
TURBO: The Swiss Knife of Auto-Encoders



Abstract
:1. Introduction
- Highlighting the main limitations of the IBN principle and the need for a new framework;
- Introducing and explaining the details of the TURBO framework, and motivating several use cases;
- Reviewing well-known models with the lens of the TURBO framework, showing how it is a straightforward generalisation of them;
- Linking the TURBO framework to additional related models, opening the door to additional studies and applications;
- Showcasing several applications where the TURBO framework gives either state-of-the-art or competing results compared to existing methods.
2. Notations and Definitions
3. Background: From IBN to TURBO
3.1. Min-Max Game: Or Bottleneck Training
3.1.1. VAE from BIB-AE Perspectives
3.1.2. GAN from BIB-AE Perspectives
3.1.3. CLUB
3.2. Max-Max Game: Or Physically Meaningful Latent Space
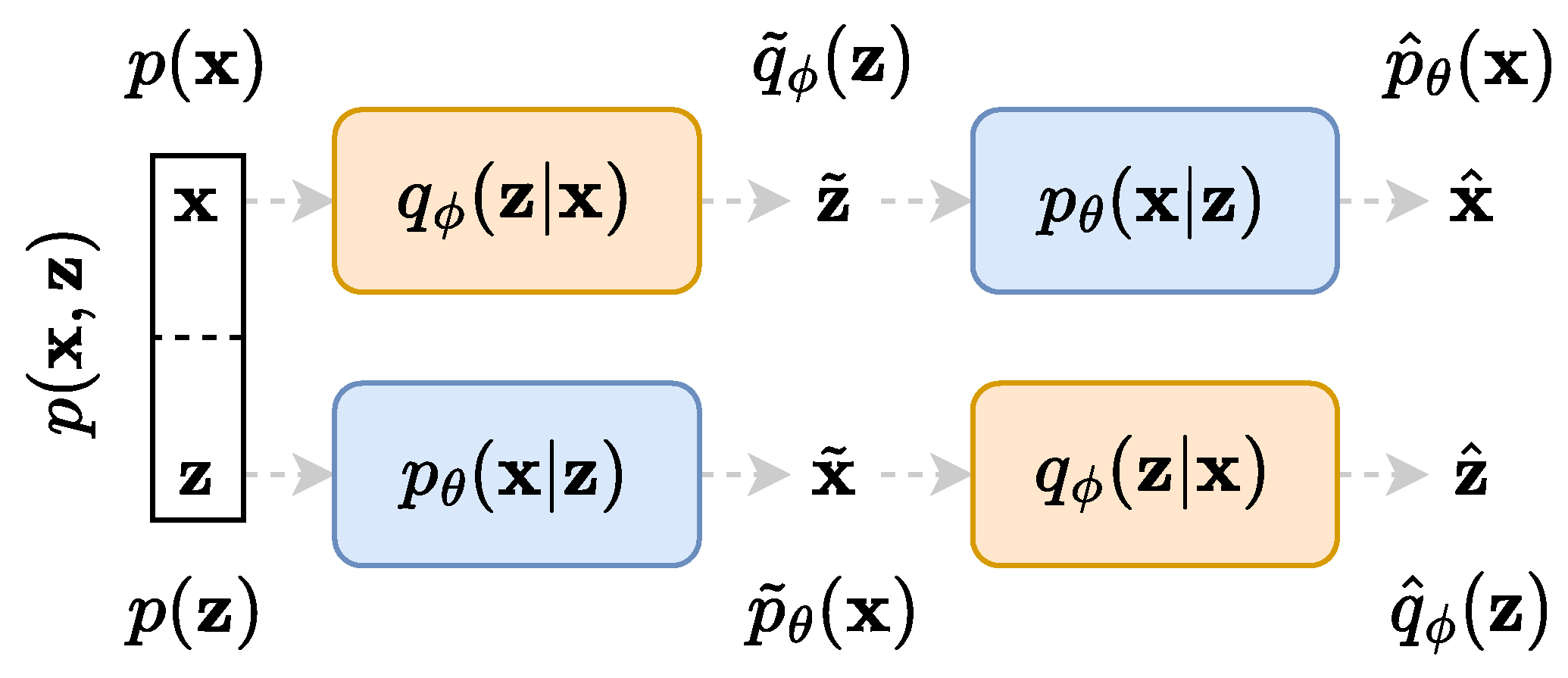
4. TURBO
4.1. General Objective Function
4.2. Generalisation of Many Models
4.2.1. AAE
4.2.2. GAN and WGAN
4.2.3. pix2pix and SRGAN
4.2.4. CycleGAN
4.2.5. Flows
4.3. Extension to Additional Models
ALAE
5. Applications
5.1. TURBO in High-Energy Physics: Turbo-Sim
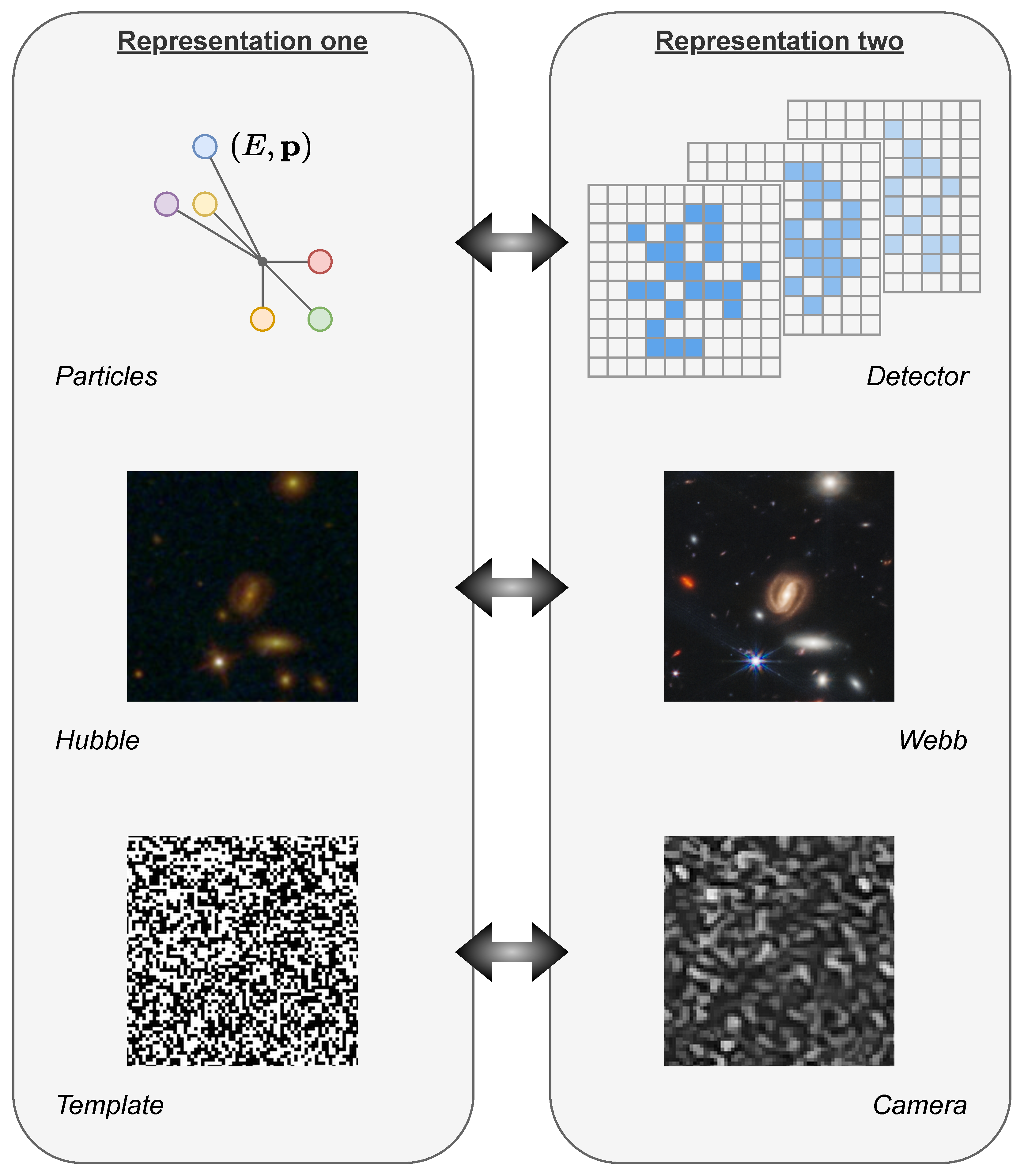
5.2. TURBO in Astronomy: Hubble-to-Webb
5.3. TURBO in Anti-Counterfeiting: Digital Twin
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| TURBO | Two-way Uni-directional Representations by Bounded Optimisation |
| IBN | Information Bottleneck |
