

Forward-Backward Sweep Method for the System of HJB-FP Equations in Memory-Limited Partially Observable Stochastic Control

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Memory-Limited Partially Observable Stochastic Control
2.1. Problem Formulation
2.2. Problem Reformulation
3. Pontryagin’s Minimum Principle
3.1. Preliminary
3.2. Necessary Condition
3.3. Sufficient Condition
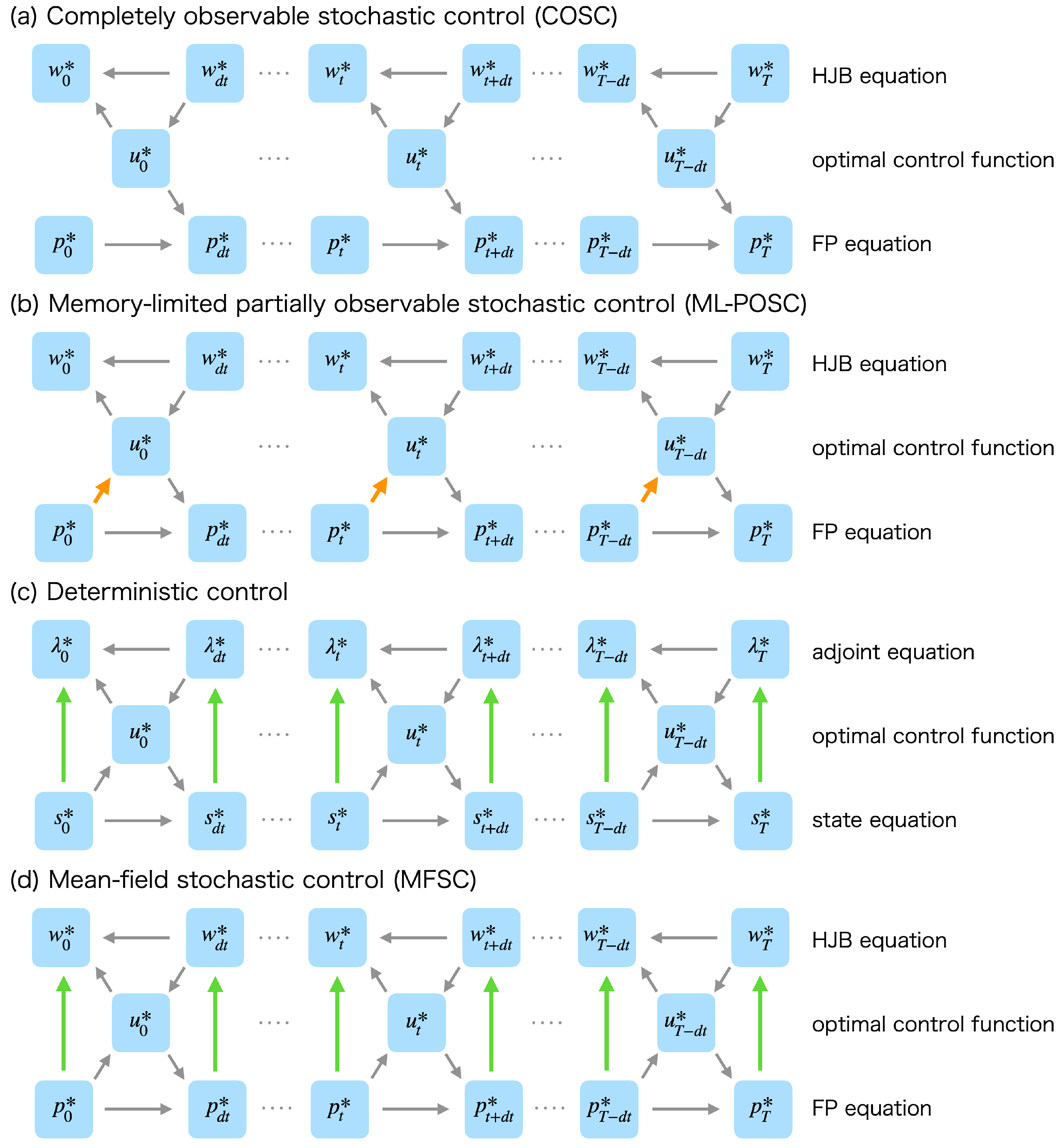
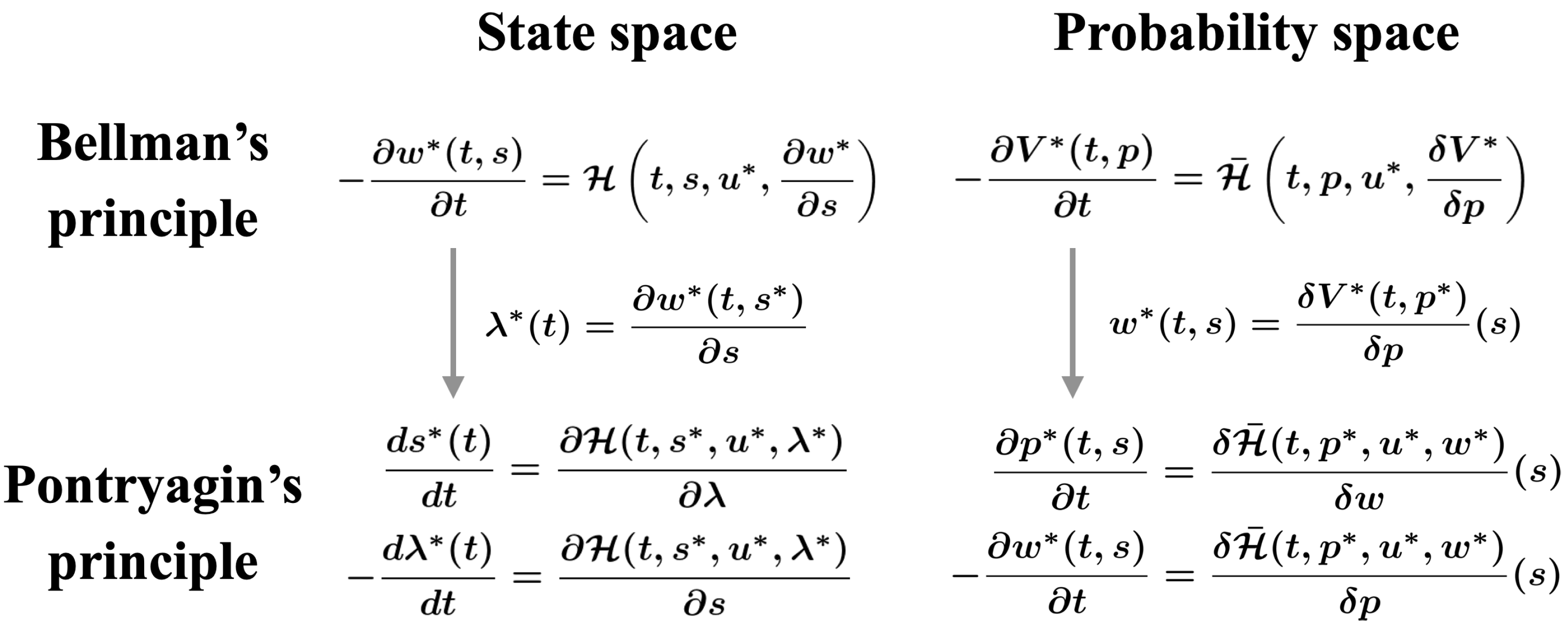
3.4. Relationship with Bellman’s Dynamic Programming Principle
3.5. Relationship with Completely Observable Stochastic Control
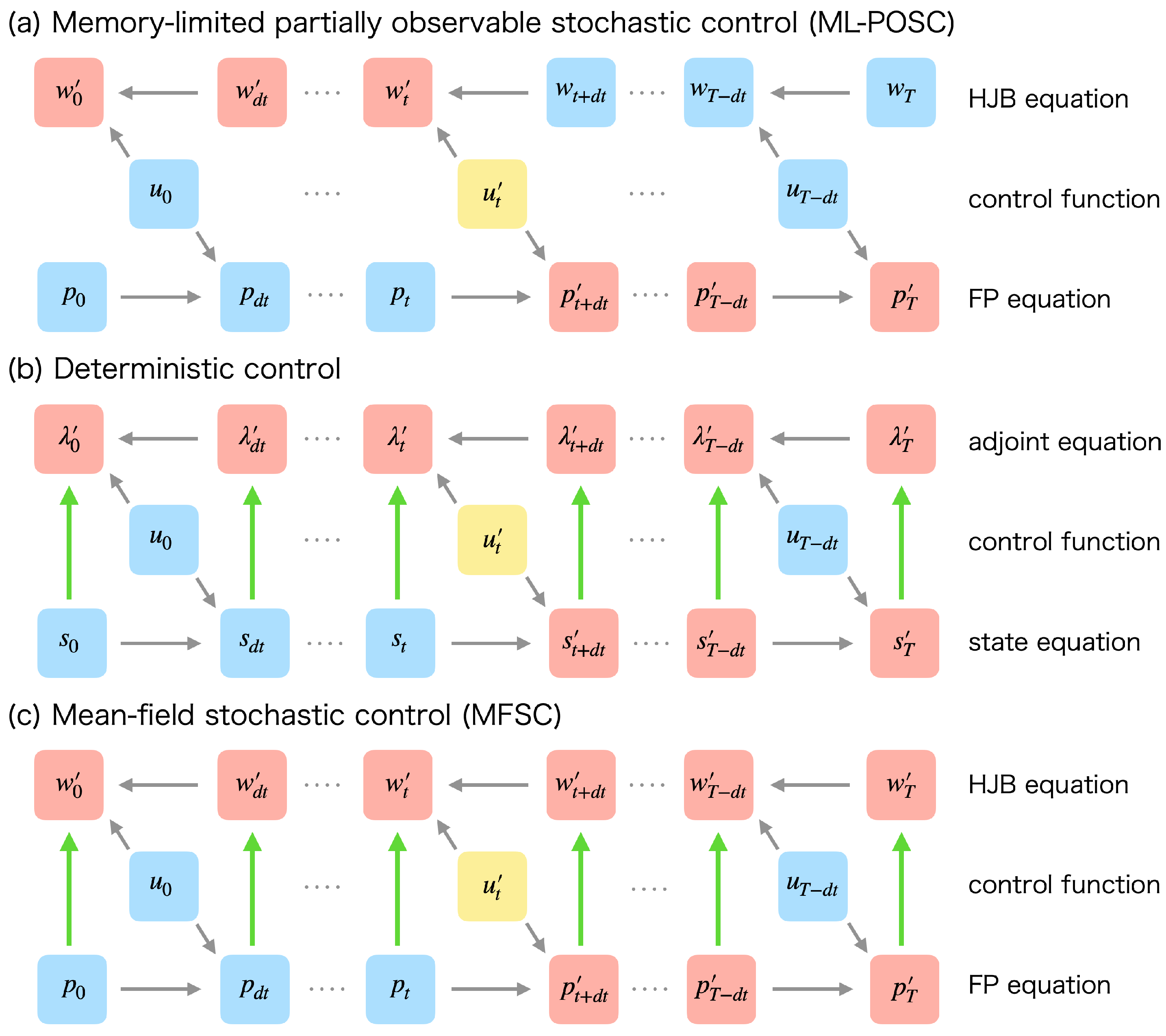
4. Forward-Backward Sweep Method
4.1. Forward-Backward Sweep Method
| Algorithm 1: Forward-Backward Sweep Method (FBSM) |
|
4.2. Preliminary
4.3. Monotonicity
4.4. Convergence to Pontryagin’s Minimum Principle
5. Linear-Quadratic-Gaussian Problem
5.1. Problem Formulation
5.2. Pontryagin’s Minimum Principle
5.3. Forward-Backward Sweep Method
| Algorithm 2: Forward-Backward Sweep Method (FBSM) in the LQG problem |
|
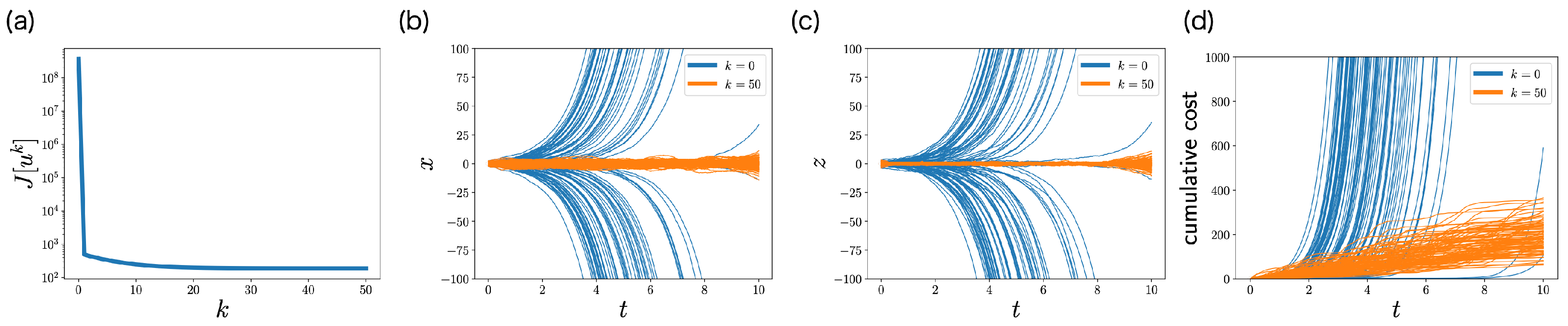
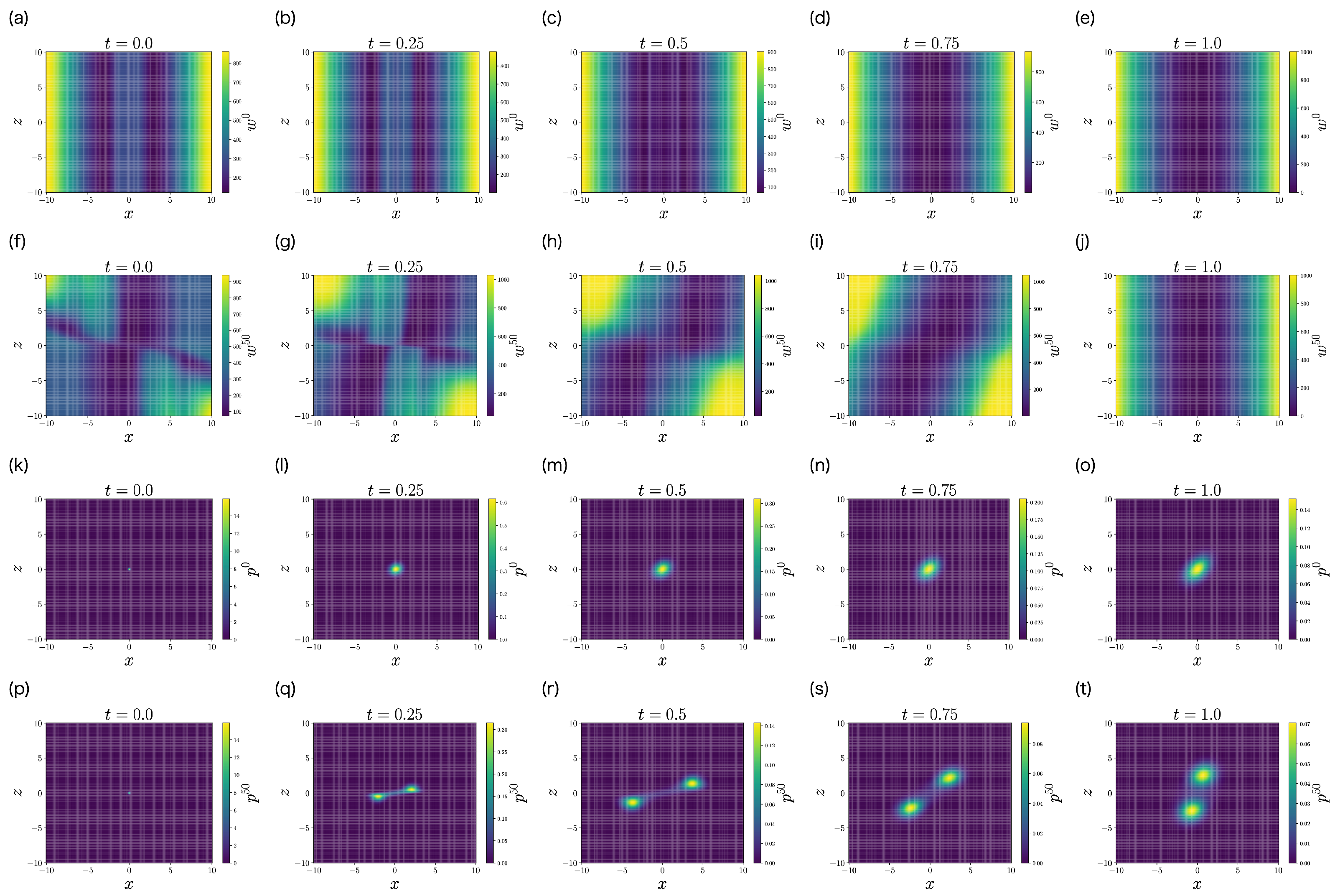
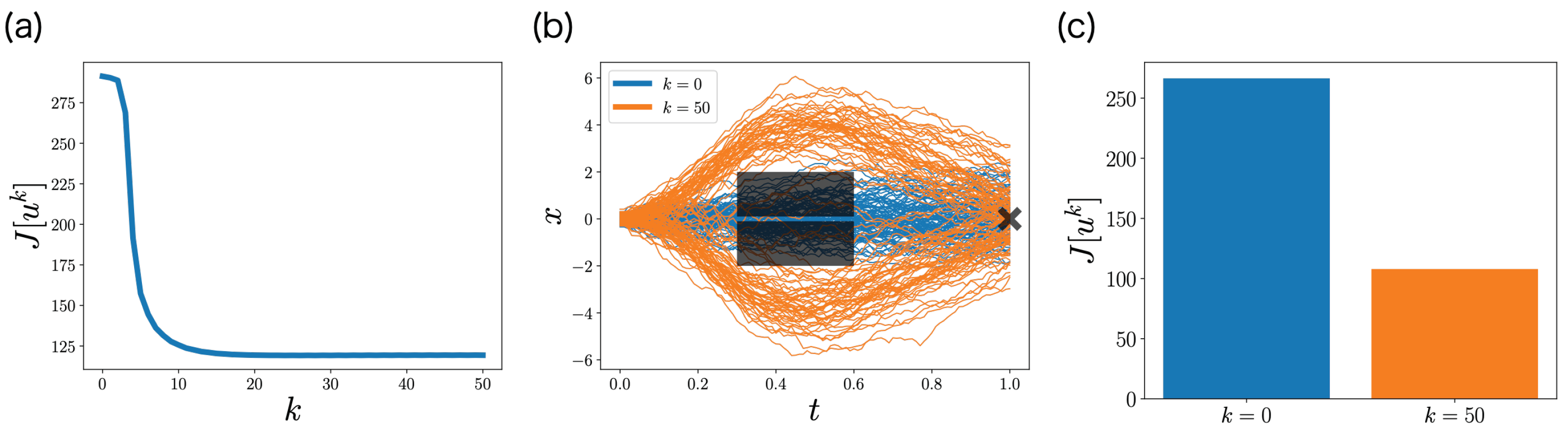
6. Numerical Experiments
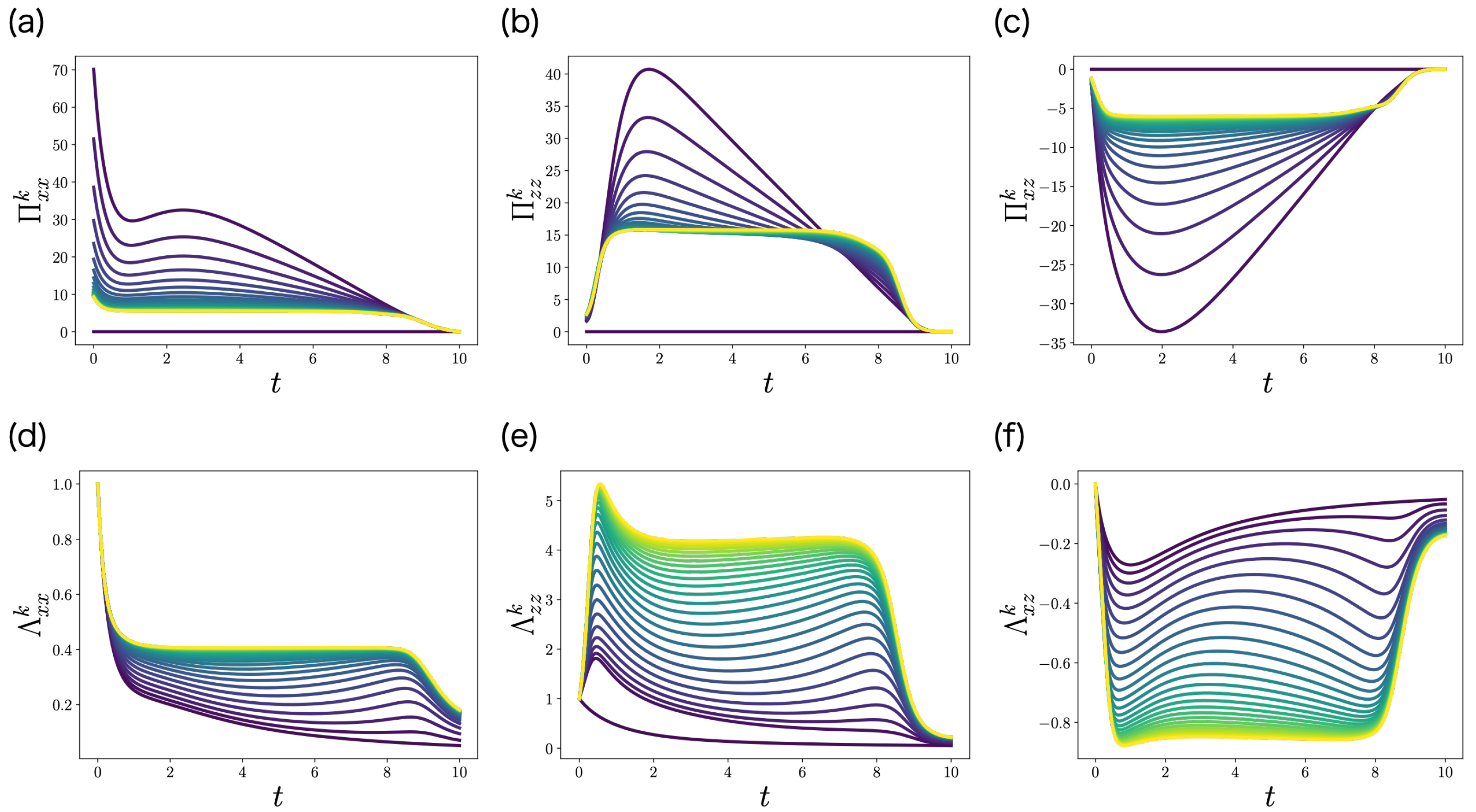
6.1. LQG Problem
6.2. Non-LQG Problem
7. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| COSC | Completely Observable Stochastic Control |
| POSC | Partially Observable Stochastic Control |
| ML-POSC | Memory-Limited Partially Observable Stochastic Control |
| MFSC | Mean-Field Stochastic Control |
| FBSM | Forward-Backward Sweep Method |
| HJB | Hamilton-Jacobi-Bellman |
| FP | Fokker-Planck |
