerical simulations to evaluate the proposed RLNC and BATS approaches. The simulation results show that both approaches can overcome the straggler issue and the packet-loss issue effectively and achieve near-optimal performance.
2. System Model
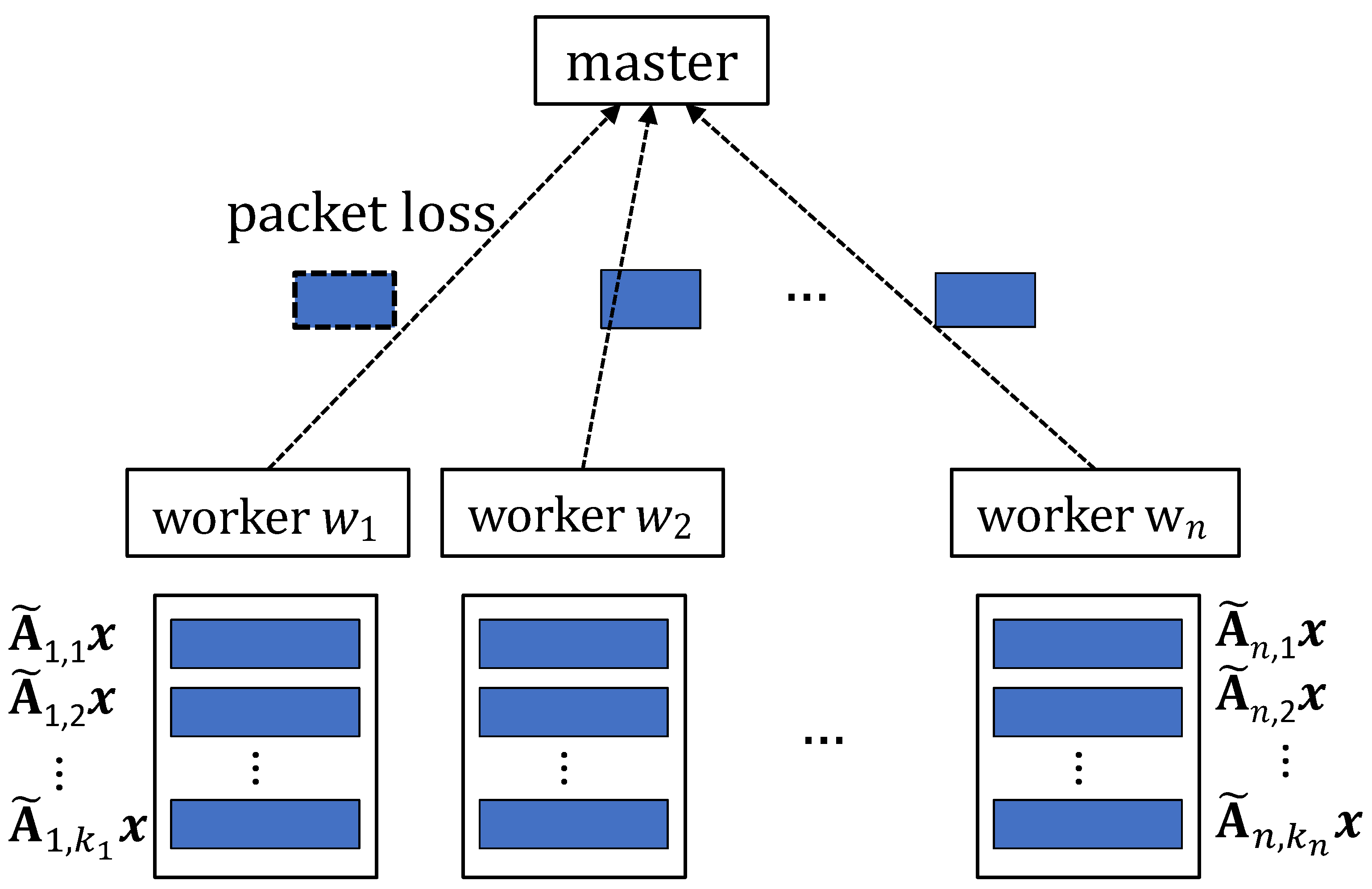
2.1. Coding-Based Wireless Distributed Computation
- Encoding before computation: The matrix is first split along its rows equally into k submatrices , i.e., . Without loss of generality, here we assume that is an integer. These submatrices are encoded into more submatrices using an error-correcting code, which are further placed on worker nodes. The submatrices assigned to worker node are denoted as , where is the number of submatrices assigned to . Here, we emphasize that, in many applications, such as linear regression, this encoding will be used for multiple computations with different inputs [11], so that the encoding is often required to be executed before the arrival of any .
