
Entropy-Weight-Method-Based Integrated Models for Short-Term Intersection Traffic Flow Prediction


Abstract
:1. Introduction
2. Literature Review
2.1. Entropy Weight Method (EWM)
2.2. Short-Term Traffic Flow Forecasting—K-Nearest Neighbor (KNN) Algorithm
- Extended state vector.State vector describes the criterion by which the current data are compared with historical data. Usually, the state vector X(t) is defined as X(t) = [S(t), S(t − 1), …, S(t − n)], where S(t), S(t − 1), …, S(t − n) denote the traffic flow rates at time intervals t, t − 1, …, t − n, respectively. Some research [25,26,27,28] added spatial factors (such as the upstream and downstream intersection traffic flow rates) to extend the dimension of the state vector.
- Improved distance measurements.The common method of measuring “proximity” in non-parametric regression is to use Euclidean distance [29,30] or weighted Euclidean distance [29] to calculate the distance between state vectors. There are other distance measuring methods that have been utilized by researchers, such as Manhattan distance [29,30,31,32], Hassanat distance [33,34], and Chi-square [35]. Improvements include using the weighted Euclidean distance by considering different factors. For example, Yu et al. suggested that weights should be assigned based on the close degree between time components in the state vector and the forecasting time [26]. Habtemichael and Cetin also recommended giving more weight to the recent measurements and less to the older ones [36].
- Improved methods for determining the K value.Based on the calculated distance, the K nearest neighbors can be identified. The KNN model is sensitive to the selected K value, and the K value affects the model accuracy [37]. Previous studies have used different methods to determine the K value based on average absolute percentage error, relative error, and root mean square error [24,25,26,27,28,38,39,40].
- Enhanced prediction algorithm.For the KNN method, the model prediction is mainly based on the simple average or weighted average of the K nearest neighbors. There are different methods to determine the weights. For example, ref. [25,26,27] used the inverse distance as the weight, and ref. [28] used the Gaussian function to determine the weights of the selected neighbors.
2.3. Short-Term Traffic Flow Forecasting—Artificial Neural Network (ANN)
3. Methodology
3.1. Data Description
- Traffic flow rates by signal cycle;
- Queue length;
- Signal timing plan;
- Weekend or not.
3.2. Model Development
3.2.1. Improved K-Nearest Neighbor’s Algorithm
- Weighted Distance Measurement:The model developed in this research is to forecast the vehicle arrival rate at the intersection 30 min later based on the arriving rates in the previous 3 h. Therefore, the prediction model can be mathematically expressed as follows.where,is the current time interval;is the arrival traffic flow rate during the current time interval.Since the traffic flow rate is at a 6 min interval, the vector () represents the arrival travel flow rates during the previous 3 h and represents the predicted traffic flow rate that will arrive at the intersection in half an hour. According to Habtemichael and Cetin [36], the time factor should be considered in the traffic flow prediction, which means when calculating the similarity between current and historical traffic flow data, more weight should be given to the more recently collected traffic flow data. According to this idea, the following weighted Euclidean distance is used:where,is the number of vehicles arriving at the tth time interval on the ith day in the historical dataset;is the number of vehicles arriving at the tth time interval on the jth day in the prediction dataset;is a time-related weight coefficient;is the normalized temporal distance between the endpoint of tth time interval and the prediction time point, which can be expressed as follows:where,is the temporal distance between the endpoint of tth time interval and the prediction time point (in the number of time intervals as the unit);is the longest temporal distance from the prediction time point;is the shortest temporal distance from the prediction time point.
- Optimized K ValueBased on the distance calculated in Equation (2), the K nearest neighbors (the K historical days that have the traffic conditions most similar to the traffic condition at the targeted time t of the prediction day) can be selected. In the basic KNN model that was developed by Qu et al. [21], a given k value (K = 10) was used. To improve the model prediction, in this study, different K values from 7 to 15 were tested and the K values that resulted in the lowest prediction error were selected for predicting the traffic flow rate at the study intersection.