| SDE | Stochastic Differential Equation |
| ODE | Ordinary Differential Equation |
| LQG | Linear-Quadratic-Gaussian |
Appendix A. Deterministic Control
Appendix A.1. Problem Formulation
Appendix A.2. Preliminary
Appendix A.3. Necessary Condition
Appendix A.4. Sufficient Condition
Appendix A.5. Relationship with Bellman’s Dynamic Programming Principle
Appendix B. Mean-Field Stochastic Control
Appendix B.1. Problem Formulation
Appendix B.2. Preliminary
Appendix B.3. Necessary Condition
Appendix B.4. Sufficient Condition
Appendix B.5. Relationship with Bellman’s Dynamic Programming Principle
Appendix C. Derivation of Main Results
Appendix C.1. Derivation of Result in Section 3.1
Appendix C.2. Derivation of Result in Section 3.2
Appendix C.3. Derivation of Result in Section 3.3
Appendix C.4. Derivation of Result in Section 3.5
Appendix C.5. Derivation of Result in Section 4.2 by the Similar Way as Pontyragin’s Minimum Principle
Appendix C.6. Derivation of Result in Section 4.2 by the Time Discretized Method
Appendix C.7. Derivation of Result in Section 4.3
Appendix C.8. Derivation of Result in Section 4.4
Appendix C.9. Derivation of Result in Section 5.3
References
- Fox, R.; Tishby, N. Minimum-information LQG control Part II: Retentive controllers. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 5603–5609. [Google Scholar] [CrossRef] [Green Version]
- Fox, R.; Tishby, N. Minimum-information LQG control part I: Memoryless controllers. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 5610–5616. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Todorov, E. An Iterative Optimal Control and Estimation Design for Nonlinear Stochastic System. In Proceedings of the 45th IEEE Conference on Decision and Control, San Diego, CA, USA, 13–15 December 2006; pp. 3242–3247. [Google Scholar] [CrossRef]
