
A Survey of Deep Learning-Based Multimodal Emotion Recognition: Speech, Text, and Face

 ,
,
Abstract
:1. Introduction
2. Popular Datasets in Multimodal Emotion Recognition
2.1. IEMOCAP
2.2. Youtube Dataset
2.3. MOUD
2.4. ICT-MMMO
2.5. CMU-MOSI
2.6. NNIME
2.7. CMU-MOSEI
2.8. OMG
2.9. MELD
2.10. SEWA
2.11. CH-SIMS
2.12. CH-SIMS V2.0
3. Feature Extraction
3.1. Speech Feature Extraction
3.1.1. Hand-Crafted Feature
- (1)
- Prosodic features: Emotions precipitate physiological changes that directly impact speech production and, thus, significantly affect speech intonation [36]. Prosodic features, capturing variations in pitch, tone, rhythm, and stress in speech, serve as robust indicators of these emotional shifts. As a result, these features have become indispensable in the field of emotion recognition and are widely acknowledged by researchers [37,38]. The array of prosodic features contributing to the depiction of emotions in speech encompasses, among others, fundamental frequency (F0), energy, and speech rate [39,40,41,42]. Among them, F0 is considered one of the most crucial features to predict emotional states in speech. Relevant studies have shown that people’s F0 tends to be higher with a wider range when they are in an excited emotional state such as anger, lower and with a narrower range when they are in a depressed emotional state such as sadness, and relatively stable when they are in a calm emotional state [42]. In addition to F0, energy (i.e., intensity) in speech is also a vital feature. Scherer et al. [38] found that high-frequency energy increases when people experience fear, happiness, and anger, while high-frequency energy decreases during times of sadness. Furthermore, Nwe et al. [43] pointed out that emotions with higher activation levels, such as anger, surprise, and happiness, generally have higher intensity, while emotions like fear, sadness, and disgust have lower intensity. Furthermore, speech rate, the speed at which words are spoken, greatly affects emotion detection. Research indicates that the speech rate tends to be faster for fear, disgust, anger, and happiness; normal for surprise; and slower for sadness [44]. Consequently, fluctuations in the speech rate serve as a vital cue in distinguishing different emotional states. In conclusion, the careful analysis and extraction of prosodic features offer a comprehensive, although not exhaustive, approach to understanding and recognizing emotional states through speech. They form a crucial part of hand-crafted features used in MER, with each contributing uniquely to the richness of emotion recognition. Nevertheless, it is important to remember that prosodic features form just one aspect of emotional recognition, and should be used in concert with other features for an all-encompassing, nuanced understanding of emotions.
- (2)
- Voice quality features: Voice quality features are primarily utilized to assess the purity, clarity, and intelligibility of speech. These are affected by acoustic performances such as wheezing, choking, and tremors, which frequently arise when the speaker is emotionally excited or has difficulty calming down. Voice quality features include formant, harmonic-to-noise ratio (HNR), jitter, and shimmer. The formant reflects the characteristics of the vocal tract, which is a significant parameter impacted by emotional speech. According to previous research findings, compared with neutral speech, the first formant frequency of happy and angry speech is slightly higher, while the first formant frequency of sad speech is significantly lower [36,42]. Another crucial voice quality feature is the HNR, which represents the ratio of harmonic components to noise components in speech. It is worth noting that the noise in this context is not environmental noise, but glottal noise arising from incomplete closure of the vocal folds during speech production. Jitter is a term for the degree of rapid and repetitive changes in the measured fundamental frequency, which mainly indicates roughness in the sound and, to a lesser extent, the degree of hoarseness commonly observed in anxious speech. Shimmer mainly demonstrates the degree of hoarseness by reflecting changes in the amplitude of voice between adjacent vibratory cycles. In conclusion, voice quality features play an indispensable role in extracting valuable insights from speech for emotion recognition. The concurrent use of these features substantially enhances the breadth and depth of emotion recognition, thus facilitating a more sophisticated comprehension of emotional states in speech.
- (3)
- Spectral features: Spectrum-based correlation features are usually short-term representations of speech signals, as speech signals are generated from the coordinated movement of multiple articulators, and the physical characteristics of the articulators determine that speech is difficult to change significantly in a short period of time. Typically, speech signals ranging from 5–50 ms are relatively stable. When recognizing emotions in speech, the most important perceptual properties are reflected in the power spectrum. Emotional expression in speech has a great impact on the distribution of spectral energy in different frequency bands. Spectral features encompass linear and cepstral features, wherein the former involves Linear Prediction Coefficients (LPC), and Log-Frequency Power Coefficients (LFPC), and the latter involves Mel Frequency Cepstral Coefficients (MFCC) and Linear Prediction Cepstral Coefficients (LPCC). Among them, MFCCs, arguably the most commonly used feature in speech signal processing, capture the power spectrum of speech on a nonlinear mel scale, which approximates the human auditory system’s response. The use of the mel scale makes MFCCs particularly valuable when capturing perceptually relevant spectral shapes, thereby enabling effective emotion recognition. To conclude, spectral feature extraction and analysis present a robust methodology for comprehending and recognizing emotional states via speech. Each feature type provides unique insights, collectively contributing significantly to the richness of emotion recognition in multimodal emotion recognition frameworks. However, it is pivotal to remember that spectral features represent merely one facet of emotion recognition and should be employed in combination with other features for a comprehensive and nuanced emotional understanding.
