1. Introduction
Recent prospective studies have revealed that over the next 30 years, the expected demographic rise in the world’s population will increase energy demand by 50% [
1]. As a result, and among the different types of fuel cells, PEMFCs are considered to be the most feasible green energy converter, suitable for both stationary and transportation applications [
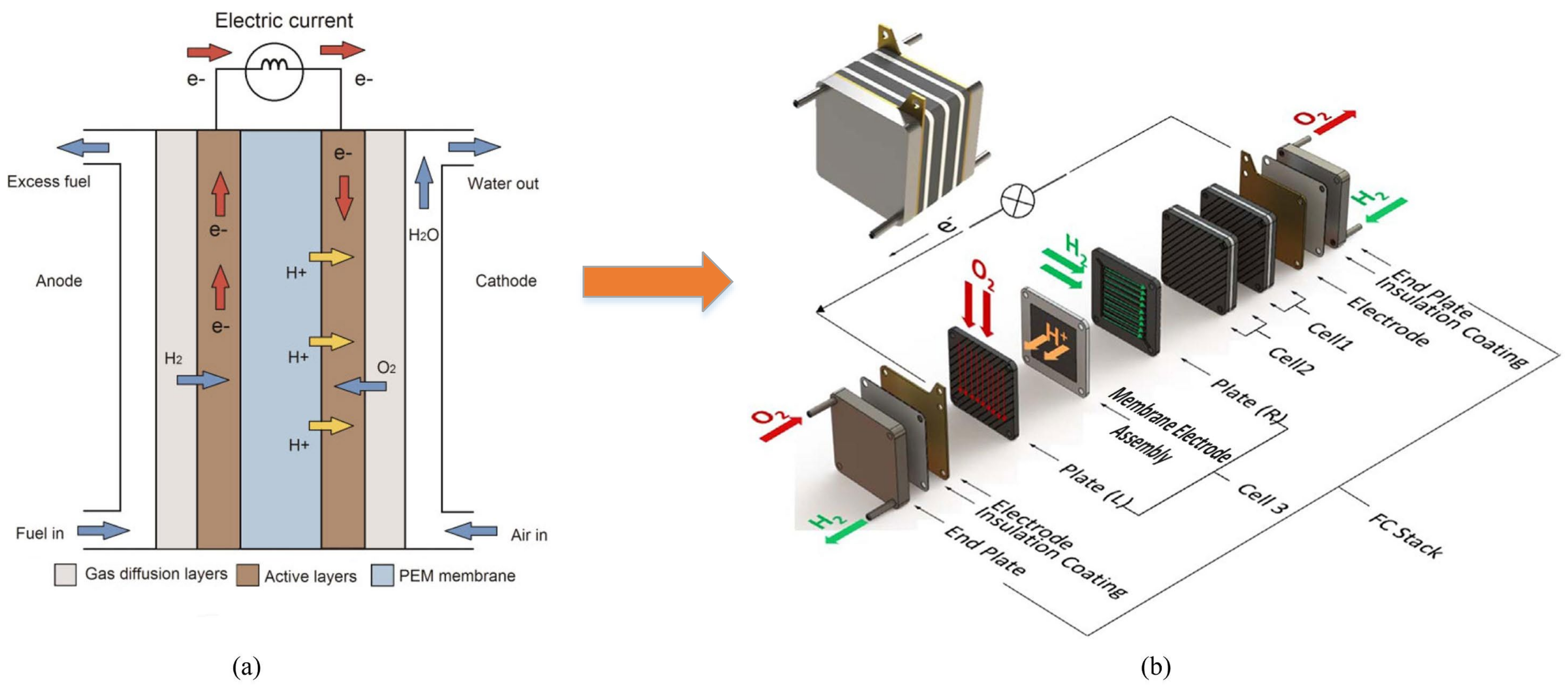
2]. PEMFC appearing on the schematic diagram of
Figure 1a is intended to convert chemical energy into electricity from hydrogen fuel. It consists of an anode, a cathode, and an electrolyte. The electrolyte is a non-conductive material that transmits charges from the cathode to the anode via an external circuit [
3]. Generally, a single PEMFC can be considered a lower voltage and higher current electricity generator that ranges from 0.4 V to 0.9 V and from 0.5 A/cm
2 to 1 A/cm
2, respectively. Therefore, as shown in
Figure 1b, several fuel cells must be stacked to satisfy a specific type of application [
3]. It is very common for PEMFC to be highly sensitive to dynamic and non-stationary external and internal operating conditions, which could reduce its lifespan [
4]. In this context, components material (
Figure 1), gas contamination, and the operating conditions imposed by the load profile are responsible for the system durability. Accordingly, a well-structured prognosis policy is needed to extend the lifetime by incorporating the required CBM tasks [
5].
Indeed, the remaining useful life (RUL) prediction, which is the estimation of the time between the current and the end of life of a system, is a key element for assessing damage propagation and aging [
6,
7]. Two particular types of prognosis can be triggered in this case: the short-term prognosis and the long-term prognosis [
4,
8]. Short-term prognosis is designed to capture local variations with high accuracy, while long-term prognosis aims to give the deterioration trend [
8]. Logically, the prediction of local variations will be more accurate in comparison to the large variation of the trend of the life path. For PEMFCs, prognosis can be modeled through three main strategies, namely model-based, filter-based, and data-based approaches [
9]. Among data-based approaches, DL tools have been widely investigated. According to [
5], the reason for choosing DL tools is motivated by the need to provide a meaningful representation of data patterns originally presented in a very complex feature space (see
Figure 2 from [
5]). In the context of PEMFCs prognosis, the entire deterioration path can be obtained under real experimental conditions. As a result, data will be “
complete” in this case. Additionally, it is common for PEMFCs to be subject to a higher level of dynamic disturbances caused by changing operating conditions leading to more “
complex” and “
drifted” data. If we project these three characteristics (i.e., data is complete, complex, and drifted) onto the flowchart proposed in the systematic guide of [
5] (see
Figure 2 of [
5]), there would be no more optimal solution than DL for such a case, and conventional machine learning will no longer be recommended. Thus, reconstructing an RUL predictive model requires meeting three main criteria: data
availability,
complexity, and
drift. In this context, to remedy learning issues regarding adaptive learning, dynamic programming is highly recommended to strengthen the learning model. Additionally, to overcome data complexity issues resulting from changing operating conditions, DL is also the main recommended path.
