1. Introduction
Recently, tensor operations have emerged as an important ingredient of many signal processing and machine learning applications [
1]. These operations are typically complex due to the large size of the associated tensors. Therefore, in the interest of a low execution time, such computations are often performed in a distributed fashion and outsourced to a cloud of multiple workers that operate in parallel over the distributed data set. These workers in many cases consist of commercial off-the-shelf servers that are characterized by failures and varying execution times. Such straggling servers are handled by state-of-the art cloud computation platforms via a repetition of the computation task at hand. However, recent work has shown that encoding the input data may help alleviate the straggler problem and thus reduce the computation latency, which mainly depends on the amount of stragglers present in the cloud computing environment; see [
2,
3]. More generally, it has been shown that coding can control the trade-off between computational delay and communication load between workers and master server [
3,
4,
5,
6]. In addition, the workers in the cloud may not be trustworthy, so the input and output of the partial computations need to be protected against unauthorized access. To this end, it has been shown that stochastic coding can help keep both input and output data secure from eavesdropping and colluding workers (see, for example, [
7,
8,
9,
10,
11,
12,
13,
14]).
In this work, we focus on the canonical problem of distributing the multiplication of two matrices A and B, i.e., , whose content should be kept secret from a prescribed number of colluding workers in the cloud. Our goal is to minimize the number of workers from which the partial result must be downloaded, the so-called recovery threshold, to recover the correct matrix product C.
Coded matrix computation was first addressed in the non-secure case by applying separate MDS codes to encode the two matrices [
3]. In [
5], polynomial codes have been introduced, which improves on the recovery threshold of [
3]. The recovery threshold was further improved by the so-called MatDot and PolyDot codes [
15,
16] at the expense of a larger download rate. In particular, PolyDot codes allow a flexible trade-off between the recovery threshold and the download rate, depending on the application at hand.
In [
17,
18] two different schemes are presented, an explicit scheme that improves on
the recovery thereshold of PolyDot codes and a construction based on the tensor rank
of matrix multiplication, which is optimal up to a factor of 2. In [
19] a new construction
for private and secure matrix multiplication is proposed based on entangled polynomial
codes, which allows for a flexible trade-off between the upload rate and the download
rate (equivalently, the recovery threshold). For small numbers of stragglers [
20] constructs
schemes that outperform the entangled polynomial scheme. Recently, several attempts have been made to design coding schemes to further reduce upload and download rates, the recovery threshold, and computational complexity for both workers and server (see, for example, [
20,
21,
22,
24,
25,
26,
27]). For example, in [
21], bivariate polynomial codes were used to reduce the recovery threshold in specific cases. In [
22], the authors considered new schemes for the private and secure case which outperform [
19] for specific parameter regions. The work in [
23] considered distributed storage repair codes, so-called field-trace polynomial codes, to reduce the download rate for specific partitions of matrices
A and
B. Very recently, the authors in [
24] proposed a black-box coding scheme based on star products, which subsumes several existing works as special cases. In [
25], a discrete Fourier transform-based scheme with low upload rates and encoding complexity is proposed. The work in [
26] focused on selecting the evaluation points for the polynomial codes, providing a better upload rate than [
9], but worse than [
25].
In the following, we propose a new scheme for secure matrix multiplication, which provides explicit evaluation points for the polynomial codes, but unlike the work in [
26], is also able to tolerate stragglers. Specifically, we exploit gaps in the underlying polynomial code. This is motivated by the observation that the recovery threshold can be improved by selecting the number of evaluation points to be equal to the number of only the
non-zero coefficients in the polynomial [
9,
19]. In addition, selecting dedicated evaluation points has the advantage that the condition for security against colluding workers is automatically satisfied (see, for example, condition C2 in [
27]). As such, our approach is able to provide a constructive scheme with provable security guarantees. Further, our coding scheme provides an advantage in terms of download rate in some cases, and is both straggler-tolerant and robust against Byzantine attacks on the workers.
This paper is organized as follows. In
Section 2, the problem statement and the background is highlighted.
Section 3 discusses design and properties of our proposed scheme and provides performance guarantees with respect to the number of helper nodes needed for recovery, security, straggler tolerance and under Byzantine attacks.
Section 4 extends the scheme of
Section 4 by introducing gaps into the code polynomials and by studying its properties. Finally,
Section 5 presents numerical results and comparisons with state-of-the-art schemes from the literature.