3.1.2. Deep Feature
3.2. Textual Feature Extraction
3.3. Facial Feature Extraction
4. Multimodal Fusion Methods
4.1. Model-Agnostic Fusion
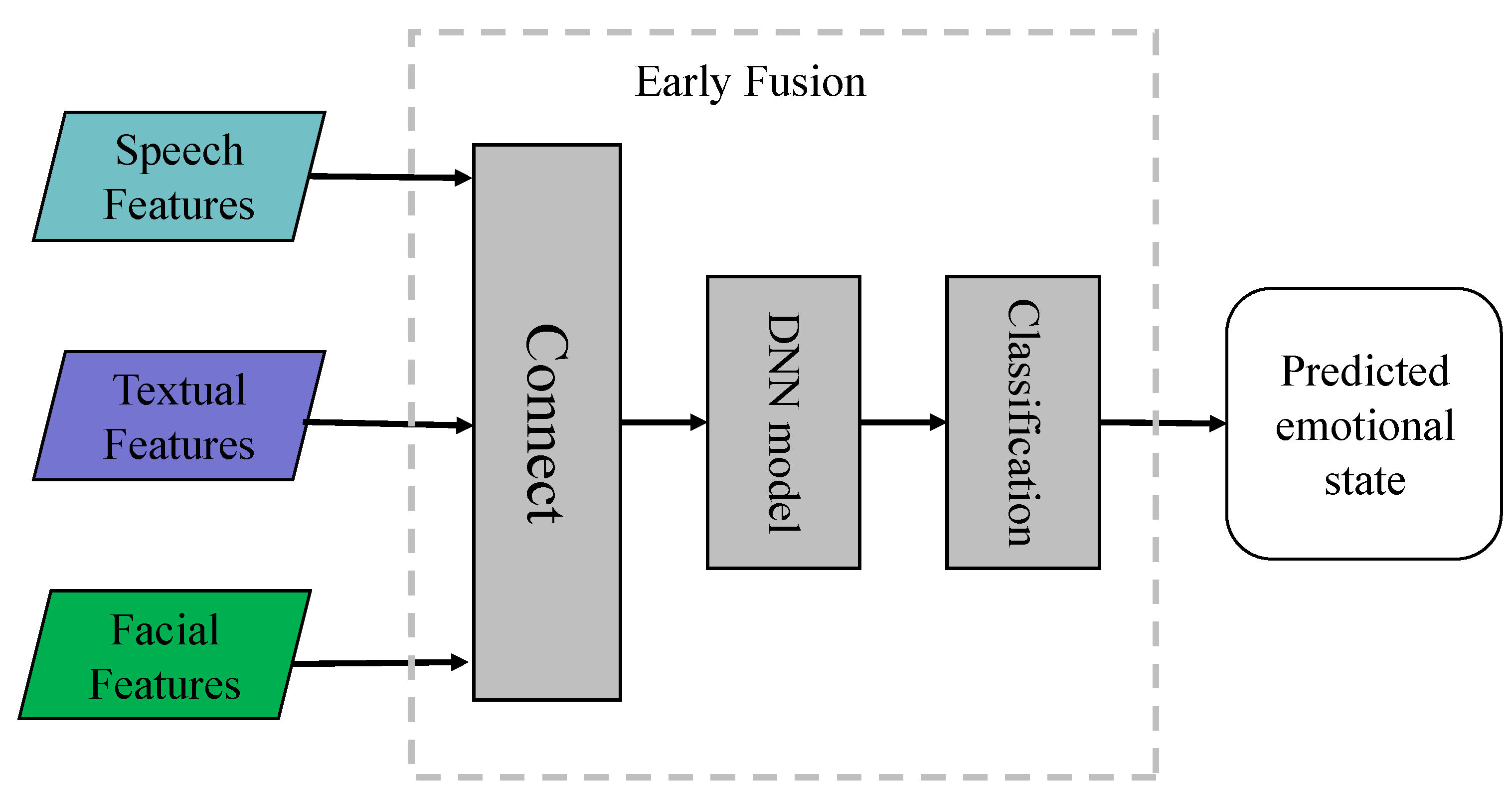
4.1.1. Early Fusion
4.1.2. Late Fusion
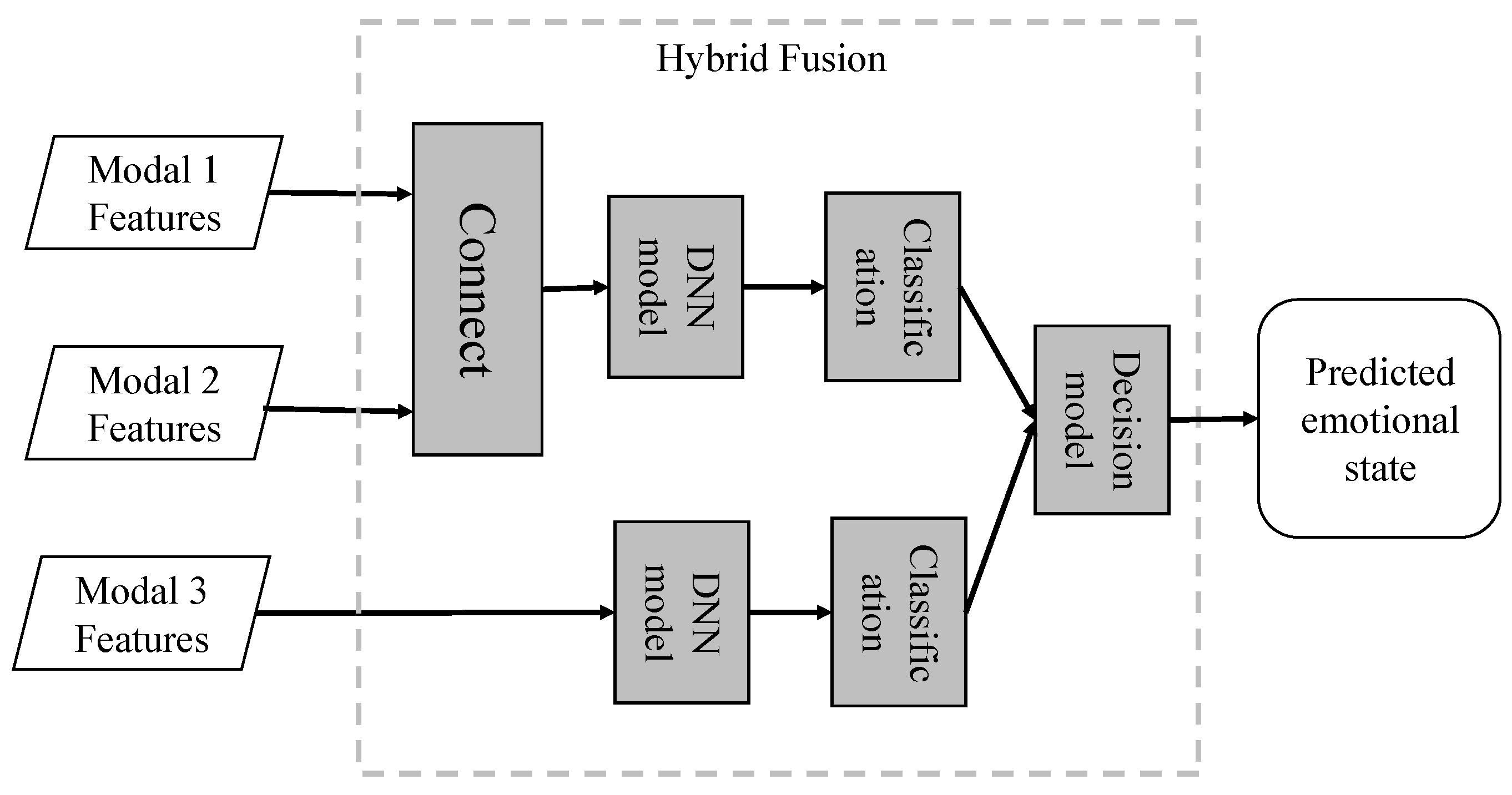
4.1.3. Hybrid Fusion
4.2. Intermediate Layer Fusion
4.2.1. Simple Concatenation Fusion
4.2.2. Utterance-Level Interaction Fusion
4.2.3. Fine-Grained Interaction Fusion
5. Evaluation Metrics
5.1. Classification Evaluation Metrics
5.1.1. Weighted Average Accuracy (ACC)
5.1.2. Unweighted Average Accuracy (UACC):
5.1.3. Weighted Average F1 (F1)
5.1.4. Unweighted Average F1 (UF1)
5.2. Regression Evaluation Metrics
5.2.1. Mean Squared Error (MSE)
5.2.2. Root Mean Squared Error (RMSE)
5.2.3. Pearson Correlation Coefficient (PCC)
5.2.4. Concordance Correlation Coefficient (CCC)
6. Analysis of Research Results
- Vocally, most studies prefer feature extraction using the COVAREP and openSMILE tools, which are open-source and adept at extracting a wide range of voice-related features. However, there is a growing inclination towards deep learning-based feature extraction, as illustrated by the significant outcomes achieved by Siriwardhana and colleagues using the Wav2Vec approach on the IEMOCAP and MELD datasets.
