

Nested Variational Chain and Its Application in Massive MIMO Detection for High-Order Constellations


School of Telecommunications Engineering, Xidian University, Xi’an 710071, China
Entropy 2023, 25(12), 1621; https://doi.org/10.3390/e25121621
Submission received: 24 October 2023
/
Revised: 21 November 2023
/
Accepted: 29 November 2023
/
Published: 5 December 2023
(This article belongs to the Special Issue Wireless Communications: Signal Processing Perspectives)
Abstract
:Multiple input multiple output (MIMO) technology necessitates detection methods with high performance and low complexity; however, the detection problem becomes severe when high-order constellations are employed. Variational approximation-based algorithms prove to deal with this problem efficiently, especially for high-order MIMO systems. Two typical algorithms named Gaussian tree approximation (GTA) and expectation consistency (EC) attempt to approximate the true likelihood function under discrete finite-set constraints with a new distribution by minimizing the Kullback–Leibler (KL) divergence. As the KL divergence is not a true distance measure, ’exclusive’ and ’inclusive’ KL divergences are utilized by GTA and EC, respctively, demonstrating different performances. In this paper, we further combine the two asymmetric KL divergences in a nested way by proposing a generic algorithm framework named nested variational chain. Acting as an initial application, a MIMO detection algorithm named Gaussian tree approximation expectation consistency (GTA-EC) can thus be presented along with its alternative version for better understanding. With less computational burden compared to its counterparts, GTA-EC is able to provide better detection performance and diversity gain, especially for large-scale high-order MIMO systems.
1. Introduction
Multiple input multiple output (MIMO) technology has attracted broad attention over the last decade and has been widely applied into practical communication systems. The benefit of MIMO technology lies in the improvement of spectral efficiency and link reliability due to the multiplexing and diversity gain that grows with the number of elements, and a MIMO system is referred to as a massive MIMO system when the scale of array elements grows large enough, which brings increasing difficulty to the signal detection due to huge computational burden, hindering the prevailing usage of massive MIMO systems [1,2].
Many research studies have been carried out for signal detection in massive MIMO systems [3,4,5,6,7,8,9,10,11,12,13,14,15,16,17]. It is well known that the maximum likelihood detection presents the best detection performance with the cost of exponentially growing computational burden [3]. Neglecting the finite-set constraint, the minimum mean square error (MMSE) approach can be applied by solving the least square fit, and a closest lattice point can then be found by treating symbols independently [4]. The MMSE approach normally exhibits a benchmark performance when comparing different detectors, and its performance can be vastly improved by MMSE-SIC when combining with the successive interference cancellation (SIC) technique [5]. However, as MMSE or MMSE-SIC cannot provide satisfied performance, several alternatives have been proposed instead, which can be divided into two major categories, i.e., sub-space searching-based and variational inference-based detectors.
The sub-space searching-based category originates from the idea of reducing the searching space of all possible lattice points with unacceptable complexity. Sphere decoding tries to replicate the maximum likelihood performance by diminishing the searching space, the dimension of which grows up with the number of antennas as well as the modulation order, making it prohibitive for the large-scale or high-order MIMO systems [6,7]. Another two local searching-based approaches were proposed by the name of likelihood ascending search and reactive tabu search [8,9,10], and the basic idea behind them is to search through a proximity sub-space around a given initial solution. They present good performance for a large number of antennas with low-order constellations but poor performance for high-order constellations. A layered tabu search algorithm was proposed in [11] by performing detection over layers, requiring a higher order of complexity for high-order constellations, and a Gibbs sampling-based detector was proposed in [12] by performing a serial of one-dimensional searches over iterations. It may provide good performance for low-order constellations with the cost of enormous processing time. Therefore, algorithms in the former category suffer from poor performance or prohibitive computational burden in large-scale high-order MIMO systems.
Proved to be suitable for the detection problem resulted by high-order constellations, the variational inference based category tries to approximate the true likelihood function into a new distribution that is much easier to handle. A Gaussian tree approximation (GTA) algorithm was proposed in [13,14] by transforming the fully connected factor graph into a tree graph, based on which belief propagation based message passing can be proceeded for inference. The GTA algorithm has comparable performance with MMSE-SIC at a similar complexity only to MMSE. The expectation propagation (EP) algorithm was proposed for MIMO detection in [15] by substituting true priors belonging to a discrete finite set with the introduced Gaussian priors being able to be updated over iterations. EP performs the best at a complexity several times that of MMSE, and its alternative named expectation consistency (EC) was then proposed to provide a more general perspective than EP [16]. Two low-complexity EP/EC-based algorithms were proposed for scenarios when the number of transmit antennas is less than that the number of receiver ones [17,18], and a double-EP based iterative detection and decoding was proposed by iteratively exploiting decoders in [19]. EP/EC-based algorithms can also be applied into channel estimation problems in massive MIMO systems [20,21].
In this paper, we would like to expand the variational inference paradigm by proposing a nested variational chain. The basic idea behind it is that ’exclusive’ and ’inclusive’ KL divergences employed by GTA and EC, respectively, are not exclusive and can be combined in a nested way so as to form an approximation chain, by which both GTA and EC are improved. The major contributions are listed as follows.
- Firstly, the basic idea of the nested variational chain is proposed, and an algorithm is then proposed to establish a general framework. By referring to ’general’, it means this framework is able to combine ’exclusive’ and ’inclusive’ KL divergences, or it degrades to either one as a special case.
- Secondly, providing several examples, we show that existing algorithms, such as MMSE, GTA, and EC, can be regarded as special cases of the variational chain.
- Finally, to provide an initial application of the variational chain into massive MIMO detection, a GTA-embedded Expecatation Consistency (GTA-EC) algorithm is proposed which proves to provide better detection performance, especially for high-order constellations. The complexity of GTA-EC is analyzed as well along with comparisons.
This paper is arranged as follows. Section 2 introduces the system model and MIMO detection problem, based on which the nested variational chain is provided in Section 3 along with a generic algorithm framework. Section 4 derives the GTA-EC algorithm with complexity analyses. Simulation results are demonstrated in Section 5 along with discussions, and the conclusion is presented in Section 6. Throughout this paper, matrices and vectors are denoted by symbols in boldface, and variables are denoted in italics. The notation or is used to represent the transpose of a vector or matrix, and represents a unit matrix.
