
Self-Supervised Node Classification with Strategy and Actively Selected Labeled Set

Abstract
:1. Introduction
2. Related Works
2.1. Data Adapted Graph Self-Supervised Learning
2.2. Auto Machine Learning
2.3. Active Learning for Graphs
3. Methods
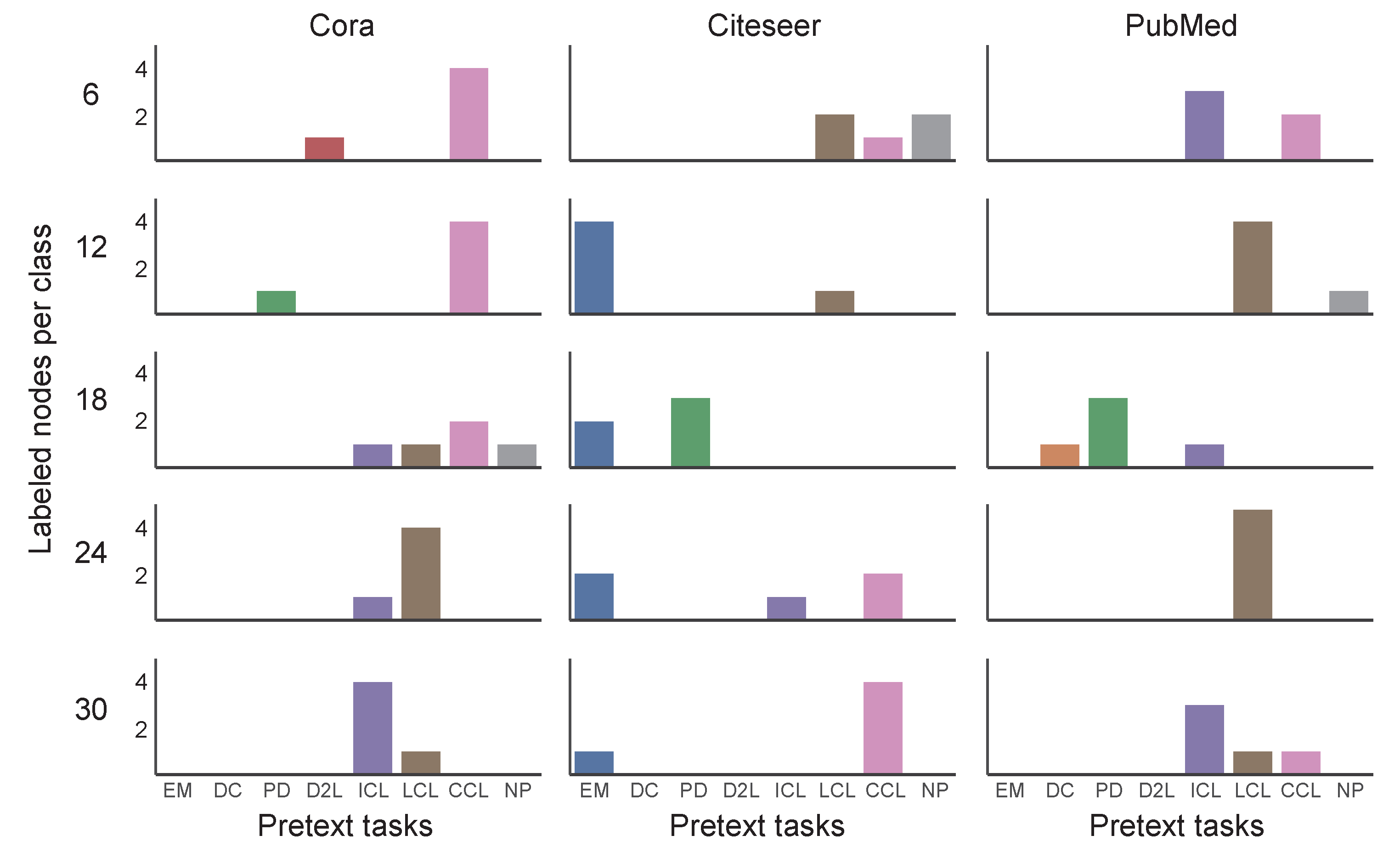
3.1. Problem Statement for Auto Graph Self-Supervised Learning
3.2. Hyperparameter Optimization
| Algorithm 1 Auto Graph Self-supervised strategy optimization |
| Input: |
| Parameters: hyperparameter optimization iterations , fine-tuning iterations , |
| labeled set |
| Initialization: , , , , |
| divide into 3 similar parts, |
| whiledo |
| Validation set: l, training set: |
| repeat |
| Update based on Equation (8) |
| Update based on Equation (15) |
| until |
| end while |
| , set , |
| whiledo |
| Validation set: l, training set: |
| repeat |
| Update based on Equation (8) |
| Update based on Equation (15) |
| until |
| end while |
| Output: |
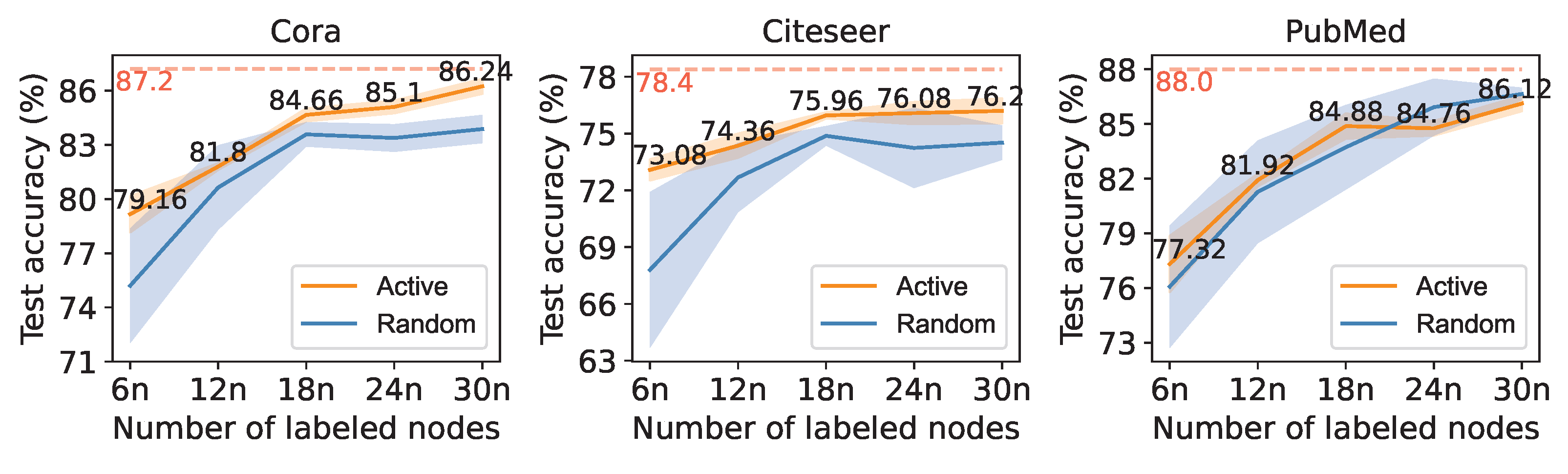
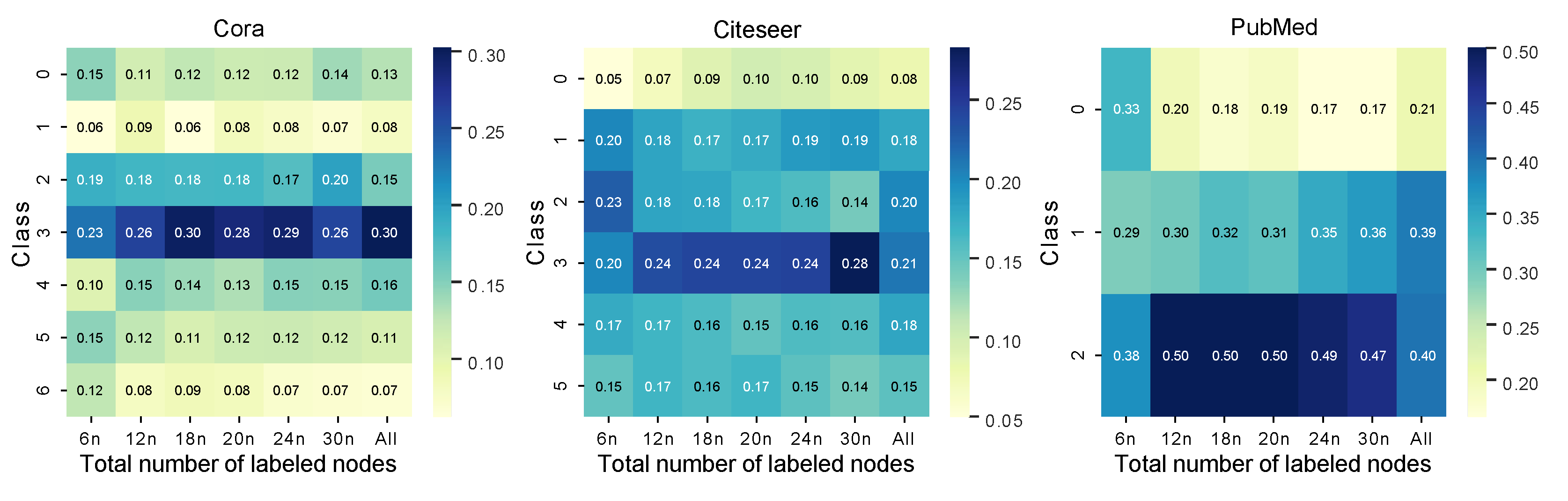
3.3. Select Nodes to Be Labeled Actively
| Algorithm 2 Weisfeiler–Lehman sampling [38] |
| Input: |
| Parameters: batch size k, labeling budget , exploration budget |
| Initialization: test set T, labeled set , unlabeled set |
| whiledo |
| Pick k random seed nodes from |
| while do |
| hop neighborhood subgraph of v |
| Weisfeiler–Lehman |
| , was labeled by oracles |
| , |
| end while |
| end while |
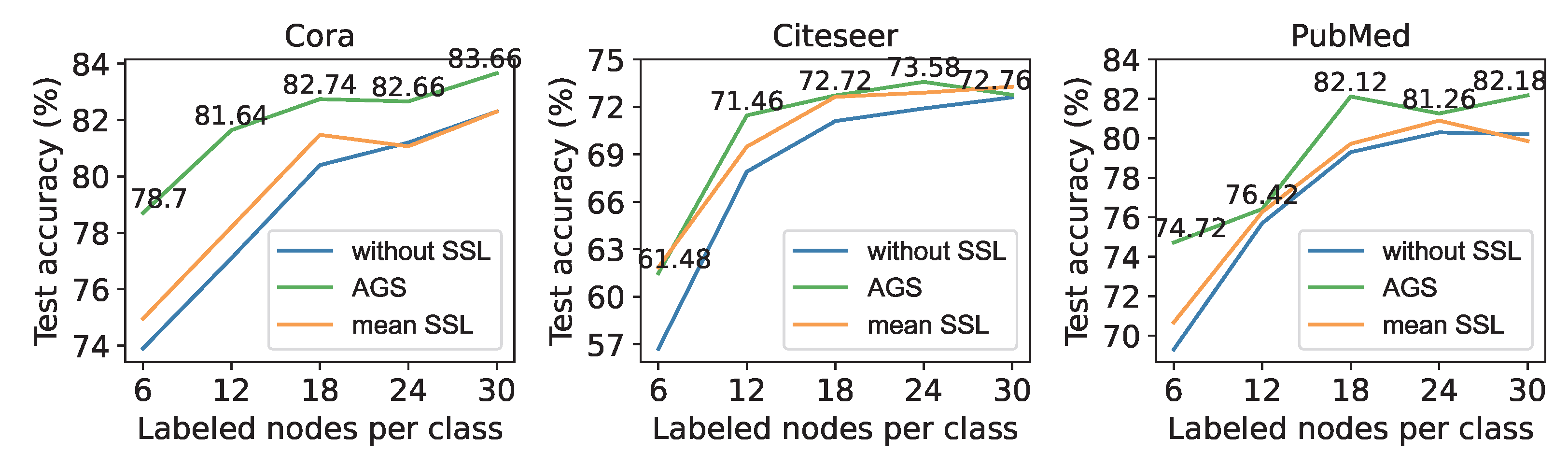
4. Experimental Results
4.1. Datasets and Experiment Settings
4.2. Results
5. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SSL | Self-supervised learning |
| GNN | Graph neural network |
| CNN | Convolutional neural network |
| RNN | Recurrent neural networks |
| GCN | Graph convolutional network |
| AGS | Auto-optimized graph self-supervised learning |
