1. Introduction
With the rapid development of the Industrial Internet of Things, the explosive growth of monitoring data brings new opportunities and challenges for predictions of the remaining useful life of rolling bearings. The data-driven remaining useful life prediction method can learn the degradation characteristics of rolling bearings from the massive monitoring data and build a corresponding remaining useful life prediction model. Therefore, it has received increasing attention in research surrounding remaining useful life prediction [
1].
Data-driven methods for remaining useful life prediction based on data typically involve three steps, including degradation feature construction, degradation trend learning, and remaining useful life estimation [
2]. In the task of rolling bearing remaining useful life prediction, the trend of rolling bearing remaining useful life degradation over time needs to be better evaluated. Therefore, increasingly time-sensitive features need to be extracted. Degradation feature construction uses a priori knowledge of rolling bearing performance to extract sensitive degradation features from the monitoring data obtained. At the current stage, rolling bearing vibration signal feature-extraction methods mainly remove the signal features reflecting time, and remove the frequency domain waveform characteristics from signals from the time and frequency domains. The methods also utilize other basic processes, such as root mean square and kurtosis. Although these signal features can reflect the fault information in a bearing signal [
3], they still have a problem: insensitivity to the trend of decline of rolling bearings over time. The resonance sparse decomposition method is a signal processing method proposed by Selesnick [
4] in 2011. The periodic vibration components generated by the regular bearing operation, and the periodic shock component developed by the bearing failure, can correspond well to high-resonance and low-resonance components generated under the decomposition of bearing vibration signals by the resonance sparse decomposition algorithm. Compared with the signal enhancement method, based on the vibration signal spectrum, the resonance sparse decomposition algorithm can directly extract low-resonance components. These contain more fault information from the vibration signal, avoid the limitation of spectrum analysis, and are more suitable for processing nonlinear signals. Permutation entropy is a method proposed by Bandt et al. [
5] to detect the randomness and kinetic mutation of time series, and it has good anti-transformation properties for mutated, non-smooth signals. Mengjie Liu et al. [
6] demonstrated that permutation entropy has an excellent ability to characterize different faults occurring in rolling bearings by comparing the performance of permutation entropy, approximate entropy, and Lempel–Zi complexity in bearing fault diagnosis. However, permutation entropy can only evaluate the characteristic information of the signal from a rolling bearing vibration on a single time scale, which may cause the critical, distinct information to be insignificant. At this stage, the rolling bearing vibration signal is complex, and an evaluation only from a single time scale can no longer reflect its complete characteristic information. Ge et al. [
7] proposed multiscale permutation entropy combined with robust principal component analysis (RPCA), which can reflect deeper features of the signal by setting different scale factors [
8,
9]. The diagnosis of bearing faults can effectively detect and locate bearing faults. Ye et al. [
10] proposed a feature-extraction method, VMD-MPE. They demonstrated that MPE could represent the feature information of rolling bearings by comparing experiments with VMD-MSE, VMD-MFE, EMD-MPE, and WT-MPE. Du et al. [
11] used MPE to extract fault features and combined it with a self-organizing fuzzy classifier based on the harmonic mean difference (HMDSOF) to classify the fault feature. The results confirmed the superiority of MPE. Not all the feature information of the rolling bearing vibration signal is sensitive to the tendency of the remaining useful life to decline over time. When using multiscale arrangement entropy as an evaluation feature, the dimensionality of the multiscale permutation entropy value increases as the scale factor increases. There will inevitably be insensitive feature information in the multiscale arrangement entropy value, which affects the accuracy of the remaining useful life prediction of the subsequent rolling bearing. Therefore, the multiscale permutation entropy features extracted from the low-resonance component must be fused to remove the redundant insensitive feature information. To change this situation, new features must be designed to improve the accuracy of the remaining useful life prediction of rolling bearings.
