4.3.1. The Evaluation of Migration VM Selection Strategy
Our LIP algorithm was compared with random selection (RS) [
9], maximum load (Max), minimum load (Min), and minimum migration time (MMT) [
9]. In order to exclude the influence of the VM migration point selection strategy, the random selection strategy was adopted uniformly in this experiment.
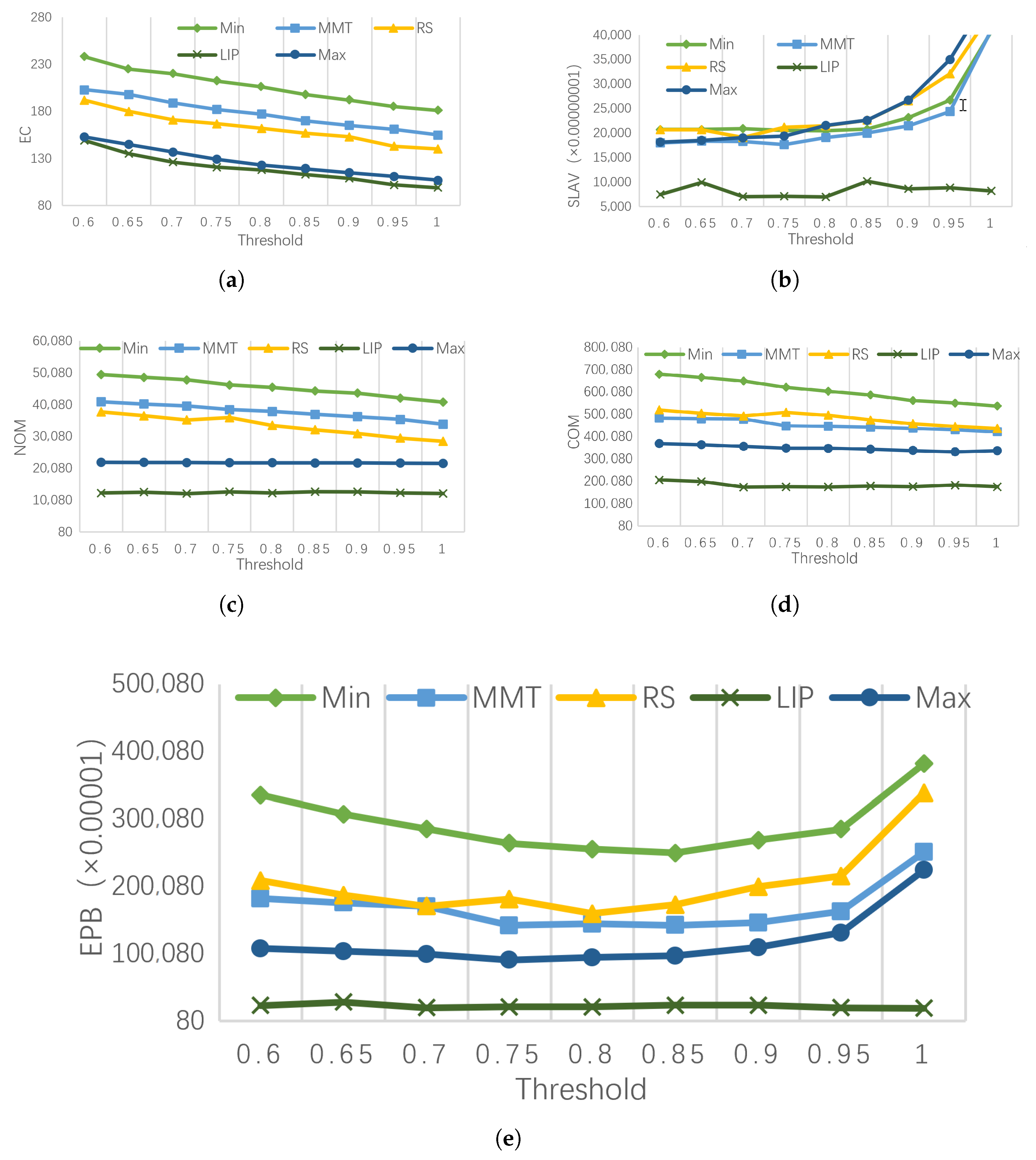
- (a)
EC (energy consumption) comparison
Figure 3a shows the energy consumption of different migration VM selection strategies under different PM load thresholds. Compared to Max, RS, Min, and MMT, LIP reduced energy consumption by approximately 10%, 25%, 45%, and 30%, respectively. It can be seen that the overall energy consumption of the data center presents a downward trend as the load threshold increases. In addition, choosing VM with a relatively high load to migrate causes less energy consumption. The reasons are due to two aspects. First, when the load of the VM is small, it is easy to use the remaining fragment resources to select the target PM. Therefore, it is easier to minimize the number of PMs in the process of VMC and reduce energy consumption. However, VM load increasing is more likely to happen if the VM load is too small. The load of the data center will be unbalanced due to the dynamic changes of the load after the integration. Finally, it will reduce the average resource utilization and increase energy consumption of the data center. Second, the more frequent VMC causes the PM state to be switched more frequently, which needs to consume additional energy [
30,
31].
