
Dynamic Feature Extraction-Based Quadratic Discriminant Analysis for Industrial Process Fault Classification and Diagnosis
Abstract
:1. Introduction
- (1)
- An approach to represent dynamics within multivariate time series data is introduced. It quantifies the dynamic relationships among lag submatrices by reconstructing past samples using current data. The reconstruction errors serve as dynamic features to expand the sample set.
- (2)
- A fault classification procedure for dynamic nonlinear processes is developed. It utilizes the WMSD criterion for dimensionality reduction of fault samples integrated with dynamic features and employs QDA for classification. The effectiveness of this approach is demonstrated in a subsequent novel cold rolling mill simulation case study.
2. Related Researches
2.1. Fisher Criterion Based Dimensionality Reduction
2.2. Bayesian Linear and Quadratic Discriminant Analysis
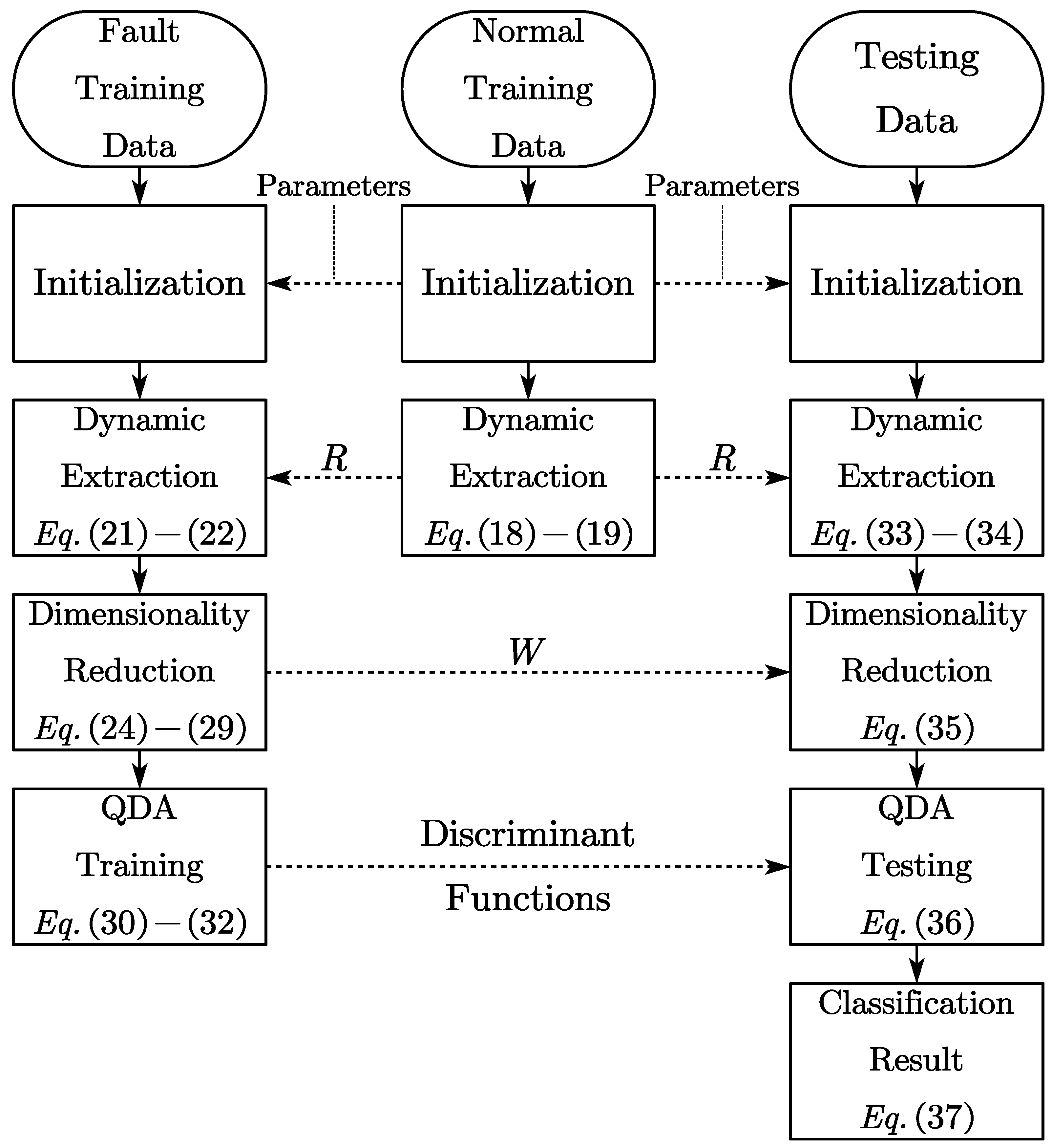
3. Dynamic Feature Extraction Based Quadratic Discriminant Analysis
3.1. Dynamic Extraction and Feature Extension
3.2. Improved Dynamic Discriminant Analysis Classifier
3.3. Offline Modeling
3.4. Online Classification
4. Simulation Experiment and Discussion
4.1. Experiment Setup in the Cold Rolling Mill Case
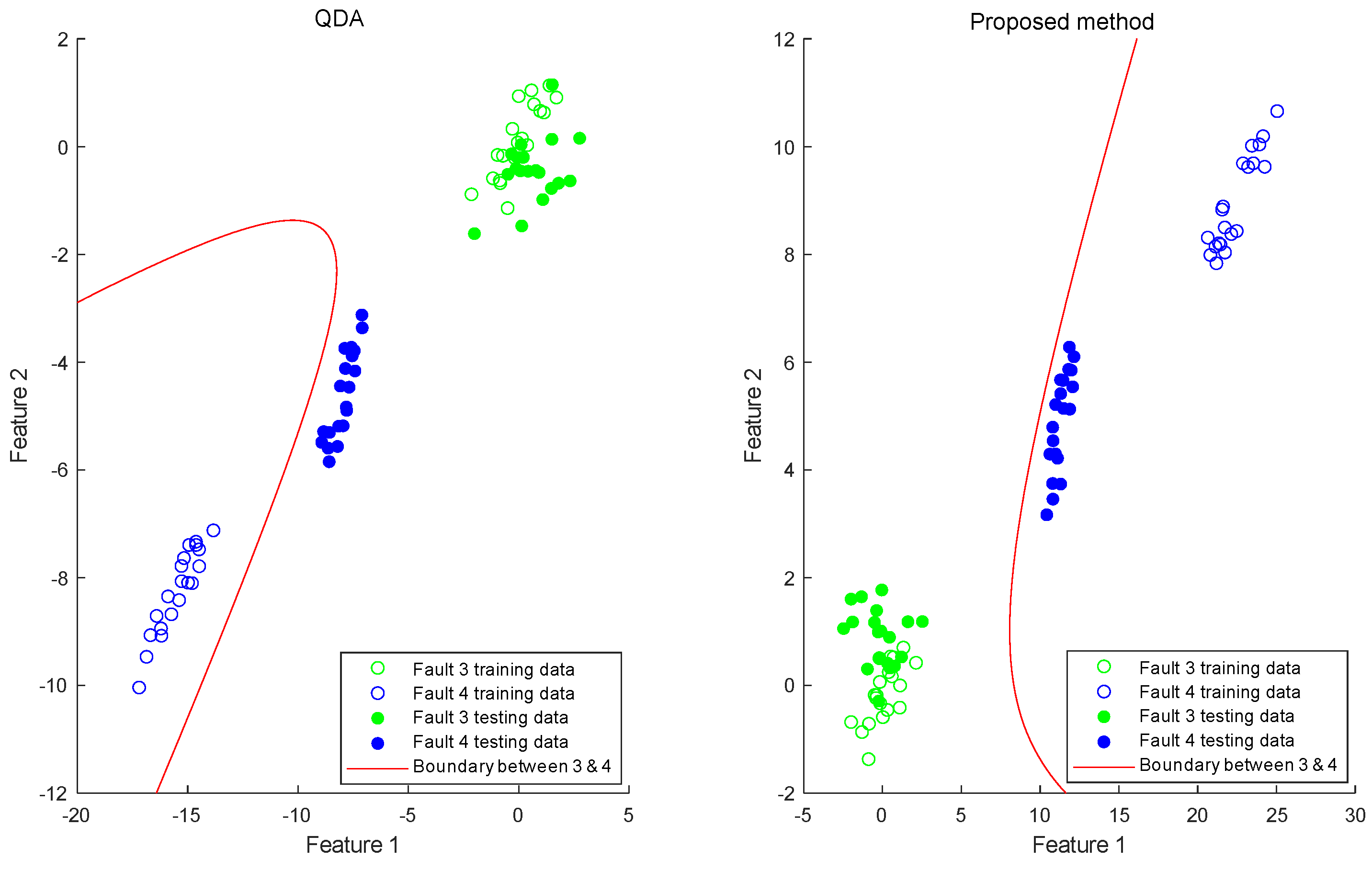
4.2. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ge, Z.; Song, Z.; Gao, F. Review of recent research on data-based process monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Jiang, Q.; Yan, X.; Huang, B. Review and perspectives of data-driven distributed monitoring for industrial plant-wide processes. Ind. Eng. Chem. Res. 2019, 58, 12899–12912. [Google Scholar] [CrossRef]
- Yan, W.; Wang, J.; Lu, S.; Zhou, M.; Peng, X. A Review of Real-Time Fault Diagnosis Methods for Industrial Smart Manufacturing. Processes 2023, 11, 369. [Google Scholar] [CrossRef]
- Cen, J.; Yang, Z.; Liu, X.; Xiong, J.; Chen, H. A review of data-driven machinery fault diagnosis using machine learning algorithms. J. Vib. Eng. Technol. 2022, 10, 2481–2507. [Google Scholar] [CrossRef]