| BIB-AE | Bounded Information Bottleneck Auto-Encoder |
| GAN | Generative Adversarial Network |
| WGAN | Wasserstein GAN |
| VAE | Variational Auto-Encoder |
| InfoVAE | Information maximising VAE |
| AAE | Adversarial Auto-Encoder |
| pix2pix | Image-to-Image Translation with Conditional GAN |
| SRGAN | Super-Resolution GAN |
| CycleGAN | Cycle-Consistent GAN |
| ALAE | Adversarial Latent Auto-Encoder |
| KLD | Kullback–Leibler Divergence |
| OTUS | Optimal-Transport-based Unfolding and Simulation |
| LPIPS | Learned Perceptual Image Patch Similarity |
| FID | Fréchet Inception Distance |
| MSE | Mean Squared Error |
| SSIM | Structural SIMilarity |
| PSNR | Peak Signal-to-Noise Ratio |
| CDP | Copy Detection Pattern |
| UMAP | Uniform Manifold Approximation and Projection |
Appendix A. Notations Summary

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| , , , , | Data joint, conditional and marginal distributions. Short notations for , , etc. |
| , , | Encoder joint and conditional distributions as defined in Equation (1). |
| Approximated marginal distribution of synthetic data in the encoder latent space. | |
| Approximated marginal distribution of synthetic data in the encoder reconstructed space. | |
| , , | Decoder joint and conditional distributions as defined in Equation (2). |
| Approximated marginal distribution of synthetic data in the decoder latent space. | |
| Approximated marginal distribution of synthetic data in the decoder reconstructed space. | |