- Li, W.; Todorov, E. Iterative linearization methods for approximately optimal control and estimation of non-linear stochastic system. Int. J. Control. 2007, 80, 1439–1453. [Google Scholar] [CrossRef]
- Nakamura, K.; Kobayashi, T.J. Connection between the Bacterial Chemotactic Network and Optimal Filtering. Phys. Rev. Lett. 2021, 126, 128102. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, K.; Kobayashi, T.J. Optimal sensing and control of run-and-tumble chemotaxis. Phys. Rev. Res. 2022, 4, 013120. [Google Scholar] [CrossRef]
- Pezzotta, A.; Adorisio, M.; Celani, A. Chemotaxis emerges as the optimal solution to cooperative search games. Phys. Rev. E 2018, 98, 042401. [Google Scholar] [CrossRef] [Green Version]
- Borra, F.; Cencini, M.; Celani, A. Optimal collision avoidance in swarms of active Brownian particles. J. Stat. Mech. Theory Exp. 2021, 2021, 083401. [Google Scholar] [CrossRef]
- Davis, M.H.A.; Varaiya, P. Dynamic Programming Conditions for Partially Observable Stochastic Systems. SIAM J. Control. 1973, 11, 226–261. [Google Scholar] [CrossRef]
- Bensoussan, A. Stochastic Control of Partially Observable Systems; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar] [CrossRef]
- Fabbri, G.; Gozzi, F.; Święch, A. Stochastic Optimal Control in Infinite Dimension. In Probability Theory and Stochastic Modelling; Springer International Publishing: Cham, Switzerland, 2017; Volume 82. [Google Scholar] [CrossRef]