- Jieyang, P.; Kimmig, A.; Dongkun, W.; Niu, Z.; Zhi, F.; Jiahai, W.; Liu, X.; Ovtcharova, J. A systematic review of data-driven approaches to fault diagnosis and early warning. J. Intell. Manuf. 2022, 34, 3277–3304. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C. Sparse exponential discriminant analysis and its application to fault diagnosis. IEEE Trans. Ind. Electron. 2017, 65, 5931–5940. [Google Scholar] [CrossRef]
- Ku, W.; Storer, R.H.; Georgakis, C. Disturbance detection and isolation by dynamic principal component analysis. Chemom. Intell. Lab. Syst. 1995, 30, 179–196. [Google Scholar] [CrossRef]
- Gang, L.; Si-Zhao, Q.; Yin-Dong, J.; Dong-Hua, Z. Total PLS based contribution plots for fault diagnosis. Acta Autom. Sin. 2009, 35, 759–765. [Google Scholar]
- Tan, R.; Cao, Y. Contribution plots based fault diagnosis of a multiphase flow facility with PCA-enhancec canonical variate analysis. In Proceedings of the 2017 23rd International Conference on Automation and Computing (ICAC), Huddersfield, UK, 7–8 September 2017; pp. 1–6. [Google Scholar]
- Amin, M.T.; Khan, F.; Ahmed, S.; Imtiaz, S. A data-driven Bayesian network learning method for process fault diagnosis. Process. Saf. Environ. Prot. 2021, 150, 110–122. [Google Scholar] [CrossRef]
- Amin, M.T. An integrated methodology for fault detection, root cause diagnosis, and propagation pathway analysis in chemical process systems. Clean. Eng. Technol. 2021, 4, 100187. [Google Scholar] [CrossRef]
- Jiang, Y.; Yin, S. Recent advances in key-performance-indicator oriented prognosis and diagnosis with a MATLAB toolbox: DB-KIT. IEEE Trans. Ind. Inform. 2018, 15, 2849–2858. [Google Scholar] [CrossRef]
- Jiang, Y.; Yin, S.; Kaynak, O. Optimized design of parity relation-based residual generator for fault detection: Data-driven approaches. IEEE Trans. Ind. Inform. 2020, 17, 1449–1458. [Google Scholar] [CrossRef]
- Liu, Y.; Zeng, J.; Xie, L.; Lang, X.; Luo, S.; Su, H. An improved mixture robust probabilistic linear discriminant analyzer for fault classification. ISA Trans. 2020, 98, 227–236. [Google Scholar] [CrossRef] [PubMed]
- Yu, J.; Zhang, Y. Challenges and opportunities of deep learning-based process fault detection and diagnosis: A review. Neural Comput. Appl. 2023, 35, 211–252. [Google Scholar] [CrossRef]