2. Preliminary
2.1. Signal Model
A multiuser MIMO system is considered, without loss of generality, in which transmitters, each equipped with one antenna, communicate with a base station that is equipped with antennas. Assume each transmitter transmits any symbol that is selected from a Quadrature Amplitude Modulation (QAM) constellation set , where stands for the complex domain, and the cardinality of the constellation set is . The transmitted symbols can be represented as a vector with the average energy of each QAM symbol defined as . After propagating through the wireless channels, the received signal at the base station can be expressed as
where stands for additive Gaussian white noises (AWGN), each element having zero mean and variance. is defined as a matrix by stacking up channel coefficients with being Rayleigh flat-fading channel coefficients of the th symbol. Perfect channel state information (CSI) is assumed such that is known at the base station.
The channel model above is usually re-expressed in the real domain by taking into consideration real and imaginary parts, respectively. By defining and as operations to take the real and imaginary part of a variable or matrix, one can define , , , and that
where , , , , , and stands for the real domain. The equivalent model in the real domain is then given as
where the variance of each element of equals , and belongs to the pulse amplitude modulation (PAM) constellation set containing real and imaginary parts of the A-QAM alphabets with its cardinality being . The average energy of a PAM symbol is , and the signal-to-noise (SNR) of the MIMO system is then defined as
2.2. MIMO Detection
As the received signal in a MIMO system is a superposition of transmitted symbols weighted by channel coefficients, the purpose of MIMO detection is to estimate successfully all transmitted symbols impaired by channel fading and noises. As is well known, the maximum a posteriori (MAP) detector could achieve the best detection performance by maximizing the a posteriori probability as follows
where the distribution given the received signal and CSI is expressed as
is defined as Gaussian distribution with a mean vector of and a covariance matrix of , and is defined as the a priori probability of symbols. When is uniformly distributed with being an indication function that takes value one if and zero otherwise, the MAP detection degrades into the maximum likelihood detection, i.e.,
The complexity of maximum likelihood detection grows up exponentially with the number of symbols N, making it prohibitive for middle- or large-scale MIMO systems with especially high-order constellations.
3. Nested Variational Chain
In order to perform low-complexity MIMO detection, one popular approach is to approximate the true posterior with another distribution that is much simpler to perform inference on, and the KL divergence is commonly used to obtain the desired distribution. Defining as the distribution utilized to approximate the true posterior, the minimization of the ’exclusive’ and ’inclusive’ KL divergences can be expressed as
and
For instance, the GTA algorithm takes the former way, while the EC algorithm takes the latter one. However, with only one approximation, GTA is unable to update its approximated tree structure, while EC only treats symbols in an independent way rather than exploiting correlation among symbles. In this case, we then would like to demonstrate that the two KL divergences could be combined together, and a nested variational chain is then proposed in what follows.
Suppose there is a desired variational distribution that can be obtained with ’exclusive’ KL divergengce:
which is embedded in an optimization for with obtained in the first place as
The processing above actually forms a variational chain with a nested structure given as
indicating should be obtained according to the minimization of with respect to , and that the desired could then be obtained by minimizing with respect to . Following the roadmap, we may derive an algorithm for the nested variational chain combining the two asymetric KL divergences.
3.1. A Generic Framework for Nested Variational Chain
To begin with, a general statistical model should first be defined as follows [12],
where is a function belonging to the exponential family, and for are non-negative factors. Normally, it is intractable or prohibitive complex to perform inference over such that the variational inference-based approaches provide another distribution that is tractable or easy to handle. The nested variational chain consists of four steps: factor substitution, inner approximation, symbol detection and factor updating.
As for factor substitution, the optimization of the KL divergence should first be achieved, i.e., , for which the EC framework can be employed. The EC algorithm assumes a distribution that belongs to the exponential family:
where instead of for are modified factors, belonging to the exponential family as well.
It should be noticed that the EC framework replaces each non-negative factor by another in the exponential family. However, the distribution remains constant during this optimization process, which may be further exploited. Based on this idea, another variational distribution could be embedded inside as an inner approximation so as to achieve a final distribution , and the optimization in (6) could be performed:
The approximation is normally expressed as . When for are defined as disjoint groups, it is mean-field approximation, and structured approximation can be employed when for are overlapped with each other.
Toward symbol detection, a cavity distribution for each factor can then be acquired as
and the final distribution can be represented as
with defined as a new distribution by attaching the true factor.
The moments of are then obtained by exploiting the true distribution as , where stands for the sufficient statistics of the exponential family. A new factor is updated as well by satisfying the moment-matching condition with
such that the distribution is able to be updated iteratively.
An algorithm is provided in Algorithm 1, which is used to approximate a statistical model . Associating with the four steps described above, the algorithm first substites all factors in Step 1 with much easier accessible ones by using the ’inclusive’ KL divergence, as seen in the EC algorithm. After that, the algorithm further approximates with a new distribution in Step 2 such that better detection performance is expected. With detection proceeded on the new distribution, moment matching can be achieved in Step 3 so as to update substituted factors in Step 4. Note that any of the steps, such as factor substitution, inner approximation, or factor updating, may be skipped for a certain purpose so as to form a special case. In the next subsection, we would like to demonstrate that the MMSE, GTA and EC algorithms could be deemed as special cases.
| Algorithm 1 An algorithm for nested variational chain |
|
3.2. MMSE, GTA and EC MIMO Detectors as Special Cases
In a MIMO system, the distribution can be expressed as the likelihood function, i.e., , and each non-negative factor for could be regarded as the probability with respect to symbols. When a factor corresponds only to one symbol , it reduces to . Hence, as there are N symbols in a MIMO system, there would be N factors or priors as well, and the expression for the substituted factor for depends on any specific algorithm.
(1) Minimum Mean Square Error
The MMSE approach could be obtained by assuming that each non-negative factor for can be replaced by a Gaussian distributed factor of zero-mean and a variance of , and the modified distribution with factor substitution for MMSE is then given as
whose second-order and first-order moments are derived as
Not mentioned though before, there is actually a simple inner approximation for MMSE to approximate the distribution . With a fully factorized distribution , each factorized one can be obtained as
which is known as the mean-field approximation. The expression refers to expectation with respect to all factors for except for . This process is equivalent to marginalization of with and being the element of and of the diagonal of .
The MMSE approach skips factor updating, but instead it may output directly the hard detection results. The final distribution of MMSE is expressed as
where is defined as a new distribution by attaching true priors, based on which symbol detection can be proceeded for each symbol independently.
(2) Expectation Consistency
The EC algorithm defines a substitution factor for each symbol as well. It replaces the prior to so the posterior can be expressed as
Note that is Gaussian distributed. In this regard, it can be noticed that EC relates essentially to MMSE with the difference that it is able to update priors. The second-order and first-order moments of are derived as
where is a diagonal matrix containing , and is a vector containing for .