| , , | Mutual information as defined in Equation (3) and below. Subscripts mean that parametrised distributions are involved in the space denoted by a tilde. |
| , , , | Lower bounds to mutual information as derived in Appendix C. Superscripts denote for which variable the corresponding loss terms are computed, subscripts denote the involved parametrised distributions and tildes follow the notations of the bounded mutual information. |
Appendix B. BIB-AE Full Derivation
Appendix B.1. Minimised Terms
Appendix B.2. Maximised Terms
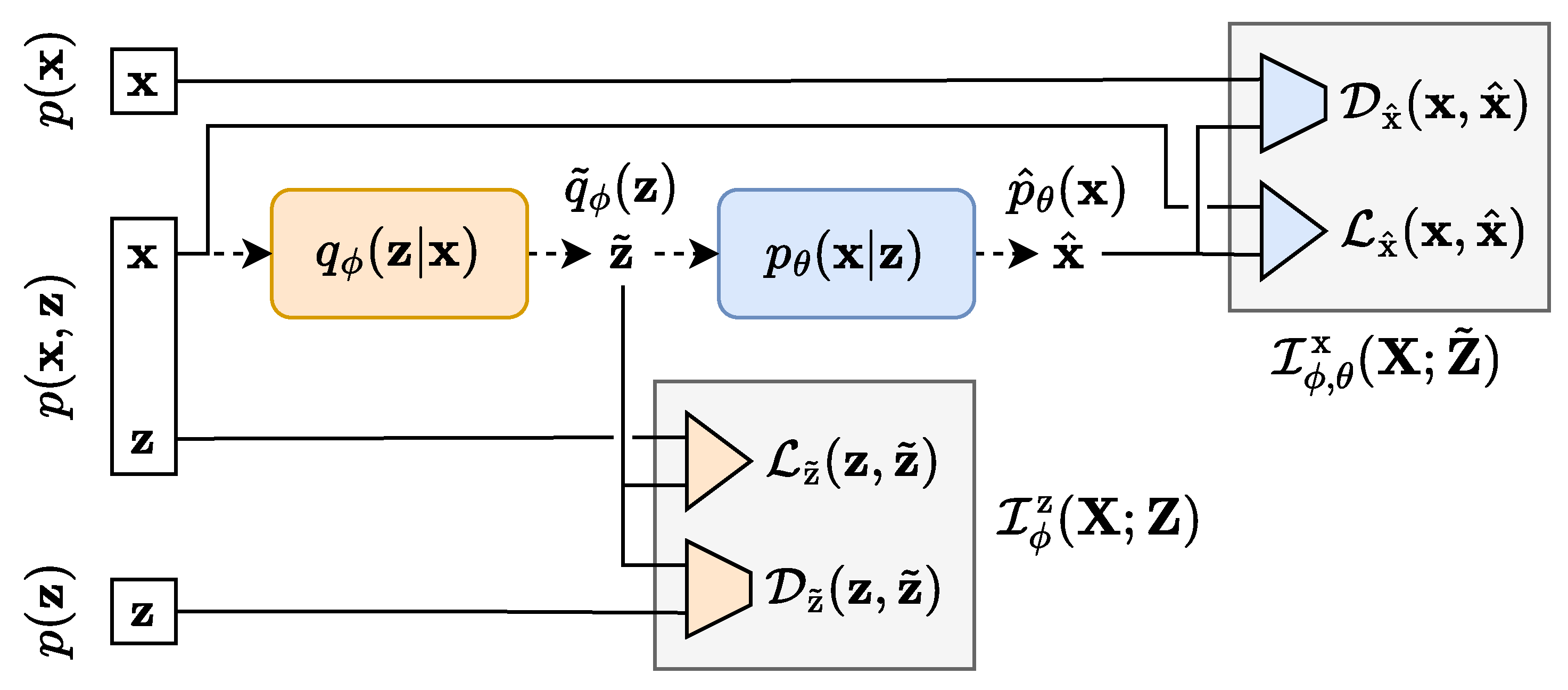
Appendix C. TURBO Full Derivation
Appendix C.1. Direct Path, Encoder Space
Appendix C.2. Direct Path, Decoder Space
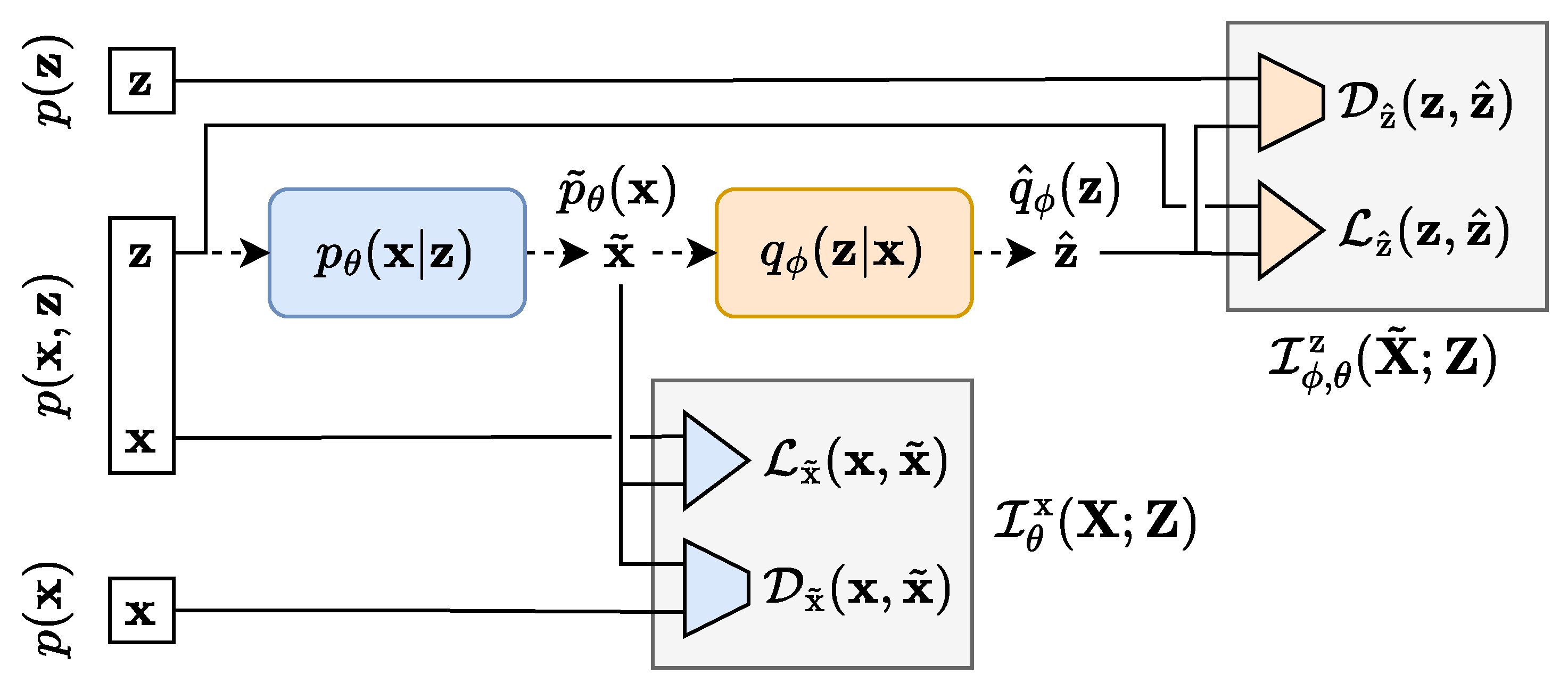
Appendix C.3. Reverse Path, Decoder Space
Appendix C.4. Reverse Path, Encoder Space
Appendix D. ALAE Modified Term
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. In Proceedings of the International Conference on Machine Learning, PMLR, Beijing, China, 21–26 June 2014; pp. 1278–1286. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial Autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the IEEE Information Theory Workshop, Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Voloshynovskiy, S.; Taran, O.; Kondah, M.; Holotyak, T.; Rezende, D. Variational Information Bottleneck for Semi-Supervised Classification. Entropy 2020, 22, 943. [Google Scholar] [CrossRef]