2. Problem Statement and Background
Let
A and
B be a pair of matrices over the finite field
, whose product is well defined. We consider the problem of computing the product
. The computation will be distributed among a number of helper nodes, each of which will execute a portion of the total calculation. We also assume that the user wishes to hide the data contained in the matrices
A and
B and that up to
T honest but curious helper nodes may collude to deduce information about the contents of
A and
B. To divide the work among the helper nodes, the matrices
A and
B are each divided into
and
blocks, respectively, of compatible dimensions, say
and
. The matrices are also assumed to have independent and identically distributed uniformly distributed entries from a sufficiently large field of cardinality
, where
N denotes the number of servers to be employed (in fact, we will require
q to exceed the degree of a polynomial
, central to this scheme). Hence, for given matrix partition of
A and
B according to
we obtain
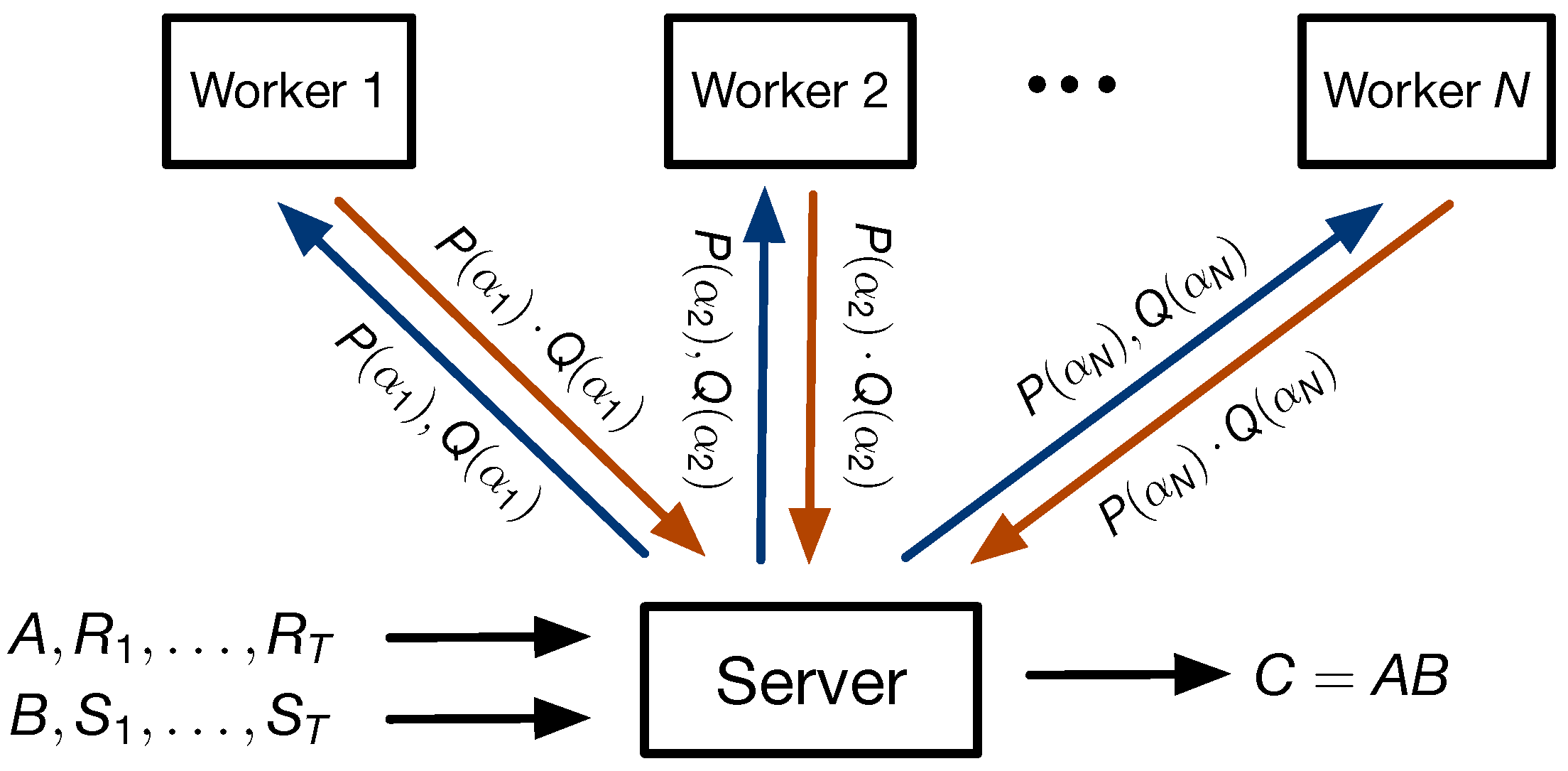
The system model is displayed in
Figure 1. We consider a distributed computing system with a master server and
N helper nodes or workers. The master server is interested in computing the product
. In
Figure 1, the worker receives matrices
A and
B and
T random uniformly independent and identically distributed matrices of size
and
for
. To keep the data secure and to leverage possible computational redundancy at the workers, the server sends encoded versions of the input matrices to the workers. This security constraint imposes the mutual information condition
between the pair
and their encodings
for all subsets
of maximum cardinality
T. The server generates a polynomial representation of
A and
by constructing a polynomial
. Likewise, a polynomial representation of
B and
results in a polynomial
. The polynomial encodings that the
p-th worker receives comprise the two polynomial evaluations
and
, for distinct evaluation points
with
. It then computes the matrix product
and sends it back to the server. The server collects a subset of
outputs from the workers as defined by the evaluation points in the subset
with
. The size of the smallest possible subset
for which perfect recovery is obtained, i.e.,
where
H denoted the entropy function, is defined as the
recovery threshold. The server then interpolates the underlying polynomial such that the correct product
can be assembled from a combination of the interpolated polynomial coefficients
(see
Section 3 for details).