The EC algorithm employs mean-field approximation for inner approximation as well, by which the fully factorized distribution is defined as , and each factorized distribution is Gaussian distributed such that:
with and being the element of and of the diagonal of , respectively. By doing so, factor updating is then operated with a cavity distribution:
and the final distribution for EC is represented as
where is defined as a new distribution. Symbol detection can then be performed to achieve the moment-matching condition so the pairs for are updated in parallel.
(3) Gaussian Tree Approximation
The GTA algorithm was proposed based on the modified distribution of MMSE, and its distribution with substituted factors can be represented as
As for inner approximation, the GTA algorithm chooses to optimally approximate the distribution with a tree graph, which can be constructed based on as
where stands for the conditional probability of given its parent , and in case that is the root of the tree.
This leads to a result that GTA skips factor updating as well, similar to MMSE, and the performance of the GTA algorithm is subject to the fixed initial distribution that is not able to be updated. In this case, by directly attaching the true priors for , the final distribution of GTA is then represented as
where . Proceeding on such a loop-free tree graph, message passing can then be utilized to perform efficient detection during all but one iteration.
4. Applications into MIMO High-Order Detection
Introducing the nested variational chain for MIMO detection, it can be seen that all existing approaches employ factor substitution. As for inner approximation, MMSE and EC actually perform mean-field approximation with fully factorized distribution, while GTA performs the maximum spanning tree approximation. Finally, only EC performs factor updating, while MMSE and GTA choose to perform direct detection.
This analysis puts forward the question of whether any improvement can be achieved when one enables GTA to update its substituted factors or whether any better inner approximation can be derived for EC rather than being fully factorized. Both thoughts lead us to an idea that it is worth trying to update the GTA factors iteratively since the approximated Gaussian tree is capable of capturing correlation among symbols rather than keeping independence among them. Following this idea, an initial application of the nested variational chain can be performed. By utilizing EC as an outer approximation, an algorithm named GTA-embedded EC (GTA-EC) is proposed in the following.
4.1. The GTA-EC Algorithm
Given for , the algorithm starts from the likelihood function with discrete priors as in (3), i.e.,
which could be divided into two parts, i.e.,
It is then possible to define a new distribution as
of which the moments can be expressed as
Note that the pair acts as priors of all symbols to be updated, and that the definition of actually serves as factor substitution.
To achieve moment consistency, another distribution is then defined as
where moment matching between and should be achieved so as to obtain and . The EC algorithm assumes another distribution:
with moments derived as
It can be observed that partly in actually serves as a cavity distribution of symbols by subtracting their substituted priors .
The next step involves inner approximation. Since fully factorization for neglects correlation among symbols, we instead propose utilizing the Gaussian approximation tree to perform detection according to the moments , , , and . This is because the Gaussian approximation tree may capture correlation among symbols rather than treating them independently. In this case, we define a new Gaussian tree-based distribution rather than as
where is a new distribution by attaching true priors, and the conditional distribution can be represented as
where and for are taken from and the diagonal of , respectively, while and for are taken from and the diagonal of .
Based on , message passing on the Gaussian tree can then be proceeded:
and
To achieve consistency, the distribution is finally utilized once again to achieve moment matching between and so as to obtain and , and the a priori moments can be updated:
The GTA-EC algorithm is concluded and depicted in detail in Algorithm 2. In step 1, the GTA-EC algorithm initiliazes the distribution , which behaves as an outer approximation by substituting true factors. In step 2, the inner approximation is applied to by using its moments, such that a maximum spanning tree is constructed. With the derived tree structure, the algorithm repeats step 3 and step 4 over iterations such that factors can be updated by performing symbol detection and moment matching, and hard outputs can then be obtained according to the final distribution.
| Algorithm 2 The GTA-EC Algorithm |
|
4.2. Complexity Analysis
The calculation of GTA-EC resides mainly on three parts. The first one involves the factor substitution step, which necessitates the calculation of second-order and first-order moments in (29), the same as MMSE in (16) or EC in (19). As is well known, its complexity in one iteration can be given as . The second part involves construction of the tree graph for inner approximation, which needs only to be initialized at the very beginning of iterations. The construction is based on Prim’s algorithm, whose complexity is . The last part involves the calculation of message passing and factor updating. For each iteration, the major complexity lies in calculating messages in (33) and (34), each requiring the maximum likelihood detection on the conditional distribution with the cardinality of PAM constellation being . Since there are conditional distributions in the tree graph, the complexity can be represented as . Therefore, by defining as the number of iterations to proceed, the total complexity can be expressed as due to the reason that is normally satisfied in a massive MIMO system. This indicates that the complexity of GTA-EC is about times more than that of MMSE or GTA, namely . As a comparison, the complexity of EC can be expressed as , suggesting that the complexity of GTA-EC is approximately in the same order. The less iterations one algorithm needs to perform, the less complexity it requires. In the next section, when comparing the performance of GTA-EC with EC, the number of iterations should be utilized for complexity comparison. A summary of complexity comparison is demonstrated in Table 1, in which it can be found that the total complexity is dominated by the complexity of factor substitution as well as the number of iterations.
5. Numerical Results
5.1. Simulation Parameters
In this section, the detection performance of a MIMO system is evaluated in terms of bit error rate (BER). Uncorrelated scattering flat-fading channel model is assumed with channel coefficients being modeled as complex Gaussian distributed variables that are independently generated for all antennas. During the simulation, 20,000 realizations of the channel matrix are employed with each used to send one message. As a comparison, several existing algorithm are evaluated as well such as the MMSE, GTA, and EC algorithms. And we mainly take into consideration the ’worst-case’ scenarios of load when and with high-order constellations 16-QAM, 64-QAM, and 256-QAM considered. The factor is set as for all algorithms, and the iteration number of EC and GTA-EC is set as 2, 4, and 6 since convergence can be achieved within iterations.
