1. Introduction
According to the statistics, most traffic accidents are caused by some interference with normal or non-standard driving behaviors. Among them, playing with mobile phones, making calls, and talking with passengers and other non-standard behaviors account for the majority [
1,
2]. With the acceleration in urbanization and the increase in per capita income, vehicle ownership is also on the rise. In 2021, the number of motor vehicles in China reached 395 million, of which 302 million were automobiles, and the number of motor vehicle drivers reached 481 million, of which 444 million were motor vehicle drivers. The number of traffic accidents has also increased with vehicle ownership. Therefore, it is significant for traffic safety to recognize non-standard driving behaviors quickly and accurately.
The driving behavior recognition method based on deep learning is considered to be a promising method, which is a practical application. It can be divided into two types: one is classification and recognition based on the traditional convolutional neural network, and the other is object detection and recognition based on the convolutional neural network. Constructed by transfer learning and supervised learning, the convolutional neural network model can recognize driving behaviors such as calling and smoking [
3]. Based on the CNN and random decision forest, the driving behavior detection model DriveNet can improve the classification performance [
4]. An ensemble model based on the combination of Vgg16 and GoogleNet has been used to identify the driving behavior, which improved the classification accuracy [
5]. The feature maps of CNN are fused by convolution kernels of different sizes to realize the recognition of driving behavior by multi-scale network fusion [
6]. Improved by regularized pruning, the VGG network can obtain higher accuracy with fewer parameters and greatly save on computing time [
7].
The traditional convolutional neural network method can solve the basic problem of driving behavior recognition and classification, but there are still some problems such as less effective feature information and the high similarity between behaviors. Because of the large scale of the network, the amount of computation, and the lack of the real-time performance on the hardware with low performance, the driving behavior recognition algorithm based on the convolutional neural network still has great problems in practical application. In contrast, an object detection and recognition algorithm based on a convolutional neural network has strong robustness and adapt ability, it improves the detection accuracy and real-time speed significantly, and reduces the parameter quantity and floating point computation.
The two-stage object detection algorithm is based on candidate regions. Based on the fusion model of DRN and Faster R-CNN, a behavior recognition algorithm replaces two-layer residual blocks with three-layer dilated convolution residual blocks, which has achieved a better recognition effect in the behavior recognition. However, due to the large size of the model, the real-time performance is obviously insufficient [
8]. Based on MobileNetV3 and ST-SRU, an algorithm was used to recognize dangerous driving behaviors. It estimates the two-dimensional coordinates of the joints and classifies the actions according to the skeleton sequences of the actions. Its accuracy is better with fewer parameters, and the real-time is improved, however, the model only obtains good performance in a simulated driving environment, and the generalization ability is not strong [
9]. Based on the Tutor–Student network, the driving behavior recognition algorithm divides the driving behaviors into two sub-tasks: action localization and action classification. After guidance by the tutor network, the student model has high recognition accuracy and strong robustness, but the computation expense is too high for low-performance devices [
10]. Based on the improved SSD, the driving behavior recognition algorithm uses the residual learning to make the network learning easier, and introduces a multi-layer feature pyramid to improve the object detection accuracy, but the recognition accuracy changes greatly with different detection environments, and the generalization ability is insufficient [
11].
To improve the driving behavior detection accuracy and detection speed, for the issues of a large number of parameters, less effective feature information, and low detection speed, in this paper, a fusion driving behavior recognition algorithm with an attention mechanism and a lightweight network is proposed. The algorithm selects YOLOV4 as the basic framework. For the lightweight network parameters, the YOLOV4 [
12] feature extraction network was reconstructed with the lightweight network MobileNetV3 [
13], and the
convolutions in the FPN network was replaced by
convolution. To retain the effective information of the driving behaviors and reduce the influence of useless information, improved channel attention mechanism and spatial attention mechanism were introduced. To verify the effect of the lightweight network and attention mechanism on the network, ablation experiments were carried out. The results show that the algorithm maintained a high behavior recognition accuracy with the reduction in the parameters. Compared with the current mainstream object detection algorithms, the algorithm in this paper still had good performance.
3. Algorithm Improvement
After adopting many optimization strategies to improve its own shortcomings, the YOLOv4 object detection algorithm performed well in various evaluation indexes under the standard dataset of high-performance devices. When the algorithm is deployed on mobile devices with poor hardware performance, it does not need high accuracy, but high prediction speed, according to different application environments. In the case of limited computing power and memory resources of mobile devices, the size of the algorithm model becomes particularly important. Obviously, the YOLOv4 algorithm is difficult to apply to mobile object detection devices. Therefore, in this paper, an improved object detection algorithm based onYOLOv4 is proposed, and there are two innovations as follows:
The feature extraction network of YOLOV4 is improved. The model is pruned and the parameter quantity is reduced, but the accuracy of the network is not reduced. The CSPDarknet53 in YOLOV4 is replaced by the improved MObileNetV3 network model.