We further define the
upload rate per worker as the sum of the dimensions of
and
, i.e.,
field elements of
. Likewise, the
download rate or
communication load is defined as the total number of field elements to be downloaded from the workers such that (
2) is satisfied, i.e.,
.
Notation. For the remainder, we fix to be matrices over such that , and we fix to be the integers as defined above. We define for any positive integer n. For each , and , we write , and to denote the and blocks of and C, respectively. The transpose of a matrix Z is denoted by .
3. Proposed Scheme
The scheme we propose uses a similar approach to the schemes in [
9,
19,
27]. We will begin with the choices for exponents in
and
and show that the desired blocks of
C appear as coefficients of the product
. We discuss the maximum possible degree of
since it gives us an upper bound on the necessary evaluations, and hence workers, needed to interpolate
. In
Section 3.3, we give explicit criteria for choices of evaluation points and prove that the scheme protects against collusion of up to
T servers.
Section 3.4 discusses the option to query additional servers to provide resilience against stragglers and Byzantine servers.
Section 4 uses ideas from the GASP scheme [
9] to reduce the recovery threshold by examining how many coefficients in the product are already known to be zero.
3.1. Choice of Exponents and Maximal Degree
We propose the following scheme to outsource the computation among the worker servers. The model will incorporate methods to secure the privacy of the data held by the matrices and C.
Let
. For the given
A and
B, we define the polynomials:
We now define polynomials
where and
are a pair of matrix polynomials:
whose coefficients are
and
matrices over
, respectively, chosen uniformly at random.
In the next theorem, we show that the desired matrices appear as coefficients of the product and can hence be retrieved by inspection of this product.
Theorem 1. For each pair , the block arising in the product appears as the coefficient of in the product .
Proof. Consider the exponents modulo D. The first term in the sum of terms above is the product . Any of the exponents of x in this term are equal to if and only if , in which case its corresponding coefficient is . In particular, the matrix block appears in the product as the coefficient of .
We claim that no other exponent of x in is equal to , from which the result will follow. Observe that the exponents in the second and third term of the product (i.e. those of ) are all between 1 and M modulo D, while every exponent of x in the fourth term, which is , is a multiple of D.□
In order to retrieve the polynomial
, we may evaluate
P and
Q at a number of distinct values
in
. The values
and
are found at a cost of zero non-scalar operations. Define
The
-entries of the coefficients of
can be retrieved by computing the product
if the degree of
is at most
N. Since this computation involves only
-linear computations, the total non-scalar cost is the total cost of performing the
matrix products
. In the distributed computation scheme as shown in
Figure 1, the server uploads each pair of evaluations
to the
i-th worker node, which then computes the product
and returns it to the server.
In this approach to reconstructing
, we require the participation of
worker nodes, where
N is the degree of
. For this reason, we study this degree. Since
we have the following result, wherein each of the values
to
correspond to the maximum possible degrees of
and
, respectively. We write
to denote the maximum possible degree of the polynomial
, as the
range over all possible matrices of the stated sizes.
Proposition 1. The degree of is upper bounded by , where Proposition 2. The following are equivalent.
,
,
.
Proof. First note that
and that
Since
is an integer, we thus have that the following inequalities are equivalent to
:
This shows that
if and only if
. Similarly, using the 2nd and 3rd inequalities just above, we have
from which we see that
if and only if
.□
Proposition 3. The following are equivalent.
,
,
.
Proof. We have the following inequalities:
from which we deduce that
. We now show that
>
. We have:
□
We tabulate (see
Table 1) the value of
based on the observations of Propositions 2 and 3.
3.2. versus
We compare the recovery threshold cost of calculating rather than . It can be shown that it is always better to calculate whenever . That is, we show that for . We consider all possible cases for the maximal degree in the following two theorems and remarks.
Proof. Since
, and
by Propositions 2 and 3 we have that
and so
.
Similarly, since
, and
, we have that
. Clearly,
if and only if:
By Propositions 2 and 3, the assumptions and imply that , while the assumptions and yield that .
Clearly, since
, we have
and
From the given assumptions, by Propositions 2 and 3, we have
and
. Since
, as in the proof of Proposition 3, we have
For the given assumptions the statement follows immediately from Propositions 2 and 3.
From the given assumptions, by Propositions 2 and 3, we have and . The rest follows immediately from .
□
Remark 1. Clearly, if and then . In this case, from Propositions 2 and 3, we have that .
Theorem 3. Let and .
- (i)
Assume and then .
- (ii)
Assume and then .
Proof. - (i)
Since we have that
and so the result follows.
- (ii)
We see that
□
Remark 2. The remaining two cases lead to a contradiction and can hence never occur. Let and and . By Remark 1, we have that and we obtain the contradiction .
3.3. T-Collusion
Each query is masked with a polynomial of the form
, where
is chosen uniformly at random. A query is private in the case of
T servers colluding if and only if the matrix
has full rank for any subset of
T evaluation points. This is the same as condition C2 in [
27]. Because of the very specific set of exponents used, we can give a more explicit condition for the invertibility of this matrix.
