
Gaussian Amplitude Amplification for Quantum Pathfinding

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
Layout
2. Gate-Based Grover’s
2.1. Optimal Amplitude Amplification
| Algorithm 1 Grover’s Search Algorithm |
|
2.2. Alternate Two-Marked Oracle
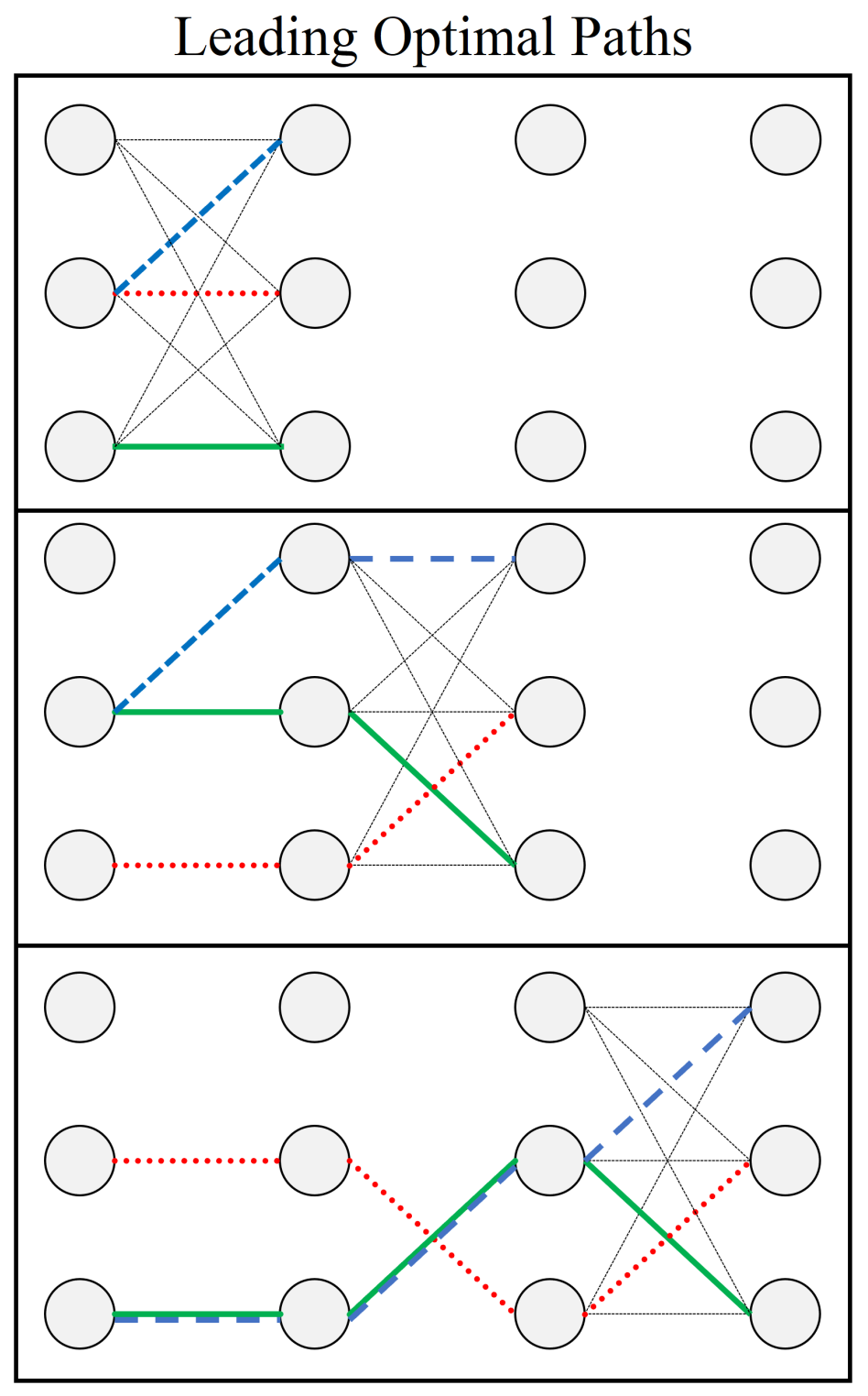
3. Pathfinding Geometry
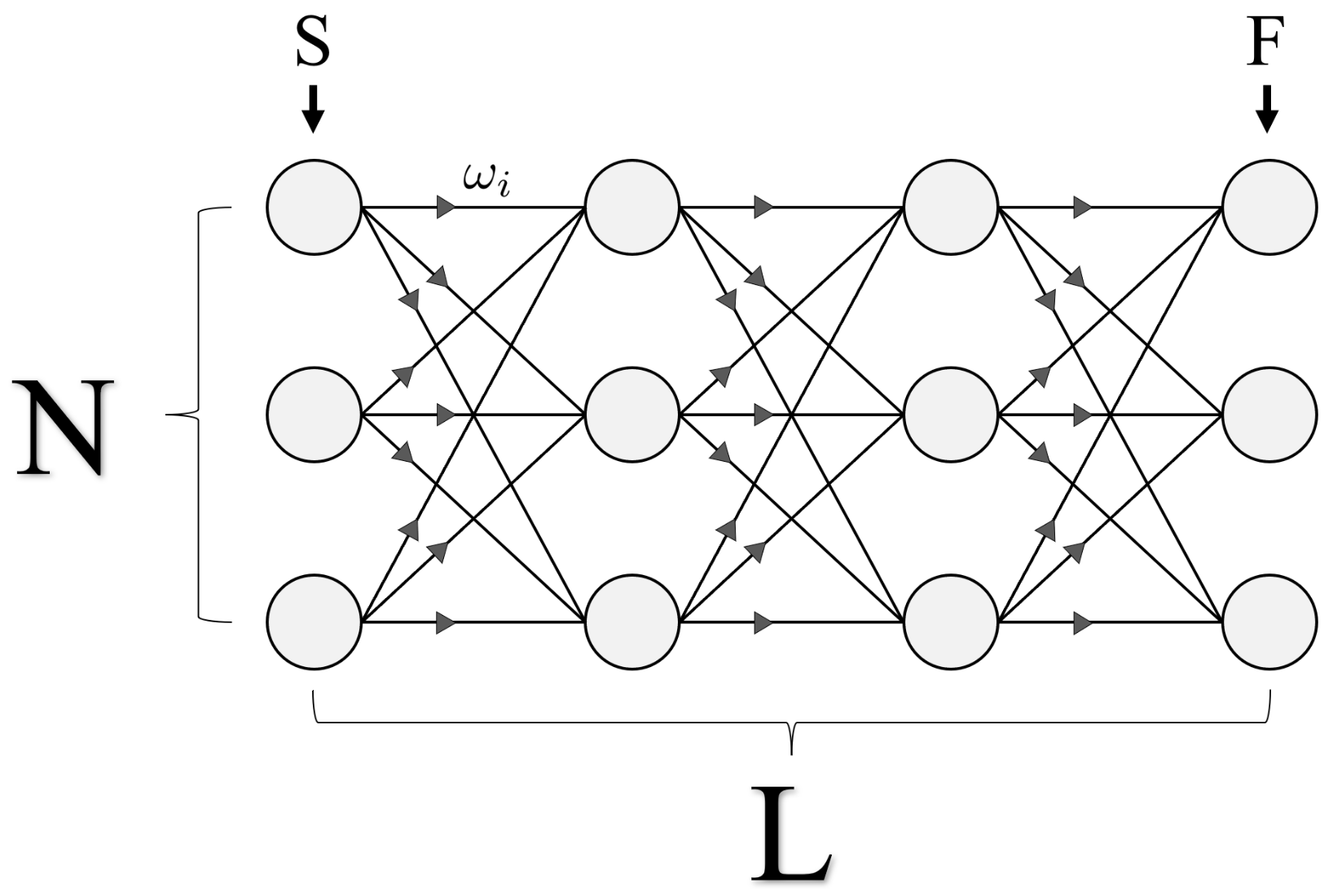
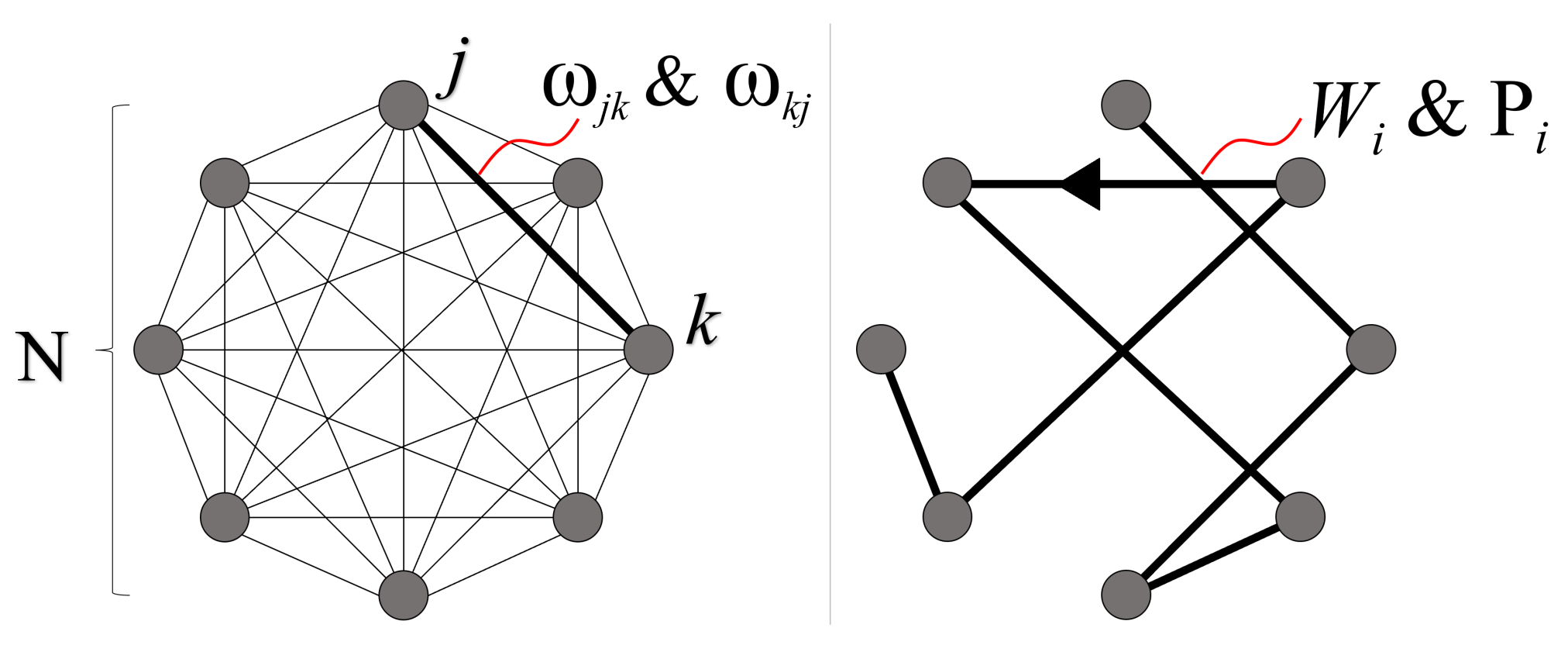
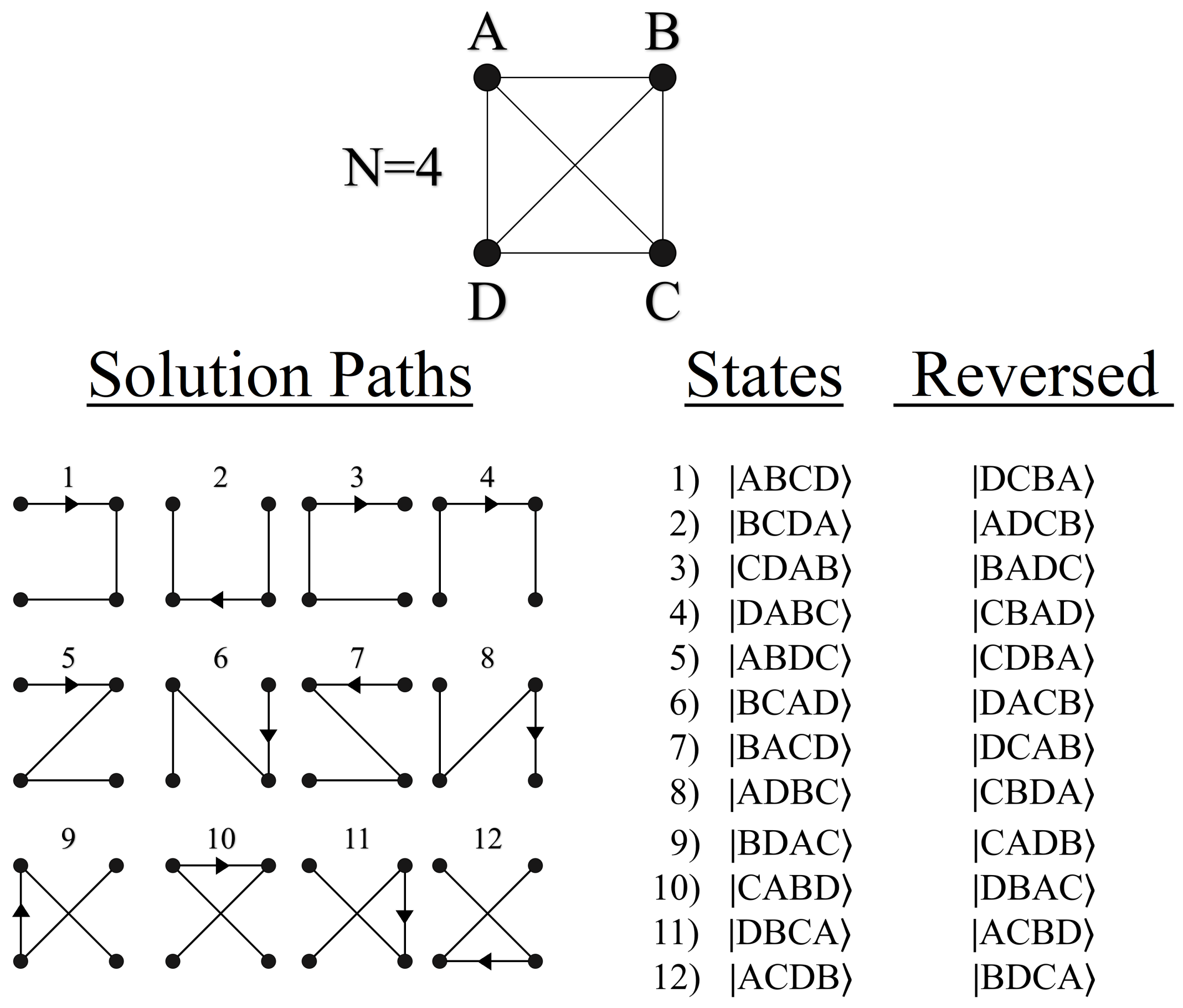
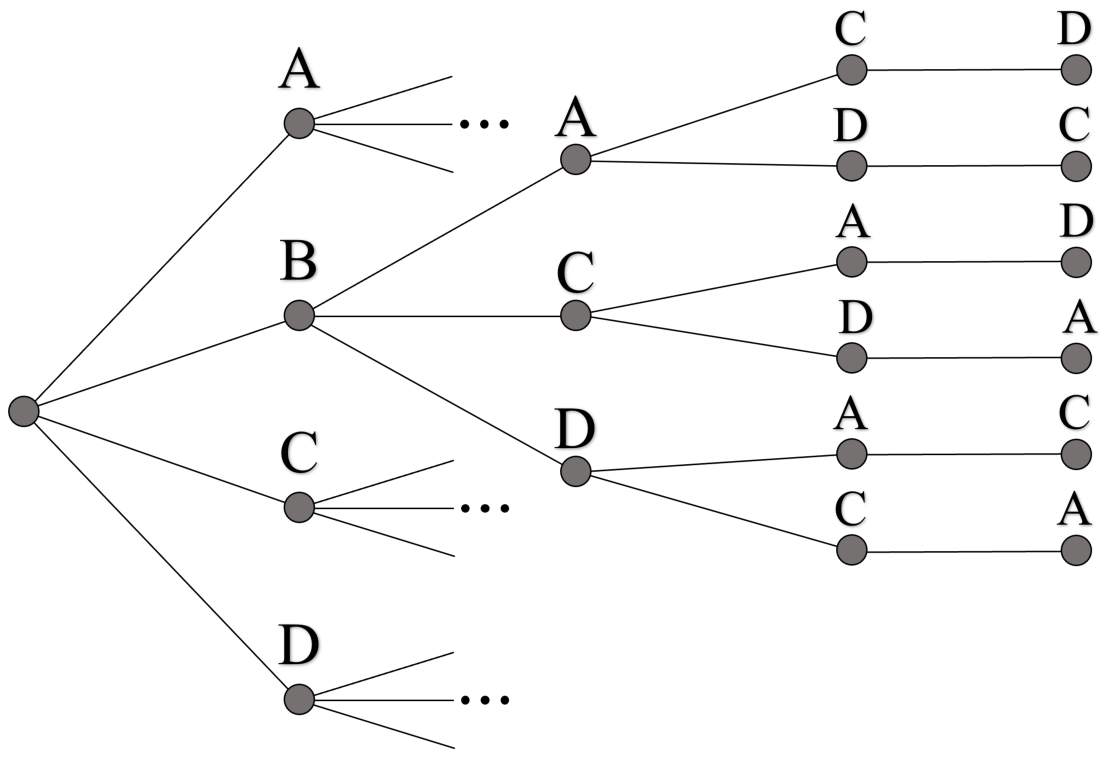
3.1. Graph Structure
3.2. Classical Solving Speed
| Algorithm 2 Classical Pathfinding |
|
4. Quantum Cost Oracle
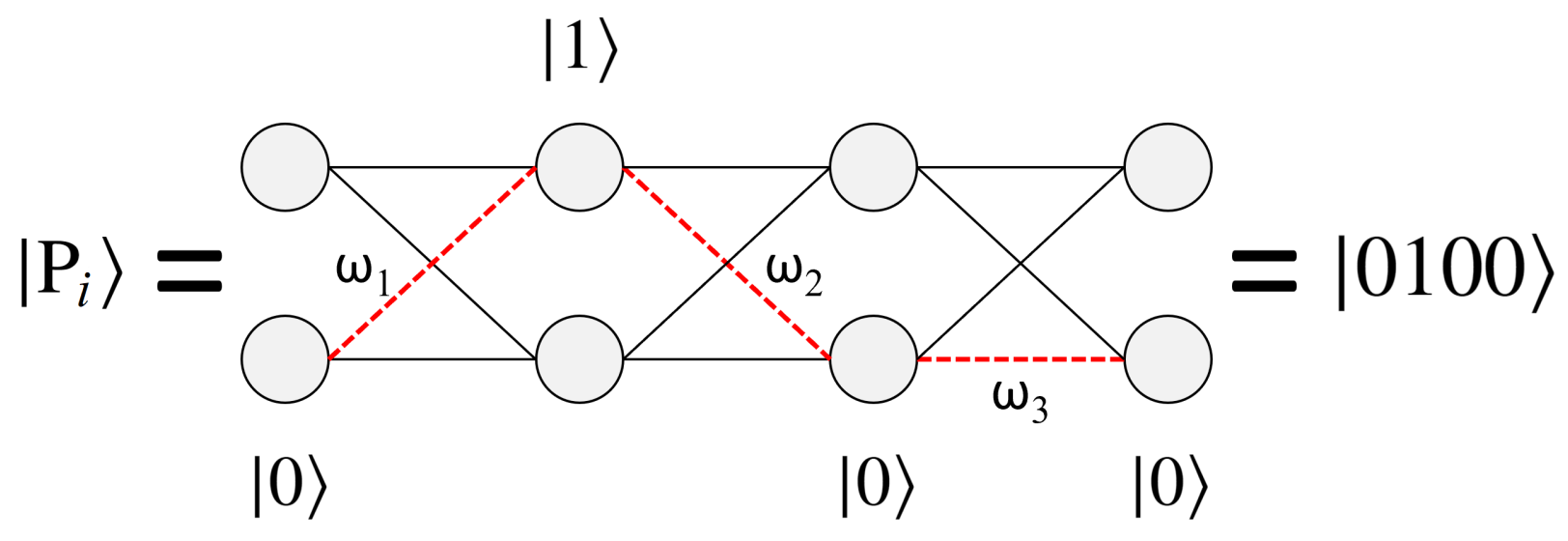
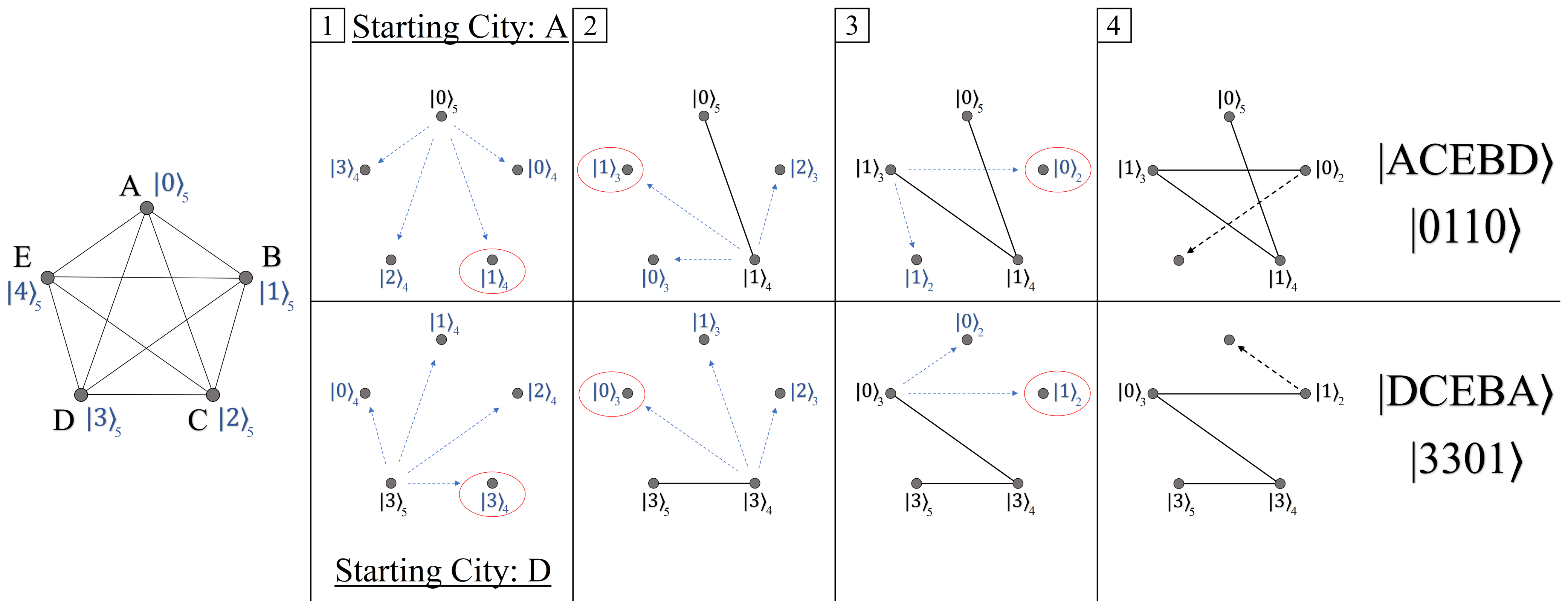
4.1. Representing Paths in Quantum
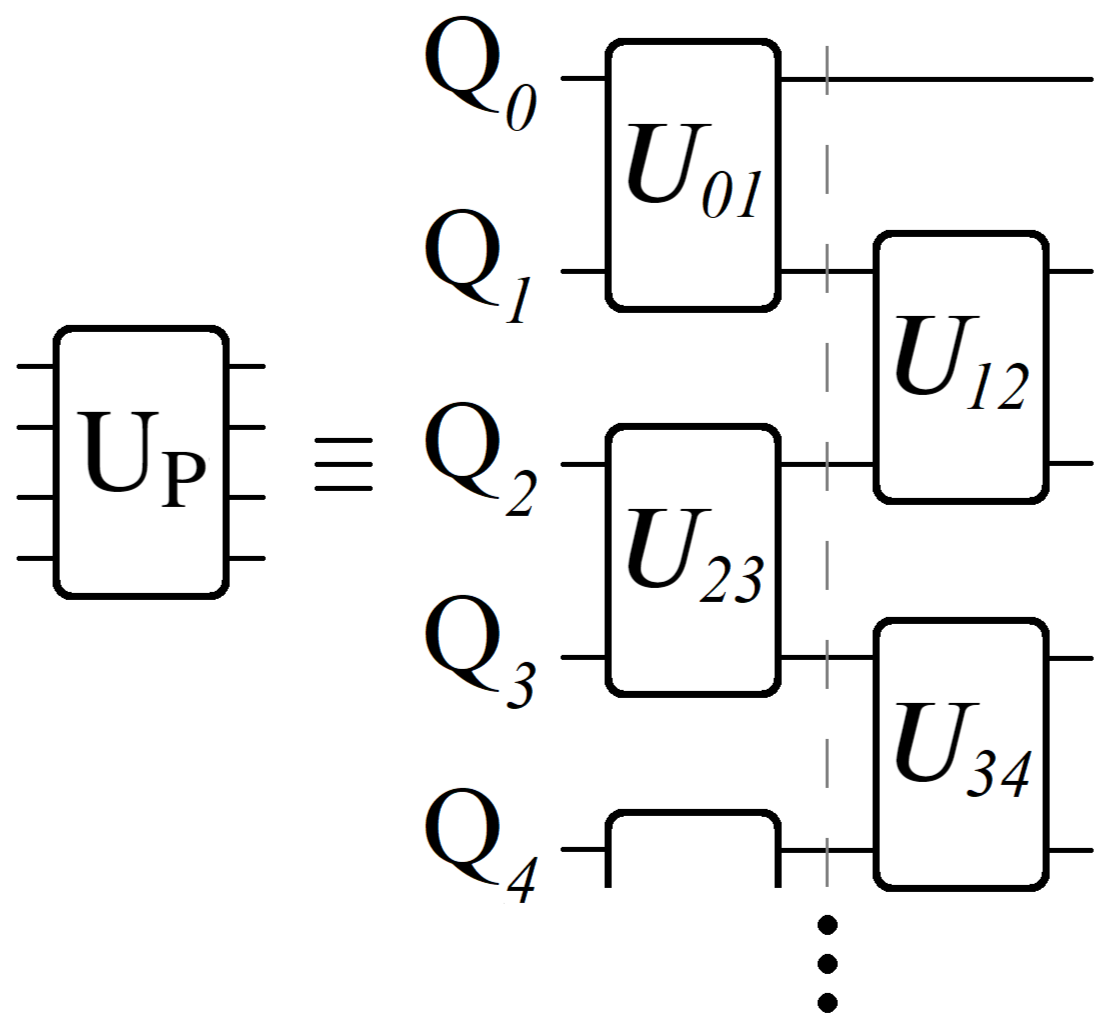
4.2. Cost Oracle UP
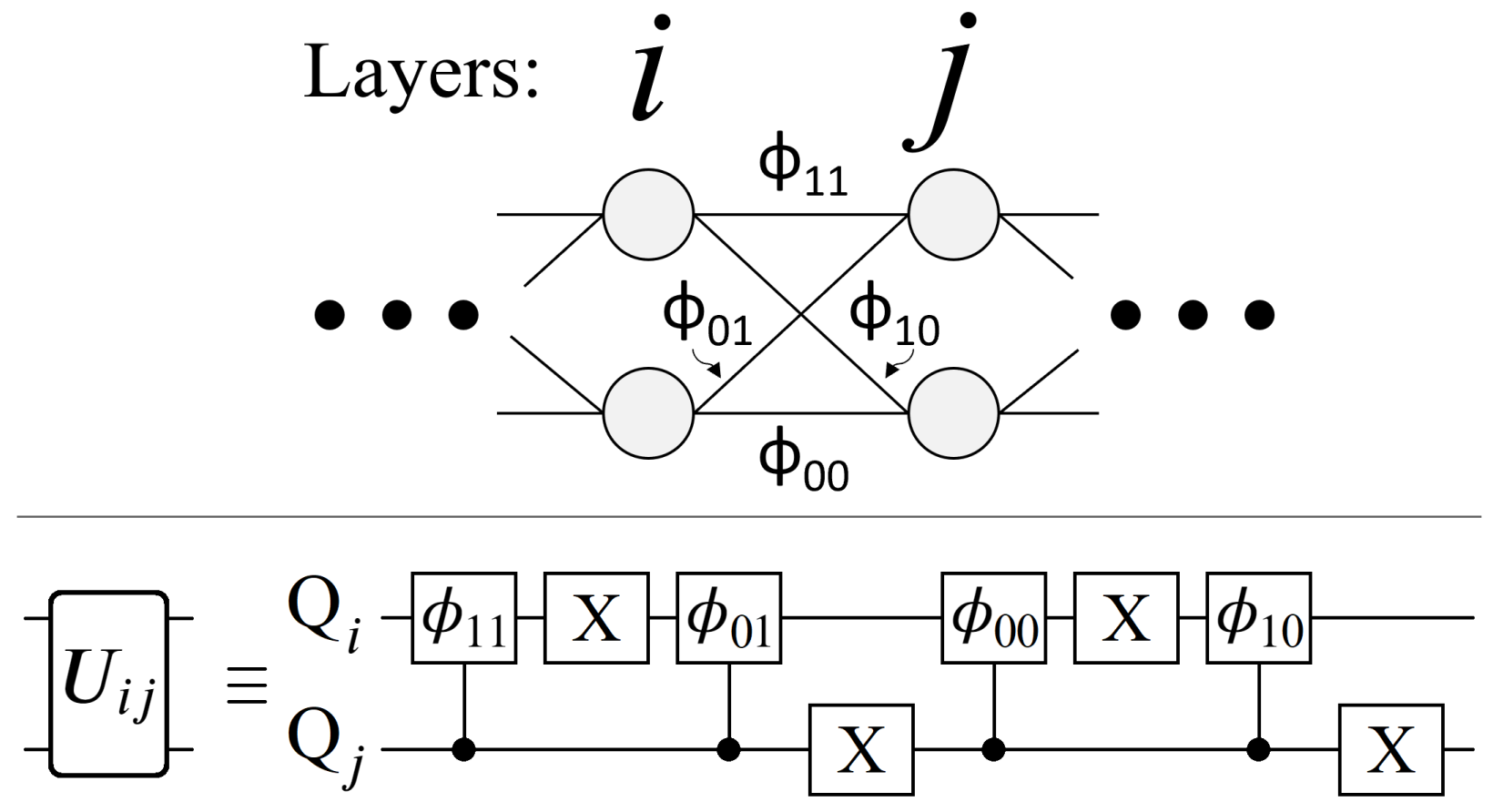
4.3. Quantum Circuit
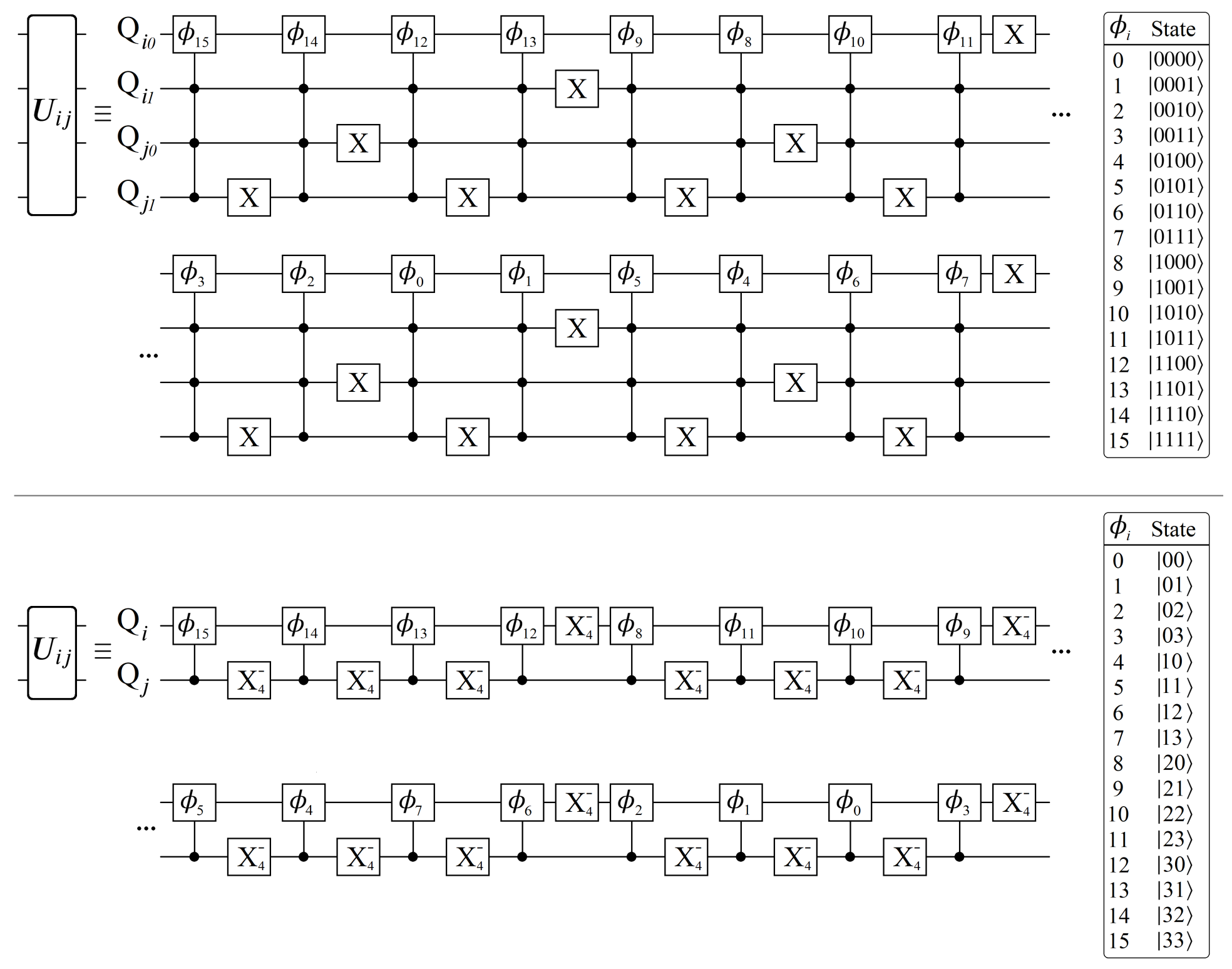
4.4. Qudit Quantum Circuit
5. Gaussian Amplitude Amplification
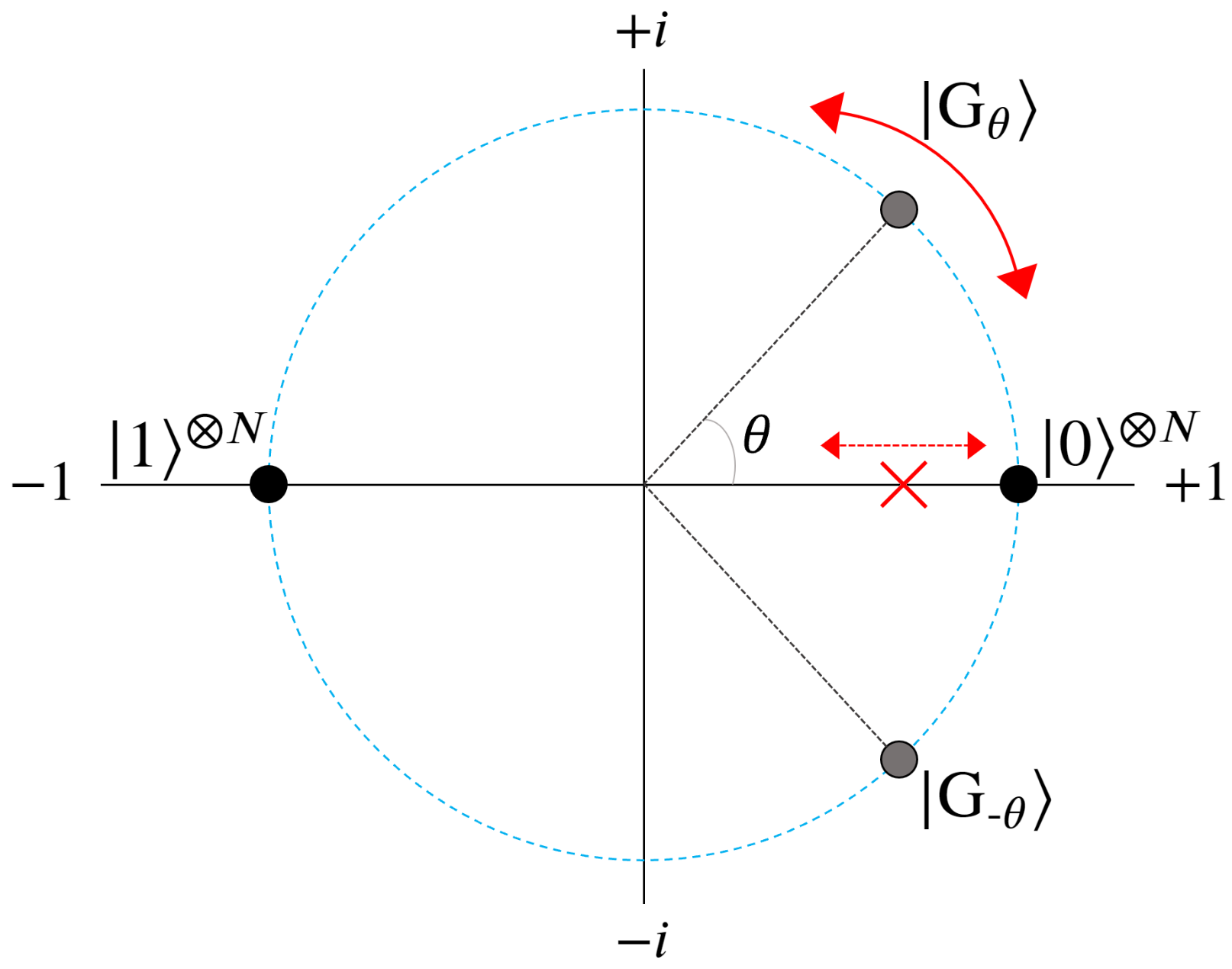
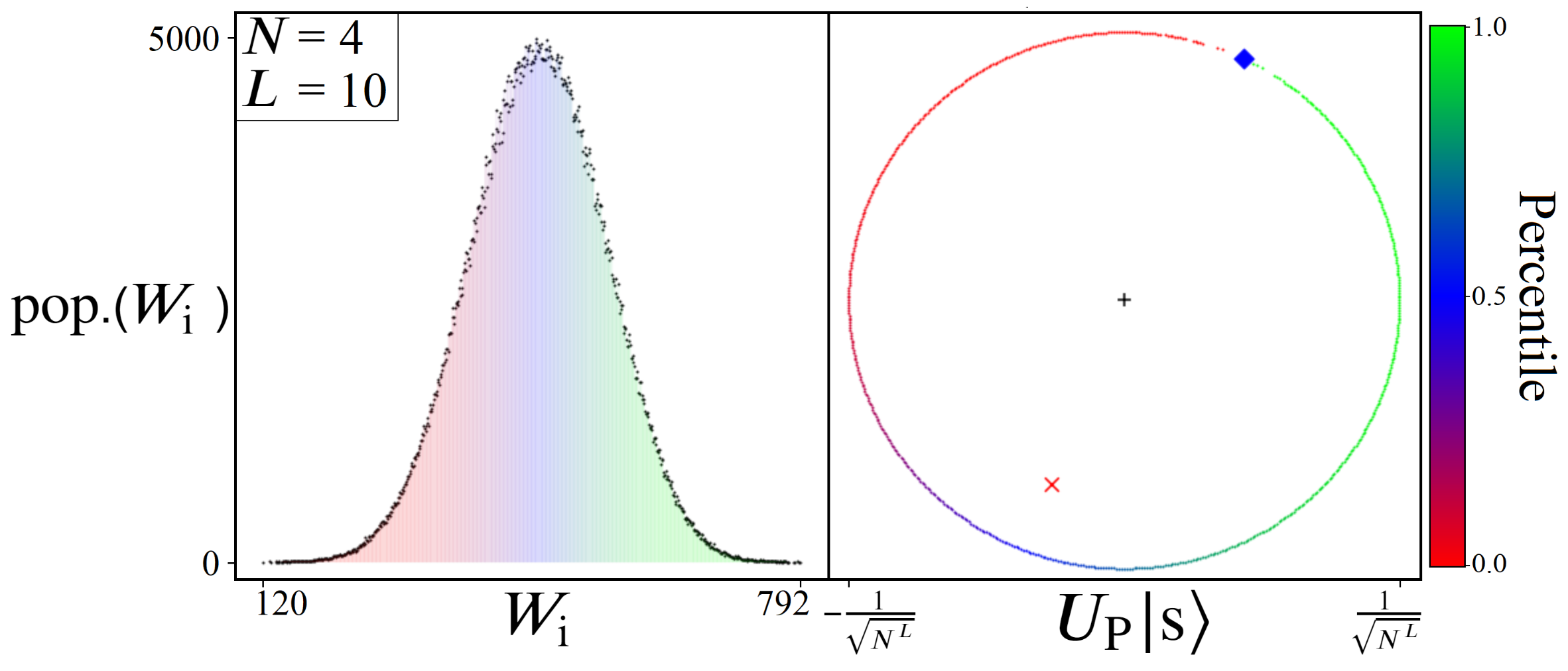
5.1. Solution Space Distributions
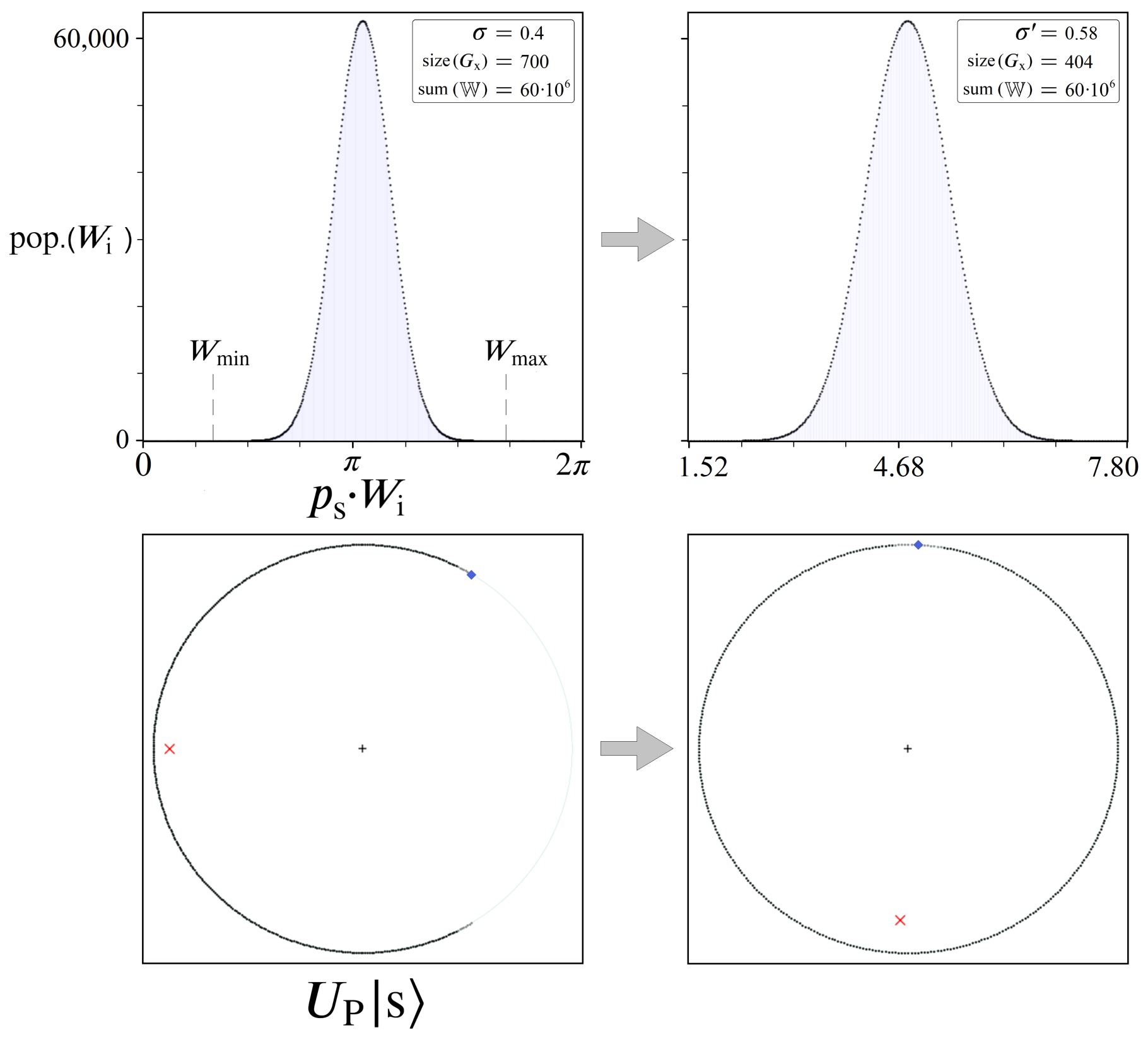
5.2. Mapping to 2π
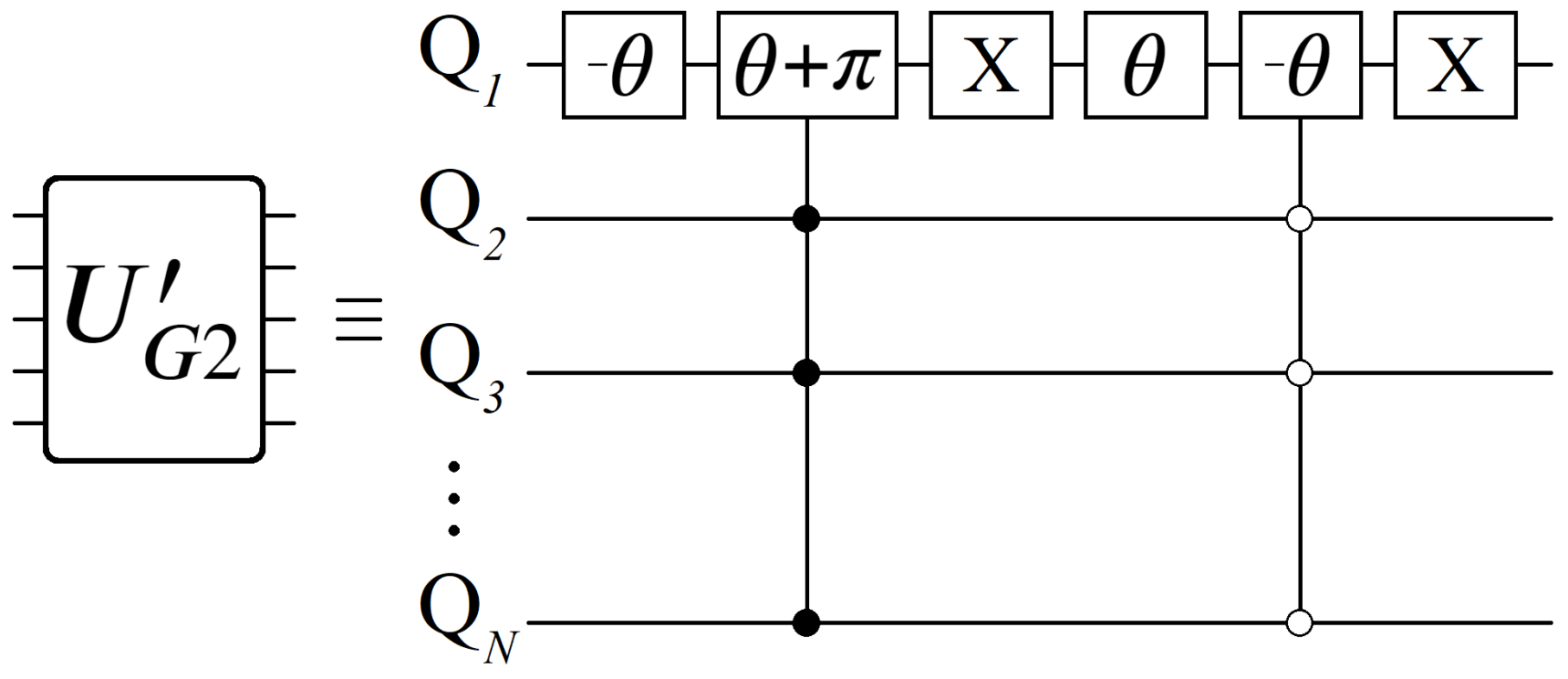
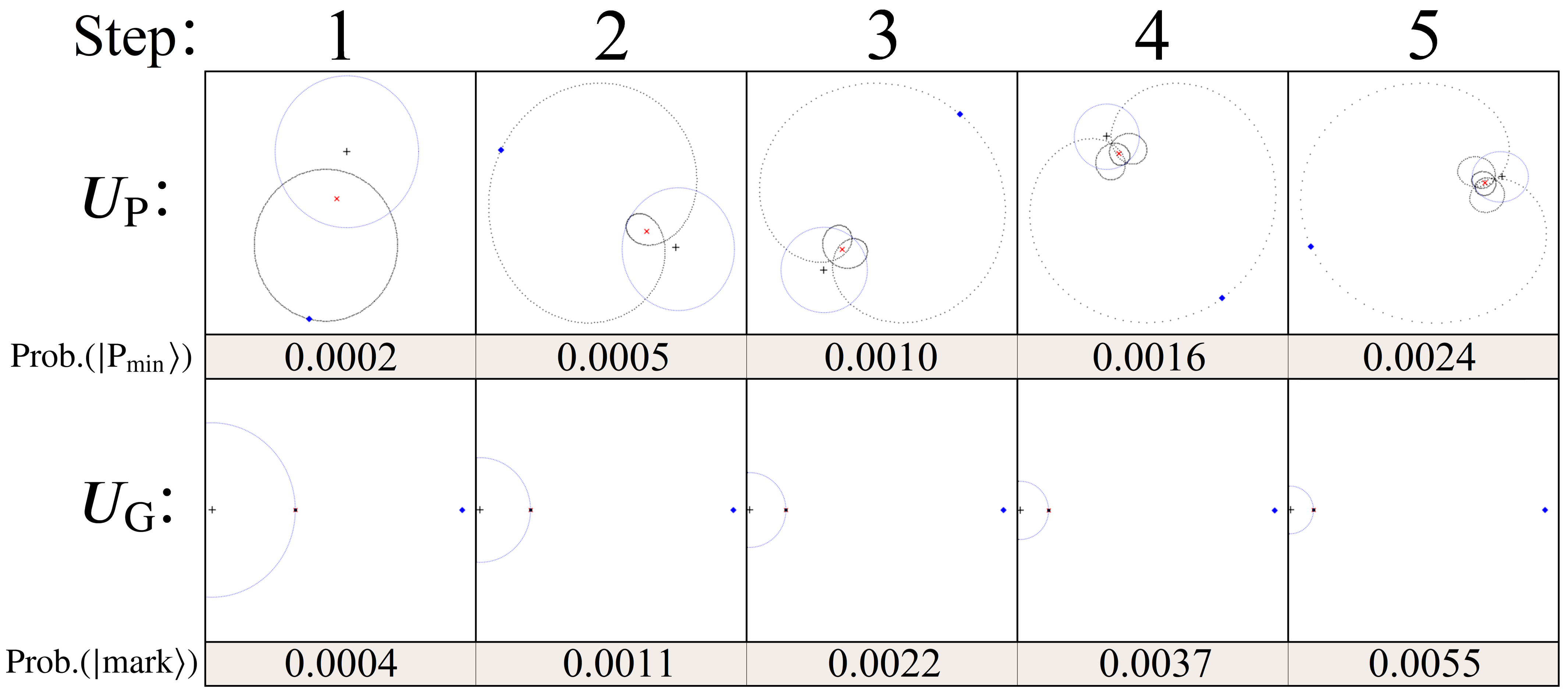
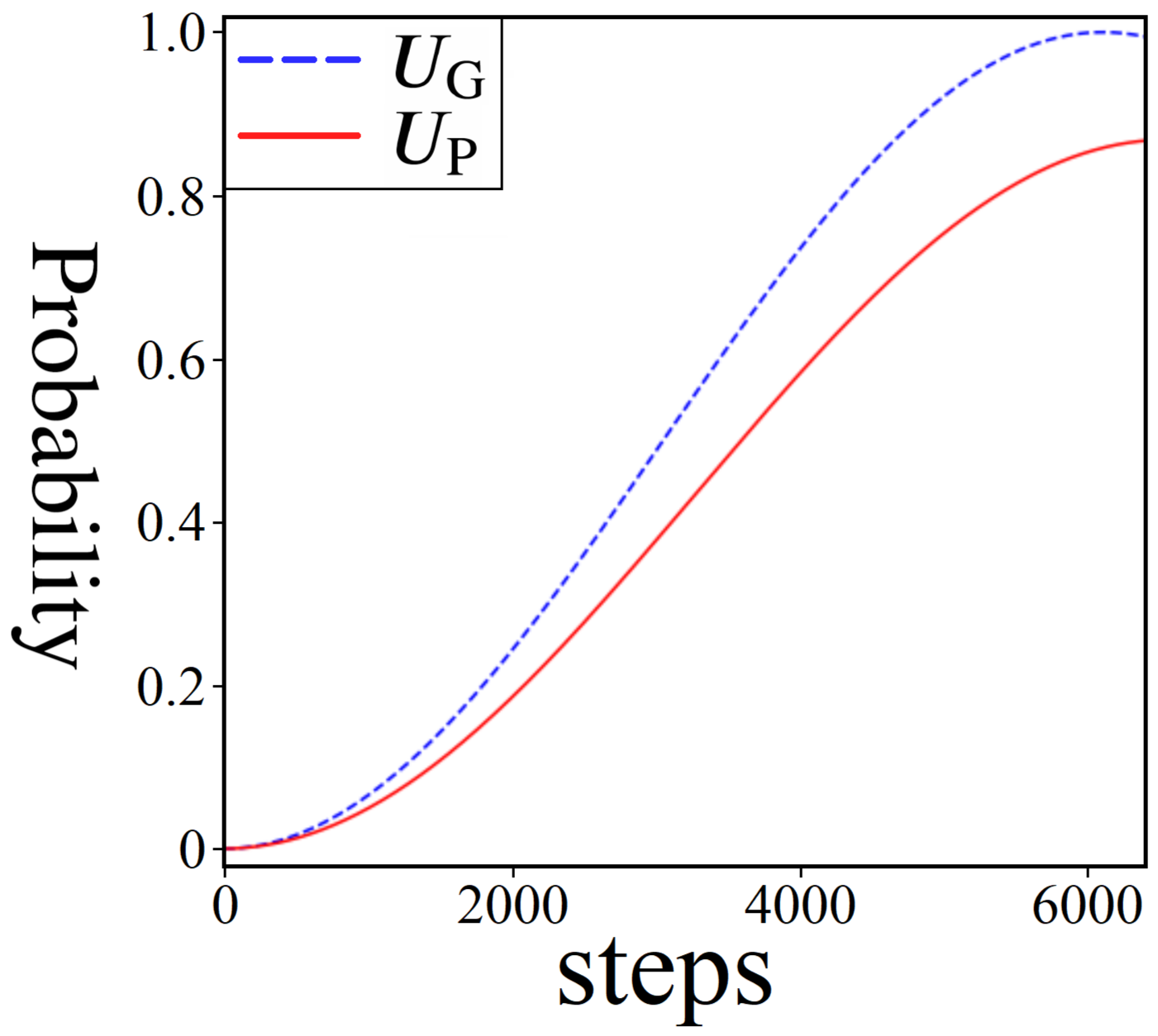
5.3. UG vs. UP Diffusion
| Algorithm 3 Quantum Pathfinding |
|
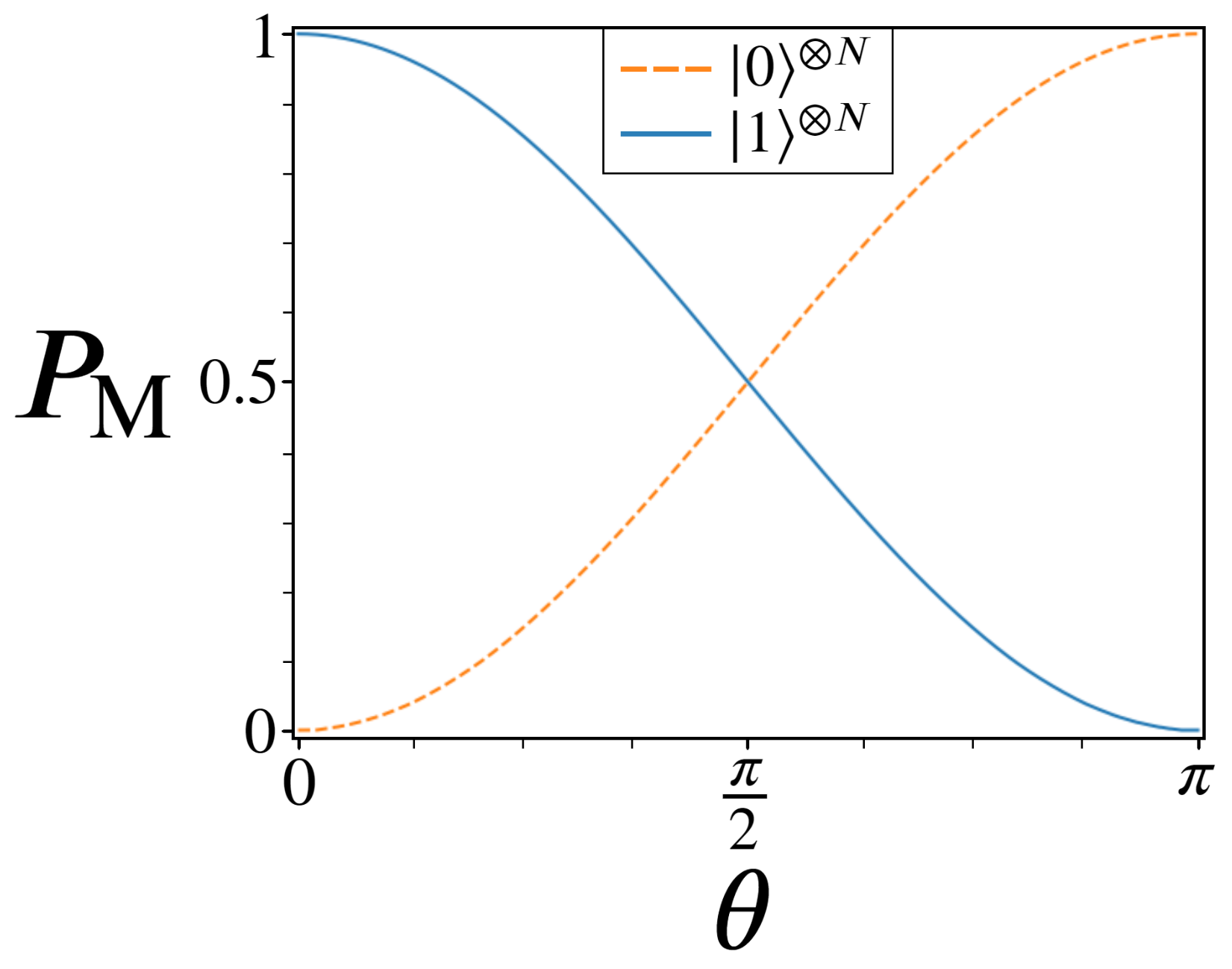
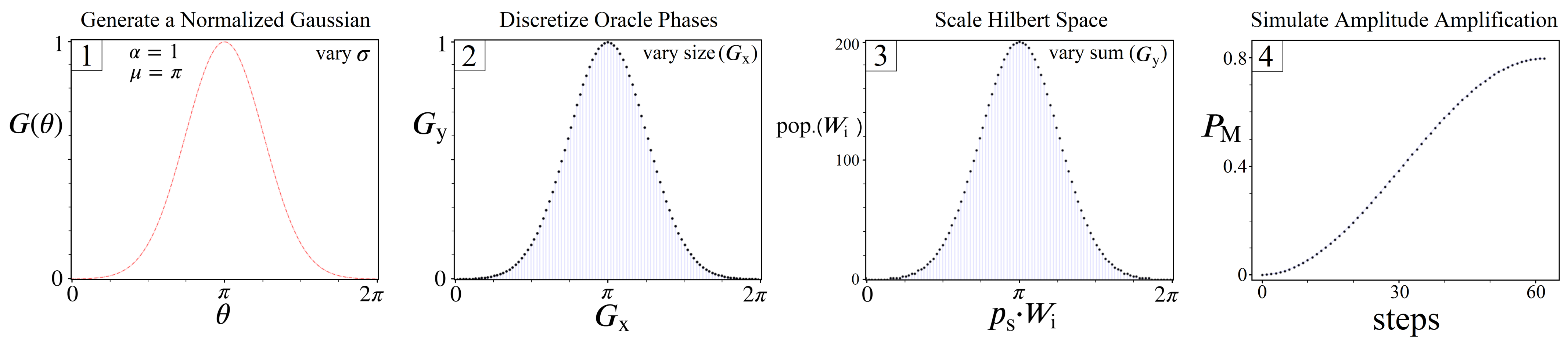
6. Simulating Gaussian Amplitude Amplification
6.1. Modeling Quantum Systems
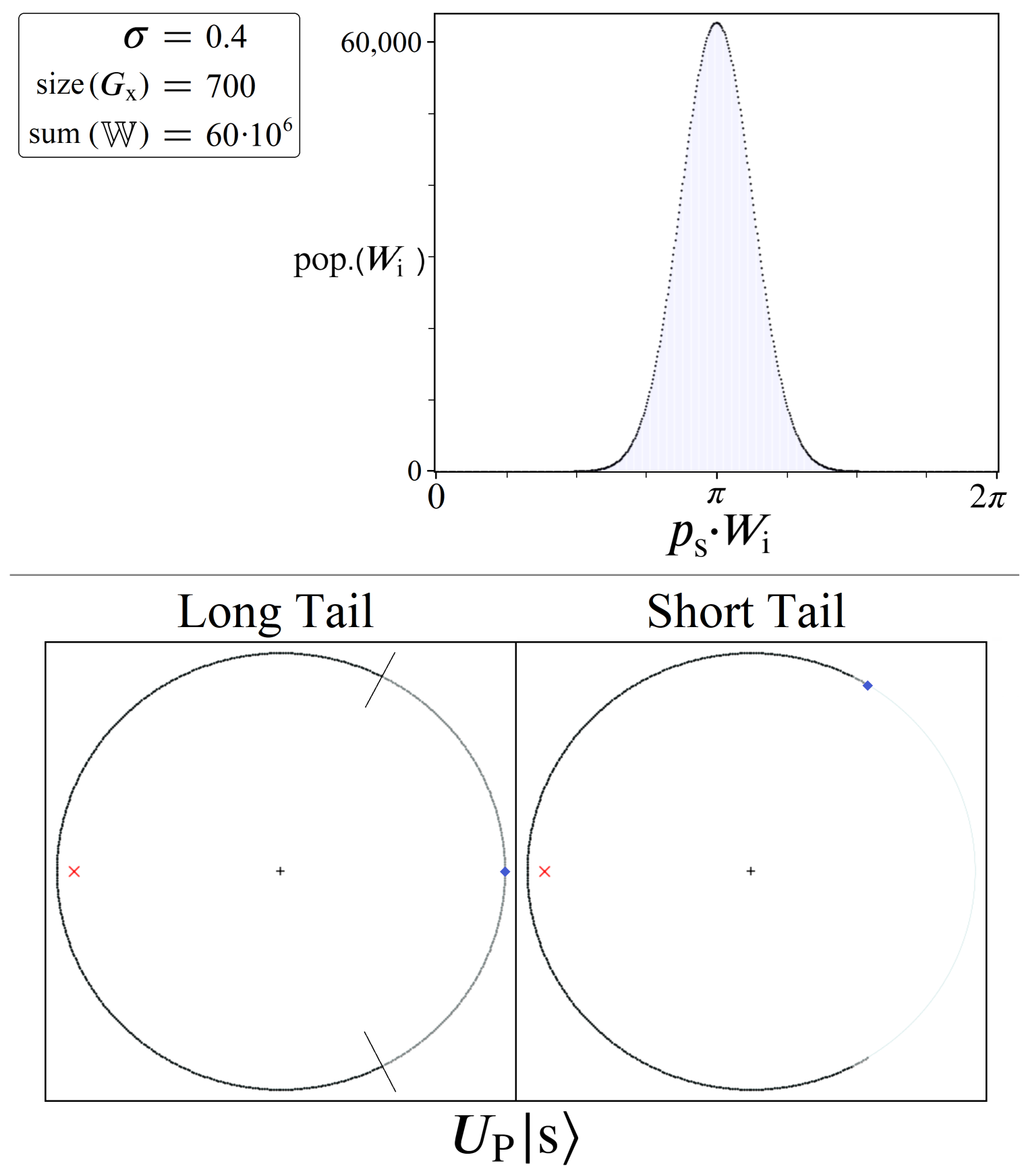
6.2. Long Tail Model
6.3. Short Tail Model
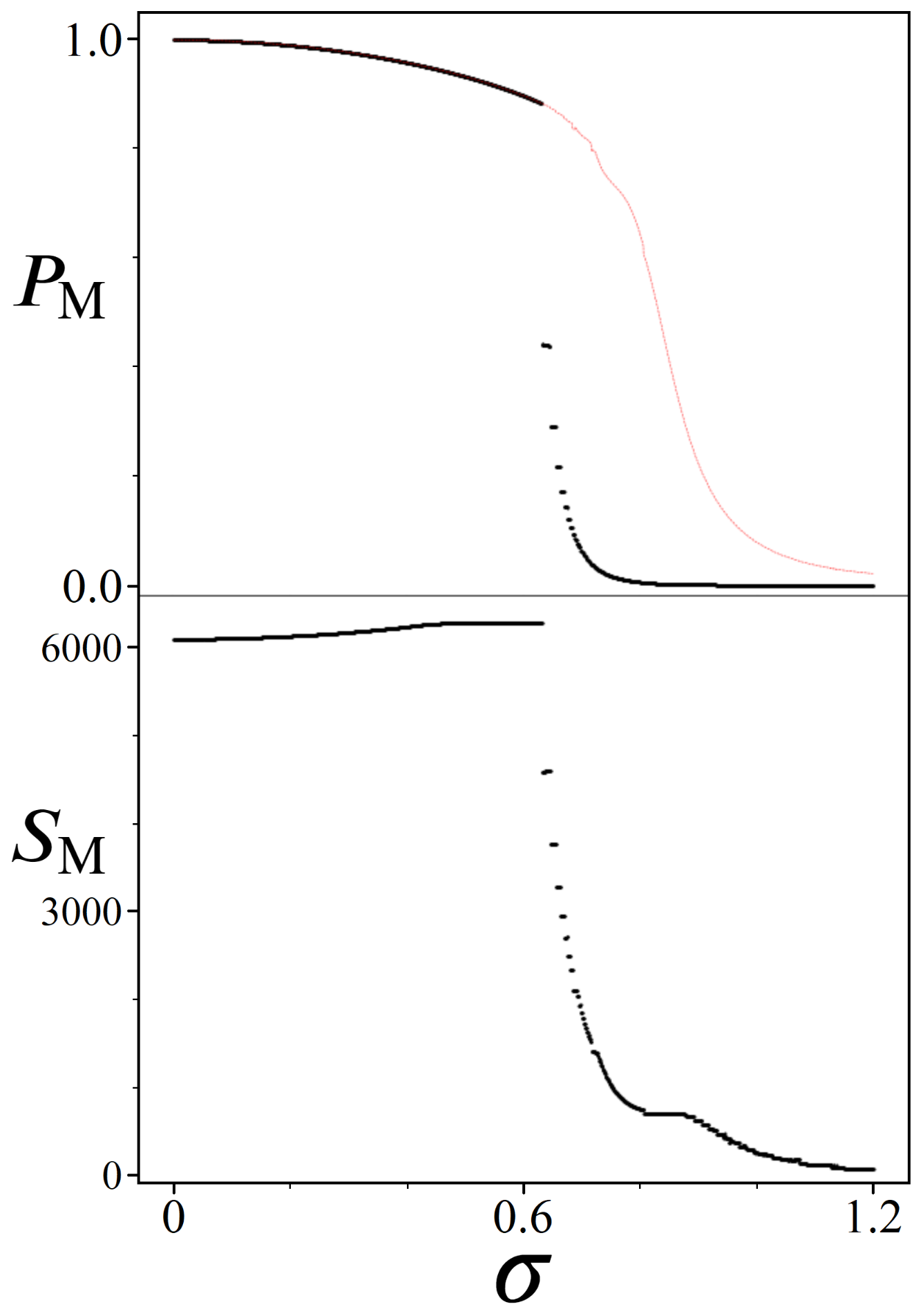
7. Algorithmic Viability
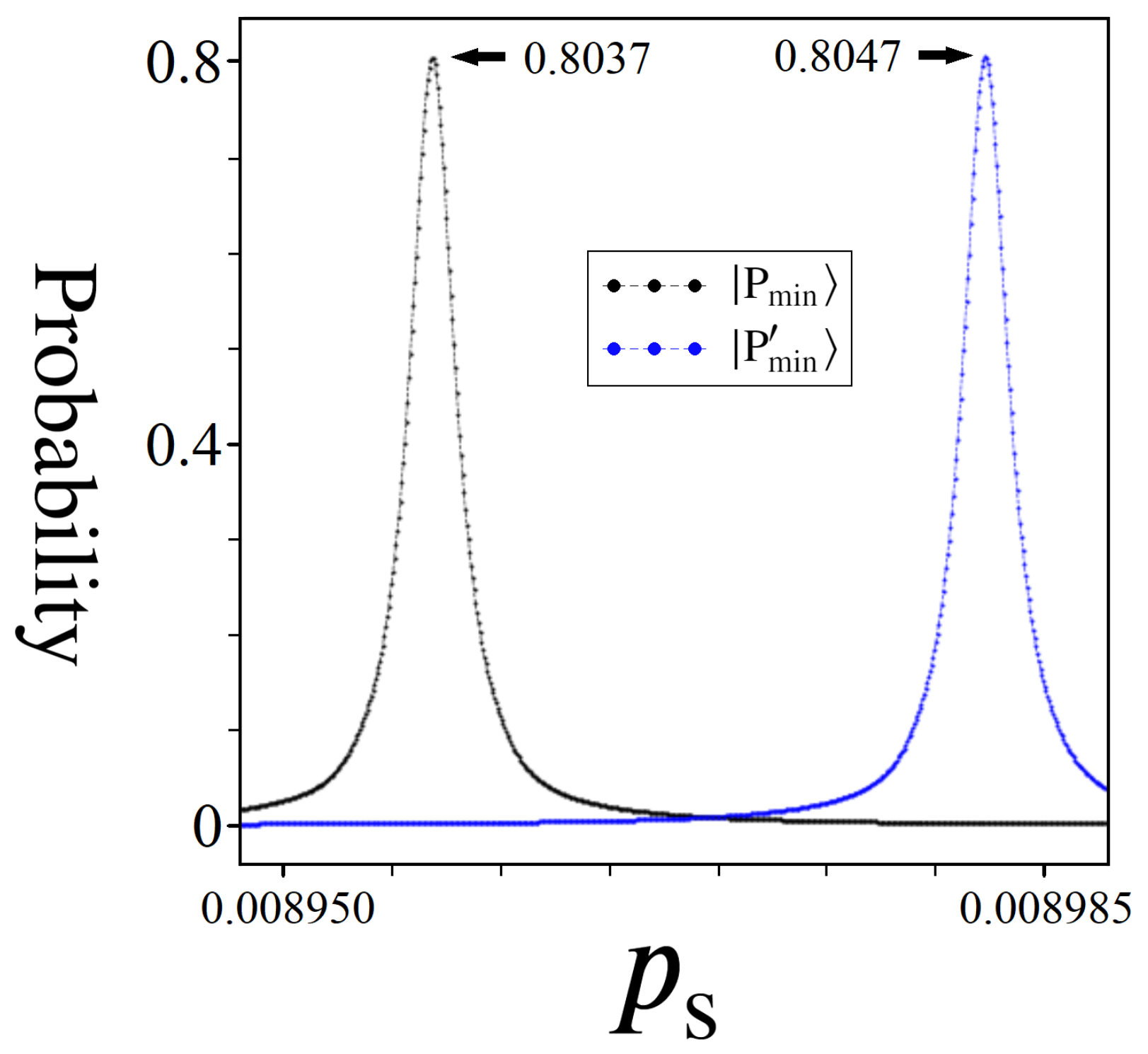