- Amjad, R.A.; Geiger, B.C. Learning Representations for Neural Network-Based Classification Using the Information Bottleneck Principle. IEEE Trans. Pattern. Anal. Mach. Intell. 2019, 42, 2225–2239. [Google Scholar] [CrossRef]
- Uğur, Y.; Arvanitakis, G.; Zaidi, A. Variational Information Bottleneck for Unsupervised Clustering: Deep Gaussian Mixture Embedding. Entropy 2020, 22, 213. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the Thirty-Seventh Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Voloshynovskiy, S.; Kondah, M.; Rezaeifar, S.; Taran, O.; Hotolyak, T.; Rezende, D.J. Information bottleneck through variational glasses. In Proceedings of the Workshop on Bayesian Deep Learning, NeurIPS, Vancouver, Canada, 13 December 2019. [Google Scholar]
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, PMLR, Virtually, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Shwartz-Ziv, R.; LeCun, Y. To Compress or Not to Compress–Self-Supervised Learning and Information Theory: A Review. arXiv 2023, arXiv:2304.09355. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational inference with normalizing flows. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 1530–1538. [Google Scholar]
- Pidhorskyi, S.; Adjeroh, D.A.; Doretto, G. Adversarial latent autoencoders. In Proceedings of the Conference on Computer Vision and Pattern Recognition, IEEE/CVF, Virtually, 14–19 June 2020; pp. 14104–14113. [Google Scholar]