Among recently published papers dealing with DL in the field of performance evaluation of PEMFCs including prognosis (i.e., RUL prediction), learning techniques, which have been derived from leading supervised learning tools such as convolutional neural networks (CNN) [
10,
11,
12,
13], long short-term memory (LSTM) [
14,
15,
16], deep belief neural networks (DBNs), and autoencoders (AEs) [
17,
18] have been extensively investigated. CNNs are generally recommended when trying to separate between different data patterns and make sure they offer a quite enhanced representation. However, CNNs’ learning rules as originally proposed lack the element of adaptive learning. Contrariwise, LSTMs and their variants such as gated units are very popular adaptive learning and time series networks [
19]. Unlike CNNs, their robustness resembled each other in considering the mathematical correlation between samples behaving similarly. At the same time, adaptive learning baselines intend to ignore (i.e., forgetting) unwanted learning samples depending on specific parameters known as gates. In the meanwhile, DBNs are totally dependent on the robustness of feature extractions. In this case, unsupervised generative models, such as autoencoders and even adversarial networks, could be involved in fine-tuning DBNs for supervised learning.
Generally speaking, the above-discussed learning models are designed to achieve real-time performance evaluation. More specifically for RUL prediction models, they have been designed either for a single step-ahead or multistep-ahead prediction. These training scenarios have been realized under previously discussed prognosis types including either a long-term or a short-term prognosis. Depending on the type of training rules, these models seemed to be successful regressors in terms of dynamic programming, approximation, or generalization. In this context, the main open challenge, in this case, is to provide a better representation than these DL models to the feature spaces. This is conducted to ensure exploring more meaningful patterns in data, which logically yields better performances.
In this context, the contributions of this paper are threefold:
In an attempt to address adaptive learning, the LSTM learning rules that seem to be a perfect choice in this case are selected to train the DL model;
To explore new representations learning features, the LSTM network has been exposed to a recurrent expansion process with multiple repeats. This process will not make the LSTM learn from input representation only, but it will also make it able to learn from feature maps and estimated targets. This makes a total of three sources of information, which are repeatedly merged into several LSTMs, leading to a deeper representation than ordinary LSTMs;
To evaluate the REDL model, the well-known PHM 2014 data challenge dataset has been employed under a long-term prognosis based on a single step-ahead prediction.
This paper is organized as follows:
Section 2 is dedicated to the problem description. In
Section 3, we introduce the REDL model and its learning rules.
Section 4 is devoted to experiments and results discussion.
Section 5 concludes this study with some remarks.
2. Problem Description
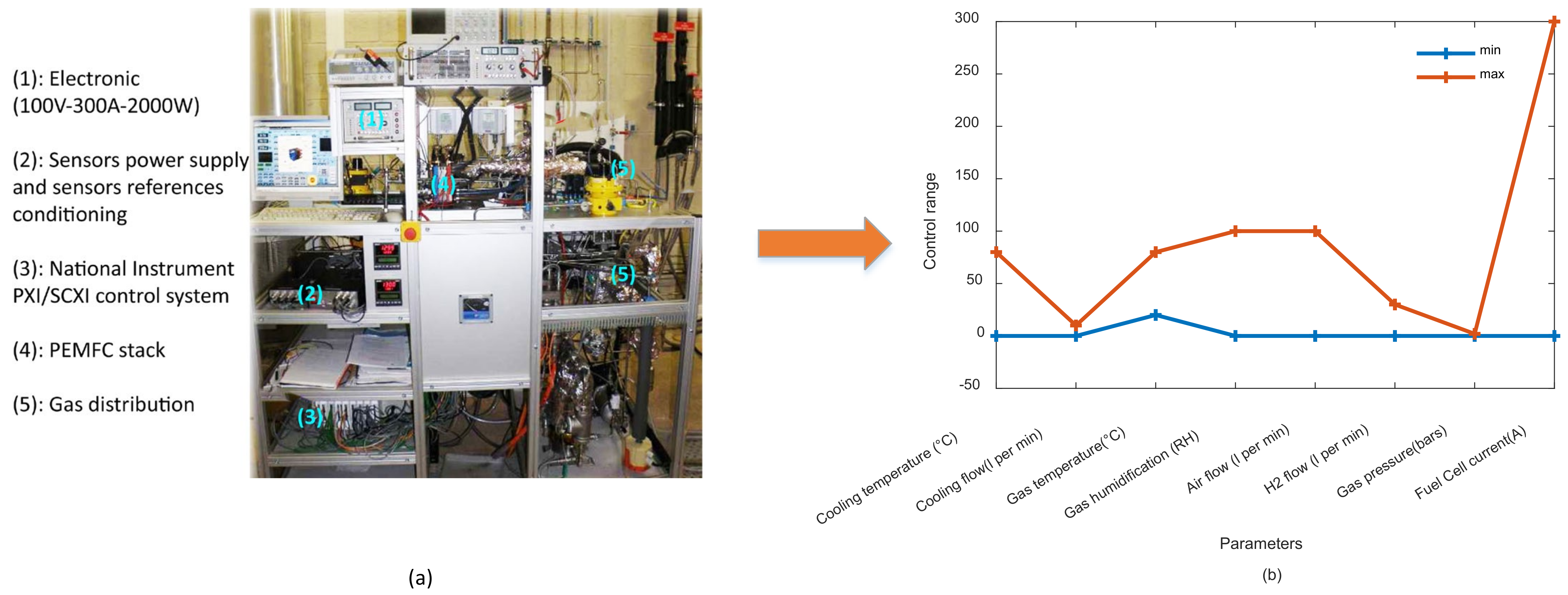
Data investigated in this study is provided by the fuel cell laboratory (FCLAB FR CNRS 3539, France,
http://eng.fclab.fr/ accessed on 7 June 2022), where it was first introduced at the IEEE PHM data challenge in 2014 [
20]. The FCLAB test bench allows performing experimental studies for both ordinary and accelerated degradations, whereas it also allows access to monitoring parameters (e.g., power loads, temperatures, hydrogen and air stoichiometry rates, etc.) and modifying operating conditions. The test bench in
Figure 2a is mainly used to study FCs with a maximum power of 1 kW, while operating conditions are depicted in
Figure 2b. Gas humidification and the transport of air and hydrogen are ensured by specific independent boilers placed upstream of the FC stack, where only the air boiler is subject to heat control to achieve the desired relative humidity. The hydrogen boiler has an ambient temperature controller, whilst the stack temperature and power supply are controlled by cooling water and a TDI Dynaload active load, respectively. The studied PEMFC stack contains five cells with an active surface of 100 cm
2. The PEMFC is constructed with commercial membranes, diffusion layers, and machined flux distribution plates. The PEMFC can reach a nominal current density of the cells equal to 0.70 A/cm
2 while the maximum current density is 1 A/cm
2.