- Improved Prediction AlgorithmIn the basic KNN model developed by Qu et al. [21], the average traffic flow rate of the selected K days was used for prediction. In this study, the weighted average method is used and the neighboring distance is used as the weight. The basic idea is that if the traffic condition of the selected day is more similar to the predicted day, it should contribute more to the predicted traffic flow rates. Thus, the weighting coefficient of each neighbor can be calculated by Equation (5).where represents the weighted Euclidean distance between the ith similar historical day and the prediction day (jth day) and is calculated by using Equation (2). Then, the predicted traffic flow at the given time t + 5 can be estimated using Equation (6).where represents the number of vehicles arriving 30 min after the target time t during the ith historical day that was one of the selected K nearest neighbors.
3.2.2. Integrated Prediction Models Based on Entropy Weight Method
- Entropy Weight Method A (EWM-A)As mentioned in the literature review section, the EWM-A method is based on the idea that the smaller the entropy value of the prediction error of an individual model, the greater the weight should be assigned to it and vice versa. According to Bai et al. (2020), by using the EWM-A method, the two selected individual models can be integrated through the following process:Step 1: Calculate the absolute error weight of the individual model at time t by Equation (7).where,,s indicates different models,n is the number of individual models (n = 2 in this study),t represents the time, m is the number of prediction time points,is the predicted value of the sth individual model at time t,is the observed value.Step 2: Calculate the entropy value of the sth individual model:If , then ,Note that, according to the entropy concept, in Equation (8) should be a probability of an event. However, according to Equation (7), is a ratio of a prediction error to the sum of prediction errors instead of a probability. This is a critical problem with this type of EWM and will be discussed more in the model evaluation part.Step 3: Calculate the weight of the sth individual model:In this study n = 2, thus, becomes:Note that, , .Step 4: Integrate the predictions of individual models based on the calculated weights:where is the predictions of the sth individual model.
- Entropy Weight Method B (EWM-B)Different from the EWM-A method, the EWM-B method is based on the idea that if an individual prediction model has a smaller entropy value of the prediction error, the variation degree and uncertainty in this model are greater, thereby a smaller weight coefficient should be assigned to this individual model. According to Huang et al. [5], the procedure of integrating the developed improved KNN model and Elman model based on EWM-B are as follows.Step 1: Calculate the relative error weight of the individual prediction model:where,,s indicates different models,n is the number of individual models (n = 2 in this study),t represents the time,m is the number of prediction time points,is the predicted value of the sth individual model at time t,is the observed value.Step 2: Calculate the entropy value of the sth individual model:If , then ,Step 3: Calculate the variation degree of the sth model:where, 0 < Hs < 1Step 4: Calculate the weight coefficient of the sth individual model:Note that, in this study n = 2, thus:Compared with the weight coefficients of EWM-A given in Equation (10), it can be seen that the weight coefficients of two individual models are simply swapped in EWM-B.Step 5: Integrate the predictions of individual models based on the calculated weights:where,is the predictions of the sth individual model.
- Entropy Weight Method C (EWM-C)In information theory, entropy is a measure of the uncertainty associated with a random variable. In the model integration, if we calculate the entropy based on the relative error of the individual prediction model as shown in Equation (7), both low and high accuracy of prediction models could all lead to a small entropy value because the error is relative to other errors. To address this problem, Shan and Zhang [6] proposed to use a new EWM-based method (EWM-C) for model integration to take into account the prediction accuracy levels of the individual models. In this method, they used a weighted entropy of the model prediction error, and the prediction accuracy level of the individual model was incorporated into this weighted entropy. In this way, the impact of the model with low accuracy can be reduced and the prediction accuracy of the integrated model can be improved. Following is the detailed procedure for integrating the prediction models using the EWM-C method.Step 1: Calculate the prediction accuracy of the sth individual model:where,is the prediction accuracy of the sth individual model at time t,s indicates different models,n is the number of individual models (n = 2 in this study),t represents the time, m is the number of prediction time points,is the predicted value of the sth individual model at time t,is the observed value.Step 2: Establish the matrix of model prediction accuracyThen, the matrix of the prediction accuracy of different individual models can be expressed as follows:Note that, the row vector represents the accuracy of the sth individual model .Step 3: Establish the matrix of accuracy level frequencyFirst, round the number in the matrix down to its integer (for example, 87.15% rounded down to 87%). Then, by counting the number of different accuracy levels, the following matrix of the accuracy level frequency can be established.where represents the number of occurrences of (integer part) in the row s.Step 4: Calculate the weighted information entropy of the sth modelThen, the weighted information entropy of the sth model, i.e., Es, can be calculated by Equation (21).where,Nst is the number of greater than the accuracy level in the sth row in matrix A (in this study = 80%).Step 5: Calculate the weight coefficient of the sth individual model:The weight coefficient of the individual model can be calculated based on the Es calculated in Step 4 as follows:where,Z is a normalization factor that ensures that all weights sum to 1.Thus, when n = 2, the weight of the two individual models can be calculated as:Step 6: Integrate the predictions of individual models based on the calculated weights:where,is the predictions of the sth individual model.According to the three different EWM-based methods introduced above, different integrated models were developed for each day of the week except Tuesday. The weight coefficients estimated by using different EWM-based methods are presented in Table 1.