5.2. Performance Evaluation
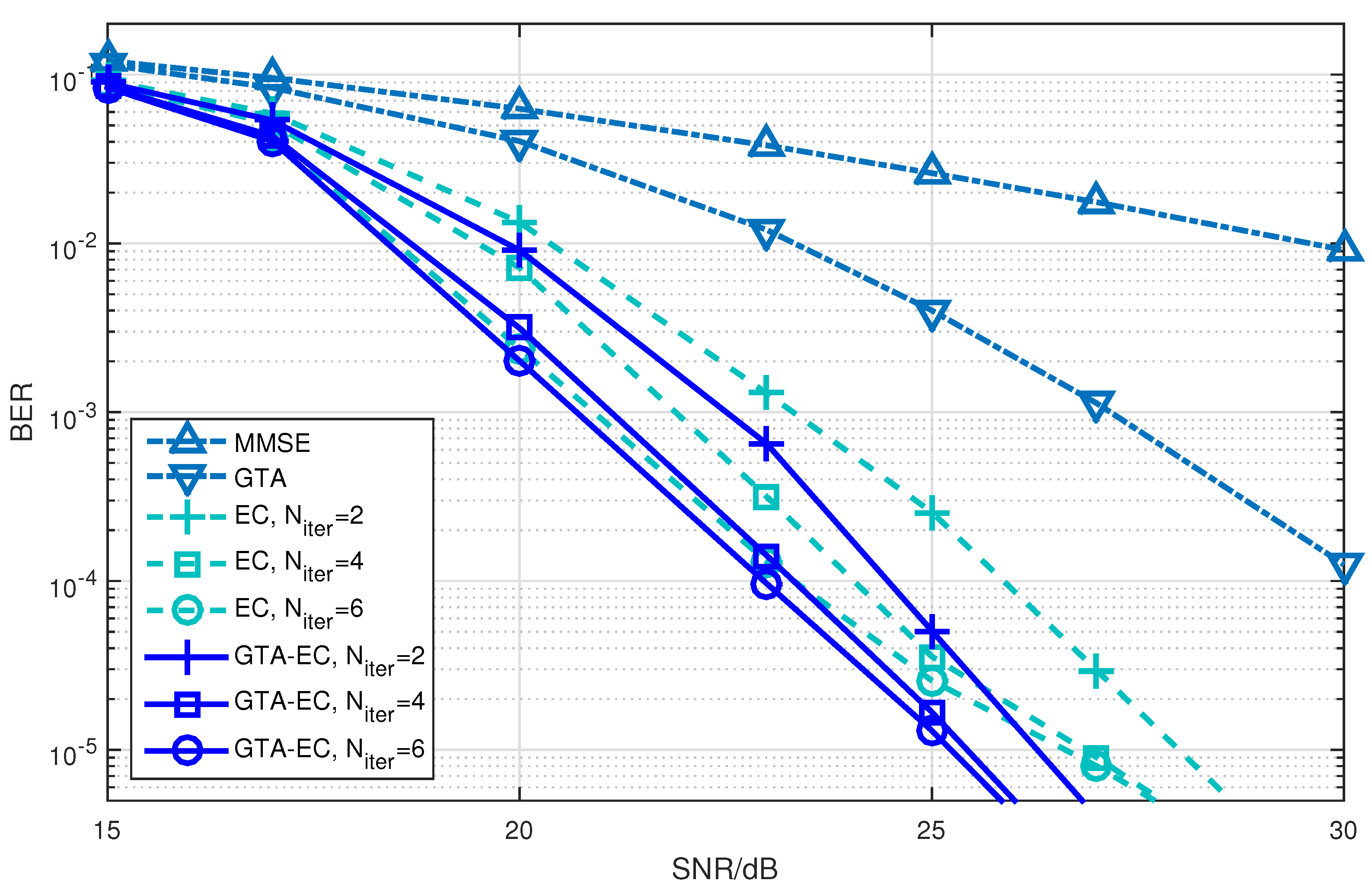
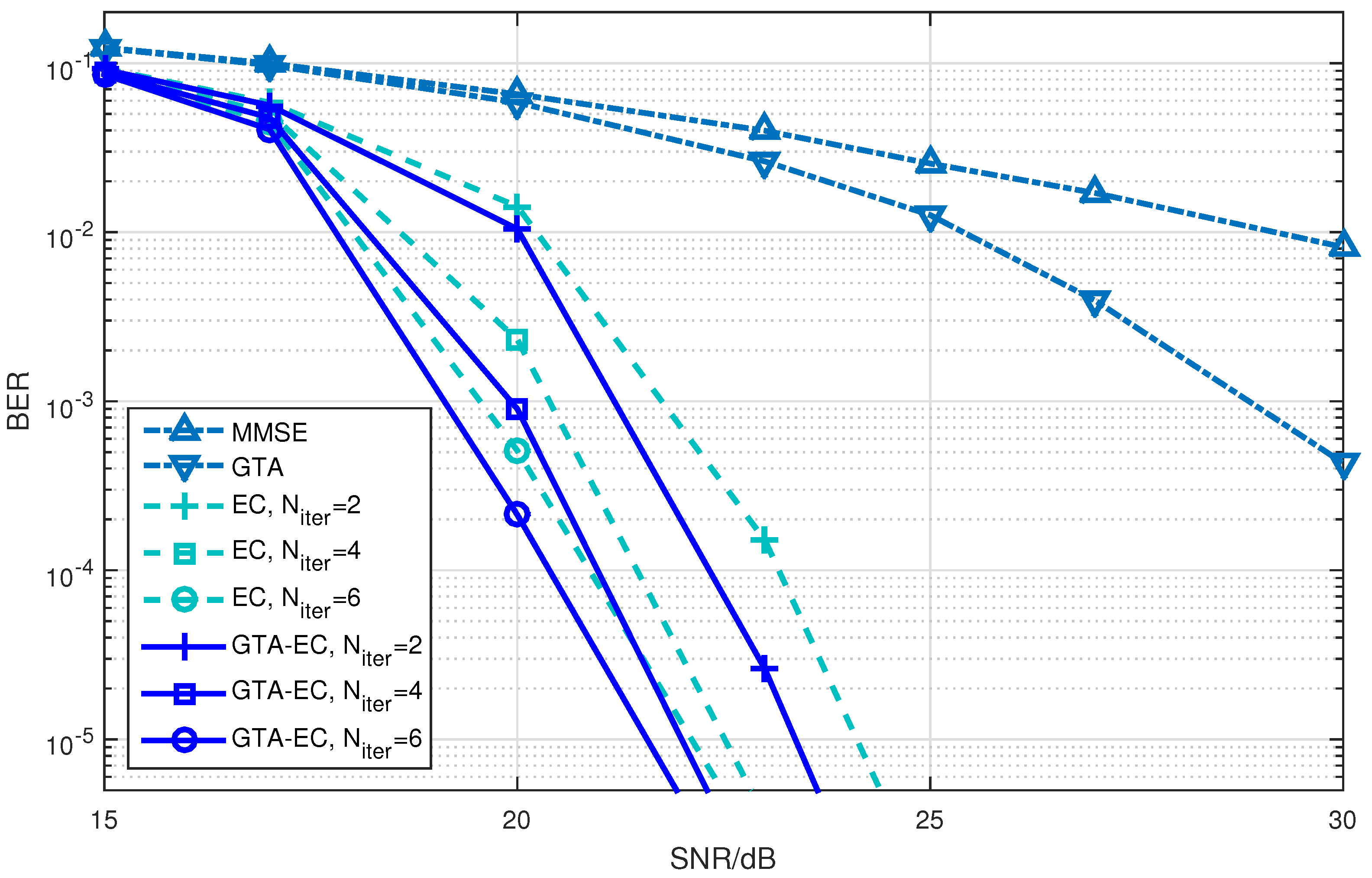
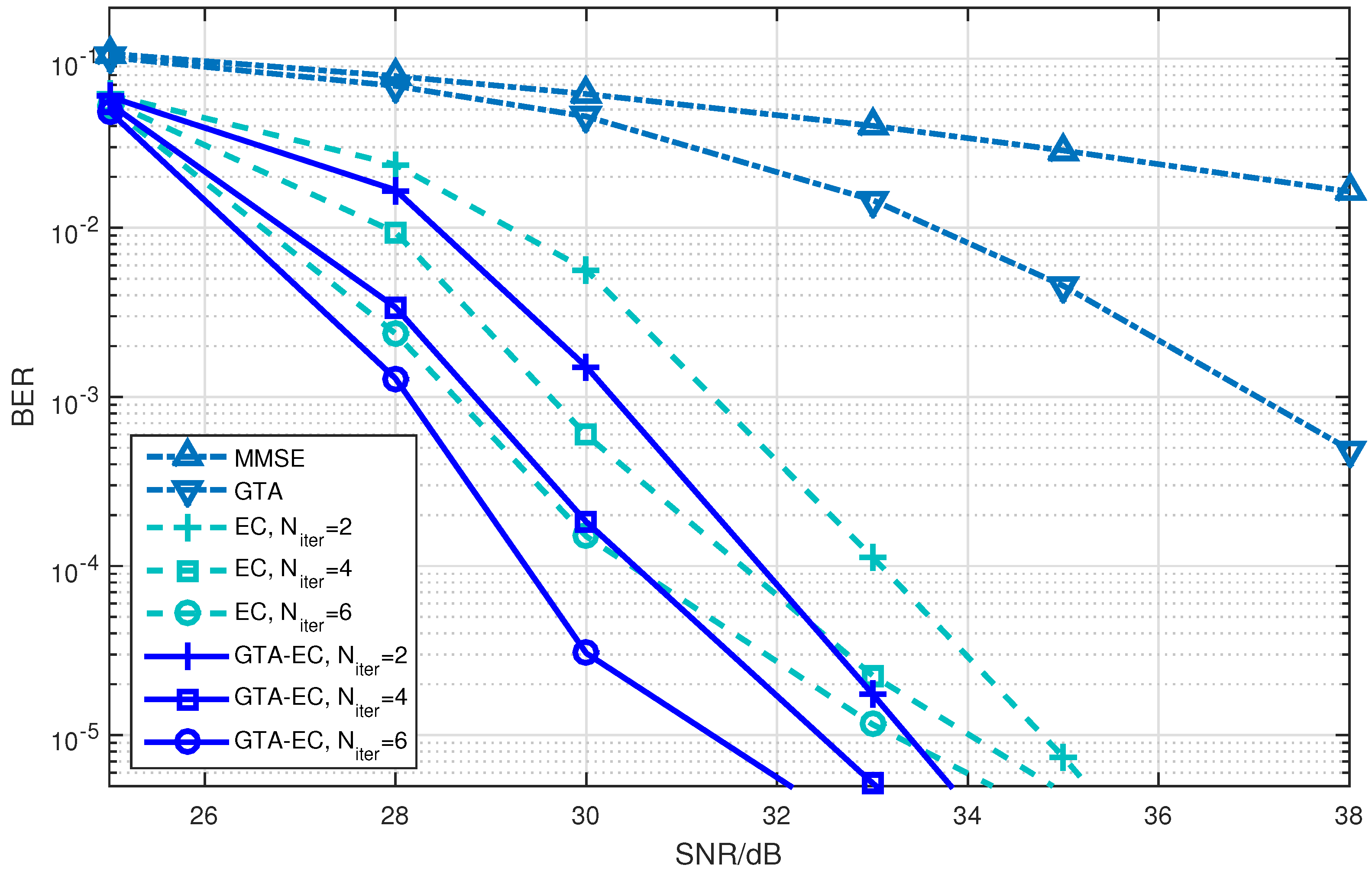
Figure 1, Figure 2 and Figure 3 demonstrate the BER comparison of the GTA-EC algorithm with existing algorithms. The number of antennas deployed at both the transmitter and receiver in the system is set as with the constellations being 16-QAM, 64-QAM and 256-QAM, respectively. It can be found that GTA-EC outperforms EC with the same number of iterations, and that GTA-EC with iterations outperforms EC with iterations, indicating that GTA-EC may achieve better performances than EC does with lower complexity. While in Figure 2 and Figure 3, GTA-EC with iterations almost exibits better performance than EC with iterations, revealing better performance gain when high-order constellations are employed. One can further obseve that the BER slopes of GTA-EC decrease faster than that of EC, demonstrating that superior divergence gain can also be obtained by GTA-EC in a high SNR regime.