7.1. Finding an Optimal
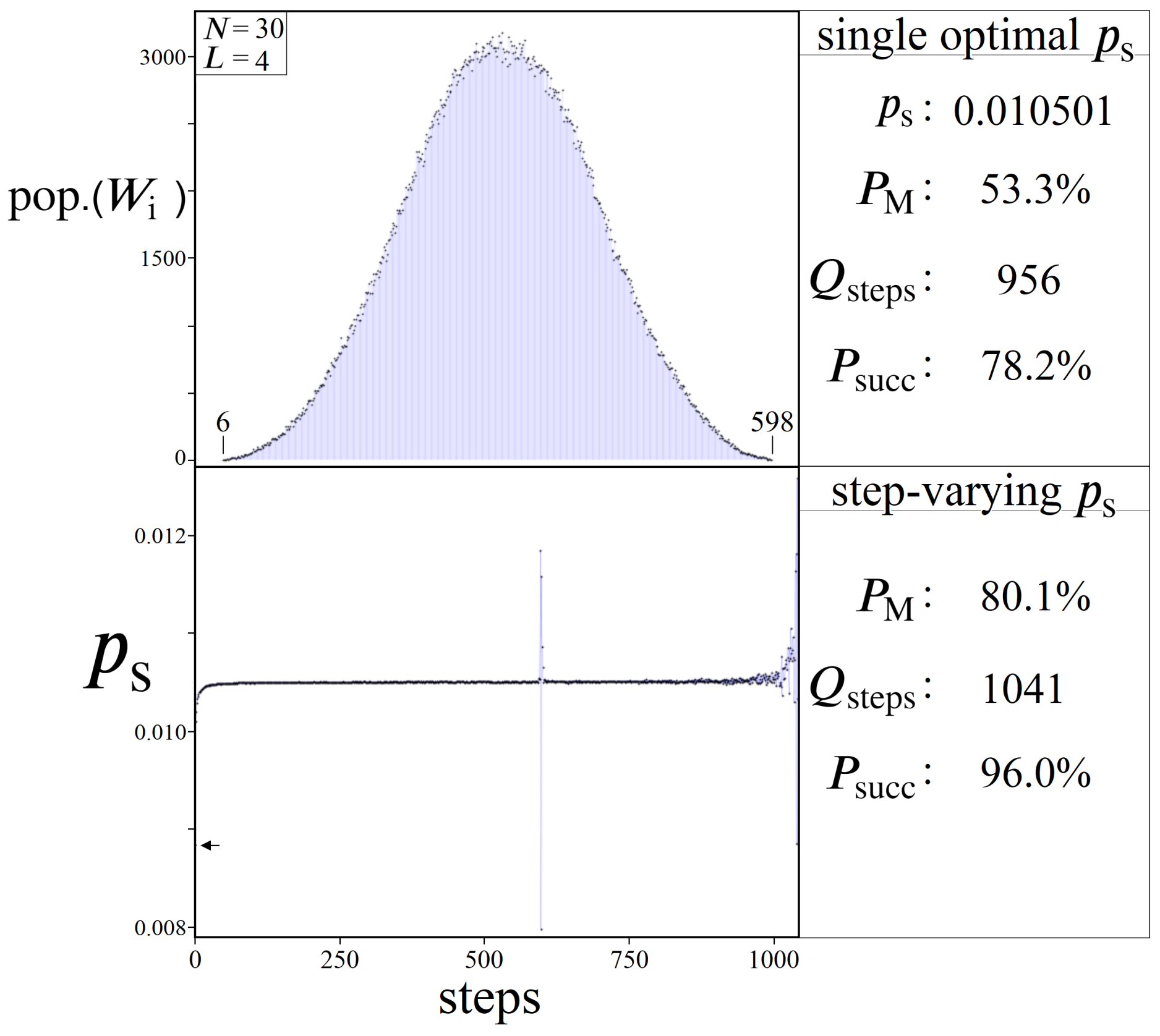
7.2. Single vs. Multiple ps
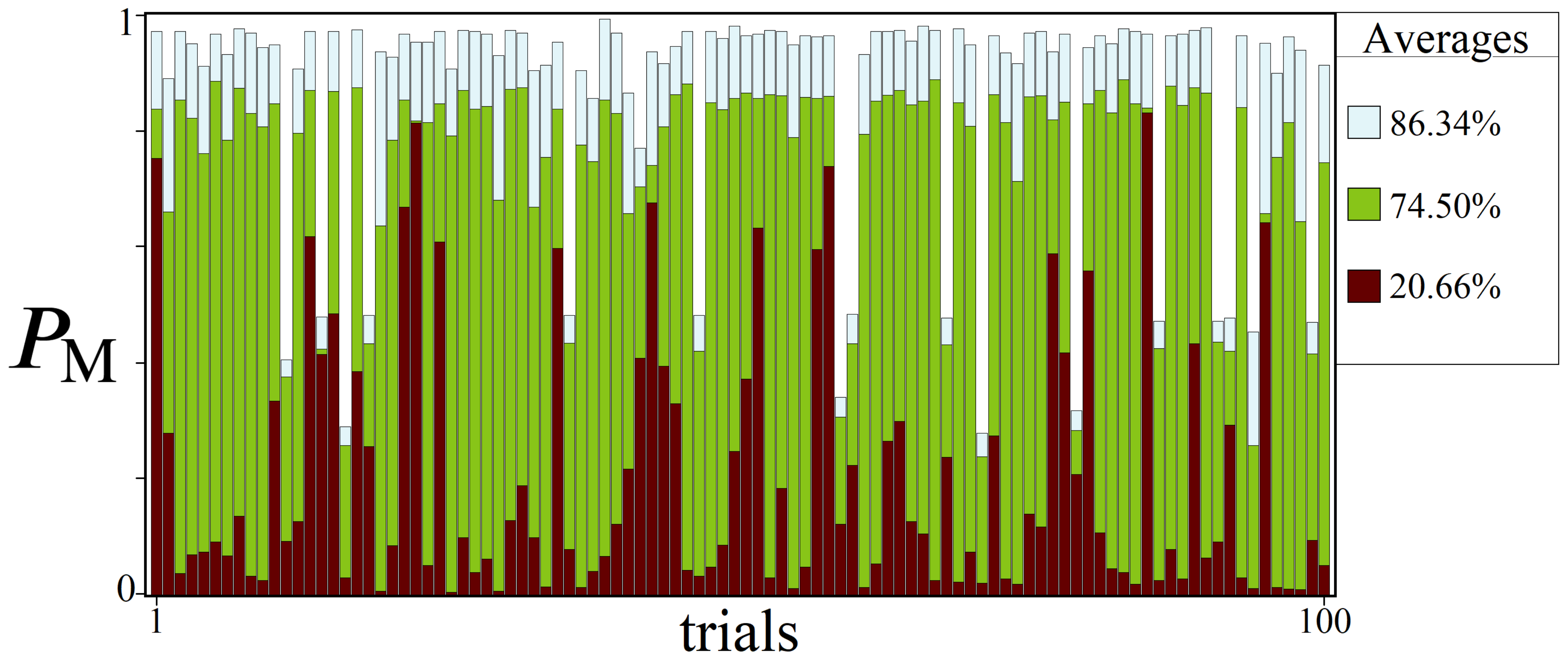
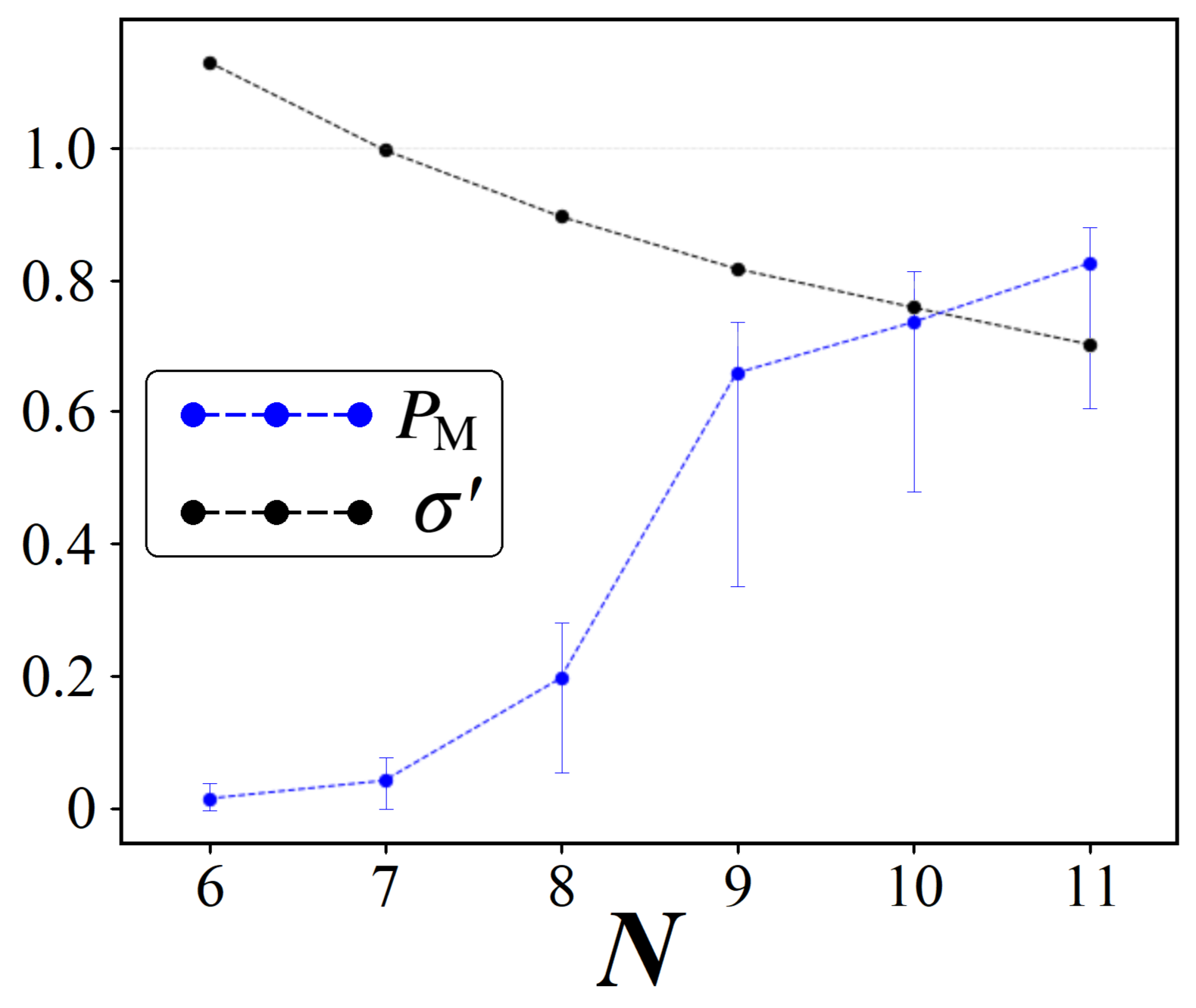
7.3. Statistical Viability
8. The Traveling Salesman
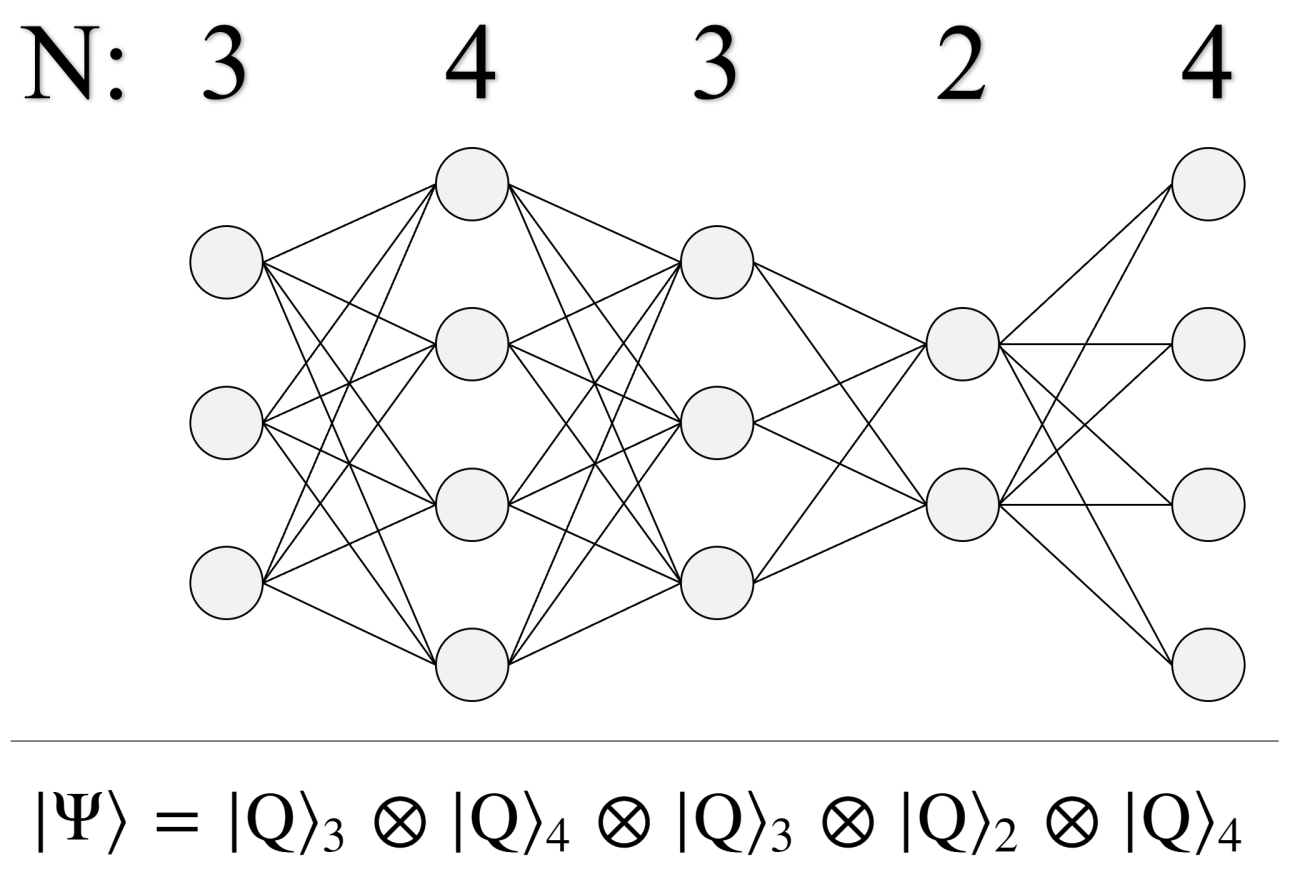
8.1. Weighted Graph Structure
8.2. Encoding Mixed Qudit States
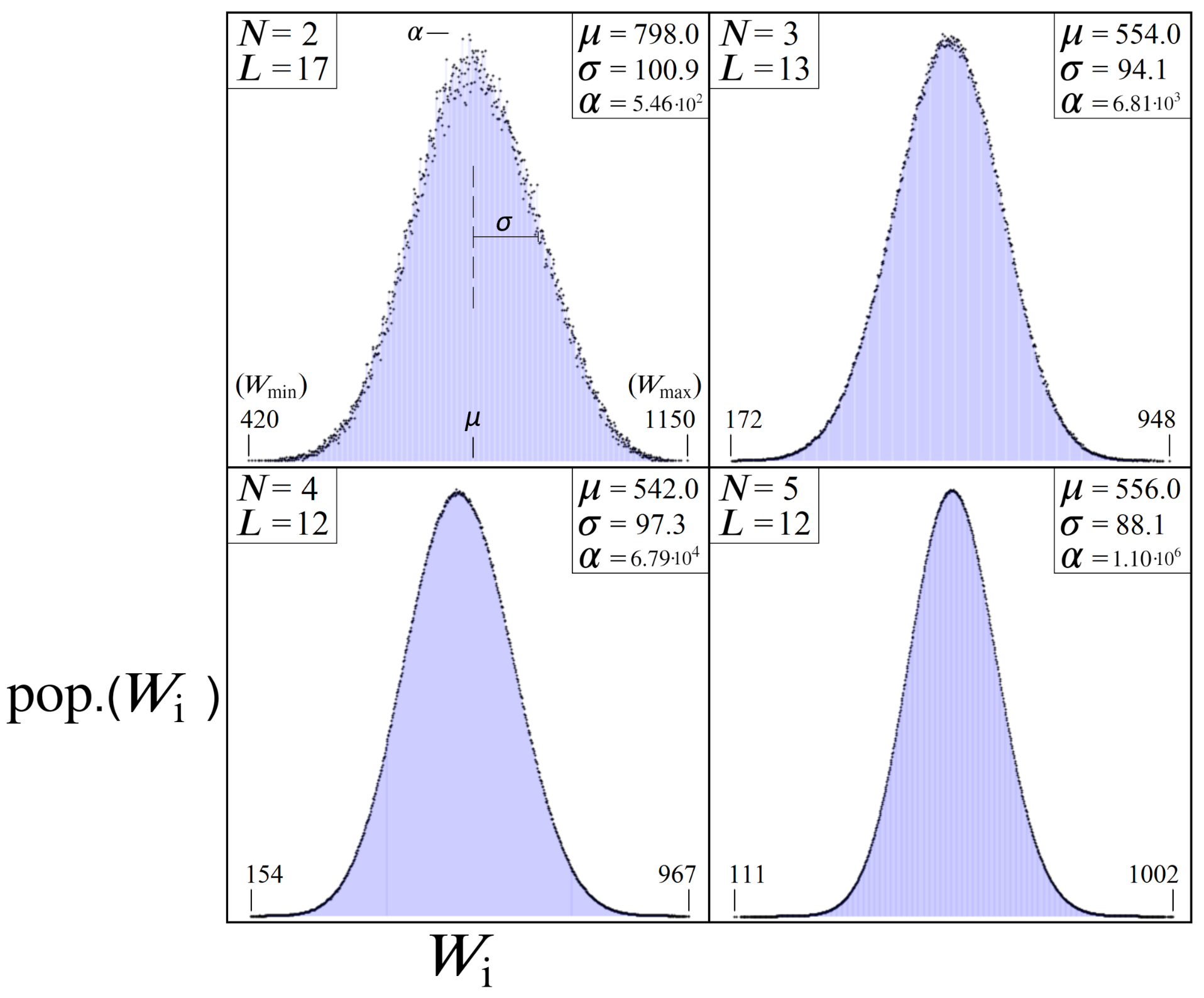
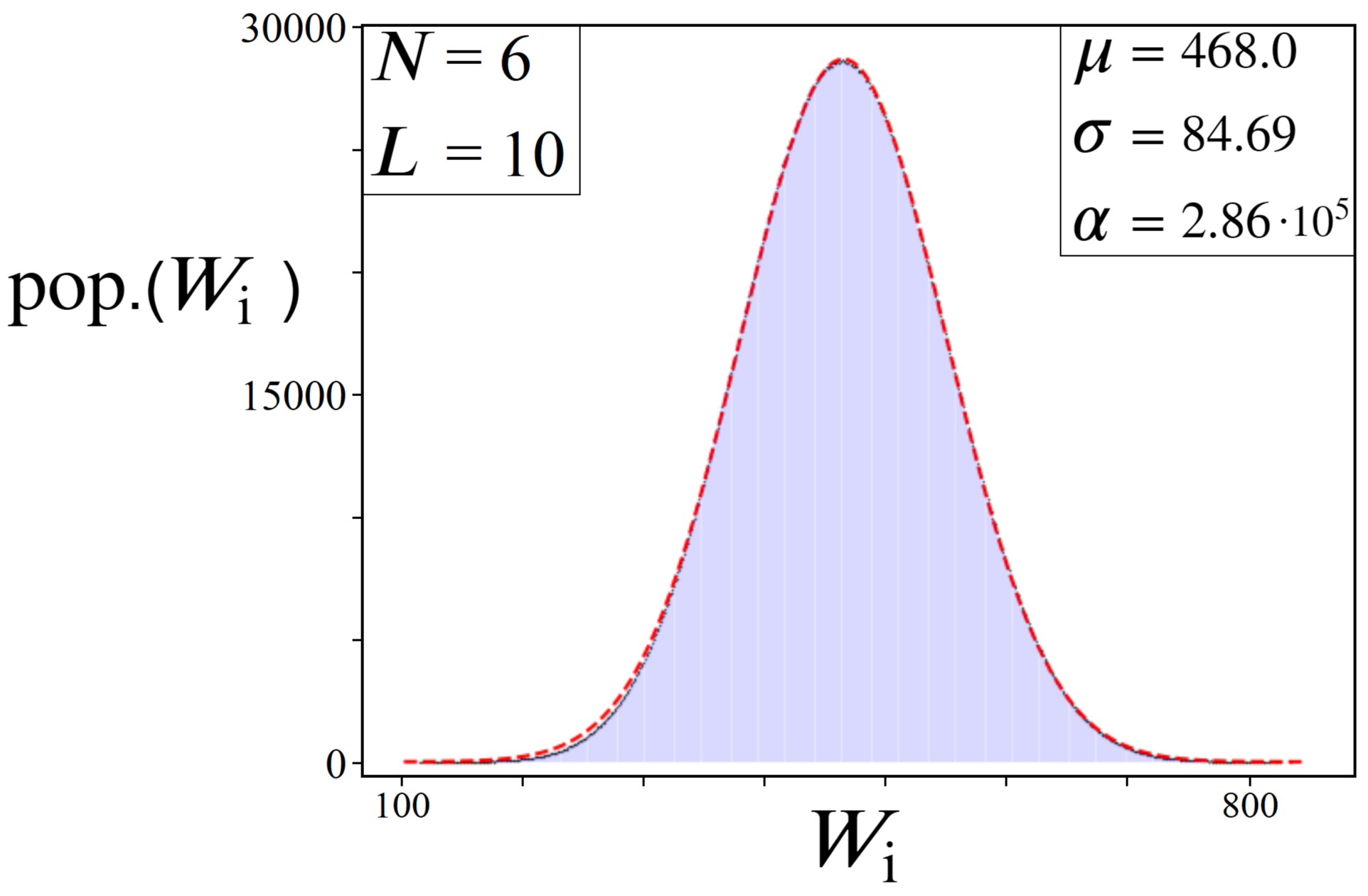
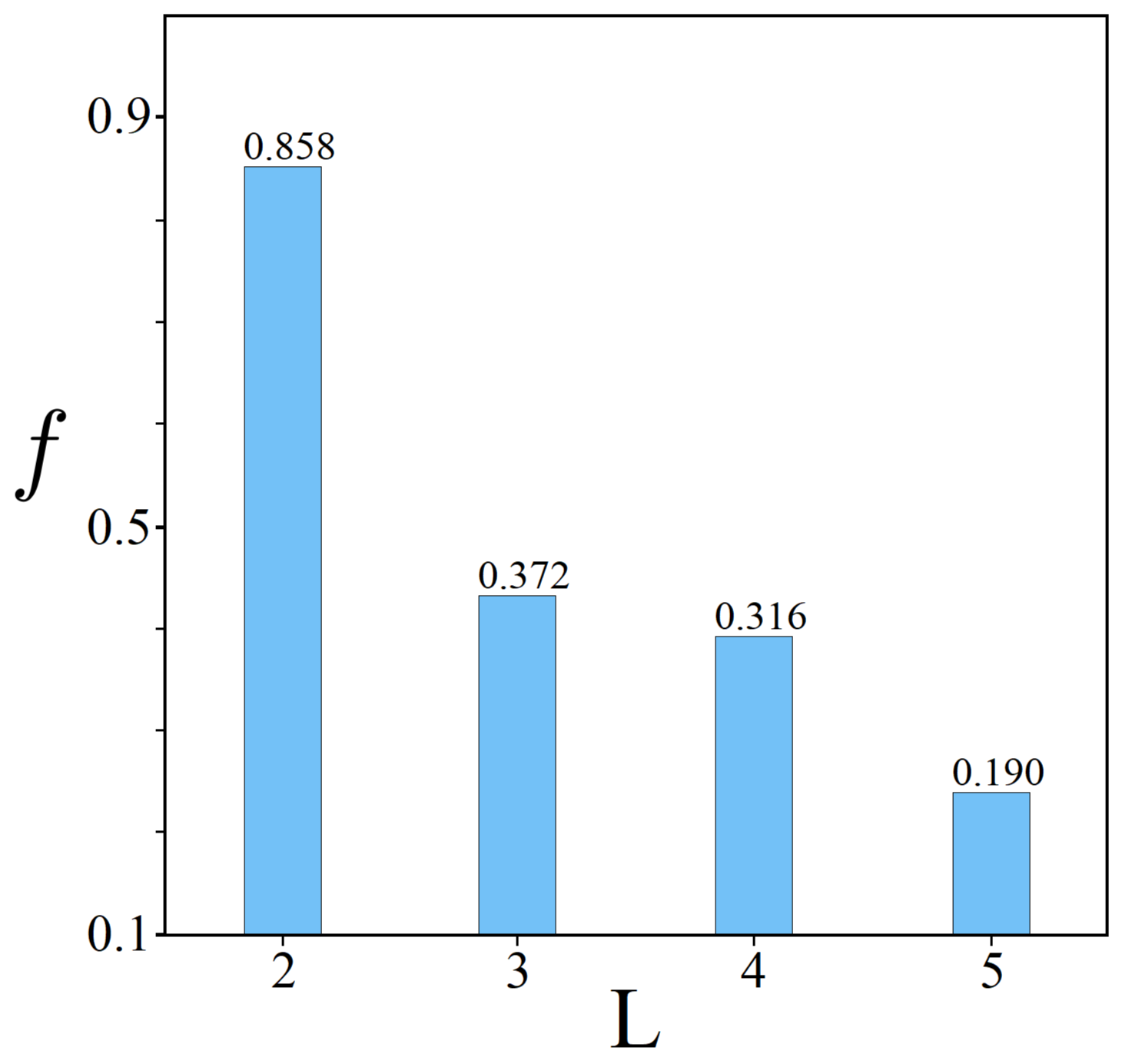
8.3. Simulated TSP Results
9. Conclusions
Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. UP Fidelity Results

Appendix B. Step-Varying ps

References
- Grover, L.K. A fast quantum mechanical algorithm for database search. arXiv 1996, arXiv:9605043. [Google Scholar]
- Boyer, M.; Brassard, G.; Hoyer, P.; Tapp, A. Tight bounds on quantum searching. Fortschr. Phys. 1998, 46, 493–506. [Google Scholar] [CrossRef] [Green Version]
- Bennett, C.H.; Bernstein, E.; Brassard, G.; Vazirani, U. Strengths and Weaknesses of Quantum Computing. Siam J. Comput. 1997, 26, 1510–1523. [Google Scholar] [CrossRef]
- Farhi, E.; Gutmann, S. Analog analogue of a digital quantum computation. Phys. Rev. A 1998, 57, 2403. [Google Scholar] [CrossRef] [Green Version]
- Brassard, G.; Hoyer, P.; Tapp, A. Quantum Counting. In Proceedings of the LNCS 1443: 25th International Colloquium on Automata, Languages, and Programming (ICALP), Aalborg, Denmark, 13–17 July 1998; pp. 820–831. [Google Scholar]
- Brassard, G.; Hoyer, P.; Mosca, M.; Tapp, A. Quantum Amplitude Amplification and Estimation. Ams Contemp. Math. 2002, 305, 53–74. [Google Scholar]
- Childs, A.M.; Goldstone, J. Spatial search by quantum walk. Phys. Rev. A 2004, 70, 022314. [Google Scholar] [CrossRef] [Green Version]