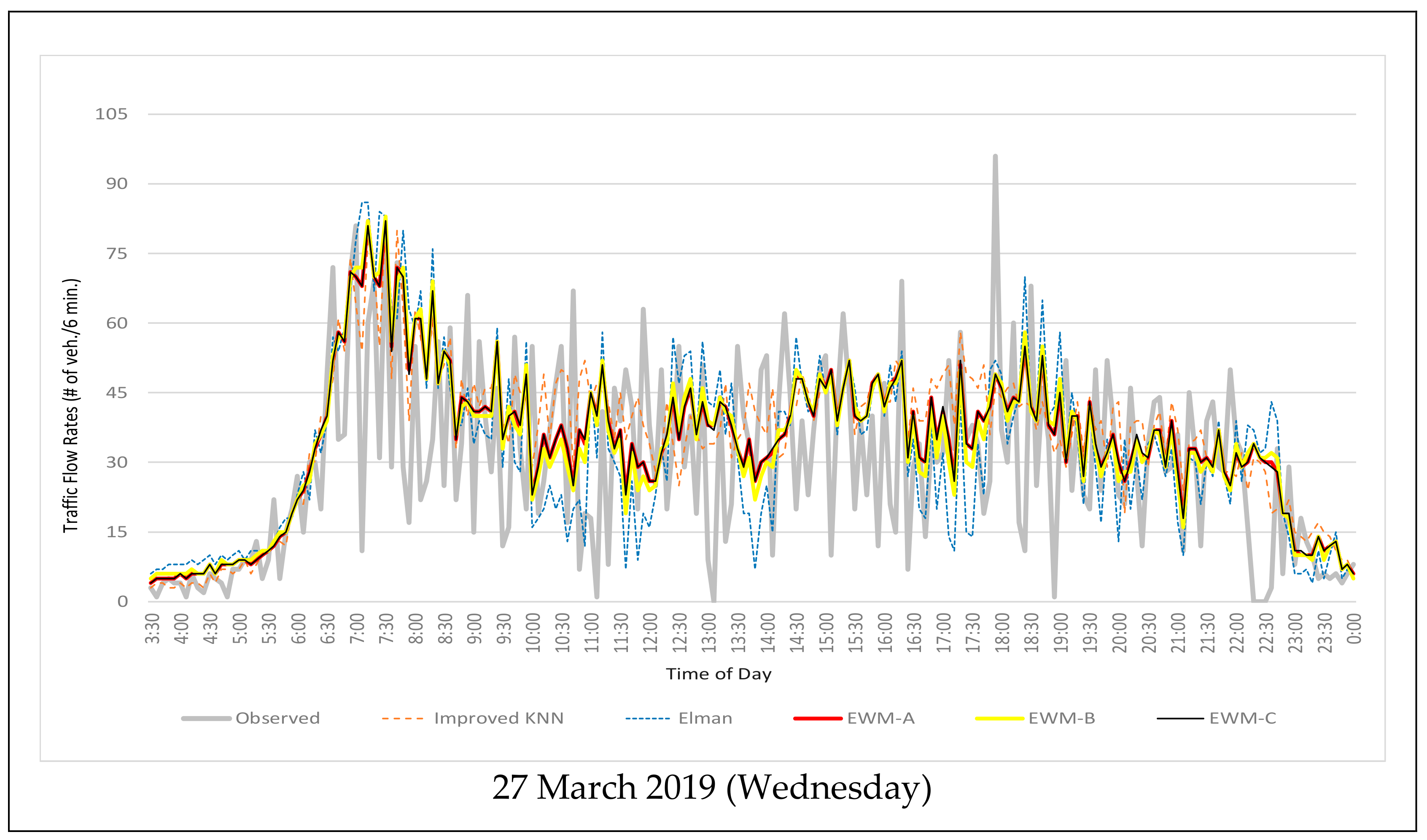
4. Model Evaluation
5. Conclusions and Recommendations
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Y.; Kong, L.; He, G. Entropy-Based Grey Correlation Fault Diagnosis Prediction Model. In Proceedings of the 2012 4th International Conference on Intelligent Human-Machine Systems and Cybernetics, Nanchang, China, 26–27 August 2012; Volume 2, pp. 88–91. [Google Scholar] [CrossRef]
- Dang, V.T.; Dang, W.V.T. Multi-Criteria Decision-Making in the Evaluation of Environmental Quality of OECD Countries: The Entropy Weight and VIKOR Methods. Int. J. Ethics Syst. 2019, 36, 119–130. [Google Scholar] [CrossRef]
- Sheng, J.; Chen, T.; Jin, W.; Zhou, Y. Selection of Cost Allocation Methods for Power Grid Enterprises Based on Entropy Weight Method. J. Phys. Conf. Ser. 2021, 1881, 022063. [Google Scholar] [CrossRef]
- Bai, H.; Feng, F.; Wang, J.; Wu, T. A Combination Prediction Model of Long-Term Ionospheric FoF2 Based on Entropy Weight Method. Entropy 2020, 22, 442. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, S.; Ming, B.; Huang, Q.; Leng, G.; Hou, B. A Case Study on a Combination NDVI Forecasting Model Based on the Entropy Weight Method. Water Resour. Manag. 2017, 31, 3667–3681. [Google Scholar] [CrossRef]
- Shan, S.; Zhang, S. A Weighted Hybrid Forecasting Model Based on Information Entropy. Electron. Technol. Softw. Eng. 2021, 5, 196–198. [Google Scholar]
- Zhang, Q.; Zhu, X.; Xu, K. Combination Forecasting on Software Reliability Based on Entropy Weight. In Proceedings of the Proceedings of 2011 International Conference on Electronic Mechanical Engineering and Information Technology, Harbin, China, 12–14 August 2011; Volume 6, pp. 3095–3097. [Google Scholar] [CrossRef]
- Sun, X.; Xing, H.; Zhang, J. Research of Combined Grey Model Based on Entropy Weight for Predicting Anchor Bolt Bearing Capacity. IOP Conf. Ser. Earth Environ. Sci. 2021, 660, 012080. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Y. Entropy-Based Combining Prediction of Grey Time Series and Its Application. In Proceedings of the 2009 Second International Conference on Intelligent Computation Technology and Automation, Changsha, China, 10–11 October 2009; Volume 2, pp. 37–40. [Google Scholar] [CrossRef]
- Wang, J.; Qiao, F.; Zhao, F.; Sutherland, J.W. A Data-Driven Model for Energy Consumption in the Sintering Process. J. Manuf. Sci. Eng. 2016, 138, 101001. [Google Scholar] [CrossRef]
- Gao, J.; Zheng, D.; Yang, S. Sensing the Disturbed Rhythm of City Mobility with Chaotic Measures: Anomaly Awareness from Traffic Flows. J. Ambient Intell. Hum. Comput. 2021, 12, 4347–4362. [Google Scholar] [CrossRef]