During this experiment, two long-term durability tests are carried out. The first experiment (FC1) is mainly dedicated to the stationary regime where the operating conditions are considered constant and stable during the whole experiment. The second one (FC2) is mainly focused on the non-stationary regime, where the operating conditions could be subject to a wide range of disturbances. Two types of data were collected, in particular, polarization curves and aging data. Polarization curves are intended to be used for state of health assessment while aging data are used for RUL prediction. In this case, we are interested in aging data as our main goal is to predict RUL.
For FC1 experiment, a complete characterization was achieved every week at times = 0; 48; 185; 348; 515; 658; 823; and 991 h where stationary conditions of a current of 70 A were imposed. First, electrochemical impedance spectroscopy (EIS) was performed only at 0.70 A/cm2 for evaluating the FC state before measuring the polarization. After that, the polarization curve was carried out under a current ramp from 0 A/cm2 to 1 A/cm2 for 1000 s. The air and hydrogen flows were reduced to a current of 20 A where they remained constant at this stage. Finally, the EIS as performed again for constant currents of 0.70 A/cm2, 0.45 A/cm2, and 0.20 A/cm2, respectively, with a stabilization period of 15 min. For the FC2 experiment, the current was subject to dynamic solicitations with a ripple of 70 A, oscillations of 7 A, and a frequency of 5 kHz. Weekly characterization for first polarization curve and EIS, respectively, at times t = 0; 35; 182; 343; 515; 666; 830; and 1016 h were performed.
The collected aging dataset features are defined as follows: Time Aging (time (h)), Single cells and stack voltage (V) (U1–U5 and Utot), Current (A) and current density (A/cm2) (I; J), Inlet and Outlet temperatures of H2 (°C) (TinH2; ToutH2), Inlet and Outlet temperatures of Air (°C) (TinAIR; ToutAIR), Inlet and Outlet temperature of cooling Water (°C) (TinWAT; ToutWAT), Inlet and Outlet Pressure of H2 (mbara) (PinH2; PoutH2), Inlet and Outlet Pressure of Air (mbara) (PinAIR; PoutAIR), Inlet and Outlet flow rate of H2 (l/mn) (DinH2; DoutH2), Inlet and Outlet flow rate of Air (l/mn) (DinAIR; DoutAIR), Flow rate of cooling water (l/mn) (DWAT), Inlet Hygrometry (Air) (%) (HrAIRFC). In this case, when considering aging data for RUL prediction, the PHM 2014 main goal was to use the dataset generated from FC1 to reconstruct the data-driven model. After that, the model will be tested on a portion of FC2 experiment, whereas a final step of validation will be performed for long-term predictions using predicted samples themselves.