- Computation at each worker node: When an input is arrived at the master node, the master node will broadcast to all these worker nodes. Once worker node receives , it will compute in a sequential manner.
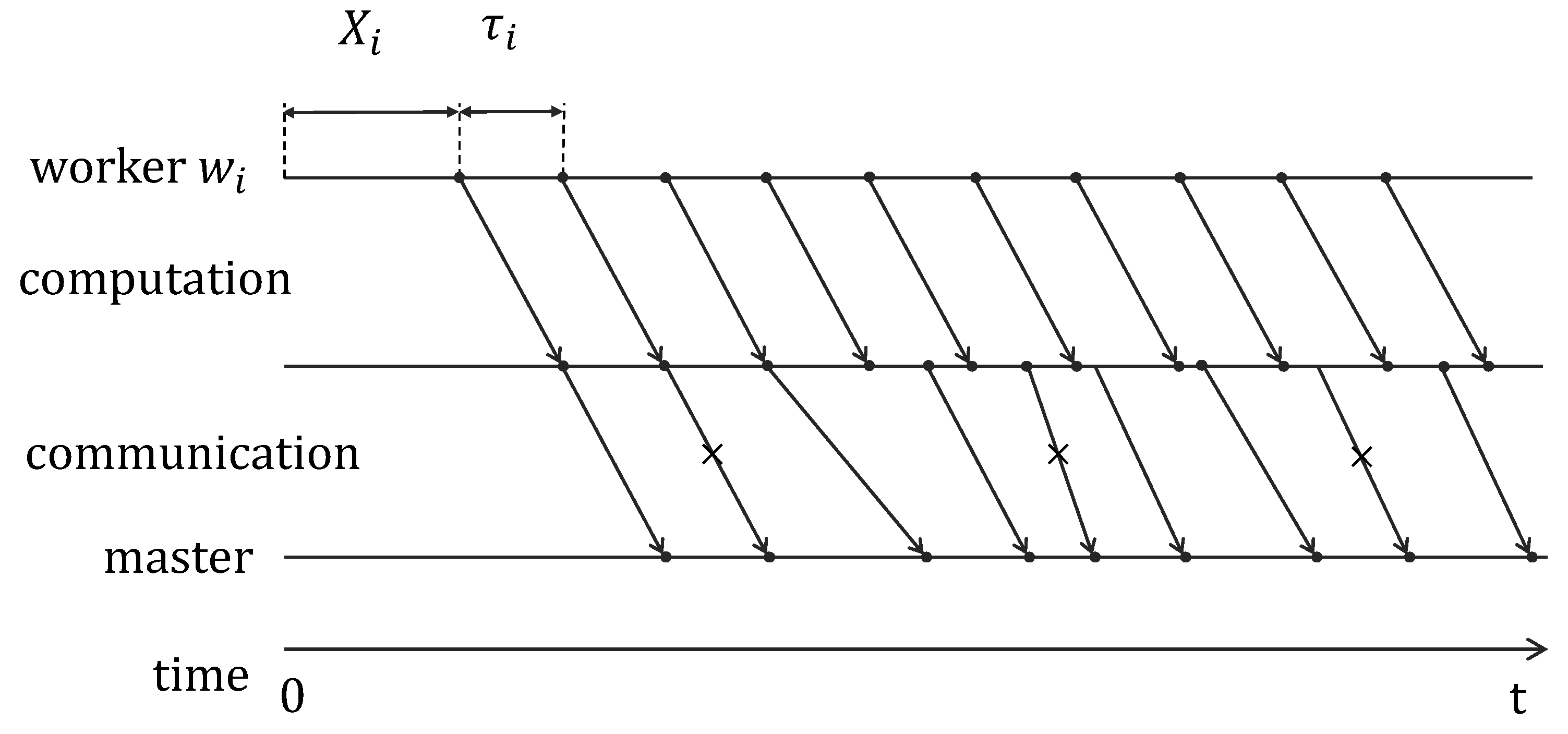
- Communication from each worker node: During the computation, each worker node also keeps on sending its local computation results to the master node in some manner. For this, each submatrix-vector product which is a vector of length is encapsulated into a packet. We assume that the communication link between worker i and the master node can be modeled as a packet erasure channel, where each packet is erased independently with probability . In order to combat these packet losses, each worker node can transmit its local computation results using a coding based approach.