- (b)
SLAV (SLA violation) comparison
Figure 3b shows the SLAV under different PM load thresholds for different migration VM selection strategies. Compared to Max, RS, Min, and MMT, LIP reduced SLAV by approximately 55%, 60%, 59%, and 53%, respectively. The SLAV of LIP is significantly smaller than those of the other algorithms. In particular, when the load threshold is close to 100%, the SLAV of LIP does not drastically increase. This is because LIP has an overall analysis and prediction of the VM load change trend, which kept the PM load as saturated as possible after the VM migration, thereby effectively reducing the probability of the PM resource competition.
- (c)
NOM (Number of Migration) and COM (Cost of Migration) Comparison
Figure 3c,d show the number of VM migrations (NOM) and the cost of migration (COM) for different migration VM selection strategies under different PM load thresholds. Compared to Max, RS, Min, and MMT, LIP reduced the cost of migration by approximately 43%, 61%, 66%, and 57%, respectively.
The experimental result shows that when the VM with high CPU load is selected to be migrated, the number of migration and cost of migration are relatively low. The reason is that it significantly eases the competition for the CPU resources on the PM. Therefore, the number of VMs to be migrated will be effectively reduced. In addition, MMT differs drastically from RS in terms of NOM and COM. Because the overall load of VMs with low COM is relatively small, frequent VMC is likely to occur, resulting in more VM migrations. However, due to the short migration time, the cost is effectively reduced.
- (d)
EPB (energy performance balance) comparison
Figure 3e shows EPB for each migration VM selection strategy under different PM load thresholds. Compared to Max, RS, Min, and MMT, the EPB of LIP was reduced by approximately 75%, 88%, 91%, and 87%, respectively. As can be seen from
Figure 3e, energy consumption and service performance reach the best balance when the load threshold is around 0.8. In the process of increasing the load threshold, the EPB of LIP remains stable, which fully demonstrates the accuracy of LIP in the selection of the migration VM.
4.3.2. The Evaluation of VM Migration Point Selection Strategy
Our SIR algorithm was compared with random selection (RS) [
9], minimum energy increase (MEI), and minimum resource fragmentation (MRF). In order to exclude the influence of the migration VM selection strategy, the random selection strategy was adopted uniformly in this experiment.
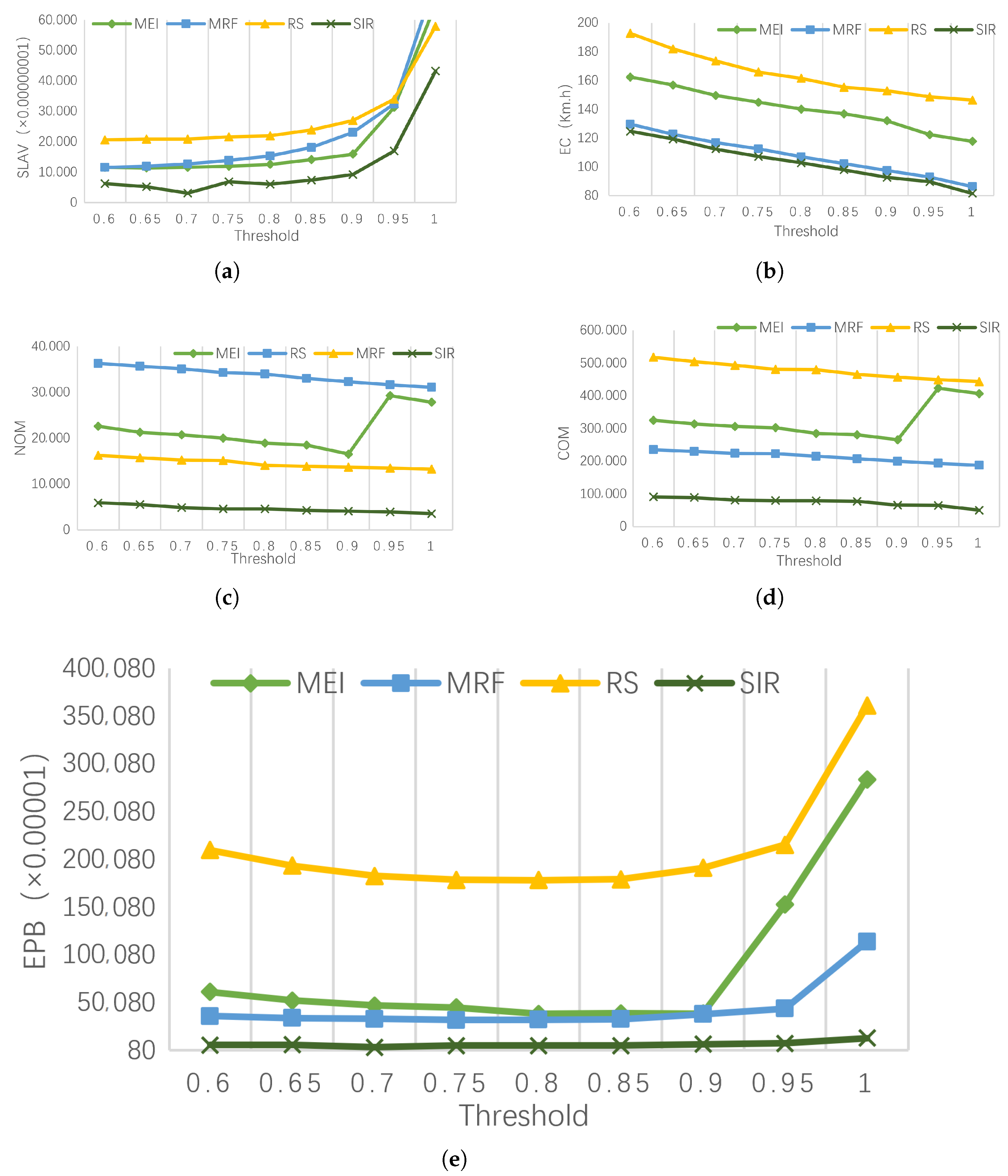
- (a)
EC (energy consumption) comparison