- Wang, G.; Wu, Z.; Xiong, J. An Introduction to Optimal Control of FBSDE with Incomplete Information; Springer Briefs in Mathematics; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Bensoussan, A.; Yam, S.C.P. Mean field approach to stochastic control with partial information. ESAIM Control. Optim. Calc. Var. 2021, 27, 89. [Google Scholar] [CrossRef]
- Tottori, T.; Kobayashi, T.J. Memory-Limited Partially Observable Stochastic Control and Its Mean-Field Control Approach. Entropy 2022, 24, 1599. [Google Scholar] [CrossRef]
- Kushner, H. Optimal stochastic control. IRE Trans. Autom. Control. 1962, 7, 120–122. [Google Scholar] [CrossRef]
- Yong, J.; Zhou, X.Y. Stochastic Controls; Springer: New York, NY, USA, 1999. [Google Scholar] [CrossRef]
- Nisio, M. Stochastic Control Theory. In Probability Theory and Stochastic Modelling; Springer: Tokyo, Japan, 2015; Volume 72. [Google Scholar] [CrossRef]
- Bensoussan, A. Estimation and Control of Dynamical Systems. In Interdisciplinary Applied Mathematics; Springer International Publishing: Cham, Switzerland, 2018; Volume 48. [Google Scholar] [CrossRef]
- Kushner, H.J.; Dupuis, P.G. Numerical Methods for Stochastic Control Problems in Continuous Time; Springer: New York, NY, USA, 1992. [Google Scholar] [CrossRef]
- Fleming, W.H.; Soner, H.M. Controlled Markov Processes and Viscosity Solutions, 2nd ed.; Number 25 in Applications of Mathematics; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; Wiley-Interscience: Hoboken, NJ, USA, 2014. [Google Scholar]
- Pontryagin, L.S. Mathematical Theory of Optimal Processes; CRC Press: Boca Raton, FL, USA, 1987. [Google Scholar]