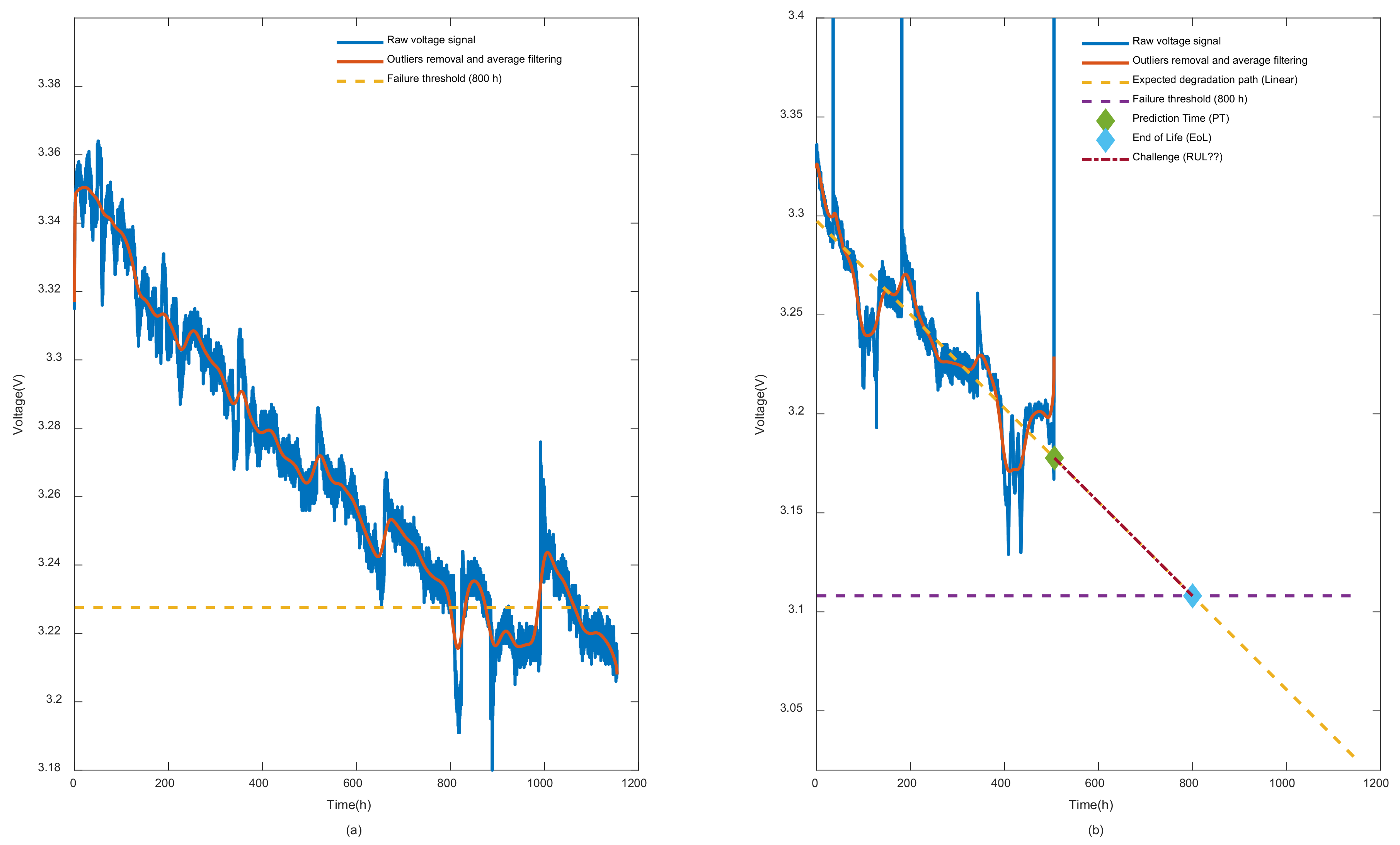
In our work, among a set of previously stated features, the fuel cell voltage, which is a commonly used static health indicator at the cell/battery level, was selected to conduct our time series prognosis experiments. In this context, and since data collection with sensors is subject to outliers, a process of filtration and outliers removal is mandatory. In this case,
Figure 3 is introduced to give a better explanation of the RUL prediction problem. In
Figure 3a, which represents FC1 case study, the entire PEMFC deterioration patterns are given while only 500 h are revealed for FC2. By comparing FC2 and FC1 voltage behavior, it seems that FC2 is subject to outliers and dynamic disturbance more than FC1. Therefore, a second filtered version of the signal is necessary. In this case, an average window filtering and outlier removers are involved to produce the clean version of the signals as appeared in the figure. In our study, we have set the failure threshold at 800 h as a default value, which reflects about 10% of the voltage drop. It should be mentioned that identifying the failure threshold for PEMFC is still an open question. However, in this situation, the 10% voltage drop is inspired by the United States Department of Energy policy for vehicle applications [
1]. In FC2, deterioration patterns from 500 to the failure threshold represent the main challenge of long-term prognosis in this case.
It should be mentioned that the linear degradation path presented in
Figure 3b is not obtained by time series predictions based on nonlinear degradation signals. In fact, the time record is used as the inputs of the linear regression model while the filtered signal is the output. This should logically not be the standard way for nonlinear prediction as in our case because time has nothing to do with the cell deterioration. It is, in fact, the operating conditions that have a real effect on the cell as time evolves. However, in our case, the main goal was to create a reference to our predictions so that at least we could assess how far the predictions approximately were away from the degradation trend, especially in the challenge part where the actual data (i.e., truth labels) were not revealed.
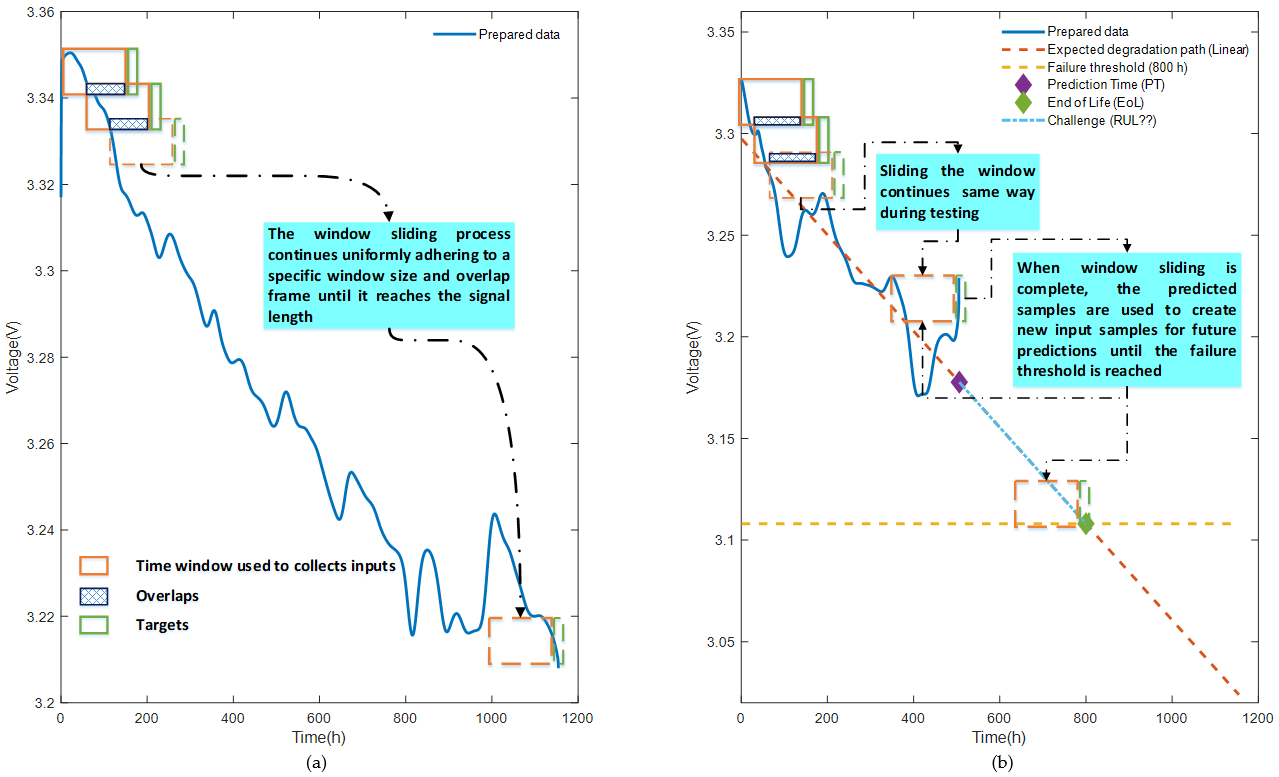
Accordingly, FC1 data were used to train the prediction model for single-step ahead prediction. While doing so, the FC2 data was used to test the model accuracy. Finally, the challenge part was the prediction using predicted samples from FC2 as an input to the model. To be able to make this work on a time series analysis, a sliding window with a size of 50 samples and an overlap of 30 samples was adopted in this work.
