2.1. Statement of Research
The functional purpose of typical modern information technology of computational analysis of speech patterns is realized by comparing the parameterized representation of the studied language unit and its corresponding etalon in a certain parametric space. The main source of uncertainty in the comparison process is the biological origin of the speech signal and its distortion during transmission and processing. However, the acoustic variability of phonation of language units (primarily, phonemes), due to the existence of dialects, is relatively stable. Based on this fact, we assume a simultaneous comparison of the studied pattern of the phonogram with the pronounced phoneme
with each element
of the set of etalons
, where
is the index of the etalon that characterizes the corresponding dialect of the phoneme
, where
is the capacity of the phonetic alphabet and
is the capacity of the set of recognized dialects for the phoneme
. Then, if the distance
,
, between the studied pattern
and at least one of the elements
of the cluster of the
-th phoneme does not exceed the specified threshold value
then we can recognize the pattern
as the phoneme
. Such a process of recognizing language units will be objective (in particular, insensitive to the dialects of phonation of language units), as the clusters
for the phonetic alphabet
are representatively defined. Depending on the value of the threshold
, the result of the analysis of the studied pattern
according to Rule (1) will be: its recognition as one of the phonemes:
; its identification with several phonemes:
,
,
; or its recognition as marginal regarding the studied phonetic alphabet:
. To simplify the calculations, we convert Rule (1) into the form
where in the process of recognizing the pattern
within the cluster
one distance
from it to the center of the cluster
is calculated, the coordinates of which determine the dialect-averaged phoneme etalon
.
Based on Rule (2), we define the procedure of computational phonetic analysis of speech as a comparison of empirical (spoken by the person) and etalon sets of equal capacity, the pairwise elements of which generalize the corresponding phonemes of the studied language both on the speaker’s side and on the side of the etalon phonetic collection .
2.2. Entropy-Argumentative Concept of Computational Phonetic Analysis of Speech Taking into Account Dialect and Individuality of Phonation
Based on the provisions of information theory, we argue the solution rule (2) in the context of the relative entropy functional [
35,
36,
37] (3):
where
is the selective probability distribution of the studied (empirical) speech signal
relative to the etalon probability distribution
,
. Assume that the distribution law
is normal:
, where
is a sample matrix of autocorrelation of the speech signal
of dimension
. Consider this in Expression (3):
, where
is the operation of finding a trace of the matrix
. If we assume that the studied speech signal is normalized to its entropy, then the last expression can be further simplified to the form
We present Function (3) in frequency space as the optimal solving statistics [
35]. For one sample of the studied speech signal, we obtain (4):
where
is the discrete frequency value for the analyzed sample of the speech signal,
is the upper limit value of the speech signal frequency equal to half of its sampling frequency, and
and
are the vectors of linear autoregression coefficients of order
for etalon signal
and empirical signal
, respectively. The expression in the numerator of (4) is an amplitude-frequency characteristic of the bleaching filter tuned to highlight the features of the
-th phoneme
,
.
Expressions (2) and (4) allow us to calculate quantitative characteristics, based on which it is possible to reasonably decide whether the studied pattern
belongs to the cluster
of the corresponding phoneme
. It is possible to vary the errors of this recognition process by changing the value of the threshold
. Given the Gaussian approximation of the speech signal, the probability of error of the first kind
for the process of phoneme recognition taking into account the dialects of the studied language is proposed to be defined in terms of
-criterion with
degrees of freedom:
where
is the probability of a random event,
.