- In the textual domain, initial studies primarily relied on word vector models such as word2vec and Glove. With the evolution of deep learning, recent methods show a preference for sophisticated models like BERT and RoBERTa, which excel at capturing textual contextual nuances.
- Techniques for extracting facial expression features are diverse, encompassing methods like 3D-CNN, FACET, and OpenFace. Additionally, some studies are delving into technologies such as DenseNet, MTCNN, and Fabnet.
- Concerning fusion strategies, Fine-grained Interaction Fusion remains a popular choice, owing to its ability to foster detailed interactions between modalities based on nuanced features.
- Regarding datasets, IEMOCAP emerges as the predominant choice, likely due to the accuracy of its emotion labels and its longstanding reputation. Nonetheless, emerging datasets like MELD and YouTube are gaining traction, possibly to explore emotion recognition challenges in multifaceted and authentic contexts.
7. Conclusions and Future Challenges
- Scale, annotation, and diversity of datasets: Datasets are crucial to deep learning models’ performance and generalization ability. An ideal dataset should exhibit representativeness, diversity, and sufficient scale while maintaining high-quality labels. Datasets enable models to learn patterns through sample observation, while diverse data provide learning opportunities in different contexts. Large-scale datasets can mitigate overfitting issues, and high-quality labels can provide accurate supervision signals. Consequently, constructing a large-scale and diverse dataset becomes imperative in the MER domain. Nevertheless, the annotation of multimodal data requires professionals to subjectively evaluate text, speech, and images, which is both time-consuming and expensive. Thus, the construction of a challenging task lies in developing a high-quality, large-scale, and diverse MER dataset.
- Multimodal Fusion: The task of fusing data from disparate modalities for emotion recognition is another predicament. Temporal misalignment and heterogeneities among features across different modalities can make the fusion process complex. This complexity often leads to models not fully utilizing the supplementary information from various modalities, which in turn undermines their performance in emotion recognition. In this context, information theory and entropy offer profound insights. By quantifying the information content in various modalities through entropy, it becomes feasible to evaluate the uncertainty or predictability of each data source. This approach can pinpoint modalities that provide substantial information while also identifying those that introduce noise or redundancy. Additionally, employing information theory concepts, such as mutual information, can elucidate the extent of interdependence between modalities. Such insights would facilitate a more harmonious and informed fusion process, ensuring that the relationships and synergies between modalities are optimally leveraged. Therefore, harnessing information theory to craft a potent strategy for amalgamating textual, facial, and auditory features—and seamlessly incorporating this multimodal information into a comprehensive model—is of paramount importance.
- Generalization Ability of Models: Despite the proposal of numerous excellent MER models, they are usually trained on specific datasets that rely on non-realistic scenarios, making them difficult to adapt to industrial applications. Therefore, MER models need to possess good generalization capability to be applicable to different scenarios and tasks. However, due to limitations in datasets and the complexity of models, the generalization capability of models with regard to new domains or unseen data remains a challenge. Addressing the construction of more universal and transferable models is one of the challenges that must be tackled.
- Leveraging Large-scale Training and Computational Resources: To attain greater accuracy and improved outcomes, deep learning models commonly necessitate abundant data and computational resources for training purposes. Nevertheless, acquiring extensive annotated data and conducting model training in the context of MER presents a formidable and expensive endeavor. Furthermore, ample computational resources and storage space are indispensable for large-scale training. Consequently, effectively utilizing limited data and computational resources, as well as accelerating the training process, is a challenge that needs to be addressed.
