
Improving Existing Segmentators Performance with Zero-Shot Segmentators




Abstract
:1. Introduction
- Zero-shot segmentators are trained on more images (billions of them, in the case of SAM) than mainstream and specialized models. This fact may allow them to beat the SOTA in some circumstances.
- Differences in the architecture and training set of the zero-shot segmentator with respect to the mainstream and/or specialized models are a source of diversity, which is the ideal prerequisite for a strong ensemble. The literature shows that ensemble models have repeatedly improved the SOTA on several tasks. Indeed, in this paper our approach allows us to improve the SOTA with an ensemble, as better explained later.
2. Related Work
2.1. Deep Learning-Based Segmentation Methods
2.2. Zero-Shot Learning in Segmentation
2.3. Combining Continuous Outputs
3. Methodology
3.1. DeepLabv3+ Architecture
3.2. Pyramid Vision Transformer Architecture
- we apply two different data augmentation, defined in [24]: DA1, a base data augmentation consisting in horizontal and vertical flip, 90° rotation; DA2, which applies a rich set of diverse operations to derive new images from the original ones. These operations encompass shadowing, color mapping, vertical or horizontal flipping, and others.
- we apply three different learning strategies: learning rate of ; learning rate of decaying to after 10 epochs; learning rate of decaying to after 15 epochs and to after 30 epochs.
3.3. SAM Architecture
3.4. SEEM Architecture
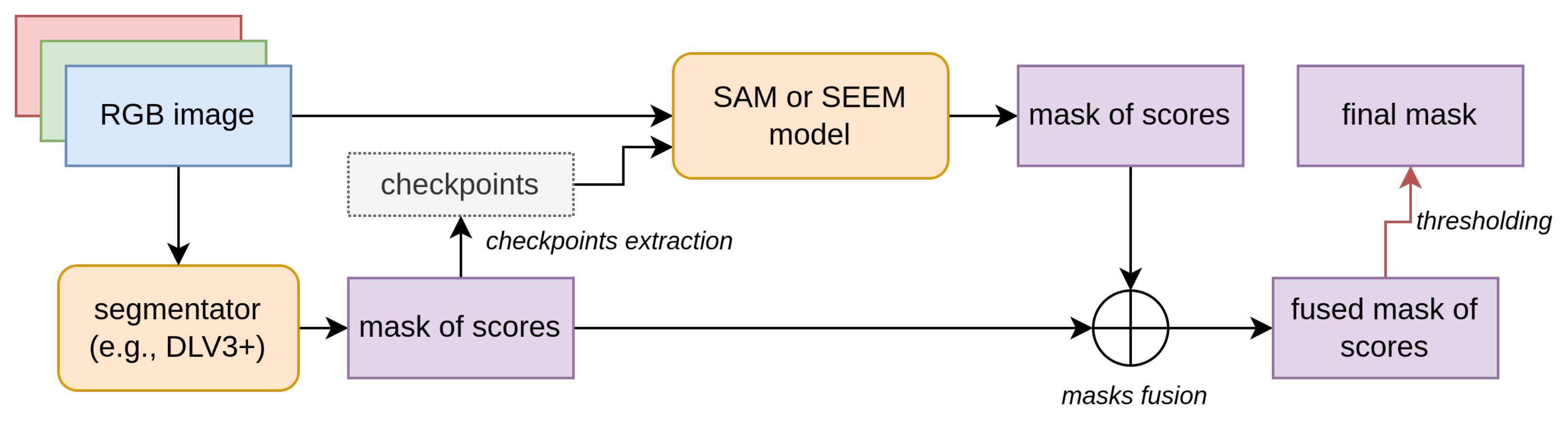
3.5. Checkpoint Engineering
- A
- selects the average coordinates of the blob as the checkpoint. While simple and straightforward, a drawback of this method is that checkpoints may occasionally fall outside the blob region.
- B
- determines the center of mass of the blob as the checkpoint. It is similar to Method A and is relatively simple, but we observed that the extracted checkpoints are less likely to lie outside the blob region.
- C
- randomly selects a point within the blob region as the checkpoint. The primary advantage of this method is its simplicity and efficiency. By randomly selecting a point within the blob, a diverse range of checkpoints can be generated.
