1. Introduction
Many problems in reality can be transformed into optimization problems. These optimization problems have complex characteristics, such as multiple constraints, high dimensionality, nonlinearity, and uncertainty, making them difficult to solve by the traditional optimization methods [
1,
2]. Therefore, an efficient new method is sought to solve these complex problems. Swarm intelligence optimization algorithms are a new evolutionary computing technology, which refers to some intelligent optimization algorithms with distributed intelligent behavior characteristics inspired by the swarm behavior of insects, herds, birds, fish, etc. [
3,
4,
5]. This has become the research focus of more and more researchers. It has a special relationship with artificial life, and includes Harris hawk optimization (HHO), slime mold algorithm (SMA), artificial bee colony (ABC), firefly optimization, cuckoo search, and brainstorming optimization algorithm [
6,
7,
8,
9] for engineering scheduling, image processing, the traveling salesman problem, cluster analysis, and logistics location.
PSO is a swarm intelligence optimization technology developed by Kennedy and Eberhart [
10]. The main idea is to solve the optimization problem through individual cooperation and information sharing. The PSO takes on a simple, strong parallel structure. Therefore, it has been used in multi-objective optimization, scheduling optimization, vehicle routing problems, etc. Although the PSO shows good optimization performance, it has slow convergence in solving complex optimization problems. Thus, a variety of improvement strategies for PSO are presented. Nickabadi et al. [
11] presented a new adaptive inertia weight approach. Wang et al. [
12] presented a self-adaptive learning model based on PSO for solving application problems. Zhan et al. [
13] presented an orthogonal learning strategy for PSO. Li and Yao [
14] presented a cooperative PSO. Xu [
15] presented an adaptive tuning for the parameters of PSO based on a velocity and inertia weight strategy to avoid the velocity close to zero in the early stages. Wang et al. [
16] presented a hybrid PSO using a diversity mechanism and neighborhood search. Chen et al. [
17] presented an aging leader and challenger PSO. Qu et al. [
18] presented a distance-based PSO. Cheng and Jin [
19] presented a social learning PSO based on controlling dimension-dependent parameters. Tanweer et al. [
20] presented a self-regulating PSO with the best human learning. Taherkhani et al. [
21] presented an adaptive PSO approach. Moradi and Gholampour [
22] presented a hybrid PSO based on a local search strategy. Gong et al. [
23] developed a new hybridized PSO framework with another optimization method for “learning”. Nouiri et al. [
24] presented an effective and distributed PSO. Wang et al. [
25] presented a hybrid PSO with adaptive learning to guarantee exploitation. Aydilek [
26] presented a hybrid PSO with a firefly algorithm mechanism. Xue et al. [
27] presented a self-adaptive PSO. Song et al. [
28] presented a variable-size cooperative co-evolutionary PSO with the idea of “divide and conquer”. Song et al. [
29] presented a bare-bones PSO with mutual information.