Proposition 4. The matrix is invertible if and only if the elements are distinct.
Proof. is a Vandermonde matrix with entries .□
Proposition 5. A set of elements of such that their powers are pairwise different has size at most .
Proof. Fix a generator γ of . Then the image of the map from to is given by 0 together with all powers where .□
Corollary 1. Let . If , then the scheme in Section 3 is secure against T-collusion for any choice of evaluation points. 3.4. Stragglers and Byzantine Servers
Considering the scheme as described in the previous section, we see that the responses are the coordinates of a codeword of a Reed–Solomon code. The polynomial that needs to be interpolated has degree at most , and hence evaluation points suffice for reconstruction. Any evaluation points are admissible and hence we have the following theorem.
Theorem 4. The scheme in Section 3 is straggler resistant against S stragglers if helper nodes are used. Proof. The responses can be considered as a codeword in an RS code, with S erasures. Since S is smaller than the minimum distance of the code, the full codeword and hence the interpolating polynomial can be recovered.□
Similarly, we can use additional helper nodes to account for possible Byzantine servers whose responses are incorrect.
Theorem 5. The scheme in Section 3 is resistant against Byzantine attacks of up to B helper nodes if helper nodes are used. Proof. The responses can be considered as a codeword in an RS code, with B errors. Since is smaller than the minimum distance of the code, the full codeword and hence the interpolating polynomial can be recovered.□
Combining both theorems give us the following corollary.
Corollary 2. The scheme in Section 3 is resistant against S stragglers and B Byzantine helper nodes if helper nodes are used. 4. Gaps in the Polynomial
The upper bound on the recovery threshold given by the maximum degree of the product
can actually be improved if we choose instead to use the fact that we need only as many servers as non-zero coefficients. Similar to considerations in [
9], as a basic observation of linear algebra, we note that only as many evaluation points as there are possible non-zero coordinates are required to retrieve the required matrix coefficients of
. Let
have degree
and suppose that
. Let
be distinct elements of
. Suppose that the zero coefficients of
are indexed by
and let
. There exist
such that the
matrix
V, found by deleting the columns of
indexed by
, is invertible. Then, each
-entry of the unknown coefficients of the polynomial
can be retrieved by computing the product
Theorem 6. Let , . LetThe number N of non-zero terms in the product satisfies Proof. We have
and
. Recall that
and
have disjoint support, as do
and
. From Theorem 1, for each each
, the matrix
is the coefficient of
in
for
Clearly, each such coefficient
. The degrees of terms arising in the product
are given by
for
and
. The sequence (7) corresponds to terms that appear in the product
. By inspection, we see that no element
in any of the sequences (8)–(10) satisfies
: in (8) this would require
and in (9) this would require
, contradicting our choices of
. The total number of distinct terms to be computed is the number of distinct integers appearing in the union
of the elements of the sequences (7)–(10). Let
denote the set of integers appearing in (7). Observe that
, unless
, in which case
. Consider the set
We make the following observations with respect to
.
If , then ,
contains the elements of (8)
contains the elements of (9) ,
contains the elements of (10) .
Consider the following sets.
Clearly,
comprises the elements of the sequence (8) and the members of
are exactly those of the sequence (10). For
, we have
in which case
is exactly the set of elements of (9). It follows that
if and only if
. This minimum is
K if
and is 1 if
. Furthermore,
is disjoint from
and from
. If
or if
, then
, while if
, then
.
Suppose first that
. We thus have that
if
and
, or if
; in either of these cases,
has at most
non-zero terms. We summarize these observations as follows.
Hence
. If
then
and so, applying inclusion–exclusion, we see that, if
, then
In the case
, we have
, while if
then the elements of (9) are contained in
. Therefore,
and so for
we have
Finally, suppose that
. If
then, since
we have
. Similar to previous computations, we see
takes the same values as in the case for
. If
and
then
. Again using similar computations as before, we see in this case that
takes the same values as in the case for
. Suppose that
and
. In this case, the integers appearing in (9) comprise the set
We have
and moreover,
Therefore, .□
Example 1. Let , that is: We will compute the product using 32 helper nodes, assuming that servers may collude. Choose a pair of polynomialswhose non-zero matrix coefficients are chosen uniformly at random over . We have Define and . In Table 2, we show the exponents that arise in the product . The monomials corresponding to the computed data are , shown in blue. The coefficients of and are, respectively, given by
Note that the total number of non-zero terms in is , as predicted by Theorem 6. This also corresponds to the case for which has degree , which is consistent with Theorem 2. Therefore, 32 helper nodes are required to retrieve and hence the coefficients . If the matrices have entries over with , then since , the user can retrieve the data securely in the presence of 3 colluding workers.