Deep learning has made a qualitative leap in feature learning and fitting capabilities compared with machine learning algorithms in the context of big data. It can be relatively easy to update model parameters in a real time according to the object being tested. Thus, more accurate performance-degradation tracking can be achieved [
12]. Based on deep learning, algorithmic models which can predict remaining useful life, such as various neural networks and their extensions, can theoretically be fitted with two layers of neural networks to approximate arbitrary functions. Deep learning techniques such as deep belief networks (DBNs) [
13], recurrent neural networks (RNNs) [
14], and convolutional neural networks (CNNs) [
15] have more powerful representational learning capabilities. They have an ability to learn complex functions that map inputs to outputs directly from raw data without relying entirely on hand-crafted features. Babu et al. [
16] proposed a CNN-based method for the RUL prediction of turbofan engines and demonstrated its superiority by comparing it with traditional machine learning methods. Hinchi et al. [
17] used CNNs and long short term memory; in the study, CNNs were first used to extract local features from vibration signals, then LSTM networks were used for RUL prediction. Zhang et al. [
18] proposed a multiobjective DBN integration and used it to estimate the RUL of turbofan engines. Zhu et al. [
19] combined wavelet transforms and CNNs to predict the bearing RUL. Yang Yu et al. [
20] put forward a DCNN-based method to localize damages of smart building structures exposed to external harmful excitations. Ince et al. [
21] used one-dimensional CNNs for the real-time monitoring of motor faults. With complex and multisource-bearing signals, the convolutional neural network feature-extraction operation cannot fully exploit the feature information of a movement at a single time scale. The problem of information loss may occur in convolutional neural networks during pooling, and this problem will be further aggravated if the feature information extraction is incomplete. Therefore, feature information needs to be extracted at more scales, and should make full use of the multiscale feature information. Li et al. [
22] proposed a fault diagnosis method based on the MPE and the multichannel fusion convolutional neural network (MCFCNN). They verified that the technique has high diagnostic accuracy, stability, and speed. Zhang et al. [
23] proposed an early fault detection method for rolling bearings based on a multiscale convolutional neural network and a gated circular unit network (MCNN-AGRU), with an attention mechanism which uses a multiscale data-processing method to make the features extracted by CNN more robust. Hou et al. [
24] proposed a multiscale convolutional neural network bearing fault diagnosis method based on wavelet transform and a one-dimensional convolutional neural network. Lv D et al. [
25] proposed a rolling bearing fault diagnosis method based on a multiscale convolutional neural network (MCNN) and decision fusion. Zhuang et al. [
26] proposed a rolling bearing fault diagnosis model based on one-dimensional multiscale deep convolutional neural network. This can broaden and deepen the neural network, enabling it to learn better and have more robust feature representations, while reducing network parameters and the training time. Han et al. [
27] proposed a multiscale convolutional neural network (MSCNN) for rolling bearing fault feature extraction. They experimentally demonstrated that MSCNN could learn more robust features than traditional CNN through multiscale convolution operation expressions, reducing the number of parameters and the training time. When feature information is extracted in a convolutional neural network, it is generally fed into the fully connected layer for outputting the final result after simple splicing. This operation weakens the correlation between the features and results in less information for the model to learn. The attention mechanism [
28] was proposed by the Google team in 2017 to improve the learning ability of a model when the input sequence is too long. The attention mechanism can attach great importance to the essential features so that the model can focus more on the essential features and improve the model’s learning ability. The attention mechanism can also improve the correlation of multiscale features. The attention mechanism can also explore the correlation of multiscale features, enhance the expression ability of the fused features, and improve the accuracy of the prediction of the remaining useful life of rolling bearings.
In summary, feature extraction is a crucial step in predicting the remaining useful life of rolling bearings. Improving the ability of features to express the declining trend of the remaining useful life of rolling bearings over time is an effective way to improve prediction accuracy. Therefore, resonant sparse decomposition and multiscale permutation entropy methods are used to extract features that can accurately reflect the declining trend of the remaining useful life of rolling bearings. The remaining life prediction model is the main part of the prediction of the residual useful life of rolling bearings; learning the degradation characteristics at a single scale can no longer meet the needs of current rolling bearing residual life prediction demand. Therefore, a multiscale feature learning module was added to the convolutional neural network to enhance the feature learning ability of the model, and the attention mechanism was added to fuse the multiscale degradation feature information, retain the correlation between the degradation feature information in different time scales, and improve the model prediction accuracy.
Feature extraction is the key to predicting the remaining life of rolling bearings. Due to the weak features of early-failure signals, it is challenging to extract sensitive information which reflects the bearings’ decline in performance, which affects the evaluation of the health status of rolling bearings. This method can improve the sensitivity of features to the decline trend of remaining useful life and predict the remaining life of rolling bearings in advance, thus improving the prediction accuracy of the model. It provides an effective technical means for the predictive maintenance of machines.
The main contents are as follows:
Section 2 presents a multiscale fusion permutation entropy feature-extraction method;
Section 3 presents a MACNN remaining useful life prediction model;
Section 4 presents our experimental validation;
Section 5 presents our conclusions.
2. Multiscale Fusion Permutation Entropy Feature Extraction
The MFPE-based bearing vibration signal feature-extraction method constructs a high-dimensional, entropy-valued feature matrix by calculating the multiscale permutation entropy values of the low-resonance components of rolling bearings. It fully reflects the complexity and instability of the signals from multiple dimensions. The local linear embedding (LLE) algorithm further removes redundant information. The overall method makes up for the imperfect reflection of the characteristics extracted at a single scale on the local trend of rolling bearing life decline and can better improve the prediction accuracy of the remaining useful life of rolling bearings.
2.1. Resonance Sparse Decomposition Method
The resonance sparse decomposition method can analyze the resonance properties of a signal. The wavelet basis function library was constructed by an adjustable quality factor wavelet transform approach. The call was sparsely represented by the wavelet basis function library according to the morphological analysis method, and the quality factor, , was used as the evaluation method to separate the different components of the signal from each other. When the quality factor, , was more extensive, it indicated that the movement bandwidth was narrower, and the movement was in the form of high-resonance periodic vibration. When the quality factor, , was smaller, it indicated that the bandwidth of the movement was more expansive, and the movement was in the form of low-resonance transient shock.