- D
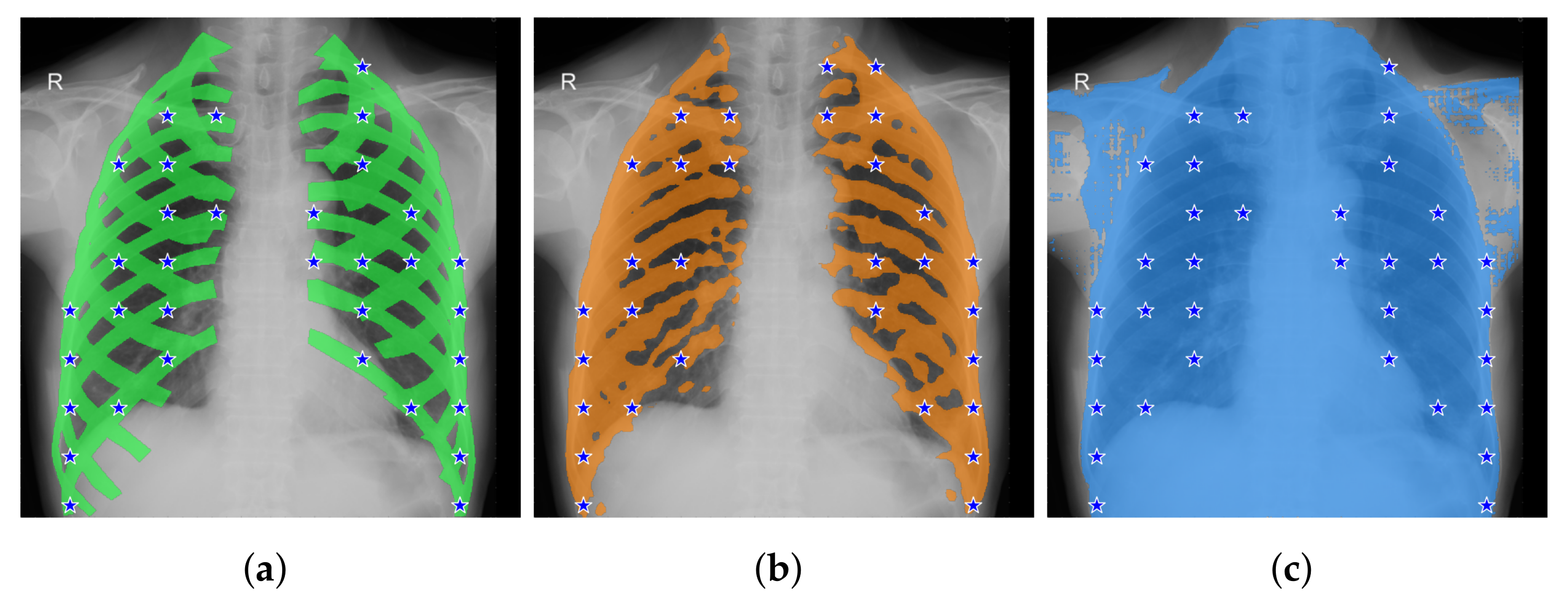
- enables the selection of multiple checkpoints within the blob region. Initially, a grid is created with uniform sampling steps of size b in both the x and the y directions. Checkpoints are chosen from the grid if they fall within the blob region. We also applied a modified version of this method that considers eroded (smaller) masks. In Table 2, this modified version is referred to as “bm” (border mode). Erosion is a morphological image processing technique used to reduce the boundaries of objects in a segmentation mask. It works by applying a predefined kernel, in our case an elliptical-shaped kernel with a size of 10 × 10 pixels, to the mask. The kernel slides through the image, and for each position, if all the pixels covered by the kernel are part of the object (i.e., white), the central pixel of the kernel is set to belong to the output eroded mask. Otherwise, it is set to background (i.e., black). This process effectively erodes the boundaries of the objects in the mask, making them smaller and removing noise or irregularities around the edges. In certain cases, this method (both eroded and not) may fail to find any checkpoints inside certain blobs. To address this, we implemented a fallback strategy: the grid of checkpoints is shifted horizontally and then vertically, continuing this process while no part of the grid overlaps with the segmentation mask. The pseudo-code for Method D, including the fallback strategy, is provided in Algorithm 1.
| Algorithm 1 Method D with mask erosion and fallback strategy. |
 |
4. Experimental Setup
4.1. Datasets
4.2. Performance Metrics
4.3. Baseline Extraction
4.4. Implementation Details
4.5. Refinement Step Description
| Algorithm 2 Combining continuous outputs of SAM and segmentator model. |
 |
- Combining complementary information: SAM and DeepLabv3+ have different strengths and weaknesses in capturing certain object details or handling specific image characteristics. By combining their logits through the weighted rule, we can leverage the complementary information captured by each model. This can lead to a more comprehensive representation of the object boundaries and semantic regions, resulting in a more accurate final segmentation.
- Noise reduction and consensus: the weighted-rule approach helps reduce the impact of noise or uncertainties in individual model predictions. By combining the logits, the noise or errors inherent in one model’s prediction may be offset or diminished by the other model’s more accurate predictions. This consensus-based aggregation can effectively filter out noisy predictions.
- Addressing model biases: different models can exhibit biases or tendencies in their predictions due to architectural differences, training data biases, or inherent limitations. The refinement step enables the combination of predictions from multiple models, mitigating the impact of any model biases and enhancing the overall robustness of the segmentation.