- Erlander, S. Optimal Spatial Interaction and the Gravity Model; Lecture Notes in Economics and Mathematical Systems; Springer: Berlin/Heidelberg, Germany, 1980; Volume 173, ISBN 978-3-540-09729-7. [Google Scholar]
- Wilson, A.G. Optimization in Locational and Transport Analysis; Wiley: Chichester, UK, 1981; ISBN 978-0-471-28005-7. [Google Scholar]
- Petrov, A.I. Entropy Method of Road Safety Management: Case Study of the Russian Federation. Entropy 2022, 24, 177. [Google Scholar] [CrossRef]
- Kim, K.; Pant, P.; Yamashita, E.; Brunner, I.M. Entropy and Accidents. Transp. Res. Rec. 2012, 2280, 173–182. [Google Scholar] [CrossRef]
- Koşun, Ç.; Özdemir, S. An Entropy-Based Analysis of Lane Changing Behavior: An Interactive Approach. Traffic Inj. Prev. 2017, 18, 441–447. [Google Scholar] [CrossRef] [PubMed]
- Xie, L.; Wu, C.; Duan, M.; Lyu, N. Analysis of Freeway Safety Influencing Factors on Driving Workload and Performance Based on the Gray Correlation Method. J. Adv. Transp. 2021, 2021, e6566207. [Google Scholar] [CrossRef]
- Crisler, M.C.; Storf, H. A Decade of Steering Entropy—Use, Impact, and Further Application. In Proceedings of the Transportation Research Board 91st Annual Meeting, Washington, DC, USA, 22–26 January 2012. [Google Scholar]
- Ishak, S.; Kotha, P.; Alecsandru, C. Optimization of Dynamic Neural Network Performance for Short-Term Traffic Prediction. Transp. Res. Rec. 2003, 1836, 45–56. [Google Scholar] [CrossRef]
- Li, R.; Lu, H. Combined Neural Network Approach for Short-Term Urban Freeway Traffic Flow Prediction. In Advances in Neural Networks—ISNN 2009; Yu, W., He, H., Zhang, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1017–1025. [Google Scholar] [CrossRef]
- Qu, W.; Li, J.; Yang, L.; Li, D.; Liu, S.; Zhao, Q.; Qi, Y. Short-Term Intersection Traffic Flow Forecasting. Sustainability 2020, 12, 8158. [Google Scholar] [CrossRef]
- Zhao, J.; Gao, H.; Jia, L. Short-Term Traffic Flow Forecasting Model Based on Elman Neural Network. In Proceedings of the 2008 27th Chinese Control Conference, Kunming, China, 16–18 July 2008; pp. 499–502. [Google Scholar] [CrossRef]
- Ma, W.; Wang, R. Traffic Flow Forecasting Research Based on Bayesian Normalized Elman Neural Network. In Proceedings of the 2015 IEEE Signal Processing and Signal Processing Education Workshop (SP/SPE), Salt Lake City, UT, USA, 9–12 August 2015; pp. 426–430. [Google Scholar]