| Sources | Results and Contribution to PSO |
| Nickabadi et al. [11] | Designed an adaptive inertia weight strategy for PSO |
| Zhan et al. [13] | Designed an orthogonal learning strategy for PSO |
| Xu [15] | Designed an adaptive tuning strategy for the parameters for PSO |
| Wang et al. [16] | Developed a hybrid PSO |
| Cheng and Jin [19] | Developed a social learning PSO |
| Tanweer et al. [20] | Developed a self-regulating PSO |
| Moradi and Gholampour [22] | Designed a local search strategy for PSO |
| Gong et al. [23] | Developed a new hybridized PSO |
| Xue et al. [27] | Developed a self-adaptive PSO |
| Song et al. [28] | Developed a variable-size cooperative co-evolutionary PSO |
| Song et al. [29] | Developed a bare-bones PSO |
The comprehensive learning PSO (CLPSO) algorithm is a variant of PSO, and has good application in multimodal problems. However, because the CLPSO algorithm uses the current search velocity and individual optimal value to update the search velocity, the search velocity value in the later iteration is very small, resulting in slow convergence and reducing the computational efficiency. In order to improve the CLPSO algorithm, researchers have conducted some useful works. Liang et al. [
30] presented a variant of PSO (CLPSO) using a new learning strategy. Maltra et al. [
31] presented a hybrid cooperative CLPSO by cloning fitter particles. Mahadevan and Kannan [
32] presented a learning strategy for PSO to develop a CLPSO to overcome premature convergence. Ali and Khan [
33] presented an attributed multi-objective CLPSO for solving well-known benchmark problems. Hu et al. [
34] presented a CLPSO-based memetic algorithm. Zhong et al. [
35] presented a discrete CLPSO with an acceptance criterion of SA. Lin and Sun [
36] presented a multi-leader CLPSO based on adaptive mutation. Zhang et al. [
37] presented a local optima topology (LOT) structure with the CLPSO for solving various functions. Lin et al. [
38] presented an adaptive mechanism to adjust the comprehensive learning probability of CLPSO. Wang and Liu [
39] presented a novel saturated control method for a quadrotor to achieve three-dimensional spatial trajectory tracking with heterogeneous CLPSO. Cao et al. [
40] presented a CLPSO with local search. Chen et al. [
41] presented a grey-wolf-enhanced CLPSO based on the elite-based dominance scheme. Wang et al. [
42] presented a heterogeneous CLPSO with a mutation operator and dynamic multi-swarm. Zhang et al. [
43] presented a novel CLPSO using the Bayesian iteration method. Zhou et al. [
44] presented an adaptive hierarchical update CLPSO based on the strategies of weighted synthesis. Tao et al. [
45] presented an enhanced CLPSO with dynamic multi-swarm.
| Sources | Results and Contribution to PSO |
| Maltra et al. [31] | Developed a hybrid cooperative CLPSO |
| Ali and Khan [33] | Developed an attributed multi-objective CLPSO |
| Hu et al. [34] | Presented a CLPSO with local search |
| Zhong et al. [35] | Presented a discrete CLPSO |
| Lin and Sun [36] | Designed an adaptive mutation for multi-leader CLPSO |
| Lin et al. [38] | Designed an adaptive mechanism for CLPSO |
| Cao et al. [40] | Developed a CLPSO with local search |
| Chen et al. [41] | Developed a grey-wolf-enhanced CLPSO |
| Wang et al. [42] | Developed a heterogeneous CLPSO |
| Zhou et al. [44] | Developed an adaptive hierarchical update CLPSO |
| Tao et al. [45] | Developed an enhanced CLPSO with dynamic multi-swarm |
These improved CLPSO algorithms use the individual optimal information of particles to guide the whole iterative process, have better diversity and search range, and can solve complex multimodal problems. However, because the global optimal value does not participate in the particle velocity and position, the particle velocity is too small in the later search, and the convergence speed is slow. At the same time, due to the lack of measures for avoiding the local optimization, once the optimal values of most particles fall into the local optimization, the convergence is unable to find the global optimal value, and the performance is unstable. Therefore, to improve the optimization performance of CLPSO, a novel multi-strategy adaptive CLPSO (MSACLPSO) based on making use of comprehensive learning, multi-population parallel, and parameter adaptation was designed for this paper. The MSACLPSO effectively promotes information exchange in different dimensions, ensures information sharing in the population, enhances the convergence and stability, and balances the search ability compared with the other related algorithms.
The main contributions and novelties of this paper are described as follows.
- (1)
A novel multi-strategy adaptive CLPSO (MSACLPSO) based on comprehensive learning, multi-population parallel, and parameter adaptation is presented.
- (2)
A multi-population parallel strategy is designed to improve population diversity and accelerate convergence.
- (3)
A new velocity update strategy is designed by adding the global optimal value in the population to the velocity update.
- (4)
A new adaptive adjustment strategy of learning factors is developed by linearly changing the learning factors.
- (5)
A parameter optimization method of photovoltaics is designed to prove the actual application ability.