- Enhanced object boundary localization: the weighted rule of logits can help improve the localization and delineation of object boundaries. As the logits from both models contribute to the final segmentation, the refinement step tends to emphasize areas of high consensus, resulting in sharper and more accurate object boundaries. This can be particularly beneficial in cases where individual models may struggle with precise boundary detection.
5. Results and Discussion
5.1. Results
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the 15th European Conference on Computer Vision—ECCV, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Gao, J.; Lee, Y.J. Segment Everything Everywhere All at Once. arXiv 2023, arXiv:2304.06718. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved baselines with Pyramid Vision Transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Online, 3–7 May 2021. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Proceedings of the 16th European Conference on Computer Vision—ECCV 2020, Glasgow, UK, 23–28 2August 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021), Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2021; Volume 34, pp. 12077–12090. [Google Scholar]
- Wang, W.; Zhou, T.; Yu, F.; Dai, J.; Konukoglu, E.; Gool, L.V. Exploring Cross-Image Pixel Contrast for Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 7283–7293. [Google Scholar] [CrossRef]
- Liang, C.; Wang, W.; Miao, J.; Yang, Y. GMMSeg: Gaussian Mixture based Generative Semantic Segmentation Models. In Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022), New Orleans, LA, USA, 28 November–9 December 2022; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 31360–31375. [Google Scholar]
- Ke, L.; Ye, M.; Danelljan, M.; Liu, Y.; Tai, Y.W.; Tang, C.K.; Yu, F. Segment Anything in High Quality. arXiv 2023, arXiv:2306.01567. [Google Scholar]
- Wu, J.; Zhang, Y.; Fu, R.; Fang, H.; Liu, Y.; Wang, Z.; Xu, Y.; Jin, Y. Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation. arXiv 2023, arXiv:2304.12620. [Google Scholar]
- Cheng, D.; Qin, Z.; Jiang, Z.; Zhang, S.; Lao, Q.; Li, K. SAM on Medical Images: A Comprehensive Study on Three Prompt Modes. arXiv 2023, arXiv:2305.00035. [Google Scholar]
- Hu, C.; Xia, T.; Ju, S.; Li, X. When SAM Meets Medical Images: An Investigation of Segment Anything Model (SAM) on Multi-phase Liver Tumor Segmentation. arXiv 2023, arXiv:2304.08506. [Google Scholar]
- He, S.; Bao, R.; Li, J.; Stout, J.; Bjornerud, A.; Grant, P.E.; Ou, Y. Computer-Vision Benchmark Segment-Anything Model (SAM) in Medical Images: Accuracy in 12 Datasets. arXiv 2023, arXiv:2304.0932. [Google Scholar]
- Zhang, Y.; Zhou, T.; Wang, S.; Liang, P.; Chen, D.Z. Input Augmentation with SAM: Boosting Medical Image Segmentation with Segmentation Foundation Model. arXiv 2023, arXiv:2304.11332. [Google Scholar]
- Shaharabany, T.; Dahan, A.; Giryes, R.; Wolf, L. AutoSAM: Adapting SAM to Medical Images by Overloading the Prompt Encoder. arXiv 2023, arXiv:2306.06370. [Google Scholar]
- Kuncheva, L.I. Diversity in multiple classifier systems. Inf. Fusion 2005, 6, 3–4. [Google Scholar] [CrossRef]