The attention mechanism structure is improved, the weights of the invalid features are reduced to retain effective features and improve the identification accuracy of the driving behavior.
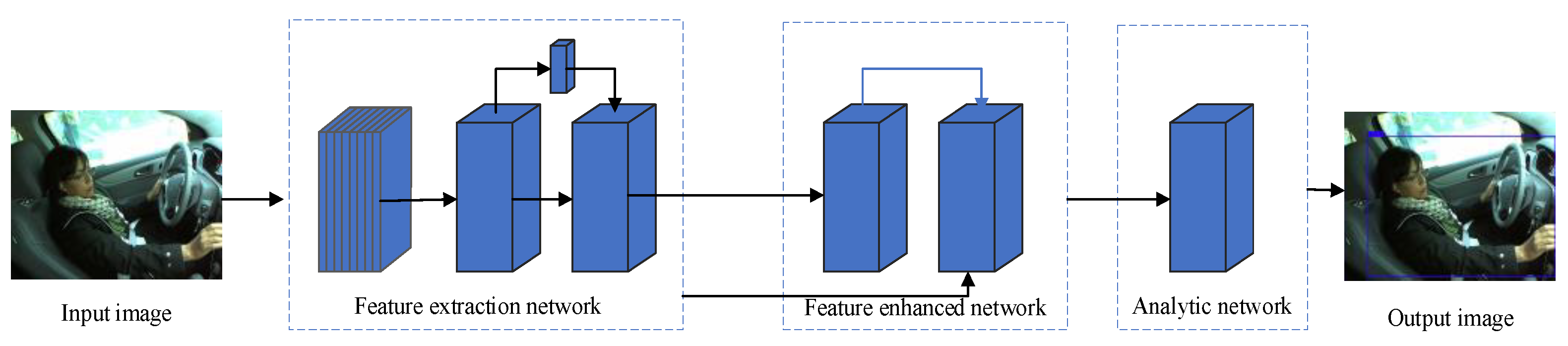
Figure 4 shows the driving behavior detection model built in this paper, which is mainly composed of a feature extraction network and a driving behavior detection network. The input image data obtained high-level semantic features through the feature extraction network, and the features were fused through the attention mechanism. Afterward, the detection network predicts the position and size of the driving behavior and obtains the prediction boundary box.
3.1. Improvement of Feature Extraction Network
The feature extraction network of the driving behavior recognition model was constructed based on MobileNetV3 and integrated with the attention mechanism. In order to use the location information of the shallow feature image and semantic information of the deep feature image, the feature fusion of shallow feature image and deep feature image wascarried out in the attention network. This was implemented inthe following steps: first, the number of feature parameters was reduced by deep separable convolution operation, and then the feature images were expanded and input into the attention module after up-sampling, and finally, three different feature images were generated.
In this paper, 640 × 480 images were created as three-channel images and input into the network. The original image size was 416 × 416, and after five operations of the bottleneck structure in MobileNetV3, three effective feature layers were obtained, and their sizes were 52 × 52, 26 × 26, and 13 × 13, respectively. The 13 × 13 feature layers were input into the spatial pyramid pooling (SPP) network, and feature fusion was carried out by different sizes pooling layers to improve the receptive field and separate effective features.
Then, the three groups of feature layers were input into the path aggregation network (PANet) for fusion. The bottom-up feature fusion path in PANet can effectively integrate richer feature information. To further reduce the number of network parameters, the traditional convolutions in PANet were replaced by depth-wise separable convolution.
Finally, the three groups of feature layers after feature fusion predict the three boundary boxes for each position. There were 10 types of driving actions in the dataset. During identification and prediction, the network generated (5 + 10) predictive values for each boundary box, among which the first four values were abscissa, ordinate, width of the prediction box, and height of the prediction box. The fifth value was the confidence degree that the object is predicted as a certain category, and the following values were the 10 predicted category labels.
3.2. Improvement of Attention Mechanism
In the process of feature extraction by the convolutional network, with the increase in the network depth, the size of the feature map continues to decrease, and the number of channels continues to increase. There are more outline features in the low-level network, and each feature map in the high-level network has rich semantic information. Different feature maps only contain a part of the semantic feature information of the driving behavior. At the same network level, the semantic information of different channel features is combined into the representation of driving behaviors in the current network layer [
18]. The expression of driving behavior in a feature map can be defined as Equation (3):
In Equation (3), is the n-th feature map in a convolutional layer, is the i-th region of a feature layer, , , represents whether there is driving behavior information in the i-th region.