Figure 4 clearly indicates the process of data inputs and targets collection for the training (
Figure 4a), testing, and challenge parts (
Figure 4b).
A very interesting point to be taken into account is that in such particular time series analysis, min–max normalization will no longer be recommended. Especially under single step ahead prediction, samples actual meaning could be easily distorted. Therefore, normalization based on the mean and variance of the entire time frame at each sliding is important and has more significance. We introduce the formula one as the main scaling method recommended in this case.
and
are original and normalized inputs of a single time frame, respectively, while
and
refer to mean and standard deviation of the entire training, testing, or challenge dataset.
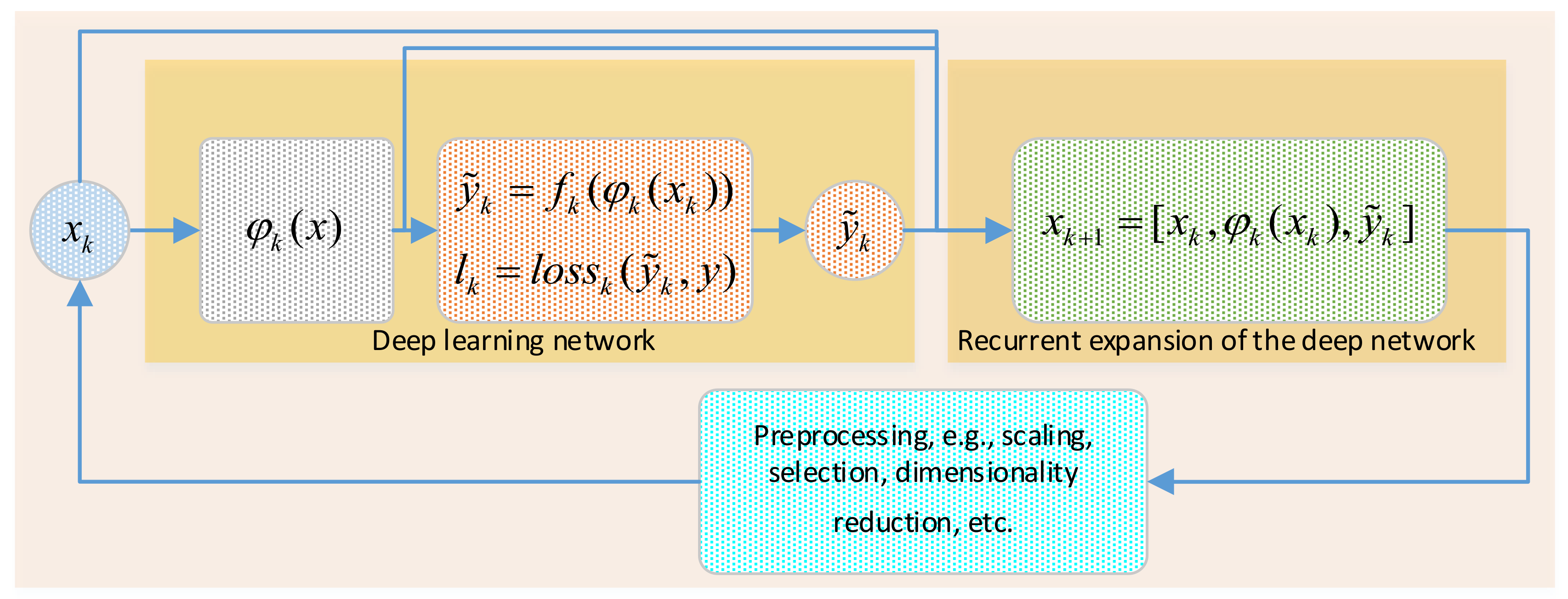
3. Recurrent Expansion of Deep Learning
This section is introduced to describe the proposed REDL algorithm and its main learning rules.
Figure 5 indicates that training a deep network with REDL rules should be performed in accordance with the following steps.
Step 1: A deep network must be used to train an approximation function
in (2) with deep representations
learned from inputs
according to a specific loss function
in (3). In this case,
could be any sort of feature mapping resulting from training the deep network such as LSTM layers, convolutional mappings, encoded layers of any type of autoencoder, hidden layers from a deep belief network, etc.
Step 2: The entire deep network including
,, and estimated targets
will be fused in a sort of concatenation as in (4) to train the same type of model repeatedly. In this case,
represents the new inputs to the next training network.
denotes the number of rounds used to repeat the recurrent expansion process.
Step 3: It should be mentioned that the combination in Equation (4) will be extremely huge due to the large layers of the deep network. Moreover, feature maps and estimated targets will no longer follow the same normalization procedures of inputs. Hence, the dimensionality reduction and renormalization of the entire collection is a very important task in this case.
Step 4: Stopping criteria, in this case, will be evaluated by different quality approximation metrics depending on the type of the application (i.e., classification or regression). Moreover, the loss function behaviors such as convergence speed and stabilization can be also used to monitor the process of multiple repeat training.
Since the RUL prediction problems are regression ones, well-known quality measuring metrics such as root mean squared error (
RMSE), mean absolute error (
MAE), and mean absolute percentage error (
MAPE) expressed by Formulas (5)–(7), are used in this work. Additionally, for the loss function
, we use also RMSE as the main approximation error. As a result, the area under loss curve (
AULC) is adopted to indicate the performance of the loss function (8).
in this case refers to the number of training, testing, or challenge samples.
designates the maximum number of epochs.
Another interesting scoring metric suggested initially by the PHM 2014 benchmark developers is also proposed. The score functions
in Equation (9) are used to measure the precision of the prediction model by considering early and late predictions’ effects on maintenance planning. Early predictions have an impact on consuming CBM resources, while later predictions could result in many damages including financial and human losses.
is a percentage error,
is a constant, and
is a penalization parameter given differently for each type of prediction (i.e.,
= 5 for late predictions and
= 20 for early ones).