- Kittler, J. Combining classifiers: A theoretical framework. Pattern Anal. Appl. 1998, 1, 18–27. [Google Scholar] [CrossRef]
- Nanni, L.; Brahnam, S.; Lumini, A. Ensemble of Deep Learning Approaches for ATC Classification. In Proceedings of the Third International Conference on Smart Computing and Informatics, Bhubaneshwar, India, 21–22 December 2018; Satapathy, S.C., Bhateja, V., Mohanty, J.R., Udgata, S.K., Eds.; Springer: Singapore, 2020; pp. 117–125. [Google Scholar] [CrossRef]
- Melotti, G.; Premebida, C.; Goncalves, N.M.M.d.S.; Nunes, U.J.C.; Faria, D.R. Multimodal CNN Pedestrian Classification: A Study on Combining LIDAR and Camera Data. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3138–3143. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A.; Loreggia, A.; Formaggio, A.; Cuza, D. An Empirical Study on Ensemble of Segmentation Approaches. Signals 2022, 3, 341–358. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the 13th European Conference on Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.T.; Sugimoto, A. Anabranch Network for Camouflaged Object Segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Kim, Y.W.; Byun, Y.C.; Krishna, A.V.N. Portrait Segmentation Using Ensemble of Heterogeneous Deep-Learning Models. Entropy 2021, 23, 197. [Google Scholar] [CrossRef]
- Liu, L.; Liu, M.; Meng, K.; Yang, L.; Zhao, M.; Mei, S. Camouflaged locust segmentation based on PraNet. Comput. Electron. Agric. 2022, 198, 107061. [Google Scholar] [CrossRef]
- Nguyen, H.C.; Le, T.T.; Pham, H.H.; Nguyen, H.Q. VinDr-RibCXR: A benchmark dataset for automatic segmentation and labeling of individual ribs on chest X-rays. In Proceedings of the 2021 International Conference on Medical Imaging with Deep Learning (MIDL 2021), Lubeck, Germany, 7–9 July 2021. [Google Scholar]
- Lumini, A.; Nanni, L. Fair comparison of skin detection approaches on publicly available datasets. Expert Syst. Appl. 2020, 160, 113677. [Google Scholar] [CrossRef]
- Wang, J.; Markert, K.; Everingham, M. Learning Models for Object Recognition from Natural Language Descriptions. In Proceedings of the British Machine Vision Conference, London, UK, 7–10 September 2009. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Proceedings of the 12th International Symposium on Visual Computing (ISVC 2016), Las Vegas, NV, USA, 12–14 December 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 234–244. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, J.M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Proceedings of the Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Quebec City, QC, Canada, 14 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar] [CrossRef]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar] [CrossRef]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to Evaluate Foreground Maps. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 248–255. [Google Scholar] [CrossRef]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-Measure: A New Way to Evaluate Foreground Maps. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4558–4567. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Liu, W.; Shen, X.; Pun, C.M.; Cun, X. Explicit Visual Prompting for Universal Foreground Segmentations. arXiv 2023, arXiv:2305.18476. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Short Name | Complete Name | Num of Samples |