- Ambainis, A. Variable time amplitude amplification and a faster quantum algorithm for solving systems of linear equations. arXiv 2010, arXiv:1010.4458. [Google Scholar]
- Singleton, R.L., Jr.; Rogers, M.L.; Ostby, D.L. Grover’s Algorithm with Diffusion and Amplitude Steering. arXiv 2021, arXiv:2110.11163. [Google Scholar]
- Kwon, H.; Bae, J. Quantum amplitude-amplification operators. Phys. Rev. A 2021, 104, 062438. [Google Scholar] [CrossRef]
- Lloyd, S. Quantum search without entanglement. Phys. Rev. A 1999, 61, 010301. [Google Scholar] [CrossRef] [Green Version]
- Viamontes, G.F.; Markov, I.L.; Hayes, J.P. Is Quantum Search Practical? arXiv 2004, arXiv:0405001. [Google Scholar] [CrossRef]
- Regev, O.; Schiff, L. Impossibility of a Quantum Speed-up with a Faulty Oracle. arXiv 2012, arXiv:1202.1027. [Google Scholar]
- Seidel, R.; Becker, C.K.-U.; Bock, S.; Tcholtchev, N.; Gheorge-Pop, I.-D.; Hauswirth, M. Automatic Generation of Grover Quantum Oracles for Arbitrary Data Structures. arXiv 2021, arXiv:2110.07545. [Google Scholar]
- Nielsen, M.A.; Chuang, I.L. Quantum Computation and Quantum Information; Cambridge University Press: Cambridge, UK, 2000; p. 249. [Google Scholar]
- Long, G.L.; Zhang, W.L.; Li, Y.S.; Niu, L. Arbitrary Phase Rotation of the Marked State Cannot Be Used for Grover’s Quantum Search Algorithm. Commun. Theor. Phys. 1999, 32, 335. [Google Scholar]
- Long, G.L.; Li, Y.S.; Zhang, W.L.; Niu, L. Phase matching in quantum searching. Phys. Lett. A 1999, 262, 27–34. [Google Scholar] [CrossRef] [Green Version]