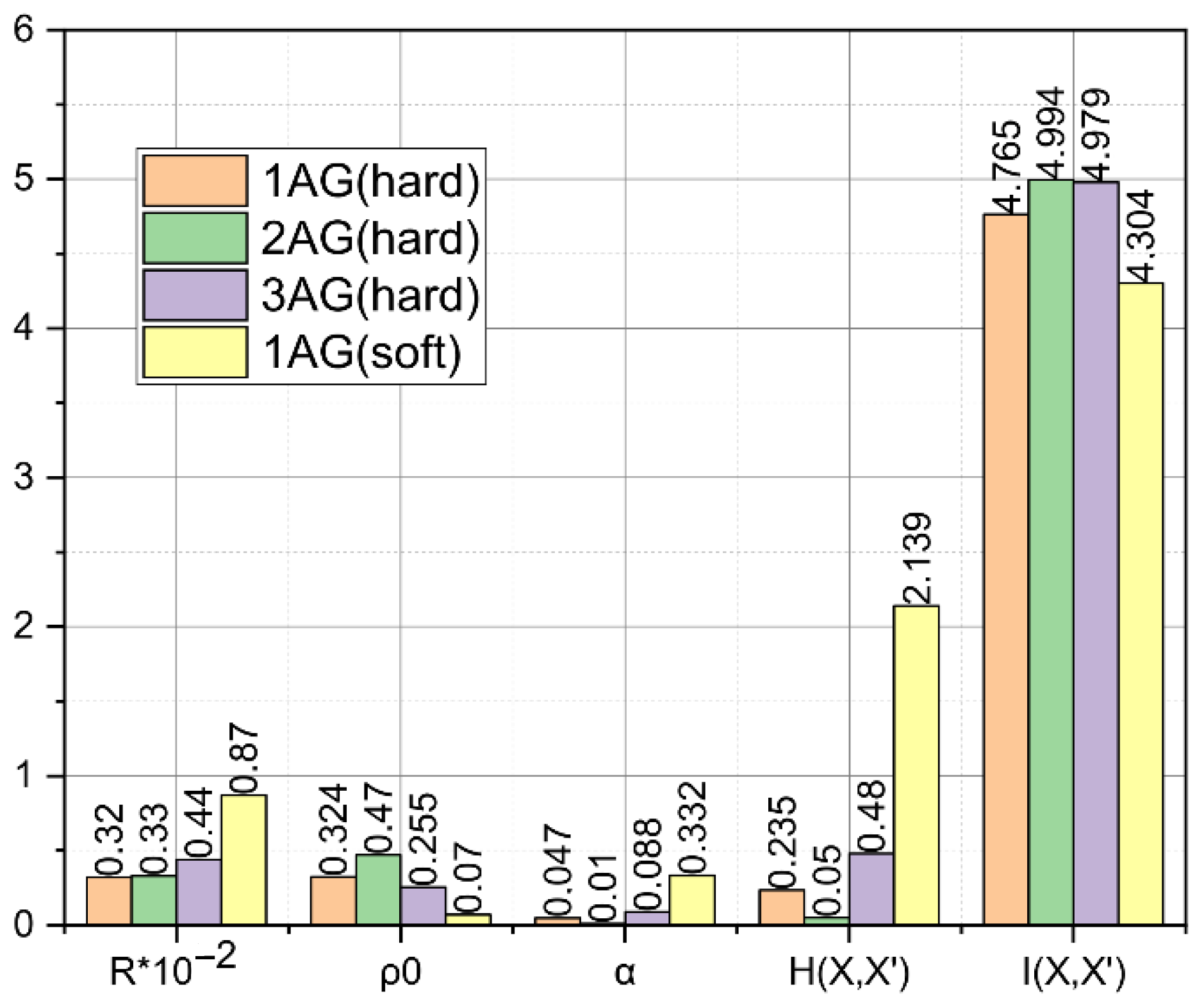
In the general case, the value of the constant is calculated by the expression , where is the order of the bleaching filter, and is a parameter whose value depends on the number of stationary intervals allocated in the studied speech signal . The value of error determined by Expression (5) is inversely proportional to the value of the threshold . For example, for a given value of at ms, kHz, , we obtain and, accordingly, . Using the -distribution tables for the significance level , we find the value of the quantile , using which we calculate the value of the threshold : .
The error of the second kind
in the context of the task of computational phonetic analysis of speech when taking into account dialects represents the probability of the confusion of phonemes
and
,
, the centers of clusters
and
of which are close enough in the parametric space
. Therefore, the value of error
is inversely proportional to the value of distance
. Analysis of the results of a statistically representative number of experiments showed that the minimum value of
the phonetic alphabets of the English language
is in the range
. Accordingly, in analogy with (5), we formalize the expression for calculating the error of the second kind
of the phoneme recognition process taking into account the dialects of the studied language:
Summarizing the considerations embodied in Expressions (5) and (6), for practical use we choose the value of the threshold
in the decision rule (2) based on the expression
The value of the threshold , calculated by Expression (7), provides a balance between the values of errors of the first and second kind of the process of phoneme recognition from the phonetic alphabet , taking into account the dialects of the studied language and the variability of the phonation process. However, the question of the influence of individual features of speakers’ articulation on the result of phonetic analysis of speech requires more detailed analytical formalization.
In the context of the provisions of information theory, we consider the speaker as a source of discrete messages , defined on the set of etalons of language units . Such a source can be comprehensively characterized by the amount of information per language unit generated by it.