- Ethical and Privacy Issues: MER is a technology that extensively analyzes various data modalities, including speech, text, and facial cues, to discern individuals’ emotional states. This in-depth analysis often involves the processing of highly personal and intimate details about a person’s emotions and experiences. In practical applications, this level of analysis results in a direct interaction with users’ private information, creating a significant risk of potential privacy breaches. Therefore, striking a balance between ensuring model performance, protecting user privacy, ensuring reasonable data usage, and safeguarding user rights is an important challenge.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, features and classifiers for speech emotion recognition: A review. Int. J. Speech Technol. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Zong, Y.; Lian, H.; Chang, H.; Lu, C.; Tang, C. Adapting Multiple Distributions for Bridging Emotions from Different Speech Corpora. Entropy 2022, 24, 1250. [Google Scholar] [CrossRef]
- Fu, H.; Zhuang, Z.; Wang, Y.; Huang, C.; Duan, W. Cross-Corpus Speech Emotion Recognition Based on Multi-Task Learning and Subdomain Adaptation. Entropy 2023, 25, 124. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.; Tang, C.; Zhang, J.; Zong, Y. Progressively Discriminative Transfer Network for Cross-Corpus Speech Emotion Recognition. Entropy 2022, 24, 1046. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.H.; Chuang, Z.J.; Lin, Y.C. Emotion recognition from text using semantic labels and separable mixture models. ACM Trans. Asian Lang. Inf. Process. (TALIP) 2006, 5, 165–183. [Google Scholar] [CrossRef]
- Shaheen, S.; El-Hajj, W.; Hajj, H.; Elbassuoni, S. Emotion recognition from text based on automatically generated rules. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; IEEE: New York, NY, USA, 2014; pp. 383–392. [Google Scholar]
- Zhang, L.; Tjondronegoro, D. Facial expression recognition using facial movement features. IEEE Trans. Affect. Comput. 2011, 2, 219–229. [Google Scholar] [CrossRef]
- Valstar, M.F.; Jiang, B.; Mehu, M.; Pantic, M.; Scherer, K. The first facial expression recognition and analysis challenge. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011; IEEE: New York, NY, USA, 2011; pp. 921–926. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef]
- Yang, H.; Xie, L.; Pan, H.; Li, C.; Wang, Z.; Zhong, J. Multimodal Attention Dynamic Fusion Network for Facial Micro-Expression Recognition. Entropy 2023, 25, 1246. [Google Scholar] [CrossRef]
- Zeng, J.; Liu, T.; Zhou, J. Tag-assisted Multimodal Sentiment Analysis under Uncertain Missing Modalities. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1545–1554. [Google Scholar]
- Shou, Y.; Meng, T.; Ai, W.; Yang, S.; Li, K. Conversational emotion recognition studies based on graph convolutional neural networks and a dependent syntactic analysis. Neurocomputing 2022, 501, 629–639. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Cui, Z. Decoupled Multimodal Distilling for Emotion Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6631–6640. [Google Scholar]
- Liu, F.; Chen, J.; Tan, W.; Cai, C. A multi-modal fusion method based on higher-order orthogonal iteration decomposition. Entropy 2021, 23, 1349. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Shen, S.Y.; Fu, Z.W.; Wang, H.Y.; Zhou, A.M.; Qi, J.Y. Lgcct: A light gated and crossed complementation transformer for multimodal speech emotion recognition. Entropy 2022, 24, 1010. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Liu, Y.; Liu, Q.; Zhang, Q.; Yan, F.; Ma, Y.; Zhang, X. Multidimensional Feature in Emotion Recognition Based on Multi-Channel EEG Signals. Entropy 2022, 24, 1830. [Google Scholar] [CrossRef] [PubMed]
- Chang, H.; Zong, Y.; Zheng, W.; Xiao, Y.; Wang, X.; Zhu, J.; Shi, M.; Lu, C.; Yang, H. EEG-based major depressive disorder recognition by selecting discriminative features via stochastic search. J. Neural Eng. 2023, 20, 026021. [Google Scholar] [CrossRef]
- Sapiński, T.; Kamińska, D.; Pelikant, A.; Anbarjafari, G. Emotion recognition from skeletal movements. Entropy 2019, 21, 646. [Google Scholar] [CrossRef] [PubMed]
- Chang, H.; Liu, B.; Zong, Y.; Lu, C.; Wang, X. EEG-Based Parkinson’s Disease Recognition Via Attention-based Sparse Graph Convolutional Neural Network. IEEE J. Biomed. Health Inform. 2023. [Google Scholar] [CrossRef]
- Gu, X.; Shen, Y.; Xu, J. Multimodal Emotion Recognition in Deep Learning: A Survey. In Proceedings of the 2021 International Conference on Culture-oriented Science & Technology (ICCST), Beijing, China, 18–21 November 2021; IEEE: New York, NY, USA, 2021; pp. 77–82. [Google Scholar]
- Koromilas, P.; Giannakopoulos, T. Deep multimodal emotion recognition on human speech: A review. Appl. Sci. 2021, 11, 7962. [Google Scholar] [CrossRef]
- Zhang, T.; Tan, Z. Deep Emotion Recognition Using Facial, Speech and Textual Cues: A Survey. TechRxiv. Preprint. 2015. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Morency, L.P.; Mihalcea, R.; Doshi, P. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proceedings of the 13th International Conference on Multimodal Interfaces, Alicante, Spain, 14–18 November 2011; pp. 169–176. [Google Scholar]
- Pérez-Rosas, V.; Mihalcea, R.; Morency, L.P. Utterance-level multimodal sentiment analysis. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 973–982. [Google Scholar]
- Wöllmer, M.; Weninger, F.; Knaup, T.; Schuller, B.; Sun, C.; Sagae, K.; Morency, L.P. Youtube movie reviews: Sentiment analysis in an audio-visual context. IEEE Intell. Syst. 2013, 28, 46–53. [Google Scholar] [CrossRef]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Mosi: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv 2016, arXiv:1606.06259. [Google Scholar]
- Chou, H.C.; Lin, W.C.; Chang, L.C.; Li, C.C.; Ma, H.P.; Lee, C.C. NNIME: The NTHU-NTUA Chinese interactive multimodal emotion corpus. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; IEEE: New York, NY, USA, 2017; pp. 292–298. [Google Scholar]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2236–2246. [Google Scholar]
- Barros, P.; Churamani, N.; Lakomkin, E.; Siqueira, H.; Sutherland, A.; Wermter, S. The OMG-emotion behavior dataset. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 527–536. [Google Scholar]