- Decoding at the master node: Once the master node receives enough information, it will recover the desired result and notify all the worker nodes to stop the computation.
2.2. Delay Model
3. A Network Coding Approach
3.1. Description
3.2. Latency Analysis
4. BATS-Code-Based Approach
4.1. Description
- Sample a degree according to a given degree distribution , where D is the maximum degree;
- Select distinct submatrices uniformly at random from ;
- Generate M random linear combinations of the submatrices, which are referred to as a batch.
4.2. Performance Optimization
5. Performance Evaluation
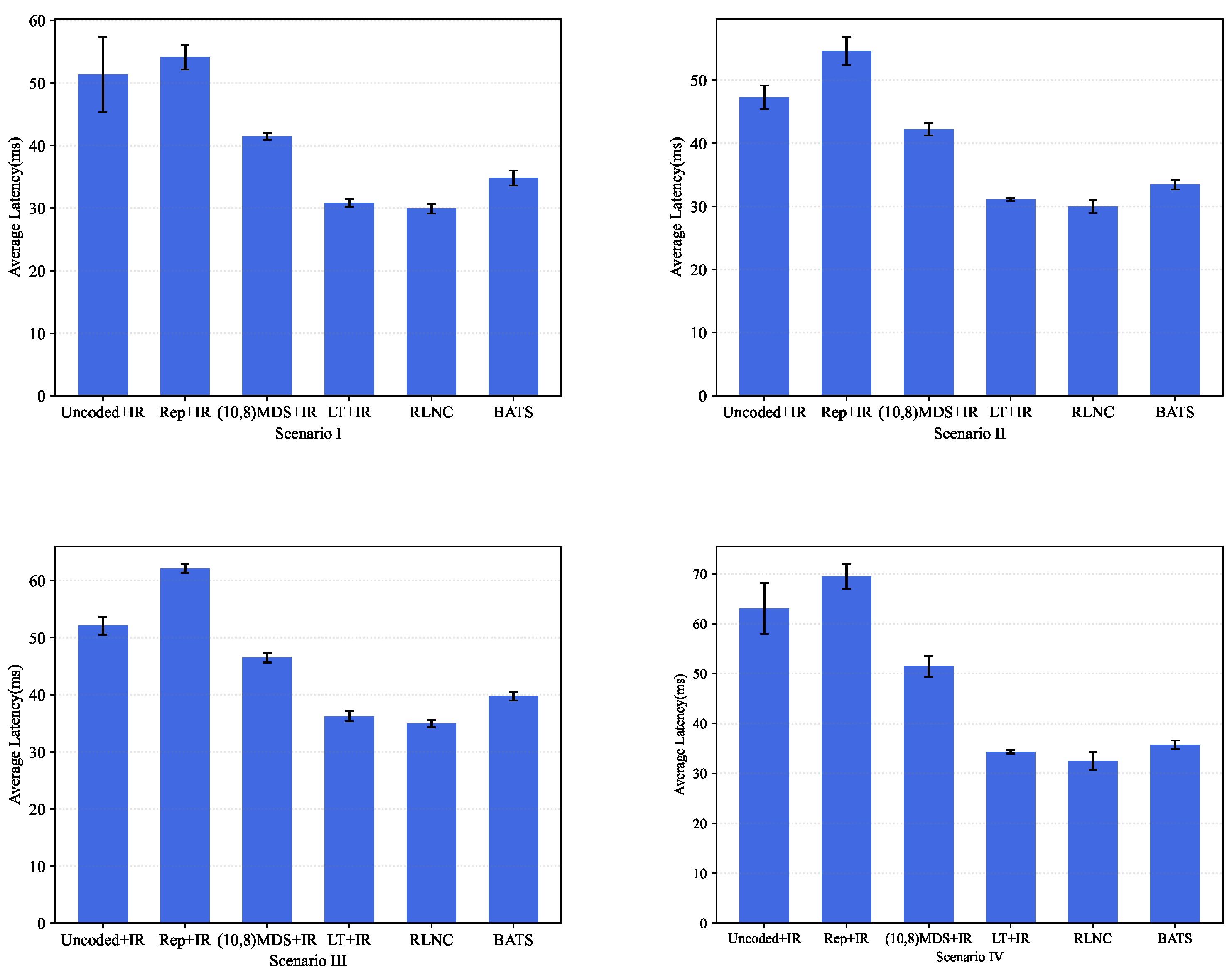
- Scenario I, where , and ;
- Scenario II, where , and ;
- Scenario III, where , and ;
- Scenario IV, where for each worker i, parameters , , , and were uniformly distributed at random over intervals [0.07, 0.2], [0.1, 0.3], [10, 20], [0.05, 0.2] and [0.1, 0.4], respectively.
- Uniform uncoded, where the divided sub-matrices were equally assigned to 10 worker nodes—i.e., each worker node computed 100 sub-matrices.
- Two-Replication, where the divided sub-matrices were equally assigned to five worker nodes, and the computing tasks of these worker nodes were replicated at another five worker nodes.
- MDS code, where the divided 1000 sub-matrices were encoded into 1250 sub-matrices and then equally assigned to 10 worker nodes.
- LT code [14], where the 1000 original sub-matrices were encoded using LT codes, and an infinite number of coded sub-matrices was assigned to each worker node.
- RLNC: The details are introduced in Section 3. The time cost of recoding and decoding operations was ignored.
- BATS code: The details are introduced in Section 4, and a batch size of eight was used.
- Among the first four schemes, LT + IR achieved the best performance for all four scenarios. Note that IR eliminates the packet-loss issue, and this result has also been demonstrated in [14], where only the straggler issue was considered. This is because LT codes can achieve near-perfect load balance among the worker nodes in the presence of stragglers.
- For all these scenarios, the proposed RLNC approach achieved the best latency performance among all these schemes. In particular, the performance of the RLNC approach was slightly better than that of LT + IR. Just like LT + IR, our RLNC approach also achieved near-perfect load balance among the worker nodes. Meanwhile, LT + IR incurred a small precode overhead, whereas the RLNC approach did not. This result also demonstrates the near-optimality of the RLNC approach.