- Hoyer, P. Arbitrary phases in quantum amplitude amplification. Phys. Rev. A 2000, 62, 052304. [Google Scholar] [CrossRef] [Green Version]
- Younes, A. Towards More Reliable Fixed Phase Quantum Search Algorithm. Appl. Math. Inf. Sci. 2013, 1, 10. [Google Scholar] [CrossRef]
- Li, T.; Bao, W.-S.; Lin, W.-Q.; Zhang, H.; Fu, X.-Q. Quantum Search Algorithm Based on Multi-Phase. Chinese Phys. Lett. 2014, 31, 050301. [Google Scholar] [CrossRef]
- Guo, Y.; Shi, W.; Wang, Y.; Hu, J. Q-Learning-Based Adjustable Fixed-Phase Quantum Grover Search Algorithm. J. Phys. Soc. Jpn. 2017, 86, 024006. [Google Scholar] [CrossRef]
- Song, P.H.; Kim, I. Computational leakage: Grover’s algorithm with imperfections. Eur. Phys. J. D 2003, 23, 299–303. [Google Scholar] [CrossRef]
- Pomeransky, A.A.; Zhirov, O.V.; Shepelyansky, D.L. Phase diagram for the Grover algorithm with static imperfections. Eur. Phys. J. D-At. Mol. Opt. Plasma Phys. 2004, 31, 131–135. [Google Scholar] [CrossRef] [Green Version]
- Janmark, J.; Meyer, D.A.; Wong, T.G. Global Symmetry is Unnecessary for Fast Quantum Search. Phys. Rev. Lett. 2014, 112, 210502. [Google Scholar] [CrossRef]
- Gutin, G.; Punnen, A.P. The Traveling Salesman Problem and Its Variations; Springer: New York, NY, USA, 2007. [Google Scholar]
- Srinivasan, K.; Satyajit, S.; Behera, B.K.; Panigrahi, P.K. Efficient quantum algorithm for solving travelling salesman problem: An IBM quantum experience. arXiv 2018, arXiv:1805.10928. [Google Scholar]
- Moylett, D.J.; Linden, N.; Montanaro, A. Quantum speedup of the traveling-salesman problem for bounded-degree graphs. Phys. Rev. A 2017, 95, 032323. [Google Scholar] [CrossRef] [Green Version]