The high-resonance element corresponded to the component of continuous oscillation in the movement, that is, the regular vibration movement generated when the bearing ran smoothly. The low-resonance component corresponded to the regular shock component in the movement, that is, the regular shock movement generated when the bearing had regular failures. The low-resonance component can adequately reflect the characteristic information in the movement caused by the fault.
The specific calculation steps of the resonance sparse decomposition algorithm are as follows.
- (1)
Assume that the input movement is . Set the resonant sparse decomposition parameters quality factor, and , redundancy factor, and , and decomposition level, and , according to the movement characteristics, and construct the wavelet basis function library, and .
- (2)
Select appropriate weighting coefficients,
and
, according to the signal-to-noise ratio index so that the different components in the signal can be separated effectively. Set the optimization target as shown in Equation (1).
where
and
are the matching coefficients of wavelet bases
and
.
- (3)
The best-matching coefficients and are obtained by solving the optimization problem of Equation (1), and the high-resonance component and the low-resonance component are obtained by combining the best-matching coefficients and with the wavelet basis function library for calculation.
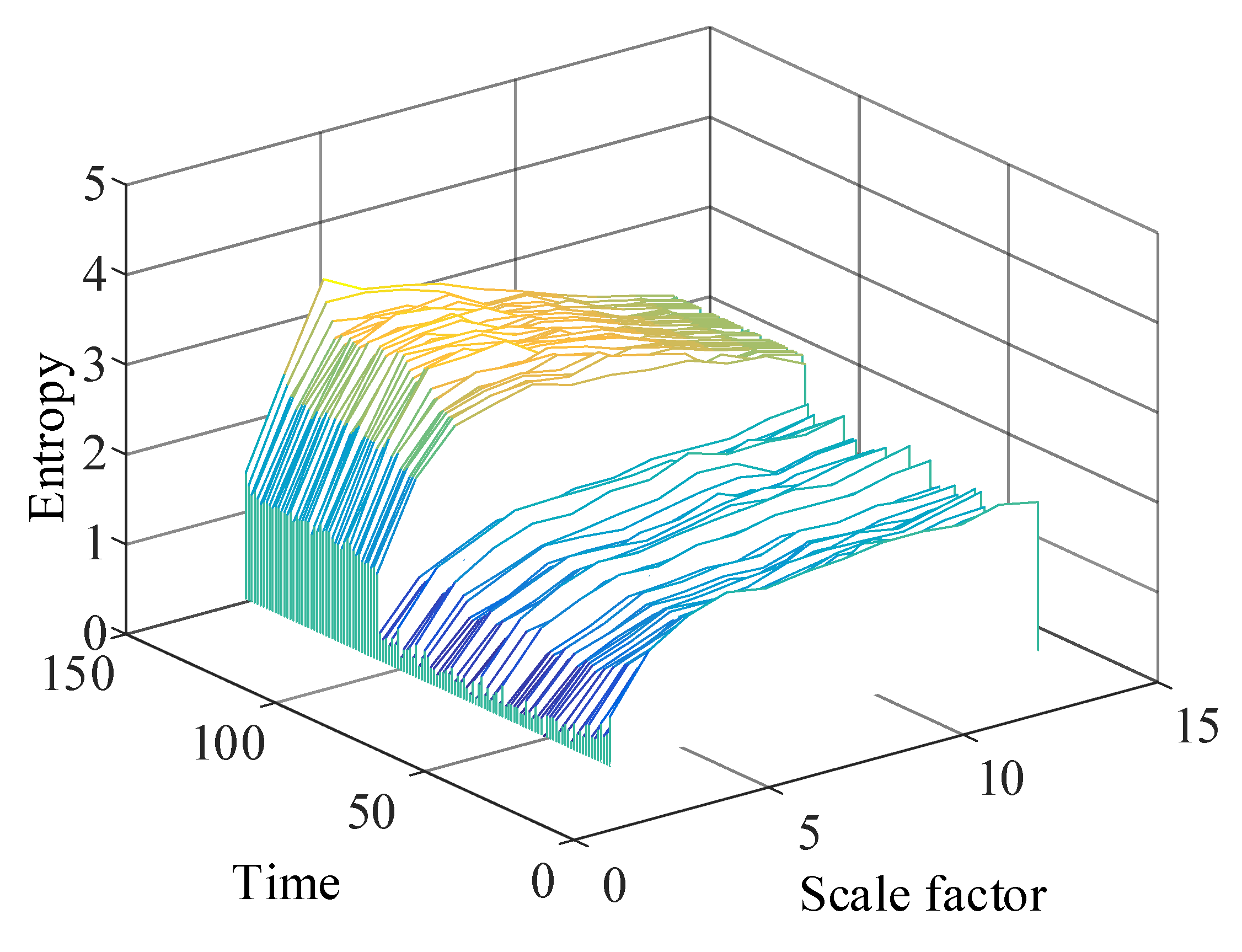
2.2. Multiscale Permutation Entropy
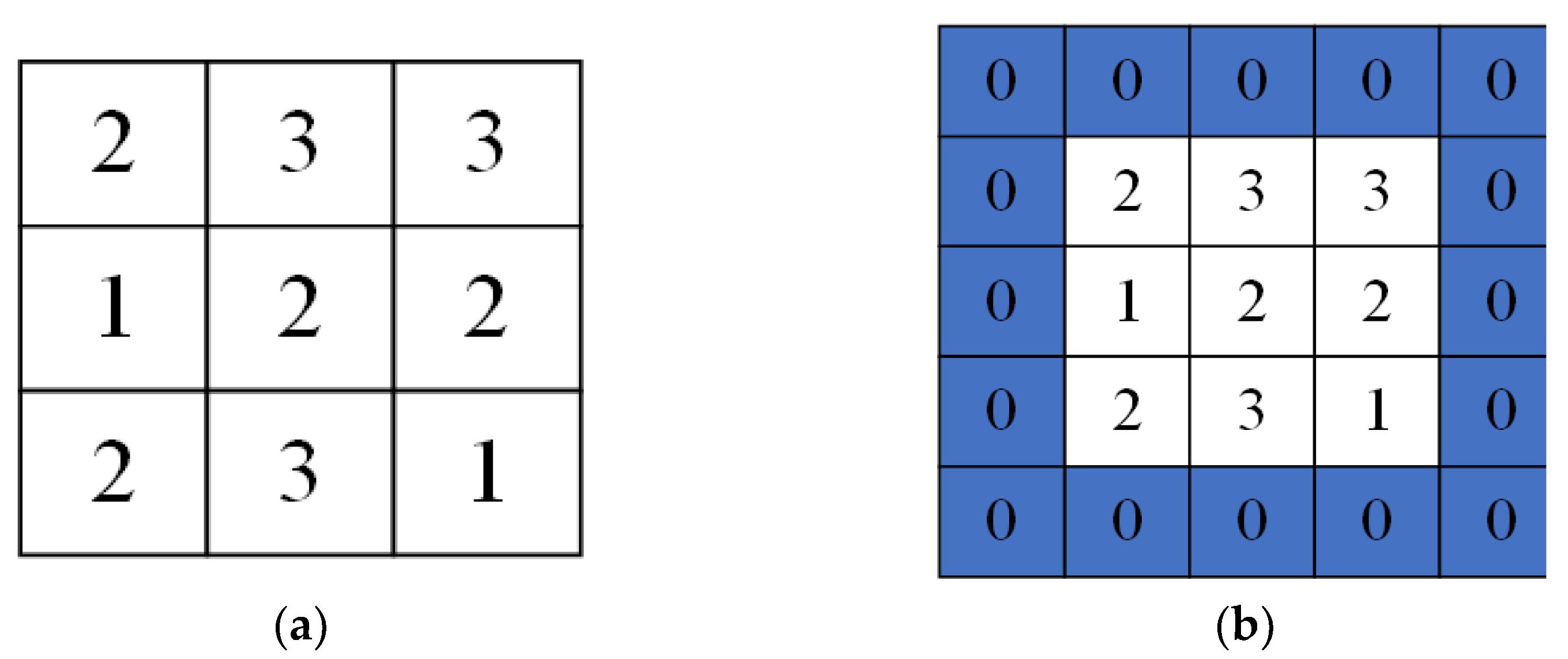
Multiscale permutation entropy avoids the limitation of the permutation entropy to evaluate the information of temporal characteristics of signals from a single scale by coarsening the input signal,
. The coarse granulation treatment at the time is shown in
Figure 1.
The specific calculation steps for multiscale permutation entropy are as follows.
- (1)
Suppose the input signal sequence is
Coarse granulation is shown in Equation (2).
where
is the scale factor;
is the coarse-graining sequence.
- (2)
The coarse-grained sequence
phase space is reconstructed to obtain the multiscale sequence, as shown in Equation (3).
where
is the multiscale sequence;
is the embedding dimension;
is the time delay sparsity.
- (3)
Arrange the multiscale time series
in ascending order and record the index
of each short time series after the ascending order. There are
permutations of each short time series. Count the number of occurrences of each permutation
and calculate the frequency of each permutation, as shown in Equation (4).
- (4)
The multiscale permutation entropy is obtained by calculating the permutation entropy of the multiscale time series, as shown in Equation (5) [
29].