|---|---|---|
| CMQ | Compaq | 4675 |
| ECU | ECU Face and Skin Detection | 2000 |
| HGR | Hand Gesture Recognition | 1558 |
| MCG | MCG-skin | 1000 |
| Prat | Pratheepan | 78 |
| Sch | Schmugge dataset | 845 |
| SFA | SFA | 1118 |
| UC | UChile DB-skin | 103 |
| VMD | Human activity recognition | 285 |
| VT | VT-AAST | 66 |
| CAMO | Portrait | Locust-Mini | VinDr-RibCXR | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | ||||||||||||
| Baseline (DLV3+) | 60.63 | 71.75 | 97.01 | 98.46 | 74.34 | 83.01 | 63.48 | 77.57 | |||||||||||
| PVTv2-Ensemble | 71.75 | 81.07 | |||||||||||||||||
| Oracle | DLV3+ | PVTv2 | Oracle | DLV3+ | Oracle | DLV3+ | Oracle | DLV3+ | |||||||||||
| Model | Method | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice | IoU | Dice |
| SAM-ViT-L | A | 51.26 | 60.42 | 47.96 | 58.36 | 49.95 | 59.97 | 57.31 | 67.96 | 55.50 | 66.49 | 48.43 | 59.56 | 35.45 | 46.15 | 37.30 | 53.96 | 30.00 | 45.76 |
| B | 50.57 | 59.66 | 48.10 | 58.49 | 49.73 | 59.72 | 57.43 | 68.04 | 55.48 | 66.41 | 48.55 | 59.81 | 35.53 | 46.22 | 37.30 | 53.96 | 29.98 | 45.73 | |
| C | 44.30 | 53.50 | 44.06 | 54.53 | 44.21 | 53.89 | 55.24 | 65.20 | 52.28 | 62.57 | 36.50 | 45.77 | 34.10 | 44.36 | 31.43 | 47.45 | 28.83 | 44.41 | |
| D 10 | 37.87 | 51.54 | 38.01 | 51.03 | 36.64 | 49.93 | 77.59 | 85.96 | 77.64 | 86.01 | 21.47 | 33.22 | 23.14 | 35.02 | 25.66 | 40.65 | 25.64 | 40.62 | |
| D 30 | 62.75 | 73.61 | 58.81 | 69.45 | 59.31 | 69.95 | 91.99 | 95.55 | 91.87 | 95.47 | 48.05 | 59.62 | 51.93 | 63.56 | 26.77 | 42.06 | 26.97 | 42.34 | |
| D 50 | 67.29 | 76.93 | 59.84 | 69.62 | 62.89 | 72.49 | 95.97 | 97.91 | 95.72 | 97.77 | 56.46 | 66.97 | 59.48 | 69.88 | 28.24 | 43.76 | 27.96 | 43.51 | |
| D 100 | 61.74 | 69.92 | 53.23 | 61.73 | 57.00 | 65.52 | 96.31 | 98.09 | 96.16 | 98.00 | 50.67 | 59.70 | 51.89 | 60.66 | 29.99 | 45.80 | 29.62 | 45.40 | |
| D 10 bm | 44.42 | 57.99 | 41.11 | 53.92 | 40.29 | 53.31 | 78.09 | 86.34 | 78.15 | 86.39 | 35.42 | 48.34 | 27.33 | 39.73 | 26.57 | 41.82 | 25.75 | 40.77 | |
| D 30 bm | 67.17 | 77.44 | 60.13 | 70.47 | 60.98 | 71.25 | 92.41 | 95.81 | 92.23 | 95.71 | 59.11 | 70.08 | 54.32 | 65.73 | 29.26 | 45.01 | 26.96 | 42.32 | |
| D 50 bm | 69.40 | 78.71 | 60.89 | 70.73 | 63.02 | 72.67 | 96.01 | 97.93 | 95.79 | 97.81 | 61.89 | 72.28 | 59.74 | 70.21 | 30.19 | 46.04 | 28.01 | 43.58 | |
| D 100 bm | 62.80 | 71.67 | 54.05 | 62.91 | 58.01 | 66.98 | 96.26 | 98.06 | 96.16 | 98.01 | 53.09 | 62.34 | 52.69 | 61.77 | 31.86 | 47.82 | 29.39 | 45.03 | |
| SAM-ViT-H | A | 50.87 | 59.77 | 50.56 | 60.62 | 52.49 | 62.07 | 54.24 | 64.63 | 51.42 | 62.35 | 48.83 | 60.11 | 40.09 | 51.05 | 33.78 | 50.10 | 31.21 | 47.23 |
| B | 50.55 | 59.44 | 50.57 | 60.61 | 52.42 | 61.99 | 54.33 | 64.79 | 51.75 | 62.67 | 48.91 | 60.21 | 40.89 | 51.80 | 33.76 | 50.08 | 31.14 | 47.14 | |
| C | 45.68 | 54.43 | 47.32 | 57.34 | 49.14 | 58.63 | 48.83 | 59.31 | 48.01 | 58.49 | 42.46 | 52.03 | 34.21 | 44.30 | 29.23 | 44.76 | 30.37 | 46.24 | |