- Martoňák, R.; Santoro, G.E.; Tosatti, E. Quantum annealing of the traveling-salesman problem. Phys. Rev. E 2004, 70, 057701. [Google Scholar] [CrossRef] [Green Version]
- Warren, R.H. Adapting the traveling salesman problem to an adiabatic quantum computer. Quantum Inf. Process. 2013, 12, 1781–1785. [Google Scholar] [CrossRef]
- Warren, R.H. Solving the traveling salesman problem on a quantum annealer. SN Appl. Sci. 2020, 2, 75. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.; Kong, X.; Chong, B.; Qin, G.; Zhou, X.; Peng, X.; Du, J. Experimental demonstration of a quantum annealing algorithm for the traveling salesman problem in a nuclear-magnetic-resonance quantum simulator. Phys. Rev. A 2011, 83, 032314. [Google Scholar] [CrossRef]
- Bang, J.; Yoo, S.; Lim, J.; Ryu, J.; Lee, C.; Lee, J. Quantum heuristic algorithm for traveling salesman problem. J. Korean Phys. Soc. 2012, 61, 1944. [Google Scholar] [CrossRef] [Green Version]
- Kues, M.; Reimer, C.; Roztocki, P.; Cortés, L.R.; Sciara, S.; Wetzel, B.; Zhang, Y.; Cino, A.; Chu, S.T.; Little, B.E.; et al. On-chip generation of high-dimensional entangled quantum states and their coherent control. Nature 2017, 546, 622–626. [Google Scholar] [CrossRef]
- Low, P.J.; White, B.M.; Cox, A.A.; Day, M.L.; Senko, C. Practical trapped-ion protocols for universal qudit-based quantum computing. Phys. Rev. Res. 2020, 2, 033128. [Google Scholar] [CrossRef]
- Yurtalan, M.A.; Shi, J.; Kononenko, M.; Lupascu, A.; Ashhab, S. Implementation of a Walsh-Hadamard gate in a superconducting qutrit. Phys. Rev. Lett. 2020, 125, 180504. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.-H.; Hu, Z.; Alshaykh, M.S.; Moore, A.J.; Wang, Y.; Imany, P.; Weiner, A.M.; Kais, S. Quantum Phase Estimation with Time-Frequency Qudits in a Single Photon. Adv. Quantum Technol. 2019, 3, 1900074. [Google Scholar] [CrossRef] [Green Version]