If we ignore the influence of individual features of the speaker’s articulatory apparatus on the phonation process and assume that the speech message is transmitted in the absence of acoustic ambient noise, the required amount of information is defined as Shannon entropy for a discrete message source [
35]:
If we mention the normalization , then, considering the equally probable appearance of language units : , we obtain a simplified form of Expression (8): . However, in real conditions, it is impossible to ignore articulatory conditioned variability of phonation. The speech signal at the output of the articulatory tract of the speaker may differ significantly from the etalon : .
This axiom is true even for individual phonemes, not to mention more massive language units. Under such conditions, an adequate mathematical model of a discrete source of speech messages should be created based on phonemes defined by Expression (5), clearly clustered in the parametric space:
,
, and taking into account the probability of an abstract,
R+1-th, language unit, which includes cases of the unreliable recognition of a signal
:
. We summarize these considerations for the decision rule (2):
where
is the conditional probability of recognizing the
r-th phoneme, provided that the variability of its phonation introduced by the speaker is ignored.
Note that Expression (8) characterizes a discrete source of speech messages without taking into account the disturbing effect of the channel of their distribution on the final result of phonation. Consider this information using as a basic expression [
35]:
where
is a specimen of the phonation of the etalon
of the phoneme
,
is a specimen of the phonation of this phoneme by the speaker (empirical specimen), and
is a posteriori entropy, which characterizes the scattering of useful information of a phonation process due to disturbing effects in its distribution channel. Taking into account Expression (9), we formulate the equivalent representation of Expression (10):
Based on Expression (11), we can say that the a posteriori entropy of information scattering in the phonation of the speech message
is in direct proportion to the entropy of the discrete speech message source (8):
Based on Expression (12), we can say that with an equally probable distribution of phonemes in the phonetic alphabet of the speaker, the upper limit of scattering of useful information in the phonation process can be described by the expression
The obtained result correlates with the known Fano inequality [
38] for arbitrary solution rules:
The last statement can be proved empirically by comparing the calculated values of the right-hand sides of Expressions (13) and (14) for the experimental data for and .
Thus, the decision rule (2), the decision statistic (4) and Expressions (7)–(9) together form the desired concept of the process of computational phonetic analysis of speech, taking into account dialects and the specifics of phonation introduced by the speaker. The central element of the concept is the matrix of information mismatch of dimensions . The data from the matrix are the basis for calculating the threshold using Expression (7). With a known value of based on Expressions (2) and (5), the procedure of segmentation of the phonetic alphabet into a set of phonemes, which with probability are reliably recognized despite the above-described disturbing factors, and another set of phonemes, which with probability are not reliably recognized. A significant factor for such segmentation is the probability of error of the first kind, which is calculated by Expression (5). The probability of error of the second kind (6) in this procedure is taken into account indirectly as a limitation in determining the threshold by Expression (7). The use of Expressions (9) and (10) allows for clarifying the result of the segmentation procedure, taking into account the variability of the phonation of the studied language units caused by the individual features of the articulation of a particular speaker. Note that although the presented concept was formulated based on phonemes, the provisions underlying it are consistent and for the analysis of speech about the content of such language units as morphemes and lexemes. Based on the proposed concept (8)–(10), Rule (11) allows us to estimate the error of the first kind (5) and the personalized entropy of the phonetic dictionary (8) as a result of the analysis of empirical data, the sample size of which is . The statistically representative volume in the study of the phonetic alphabet of elements by Rule (11) as a result of analysis of phonograms of speech signals with a sampling frequency of 16 kHz is achieved with a censored duration.
2.3. Entropy-Argumentative Concept of Detection and Correction of Errors of Computational Phonetic Analysis of Speech
Let
,
,
be a set of independent classified samples of type
with a capacity
of
Gaussian distributions
with zero mathematical expectation and unknown autocorrelation matrix
of dimension
, where
is the identifier of the cycle of observations of the
-th distribution,
is the transposition operation,
is the mathematical expectation of the sample of sets
. Denote by
a sample of the form
with capacity
for the studied signal with an unknown distribution
. The task of recognizing the signal
involves
-alternative testing of statistical hypotheses
regarding the distribution law of this signal:
Let
, i.e., two competing hypotheses,
and
, are tested for a priori unknown autocorrelation matrices
and
. The verification will be performed using the asymptotic minimax criterion of the likelihood ratio [
35,
36,
37] based on data from a sample
,
. Under such conditions, the hypothesis
will be considered true if the condition
is satisfied, where
is the plausibility function of the signal
provided that hypothesis
is confirmed, and
is the plausibility function of the signal
.