- Vinter, R. Optimal Control; Birkhäuser Boston: Boston, MA, USA, 2010. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.; Syrmos, V.L. Optimal Control; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Aschepkov, L.T.; Dolgy, D.V.; Kim, T.; Agarwal, R.P. Optimal Control; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Bensoussan, A.; Frehse, J.; Yam, P. Mean Field Games and Mean Field Type Control Theory; Springer Briefs in Mathematics; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Carmona, R.; Delarue, F. Probabilistic Theory of Mean Field Games with Applications I; Number Volume 83 in Probability Theory and Stochastic Modelling; Springer Nature: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Carmona, R.; Delarue, F. Probabilistic Theory of Mean Field Games with Applications II; Volume 84, Probability Theory and Stochastic Modelling; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Carmona, R.; Delarue, F. The Master Equation for Large Population Equilibriums. In Stochastic Analysis and Applications 2014; Crisan, D., Hambly, B., Zariphopoulou, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 100, pp. 77–128. [Google Scholar] [CrossRef] [Green Version]
- Bensoussan, A.; Frehse, J.; Yam, S.C.P. The Master equation in mean field theory. J. Math. Pures Appl. 2015, 103, 1441–1474. [Google Scholar] [CrossRef]
- Bensoussan, A.; Frehse, J.; Yam, S.C.P. On the interpretation of the Master Equation. Stoch. Process. Their Appl. 2017, 127, 2093–2137. [Google Scholar] [CrossRef] [Green Version]
- Krylov, I.; Chernous’ko, F. On a method of successive approximations for the solution of problems of optimal control. USSR Comput. Math. Math. Phys. 1963, 2, 1371–1382. [Google Scholar] [CrossRef]