2.3. Multiscale Fusion Permutation Entropy
The multiscale permutation entropy reconstructs the movement by coarse granulation and phase space reconstruction operations. It can obtain the feature information of the movement on different time scales. The problem of incomplete feature information on a single dimension was improved. It can improve the accuracy of the remaining useful life prediction. Due to the use of the sliding window slicing processing method to construct the short time series matrix, a partial overlap of the movement was caused. Although this operation can enrich the feature information in the signal, it can also cause the redundancy of features in the signals that are insensitive to the decline trend of the remaining useful life of the rolling bearing. In turn, this causes feature redundancy in the high-dimensional, multiscale permutation entropy feature matrix. Therefore, dimensionality reduction is needed to retain the primary feature information in the high-dimensional feature matrix.
The specific steps of the multiscale fusion permutation entropy feature-extraction method are shown below:
- (1)
The input data are known to comprise a multiscale permutation entropy matrix
, which contains
-dimensional multiscale permutation entropy vectors, and the objective is to reduce the multiscale permutation entropy matrix to
dimensions. The
nearest neighbors of an entropy value
(
) are found according to the Euclidean distance. The linear relationship between the entropy value
and the
nearest neighbors are established after the
nearest neighbors are found. The loss function is shown in Equation (6).
where
denotes the
nearest neighbor samples with an entropy value
;
is the linear weight coefficient, which is generally normalized to satisfy the condition shown in Equation (7). For the entropy value of the
nearest neighbor samples that are not in the entropy value
, the weight coefficient will be made to be 0, and the weight coefficient will be extended to the dimensionality of the whole dataset.
- (2)
Calculate the covariance matrix
in the space of
nearest neighbor samples, as shown in Equation (8), and find the corresponding vector of weight coefficients
, as shown in Equation (9).
where
is a vector with the
-dimensional value of 1.
- (3)
The weight coefficient vector
is constructed as the weight coefficient matrix
, from which the conditioned matrix
is calculated as shown in Equation (10).
where
is the constraint that ensures that the entropy value retains the original feature information as much as possible after dimensionality reduction.
;
is the fusion entropy value obtained after dimensionality reduction.
- (4)
Compute the first eigenvalues of the conditional matrix and compute the eigenvector corresponding to these eigenvalues.
- (5)
The matrix consisting of the second eigenvector to the st eigenvector is the multiscale fusion permutation entropy matrix, , obtained by dimensionality reduction.
3. MACNN Remaining Useful Life Prediction Model
The MACNN remaining useful life prediction model consists of a multiscale convolutional learning module and a remaining useful life forecast module. In the MACNN model, the multiscale fusion permutation entropy feature matrix was used as the input. The detailed data were automatically learned and detected by constructing the multiscale convolutional learning module. The primary information for determining the remaining useful life was fused and highlighted by a self-attentive mechanism and input into the module for remaining useful life prediction.
3.1. Multiscale Convolution Module
A convolutional neural network is a feed-forward neural network, and the main structure of a convolutional neural network is shown in
Figure 2.
- (1)
Convolutional layer:
Through feature extraction in the convolutional layer, a convolutional neural network can capture the deep features of interconnections between the input data. In the conventional layer, multiple convolution kernels are passed that are updated with model training. The output feature matrix of the convolution layer is obtained by performing dot product operations between convolution kernels and corresponding elements of the feature matrix covered by convolution kernels. Each output feature matrix is calculated from multiple input feature matrices of the previous convolutional layer. The output value
of the
-th cell of the convolution layer
is shown in Equation (11), and the convolution calculation is shown in
Figure 3 [
30].
where
is the bias,
is the convolution kernel, and the parameters are updated when feedback updates are performed after each round of model training.
There are two problems in the convolution calculation process.
- (1)
The output feature matrix size declines after each convolution computation compared with the input feature matrix. When the input feature matrix has a small size, or multiple consecutive convolution calculations are executed, the amount of information in the output feature matrix will be minimal, resulting in the loss of useful information and altering the reliability of subsequent tasks.
- (2)
Edge features of the input feature matrix. The number of calculations is less, which means that the edge information in the input feature matrix will be less involved in the analysis of the final output result. It causes the edge information of input features to be lost.
To solve these two problems, the input feature matrix is usually padded, and the main padding operations are valid padding and same padding. Valid padding is used directly to convolve the image with the convolution kernel of the input feature matrix. It is used when the input feature matrix size is significant and needs to be reduced. The same padding is used to restore the original size of the output feature matrix by padding 0. The output feature matrix, after filling with valid and same padding, is shown in
Figure 4.
- (2)
ReLU layer:
It is essential to add an activation function after the convolutional layer to enhance the nonlinear expression ability of the input movement and make the learned features more distinguishable. In recent years, rectified linear unit (ReLU), which is the most widely used activation unit, has been applied to CNNs to accelerate the convergence. Combined with the backpropagation learning method to adjust parameters, the ReLU makes shallow weights more trainable [
31]. The ReLU function is calculated as shown in Equation (12), and the function image is shown in
Figure 5.
The ReLU activation function has the following advantages:
- (1)
Smaller computation: Because the ReLU function does not involve complex operations, it can save a lot of computation time and can improve the efficiency of the overall network model.