- Kossaifi, J.; Walecki, R.; Panagakis, Y.; Shen, J.; Schmitt, M.; Ringeval, F.; Han, J.; Pandit, V.; Toisoul, A.; Schuller, B.; et al. Sewa db: A rich database for audio-visual emotion and sentiment research in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1022–1040. [Google Scholar] [CrossRef] [PubMed]
- Yu, W.; Xu, H.; Meng, F.; Zhu, Y.; Ma, Y.; Wu, J.; Zou, J.; Yang, K. Ch-sims: A chinese multimodal sentiment analysis dataset with fine-grained annotation of modality. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3718–3727. [Google Scholar]
- Liu, Y.; Yuan, Z.; Mao, H.; Liang, Z.; Yang, W.; Qiu, Y.; Cheng, T.; Li, X.; Xu, H.; Gao, K. Make Acoustic and Visual Cues Matter: CH-SIMS v2.0 Dataset and AV-Mixup Consistent Module. In Proceedings of the 2022 International Conference on Multimodal Interaction, Bengaluru, India, 7–11 November 2022; pp. 247–258. [Google Scholar]
- Lin, J.C.; Wu, C.H.; Wei, W.L. Error weighted semi-coupled hidden Markov model for audio-visual emotion recognition. IEEE Trans. Multimed. 2011, 14, 142–156. [Google Scholar] [CrossRef]
- Murray, I.R.; Arnott, J.L. Toward the simulation of emotion in synthetic speech: A review of the literature on human vocal emotion. J. Acoust. Soc. Am. 1993, 93, 1097–1108. [Google Scholar] [CrossRef]
- Scherer, K.R. Vocal communication of emotion: A review of research paradigms. Speech Commun. 2003, 40, 227–256. [Google Scholar] [CrossRef]
- Wu, S.; Falk, T.H.; Chan, W.Y. Automatic speech emotion recognition using modulation spectral features. Speech Commun. 2011, 53, 768–785. [Google Scholar] [CrossRef]
- Zeng, Z.; Pantic, M.; Roisman, G.I.; Huang, T.S. A survey of affect recognition methods: Audio, visual and spontaneous expressions. In Proceedings of the 9th International Conference on Multimodal Interfaces, Nagoya, Japan, 12–15 November 2007; pp. 126–133. [Google Scholar]
- Kwon, O.W.; Chan, K.; Hao, J.; Lee, T.W. Emotion recognition by speech signals. In Proceedings of the Eighth European Conference on Speech Communication and Technology, Geneva, Switzerland, 1–4 September 2003. [Google Scholar]
- Morrison, D.; Wang, R.; De Silva, L.C. Ensemble methods for spoken emotion recognition in call-centres. Speech Commun. 2007, 49, 98–112. [Google Scholar] [CrossRef]
- Nwe, T.L. Analysis and Detection of Human Emotion and Stress from Speech Signals. Ph.D. Thesis, National University of Singapore, Singapore, 2004. [Google Scholar]
- Nwe, T.L.; Foo, S.W.; De Silva, L.C. Speech emotion recognition using hidden Markov models. Speech Commun. 2003, 41, 603–623. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM international conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Degottex, G.; Kane, J.; Drugman, T.; Raitio, T.; Scherer, S. COVAREP—A collaborative voice analysis repository for speech technologies. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: New York, NY, USA, 2014; pp. 960–964. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B. OpenEAR—Introducing the Munich open-source emotion and affect recognition toolkit. In Proceedings of the 2009 3rd International Conference on Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009; IEEE: New York, NY, USA, 2009; pp. 1–6. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 11–17 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Baevski, A.; Schneider, S.; Auli, M. vq-wav2vec: Self-Supervised Learning of Discrete Speech Representations. arXiv 2019, arXiv:1910.05453. [Google Scholar]
- Lu, C.; Zheng, W.; Lian, H.; Zong, Y.; Tang, C.; Li, S.; Zhao, Y. Speech Emotion Recognition via an Attentive Time–Frequency Neural Network. IEEE Trans. Comput. Soc. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Lu, C.; Lian, H.; Zheng, W.; Zong, Y.; Zhao, Y.; Li, S. Learning Local to Global Feature Aggregation for Speech Emotion Recognition. arXiv 2023, arXiv:2306.01491. [Google Scholar]
- Zhao, Y.; Wang, J.; Zong, Y.; Zheng, W.; Lian, H.; Zhao, L. Deep Implicit Distribution Alignment Networks for cross-Corpus Speech Emotion Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, J.; Ye, R.; Zong, Y.; Zheng, W.; Zhao, L. Deep Transductive Transfer Regression Network for Cross-Corpus Speech Emotion Recognition. Proc. Interspeech 2022, 2022, 371–375. [Google Scholar] [CrossRef]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.; Chen, Z.; Wu, Y.; Liu, S.; Chen, Z.; Li, J.; Kanda, N.; Yoshioka, T.; Xiao, X.; et al. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 2022, 16, 1505–1518. [Google Scholar] [CrossRef]
- Soumya George, K.; Joseph, S. Text classification by augmenting bag of words (BOW) representation with co-occurrence feature. IOSR J. Comput. Eng. 2014, 16, 34–38. [Google Scholar] [CrossRef]
- Zhao, R.; Mao, K. Fuzzy bag-of-words model for document representation. IEEE Trans. Fuzzy Syst. 2017, 26, 794–804. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Tang, D.; Wei, F.; Yang, N.; Zhou, M.; Liu, T.; Qin, B. Learning sentiment-specific word embedding for twitter sentiment classification. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Baltimore, MA, USA, 22–27 June 2014; pp. 1555–1565. [Google Scholar]
- Xu, P.; Madotto, A.; Wu, C.S.; Park, J.H.; Fung, P. Emo2vec: Learning generalized emotion representation by multi-task training. arXiv 2018, arXiv:1809.04505. [Google Scholar]
- Chen, J.; Liu, X.; Tu, P.; Aragones, A. Learning person-specific models for facial expression and action unit recognition. Pattern Recognit. Lett. 2013, 34, 1964–1970. [Google Scholar] [CrossRef]
- Lanitis, A.; Taylor, C.J.; Cootes, T.F. Automatic face identification system using flexible appearance models. Image Vis. Comput. 1995, 13, 393–401. [Google Scholar] [CrossRef]
- Cootes, T.F.; Taylor, C.J.; Cooper, D.H.; Graham, J. Active shape models-their training and application. Comput. Vis. Image Underst. 1995, 61, 38–59. [Google Scholar] [CrossRef]
- Chu, W.S.; De la Torre, F.; Cohn, J.F. Selective transfer machine for personalized facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 529–545. [Google Scholar] [CrossRef] [PubMed]
- Baltrušaitis, T.; Mahmoud, M.; Robinson, P. Cross-dataset learning and person-specific normalisation for automatic action unit detection. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; IEEE: New York, NY, USA, 2015; Volume 6, pp. 1–6. [Google Scholar]