- Achille, A.; Soatto, S. Information Dropout: Learning Optimal Representations Through Noisy Computation. IEEE Trans. Pattern. Anal. Mach. Intell. 2018, 40, 2897–2905. [Google Scholar] [CrossRef]
- Razeghi, B.; Calmon, F.P.; Gündüz, D.; Voloshynovskiy, S. Bottlenecks CLUB: Unifying Information-Theoretic Trade-Offs Among Complexity, Leakage, and Utility. IEEE Trans. Inf. Forensics Secur. 2023, 18, 2060–2075. [Google Scholar] [CrossRef]
- Tian, Y.; Pang, G.; Liu, Y.; Wang, C.; Chen, Y.; Liu, F.; Singh, R.; Verjans, J.W.; Wang, M.; Carneiro, G. Unsupervised Anomaly Detection in Medical Images with a Memory-augmented Multi-level Cross-attentional Masked Autoencoder. arXiv 2022, arXiv:2203.11725. [Google Scholar]
- Patel, A.; Tudiosu, P.D.; Pinaya, W.H.; Cook, G.; Goh, V.; Ourselin, S.; Cardoso, M.J. Cross Attention Transformers for Multi-modal Unsupervised Whole-Body PET Anomaly Detection. J. Mach. Learn. Biomed. Imaging 2023, 2, 172–201. [Google Scholar] [CrossRef]
- Golling, T.; Nobe, T.; Proios, D.; Raine, J.A.; Sengupta, D.; Voloshynovskiy, S.; Arguin, J.F.; Martin, J.L.; Pilette, J.; Gupta, D.B.; et al. The Mass-ive Issue: Anomaly Detection in Jet Physics. arXiv 2023, arXiv:2303.14134. [Google Scholar]
- Buhmann, E.; Diefenbacher, S.; Eren, E.; Gaede, F.; Kasieczka, G.; Korol, A.; Krüger, K. Getting high: High fidelity simulation of high granularity calorimeters with high speed. Comput. Softw. Big Sci. 2021, 5, 13. [Google Scholar] [CrossRef]