- (2)
Prevent gradient decay: When the result of the activation function is small, training parameters are updated to a lesser extent or are not updated. In contrast, the ReLU function has a result of 1 in the activation function interval, avoiding this phenomenon.
- (3)
The overfitting phenomenon is mitigated, as shown in
Figure 5. When the feature value obtained after the calculation is less than zero, the ReLU activation function will be assigned to zero. Although this may cause information loss, it also increases the sparsity of the model, reduces the learning ability of the model, and enhances the generalization ability of the model.
The ReLU activation function performs poorly for data with more negative values in input features. In the continuing life forecast for rolling bearings, the input data used are all positive, and output target values are all greater than, or equal to, zero. Consequently, if initialization weight parameters of the control model are more significant than zero, the shortcomings of the ReLU activation function can be prevented, and the computational efficiency and accuracy of the model can be improved.
- (3)
Pooling layer:
The pooling layer and the convolutional layer form the feature-extraction module. The pooling layer can reduce the redundancy of the feature matrix and alleviate the overfitting phenomenon. The activation value
in pooling layer
is calculated as shown in Equation (13).
where
is the bias;
is the multiplicative remaining useful;
is the pooling window size;
denotes the pooling function; the commonly used pooling function is calculated as shown in
Figure 6.
- (4)
Flatten layer:
The flatten layer converts the feature matrix output from the feature-extraction module into a one-dimensional feature vector so that the features meet the input dimension requirements of the subsequent, fully connected layers.
- (5)
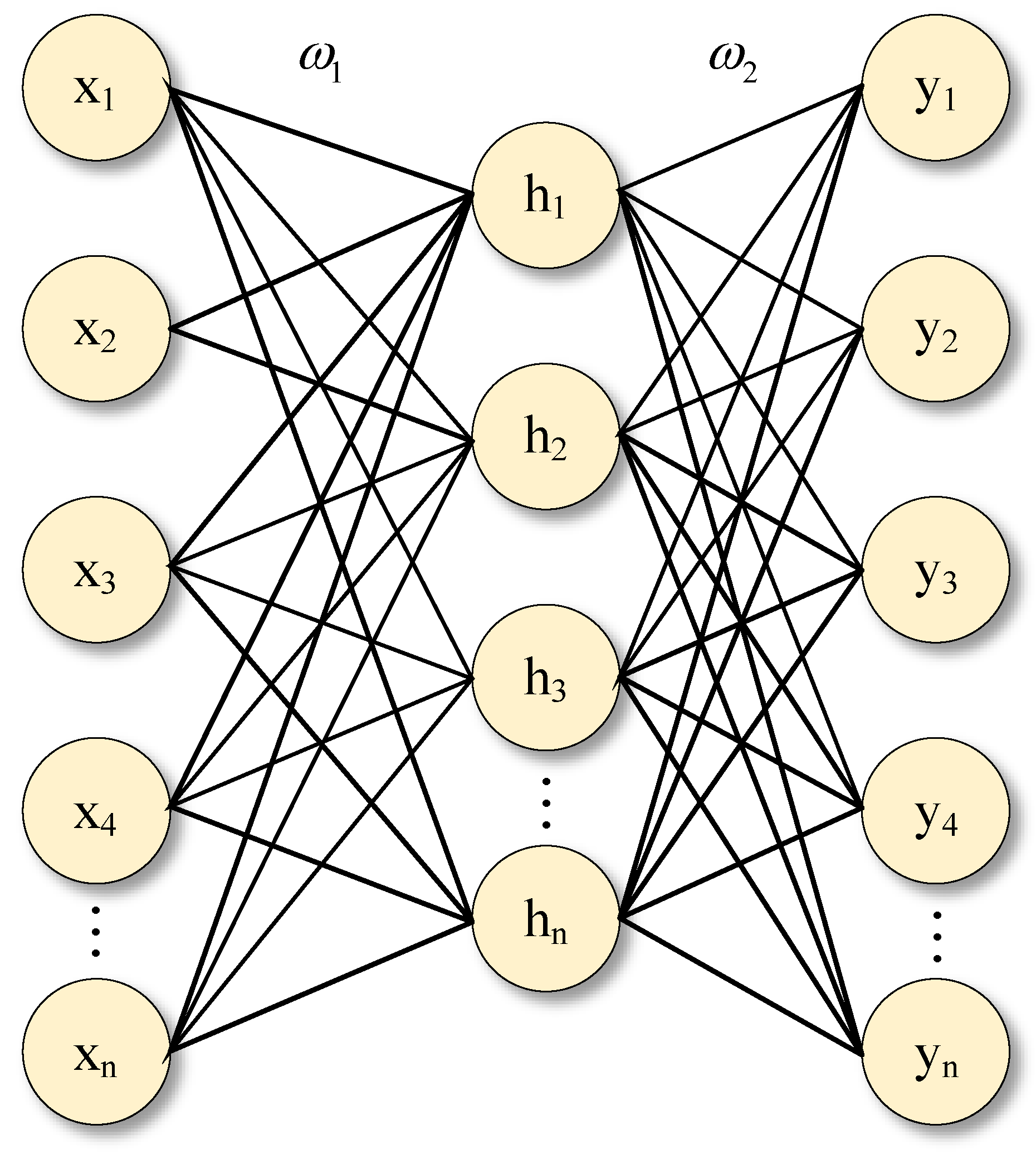
Fully connected layer:
In a convolutional neural network, after feature-extraction operations such as convolution and pooling, the output feature matrix is converted into a one-dimensional feature vector by the flatten layer, which is input to the fully connected layer for classification or prediction tasks. The fully connected layer in a convolutional neural network is the same as a multilayer perceptron. The fully connected layer discovers the local information contained in features. The structure of the fully connected layer is shown in
Figure 7 and is calculated as shown in Equation (14).