- Mitter, S.K. Successive approximation methods for the solution of optimal control problems. Automatica 1966, 3, 135–149. [Google Scholar] [CrossRef]
- Chernousko, F.L.; Lyubushin, A.A. Method of successive approximations for solution of optimal control problems. Optim. Control. Appl. Methods 1982, 3, 101–114. [Google Scholar] [CrossRef]
- Lenhart, S.; Workman, J.T. Optimal Control Applied to Biological Models; Chapman and Hall/CRC: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Sharp, J.A.; Burrage, K.; Simpson, M.J. Implementation and acceleration of optimal control for systems biology. J. R. Soc. Interface 2021, 18, 20210241. [Google Scholar] [CrossRef]
- Hackbusch, W. A numerical method for solving parabolic equations with opposite orientations. Computing 1978, 20, 229–240. [Google Scholar] [CrossRef]
- McAsey, M.; Mou, L.; Han, W. Convergence of the forward-backward sweep method in optimal control. Comput. Optim. Appl. 2012, 53, 207–226. [Google Scholar] [CrossRef]
- Carlini, E.; Silva, F.J. Semi-Lagrangian schemes for mean field game models. In Proceedings of the 52nd IEEE Conference on Decision and Control, Firenze, Italy, 10–13 December 2013; pp. 3115–3120. [Google Scholar] [CrossRef] [Green Version]
- Carlini, E.; Silva, F.J. A Fully Discrete Semi-Lagrangian Scheme for a First Order Mean Field Game Problem. SIAM J. Numer. Anal. 2014, 52, 45–67. [Google Scholar] [CrossRef] [Green Version]
- Carlini, E.; Silva, F.J. A semi-Lagrangian scheme for a degenerate second order mean field game system. Discret. Contin. Dyn. Syst. 2015, 35, 4269. [Google Scholar] [CrossRef]
- Lauriere, M. Numerical Methods for Mean Field Games and Mean Field Type Control. arXiv 2021, arXiv:2106.06231. [Google Scholar]