| D 10 | 60.80 | 72.85 | 53.53 | 66.36 | 54.86 | 67.40 | 77.19 | 86.11 | 76.91 | 85.88 | 40.50 | 55.19 | 40.18 | 54.47 | 28.94 | 44.73 | 29.01 | 44.80 | |
| D 30 | 78.49 | 86.37 | 65.44 | 75.46 | 70.19 | 79.28 | 92.73 | 96.14 | 92.24 | 95.85 | 70.81 | 80.78 | 68.64 | 78.43 | 37.79 | 54.65 | 38.17 | 55.07 | |
| D 50 | 77.93 | 85.81 | 63.46 | 73.00 | 69.83 | 78.49 | 96.38 | 98.14 | 95.98 | 97.92 | 67.85 | 77.92 | 68.89 | 78.69 | 37.89 | 54.61 | 38.67 | 55.48 | |
| D 100 | 66.65 | 73.95 | 55.45 | 63.55 | 59.97 | 67.94 | 95.01 | 97.40 | 94.76 | 97.26 | 51.64 | 60.55 | 53.54 | 62.14 | 31.22 | 47.18 | 31.37 | 47.41 | |
| D 10 bm | 65.27 | 76.57 | 55.01 | 67.53 | 56.71 | 68.86 | 77.31 | 86.18 | 77.00 | 85.93 | 57.04 | 70.34 | 45.88 | 59.23 | 35.79 | 52.51 | 29.46 | 45.36 | |
| D 30 bm | 78.12 | 86.46 | 64.95 | 75.18 | 69.81 | 79.10 | 92.96 | 96.27 | 92.54 | 96.02 | 71.51 | 81.53 | 68.67 | 78.58 | 39.41 | 56.23 | 38.16 | 55.05 | |
| D 50 bm | 76.02 | 84.26 | 63.37 | 73.21 | 69.00 | 77.98 | 96.38 | 98.14 | 95.98 | 97.92 | 68.05 | 78.34 | 68.53 | 78.46 | 35.53 | 51.95 | 38.45 | 55.22 | |
| D 100 bm | 67.02 | 75.45 | 56.22 | 64.67 | 61.75 | 70.10 | 94.99 | 97.38 | 94.74 | 97.25 | 53.26 | 62.54 | 54.56 | 63.44 | 31.13 | 46.99 | 31.28 | 47.28 | |
| SEEM | A | 48.24 | 55.46 | 38.58 | 44.58 | 38.12 | 44.52 | 93.52 | 95.73 | 92.94 | 95.23 | 39.20 | 47.81 | 35.87 | 43.31 | 32.13 | 48.42 | 32.12 | 48.41 |
| B | 48.24 | 55.46 | 38.37 | 44.38 | 37.82 | 44.21 | 93.52 | 95.73 | 92.94 | 95.23 | 39.20 | 47.81 | 35.87 | 43.31 | 32.13 | 48.42 | 32.12 | 48.41 | |
| C | 44.64 | 51.09 | 41.65 | 47.76 | 33.97 | 39.67 | 92.31 | 94.45 | 89.84 | 92.14 | 32.98 | 40.61 | 26.25 | 32.73 | 31.58 | 47.78 | 31.90 | 48.18 | |
| D 10 | 57.77 | 65.56 | 53.82 | 61.56 | 45.39 | 52.46 | 95.90 | 97.88 | 95.87 | 97.86 | 63.93 | 72.13 | 58.21 | 65.93 | 32.15 | 48.46 | 32.05 | 48.35 | |
| D 30 | 57.18 | 64.76 | 53.37 | 61.08 | 52.74 | 60.16 | 95.89 | 97.87 | 95.86 | 97.86 | 61.97 | 69.96 | 59.54 | 67.14 | 32.13 | 48.43 | 32.12 | 48.42 | |
| D 50 | 55.09 | 62.23 | 51.64 | 58.74 | 50.91 | 58.10 | 95.85 | 97.85 | 95.84 | 97.84 | 59.30 | 67.12 | 58.35 | 65.94 | 31.98 | 48.26 | 32.05 | 48.33 | |
| D 100 | 51.92 | 58.68 | 49.14 | 55.89 | 50.38 | 57.16 | 95.80 | 97.83 | 95.80 | 97.82 | 47.42 | 55.07 | 43.45 | 50.74 | 31.79 | 48.03 | 31.83 | 48.08 | |
| D 10 bm | 58.89 | 66.79 | 54.26 | 62.11 | 52.97 | 60.75 | 95.92 | 97.89 | 95.91 | 97.88 | 62.39 | 70.80 | 57.33 | 65.59 | 32.17 | 48.48 | 32.12 | 48.42 | |
| D 30 bm | 57.57 | 65.25 | 53.27 | 61.03 | 52.87 | 60.29 | 95.92 | 97.89 | 95.91 | 97.88 | 60.79 | 68.74 | 58.10 | 65.68 | 32.07 | 48.35 | 32.11 | 48.42 | |
| D 50 bm | 55.11 | 62.38 | 51.62 | 58.65 | 51.55 | 58.77 | 95.89 | 97.87 | 95.89 | 97.87 | 58.16 | 66.20 | 57.05 | 64.71 | 31.94 | 48.19 | 32.05 | 48.33 | |
| D 100 bm | 51.78 | 58.62 | 48.83 | 55.53 | 49.86 | 56.67 | 95.81 | 97.83 | 95.79 | 97.82 | 47.67 | 55.43 | 43.82 | 51.14 | 31.71 | 47.94 | 31.82 | 48.06 | |
| FUSION | D 30 | - | - | 63.87 | 74.41 | 73.31 | 82.02 | - | - | 97.13 | 98.53 | - | - | 75.99 | 84.21 | - | - | 60.96 | 75.64 |