| AAGS | Active auto graph self-supervised learning |
| autoML | Auto machine learning |
References
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sarker, I.H. Deep Learning: A Comprehensive Overview on Techniques, Taxonomy, Applications and Research Directions. SN Comput. Sci. 2021, 2, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Cai, H.; Zheng, V.W.; Chang, K.C.C. A comprehensive survey of graph embedding: Problems, techniques, and applications. IEEE Trans. Knowl. Data Eng. 2018, 30, 1616–1637. [Google Scholar] [CrossRef] [Green Version]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, Y.; Jin, M.; Pan, S.; Zhou, C.; Zheng, Y.; Xia, F.; Yu, P. Graph self-supervised learning: A survey. IEEE Trans. Knowl. Data Eng. 2022. [Google Scholar] [CrossRef]
- Park, J.; Lee, M.; Chang, H.J.; Lee, K.; Choi, J.Y. Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6518–6527. [Google Scholar]
- Jin, W.; Derr, T.; Liu, H.; Wang, Y.; Wang, S.; Liu, Z.; Tang, J. Self-supervised learning on graphs: Deep insights and new direction. arXiv 2020, arXiv:2006.10141. [Google Scholar]
- Sun, K.; Lin, Z.; Zhu, Z. Multi-stage self-supervised learning for graph convolutional networks on graphs with few labeled nodes. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 5892–5899. [Google Scholar]
- Velickovic, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. In Proceedings of the 7th International Conference on Learning Representations, ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhu, Y.; Xu, Y.; Yu, F.; Liu, Q.; Wu, S.; Wang, L. Deep Graph Contrastive Representation Learning. In Proceedings of the ICML Workshop on Graph Representation Learning and Beyond, Online, 17 July 2020. [Google Scholar]