- Cohen, J.; Cohen, P.; West, S.G.; Aiken, L.S. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences; Routledge: Oxfordshire, UK, 2013. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Rao, C.R. The utilization of multiple measurements in problems of biological classification. J. R. Stat. Soc. Ser. Methodol. 1948, 10, 159–203. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Gao, H.; Davis, J.W. Why direct LDA is not equivalent to LDA. Pattern Recognit. 2006, 39, 1002–1006. [Google Scholar] [CrossRef]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and empirical comparison of dimensionality reduction algorithms (pca, kpca, lda, mds, svd, lle, isomap, le, ica, t-sne). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Zhong, S.; Wen, Q.; Ge, Z. Semi-supervised Fisher discriminant analysis model for fault classification in industrial processes. Chemom. Intell. Lab. Syst. 2014, 138, 203–211. [Google Scholar] [CrossRef]
- He, Z.; Wu, M.; Zhao, X.; Zhang, S.; Tan, J. Representative null space LDA for discriminative dimensionality reduction. Pattern Recognit. 2021, 111, 107664. [Google Scholar] [CrossRef]
- Yu, H.; Yang, J. A Direct LDA Algorithm for High-Dimensional Data—With Application to Face Recognition. Pattern Recognit. 2001, 34, 2067–2070. [Google Scholar] [CrossRef]
- Yu, W.; Zhao, C. Online fault diagnosis in industrial processes using multimodel exponential discriminant analysis algorithm. IEEE Trans. Control. Syst. Technol. 2018, 27, 1317–1325. [Google Scholar] [CrossRef]
- Zhang, T.; Fang, B.; Tang, Y.Y.; Shang, Z.; Xu, B. Generalized discriminant analysis: A matrix exponential approach. IEEE Trans. Syst. Man Cybern. Part Cybern. 2009, 40, 186–197. [Google Scholar] [CrossRef]
- Adil, M.; Abid, M.; Khan, A.Q.; Mustafa, G.; Ahmed, N. Exponential discriminant analysis for fault diagnosis. Neurocomputing 2016, 171, 1344–1353. [Google Scholar] [CrossRef]
- Song, F.X.; Cheng, K.; Yang, J.Y.; Liu, S.H. Maximum Scatter Difference, Large Margin Linear Projection and Support Vector Machines. Acta Autom. Sin. 2004, 30, 890–896. [Google Scholar]
- Li, H.; Jiang, T.; Zhang, K. Efficient and robust feature extraction by maximum margin criterion. IEEE Trans. Neural Netw. 2006, 17, 157–165. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Fei, S.; Zhang, T. Weighted maximum scatter difference based feature extraction and its application to face recognition. Mach. Vis. Appl. 2011, 22, 591–595. [Google Scholar] [CrossRef]