Based on our aforementioned remark regarding the alteration of PEMFC owing to dynamism in operating conditions, the single-layer LSTM was adopted as the main deep architecture to train the REDL model. Accordingly, LSTM layers will represent and its estimated targetsin each round will be expressed by .
For a better understanding of the followed training procedures, the pseudo-code of Algorithm 1 gives more explanations about REDL training rules.
| Algorithm 1. REDL algorithm |
| Inputs: |
| Outputs:
|
| For |
| % Train the deep network and evaluate the loss function |
|
|
| % Rebuild the new inputs |
|
| % Evaluate training metrics |
|
|
|
|
|
| End (For) |
4. Results and Discussion
Prognosis model reconstruction experiments were carried out in MATLAB r2018b environment while computational resources involved a Personal Computer (PC) with an i7 microprocessor, 16 GB of RAM memory, and a 12 MB of cache RAM. A single layer LSTM network with 16 neurons, , , ADAM optimizer, , , and was trained according to REDL rules. Since our goal, in this case, was to study the effect of REDL rules in improving DL representation for RUL prediction of PEMFC, these parameters were manually tuned according to expert decisions and then fixed for the entire procedure. Additionally, a random seed of learning weights generation was fixed to a single source to make sure that expressed variations in outcomes only resulted from REDL rules and not from other sources. In this context, the LSTM as trained for rounds with REDL rules.
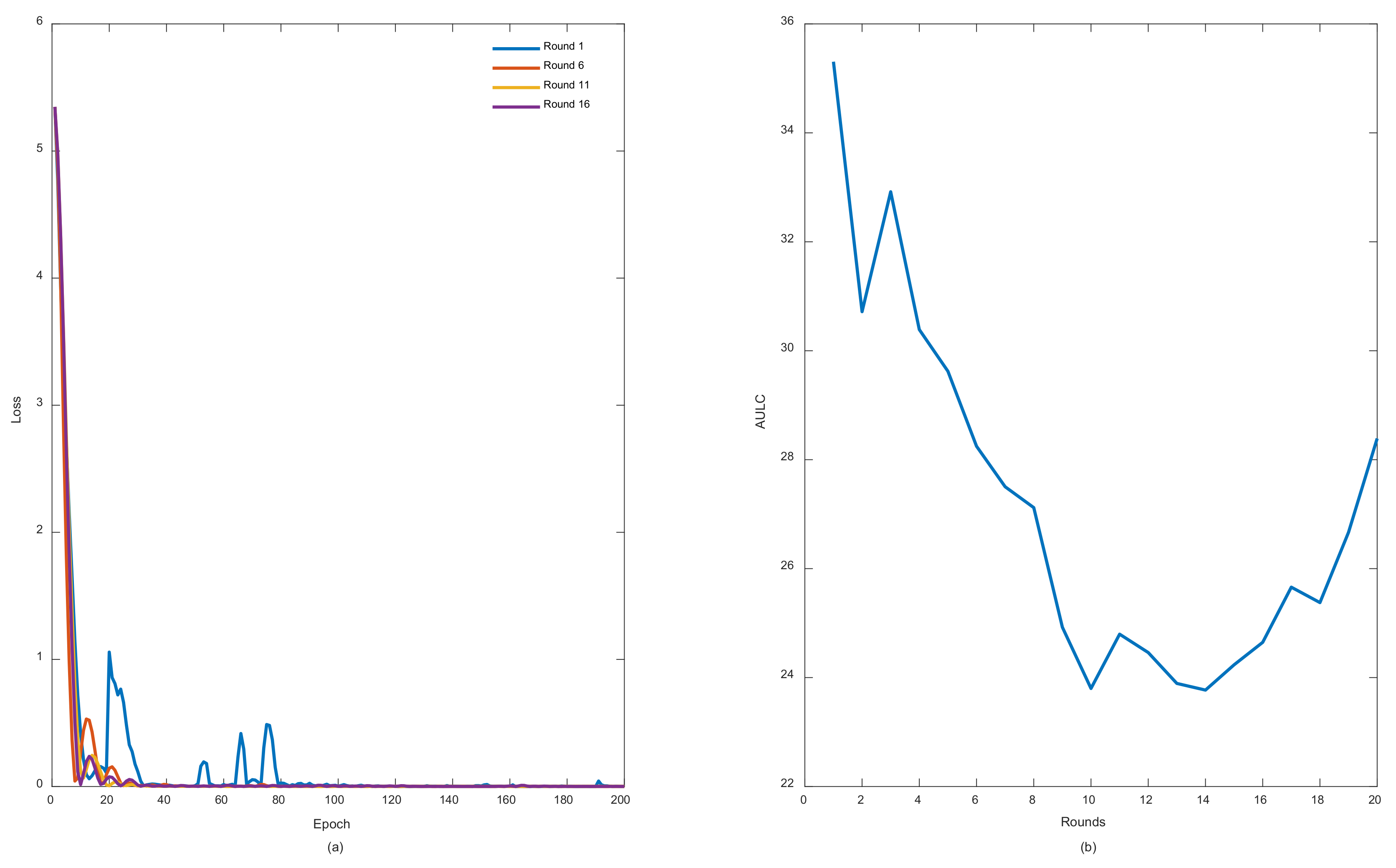
To evaluate our proposed model, all previously discussed metrics for the entire three subsets including, training, testing, and challenge subsets were recorded in each round. Exceptions were made for the loss function curves and AULC metrics, which were basically related to training only.
Figure 6a elucidates some loss curves during those rounds, while
Figure 6b illustrates the AULC parameter.
Figure 6a shows that in each round from rounds 1 to 16, the loss curves demonstrate less fluctuations, better convergence, and stabilization performances.
Figure 6b also reveals the same behavior by highlighting an obvious AULC reduction after each round until a certain threshold. In this case, it can be stated that REDL helps in discovering new representations from each previously trained model. These representations are considered very important until they start to vanish. At this point, unrolling the model several times becomes meaningless to the learning model.