- Hu, W.; Liu, B.; Gomes, J.; Zitnik, M.; Liang, P.; Pande, V.S.; Leskovec, J. Strategies for Pre-training Graph Neural Networks. In Proceedings of the 8th International Conference on Learning Representations, ICLR, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Qiu, J.; Chen, Q.; Dong, Y.; Zhang, J.; Yang, H.; Ding, M.; Wang, K.; Tang, J. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2020; pp. 1150–1160. [Google Scholar]
- Zhu, Q.; Du, B.; Yan, P. Self-supervised training of graph convolutional networks. arXiv 2020, arXiv:2006.02380. [Google Scholar]
- You, Y.; Chen, T.; Wang, Z.; Shen, Y. When does self-supervision help graph convolutional networks? In Proceedings of the International Conference on Machine Learning. PMLR, Cambridge, MA, USA, 16–18 November 2020; pp. 10871–10880. [Google Scholar]
- Settles, B. Active Learning Literature Survey; Technical Report TR-1648; University of Wisconsin-Madison Department of Computer Sciences: Madison, WI, USA, 2009. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Chang, K.; Sun, Y. GPT-GNN: Generative Pre-Training of Graph Neural Networks. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, 6–10 July 2020; pp. 1857–1867. [Google Scholar]
- Manessi, F.; Rozza, A. Graph-based neural network models with multiple self-supervised auxiliary tasks. Pattern Recognit. Lett. 2021, 148, 15–21. [Google Scholar] [CrossRef]
- Jin, W.; Liu, X.; Zhao, X.; Ma, Y.; Shah, N.; Tang, J. Automated Self-Supervised Learning for Graphs. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar] [CrossRef]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification. Bioinformatics 2003, 1, 1396–1400. [Google Scholar]
- Thornton, C.; Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Auto-WEKA: Combined selection and hyperparameter optimization of classification algorithms. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD, Chicago, IL, USA, 11–14 August 2013; pp. 847–855. [Google Scholar]