Because the weight of the traditional CNN channel is usually fixed and equal, the ability for a different expression of the network is limited. If the weight of each channel is recalculated, the feature channel of the object’s visible region contributes more to the final convolution feature, which can highlight the object feature in the background. The weight of the channel can be calculated as Equation (4):
In Equation (4), is the feature channel, and is the weight. The channel attention mechanism is to continuously learn new and reweigh the channel, so that the network can adapt to different feature channels.
In MobileNetV3, it only uses the channel attention mechanism and ignores the importance of spatial information for the feature map. The spatial information of feature maps is helpful to the network to focus on the object’s regions of interest, so the feature channel attention mechanism and spatial attention mechanism can be used in the image description [
19]. When the spatial attention mechanism is applied to the object detection, useful features are highlighted in the network [
20]. The feature spatial information was used in the driving behavior detection, and a spatial attention module was constructed to highlight the driver object region. Based on the spatial information of the feature map, the spatial attention module obtains the weights of the spatial attention and reactivates the input features to lead the network to pay attention to the driving behavior and suppress the background interference.
The attention network consists of two sub-modules: channel attention and space attention. In the attention network, the input features are connected in channel dimensions, F, and then F is input into the channel attention and spatial attention module for feature fusion.
From the above analysis, according to the attention model, the channel information and the spatial information of the feature map can be constructed, and the network can strengthen the presentation ability of the regional features and obtain the position of the region of interest. It uses the effective features and suppresses the useless information. To improve the accuracy of the detection of continuous actions, the residuals with dilatative convolution were used to reduce the parameter quantity in the spatial attention model, and the sensing field was also improved.
3.2.1. Improvement of Channel Attention
Channel attention focuses on the input feature map. First, global maximum pooling and mean pooling are used to map the feature information to form two different channel descriptions. represents the channel information after average pooling for F, and represents the channel information after maximum pooling F.
Because of the low computational budget, lightweight convolutional neural networks are limited in the depth and width of CNNs, which led to the decline in the model performance and the limitation in representation ability.
In this paper, a one-dimensional convolution with adaptive dimension
k was adapted to aggregate the feature information of k neighborhood channels. The size of the convolution kernel can be adaptively adjusted according to the number of channels. The information of the two channels were added together and activated by sigmoid function to generate channel attention
, and were then multiplied with the original input feature to inject the channel attention mechanism. The specific calculation process is shown in Equations (5) and (6). The attention structure of the improved feature channel is shown in
Figure 5.
In Equation (5),
σ represents sigmoid activation function, and
represents a one-dimensional convolution operation with convolution whose kernel size is
k.
In Equation (6), C is the number of channel of the feature map, is the nearest odd number to *, and .
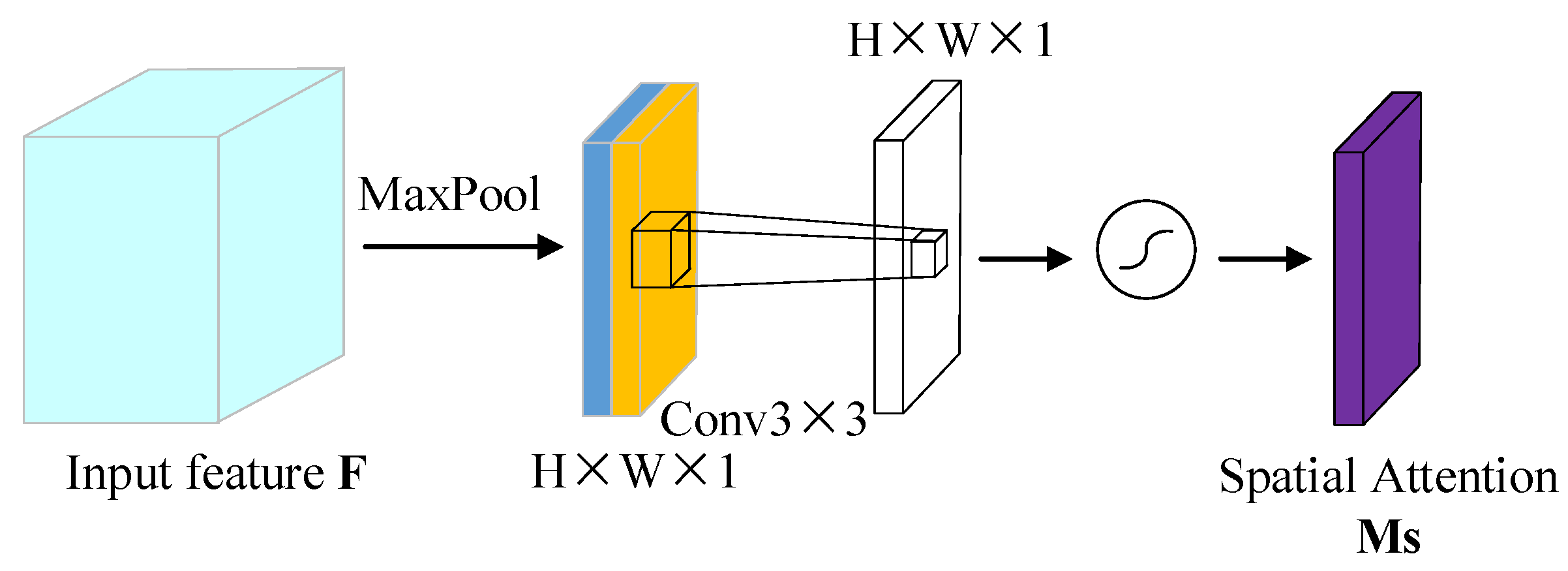
3.2.2. Improvement of Spatial Attention Module
Because the useful information of the detected object is usually covered by the background, when the feature expression is enhanced through the channel attention module, the spatial location of the useful information needs to be determined. Unlike the channel attention mechanism, the spatial attention mechanism is mainly used to highlight the region associated with the current task in the feature map, which is to guide the network to focus on the visible region of the object. To solve the problem of network degradation caused by the addition of the convolution layer in a deep network, the convolution structure in the original network is replaced by the residual structure with dilated convolution. As shown in