- Our BATS approach performed much better than Uncoded + IR, Rep + IR, and (10,8) MDS + IR in all these scenarios, but slightly worse than LT + IR and RLNC. Since LT + IR assumes an ideal retransmission scheme, which is impractical, and the RLNC approach incurs high encoding and decoding costs, the BATS approach is much more practical.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Zhao, S. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 2179–2217. [Google Scholar] [CrossRef]
- Drolia, U.; Guo, K.; Narasimhan, P. Precog: Prefetching for image recognition applications at the edge. In Proceedings of the Second ACM/IEEE Symposium on Edge Computing, San Jose, CA, USA, 12–14 October 2017; pp. 1–13. [Google Scholar]
- Datla, D.; Chen, X.; Tsou, T.; Raghunandan, S.; Hasan, S.S.; Reed, J.H.; Kim, J.H. Wireless distributed computing: A survey of research challenges. IEEE Commun. Mag. 2012, 50, 144–152. [Google Scholar] [CrossRef]
- Li, S.; Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. A scalable framework for wireless distributed computing. IEEE-ACM Trans. Netw. 2017, 25, 2643–2654. [Google Scholar] [CrossRef]
- Dean, J.; Barroso, L.A. The tail at scale. Commun. ACM 2013, 56, 74–80. [Google Scholar] [CrossRef]
- Zaharia, M.; Konwinski, A.; Joseph, A.D.; Katz, R.H.; Stoica, I. Improving MapReduce performance in heterogeneous environments. In Proceedings of the 8th USENIX Symposium on Operating Systems Design and Implementation, San Diego, CA, USA, 8–10 December 2008; pp. 7–21. [Google Scholar]
- Wang, D.; Joshi, G.; Wornell, G. Efficient task replication for fast response times in parallel computation. In Proceedings of the 2014 ACM International Conference on Measurement and Modeling of Computer Systems, Austin, TX, USA, 16–20 June 2014; pp. 599–600. [Google Scholar]
- Wang, D.; Joshi, G.; Wornell, G. Using straggler replication to reduce latency in large-scale parallel computing. ACM Sigmetrics Perform. Eval. Rev. 2015, 43, 7–11. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Comm. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Spark: Cluster computing with working sets. HotCloud 2010, 10, 10. [Google Scholar]
- Lee, K.; Lam, M.; Pedarsani, R.; Papailiopoulos, D.; Ramchandran, K. Speeding up distributed machine learning using codes. IEEE Trans. Inf. Theory 2017, 64, 1514–1529. [Google Scholar] [CrossRef]
- Ferdinand, N.; Draper, S.C. Hierarchical coded computation. In Proceedings of the 2018 IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 1620–1624. [Google Scholar]
- Kiani, S.; Ferdinand, N.; Draper, S.C. Exploitation of stragglers in coded computation. In Proceedings of the 2018 IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 1988–1992. [Google Scholar]
- Mallick, A.; Chaudhari, M.; Sheth, U.; Palanikumar, G.; Joshi, G. Rateless codes for near-perfect load balancing in distributed matrix-vector multiplication. Commun. ACM 2022, 65, 111–118. [Google Scholar] [CrossRef]
- Luby, M. LT codes. In Proceedings of the 43rd Annual IEEE Symposium on Foundations of Computer Science, Vancouver, BC, Canada, 16–19 November 2002; pp. 271–282. [Google Scholar]
- Shokrollahi, A. Raptor codes. IEEE Trans. Inf. Theory 2006, 52, 2551–2567. [Google Scholar] [CrossRef]
- Han, D.J.; Sohn, J.Y.; Moon, J. Coded Wireless Distributed Computing With Packet Losses and Retransmissions. IEEE Trans. Wirel. Commun 2021, 20, 8204–8217. [Google Scholar] [CrossRef]
- Ahlswede, R.; Cai, N.; Li, S.Y.; Yeung, R.W. Network information flow. IEEE Trans. Inf. Theory 2000, 46, 1204–1216. [Google Scholar] [CrossRef]
- Ho, T.; Médard, M.; Koetter, R.; Karger, D.R.; Effros, M.; Shi, J.; Leong, B. A random linear network coding approach to multicast. IEEE Trans. Inf. Theory 2006, 52, 4413–4430. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Yeung, R.W. Batched sparse codes. IEEE Trans. Inf. Theory 2014, 60, 5322–5346. [Google Scholar] [CrossRef] [Green Version]
- Park, H.; Lee, K.; Sohn, J.Y.; Suh, C.; Moon, J. Hierarchical coding for distributed computing. In Proceedings of the 2018 IEEE International Symposium on Information Theory, Vail, CO, USA, 17–22 June 2018; pp. 1630–1634. [Google Scholar]