- Ahsan, T.; Jabid, T.; Chong, U.P. Facial expression recognition using local transitional pattern on Gabor filtered facial images. IETE Tech. Rev. 2013, 30, 47–52. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Yu, Z.; Liu, G.; Liu, Q.; Deng, J. Spatio-temporal convolutional features with nested LSTM for facial expression recognition. Neurocomputing 2018, 317, 50–57. [Google Scholar] [CrossRef]
- Littlewort, G.; Whitehill, J.; Wu, T.; Fasel, I.; Frank, M.; Movellan, J.; Bartlett, M. The computer expression recognition toolbox (CERT). In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011; IEEE: New York, NY, USA, 2011; pp. 298–305. [Google Scholar]
- Baltrusaitis, T.; Zadeh, A.; Lim, Y.C.; Morency, L.P. Openface 2.0: Facial behavior analysis toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: New York, NY, USA, 2018; pp. 59–66. [Google Scholar]
- Zhu, L.; Zhu, Z.; Zhang, C.; Xu, Y.; Kong, X. Multimodal sentiment analysis based on fusion methods: A survey. Inf. Fusion 2023, 95, 306–325. [Google Scholar] [CrossRef]
- D’mello, S.K.; Kory, J. A review and meta-analysis of multimodal affect detection systems. ACM Comput. Surv. (CSUR) 2015, 47, 1–36. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Bajpai, R.; Hussain, A. A review of affective computing: From unimodal analysis to multimodal fusion. Inf. Fusion 2017, 37, 98–125. [Google Scholar] [CrossRef]
- Shoumy, N.J.; Ang, L.M.; Seng, K.P.; Rahaman, D.M.; Zia, T. Multimodal big data affective analytics: A comprehensive survey using text, audio, visual and physiological signals. J. Netw. Comput. Appl. 2020, 149, 102447. [Google Scholar] [CrossRef]
- Abdullah, S.M.S.A.; Ameen, S.Y.A.; Sadeeq, M.A.; Zeebaree, S. Multimodal emotion recognition using deep learning. J. Appl. Sci. Technol. Trends 2021, 2, 52–58. [Google Scholar] [CrossRef]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Poria, S.; Cambria, E.; Hussain, A.; Huang, G.B. Towards an intelligent framework for multimodal affective data analysis. Neural Netw. 2015, 63, 104–116. [Google Scholar] [CrossRef]
- Huang, J.; Li, Y.; Tao, J.; Lian, Z.; Niu, M.; Yang, M. Multimodal continuous emotion recognition with data augmentation using recurrent neural networks. In Proceedings of the 2018 on Audio/Visual Emotion Challenge and Workshop, Seoul, Korea, 22 October 2018; pp. 57–64. [Google Scholar]
- Williams, J.; Kleinegesse, S.; Comanescu, R.; Radu, O. Recognizing emotions in video using multimodal dnn feature fusion. In Proceedings of the Grand Challenge and Workshop on Human Multimodal Language (Challenge-HML), Melbourne, Australia, 20 July 2018; pp. 11–19. [Google Scholar]
- Poria, S.; Cambria, E.; Howard, N.; Huang, G.B.; Hussain, A. Fusing audio, visual and textual clues for sentiment analysis from multimodal content. Neurocomputing 2016, 174, 50–59. [Google Scholar] [CrossRef]
- Huang, J.; Li, Y.; Tao, J.; Lian, Z.; Wen, Z.; Yang, M.; Yi, J. Continuous multimodal emotion prediction based on long short term memory recurrent neural network. In Proceedings of the 7th Annual Workshop on Audio/Visual Emotion Challenge, Mountain View, CA, USA, 23 October 2017; pp. 11–18. [Google Scholar]
- Su, H.; Liu, B.; Tao, J.; Dong, Y.; Huang, J.; Lian, Z.; Song, L. An Improved Multimodal Dimension Emotion Recognition Based on Different Fusion Methods. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; IEEE: New York, NY, USA, 2020; Volume 1, pp. 257–261. [Google Scholar]
- Sun, L.; Lian, Z.; Tao, J.; Liu, B.; Niu, M. Multi-modal continuous dimensional emotion recognition using recurrent neural network and self-attention mechanism. In Proceedings of the 1st International on Multimodal Sentiment Analysis in Real-life Media Challenge and Workshop, Seattle, VA, USA, 16 October 2020; pp. 27–34. [Google Scholar]
- Sun, L.; Xu, M.; Lian, Z.; Liu, B.; Tao, J.; Wang, M.; Cheng, Y. Multimodal emotion recognition and sentiment analysis via attention enhanced recurrent model. In Proceedings of the 2nd on Multimodal Sentiment Analysis Challenge, Online, 24 October 2021; pp. 15–20. [Google Scholar]
- Nemati, S.; Rohani, R.; Basiri, M.E.; Abdar, M.; Yen, N.Y.; Makarenkov, V. A hybrid latent space data fusion method for multimodal emotion recognition. IEEE Access 2019, 7, 172948–172964. [Google Scholar] [CrossRef]
- Nguyen, T.L.; Kavuri, S.; Lee, M. A multimodal convolutional neuro-fuzzy network for emotion understanding of movie clips. Neural Netw. 2019, 118, 208–219. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, S.; Tripathi, S.; Beigi, H. Multi-Modal Emotion Recognition on Iemocap with Neural Networks. arXiv 2018, arXiv:1804.05788. [Google Scholar]
- Ortega, J.D.; Senoussaoui, M.; Granger, E.; Pedersoli, M.; Cardinal, P.; Koerich, A.L. Multimodal fusion with deep neural networks for audio-video emotion recognition. arXiv 2019, arXiv:1907.03196. [Google Scholar]
- Liang, J.; Li, R.; Jin, Q. Semi-supervised multi-modal emotion recognition with cross-modal distribution matching. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2852–2861. [Google Scholar]
- Yu, W.; Xu, H.; Yuan, Z.; Wu, J. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 10790–10797. [Google Scholar]
- Han, W.; Chen, H.; Poria, S. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 9180–9192. [Google Scholar]
- Zheng, J.; Zhang, S.; Wang, X.; Zeng, Z. Multimodal Representations Learning Based on Mutual Information Maximization and Minimization and Identity Embedding for Multimodal Sentiment Analysis. arXiv 2022, arXiv:2201.03969. [Google Scholar]
- Mai, S.; Zeng, Y.; Hu, H. Multimodal information bottleneck: Learning minimal sufficient unimodal and multimodal representations. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.P. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1103–1114. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.B.; Morency, L.P. Efficient Low-rank Multimodal Fusion With Modality-Specific Factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2247–2256. [Google Scholar]
- Liang, P.P.; Liu, Z.; Tsai, Y.H.H.; Zhao, Q.; Salakhutdinov, R.; Morency, L.P. Learning representations from imperfect time series data via tensor rank regularization. arXiv 2019, arXiv:1907.01011. [Google Scholar]