2. PSO
PSO is a population-based search algorithm that simulates the social behavior of birds within a range. In PSO, all individuals are referred to as particles, which are flown through the search space to delete the success of other individuals. The position of particles changes according to the individual’s social and psychological tendencies. The change of one particle is influenced by knowledge or experience. As a modeling result of the social behavior, the search is processed to return to previously successful areas in the search space. The particle’s velocity (
) and position (
) are changed by the particle best value (
) and global best value (
). The formula for updating velocity and position is given as follows:
where
is the velocity of the
particle at the
iteration,
is the position of particle
at the
iteration, and the position of the particle is related to its velocity.
is an inertia weight factor, which is used to reflect the motion habits of particles and represent the tendency of particles to maintain their previous speed.
is a self-cognition factor, which reflects the particle’s memory of its own historical experience, and represents that the particle has a tendency to approach its best position.
is a social cognition factor, which reflects the population’s historical experience of collaboration and knowledge sharing among particles, and represents that particles tend to approach the best position in the population or field history.
and
represent random numbers in [0, 1], which denote the remembrance ability for the research. Generally, the value in the
can be clamped to the range [−
,
] in order to control the excessive roaming of particles outside the search space. The PSO is terminated until the maximal number of iterations is reached or the best particle position cannot be further improved. The PSO achieves better robustness and effectiveness in solving optimization problems.
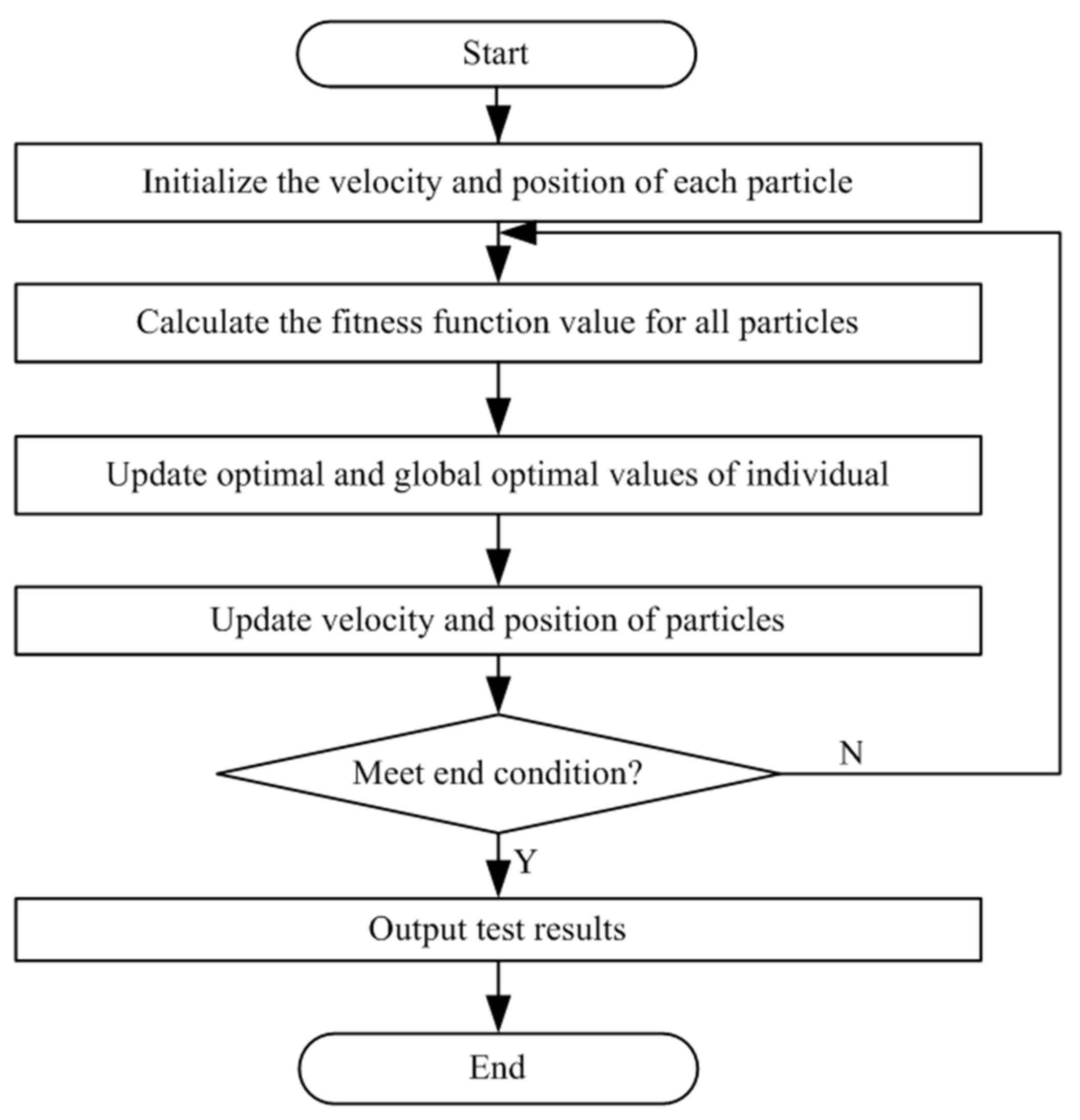
The basic flow of the PSO is shown in
Figure 1.