| D 50 | - | - | 62.95 | 73.36 | 73.46 | 82.02 | - | - | 97.18 | 98.55 | - | - | 75.74 | 84.07 | - | - | 60.65 | 75.41 | |
| D 30 bm | - | - | 63.48 | 74.18 | 73.13 | 81.92 | - | - | 97.14 | 98.53 | - | - | 76.01 | 84.23 | - | - | 60.95 | 75.63 | |
| D 50 bm | - | - | 63.03 | 73.54 | 73.27 | 81.94 | - | - | 97.17 | 98.55 | - | - | 75.74 | 84.07 | - | - | 60.67 | 75.43 | |
| COCO_Animals | DLV3+ | SAM-DLV3+ | SAM ⓦ DLV3+ | *DLV3+ | SAM-*DLV3+ | SAM ⓦ *DLV3+ |
|---|---|---|---|---|---|---|
| IoU ↑ | 66.04 | 67.45 | 69.15 | 54.61 | 65.59 | 68.24 |
| Dice ↑ | 75.93 | 75.19 | 77.93 | 66.53 | 73.17 | 77.26 |
| DLV3+ | SAM-DLV3+ | SAM ⓦ DLV3+ | SOTA | SAM-SOTA | SAM ⓦ SOTA | ||
|---|---|---|---|---|---|---|---|
| IoU↑ | 95.57 | 92.57 | 96.11 | 96.95 | 93.85 | 96.92 | |
| 95.68 | 93.28 | 96.13 | 97.13 | 93.52 | 97.15 | ||
| 95.26 | 92.81 | 95.71 | 97.00 | 93.92 | 97.04 | ||
| 95.37 | 92.55 | 96.07 | 96.90 | 94.09 | 96.92 | ||
| Dice↑ | 97.72 | 95.80 | 98.01 | 98.44 | 96.73 | 98.43 | |
| 97.78 | 96.44 | 98.01 | 98.54 | 96.57 | 98.55 | ||
| 97.53 | 96.13 | 97.77 | 98.47 | 96.81 | 98.49 | ||
| 97.62 | 95.75 | 97.98 | 98.42 | 96.91 | 98.43 |
| DLV3+ | SAM-DLV3+ | SAM ⓦ DLV3+ | PVTv2 | SAM-PVTv2 | SAM ⓦ PVTv2 | ||
|---|---|---|---|---|---|---|---|
| IoU↑ | 73.58 | 68.22 | 74.37 | 76.62 | 68.09 | 76.75 | |
| 90.34 | 86.26 | 90.31 | 91.30 | 86.38 | 91.34 | ||
| 94.32 | 94.42 | 94.73 | 94.34 | 94.35 | 94.64 | ||
| 79.81 | 79.34 | 80.67 | 80.74 | 79.70 | 81.33 | ||
| 85.75 | 73.81 | 86.63 | 86.16 | 74.85 | 87.14 | ||
| 63.72 | 52.02 | 63.07 | 66.15 | 53.68 | 65.51 | ||
| 90.72 | 91.58 | 91.56 | 91.25 | 91.72 | 91.80 | ||
| 84.71 | 67.00 | 85.67 | 87.49 | 62.89 | 82.99 | ||
| 59.49 | 33.51 | 60.86 | 59.78 | 33.33 | 59.31 | ||
| 65.96 | 47.28 | 69.48 | 74.59 | 47.65 | 76.64 | ||
| Dice↑ | 84.78 | 81.11 | 85.30 | 86.77 | 81.01 | 86.85 | |
| 94.92 | 92.63 | 94.91 | 95.45 | 92.69 | 95.48 | ||
| 97.08 | 97.13 | 97.29 | 97.09 | 97.09 | 97.25 | ||
| 88.77 | 88.48 | 89.30 | 89.34 | 88.70 | 89.71 | ||
| 92.33 | 84.93 | 92.84 | 92.57 | 85.62 | 93.13 | ||
| 77.84 | 68.44 | 77.35 | 79.63 | 69.86 | 79.16 | ||
| 95.13 | 95.61 | 95.59 | 95.42 | 95.68 | 95.73 | ||
| 91.72 | 80.24 | 92.28 | 93.33 | 77.22 | 90.70 | ||
| 74.60 | 50.20 | 75.67 | 74.83 | 50.00 | 74.46 | ||
| 79.49 | 64.21 | 81.99 | 85.45 | 64.54 | 86.78 |
| IoU ↑ | Dice ↑ | MAE ↓ | F-Score ↑ | E-Measure ↑ | |
|---|---|---|---|---|---|
| DLV3+ | 60.63 | 71.75 | 8.39 | 75.57 | 83.04 |
| PVTv2-ensemble | 71.75 | 81.07 | 5.74 | 82.46 | 89.96 |
| EVPv2 (current SOTA) | - | - | 5.80 | 78.60 | 89.90 |
| SAM-DLV3+ | 63.46 | 73.00 | 9.78 | 74.25 | 81.90 |
| SAM ⓦ DLV3+ | 62.95 | 73.36 | 8.02 | 76.92 | 83.49 |
| SAM-PVTv2 | 69.83 | 78.49 | 7.67 | 78.96 | 86.21 |
| SAM ⓦ PVTv2 | 73.46 | 82.02 | 5.45 | 83.56 | 90.00 |
| Dataset | Metric | DLV3+ | PVTv2 | DLV3+ ⓐ PVTv2 | DLV3+ ⓦ PVTv2 | SAM ⓦ DLV3+ | SAM ⓦ PVTv2 |
|---|---|---|---|---|---|---|---|
| CAMO | IoU ↑ | 60.63 | 71.75 | 69.32 | 71.23 | 62.95 | 73.46 |
| Dice ↑ | 71.75 | 81.07 | 79.16 | 80.60 | 73.36 | 82.02 | |
| CMQ | IoU ↑ | 73.58 | 76.62 | 77.09 | 77.30 | 74.37 | 76.75 |
| Dice ↑ | 84.78 | 86.77 | 87.07 | 87.20 | 85.30 | 86.85 | |