- Smith, B.L.; Williams, B.M.; Keith Oswald, R. Comparison of Parametric and Nonparametric Models for Traffic Flow Forecasting. Transp. Res. Part C Emerg. Technol. 2002, 10, 303–321. [Google Scholar] [CrossRef]
- Wu, S.; Yang, Z.; Zhu, X.; Yu, B. Improved K-Nn for Short-Term Traffic Forecasting Using Temporal and Spatial Information. J. Transp. Eng. 2014, 140, 04014026. [Google Scholar] [CrossRef]
- Yu, B.; Song, X.; Guan, F.; Yang, Z.; Yao, B. K-Nearest Neighbor Model for Multiple-Time-Step Prediction of Short-Term Traffic Condition. J. Transp. Eng. 2016, 142, 04016018. [Google Scholar] [CrossRef]
- Kou, F.; Xu, W.; Yang, H. Short-Term Traffic Flow Forecasting Considering Upstream Traffic Information; Atlantis Press: Amsterdam, The Netherlands, 2018; pp. 560–564. [Google Scholar] [CrossRef] [Green Version]
- Cai, P.; Wang, Y.; Lu, G.; Chen, P.; Ding, C.; Sun, J. A Spatiotemporal Correlative K-Nearest Neighbor Model for Short-Term Traffic Multistep Forecasting. Transp. Res. Part C Emerg. Technol. 2016, 62, 21–34. [Google Scholar] [CrossRef]
- Chomboon, K.; Chujai, P.; Teerarassammee, P.; Kerdprasop, K.; Kerdprasop, N. An Empirical Study of Distance Metrics for K-Nearest Neighbor Algorithm. In Proceedings of the 3rd International Conference on Industrial Application Engineering, Kitakyushu, Japan, 28–31 March 2015; pp. 280–285. [Google Scholar] [CrossRef] [Green Version]
- Lopes, N.; Ribeiro, B. On the Impact of Distance Metrics in Instance-Based Learning Algorithms. In Pattern Recognition and Image Analysis; Paredes, R., Cardoso, J.S., Pardo, X.M., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 48–56. [Google Scholar] [CrossRef]
- Gao, X.; Li, G. A KNN Model Based on Manhattan Distance to Identify the SNARE Proteins. IEEE Access 2020, 8, 112922–112931. [Google Scholar] [CrossRef]
- Mulak, P.; Talhar, N. Analysis of Distance Measures Using K-Nearest Neighbor Algorithm on KDD Dataset. Int. J. Sci. Res. 2015, 4, 2319–7064. [Google Scholar]
- Alkasassbeh, M.; Altarawneh, G.A.; Hassanat, A.B.A. On Enhancing the Performance of Nearest Neighbour Classifiers Using Hassanat Distance Metric. arXiv 2015, arXiv:1501.00687. [Google Scholar]
- Abu Alfeilat, H.A.; Hassanat, A.B.A.; Lasassmeh, O.; Tarawneh, A.S.; Alhasanat, M.B.; Eyal Salman, H.S.; Prasath, V.B.S. Effects of Distance Measure Choice on K-Nearest Neighbor Classifier Performance: A Review. Big Data 2019, 7, 221–248. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, L.-Y.; Huang, M.-W.; Ke, S.-W.; Tsai, C.-F. The Distance Function Effect on K-Nearest Neighbor Classification for Medical Datasets. SpringerPlus 2016, 5, 1304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Habtemichael, F.G.; Cetin, M. Short-Term Traffic Flow Rate Forecasting Based on Identifying Similar Traffic Patterns. Transp. Res. Part C Emerg. Technol. 2016, 66, 61–78. [Google Scholar] [CrossRef]