3. CLPSO
PSO can easily fall into local extrema, which leads to premature convergence. Thus, a new update strategy is presented to develop a CLPSO algorithm. In the PSO, each particle learns from its own optimal value and the global optimal value. Therefore, in the velocity update formula of CLPSO, the social part of the global optimal solution of particle learning is not used. In addition, in the velocity update formula of the traditional PSO algorithm, each particle learns from all dimensions of its own optimal value, but its own optimal value is not optimal in all dimensions. Therefore, the CLPSO algorithm introduces a comprehensive learning strategy to construct learning samples using the
of all particles to promote the information exchange, improve population diversity, and avoid falling into local extrema. The comprehensive learning strategy is to use the individual historical optimal solution of all particles in the population to update the particle position in order to effectively enhance the exploration ability of the PSO and achieve excellent optimization performance in solving multimodal optimization problems. The velocity update of particle and position is described as follows:
where
P and
D. P is the size of the population and
is the search space dimension.
is the particle position,
is the velocity of particle
,
is the search range of particle
,
is the velocity range,
is the inertia weight,
is the learning factor,
is a randomly distributed number on (0, 1),
refers to other particles that particle
needs to learn in the D-dimension, and
can be the optimal position of any particle.
The determination method of is described as follows: For each particle dimension, a random probability is produced. If the random probability is greater than the learning probability , then this particle dimension learns from the corresponding dimension of its own individual optimal value. On the other hand, two particles are randomly selected to learn the better optimal value. To ensure the population’s polymorphism, the CLPSO also sets an update interval number m; that is, when the individual optimal value of particle has not been updated for iterations, it is regenerated.
4. MSACLPSO
PSO has simplicity, practicality, and fixed parameters, but it has the disadvantage of easily falling into local optima, as well as weak local search ability. The CLPSO has slow velocity in the later search, low convergence speed, and unstable performance. To solve these problems, a multi-strategy adaptive CLPSO (MSACLPSO) algorithm is proposed by introducing a comprehensive learning strategy, multi-population parallel strategy, velocity update strategy, and parameter adaptive strategy. In MSACLPSO, a comprehensive learning strategy is introduced to construct learning samples using the pBest of all particles to promote information exchange, improve population diversity, and avoid falling into local extrema. To overcome the lack of local search ability in the later stage, the global optimal value of the population is used for the velocity update, and a new update strategy is proposed to enhance the local search ability. The multi-population parallel strategy is employed to divide the population into subpopulations, and then iterative evolution is carried out appropriately to achieve particle exchange and mutation, enhance the population diversity, accelerate the convergence, and ensure information sharing between the particles. The linearly changing strategy of the learning factors is employed to realize the iterative evolution in different stages and the adaptive adjustment strategy of learning factors, which can enhance the global search ability and improve the local search ability. The -shaped decreasing function is adopted to realize the adaptive adjustment of inertia weight to ensure that the population has high speed in the initial stage, reduce the search speed in the middle stage—so that the particles will more easily converge to the global optimum—and maintain a certain speed for the final convergence in the later stage.