| ECU | IoU ↑ | 90.34 | 91.30 | 91.55 | 91.54 | 90.31 | 91.34 |
| Dice ↑ | 94.92 | 95.45 | 95.59 | 95.58 | 94.91 | 95.48 | |
| HGR | IoU ↑ | 94.32 | 94.34 | 94.66 | 94.55 | 94.73 | 94.64 |
| Dice ↑ | 97.08 | 97.09 | 97.26 | 97.20 | 97.29 | 97.25 | |
| MCG | IoU ↑ | 79.81 | 80.74 | 80.85 | 80.85 | 80.67 | 81.33 |
| Dice ↑ | 88.77 | 89.34 | 89.41 | 89.41 | 89.30 | 89.71 | |
| Prat | IoU ↑ | 85.75 | 86.16 | 86.80 | 86.66 | 86.63 | 87.14 |
| Dice ↑ | 92.33 | 92.57 | 92.93 | 92.85 | 92.84 | 93.13 | |
| Sch | IoU ↑ | 63.72 | 66.15 | 66.88 | 67.27 | 63.07 | 65.51 |
| Dice ↑ | 77.84 | 79.63 | 80.15 | 80.43 | 77.35 | 79.16 | |
| SFA | IoU ↑ | 90.72 | 91.25 | 91.55 | 91.47 | 91.56 | 91.80 |
| Dice ↑ | 95.13 | 95.42 | 95.59 | 95.55 | 95.59 | 95.73 | |
| UC | IoU ↑ | 84.71 | 87.49 | 88.88 | 88.92 | 85.67 | 82.99 |
| Dice ↑ | 91.72 | 93.33 | 94.11 | 94.13 | 92.28 | 90.70 | |
| VMD | IoU ↑ | 59.49 | 59.78 | 63.51 | 63.41 | 60.86 | 59.31 |
| Dice ↑ | 74.60 | 74.83 | 77.68 | 77.61 | 75.67 | 74.46 | |
| VT | IoU ↑ | 65.96 | 74.59 | 71.73 | 73.04 | 69.48 | 76.64 |
| Dice ↑ | 79.49 | 85.45 | 83.54 | 84.42 | 81.99 | 86.78 | |
| IoU ↑ | 95.57 | 96.95 | 96.83 | 96.94 | 96.11 | 96.92 | |
| Dice ↑ | 97.72 | 98.44 | 98.38 | 98.44 | 98.01 | 98.43 | |
| IoU ↑ | 95.68 | 97.13 | 97.00 | 97.13 | 96.13 | 97.15 | |
| Dice ↑ | 97.78 | 98.54 | 98.47 | 98.54 | 98.01 | 98.55 | |
| IoU ↑ | 95.26 | 97.00 | 96.67 | 96.86 | 95.71 | 97.04 | |
| Dice ↑ | 97.53 | 98.47 | 98.29 | 98.39 | 97.77 | 98.49 | |
| IoU ↑ | 95.37 | 96.90 | 96.77 | 96.90 | 96.14 | 96.95 | |
| Dice ↑ | 97.62 | 98.42 | 98.35 | 98.42 | 97.98 | 98.43 |
| Dataset | Metric | DLV3+ | PVTv2 | DLV3+ ⓐ PVTv2 | DLV3+ ⓦ PVTv2 | SAM ⓦ DLV3+ | SAM ⓦ PVTv2 |
|---|---|---|---|---|---|---|---|
| CAMO | IoU ↑ | 60.63 | 71.75 | 69.32 | 71.23 | 62.95 | 73.46 |
| Dice ↑ | 71.75 | 81.07 | 79.16 | 80.60 | 73.36 | 82.02 | |
| Portrait | IoU ↑ | 97.01 | - | - | - | 97.18 | - |
| Dice ↑ | 98.46 | - | - | - | 98.55 | - | |
| Locust-mini | IoU ↑ | 74.34 | - | - | - | 75.74 | - |
| Dice ↑ | 83.01 | - | - | - | 84.07 | - | |
| VinDr-RibCXR | IoU ↑ | 63.48 | - | - | - | 60.65 | - |
| Dice ↑ | 77.57 | - | - | - | 75.41 | - | |
| SKIN | IoU ↑ | 78.84 | 80.84 | 81.35 | 81.50 | 79.73 | 80.74 |
| Dice ↑ | 87.67 | 88.99 | 89.33 | 89.44 | 88.25 | 88.92 | |
| Butterfly | IoU ↑ | 95.47 | 97.00 | 96.82 | 96.96 | 96.02 | 97.02 |
| Dice ↑ | 97.66 | 98.47 | 98.37 | 98.45 | 97.94 | 98.48 | |
| COCO animals | IoU ↑ | 66.04 | - | - | - | 69.15 | - |
| Dice ↑ | 75.93 | - | - | - | 77.93 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanni, L.; Fusaro, D.; Fantozzi, C.; Pretto, A. Improving Existing Segmentators Performance with Zero-Shot Segmentators. Entropy 2023, 25, 1502. https://doi.org/10.3390/e25111502
Nanni L, Fusaro D, Fantozzi C, Pretto A. Improving Existing Segmentators Performance with Zero-Shot Segmentators. Entropy. 2023; 25(11):1502. https://doi.org/10.3390/e25111502
Chicago/Turabian StyleNanni, Loris, Daniel Fusaro, Carlo Fantozzi, and Alberto Pretto. 2023. "Improving Existing Segmentators Performance with Zero-Shot Segmentators" Entropy 25, no. 11: 1502. https://doi.org/10.3390/e25111502