Figure 4a shows the energy consumption under different PM load thresholds for different strategies. Compared to MEI, RS, and MRF, SIR reduced energy consumption by approximately 30%, 41%, and 6%, respectively. Although the goal of MEI is to minimize the increase in energy, the energy consumption is higher than that of MRF and SIR. The reason is that MEI fails to fully utilize the resource fragmentation of the PM, resulting in a low utilization rate of the data center. The goal of MRF is to minimize resource fragmentation and has a significant reduction in energy consumption compared to RS and MRF. The goal of SIR is to increase the smoothness of the PM load sequence. When the PM load sequence is smooth, the utilization rate of PM will increase, therefore reducing the energy consumption of data center.
- (b)
SLAV (SLA violation) comparison
Figure 4b shows the SLAV of different strategies under different PM load thresholds. Compared to MEI, RS, and MRF, the SLAV of SIR was reduced by approximately 55%, 79%, and 64%, respectively. First, the SLAV increases with the increase of the load threshold. When the load threshold exceeds 0.8, the SLAV increases sharply. Secondly, the SLAV of MEI is lower than MRF. This is because MRF makes the PM resources fragmentation smaller, which increases the risk of resource competition. SIR makes the PM load more stable and effectively reduces the SLAV caused by the full load of the PM CPU.
- (c)
NOM (number of migration) and COM (cost of migration) comparison
Figure 4c,d respectively show NOM and COM for different strategies under different PM load thresholds. Compared with MEI, RS, and MRF, SIR reduced COM by approximately 23%, 87%, and 60%, respectively. SIR makes the PM load sequence smooth, and the performance improvement effect in terms of NOM and COM is obvious. When the load threshold reaches 0.9, NOM and COM of MEI dramatically increase because MEI fails to consider the intense competition of PM resources. Secondly, there is a clear consistency between NOM and COM because the choice of VM migration points does not affect the VM migration cost.
- (d)
EPB (energy performance balance) comparison
Figure 4e shows the EPB for different strategies under different PM load thresholds. Compared to MEI, RS, and MRF, SIR reduced energy consumption by approximately 91%, 77%, and 88%, respectively. It can be seen that energy consumption and service performance reach the optimal balance when the load threshold is around 0.8. SIR demonstrated performance improvements over the other strategies.
All the above experimental results show that the proposed VMC algorithm has better efficiency good in terms of accuracy, stability, and energy efficiency than existing schemes. Therefore, it can reduce the cloud computing pressure brought by the growth of IoT devices.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}