- Stamoulis, D.; Ding, R.; Wang, D.; Lymberopoulos, D.; Priyantha, B.; Liu, J.; Marculescu, D. Single-path nas: Designing hardware-efficient convnets in less than 4 hours. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2019; pp. 481–497. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural Architecture Search with Reinforcement Learning. In Proceedings of the 5th International Conference on Learning Representations, ICLR, Toulon, France, 24–26 April 2017. [Google Scholar]
- Liu, H.; Simonyan, K.; Yang, Y. DARTS: Differentiable Architecture Search. In Proceedings of the 7th International Conference on Learning Representations, ICLR, Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Yao, Q.; Wang, M.; Chen, Y.; Dai, W.; Li, Y.F.; Tu, W.W.; Yang, Q.; Yu, Y. Taking human out of learning applications: A survey on automated machine learning. arXiv 2018, arXiv:1810.13306. [Google Scholar]
- Aggarwal, C.C.; Kong, X.; Gu, Q.; Han, J.; Philip, S.Y. Active learning: A survey. In Data Classification; Chapman and Hall/CRC: London, UK, 2014; pp. 599–634. [Google Scholar]
- Settles, B.; Craven, M. An Analysis of Active Learning Strategies for Sequence Labeling Tasks. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 1070–1079. [Google Scholar]
- Bilgic, M.; Mihalkova, L.; Getoor, L. Active Learning for Networked Data. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 79–86. [Google Scholar]
- Zhang, Y.; Lease, M.; Wallace, B.C. Active Discriminative Text Representation Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3386–3392. [Google Scholar]
- Guo, Y.; Greiner, R. Optimistic active-learning using mutual information. In Proceedings of the IJCAI, Hyderabad, India, 6–12 January 2007; pp. 823–829. [Google Scholar]
- Schein, A.I.; Ungar, L.H. Active learning for logistic regression: An evaluation. Mach. Learn. 2007, 68, 235–265. [Google Scholar] [CrossRef]