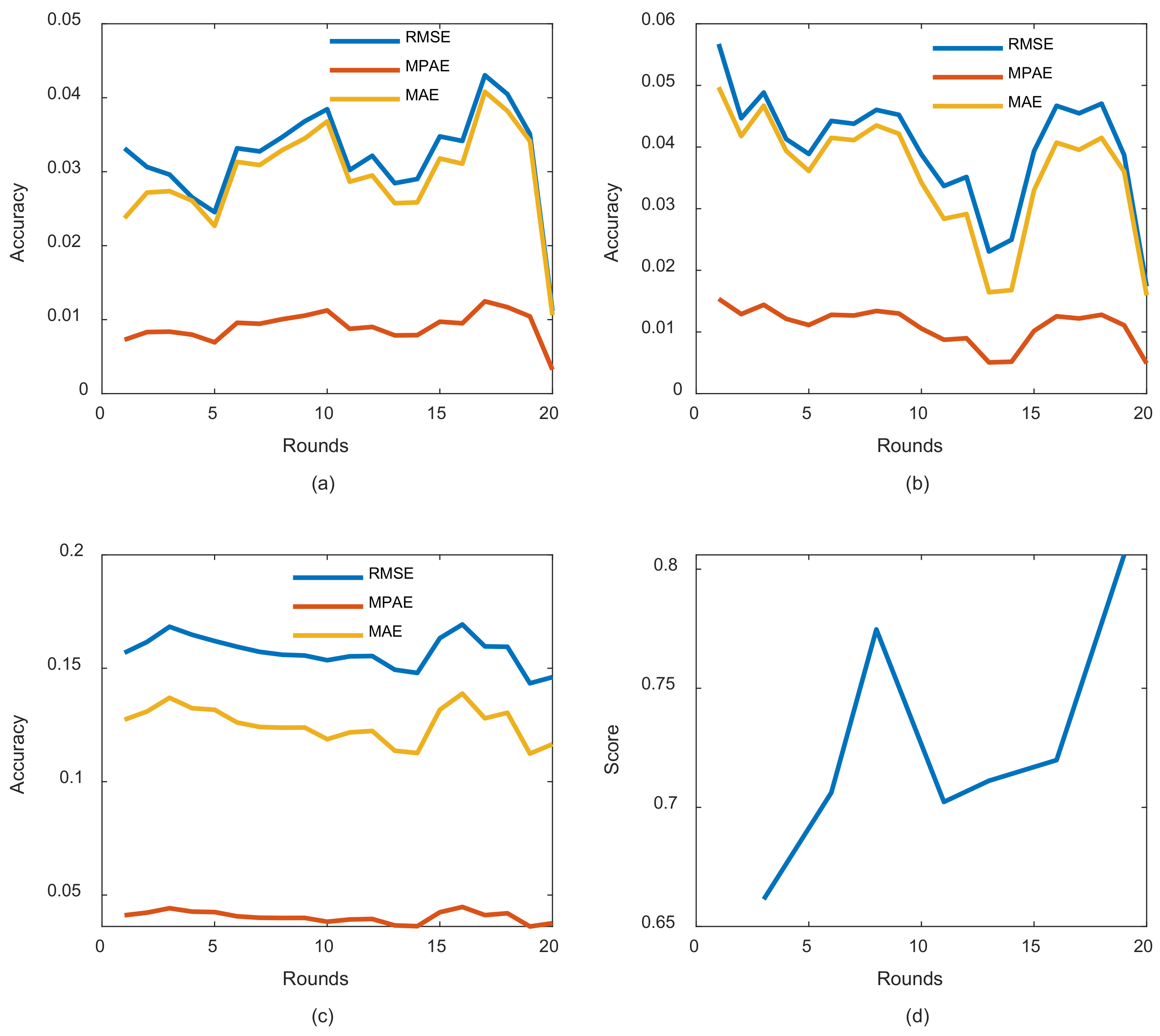
The curves of
Figure 7 are also devoted to addressing other metrics in the entire model training and evaluation phases. We can observe significant enhancements in each training round. Exceptions also are made for some rounds, such as in rounds 17 and 18 (from
Figure 7a–c). The same previous explanation associated with
Figure 6 can be applied here to justify such a phenomenon. Concerning
Figure 7d related to the challenge part, the model expresses great performances, which are most important in this case because the main goal is to achieve a long-term prognosis that is as accurate as possible.
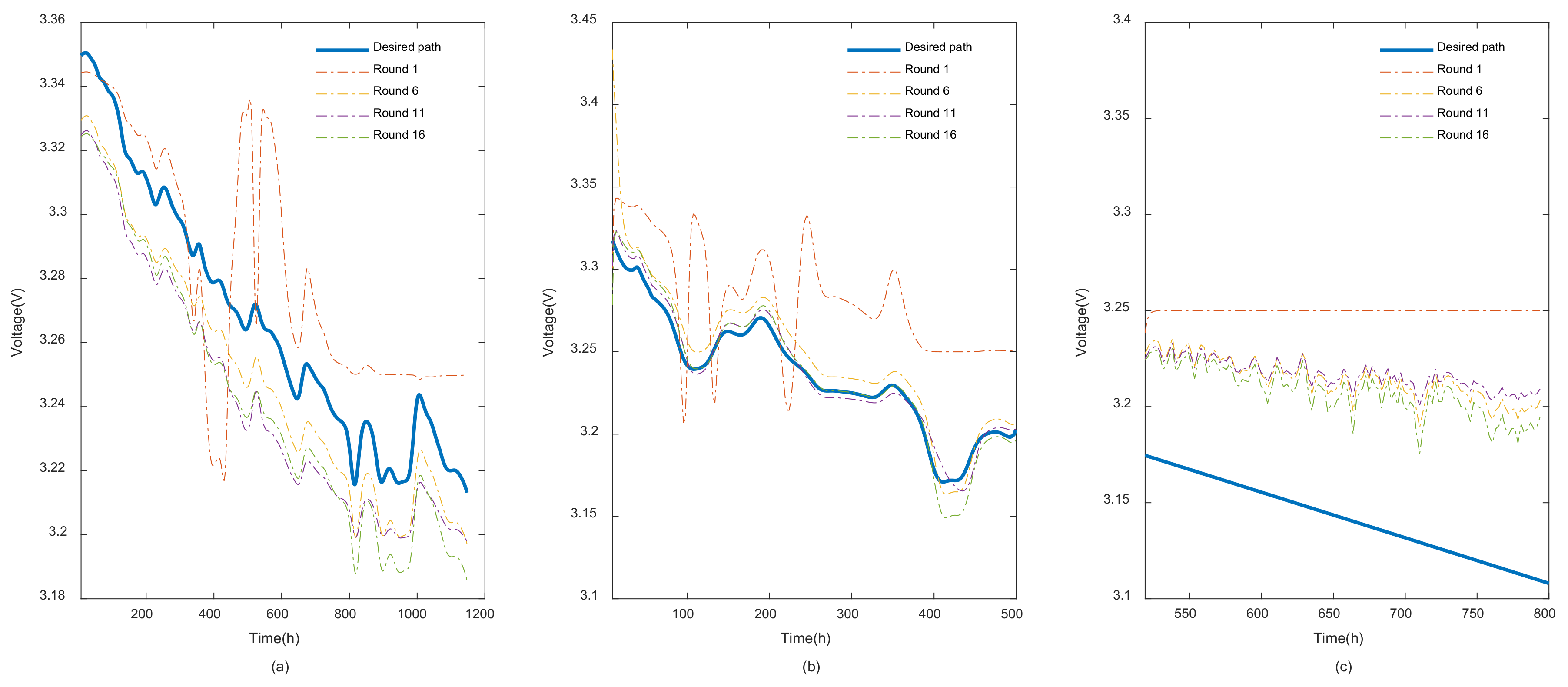
When it comes to prediction illustrations, REDL curves in different rounds are showcased in
Figure 8. It also explains the same previous conclusions where the model in each round clearly reflects a better curve fit. In this case, the proposed score function can be applied as the best way to evaluate the precision of the predictions.