- Mai, S.; Hu, H.; Xing, S. Divide, conquer and combine: Hierarchical feature fusion network with local and global perspectives for multimodal affective computing. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 481–492. [Google Scholar]
- Barezi, E.J.; Fung, P. Modality-based factorization for multimodal fusion. arXiv 2018, arXiv:1811.12624. [Google Scholar]
- Liu, F.; Chen, J.; Li, K.; Tan, W.; Cai, C.; Ayub, M.S. A Parallel Multi-Modal Factorized Bilinear Pooling Fusion Method Based on the Semi-Tensor Product for Emotion Recognition. Entropy 2022, 24, 1836. [Google Scholar] [CrossRef] [PubMed]
- Mai, S.; Hu, H.; Xing, S. Modality to modality translation: An adversarial representation learning and graph fusion network for multimodal fusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 164–172. [Google Scholar]
- Wu, T.; Peng, J.; Zhang, W.; Zhang, H.; Tan, S.; Yi, F.; Ma, C.; Huang, Y. Video sentiment analysis with bimodal information-augmented multi-head attention. Knowl. Based Syst. 2022, 235, 107676. [Google Scholar] [CrossRef]
- Liu, S.; Gao, P.; Li, Y.; Fu, W.; Ding, W. Multi-modal fusion network with complementarity and importance for emotion recognition. Inf. Sci. 2023, 619, 679–694. [Google Scholar] [CrossRef]
- Wu, Y.; Lin, Z.; Zhao, Y.; Qin, B.; Zhu, L.N. A text-centered shared-private framework via cross-modal prediction for multimodal sentiment analysis. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 4730–4738. [Google Scholar]
- Chen, M.; Wang, S.; Liang, P.P.; Baltrušaitis, T.; Zadeh, A.; Morency, L.P. Multimodal sentiment analysis with word-level fusion and reinforcement learning. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, Scotland, 13–17 November 2017; pp. 163–171. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Poria, S.; Vij, P.; Cambria, E.; Morency, L.P. Multi-attention recurrent network for human communication comprehension. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1359–1367. [Google Scholar]
- Liang, P.P.; Liu, Z.; Zadeh, A.B.; Morency, L.P. Multimodal Language Analysis with Recurrent Multistage Fusion. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 150–161. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal transformer for unaligned multimodal language sequences. Proc Conf Assoc Comput Linguist Meet. 2019, 2019, 6558. [Google Scholar]
- Liang, T.; Lin, G.; Feng, L.; Zhang, Y.; Lv, F. Attention is not enough: Mitigating the distribution discrepancy in asynchronous multimodal sequence fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8148–8156. [Google Scholar]
- Lv, F.; Chen, X.; Huang, Y.; Duan, L.; Lin, G. Progressive modality reinforcement for human multimodal emotion recognition from unaligned multimodal sequences. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–25 June 2021; pp. 2554–2562. [Google Scholar]
- Tzirakis, P.; Chen, J.; Zafeiriou, S.; Schuller, B. End-to-end multimodal affect recognition in real-world environments. Inf. Fusion 2021, 68, 46–53. [Google Scholar] [CrossRef]
- Lian, Z.; Liu, B.; Tao, J. CTNet: Conversational transformer network for emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 985–1000. [Google Scholar] [CrossRef]
- Nicolaou, M.A.; Gunes, H.; Pantic, M. Continuous prediction of spontaneous affect from multiple cues and modalities in valence-arousal space. IEEE Trans. Affect. Comput. 2011, 2, 92–105. [Google Scholar] [CrossRef]
- Ringeval, F.; Schuller, B.; Valstar, M.; Jaiswal, S.; Marchi, E.; Lalanne, D.; Cowie, R.; Pantic, M. Av+ ec 2015: The first affect recognition challenge bridging across audio, video, and physiological data. In Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, Brisbane, Australia, 26–23 October 2015; pp. 3–8. [Google Scholar]
- Poria, S.; Cambria, E.; Hazarika, D.; Mazumder, N.; Zadeh, A.; Morency, L.P. Multi-level multiple attentions for contextual multimodal sentiment analysis. In Proceedings of the 2017 IEEE International Conference on Data Mining (ICDM), New Orleans, LA, USA, 18–21 November 2017; IEEE: New York, NY, USA, 2017; pp. 1033–1038. [Google Scholar]
- Pham, H.; Manzini, T.; Liang, P.P.; Poczós, B. Seq2Seq2Sentiment: Multimodal Sequence to Sequence Models for Sentiment Analysis. arXiv 2018, arXiv:1807.03915. [Google Scholar]
- Poria, S.; Majumder, N.; Hazarika, D.; Cambria, E.; Gelbukh, A.; Hussain, A. Multimodal sentiment analysis: Addressing key issues and setting up the baselines. IEEE Intell. Syst. 2018, 33, 17–25. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Majumder, N.; Hazarika, D.; Gelbukh, A.; Cambria, E.; Poria, S. Multimodal sentiment analysis using hierarchical fusion with context modeling. Knowl.-Based Syst. 2018, 161, 124–133. [Google Scholar] [CrossRef]
- Tsai, Y.H.H.; Liang, P.P.; Zadeh, A.; Morency, L.P.; Salakhutdinov, R. Learning Factorized Multimodal Representations. In Proceedings of the International Conference on Representation Learning, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, Y.; Shen, Y.; Liu, Z.; Liang, P.P.; Zadeh, A.; Morency, L.P. Words can shift: Dynamically adjusting word representations using nonverbal behaviors. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7216–7223. [Google Scholar]
- Pham, H.; Liang, P.P.; Manzini, T.; Morency, L.P.; Póczos, B. Found in translation: Learning robust joint representations by cyclic translations between modalities. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6892–6899. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, Z.; Wan, Z.; Wan, X. Transmodality: An end2end fusion method with transformer for multimodal sentiment analysis. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2514–2520. [Google Scholar]
- Sun, Z.; Sarma, P.; Sethares, W.; Liang, Y. Learning relationships between text, audio, and video via deep canonical correlation for multimodal language analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8992–8999. [Google Scholar]
- Siriwardhana, S.; Kaluarachchi, T.; Billinghurst, M.; Nanayakkara, S. Multimodal emotion recognition with transformer-based self supervised feature fusion. IEEE Access 2020, 8, 176274–176285. [Google Scholar] [CrossRef]