- Li, X.; Guo, Y. Active Learning with Multi-Label SVM Classification. In Proceedings of the IJCAI 2013—23rd International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1479–1485. [Google Scholar]
- Cai, H.; Zheng, V.W.; Chang, K.C. Active Learning for Graph Embedding. arXiv 2017, arXiv:1705.05085. [Google Scholar]
- Madhawa, K.; Murata, T. Active learning for node classification: An evaluation. Entropy 2020, 22, 1164. [Google Scholar] [CrossRef] [PubMed]
- Hao, Z.; Lu, C.; Huang, Z.; Wang, H.; Hu, Z.; Liu, Q.; Chen, E.; Lee, C. ASGN: An Active Semi-supervised Graph Neural Network for Molecular Property Prediction. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, 6–10 July 2020; pp. 731–752. [Google Scholar]
- Li, Y.; Yin, J.; Chen, L. Seal: Semisupervised adversarial active learning on attributed graphs. IEEE Trans. Neural Networks Learn. Syst. 2020, 32, 3136–3147. [Google Scholar] [CrossRef] [PubMed]
- Ahsan, R.; Zheleva, E. Effectiveness of Sampling Strategies for One-shot Active Learning from Relational Data. In Proceedings of the 16th International Workshop on Mining and Learning with Graphs (MLG), San Diego, CA, USA, 24 August 2020. [Google Scholar]
- Wang, S.; Wang, Z.; Che, W.; Zhao, S.; Liu, T. Combining Self-supervised Learning and Active Learning for Disfluency Detection. Trans. Asian -Low-Resour. Lang. Inf. Process. 2021, 21, 1–25. [Google Scholar] [CrossRef]
- Bengar, J.Z.; van de Weijer, J.; Twardowski, B.; Raducanu, B. Reducing Label Effort: Self-Supervised Meets Active Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Virtual, 10 March 2021; pp. 1631–1639. [Google Scholar]
- Shervashidze, N.; Schweitzer, P.; Van Leeuwen, E.J.; Mehlhorn, K.; Borgwardt, K.M. Weisfeiler-lehman graph kernels. J. Mach. Learn. Res. 2011, 12, 2539–2561. [Google Scholar]