- Wonham, W.M. On the Separation Theorem of Stochastic Control. SIAM J. Control. 1968, 6, 312–326. [Google Scholar] [CrossRef]
- Li, Q.; Chen, L.; Tai, C.; E, W. Maximum Principle Based Algorithms for Deep Learning. J. Mach. Learn. Res. 2018, 18, 1–29. [Google Scholar]
- Liu, X.; Frank, J. Symplectic Runge–Kutta discretization of a regularized forward–backward sweep iteration for optimal control problems. J. Comput. Appl. Math. 2021, 383, 113133. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Howard, R.A. Dynamic Programming and Markov Processes; John Wiley: Oxford, UK, 1960. [Google Scholar]
- Kappen, H.J. Linear Theory for Control of Nonlinear Stochastic Systems. Phys. Rev. Lett. 2005, 95, 200201. [Google Scholar] [CrossRef] [Green Version]
- Kappen, H.J. Path integrals and symmetry breaking for optimal control theory. J. Stat. Mech. Theory Exp. 2005, 2005, P11011. [Google Scholar] [CrossRef] [Green Version]
- Satoh, S.; Kappen, H.J.; Saeki, M. An Iterative Method for Nonlinear Stochastic Optimal Control Based on Path Integrals. IEEE Trans. Autom. Control. 2017, 62, 262–276. [Google Scholar] [CrossRef]
- Cacace, S.; Camilli, F.; Goffi, A. A policy iteration method for Mean Field Games. arXiv 2021, arXiv:2007.04818. [Google Scholar] [CrossRef]
- Laurière, M.; Song, J.; Tang, Q. Policy iteration method for time-dependent Mean Field Games systems with non-separable Hamiltonians. arXiv 2021, arXiv:2110.02552. [Google Scholar] [CrossRef]
- Camilli, F.; Tang, Q. Rates of convergence for the policy iteration method for Mean Field Games systems. arXiv 2022, arXiv:2108.00755. [Google Scholar] [CrossRef]