Figure 6, in the spatial attention module, the channel attention was introduced into feature information, and global average pooling (GAP) and global max pooling (GMP) were carried out. Two different types of channel information
and
were generated and concatenated to generate a more effective spatial feature layer. Then, the residual structure with dilatative convolution was used to further aggregate the information in the upper and lower space to improve the receptive field. After sigmoid function activation, the spatial attention model
was generated. Finally, the spatial attention model
was multiplied by the corresponding elements of the input feature to inject the spatial attention mechanism.
The specific calculation process is shown in Equation (7):
In Equation (7), represents the expansion convolution with the convolution kernel size of 3, and represents the standard convolution whose kernel size is1.
3.3. Improvement of Loss Function
The driving behavior detection task was regarded as a kind of high-level semantic feature detection. On the basis of the semantic features, the final prediction boundary box was obtained through the driving behavior parsing network. In this paper, the driver’s position, category, and height were predicted, and the boundary box was obtained by simple geometric conversion. After obtaining the driver’s predicted height h, according to the ratio of the height to the width a, the width of the boundary box can be calculated.
When the lightweight YOLOV4 detects the driving behavior, it first determines the position of the object in the annotated image, and then classifies the object in the ground truth box. It can be described as follows: input the image
X, locate and classify the image according to the task requirements, and adjust the loss of anchor box
and confidence
. The loss function is shown in Equation (8).
In Equation (8), N is the number of anchor box, ∂ is the scale between and , whose default value is 1; c is the predicted value of the category confidence; l is the anchor box position of the boundary box; g is the position parameter of the real object; x is an indicator parameter whose standard form is , which is the probability of p class when the i-th anchor box matches the j-th object.
The position loss function
adopts smoothL1. It combines the advantages of L1 loss and L2 loss, which can speed up network training and smoothen the gradient of the object image changes. The formula is shown as Equation (9), and the parameters in Equation (9) are shown in Equations (10)–(14).
According to
, only positive samples work in training the anchor box, therefore, the SoftMax loss function is used for the probability loss of the category, which is composed of the SoftMax and cross entropy loss. The loss function becomes smaller when the predicted value is closer to the true value and vice versa. The optimization process increasingly showed more predicted values close to the true values, thus reducing the loss function to speed up the fitting, which is shown in Equation (15):
In Equation (15), represents the probability that the i-th anchor box is predicted as p, and represents the probability that the i-th category is predicted as the foreground when p is predicted.
5. Conclusions
In this paper, YOLOV4 and MobileNetV3 were fused, the model parameter quantity was further reduced by using the lightweight deep separable convolution, and the channel attention and spatial attention were improved. On the Kaggle dataset, the accuracy of our algorithm achieved 96.49%, the parameters of the model occupied 12.629 M, and the FLOPs was10.652 G. It can also be used for real-time detection. However, in the practical application of the driving behavior recognition algorithm, various factors such as continuity, diversity, and coincidence of driver actions should be taken into account. A time sequence network can be introduced to perform the time sequence analysis of actions, or fuse multi-feature network to prevent false detection caused by a single detection method. There is still some improvements to be made in detection and tracking in fast movement scenes, and the real-time performance will decline in deeper networks. In the future, we will devote study as to how to prune the model to further simplify the network structure to meet the actual deployment applications.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}