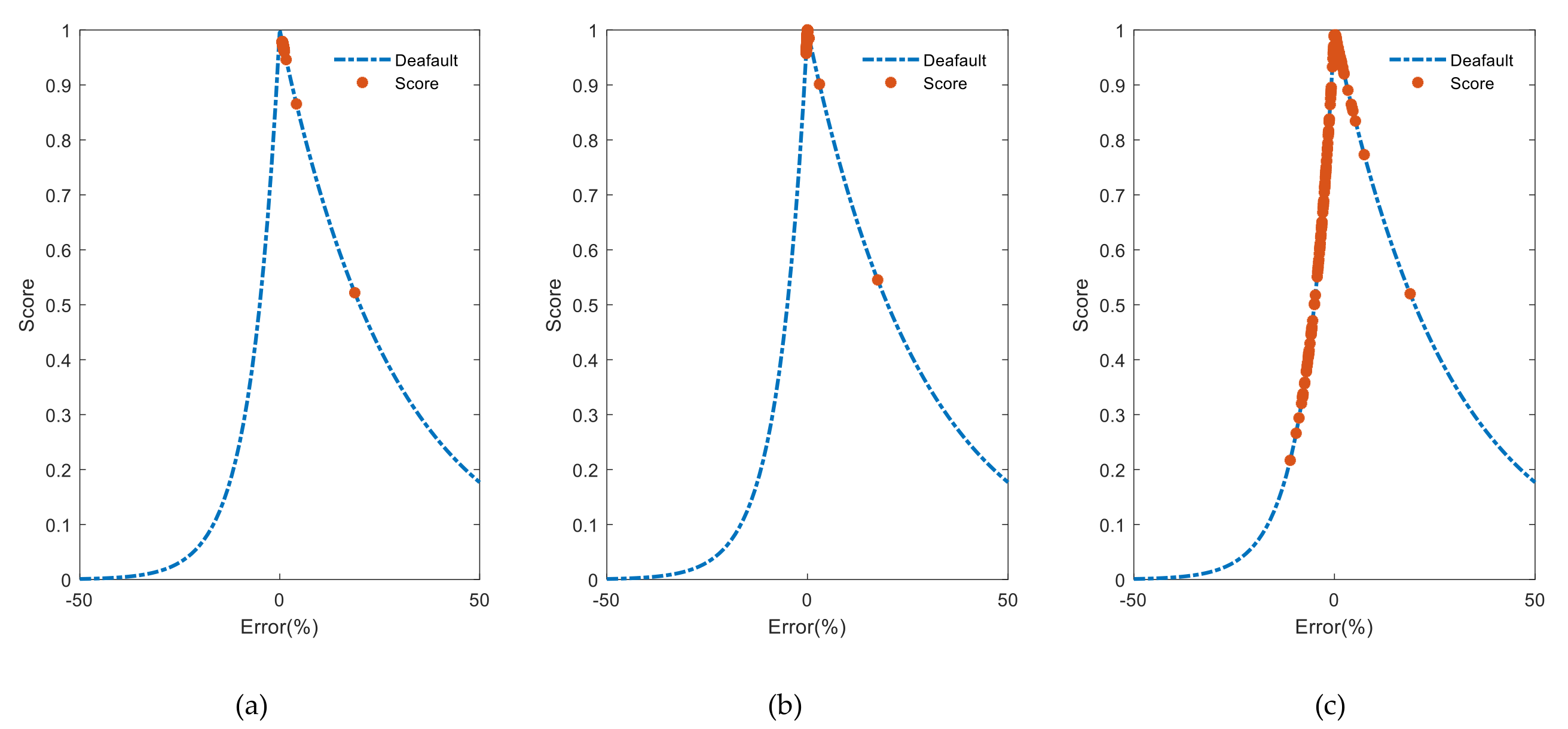
Figure 9 depicts score values distribution according to the percentage error at the last round. During training and testing phase (
Figure 9a,b), the model discloses a high precision when it approaches maximum value one. Moreover, we observe in this case a sort of calibration between early (i.e.,
) and late predictions (i.e.,
). Additionally, according to
Table 1, the long-term predictions (
Figure 9c) are late predictions with a lower precision than the testing phase with about 30%.
Table 1 addresses all obtained results at different phases of model training and the evaluation as well. It is provided that the higher performances of the model are obtained at the last rounds of each phase. Despite the difficulty of obtaining a convincing explanation, it can be asserted that the new training sources including feature maps, and estimated targets from different models have an important role in representation learning compared to a single source of inputs.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}