4.1. Multi-Population Parallel Strategy
The idea of multi-population parallel is based on the natural phenomenon of the evolution of the same species in different regions. It divides the population into multiple subpopulations, and then each subpopulation searches for the optimal value in parallel to improve the search ability. The indirect exchange of the optimal value and dynamic recombination of the population can enhance the population diversity and accelerate the convergence. A multi-population parallel strategy is proposed here. The main ideas of the multi-population parallel strategy are described as follows: The population is divided into
N subpopulations in the process of evolution. For each subpopulation, the particle carries out iterative evolution, and the particle exchange and particle mutation under appropriate conditions are executed according to certain rules, so as to ensure information sharing between the particles of the population through the exchange of particles between subpopulations. Therefore, to enhance the local search ability of the CLSPO algorithm in the later stage, a new update strategy is presented after the g0 generation is completed. That is, the global optimal value
of the population is added to the velocity update, as shown in Equation (4):
where
and
are learning factors,
is the optimal value of the particle in each subpopulation
,
is the optimal value of each subpopulation
,
and
are randomly distributed numbers on (0, 1).
4.2. Adaptive Learning Factor Strategy
In PSO, the values of
and
are set in advance according to experiences, reducing the self-learning ability. Therefore, the linearly changing strategy of the learning factors is developed for
and
. In the early evolution stage, the self-cognition item is reduced and the social cognition item is increased to improve the global search ability. In the later evolution stage, the local search ability is guaranteed by encouraging particles to converge towards the global optimum. Therefore, the adaptive learning factor strategy is described as follows:
where
and
are the maximum value and minimum value, respectively.
4.3. Adaptive Inertia Weight Strategy
In PSO, when the particles in the population tend to be the same, the last two terms in the particle velocity update formula—namely, the social cognition part, and the individual’s own cognition part—will gradually tend towards 0. If the inertia weight
is less than 1, the particle speed will gradually decrease, or even stop moving, which result in premature convergence. When the optimal fitness of the population has not changed (i.e., has stagnated) for a long time, the inertia weight