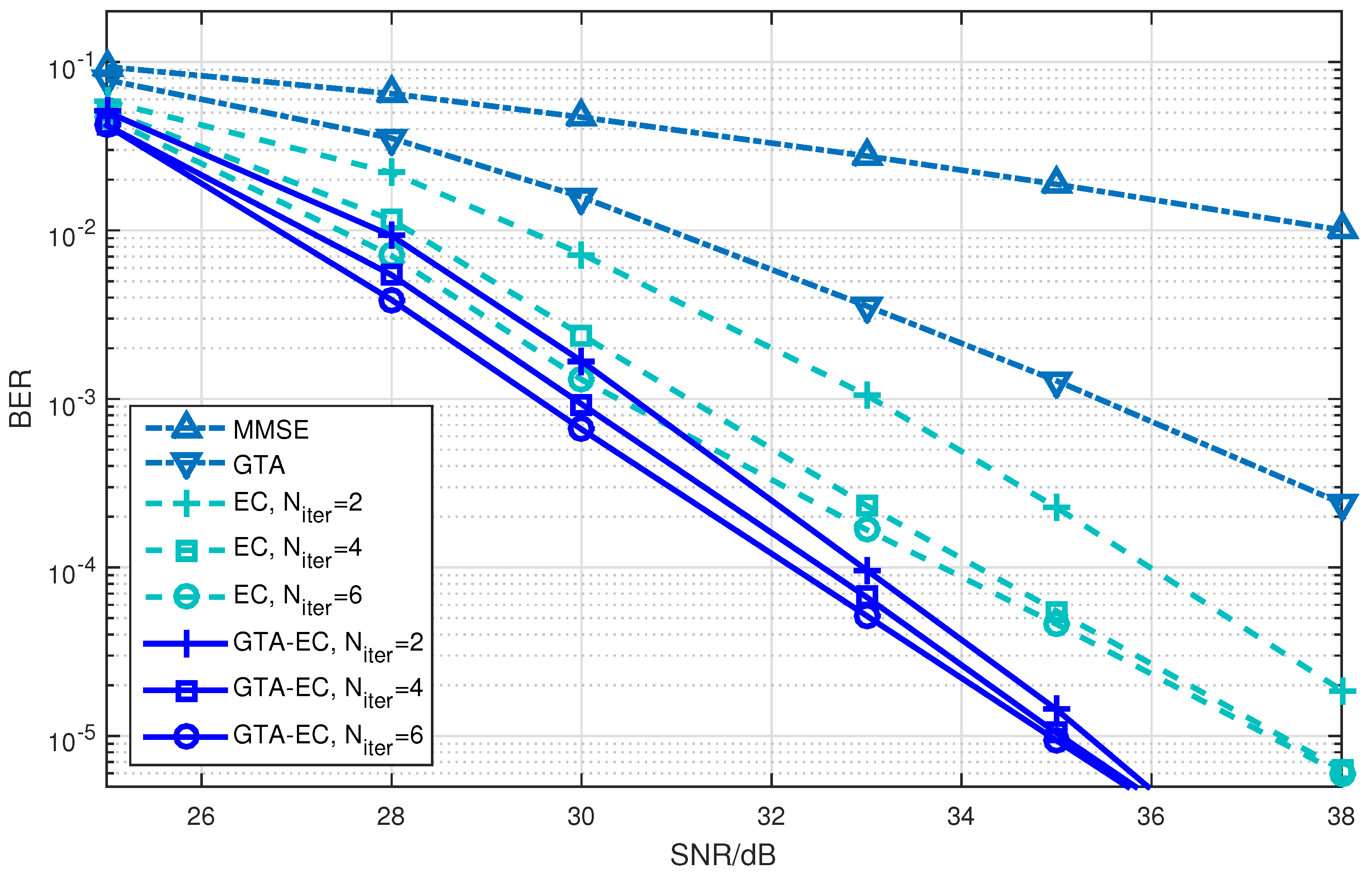
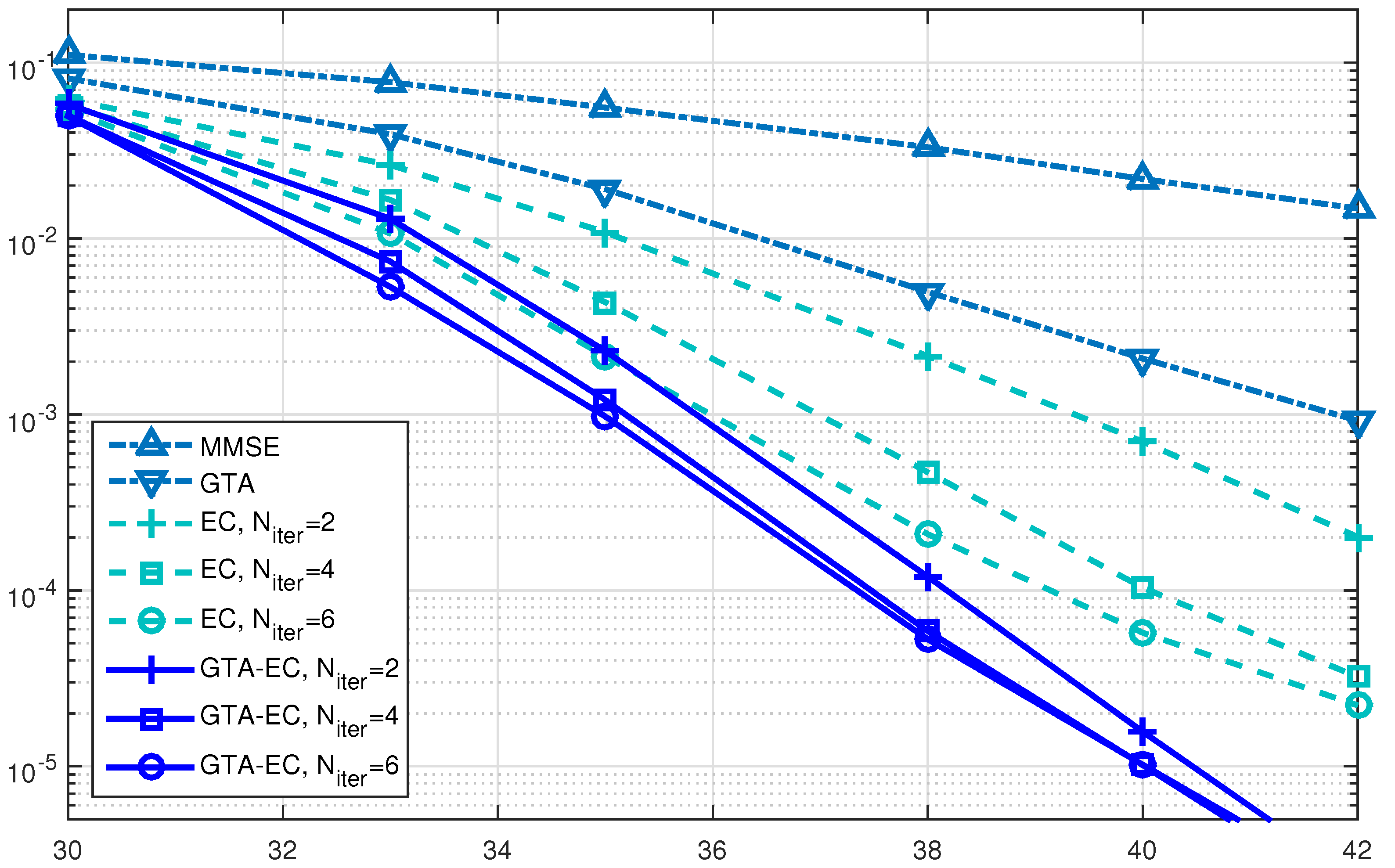
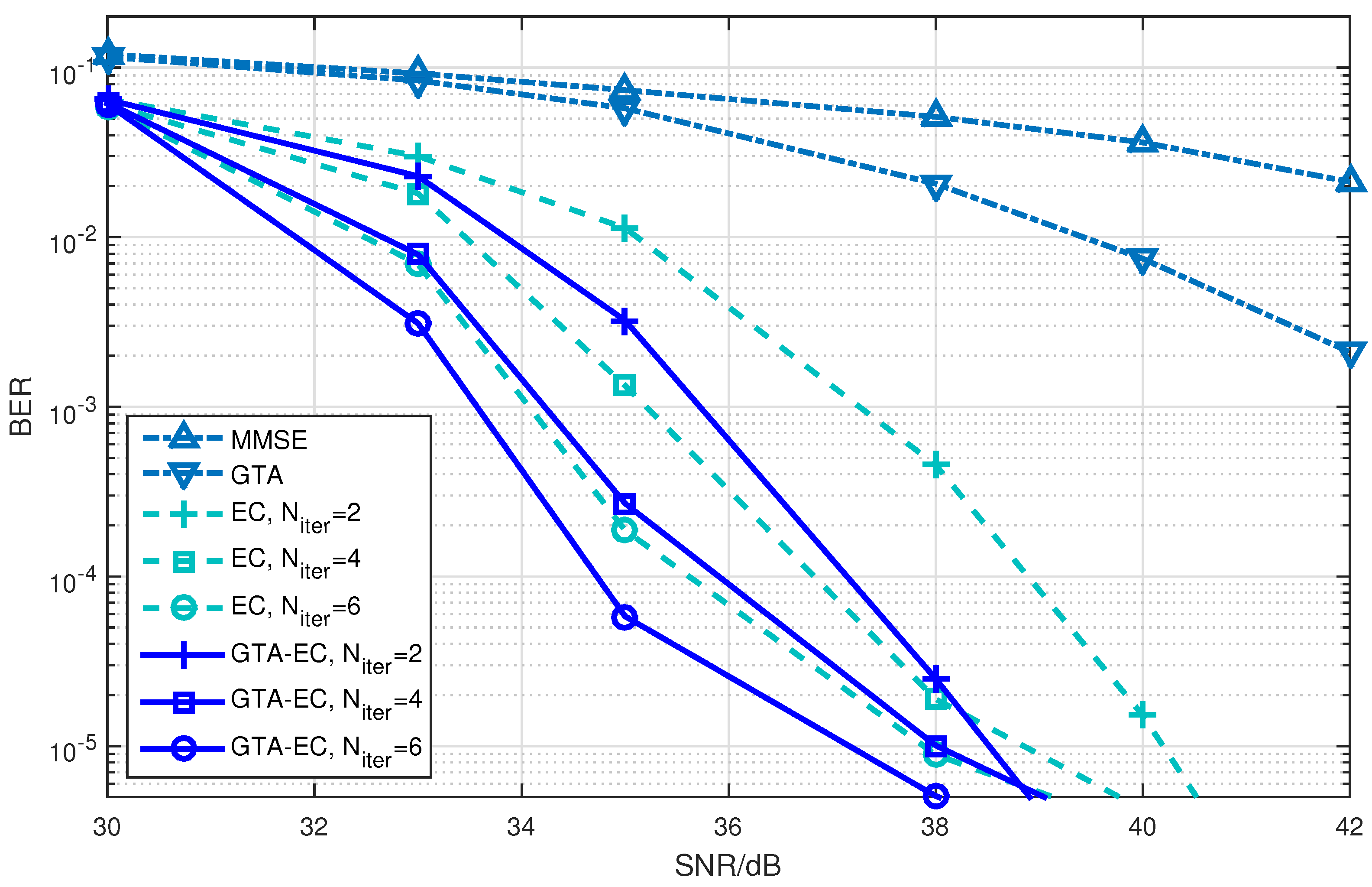
Figure 4, Figure 5 and Figure 6 demonstrate a BER comparison of the GTA-EC algorithm with existing algorithms. The number of antennas deployed at both the transmitter and receiver is given as with the constellations being 16-QAM, 64-QAM and 256-QAM, respectively. In these figures, it can be found that GTA-EC outperforms EC with the same number of iterations, while GTA-EC with iterations may have similar performance to that of EC with iterations. This indicates that GTA-EC exhibits better performance than EC does at the same order of complexity or that GTA-EC presents similar performance to that of EC with lower complexity. And in Figure 4 and Figure 5, one can further observe that the BER slope of GTA-EC decreases faster than that of EC, leading to better performance in a high SNR regime.
By observing and analyzing the figures in different scenarios, we may come to conclusions about the performance comparison of GTA-EC with existing algorithms.
- On one hand, both EC and GTA-EC significantly outperform existing algorithms such as MMSE and GTA. In most scenarios, GTA-EC can obviously outperform EC with either 16-QAM, 64-QAM, or 256-QAM employed. The performance gain of GTA-EC becomes larger when high-order constellation is employed. For example, both the 64-QAM and 256-QAM cases exhibit larger gain than the 16-QAM case when employing 16 or 64 antennas. This indicates that GTA-EC has superior performance gain and is especially suitable for high-order constellations. We believe that the performance gain comes from exploiting additonal relations (correlation) among symbols rather than treating them independently.
- On the other hand, as for the complexity issue, GTA-EC with iterations may outperform or have comparable performance to EC with iterations, suggesting that GTA-EC requires less complexity than EC by recalling that their computational burdens are dominated by the number of iterations needed. As a result, iterations are recommended for GTA-EC according to the simulation results, and hence the complexity of GTA-EC is approximately times more than MMSE, indicating that it is a practical method for massive MIMO systems.
6. Conclusions
A nested variational chain is proposed along with an algorithm provided, which combines two asymmetic KL divergences. Introduced into MIMO systems, it can be found that several existing algorithms such as MMSE, GTA, and EC can be regarded as special cases. As initial applications for MIMO detection, an algorithm named GTA-EC is proposed with complexity analysis, and numerical results prove that it may achieve better detection performance with less complexity compared to existing algorithms. As for further research topics, it is suggested that one can find better inner approximation that may capture much more correlation among symbols by applying this framework to other detection fields, such as space code multiple access (SCMA), orthogonal time frequency space (OTFS), or low-density parity check (LDPC) decoding systems.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 61801352 and 62371363.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The author declares no conflict of interest.