Suppose now that we have colluding servers. In this case, we have and and so from Theorem 6, we expect the polynomial to have at most non-zero coefficients. These exponents are shown in the corresponding degree table for our scheme (see Table 3). In this case, to protect against collusion by 6 workers, we require a total of 44 helpers. While the degree of in this case is 50 (see Table 1), the coefficients corresponding to the exponents are zero, and hence known a priori to the user. Let α be a root of , so that α generates . Let V be the matrix obtained from by deleting the columns and rows indexed by . It is readily checked (e.g., as here, using MAGMA [28]) that the determinant of V is and in particular is non-zero. Therefore, we can solve the system to find the unknown coefficients of via the computation . We remark that for the case of no collusion, Theorem 6 does not yield an optimal scheme. The proposition below outlines a modified scheme with a lower recovery threshold if secrecy is not a consideration.
Proposition 6. The following hold:
Proof. For each , define the following:
,
.
The distinct monomials arising in the product
are those indexed by the distinct elements of
. It is straightforward to check that for each
, the integer
is not contained in
for any
and hence the required coefficients
that appear in the product
, which are indexed by the
, can be uniquely retrieved. We compute the number of workers required by this scheme. We have
□
The recovery threshold of this scheme takes the same value as the recovery threshold of the poly-entangled scheme of Theorem 1 [
18].
5. Results and Comparison with the State-of-the-Art
We provide some comparison plots that highlight parameter regions of interest. In
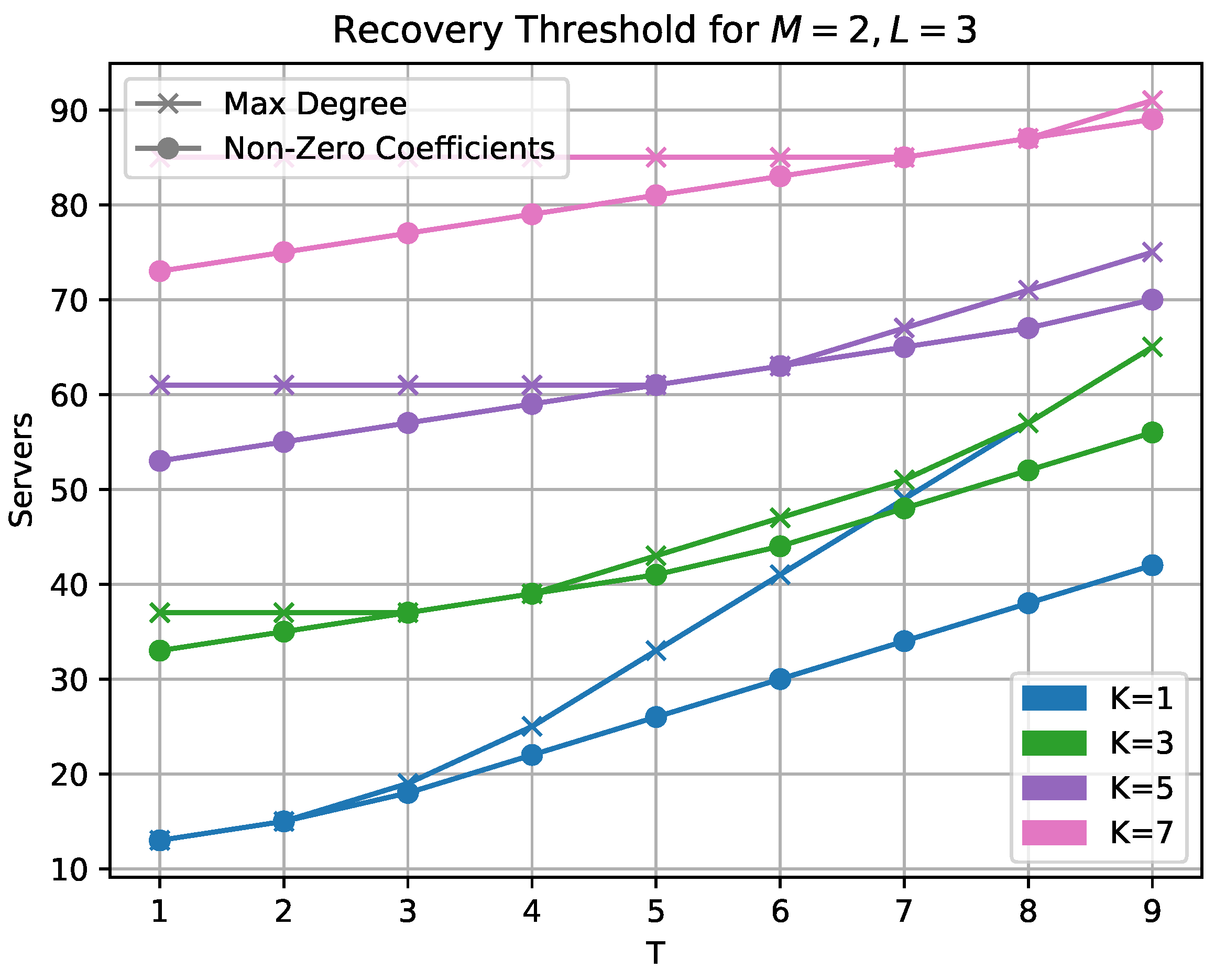
Figure 2, we compare the two variants of our own scheme. The recovery threshold when considering the maximal degree of the resulting product polynomial is shown alongside the count of possibly non-zero coefficients. We see that significant gains can be achieved, especially in the higher collusion number region.