- Niu, M.Y.; Chuang, I.L.; Shapiro, J.H. Qudit-Basis Universal Quantum Computation Using χ2 Interactions. Phys. Rev. Lett. 2018, 120, 160502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, M.-X.; Wang, X.-J. Universal quantum computation with qudits. Sci. China Phys. Mech. Astron. 2014, 57, 1712–1717. [Google Scholar] [CrossRef]
- Li, B.; Yu, Z.-H.; Fei, S.-M. Geometry of Quantum Computation with Qutrits. Sci. Rep. 2013, 3, 2594. [Google Scholar] [CrossRef] [Green Version]
- Lanyon, B.P.; Barbieri, M.; Almeida, M.P.; Jennewein, T.; Ralph, T.C.; Resch, K.J.; Pryde, G.J.; O’Brien, J.L.; Gilchrist, A.; White, A.G. Quantum computing using shortcuts through higher dimensions. Nat. Phys. 2009, 5, 134–140. [Google Scholar] [CrossRef] [Green Version]
- Gokhale, P.; Baker, J.M.; Duckering, C.; Brown, N.C.; Brown, K.R.; Chong, F.T. Asymptotic improvements to quantum circuits via qutrits. In Proceedings of the ISCA ‘19: 46th International Symposium on Computer Architecture, Phoenix, AZ, USA, 22–26 June 2019; pp. 554–566. [Google Scholar]
- Khan, F.S.; Perkowski, M. Synthesis of multi-qudit Hybrid and d-valued Quantum Logic Circuits by Decomposition. Theor. Comput. Sci. 2006, 367, 336–346. [Google Scholar] [CrossRef] [Green Version]
- Muthukrishnan, A.; Stroud, C.R., Jr. Multi-valued Logic Gates for Quantum Computation. Phys. Rev. A 2000, 62, 052309. [Google Scholar] [CrossRef] [Green Version]
- Daboul, J.; Wang, X.; Sanders, B.C. Quantum gates on hybrid qudits. J. Phys. A Math. Gen. 2003, 36, 2525–2536. [Google Scholar] [CrossRef]