where
is the weight between each hidden layer,
is the bias, and
is the activation function.
In the task of predicting the continuing life of bearings, the input is a one-dimensional feature vector. So, a one-dimensional convolutional neural network model is used as the base model for remaining useful life prediction. The one-dimensional convolutional neural network convolution process is illustrated in
Figure 8. Convolutional kernels of dimensions (1, 4) and (1, 3) are used to convolve the input sequence under the condition of the concurrent length of the same value, respectively. The input sequence is an ascending sequence with fluctuations in the middle. From the convolution results, feature sequences calculated by convolution kernels of different scales reflect the feature trends of the input sequence differently. The feature sequence extracted from the convolution kernel of size (1, 4) reflects the increasing trend of the input sequence well but does not reflect the fluctuation trend in the input sequence. The feature sequence extracted from the convolutional kernel of size (1, 3) reflects the rising and fluctuating trends of the input features but does not reflect either direction significantly.
Convolutional neural networks often do not reflect the feature information well when the feature extraction is performed on input features at a single scale. Therefore, a multiscale convolutional module is proposed for feature learning, which consists of four conventional modules with different convolution kernel sizes in parallel. Each convolutional module consists of three layers, two ReLU activation layers, one BN layer, and one pooling layer [
32], as shown in
Figure 9. With the multiscale convolution module, the resolution of the features can be improved, which improves the remaining useful life prediction accuracy.
Suppose
and
denote the input vector and the learnable convolutional kernel, respectively, where
denotes the input vector length,
denotes the number of input channels,
represents the size of the convolutional kernel, and
represents the number of convolutional kernels. Then, the
-th feature vector of the
-th convolutional layer is shown in Equations (15) and (16).
where
denotes the Relu activation function,
denotes the output of the convolutional layer,
denotes the convolutional computation,
denotes the n-th convolutional kernel of the
-th convolutional layer, and
denotes the bias.
In the multiscale convolution module, the pooling layer is set after the third convolution layer. The main feature information learned is obtained by the maximum pooling operation after passing through the convolution layer, as shown in Equation (17).
where
is the output of the
-th feature map,
denotes the maximum pooling function,
denotes the pooling layer size, and
denotes the number of steps.
3.2. Attentional Mechanisms
The attention mechanism is an algorithm inspired by the human visual attention mechanism, which assigns different attention weights to each feature, thus allowing the model to focus more on more critical features, as shown in
Figure 10.
The commonly used weight calculation methods in the attention mechanism are additive, dot product, and scaled dot product bilinear calculations, as shown in Equation (18).
where
is the state of the last time step when the model performs time series prediction.
is the state of each time step when the model performs time series prediction.
is the attention weight calculation mechanism that calculates the correlation between
and
.
is the dimensionality of the data in the time step.
is the estimated attention weight, which suggests the importance of the time step to the overall time series feature expression importance;
is the same as
, which suggests the state of each time step when the model performs time series prediction.
3.3. Remaining Useful Life Prediction Module
The remaining useful life prediction module consists of the attention module and the fully connected neural network. The attention module is constructed to effectively fuse the feature information learned by the multiscale convolutional module and highlight the part of it that is relevant to the remaining useful life. As shown in
Figure 11, features extracted by the multiscale convolution module are used as the input of the remaining useful life prediction module, assuming that
denotes the input feature vector;
indicates the attention weight, where
is the length of the feature vector;
indicates the number of feature vectors. The attention module features are fused, as shown in Equation (19).
where
denotes the corresponding element multiplication operation in the matrix,
is the fused eigenvector,
indicates the attention weight calculation function, and the scaled dot product calculation function is used in this paper.
Finally, the fused feature vectors are input to the fully connected neural network for remaining useful life prediction. The fully connected neural network in this paper contains two hidden layers containing 64 and 128 nodes, respectively. The fully connected neural network prediction is calculated in Equation (20).
where
denotes the weight of the
-th node of the
-th hidden layer,
is the output of the
-th node of the
-th hidden layer,
represents the activation function after the hidden layer, and
is the final predicted output.