In
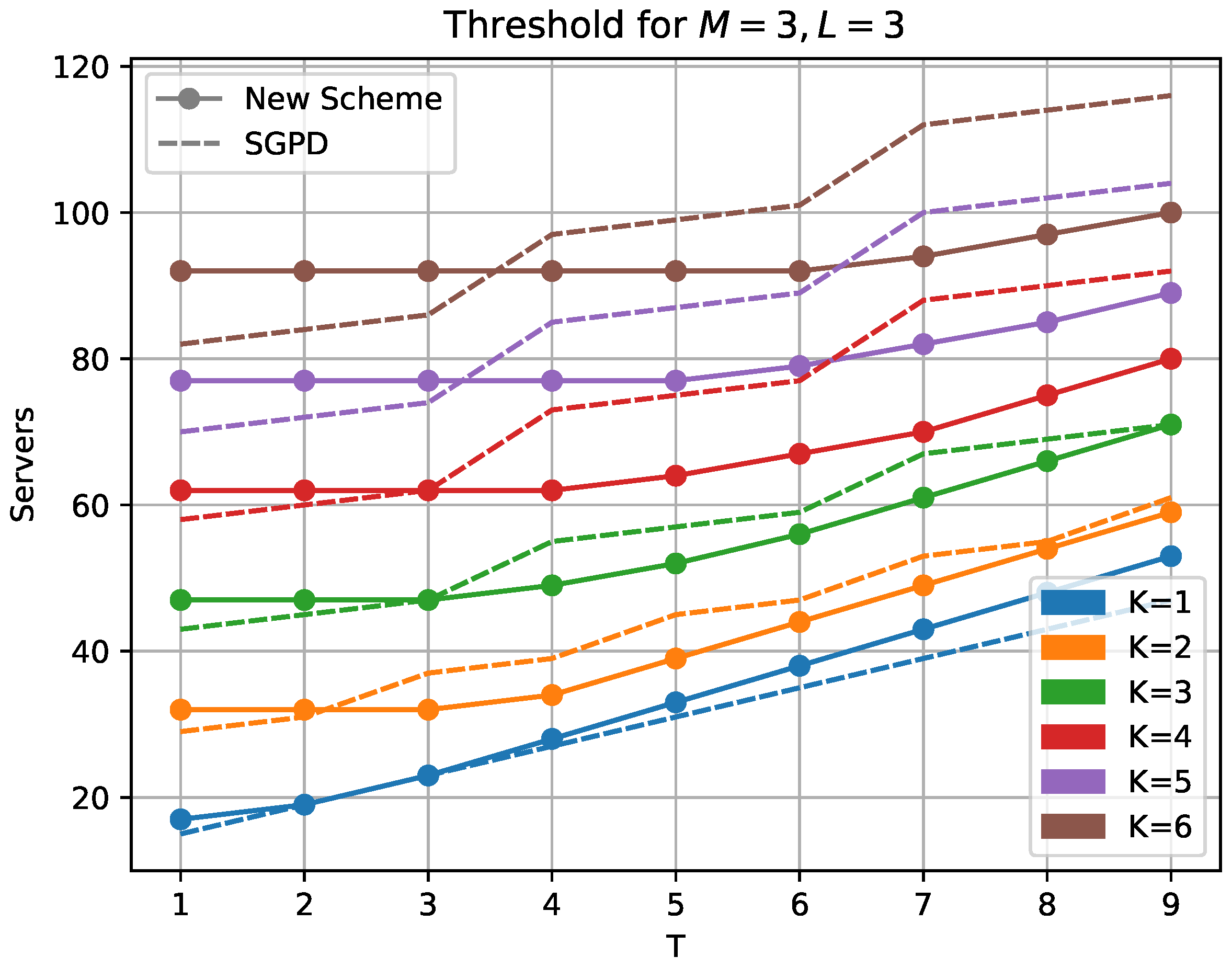
Figure 3, we compare our (non-zero coefficient) scheme with the SGPD scheme presented in [
19]. For
, we see that, except for very low values of
T, our new scheme outperforms the SGPD scheme. This comparison of the recovery threshold for the two schemes is well justified since they use the same division of the matrices and will have identical upload and download costs per server.