- Blok, M.S.; Ramasesh, V.V.; Schuster, T.; O’Brien, K.; Kreikebaum, J.M.; Dahlen, D.; Morvan, A.; Yoshida, B.; Yao, N.Y.; Siddiqi, I. Quantum Information Scrambling on a Superconducting Qutrit Processor. Phys. Rev. X 2021, 11, 021010. [Google Scholar] [CrossRef]
- Hu, X.-M.; Zhang, C.; Liu, B.-H.; Cai, Y.; Ye, X.-J.; Guo, Y.; Xing, W.-B.; Huang, C.-X.; Huang, Y.-F.; Li, C.-F.; et al. Experimental High-Dimensional Quantum Teleportation. Phys. Rev. Lett. 2020, 125, 230501. [Google Scholar] [CrossRef]
- Laplace, P.S. Mémoire sur les approximations des formules qui sont fonctions de très grands nombres et sur leur application aux probabilités. In Mémoires de l’Académie Royale des Sciences de Paris; Baudouin: Brussels, Belgium, 1810; Volume 10. [Google Scholar]
- Bernoulli, J. Ars Conjectandi; Thurnisiorum: Basileae, Switzerland, 1713. [Google Scholar]
- Gauss, C.F. Theoria Motus Corporum Coelestium in Sectionibus Conicis Solem Ambientium; Friedrich Perthes: Hamburg, Geramey; I.H. Besser: Hamburg, Geramey, 1809. [Google Scholar]
- Satoh, T.; Ohkura, Y.; Meter, R.V. Subdivided Phase Oracle for NISQ Search Algorithms. IEEE Trans. Quantum Eng. 2020, 1, 1–15. [Google Scholar] [CrossRef]
- Benchasattabuse, N.; Satoh, T.; Hajdušek, M.; Meter, R.V. Amplitude Amplification for Optimization via Subdivided Phase Oracle. arXiv 2022, arXiv:2205.00602. [Google Scholar]
- Shyamsundar, P. Non-Boolean Quantum Amplitude Amplification and Quantum Mean Estimation. arXiv 2021, arXiv:2102.04975. [Google Scholar]
- Koch, D.; Wessing, L.; Alsing, P.M. Introduction to Coding Quantum Algorithms: A Tutorial Series Using Qiskit. arXiv 2019, arXiv:1903.04359. [Google Scholar]