- Tharwat, A. Linear vs. quadratic discriminant analysis classifier: A tutorial. Int. J. Appl. Pattern Recognit. 2016, 3, 145–180. [Google Scholar] [CrossRef]
- Qin, Y. A review of quadratic discriminant analysis for high-dimensional data. Wiley Interdiscip. Rev. Comput. Stat. 2018, 10, e1434. [Google Scholar] [CrossRef]
- Friedman, J.H. Regularized discriminant analysis. J. Am. Stat. Assoc. 1989, 84, 165–175. [Google Scholar] [CrossRef]
- Le, Y.; Hastie, T. Sparse quadratic discriminant analysis and community bayes. arXiv 2014, arXiv:1407.4543. [Google Scholar]
- Li, Q.; Shao, J. Sparse quadratic discriminant analysis for high dimensional data. Stat. Sin. 2015, 25, 457–473. [Google Scholar] [CrossRef]
- Xiong, C.; Zhang, J.; Luo, X. Ridge-forward quadratic discriminant analysis in high-dimensional situations. J. Syst. Sci. Complex. 2016, 29, 1703–1715. [Google Scholar] [CrossRef]
- Mirsadeghi, M.; Behnam, H.; Shalbaf, R.; Jelveh Moghadam, H. Characterizing awake and anesthetized states using a dimensionality reduction method. J. Med. Syst. 2016, 40, 13. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Mai, Q. Efficient integration of sufficient dimension reduction and prediction in discriminant analysis. Technometrics 2018, 61, 259–272. [Google Scholar] [CrossRef]
- Khaled, A.Y.; Abd Aziz, S.; Bejo, S.K.; Nawi, N.M.; Jamaludin, D.; Ibrahim, N.U.A. A comparative study on dimensionality reduction of dielectric spectral data for the classification of basal stem rot (BSR) disease in oil palm. Comput. Electron. Agric. 2020, 170, 105288. [Google Scholar] [CrossRef]
- Li, H.; Jia, M.; Mao, Z. Dynamic reconstruction principal component analysis for process monitoring and fault detection in the cold rolling industry. J. Process. Control. 2023, 128, 103010. [Google Scholar] [CrossRef]
- Li, H.; Jia, M.; Mao, Z. Modular Simulation for Thickness and Tension of Five-Stand Cold Rolling. In Proceedings of the 2019 Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; pp. 5897–5902. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Unit |
|---|---|---|