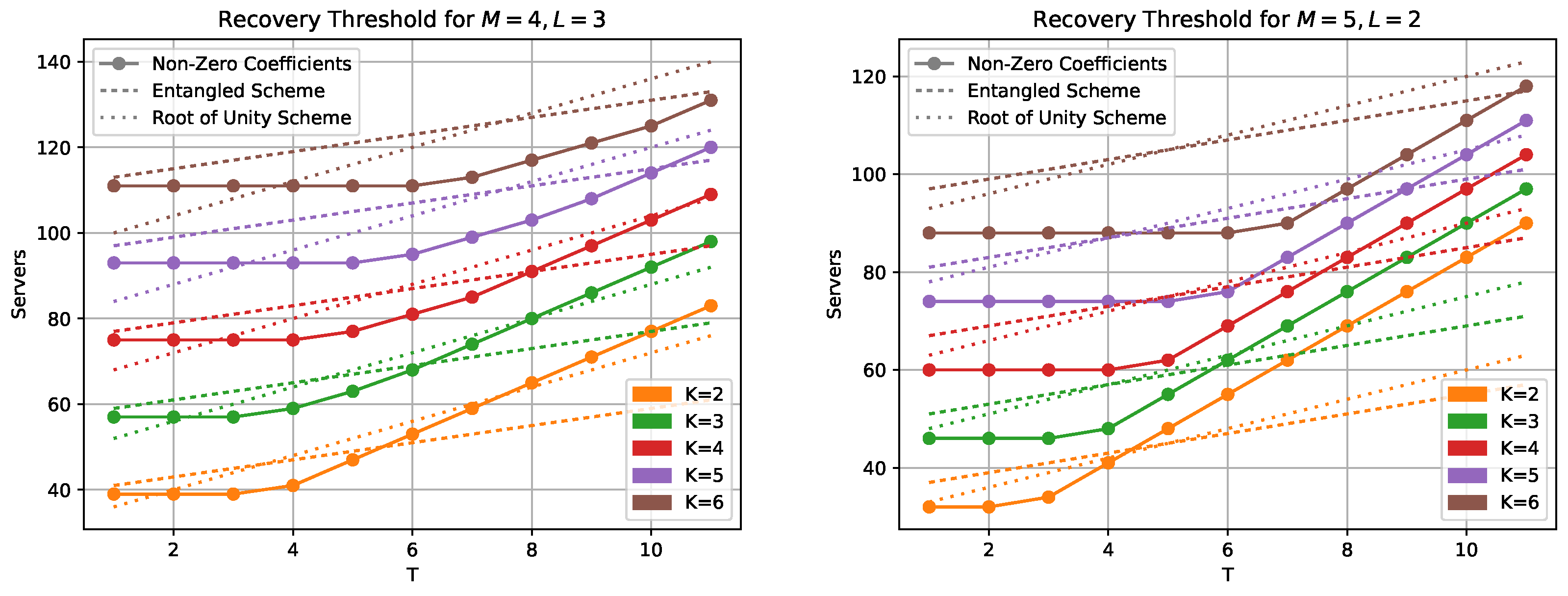
The comparison in
Figure 4 with the entangled codes scheme [
17] and a newer scheme using roots of unity [
26] shows that our new codes have lower recovery threshold for low number of colluding servers. Calculating the actual number of servers needed for the entangled scheme requires knowledge of the tensor rank of matrix multiplication. These ranks, or their best known upper bounds, are taken from [
29,
30]. It should be noted that the scheme in [
26] requires that either
or
where
q is the field size. The requirements for our scheme outlined in Proposition 5 and Corollary 1 (i.e., that
) are much less restrictive.
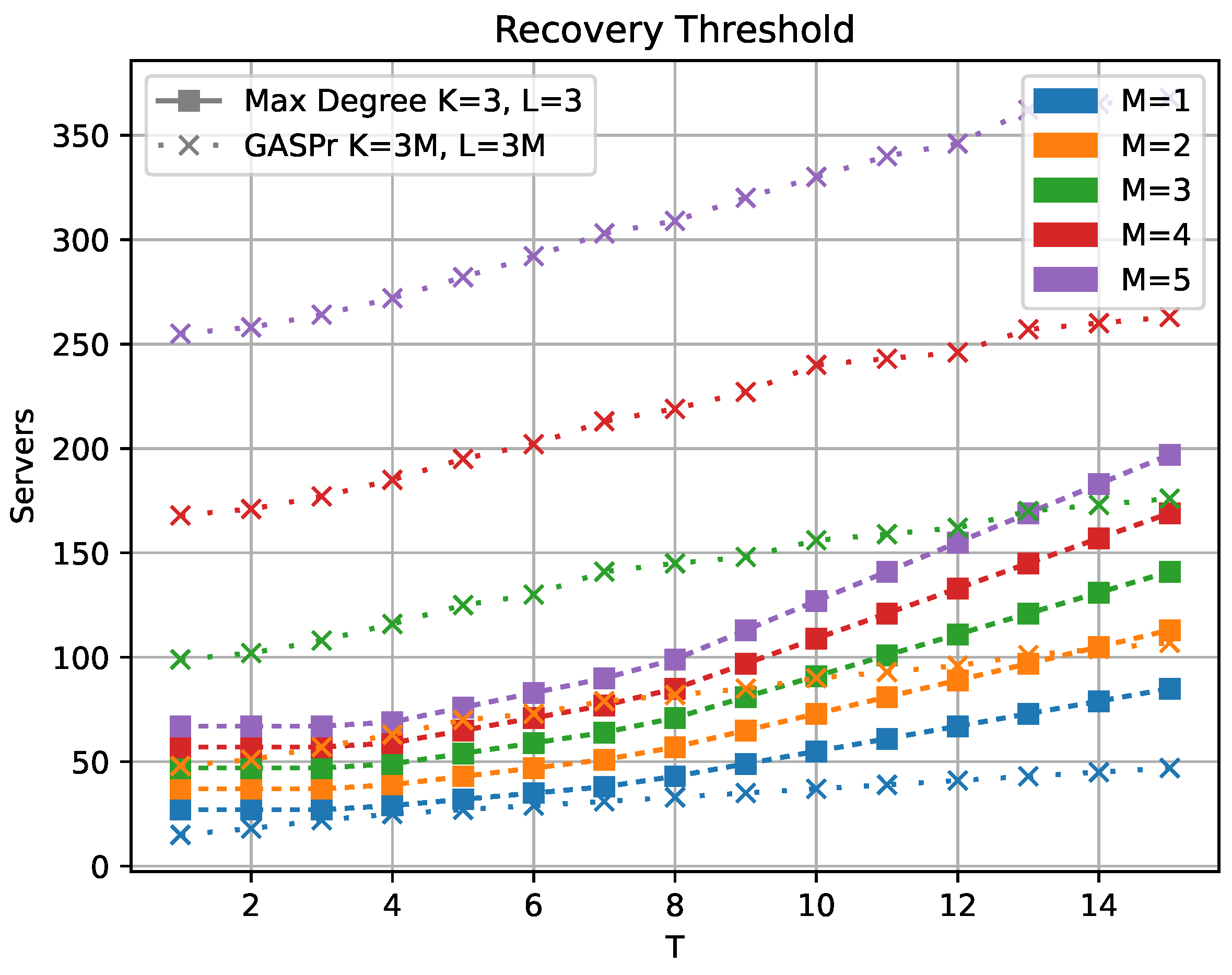
The comparison with the GASP scheme is less straightforward since the partitioning in GASP has a fixed value of
. The plot in
Figure 5 shows the recovery thresholds for the GASP scheme with partitioning
as well as the recovery thresholds of our scheme for
and varying
M from 1 to 5. We compare here with the maximal degree of our scheme, not the non-zero coefficients, to show that the variant of our scheme that is able to mitigate stragglers and Byzantine servers achieve much lower recovery thresholds. Fixing
K and
L to be the same value across this comparison means that the download cost per server is the same for all our schemes and the
GASP scheme. Note that in the
case, we have identical partition and hence upload cost per server as the
GASP scheme, while for
, we have identical upload cost with the
GASP scheme, and
corresponds to the
GASP scheme. We can see that the grid partitioning allows for a much lower recovery threshold when the upload cost is fixed. The outer partitioning of the GASP scheme allows for low download cost per server that makes up for the higher recovery threshold. Explicitly, the outer partition into
and
blocks allows for a download rate of
, where
is the recovery threshold for the GASP scheme. In contrast, the scheme presented in this paper will have a download rate of
if we partition into
and
blocks.
It should be noted though that our construction allows to explicitly control the field size needed. In contrast, the GASP scheme might have to choose its evaluations points from an extension field Theorem 1 [
9] if the base field is fixed by the entries of the matrices
A and