- Lin, Z.; Narra, K.G.; Yu, M.; Avestimehr, S.; Annavaram, M. Train where the data is: A case for bandwidth efficient coded training. arXiv 2019, arXiv:1910.10283. [Google Scholar]
- Yu, Q.; Maddah-Ali, M.; Avestimehr, S. Polynomial codes: An optimal design for high-dimensional coded matrix multiplication. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ramamoorthy, A.; Tang, L.; Vontobel, P.O. Universally decodable matrices for distributed matrix-vector multiplication. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1777–1781. [Google Scholar]
- Ramamoorthy, A.; Tang, L. Numerically stable coded matrix computations via circulant and rotation matrix embeddings. IEEE Trans. Inf. Theory 2022, 68, 2684–2703. [Google Scholar] [CrossRef]
- Wu, Y. A trellis connectivity analysis of random linear network coding with buffering. In Proceedings of the IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 768–772. [Google Scholar]
- Motwani, R.; Raghavan, P. Randomized Algorithms; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar]
- Tang, B.; Yang, S.; Ye, B.; Yin, Y.; Lu, S. Expander chunked codes. EURASIP J. Adv. Signal Process. 2015, 1, 106. [Google Scholar] [CrossRef] [Green Version]
- Tang, B.; Yang, S. An LDPC approach for chunked network codes. IEEE ACM Trans. Netw. 2018, 26, 605–617. [Google Scholar] [CrossRef]
- Feizi, S.; Lucani, D.E.; Médard, M. Tunable sparse network coding. In Proceedings of the 22th International Zurich Seminar on Communications (IZS), Zürich, Switzerland, 29 February–2 March 2012. [Google Scholar]
- Garrido, P.; Sørensen, C.W.; Lucani, D.E.; Agüero, R. Performance and complexity of tunable sparse network coding with gradual growing tuning functions over wireless networks. In Proceedings of the 2016 IEEE 27th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Valencia, Spain, 4–8 September 2016. [Google Scholar]
- Garrido, P.; Gómez, D.; Lanza, J.; Agüero, R. Exploiting sparse coding: A sliding window enhancement of a random linear network coding scheme. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016. [Google Scholar]
- Wunderlich, S.; Gabriel, F.; Pandi, S.; Fitzek, F.H.; Reisslein, M. Caterpillar RLNC (CRLNC): A practical finite sliding window RLNC approach. IEEE Access 2017, 5, 20183–20197. [Google Scholar] [CrossRef]
- Yang, J.; Shi, Z.P.; Wang, C.X.; Ji, J.B. Design of optimized sliding-window BATS codes. IEEE Commun. Lett. 2019, 23, 410–413. [Google Scholar] [CrossRef]
- Karetsi, F.; Papapetrou, E. Lightweight network-coded ARQ: An approach for ultra-reliable low latency communication. Comput. Commun. 2022, 185, 118–129. [Google Scholar] [CrossRef]
- Tasdemir, E.; Nguyen, V.; Nguyen, G.T.; Fitzek, F.H.; Reisslein, M. FSW: Fulcrum sliding window coding for low-latency communication. IEEE Access 2022, 10, 54276–54290. [Google Scholar] [CrossRef]
- Tang, B.; Yang, S.; Ye, B.; Guo, S.; Lu, S. Near-optimal one-sided scheduling for coded segmented network coding. IEEE Trans. Comput. 2015, 65, 929–939. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| 1000 | 2000 | 4000 | 8000 | 16,000 | 32,000 | |
|---|---|---|---|---|---|---|
| matrix multiplication delay | 34.16 | 69.59 | 138.69 | 280.86 | 550.43 | 1116.84 |
| decoding delay (RLNC) | 34.51 | 34.51 | 34.51 | 34.51 | 34.51 | 34.51 |
| decoding delay (BATS) | 0.54 | 0.54 | 0.54 | 0.54 | 0.54 | 0.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, B.; Tang, B.; Qu, Z.; Ye, B. Network Coding Approaches for Distributed Computation over Lossy Wireless Networks. Entropy 2023, 25, 428. https://doi.org/10.3390/e25030428
Fan B, Tang B, Qu Z, Ye B. Network Coding Approaches for Distributed Computation over Lossy Wireless Networks. Entropy. 2023; 25(3):428. https://doi.org/10.3390/e25030428
Chicago/Turabian StyleFan, Bin, Bin Tang, Zhihao Qu, and Baoliu Ye. 2023. "Network Coding Approaches for Distributed Computation over Lossy Wireless Networks" Entropy 25, no. 3: 428. https://doi.org/10.3390/e25030428