- Zhang, S.; Cheng, D.; Deng, Z.; Zong, M.; Deng, X. A Novel KNN Algorithm with Data-Driven k Parameter Computation. Pattern Recognit. Lett. 2018, 109, 44–54. [Google Scholar] [CrossRef]
- Lall, U.; Sharma, A. A Nearest Neighbor Bootstrap For Resampling Hydrologic Time Series. Water Resour. Res. 1996, 32, 679–693. [Google Scholar] [CrossRef]
- Ghosh, A.K. On Optimum Choice of k in Nearest Neighbor Classification. Comput. Stat. Data Anal. 2006, 50, 3113–3123. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, S.; Zhao, J.; Zhao, X.; Mo, Y. A New Classification Algorithm Using Mutual Nearest Neighbors. In Proceedings of the 2010 Ninth International Conference on Grid and Cloud Computing, Nanjing, China, 1–5 November 2010; pp. 52–57. [Google Scholar] [CrossRef]
- Smith, B.L.; Demetsky, M.J. Short-Term Traffic Flow Prediction: Neural Network Approach. Transp. Res. Rec. 1994, 1454, 98–104. [Google Scholar]
- Kumar, K.; Parida, M.; Katiyar, V.K. Short Term Traffic Flow Prediction for a Non Urban Highway Using Artificial Neural Network. Procedia Soc. Behav. Sci. 2013, 104, 755–764. [Google Scholar] [CrossRef] [Green Version]
- Zheng, W.; Lee, D.-H.; Shi, Q. Short-Term Freeway Traffic Flow Prediction: Bayesian Combined Neural Network Approach. J. Transp. Eng. 2006, 132, 114–121. [Google Scholar] [CrossRef] [Green Version]
- Çetiner, B.G.; Sari, M.; Borat, O. A Neural Network Based Traffic-Flow Prediction Model. Math. Comput. Appl. 2010, 15, 269–278. [Google Scholar] [CrossRef]
- Jiber, M.; Lamouik, I.; Ali, Y.; Sabri, M.A. Traffic Flow Prediction Using Neural Network. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Sharma, B.; Kumar, S.; Tiwari, P.; Yadav, P.; Nezhurina, M.I. ANN Based Short-Term Traffic Flow Forecasting in Undivided Two Lane Highway. J. Big Data 2018, 5, 48. [Google Scholar] [CrossRef]
- Kashyap, A.A.; Raviraj, S.; Devarakonda, A.; Nayak, S.R.; KV, S.; Bhat, S.J. Traffic Flow Prediction Models—A Review of Deep Learning Techniques. Cogent Eng. 2022, 9, 2010510. [Google Scholar] [CrossRef]
- Karim, A.M.; Abdellah, A.M.; Hamid, S. Long-Term Traffic Flow Forecasting Based on an Artificial Neural Network. Adv. Sci. Technol. Eng. Syst. J. 2019, 4, 323–327. [Google Scholar] [CrossRef] [Green Version]