B, or just requires a very large base field. This would greatly increase the computational cost and the rates at all steps of the scheme. For example, for
, GASP
uses
servers and the exponents for the randomness in one of the polynomials are
. Then, there are no suitable evaluation points for
and so for these values of
q, an extension field is required.
Furthermore, the scheme presented in this paper can be used in situations where stragglers or Byzantine servers are expected as described in Corollary 2.
Complexity
We summarize the cost of
-arithmetic operations and transmission of
elements associated with this scheme, using
N servers. We refer the reader to ([
25],
Table 1) and ([
26],
Table 1) to view the complexity of other schemes in the literature (note that the costs defined in [
25] are normalized). There are various trade-offs in costs depending on the partitioning chosen (the proposed scheme is completely flexible in this respect), ability to handle stragglers and Byzantine servers, and constraints on the field size
q.
We remark that additions in general are much less costly than
-multiplications in terms of space and time: for example, if
, then an addition has space complexity (number of AND and XOR gates)
and costs 1 clock in time, while multiplication has space complexity
and time complexity
[
31,
32].
The encoding complexity of our scheme comes at the cost of evaluating the pair of polynomials and each at N distinct elements of . This is equivalent to performing (scalar) polynomial evaluations in . Given , the -entry of is an evaluation of an -polynomial with coefficients, while the -entry of is an evaluation of an -polynomial with coefficients.
The decoding complexity is the cost of interpolating the polynomial using N evaluation points, when has at most N unknown coefficients.
The cost of either polynomial evaluation at N points or interpolation of a polynomial of degree at most has complexity log log N). Therefore, we have the following statement.
Proposition 7. The encoding phase of the scheme presented in Section 3, using N servers, has complexity log log
N).
The decoding phase of the scheme presented in Section 3, using N servers, has complexity log log
N).
The total upload cost of the scheme presented in Section 3, using N servers, is . The total download cost of the scheme presented in Section 3, using N servers, is .









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}