References
- Yang, S.; Hanzo, L. Fifty Years of MIMO Detection: The Road to Large-Scale MIMOs. IEEE Commun. Surv. Tutor. 2015, 17, 1941–1988. [Google Scholar] [CrossRef]
- Albreem, M.A.; Juntti, M.; Shahabuddin, S. Massive MIMO Detection Techniques: A Survey. IEEE Commun. Surv. Tutorials 2019, 21, 3109–3132. [Google Scholar] [CrossRef]
- Chen, J.-C. A low complexity data detection algorithm for uplink multiuser massive MIMO systems. IEEE J. Selecive Areas Commun. 2017, 35, 1701–1714. [Google Scholar] [CrossRef]
- Caire, G.; Muller, R.; Tanaka, T. Iterative multiuser joint decoding: Optimal power allocation and low-complexity implementation. IEEE Trans. Inf. Theory 2004, 50, 1950–1973. [Google Scholar] [CrossRef]
- Liu, T.; Liu, Y.-L. Modified fast recursive algorithm for efficient MMSE-SIC detection of the V-BLAST system. IEEE Trans. Wirel. Commun. 2008, 7, 3713–3717. [Google Scholar]
- Albreem, M.A.M.; Salleh, M.F.M. Radius selection for lattice sphere decoder-based block data transmission systems. Wirel. Netw. 2016, 22, 655–662. [Google Scholar] [CrossRef]
- Cui, T.; Han, S.; Tellambura, C. Probability-distribution-based node pruning for sphere decoding. IEEE Trans. Veh. Technol. 2013, 62, 1586–1596. [Google Scholar] [CrossRef]
- Chockalingam, A. Low-complexity algorithms for large-MIMO detection. In Proceedings of the 2010 4th International Symposium on Communications, Control and Signal Processing (ISCCSP), Limassol, Cyprus, 3–5 March 2010; pp. 1–6. [Google Scholar]
- Pereira, A.A., Jr.; Sampaio-Neto, R. A random-list based LAS algorithm for near-optimal detection in large-scale uplink multiuser MIMO systems. In Proceedings of the 19th International ITG Workshop on Smart Antennas, Ilmenau, Germany, 3–5 March 2015; pp. 1–5. [Google Scholar]
- Datta, T.; Srinidhi, N.; Chockalingam, A.; Rajan, B.S. Random restart reactive Tabu search algorithm for detection in large-MIMO systems. IEEE Commun. Lett. 2010, 14, 1107–1109. [Google Scholar] [CrossRef]
- Srinidhi, N.; Datta, T.; Chockalingam, A.; Rajan, B.S. Layered Tabu search algorithm for large-MIMO detection and a lower bound on ML performance. IEEE Trans. Commun. 2010, 59, 2955–2963. [Google Scholar] [CrossRef]
- Bai, L.; Li, T.; Liu, J.; Yu, Q.; Choi, J. Large-scale MIMO detection using MCMC approach with blockwise sampling. IEEE Trans. Commun. 2016, 64, 3697–3707. [Google Scholar] [CrossRef]
- Goldberger, J.; Leshem, A. MIMO detection for high-order QAM based on a Gaussian tree approximation. IEEE Trans. Inf. Theory 2011, 57, 4973–4982. [Google Scholar] [CrossRef]
- Goldberger, J. Improved MIMO detection based on successive tree approximations. In Proceedings of the 2013 IEEE International Symposium on Information Theory, Istanbul, Turkey, 7–12 July 2013; pp. 2004–2008. [Google Scholar]
- Céspedes, J.; Olmos, P.M.; Sánchez-Fernández, M.; Perez-Cruz, F. Expectation propagation detection for high-order high-dimensional MIMO systems. IEEE Trans. Commun. 2014, 62, 2840–2849. [Google Scholar] [CrossRef]
- Céspedes, J.; Olmos, P.M.; Sánchez-Fernández, M.; Perez-Cruz, F. Probabilistic MIMO Symbol Detection With Expectation Consistency Approximate Inference. IEEE Trans. Veh. Technol. 2018, 67, 3481–3494. [Google Scholar] [CrossRef]
- Tan, X.; Ueng, Y.; Zhang, Z.; You, X.; Zhang, C. A Low-Complexity Massive MIMO Detection Based on Approximate Expectation Propagation. IEEE Trans. Veh. Technol. 2019, 68, 7260–7272. [Google Scholar] [CrossRef]
- Ge, Y.; Tan, X.; Ji, Z.; Zhang, Z.; You, X.; Zhang, C. Improving Approximate Expectation Propagation Massive MIMO Detector With Deep Learning. IEEE Wirel. Commun. Lett. 2021, 10, 2145–2149. [Google Scholar] [CrossRef]
- Fuentes, J.J.; Santos, I.; Aradillas, J.C.; Sánchez-Fernández, M. A Low-Complexity Double EP-based Detector for Iterative Detection and Decoding in MIMO. IEEE Trans. Commun. 2021, 69, 1538–1547. [Google Scholar] [CrossRef]
- Wataru, T.; Keigo, T. Pilot Decontamination in Spatially Correlated Massive MIMO Uplink via Expectation Propagation. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2021, E104/A, 723–733. [Google Scholar]
- Rashid, M.; Naraghi-Pour, M. Clustered Sparse Channel Estimation for Massive MIMO Systems by Expectation Maximization-Propagation (EM-EP). IEEE Trans. Veh. Technol. 2023, 72, 9145–9159. [Google Scholar] [CrossRef]
Figure 1.
BER comparison of GTA-EC with existing algorithms when with 16-QAM.

Figure 2.
BER comparison of GTA-EC with existing algorithms when with 64-QAM.

Figure 3.
BER comparison of GTA-EC with existing algorithms when with 256-QAM.

Figure 4.
BER comparison of GTA-EC with existing algorithms when with 16-QAM.

Figure 5.
BER comparison of GTA-EC with existing algorithms when with 64-QAM.

Figure 6.
BER comparison of GTA-EC with existing algorithms when with 256-QAM.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparisons of complexity.
| Algorithm | Factor Substitution | Inner Approximation | Detection and Factor Updating | Total Complexity |
|---|---|---|---|---|
| MMSE | ||||
| GTA | ||||
| EC | ||||
| GTA-EC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Wang, Q. Nested Variational Chain and Its Application in Massive MIMO Detection for High-Order Constellations. Entropy 2023, 25, 1621. https://doi.org/10.3390/e25121621
AMA Style
Wang Q. Nested Variational Chain and Its Application in Massive MIMO Detection for High-Order Constellations. Entropy. 2023; 25(12):1621. https://doi.org/10.3390/e25121621
Chicago/Turabian StyleWang, Qiwei. 2023. "Nested Variational Chain and Its Application in Massive MIMO Detection for High-Order Constellations" Entropy 25, no. 12: 1621. https://doi.org/10.3390/e25121621
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.