- Buhmann, E.; Diefenbacher, S.; Hundhausen, D.; Kasieczka, G.; Korcari, W.; Eren, E.; Gaede, F.; Krüger, K.; McKeown, P.; Rustige, L. Hadrons, better, faster, stronger. Mach. Learn. Sci. Technol. 2022, 3, 025014. [Google Scholar] [CrossRef]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Zhao, S.; Song, J.; Ermon, S. InfoVAE: Information Maximizing Variational Autoencoders. arXiv 2017, arXiv:1706.02262. [Google Scholar]
- Mohamed, S.; Lakshminarayanan, B. Learning in Implicit Generative Models. arXiv 2016, arXiv:1610.03483. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond pixels using a learned similarity metric. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 1558–1566. [Google Scholar]
- Howard, J.N.; Mandt, S.; Whiteson, D.; Yang, Y. Learning to simulate high energy particle collisions from unlabeled data. Sci. Rep. 2022, 12, 7567. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition, IEEE/CVF, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Sauer, A.; Schwarz, K.; Geiger, A. StyleGAN-XL: Scaling StyleGAN to Large Diverse Datasets. In Proceedings of the SIGGRAPH Conference. ACM, Vancouver, BC, Canada, 8–11 August 2022; pp. 1–10. [Google Scholar]
- Image Generation on ImageNet 256 × 256. Available online: https://paperswithcode.com/sota/image-generation-on-imagenet-256x256 (accessed on 29 August 2023).
- Image Generation on FFHQ 256 × 256. Available online: https://paperswithcode.com/sota/image-generation-on-ffhq-256-x-256 (accessed on 29 August 2023).