should be adjusted adaptively according to the degree of premature convergence. If the same adaptive operation is adopted for the population, when the population has converged to the global optimum, the probability of destroyed excellent particles will increase with the increase in their inertia weight, which will degrade the performance of the PSO algorithm. To better balance the search ability, an
-shaped decreasing function is adopted to ensure that the population has high speed in the initial stage, and the search speed decreases in the middle stage, so that the particles can easily converge to the global optimum value and, finally, converge at a certain speed in the later stage. The
-shaped decreasing function for the inertia weight
is described as follows:
where
and
are the maximum and minimum values, respectively—
and
—and
is the control coefficient to adjust the speed change, where
a = 13.
4.4. Model of MSACLPSO
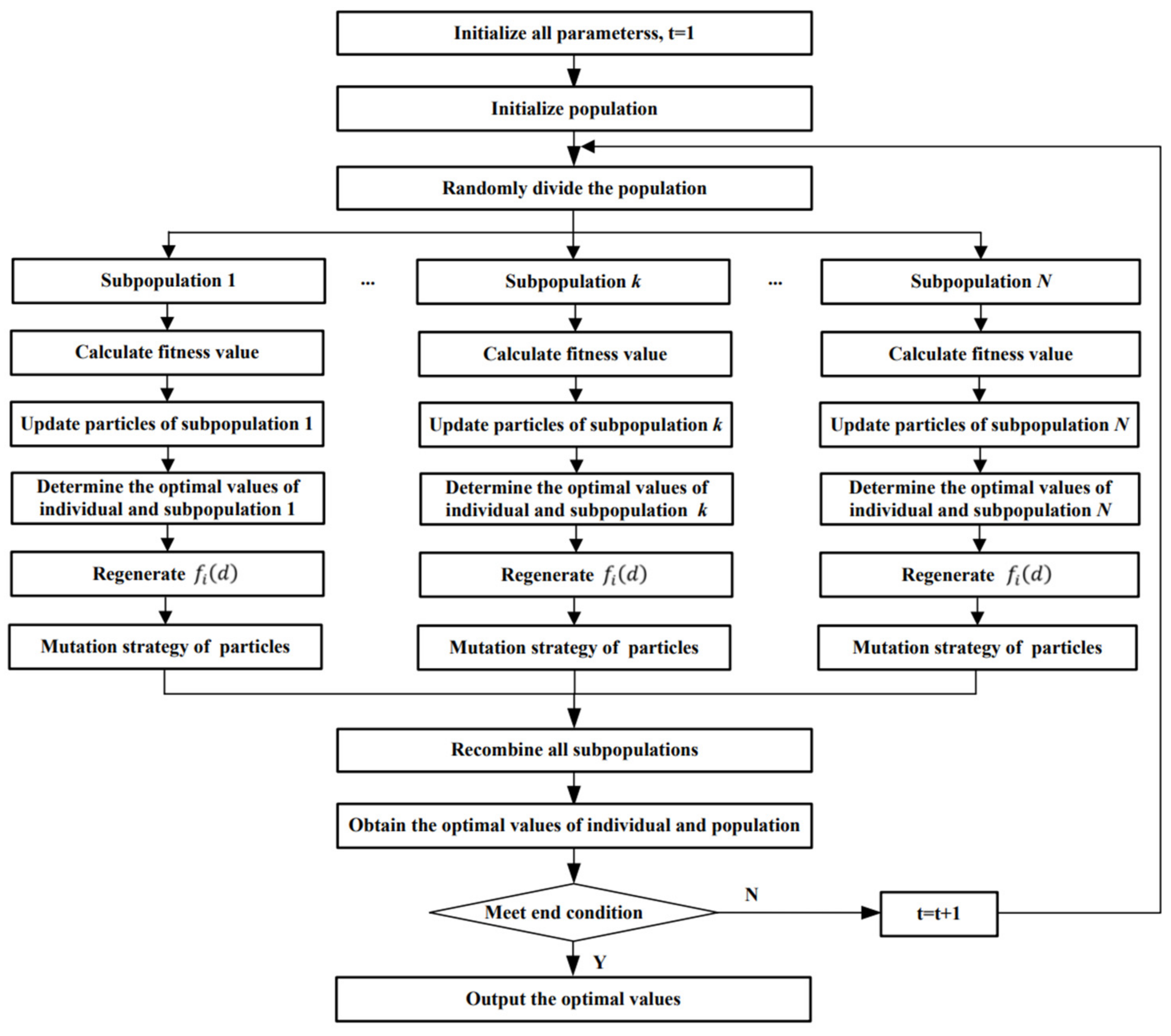
The flow of MSACLPSO is shown in
Figure 2.
The steps of MSACLPSO are described as follows:
Step 1: Divide the population into subpopulations, and initialize all parameters.
Step 2: Execute the CLPSO algorithm for each subpopulation. The objective function is used to find out the individual optimal value of the particle, the optimal value of the subpopulation, and the global optimal value of the population. To ensure the high global search ability in the early stage, T0 is set for the early stage, and each subpopulation updates all particle states according to Equation (3). To enhance the local search ability of CLSPO in the later stage, after the T0 iteration is completed, each subpopulation updates all particle states according to Equation (4).
Step 3: If the optimal value of one subpopulation does not update for successive R1 iterations, the population may fall into local optimization. To avoid falling into the local optimum for the subpopulation, the mutation strategy is used here. Each dimension of each particle in the subpopulation is mutated with the probability
. The mutation mode is described as follows:
where
is the random number on (−1, 1).
Step 4: After T0 iterations are executed, to enhance population diversity, the particles are randomly exchanged between populations every interval R iteration to recombine subpopulations. The recombination of subpopulations is described as follows: All subpopulations randomly select 50% of the particles, which are randomly exchanged with the particles of other populations. Then, according to the fitness values of all particles in all subpopulations, 1/N particles with the best fitness values in each subpopulation are selected to construct a new population. It is worth noting that the exchanged particle can be any particle in any other population.
Step 5: Determine whether the end conditions are met. If they are met, the optimal result is output; otherwise, return to Step 2.





{kind=link}
{kind=link}