- Shenfield, A.; Day, D.; Ayesh, A. Intelligent Intrusion Detection Systems Using Artificial Neural Networks. ICT Express 2018, 4, 95–99. [Google Scholar] [CrossRef]
- Ho, F.-S.; Ioannou, P. Traffic Flow Modeling and Control Using Artificial Neural Networks. IEEE Control Syst. Mag. 1996, 16, 16–26. [Google Scholar] [CrossRef]
- Khotanzad, A.; Sadek, N. Multi-Scale High-Speed Network Traffic Prediction Using Combination of Neural Networks. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 2, pp. 1071–1075. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Weight | Wed. | Thu. | Fri. | Sat. | Sun. | Mon. | |
|---|---|---|---|---|---|---|---|
| EWM-A | 0.5579 | 0.5955 | 0.6189 | 0.5280 | 0.5277 | 0.5599 | |
| 0.4421 | 0.4045 | 0.3811 | 0.4720 | 0.4723 | 0.4401 | ||
| EWM-B | 0.4421 | 0.4045 | 0.3811 | 0.4720 | 0.4723 | 0.4401 | |
| 0.5579 | 0.5955 | 0.6189 | 0.5280 | 0.5277 | 0.5599 | ||
| EWM-C | 0.5673 | 0.5974 | 0.5738 | 0.5052 | 0.4954 | 0.5602 | |
| 0.4327 | 0.4026 | 0.4262 | 0.4948 | 0.5046 | 0.4398 |
| Model | 3.27 (Wed.) | 3.28 (Thu.) | 3.29 (Fri.) | 3.30 (Sat.) | 3.31 (Sun.) | 4.1 (Mon.) | Average |
|---|---|---|---|---|---|---|---|
| BP * Elman | 769.8010 794.0899 | 544.7767 511.1533 | 309.5437 262.9230 | 286.7621 273.4558 | 212.2913 211.9528 | 363.5728 319.3155 | 414.4679 395.4817 |
| KNN * Improved KNN | 670.9806 310.5000 | 534.8592 378.8010 | 231.0146 226.3252 | 243.3155 298.1456 | 218.4417 187.6456 | 284.1707 256.7816 | 363.7971 276.3665 |
| KNN + Elman * | 749.3786 | 406.6602 | 251.74272 | 261.9806 | 216.8980 | 274.3980 | 360.1764 |
| EWM-A EWM-B EWM-C | 308.9466 | 372.3883 | 208.5777 | 253.0825 | 179.5485 | 248.2718 | 261.8026 |
| 320.8932 | 398.7524 | 215.8252 | 250.0631 | 181.1650 | 255.8544 | 270.4256 | |
| 307.3204 | 371.4563 | 208.4223 | 253.0146 | 180.6845 | 248.2718 | 261.5283 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, W.; Li, J.; Song, W.; Li, X.; Zhao, Y.; Dong, H.; Wang, Y.; Zhao, Q.; Qi, Y. Entropy-Weight-Method-Based Integrated Models for Short-Term Intersection Traffic Flow Prediction. Entropy 2022, 24, 849. https://doi.org/10.3390/e24070849
Qu W, Li J, Song W, Li X, Zhao Y, Dong H, Wang Y, Zhao Q, Qi Y. Entropy-Weight-Method-Based Integrated Models for Short-Term Intersection Traffic Flow Prediction. Entropy. 2022; 24(7):849. https://doi.org/10.3390/e24070849
Chicago/Turabian StyleQu, Wenrui, Jinhong Li, Wenting Song, Xiaoran Li, Yue Zhao, Hanlin Dong, Yanfei Wang, Qun Zhao, and Yi Qi. 2022. "Entropy-Weight-Method-Based Integrated Models for Short-Term Intersection Traffic Flow Prediction" Entropy 24, no. 7: 849. https://doi.org/10.3390/e24070849