- Papamakarios, G.; Nalisnick, E.; Rezende, D.J.; Mohamed, S.; Lakshminarayanan, B. Normalizing Flows for Probabilistic Modeling and Inference. J. Mach. Learn. Res. 2021, 22, 1–64. [Google Scholar]
- Quétant, G.; Drozdova, M.; Kinakh, V.; Golling, T.; Voloshynovskiy, S. Turbo-Sim: A generalised generative model with a physical latent space. In Proceedings of the Workshop on Machine Learning and the Physical Sciences, NeurIPS, Virtually, 13 December 2021. [Google Scholar]
- Bellagente, M.; Butter, A.; Kasieczka, G.; Plehn, T.; Rousselot, A.; Winterhalder, R.; Ardizzone, L.; Köthe, U. Invertible networks or partons to detector and back again. SciPost Phys. 2020, 9, 074. [Google Scholar] [CrossRef]
- Belousov, Y.; Pulfer, B.; Chaban, R.; Tutt, J.; Taran, O.; Holotyak, T.; Voloshynovskiy, S. Digital twins of physical printing-imaging channel. In Proceedings of the IEEE International Workshop on Information Forensics and Security, Virtually, 12–16 December 2022; pp. 1–6. [Google Scholar]
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]

















| BIB-AE | TURBO | |
|---|---|---|
| Paradigm | Minimising the mutual information between the input space and the latent space, while maximising the mutual information between the latent space and the output space | Maximising the mutual information between the input space and the latent space, and maximising the mutual information between the latent space and the output space |
| One-way encoding | Two-way encoding | |
| Data and latent space distributions are considered independently | Data and latent space distributions are considered jointly | |
| Targeted tasks |
|
|
| Advantages |
|
|
| Drawbacks |
|
|
| Particular cases | VAE, GAN, VAE/GAN | AAE, GAN, pix2pix, SRGAN, CycleGAN, Flows |
| Related models | InfoVAE, CLUB | ALAE |
| Z space | X space | Rec. space | |
|---|---|---|---|
| Model | |||
| Turbo-Sim | 3.96 | 4.43 | 2.97 |
| OTUS | 2.76 | 5.75 | 15.8 |
| Model | MSE ↓ | SSIM ↑ | PSNR ↑ | LPIPS ↓ | FID ↓ |
|---|---|---|---|---|---|
| CycleGAN | 0.0097 | 0.83 | 20.11 | 0.48 | 128.1 |
| pix2pix | 0.0021 | 0.93 | 26.78 | 0.44 | 54.58 |
| TURBO | 0.0026 | 0.92 | 25.88 | 0.41 | 43.36 |
| Model | FID ↓ | FID ↓ | Hamming ↓ | MSE ↓ | SSIM ↑ |
|---|---|---|---|---|---|
| W/O processing | 304 | 304 | 0.24 | 0.18 | 0.48 |
| CycleGAN | 3.87 | 4.45 | 0.15 | 0.05 | 0.73 |
| pix2pix | 3.37 | 8.57 | 0.11 | 0.05 | 0.76 |
| TURBO | 3.16 | 6.60 | 0.09 | 0.04 | 0.78 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quétant, G.; Belousov, Y.; Kinakh, V.; Voloshynovskiy, S. TURBO: The Swiss Knife of Auto-Encoders. Entropy 2023, 25, 1471. https://doi.org/10.3390/e25101471
Quétant G, Belousov Y, Kinakh V, Voloshynovskiy S. TURBO: The Swiss Knife of Auto-Encoders. Entropy. 2023; 25(10):1471. https://doi.org/10.3390/e25101471
Chicago/Turabian StyleQuétant, Guillaume, Yury Belousov, Vitaliy Kinakh, and Slava Voloshynovskiy. 2023. "TURBO: The Swiss Knife of Auto-Encoders" Entropy 25, no. 10: 1471. https://doi.org/10.3390/e25101471