- Yang, Z.; Cohen, W.W.; Salakhutdinov, R. Revisiting Semi-Supervised Learning with Graph Embeddings. In Proceedings of the 33nd International Conference on Machine Learning, ICML, New York, NY, USA, 19–24 June 2016; pp. 40–48. [Google Scholar]
- Laurens, V.D.M.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Graph | Nodes | Edges | Classes | Features |
|---|---|---|---|---|---|
| Cora | 1 | 2708 | 5429 | 7 | 1433 |
| Citeseer | 1 | 3312 | 4732 | 6 | 3703 |
| PubMed | 1 | 19,717 | 44,338 | 3 | 500 |
| Self-Supervised Tasks | Dataset | ||
|---|---|---|---|
| Cora | Citeseer | PubMed | |
| GCN backbone | 81.52 ± 0.43% | 71.94 ± 0.22% | 79.46 ± 0.30% |
| EdgeMask | 82.04 ± 0.88% | 71.36 ± 1.06% | 79.34 ± 0.54% |
| Distance2Cluster | 83.22 ± 0.44% | 71.60 ± 0.37% | 79.02 ± 0.38% |
| PairwiseAttrSim | 82.14 ± 0.52% | 71.92 ± 0.12% | 79.52 ± 0.31% |
| Distance2Labeled | 83.36 ± 0.72% | 71.52 ± 0.49% | 79.10 ± 0.28% |
| ICAContextLabel | 83.54 ± 0.39% | 72.70 ± 0.53% | 82.38 ± 0.18% |
| LPContextLabel | 81.38 ± 0.60% | 72.44 ± 0.46% | 79.86 ± 0.27% |
| CombinedContextLabel | 83.32 ± 0.32% | 73.02 ± 0.40% | 82.72 ± 0.31% |
| NodeProperty | 82.00 ± 0.82% | 72.02 ± 0.31% | 79.38 ± 0.47% |
| AGS (ours) | 83.56 ± 0.18% | 73.68 ± 0.20% | 83.02 ± 0.61% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Y.; Liu, K.; Cao, Z.; Zhang, J. Self-Supervised Node Classification with Strategy and Actively Selected Labeled Set. Entropy 2023, 25, 30. https://doi.org/10.3390/e25010030
Kang Y, Liu K, Cao Z, Zhang J. Self-Supervised Node Classification with Strategy and Actively Selected Labeled Set. Entropy. 2023; 25(1):30. https://doi.org/10.3390/e25010030
Chicago/Turabian StyleKang, Yi, Ke Liu, Zhiyuan Cao, and Jiacai Zhang. 2023. "Self-Supervised Node Classification with Strategy and Actively Selected Labeled Set" Entropy 25, no. 1: 30. https://doi.org/10.3390/e25010030