| V1 | Output of the inner loop position controller | V |
| V2 | No-load flow of the servo valve | m/s |
| V3 | Pressure of the hydraulic cylinder | Pa |
| V4 | Displacement of the hydraulic cylinder | mm |
| V5 | Strip thickness of the inlet side | mm |
| V6 | Strip thickness of the outlet side | mm |
| V7 | Output of the outer loop thickness controller | V |
| V8 | Rolling force | kN |
| V9 | Strip speed of the inlet side | m/s |
| V10 | Strip speed of the outlet side | m/s |
| V11 | Strip tension of the inlet side | MPa |
| V12 | Strip tension of the outlet side | MPa |
| Case | Description |
|---|---|
| F1 | Change in the servo valve gain coefficient |
| F2 | Air mixed into the oil, causing a change in the parameter |
| F3 | Change in the load damping coefficient |
| F4 | Gradual shift in the displacement sensor coefficient |
| F5 | Gradual shift in the inlet thickness sensor coefficient |
| F6 | Gradual shift in the outlet thickness sensor coefficient |
| Proposed Method | WMSD- LDA | WMSD- QDA | Kernel FDA | |
|---|---|---|---|---|
| Parameters | ||||
| Proposed Method | WMSD- LDA | WMSD- QDA | Kernel FDA | |
|---|---|---|---|---|
| Fault 1 (%) | 100 | 48.3 | 100 | 100 |
| Fault 2 (%) | 100 | 61.9 | 100 | 100 |
| Fault 3 (%) | 98.8 | 100 | 98.9 | 98.9 |
| Fault 4 (%) | 98.7 | 47.6 | 92.5 | 92.6 |
| Fault 5 (%) | 96.7 | 48.7 | 80.3 | 80.2 |
| Fault 6 (%) | 95.8 | 32.3 | 92 | 92.1 |
| Overall average (%) | 98.3 | 56.4 | 93.9 | 94 |
| Worst average (%) | 94.8 | 48 | 84 | 84 |
| Standard deviation (%) | 1.48 | 4.55 | 5.02 | 5.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Jia, M.; Mao, Z. Dynamic Feature Extraction-Based Quadratic Discriminant Analysis for Industrial Process Fault Classification and Diagnosis. Entropy 2023, 25, 1664. https://doi.org/10.3390/e25121664
Li H, Jia M, Mao Z. Dynamic Feature Extraction-Based Quadratic Discriminant Analysis for Industrial Process Fault Classification and Diagnosis. Entropy. 2023; 25(12):1664. https://doi.org/10.3390/e25121664
Chicago/Turabian StyleLi, Hanqi, Mingxing Jia, and Zhizhong Mao. 2023. "Dynamic Feature Extraction-Based Quadratic Discriminant Analysis for Industrial Process Fault Classification and Diagnosis" Entropy 25, no. 12: 1664. https://doi.org/10.3390/e25121664