Using the known computational algorithm [
38] under the condition of independence of observations
, we write a system of equations of the form
where
is the determinant of the matrix
, and
is the estimate of the maximum likelihood for the matrix
determined on the sample
,
. We describe based on Rxpression (17) the fact that the upper limits
are reached at
:
where
,
.
Similarly, we obtain the expression for determining the upper limits for
:
where
, and
is the estimate of the maximum likelihood for the matrix
determined on the combined sample
with capacity
.
Substitute Expressions (18) and (19) into Expression (16) and obtain the condition under which the hypothesis
will be considered correct:
where
is the value of the relative entropy functional between two hypothetical probability distributions with autocorrelation matrices
and
.
We scale rule (20) for the task of recognizing signals of the form in (15) with an arbitrary number of hypotheses
:
Assuming the homogeneity of the pair of signals
and
in the sample
and considering that
,
and
, we present Rule (21) in the form
where the solving statistics of the relative entropy functional
are determined on the
-set of pairs of sample distributions
,
,
.
An alternative to Expressions (23) and (24) may be to take into account the principle of the minimum value of information non-directional mismatch
between stochastic signals
and
,
, in the rule (22):
where the decision statistics
are determined by Expression (23).
Expression (25) is a particular case of Criterion (22), provided that with an unlimited increase in the volume of training samples , the second term in Expression (21) asymptotically reduces to zero: . Thus, the transition from Rule (22) to (25) is appropriate provided that there is a significant asymmetry in the values of the decision statistics (23), (24).
The probability
of confusion of the
-th and
-th signals,
, from the user database of a priori data
in the formalism of Rule (22) can be described by the expression
If we take into account that the empirical signal before recognition is normalized to the value of its specific entropy, then the system of asymptotic equations
is satisfied. We take this fact into account by presenting the solving statistics
in the
-distribution formalism with
degrees of freedom:
, where
is an auxiliary variable. Substitute the obtained expression for statistics
into Expression (26):
where
and
are the specific values of the information discrepancy for the studied pair of distributions
and
at
, and
is an auxiliary variable of the same type as
. If we assume the mutual noncorrelation of the three
-distributions in Expression (27), then Expression (26) for calculating the probability of confusion
can be represented as
, where
and
are statistics of the
-distribution with
degrees of freedom. Accordingly, the upper limit of the probability of confusion
can be estimated by the expression
where
and
are statistics of the
-distribution with
and
degrees of freedom, respectively;
is the integral function of the
-distribution with
degrees of freedom.
From Expression (28), it follows that there are essentially unequal distributions of statistics and a pair of statistics , provided that . Thus, Expression (28) theoretically proves the correctness of Expressions (23) and (24) concerning the asymmetry of the value of information discrepancy, which is taken into account in the decision rule (22). This means that when the condition is satisfied, it is more appropriate to apply the decision rule (22) rather than (25) to make decisions about the recognition of language units in the speech signal parameterized in the paradigm of concept (8)–(10). This thesis will be tested in the experimental part of this article.
Assume that when recognizing the signal under study using the decision rule (25), the verdict was erroneously in favor of the hypothesis
, not the hypothesis
. Suppose also that when recognizing the same signal using decision rule (22), the verdict was made in favor of the hypothesis
. The stated assumptions assume that according to Expressions (25) and (26), inequalities
and
were fulfilled simultaneously, which is possible only if the condition
is satisfied. Thus, an analytical indication of the erroneousness of the decision made under Rule (25) concerning the analyzed sample
may be inequality of the form
or
where
,
are the specific values of the solving statistics (23), (24), respectively;
is the threshold value (minimum value of the asymmetry coefficient of the values (23) and (24) in Rule (22)), set depending on the maximum permissible error
Repeating the considerations that accompanied the transition from Expressions (26) to (28), we rewrite the defined expression to determine the probability
in terms of the
-distribution:
Analyzing Expression (30), we obtain an equation , where is the quantile of the -distribution with degrees of freedom and the level of significance . For example, for and from the tables for -distribution, we have: .
Thus, Rule (29) allows us to estimate the probability of the event of marginal recognition of the correct result of the phoneme recognition procedure, employing the decision rule (25). The stochastic estimate of such an event is characterized by the expression
and is determined by the result of comparing the opposing elements
and
in the matrix
.





{kind=link}
{kind=link}
{kind=link}