- Ruthotto, L.; Osher, S.J.; Li, W.; Nurbekyan, L.; Fung, S.W. A machine learning framework for solving high-dimensional mean field game and mean field control problems. Proc. Natl. Acad. Sci. USA 2020, 117, 9183–9193. [Google Scholar] [CrossRef] [Green Version]
- Lin, A.T.; Fung, S.W.; Li, W.; Nurbekyan, L.; Osher, S.J. Alternating the population and control neural networks to solve high-dimensional stochastic mean-field games. Proc. Natl. Acad. Sci. USA 2021, 118, e2024713118. [Google Scholar] [CrossRef]
- Laurière, M.; Pironneau, O. Dynamic programming for mean-field type control. C. R. Math. 2014, 352, 707–713. [Google Scholar] [CrossRef] [Green Version]
- Laurière, M.; Pironneau, O. Dynamic programming for mean-field type control. J. Optim. Theory Appl. 2016, 169, 902–924. [Google Scholar] [CrossRef]
- Pham, H.; Wei, X. Bellman equation and viscosity solutions for mean-field stochastic control problem. ESAIM Control. Optim. Calc. Var. 2018, 24, 437–461. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tottori, T.; Kobayashi, T.J. Forward-Backward Sweep Method for the System of HJB-FP Equations in Memory-Limited Partially Observable Stochastic Control. Entropy 2023, 25, 208. https://doi.org/10.3390/e25020208
Tottori T, Kobayashi TJ. Forward-Backward Sweep Method for the System of HJB-FP Equations in Memory-Limited Partially Observable Stochastic Control. Entropy. 2023; 25(2):208. https://doi.org/10.3390/e25020208
Chicago/Turabian StyleTottori, Takehiro, and Tetsuya J. Kobayashi. 2023. "Forward-Backward Sweep Method for the System of HJB-FP Equations in Memory-Limited Partially Observable Stochastic Control" Entropy 25, no. 2: 208. https://doi.org/10.3390/e25020208