- Wang, Y.; Hu, Z.; Sanders, B.C.; Kais, S. Qudits and High-Dimensional Quantum Computing. Front. Phys. 2020, 10, 589504. [Google Scholar] [CrossRef]
- Farhi, E.; Goldstone, J.; Gutmann, S. A Quantum Approximate Optimization Algorithm. arXiv 2014, arXiv:1411.4028. [Google Scholar]
- Hadfield, S.; Wang, Z.; O’Gorman, B.; Rieffel, E.G.; Venturelli, D.; Biswas, R. From the Quantum Approximate Optimization Algorithm to a Quantum Alternating Operator Ansatz. Algorithms 2019, 12, 34. [Google Scholar] [CrossRef] [Green Version]
- Peruzzo, A.; McClean, J.; Shadbolt, P.; Yung, M.-H.; Zhou, Z.-Q.; Love, P.J.; Aspuru-Guzik, A.; O’Brien, J.L. A variational eigenvalue solver on a quantum processor. Nat. Commun. 2014, 5, 4213. [Google Scholar] [CrossRef] [Green Version]
- IBM 7-Qubit Casablanca and Lagos Architectures. Available online: https://quantum-computing.ibm.com (accessed on 10 April 2021).





























Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koch, D.; Cutugno, M.; Karlson, S.; Patel, S.; Wessing, L.; Alsing, P.M. Gaussian Amplitude Amplification for Quantum Pathfinding. Entropy 2022, 24, 963. https://doi.org/10.3390/e24070963
Koch D, Cutugno M, Karlson S, Patel S, Wessing L, Alsing PM. Gaussian Amplitude Amplification for Quantum Pathfinding. Entropy. 2022; 24(7):963. https://doi.org/10.3390/e24070963
Chicago/Turabian StyleKoch, Daniel, Massimiliano Cutugno, Samuel Karlson, Saahil Patel, Laura Wessing, and Paul M. Alsing. 2022. "Gaussian Amplitude Amplification for Quantum Pathfinding" Entropy 24, no. 7: 963. https://doi.org/10.3390/e24070963