3.4. Model Parameters and Structure
The MACNN remaining useful life prediction model of rolling bearings is built on a multiscale feature-extraction module with an attention mechanism. The overall model first uses a convolution kernel of size (1, 1) to extract the shallow features of the input data. Then, four convolution modules are used to remove the deep features at different scales, respectively. Because of the large number of parameters in the overall model, to prevent the model from overfitting, the remaining join is used to stitch the shallow features with the extracted deep features. Spliced multiscale features are input into the attention fusion layer to obtain the fused attention feature vector, which is input to the fully connected layer to obtain the final prediction results. The specific parameters of the overall model are shown in
Table 1, and the model structure is shown in
Figure 12.
3.5. Overall Methodology Flow
The rolling bearing remaining useful life prediction model using the MFPE–MACNN adequately reflects the complexity and instability of the movement from multiple dimensions. The overall method makes up for a defect: the features extracted at a single scale do not fully reflect the local trend of decline of the life of rolling bearings. It can improve the accuracy of the remaining useful life prediction for rolling bearings. Based on the construction of the multiscale fusion permutation entropy with low-resonance components as features for assessing the bearing life decline trend, the multiscale feature-extraction module and the attention mechanism are added to the one-dimensional convolutional neural network to enhance the learning ability of the model for multiscale features. A multiscale attentional convolutional neural network rolling bearing remaining useful life prediction model is built. The overall method flow chart is shown in
Figure 13, and the specific steps are as follows.
Step 1: The resonant sparse decomposition of the input movement sequence as yields the high-resonance component and the low-resonance component.
Step 2: The short time series multiscale permutation entropy values are calculated to the entropy matrix for the low-resonance components.
Step 3: Find the nearest neighbor with entropy value and calculate the covariance matrix and the corresponding weight coefficient vector in the sample space of the nearest neighbors.
Step 4: Construct the weight coefficient vector into the weight coefficient matrix , and use it to calculate the conditioned matrix .
Step 5: Calculate the first eigenvalues of the conditioned matrix and calculate the eigenvector corresponding to these eigenvalues.
Step 6: The matrix consisting of the second eigenvector to the st eigenvector is the multiscale fusion permutation entropy matrix obtained by dimensionality reduction.
Step 7: Determine the size of multiple convolutional kernels, select the loss function, select the activation function, and determine the number of layers of the multiscale convolutional kernel for the remaining useful life prediction model of the multiscale convolutional neural network.
Step 8: Incorporate the attention mechanism into the remaining useful life prediction model of the multiscale convolutional neural network to form the remaining useful life prediction model of the multiscale convolutional attention neural network.
Step 9: The extracted feature matrix of the training set is input to the remaining useful life prediction model of the multiscale convolutional attention neural network to obtain the output error, and the error is backpropagated to update the prediction model parameters.
Step 10: After the parameters of the prediction model are updated to reach the optimal requirements, the test set is input to the MACNN prediction model to complete the prediction of the remaining useful life of the rolling bearing.
5. Conclusions
In this paper, an MFPE–MACNN model was proposed for the prediction of the remaining useful life of rolling bearings. This study solved the problem posed by the fact that the convolution-based deep learning model complicates the extraction of feature information from complex time series. The problem of redundant information concerning rolling bearing recession features was removed. The prediction accuracy of the rolling bearing life was improved. The multiscale fusion permutation entropy-based feature-extraction method extracts the MFPE features with low-resonance components, quantifies the evaluation signal time complexity, and reflects the decline trend of the remaining useful life. The remaining useful life prediction model for rolling bearings, based on the multiscale convolutional attention neural network, can extract the feature information of MFPE features at different time scales, fuse multiscale features, improve the fitting ability of the model, and reduce the prediction bias. The XTJU-SY rolling bearing complete lifecycle dataset was used for experimental validation and compared with other remaining useful life prediction models. Compared with the MCNN model, the CNN model, and the attention–CNN model, the MAE evaluation index was reduced by 9.91%, 37.41%, and 32.5%, respectively. The RMSE evaluation index was reduced by 15.03%, 41.98%, and 38.02% compared with the MCNN model, the CNN model, and the attention–CNN model, respectively, indicating that the MACNN model has improved fitting ability and generalization ability. The prediction error of the MACNN model occurs within 5 min, which means that researchers can better capture the information of life decline characteristics, with suitable accuracy for remaining useful life prediction.
The limitation of this article is that the overall effect of the proposed feature extraction fluctuates wildly when the bearing operating conditions are more complex, which may lead to significant deviations in the prediction of subsequent remaining useful life prediction models. In future research, a more stable feature-extraction method will be investigated to evaluate the remaining useful life of rolling bearings. Another shortcoming is that the proposed prediction model for the remaining useful life of rolling bearings has more training parameters and the model training time is longer. The model needs to be retrained after changing the bearing type or working conditions. In future research, the migration learning method will be used to solve this problem, and to improve the overall generalization and prediction efficiency of the model.












































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}