- Koepke, A.S.; Wiles, O.; Zisserman, A. Self-supervised learning of a facial attribute embedding from video. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; p. 302. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Samples | Language | Type | Recording Environment | Emotions | Data Sources | Speakers |
|---|---|---|---|---|---|---|---|
| IEMOCAP (2008) [24] | 10,039 | English | Acted and Natural | In the lab | Discrete: anger, sadness, happiness, disgust, fear, surprise, frustration, excited, and neutral states; Continuous: VAD (activation, valence, and dominance) | Recored | 10 |
| Youtube dataset (2011) [25] | 47 | English | Natural | In the wild | Discrete: positive, negative, and neutral | Youtube | 47 |
| MOUD (2013) [26] | 498 | Spanish | Natural | In the wild | Discrete: positive, negative, and neutral | Youtube | 80 |
| ICT-MMMO (2013) [27] | 370 | English | Natural | In the wild | Discrete: strongly negative, weakly negative, neutral, weakly positive, and strongly positive | Youtube and ExpoTV | 370 |
| CMU-MOSI (2016) [28] | 2199 | English | Natural | In the wild | Discrete: positive, negative | Youtube | 89 |
| NNIME (2017) [29] | 6701 | Chinese | Natural | In the lab | Discrete: anger, sadness, happiness, frustration, neutral, and surprise; Continuous: VA (valence and arousal) | Record | 44 |
| CMU-MOSEI (2018) [30] | 23,453 | English | Natural | In the wild | Discrete: anger, happiness, disgust, sadness, fear, and surprise | Youtube | 1000 |
| OMG(2018) [31] | 7371 | English | Acted and Natural | In the wild | Discrete: anger, happiness, disgust, sadness, fear, surprise, and neutral; Continuous: VA (valence and arousal) | Youtube | N/A |
| MELD (2019) [32] | 13,708 | English | Acted | In the wild | Discrete: (1) joy, sadness, anger, fear, disgust, surprise, and neutral; (2) positive, negative, neutral | TV series Friends | 407 |
| SEWA (2019) [33] | 2562 | Chinese, English, German, Greek, Hungarian, and Serbian | Natural | In the wild | Continuous: VA (valence and arousal) | Record | 398 |
| CH-SIMS (2020) [34] | 2281 | Chinese | Acted | In the wild | Discrete: negative, weakly negative, neutral, weakly positive, and positive | Movies, TV series | N/A |
| CH-SIMS V2.0 (2022) [35] | 4402 | Chinese | Acted | In the wild | Discrete: negative, weakly negative, neutral, weakly positive, and positive | Movies, TV series, etc. | N/A |
| Method | Feature Extraction | Fusion Method | Datasets | Performance |
|---|---|---|---|---|
| Poria et al. [121] | S: openSMILE T: word2vec F: 3D-CNN | Early Fusion | CMU-MOSI | ACC: 0.813 (2 classes) |
| Liu et al. [100] | S: COVAREP T: Glove F: FACET | Utterance-level Interaction Fusion | IEMOCAP | UF1: 0.831 (4 classes) |
| Zadeh et al. [111] | S: COVAREP T: Glove F: FACET | Fine-grained Interaction Fusion | a. Youtube b. MOUD c. IEMOCAP | a. ACC: 0.610, F1: 0.607 (3 classes); b. ACC: 0.811, F1: 0.804 (2 classes); c. ACC: 0.365, F1: 0.349 (9 classes) |
| Pham et al. [122] | S: MFCC T: Glove F: FACET and OpenFace | Fine-grained Interaction Fusion | CMU-MOSI | ACC: 0.765, F1: 0.734 (2 classes) |
| Poria et al. [123] | S: openSMILE T: CNN F: 3D-CNN | Early Fusion | a. IEMOCAP; b. MOUD; c. CMU-MOSI; | a. ACC: 0.716 (4 classes); b. ACC: 0.679 (2 classes); c. ACC: 0.767 (2 classes) |
| Zadeh et al. [30] | S: COVARE T: Glove F: MTCNN [124] | Fine-grained Interaction Fusion | CMU-MOSEI | UACC: 0.624, UF1: 0.763 (6 classes) |
| Majumber et al. [125] | S: openSMILE T: word2vec F: 3D-CNN | Fine-grained Interaction Fusion | a. CMU-MOSI b. IEMOCAP | a. ACC: 0.800 (2 classes); b. ACC: 0.765 (4 classes) |
| Tsai et al. [126] | S: COVAREP T: Glove F: FACET | Fine-grained Interaction Fusion | a. ICT-MMMO b. Youtube c. MOUD d.IEMOCAP | a. ACC: 0.813, F1: 0.792 (2 classes); b. ACC: 0.533, F1: 0.524 (3 classes); c. ACC: 0.821, F1: 0.817 (2 classes); d.UACC: 0.848, UF1: 0.814 (6 classes) |
| Wang et al. [127] | S: COVAREP T: Glove F: FACET | Fine-grained Interaction Fusion | IEMOCAP | UACC: 0.819, UF1: 0.812 (4 classes) |
| Tsai et al. [114] | S: COVAREP T: Glove F: FACET | Fine-grained Interaction Fusion | IEMOCAP | UACC: 0.747, UF1: 0.715 (4 classes) |
| Pham et al. [128] | S: COVAREP T: Glove F: FACET | Fine-grained Interaction Fusion | a. ICT-MMMO b. Youtube | a. ACC: 0.813, F1: 0.808 (2 classes); b. ACC: 0.517, F1: 0.524 (2 classes) |
| Liang et al. [94] | S: OpenSMILE T: BERT F: DenseNet [129] | Simple Concatenation Fusion | a. IEMOCAP b. MELD | a. ACC: 0.756, UACC: 0.745 (4 class); b. F1: 0.571 (7 classes) |
| Mittal et al. [112] | S: 12 MFCC, pitch, voiced/unvoiced segmentation features, glottal source parameters, among others. T: Glove F: Facial recognition models, facial action units, and facial landmarks. | Fine-grained Interaction Fusion | a. IEMOCAP b. CMU-MOSEI | a. ACC:0.827, F1: 0.824 (4 classes); b. ACC: 0.890, F1: 0.802 (6 classes) |
| Wang et al. [130] | S: OpenSMILE T: CNN F: 3D-CNN | Fine-grained Interaction Fusion | a. IEMOCAP b. CUM-MOSI c. MELD d.CMU-MOSI | a. ACC: 0.608 (6 classes); b. ACC: 0.827 (2 classes); c. ACC:0.620 (7 classes); d.ACC:0.827 (2 classes) |
| Sun et al. [131] | S: COVAREP T: BERT F: FACET | Fine-grained Interaction Fusion | IEMOCAP | UACC: 0.830, UF1: 0.818 (4 classes) |
| Siriwardhana et al. [132] | S: Wav2Vec T: RoBERTa F: Fabnet [133] | Fine-grained Interaction Fusion | a. IEMOCAP b. MELD | a. UACC: 0.847 UF1: 0.842 (4 classes); b. ACC: 0.643, F1: 0.639 (7 classes) |
| Lv et al. [116] | S: COVAREP T: BERT F: FACET | Fine-grained Interaction Fusion | a. IEMOCAP b. CMU-MOSI | a. UACC: 0.851, UF1: 0.838 (4 classes); b. ACC: 0.836, F1: 0.834 (2 classes) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lian, H.; Lu, C.; Li, S.; Zhao, Y.; Tang, C.; Zong, Y. A Survey of Deep Learning-Based Multimodal Emotion Recognition: Speech, Text, and Face. Entropy 2023, 25, 1440. https://doi.org/10.3390/e25101440
Lian H, Lu C, Li S, Zhao Y, Tang C, Zong Y. A Survey of Deep Learning-Based Multimodal Emotion Recognition: Speech, Text, and Face. Entropy. 2023; 25(10):1440. https://doi.org/10.3390/e25101440
Chicago/Turabian StyleLian, Hailun, Cheng Lu, Sunan Li, Yan Zhao, Chuangao Tang, and Yuan Zong. 2023. "A Survey of Deep Learning-Based Multimodal Emotion Recognition: Speech, Text, and Face" Entropy 25, no. 10: 1440. https://doi.org/10.3390/e25101440